專案— —python構建一個網路爬蟲應用
本專案使用python的requests庫和BeautifulSopu來進行網頁內容的爬取,首先簡單介紹這兩個庫,之後說明爬取網頁內容的一般步驟,最後以爬取豆瓣讀書top250中的前50本書爲例說明實際的python爬蟲應用應該怎麼去構建。
1、requests庫
requests 庫是一個簡潔且簡單的處理HTTP請求的第三方庫。
request 庫支援非常豐富的鏈接存取功能,包括:國際域名和URL 獲取、HTTP 長連線和連線快取、HTTP 對談和Cookie 保持、瀏覽器使用風格的SSL 驗證、基本的摘要認證、有效的鍵值對Cookie 記錄、自動解壓縮、自動內容解碼、檔案分塊上傳、HTTP(S)代理功能、連線超時處理、流數據下載等。
requests學習資料我推薦看官方文件快速上手部分,這將會讓你快速瞭解request的使用方法。
其他資料:
2. BeautifulSoup庫
簡單來說,Beautiful Soup是python的一個庫,最主要的功能是解析網頁從而抓取需要的數據。官方解釋如下:Beautiful Soup提供一些簡單的、python式的函數用來處理導航、搜尋、修改分析樹等功能。它是一個工具箱,通過解析文件爲使用者提供需要抓取的數據,因爲簡單,所以不需要多少程式碼就可以寫出一個完整的應用程式。
BeautifulSoup學習資料我只推薦看官方文件。
3. 爬蟲一般步驟
在對requests和BeautifulSoup這兩個庫有初步的瞭解之後,你就可以通過一個或幾個實戰的小專案來加深對python爬蟲的理解,但在這之前我想要先根據我的經驗來說明一下我在實際的編寫爬蟲程式碼的過程中遵循的一些步驟。
3.1 爬取HTML頁面通用步驟
def getHTMLText( url ):
"""
爬取HTML網頁通用框架
:param url: 鏈接
:return: text
"""
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/49.0.2623.221 Safari/537.36 SE 2.X MetaSr 1.0'}
r = requests.get(url, headers=headers)
r.encoding = r.apparent_encoding
text = r.content.decode('utf-8')
# text = r.text
return text
接着,我們逐行解析以上的程式碼。在使用requests的get()函數獲取網頁HTML之前,我們首先要構造一個請求頭。因爲我們要爬取的很多網站都有反爬蟲的措施,如果我們簡單地給get()函數一個url鏈接,那麼大概率會被網站識別這個請求來源於爬蟲。因此我們需要提前僞造一個請求頭,讓網站以爲我們的請求是來源於瀏覽器,這樣就可以避免被網站判斷爲是爬蟲請求。
舉個例子,假設現在我們要爬取豆瓣主頁的內容,程式碼如下
url = "https://www.douban.com/"
headers = {'User-Agent':
'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/49.0.2623.221 Safari/537.36 SE 2.X MetaSr 1.0'}
r = requests.get(url, headers=headers) # 構造請求頭
print(r.status_code)
print(r.encoding)
r_n = requests.get(url, headers=None) # 沒有構造請求頭
print(r_n.status_code)
print(r_n.encoding)
執行以上程式碼後我們將會得到以下結果
200
utf-8
418
None
我們可以看出,未構造請求頭不能正常爬取網頁內容。
其次,我們關注text = r.content.decode('utf-8')。通常情況下,r.text返迴文字字串,r.content返回二進制內容。但是,我們在獲得HTML內容時用的卻是r.content而不是r.text,這是因爲我們在使用BeautifulSoup解析頁面內容時,如果我們將r.text傳入,則會導致亂碼,相反的如果我們將r.content先轉碼爲utf-8然後傳入BeautifulSoup則可以避免亂碼(經驗之談)。因此無論我們需要文字內容還是二進制圖片等內容,一般我們都使用r.content。
3.2 使用BeautifulSoup解析HTML頁面
def get_soup(url):
"""
使用bs4解析HTML頁面
"""
text = getHTMLText(url)
soup = BeautifulSoup(text, 'lxml')
print(soup.prettify()) # 格式化列印HTML介面
return soup
使用BeautifulSoup解析HTML頁面後會返回soup物件,接下來我們就要通過使用soup物件對應的方法來從HTML頁面中找到我們需要的內容。
3.3 獲取資訊
在得到soup物件之後,我們就要開始解析HTML頁面以此獲得我們需要的資訊。這部分我將以獲取豆瓣讀書top50的圖書鏈接爲例來說明如何通過解析HTML來獲取我們所需的資訊。
首先,我們通過搜尋得到豆瓣讀書TOP50鏈接有兩個,每個頁面包含25本圖書的資訊,我們要通過解析這兩個HTML頁面來獲取50本圖書的鏈接。
urls = ["https://book.douban.com/top250?start=0",
"https://book.douban.com/top250?start=25"]
其次我們將每個鏈接對應的HTML頁面通過BeautifulSoup進行解析。得到一個soup物件
soup = get_soup(url)
通過使用瀏覽器開發者工具,我們可以找到圖書鏈接對應的tag位置。我們可以看到對於每一本書的鏈接,我們可以通過逐步深入tag來找到,如 tr->td->a[‘href’]。由此,通過使用soup.find_all(‘tr’, class_=‘item’)函數便可以獲取該HTML頁面中所有圖書對應的tag範圍,然後逐步深入tag直到獲得圖書鏈接。程式碼如下
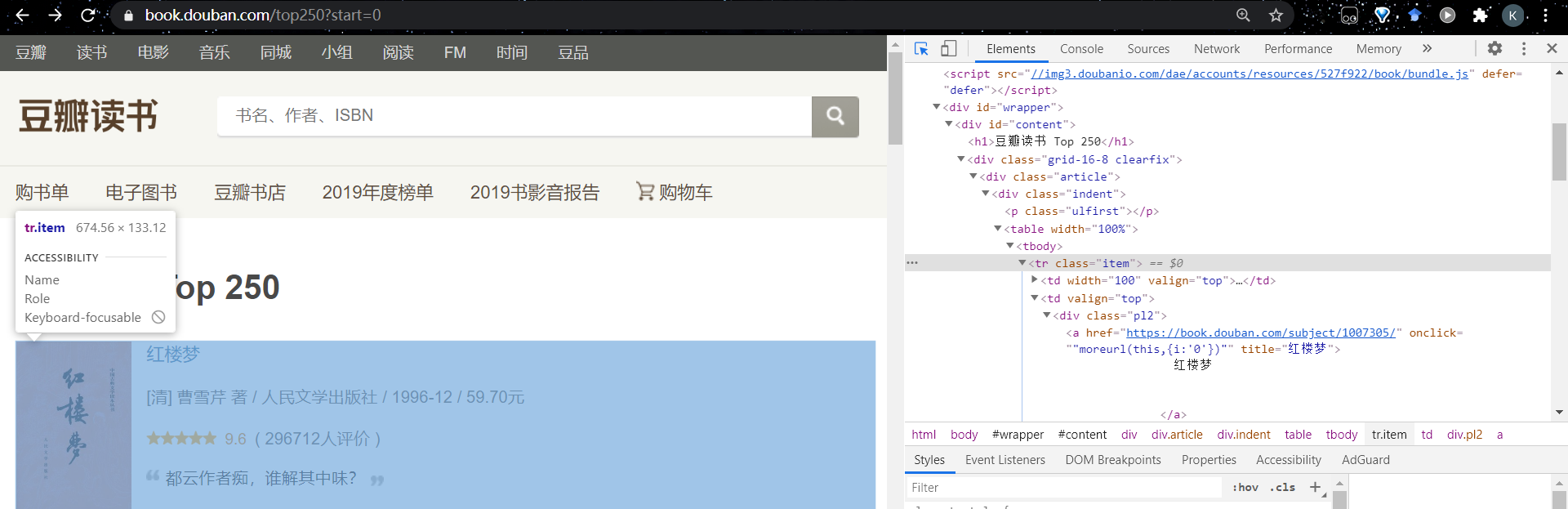
def get_books_link():
# 得到豆瓣讀書TOP50鏈接
urls = ["https://book.douban.com/top250?start=0",
"https://book.douban.com/top250?start=25"] # 可新增頁面鏈接獲得更多圖書鏈接
book_links = []
for url in urls:
soup = get_soup(url)
children = soup.find_all('tr', class_='item')
for child in children:
book_links.append(child.td.a.attrs['href'])
return book_links
3.4 總結
以上就是使用requests庫和BeautifulSoup庫進行網路爬蟲(HTML資訊獲取)的一般步驟。下面 下麪指令碼完整實現了爬取豆瓣讀書top50書籍資訊的程式碼:
import requests
from bs4 import BeautifulSoup
import re
import pandas as pd
def getHTMLText( url ):
"""
爬取HTML網頁通用框架
:param url: 鏈接
:return: text
"""
headers = {'User-Agent':
'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/49.0.2623.221 Safari/537.36 SE 2.X MetaSr 1.0'
}
r = requests.get(url, headers=headers)
r.encoding = r.apparent_encoding
text = r.content.decode('utf-8')
# text = r.text
return text
def get_soup(url):
"""
使用bs4解析HTML頁面
"""
text = getHTMLText(url)
soup = BeautifulSoup(text, 'lxml')
# print(soup.prettify())
#print(soup.original_encoding)
return soup
def get_books_link():
# 得到豆瓣讀書TOP50鏈接
urls = ["https://book.douban.com/top250?start=0",
"https://book.douban.com/top250?start=25"] # 可新增頁面鏈接獲得更多圖書鏈接
book_links = []
for url in urls:
soup = get_soup(url)
children = soup.find_all('tr', class_='item')
for child in children:
book_links.append(child.td.a.attrs['href'])
return book_links
def get_book_name(soup):
"""
得到書名
"""
children = soup.find_all('span', property="v:itemreviewed")
for child in children:
book_name = child.string # just once
return book_name
def get_publication_status(soup):
"""
得到圖書出版情況
"""
def pares(s):
# 使用正則表達式匹配沒有標籤的文字
c = re.compile(r'<span class="pl">(.*?):</span>(.*?)<br/>')
return (c.findall(s))
children = soup.find_all('div', id='info')
for child in children:
info = pares(str(child))
info_dit = {}
for i in range(len(info)):
if info[i][0] == "出版社":
info_dit['出版社'] = info[i][1].strip()
elif info[i][0] == "出版年":
info_dit['出版年'] = info[i][1].strip()
elif info[i][0] == "定價":
info_dit["定價"] = info[i][1].strip()
publication_status = child.a.string.replace(' ', '').replace('\n', '')+ '/' + info_dit['出版社'] + '/' + \
info_dit["出版年"] + '/' + info_dit["定價"]
return publication_status
def get_score(soup):
"""
得到評分
"""
children = soup.find_all('div', id="interest_sectl")
for child in children:
score = child.strong.string.replace(' ', '').replace('\n', '')
return score
def get_votes(soup):
"""
得到評分人數
"""
children = soup.find_all('div', id="interest_sectl")
for child in children:
votes = child.find_all('span', property="v:votes")[0].string.replace(' ', '').replace('\n', '')
return votes
def get_star_rate(soup, star_num):
"""
得到星比例
"""
children = soup.find_all('div', id="interest_sectl")
for child in children:
chileren2 = child.find_all('span', class_="rating_per")
votes = []
for child2 in chileren2:
vote = child2.string.replace(' ', '').replace('\n', '')
votes.append(vote)
return votes[int(star_num-1)]
if __name__ == '__main__':
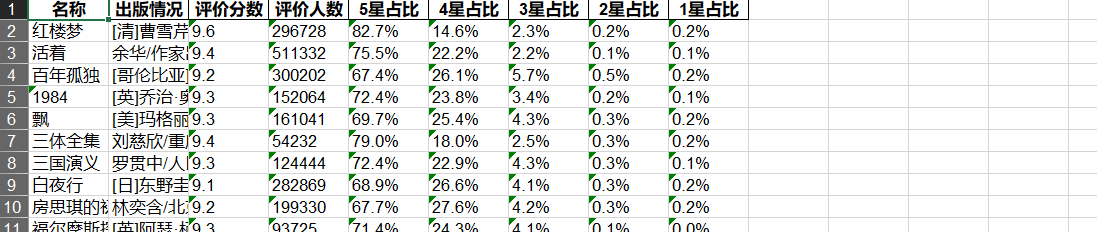
columns = ["名稱", "出版情況", "評價分數", "評價人數", "5星佔比",
"4星佔比", "3星佔比", "2星佔比", "1星佔比"]
book_info = pd.DataFrame(columns=columns)
book_links = get_books_link()
for link in book_links:
soup = get_soup(link)
data = []
data.append(get_book_name(soup))
data.append(get_publication_status(soup))
data.append(get_score(soup))
data.append(get_votes(soup))
for i in range(5):
data.append(get_star_rate(soup, i+1))
print(len(data))
book_info.loc[len(book_info)] = data
book_info.to_excel('./豆瓣讀書Top50.xls',sheet_name='豆瓣讀書Top50', index=False)
print(book_info)
執行結果如下: