PySpark包依賴問題解決方案及實踐
摘要:
hadoop yarn排程pyspark在使用過程中,使用場景不一致,需要安裝一些三方依賴,尤其在機器學習演算法方面依賴許多科學包如numpy、pandas 、matlib等等,安裝這些依賴是一個非常痛苦的過程,本章結合ti產品在私有化過程中依賴包及版本升級等爲題進行簡單介紹。
Spark on yarn分爲client模式和cluster模式,在client模式下driver 會執行在提交節點上,該節點也可能不是yarn叢集內部節點,這種方式可以根據自己的需要安裝軟體和依賴,以支撐spark application正常執行。而在cluster模式下,spark application執行的所有進程都在yarn叢集的nodemanager上,具體那些節點不確定,這時候就需要叢集中所有nodemanager都有執行python程式所需要的依賴包。 在智慧鈦私有化過程中是通過:anaconda進行包管理和初始環境安裝。
初始安裝:安裝初始ancoda-》安裝所需要的依賴包-》編寫rpm編譯指令碼-》打包成rpm包:之所以採用rpm進行管理,是因爲rpm包進行安裝、升級、回退。維護相對比較方便,大數據平臺ambari可以很好的完成rpm包的自動化安裝部署升級。
Name: anaconda2
Version: 4.4.0
Release: 0
License: Restricted
Group: Apache/Hue
BuildRoot: %{_builddir}/%{name}-anaconda2
URL: http://gethue.com/
Vendor: Tencent
Packager: test
BuildArchitectures: x86_64
Requires: jdk >= 1.6
%description
Anaconda2
%prep
%build
pwd
%install
pwd
rm -rf $RPM_BUILD_ROOT
mkdir -p $RPM_BUILD_ROOT/data/anaconda2-4.4.0
cp -arf %{_sourcedir}/anaconda2-4.4.0.zip $RPM_BUILD_ROOT/data/anaconda2-4.4.0
pwd
%post
cd /data/anaconda2-4.4.0
unzip -qq anaconda2-4.4.0.zip && rm -rf anaconda2-4.4.0.zip
%postun
rm -rf /data/anaconda2-4.4.0
%files
%defattr(-,root,root)
%attr(755,root,root) /data/anaconda2-4.4.0
%clean
rm -rf $RPM_BUILD_ROOT
#!/bin/bash
curdir=$(dirname $(readlink -f $0))
echo $curdir
cd $curdir
last_changed_version=$1
if [[ -d $curdir ]]; then
rpmbase=$(rpm --showrc | grep _topdir | grep -v % | awk '{print $3}')
rpmsrc=$rpmbase/SOURCES
rpmspec=$rpmbase/SPECS
rm -rf $rpmsrc/anaconda2-4.4.0.zip
cp anaconda2-4.4.0.zip $rpmsrc
cp anaconda2.spec $rpmspec/anaconda2.spec
sed -i "s/Release:.*/Release:${last_changed_version}/g" $rpmspec/anaconda2.spec
rpmbuild -bb $rpmspec/anaconda2.spec
fi
包更新升級,如果有python包更新,可以重新打rpm 然後yum update 更新操作
使用用戶端 spark-submit 在設定pyspark演算法,如模型評估、視覺化演算法時,通常會依賴許多包和升級問題,如上圖安裝升級相關包,然後再重新打包rpm,在環境中進行yum update 進行升級。還是挺方便的。
對接使用者的cdh叢集情況:
當對接cdh時候, 這時候肯定不能往hadoop 叢集所有機器安裝python環境,這個時候pyspark程式預設提交節點採用client模式,每台執行機器機器上自帶anaconda python環境,就對使用者環境產生較小的影響,同時也能保證功能的正常使用。如果要用cluster模式就最好使用spark spark.yarn.archive 等方式
其他包依賴方案:
files to be distributed with your application. If you depend on multiple Python files we recommend
packaging them into a .zip or .egg.
另外還有一種:
當有某些特別依賴看,比如tensorflow、cafe、xgboost:可以把python整個環境打包成zip包,提交指令碼可以使用
spark.yarn.dist.archives | spark.pyspark.python 來指定python依賴包
操作步驟:
-
將帶有python環境的打包(這裏暫時使用anaconda),也可以其它python環境。

-
hadoop fs -put anaconda2.zip /data 上傳到hdfs目錄

spark-conf中設定
spark.yarn.dist.archives=hdfs://hdfsCluster/data/anaconda2.zip#anaconda2
spark.pyspark.python=./anaconda2/anaconda2/bin/python2
注:此時應特別注意解壓路徑,在anaconda2.zip在本地解壓後,python的可執行路徑爲anaconda2/bin/python2,但在伺服器上面會多一層。
測試指令碼:
from __future__ import print_function
import sys
from operator import add
from pyspark import SparkContext
if __name__ == "__main__":
if len(sys.argv) != 2:
print("Usage: wordcount <file>", file=sys.stderr)
exit(-1)
import numpy
import pandas
print("------------teslatest---------")
print(numpy.__version__)
print(pandas.__version__)
sc = SparkContext(appName="PythonWordCount")
lines = sc.textFile(sys.argv[1], 1)
counts = lines.flatMap(lambda x: x.split(' ')) \
.map(lambda x: (x, 1)) \
.reduceByKey(add)
output = counts.collect()
for (word, count) in output:
print("%s: %i" % (word, count))
sc.stop()
執行結果:列印了pandas 及numpy版本。
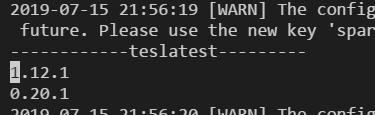
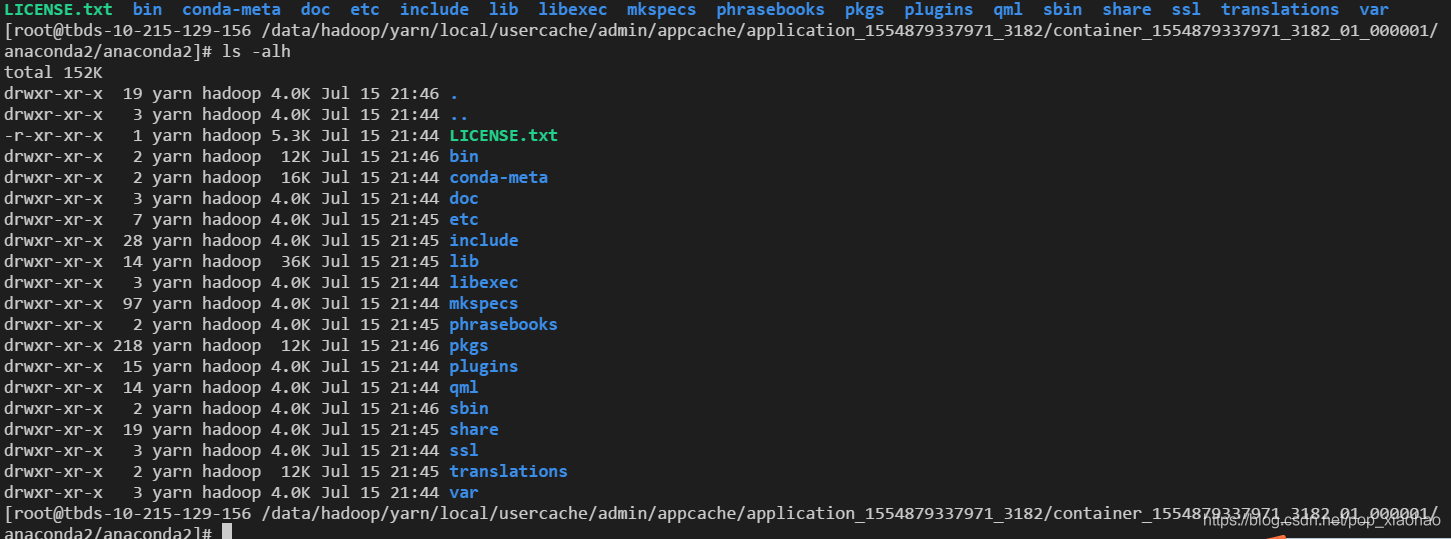
/data/hadoop/yarn/local/usercache/admin/appcache/application_1554879337971_3182/container_1554879337971_3182_01_000001/anaconda2/anaconda2
同時我們可以看到anaconda2 的python環境 同步到了nodemanager 本機
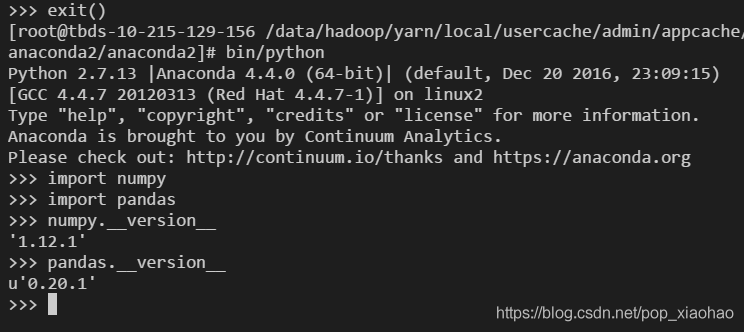
再來看下本機器上的python包版本情況
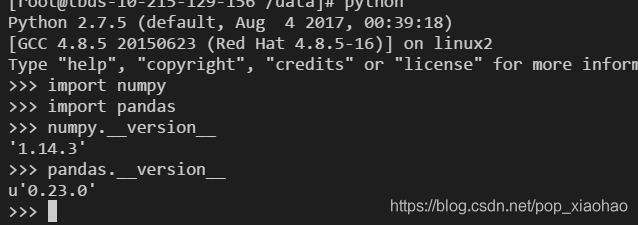
驗證spark執行pyspark對應的numpy版本以及pandas版本,可以得知確實是使用的hdfs中的包。
so如果大家在有包依賴的問題,可以使用後面的終極大招。