知識圖譜學習總結(持續更新)
知識圖譜學習總結(持續更新)
目錄
一、知識圖譜的定義
知識圖譜(Knowledge Graph)以結構化的形式描述客觀世界中概念、實體及其關係,將網際網路的資訊表達成更接近人類認知世界的形式,提供了一種更好地組織、管理和理解網際網路海量資訊的能力。知識圖譜給網際網路語意搜尋帶來了活力,同時也在智慧問答中顯示出強大威力,已經成爲網際網路知識驅動的智慧應用的基礎設施。知識圖譜與大數據和深度學習一起,成爲推動網際網路和人工智慧發展的核心驅動力之一。
知識圖譜不是一種新的知識表示方法,而是知識表示在工業界的大規模知識應用,它將網際網路上可以識別的客觀物件進行關聯,以形成客觀世界實體和實體關係的知識庫,其本質上是一種語意網絡,其中的節點代表實體(entity)或者概念(concept),邊代表實體/概念之間的各種語意關係。知識圖譜的架構,包括知識圖譜自身的邏輯結構以及構建知識圖譜所採用的技術(體系)架構。知識圖譜的邏輯結構可分爲模式層與數據層,模式層在數據層之上,是知識圖譜的核心,模式層儲存的是經過提煉的知識,通常採用本體庫來管理知識圖譜的模式層,藉助本體庫對公理、規則和約束條件的支援能力來規範實體、關係以及實體的型別和屬性等物件之間的聯繫。數據層主要是由一系列的事實組成,而知識將以事實爲單位進行儲存。在知識圖譜的數據層,知識以事實,(fact)爲單位儲存在圖數據庫。如果以「實體-關係-實體」或者「實體-屬性-性值」三元組作爲事實的基本表達方式,則儲存在圖數據庫中的所有數據將構成龐大的實體關係網路,形成「知識圖譜」。
知識圖譜在以下應用中已經凸顯出越來越重要的應用價值:
- 知識融合:當前網際網路大數據具有分佈異構的特點,通過知識圖譜可以對這些數據資源進行語意標註和鏈接,建立以知識爲中心的資源語意整合服務;
- 語意搜尋和推薦:知識圖譜可以將使用者搜尋輸入的關鍵詞,對映爲知識圖譜中客觀世界的概念和實體,搜尋結果直接顯示出滿足使用者需求的結構化資訊內容,而不是網際網路網頁;
- 問答和對話系統:基於知識的問答系統將知識圖譜看成一個大規模知識庫,通過理解將使用者的問題轉化爲對知識圖譜的查詢,直接得到使用者關心問題的答案;
- 大數據分析與決策:知識圖譜通過語意鏈接可以幫助理解大數據,獲得對大數據的洞察,提供決策支援。
當前知識圖譜中包含的主要幾種節點有:
- 實體:指的是具有可區別性且獨立存在的某種事物。如某一個人、 某一座城市、某一種植物、某一件商品等等。世界萬物由具體事物組成,此指實體。實體是知識圖譜中的最基本元素,不同的實體間存在不同的關係。
- 概念:具有同種特性的實體構成的集合,如國家、民族、書籍、電腦等。
- 屬性:用於區分概唸的特徵,不同概念具有不同的屬性。不同的屬性值型別對應於不同類型屬性的邊。如果屬性值對應的是概念或實體,則屬性描述兩個實體之間的關係,稱爲物件屬性;如果屬性值是具體的數值,則稱爲數據屬性。
二、知識圖譜的發展歷史
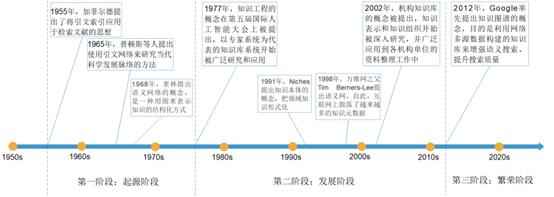
知識圖譜始於20世紀50年代,至今大致分爲三個發展階段:
第一階段(1955年-1977年)是知識圖譜的起源階段,在這一階段中引文網路分析開始成爲一種研究當代科學發展脈絡的常用方法;
第二階段(1977年-2012年)是知識圖譜的發展階段,語意網得到快速發展,「知識本體」的研究開始成爲電腦科學的一個重要領域,知識圖譜吸收了語義網、本體在知識組織和表達方面的理念,使得知識更易於在計算機之間和計算機與人之間交換、流通和加工;
第三階段(2012年-至今)是知識圖譜繁榮階段,2012年穀歌提出Google Knowledge Graph,知識圖譜正式得名,谷歌通過知識圖譜技術改善了搜尋引擎效能。在人工智慧的蓬勃發展下,知識圖譜涉及到的知識抽取、表示、融合、推理、問答等關鍵問題得到一定程度的解決和突破,知識圖譜成爲知識服務領域的一個新熱點,受到國內外學者和工業界廣泛關注。知識圖譜具體的發展歷程如圖1所示。
三、知識圖譜的重要性
1、知識圖譜是人工智慧的重要基石
人工智慧分爲兩個層次:感知層與認知層。首先感知層,即計算機的視覺、聽覺、觸覺等感知能力,目前人類在語音識別、影象識別等感知領域已取得重要突破,機器在感知智慧方面已越來越接近於人類;第二個層次是認知層,是指機器能夠理解世界和具有思考的能力。認知世界是通過大量的知識積累實現的,要使機器具有認知能力,就需要建立一個豐富完善的知識庫,因此從這個角度說,知識圖譜是人工智慧的一個重要分支,也是機器具有認知能力的基石,在人工智慧領域具有非常重要的地位。
2、知識圖譜推動智慧應用
知識圖譜將人與知識智慧地連線起來,能夠對各類應用進行智慧化升級,爲使用者帶來更智慧的應用體驗。知識圖譜是一個宏大的數據模型,可以構建龐大的「知識」網路,包含客觀世界存在的大量實體、屬性以及關係,爲人們提供一種快速便捷進行知識檢索與推理的方式。近些年蓬勃發展的人工智慧本質上是一次知識革命,其核心在於通過數據觀察與感知世界,實現分類預測、自動化等智慧化服務。知識圖譜作爲人類知識描述的重要載體,推動着資訊檢索、智慧問答等衆多智慧應用。
3、知識圖譜是強人工智慧發展的核心驅動力之一
儘管人工智慧依靠機器學習和深度學習取得了快速進展,但嚴重依賴於人類的監督以及大量的標註數據,屬於弱人工智慧智慧範疇,離強人工智慧仍然具有較大差距,而強人工智慧的實現需要機器掌握大量的常識性知識,同時以人的思維模式和知識結構來進行語言理解、視覺場景解析和決策分析。如圖2所示,知識圖譜技術將資訊中的知識或者數據加以關聯,實現人類知識的描述及推理計算,並最終實現像人類一樣對事物進行理解與解釋。知識圖譜技術是由弱人工智慧發展到強人工智慧過程中的必然趨勢,對於實現強人工智慧有着重要的意義。
四、相關會議及高被引論文
表1展示知識圖譜領域10個相關重要國際學術會議,這些會議爲知識圖譜領域的研究方向、技術趨勢與學者研究成果提供重要資訊,爲本報告研究學者的選取提供依據。
| 會議簡稱 | 會議全稱 |
|---|---|
| ACL | Association of Computational Linguistics |
| EMNLP | Empirical Methods in Natural Language Processing |
| WWW | International World Wide Web Conference |
| ISWC | International Semantic Web Conference |
| IJCAI | International Joint Conference on Artificial Intelligence |
| AAAI | National Conference of the American Association for Artificial Intelligence |
| COLING | International Conference on Computational Linguistics |
| KR | International Conference on Principles of KR & Reasoning |
| KDD | ACM International Conference on K nowledge Discovery and Data Mining |
| CIKM | ACM International Conference on Information and Knowledge Management |
有關知識圖譜所有論文參照量最高的前十篇論文爲:
| 序號 | 論文題目 |
|---|---|
| 1 | Distant supervision for relation extraction without labeled data–Mike Mintz, Steven Bills, Rion Snow, and Dan Jurafsky.ACL/IJCNLP,2009. |
| 2 | You are where you tweet: a content-based approach to geo-locating twiter users–Zhiyuan Cheng, James Caverlee, and Kyumin Lee.CIKM,2010. |
| 3 | YAGO2: a spatially and temporally enhanced knowledge base from Wikipedia–Johannes Hoffart, Fabian M. Suchanek, Klaus Berberich, and Gerhard Weikum.IJCAI,2013. |
| 4 | Knowledge vault: a web-scale approach to probabilistic knowledge fision–Xin Dong 0001, Evgeniy Gabrilovich, Geremy Heitz, Wilko Horn, Ni Lao, Kevin Murphy, Thomas Strohmann, Shaohua Sun, and Wei Zhang.KDD,2014. |
| 5 | Robust discambiguation of named entities in text–Johannes Hoffart, Mohamed Amir Yosef, llaria Bordino, Hagen Firstenau, Manfred Pinkal, Marc Spaniol, Bilyana Taneva, Stefan Thater, and Gerhard Weikum. EMNLP,2011. |
| 6 | BabelNet: building a very large mulingual semantic network–Roberto Navigli, and Simone Paolo Ponzetto.ACL,2010. |
| 7 | Driving with knowledge firom the physical world–Jing Yuan, Yu Zheng, Xing Xie, and Guangzhong Sun.KDD,2011. |
| 8 | Open domain event extraction from twitter–Alan Ritter, Mausam, Oren Etzioni, and Sam Clark KDD,2012. |
| 9 | Sentiment analysis of blogs by combining lexical knowledge with text classification–Prem Melville, Wojciech Gryc, and Richard D. Lawrence. KDD,2009. |
| 10 | Open information extraction: the second generation–Etzioni, Oren and Fader, Anthony and Christensen, Janara and Soderland, Stephen and Mausam, Mausam.IJCAI, 2011 |
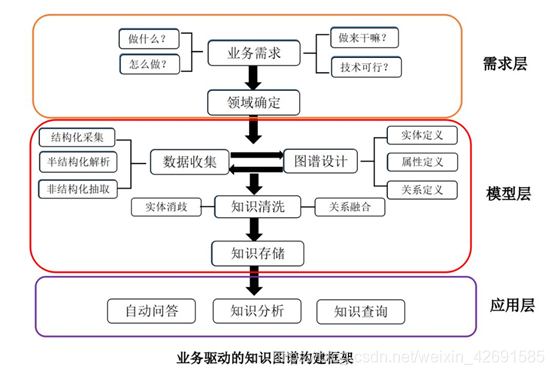
五、知識圖譜的構建
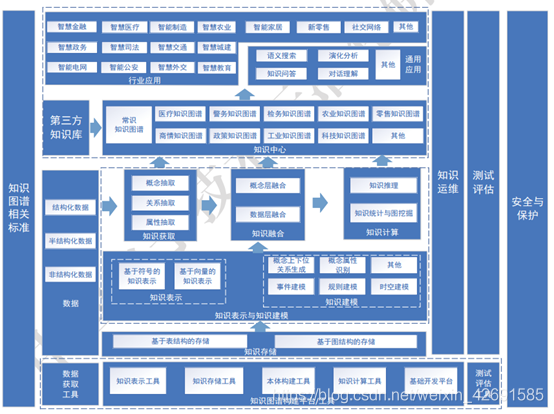
知識圖譜主要技術包括知識獲取、知識表示、知識儲存、知識建模、知識融合、知識理解、知識運維等七個方面,通過面向結構化、半結構化和非結構化數據構建知識圖譜爲不同領域的應用提供支援,具體的技術架構圖如圖3所示。
通用的基於本體的知識圖譜構建架構如圖4所示,其中虛線框內的部分爲知識圖譜的構建過程,同時也是知識圖譜更新的過程。
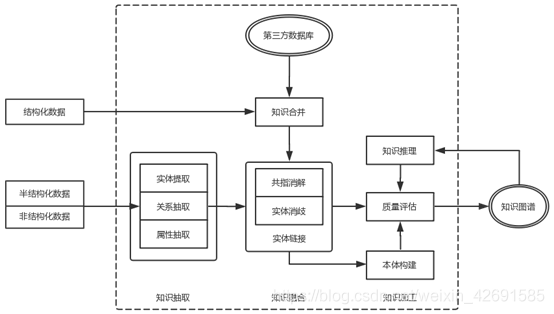
知識圖譜的構建的原始數據包含結構化數據、半結構化數據、非結構化數據三種,通過一系列自動化或半自動化的技術手段,從原始數據中提取出知識要素(即實體及其關係),將其存入知識圖譜的模式層與數據層。
構建知識圖譜是一個迭代更新的過程,根據知識獲取的邏輯,每一輪迭代包含三個階段:知識抽取、知識融合、知識加工。
1 知識抽取
知識圖譜中的知識來源於結構化、半結構化和非結構化的資訊資源,如圖5所示。知識抽取技術從這些不同結構和型別的數據中提取出計算機可理解和計算的結構化數據,以供進一步的分析和利用。知識獲取即是從不同來源、不同結構的數據中進行知識提取,形成結構化的知識並存入到知識圖譜中。當前,知識獲取主要針對文字數據進行,需要解決的抽取問題包括:實體抽取、關係抽取、屬性抽取和事件抽取。
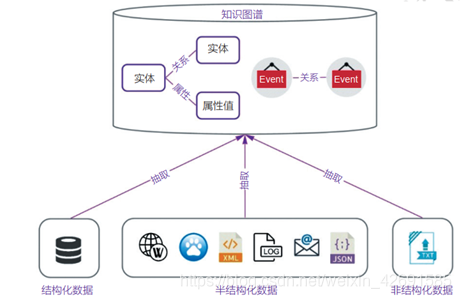
1.1 實體抽取
實體抽取也稱爲命名實體識別( named entity recognition,NER ),是指從文字語料庫中自動識別出專有名詞(如機構名、地名、人名、時間等)或有意義的名詞性短語,實體抽取的準確性直接影響知識獲取的品質和效率。
如:姚明、易建聯
實體抽取是知識圖譜構建和知識獲取的基礎和關鍵。爲了解決早期的實體抽取方法存在的問題,規則和監督學習相結合的方法、半監督方法、遠端監督方法以及海量數據的自學習方法等被相繼提出。
1.2 關係抽取
關係抽取是利用多種技術自動從文字中發現命名實體之間的語意關係,將文字中的關係對映到實體關係三元組上。較於實體抽取,關係抽取更加複雜,研究的難點主要體現在並非所有的關係都很明顯,即關係表達的隱含性;實體關係不僅有二元,還有多元,即關係的複雜性;一種關係可能會有多種表述形式,如A位於B或B的省會是A,即語言的多樣性。
如:姚明 → (朋友) → 易建聯
1.3 屬性抽取
從不同資訊源中採集特定實體的屬性資訊。
屬性主要是針對實體而言的,以實現對實體的完整描述,由於可以把實體的屬性看作實體與屬性值之間的一種名詞性關係,所以屬性抽取任務就可以轉化爲關係抽取任務,例如,[Guo et al., 2012] 採用SVM方法將人物屬性抽取問題轉化爲人物的關係抽取,[Suchaneketal,2007] 提出的基於規則與啓發式的抽取方法能夠從Wikipedia和WordNet半結構化網頁中自動抽取出屬性和屬性值,其抽取的準確率可達95%,並因此得到了著名的本體知識庫YOGO,還有直接從非結構化文字中挖掘出實體屬性名稱和屬性值之間的位置關係模式的屬性抽取的方法 [劉嶠等,2016]。
如:姚明的生日、身高等資訊
1.4 事件抽取
事件是發生在某個特定時間點或時間段、某個特定地域範圍內,由一個或者多個角色參與的一個或者多個動作組成的事情或者狀態的改變。目前已存在的知識資源(如維基百科等)所描述實體及實體間的關聯關係大多是靜態的,事件能描述粒度更大的、動態的、結構化的知識,是現有知識資源的重要補充。
2 知識融合
知識融合的概念最早出現在1983年發表的文獻 [HOLSAPPLEC,et al,1983] 中,並在20世紀九十年代得到研究者的廣泛關注。而另一種知識融合的定義是指對來自多源的不同概念、上下文和不同表達等資訊進行融合的過程[維基百科]。[A .Smirnov, et a1,2002] 認爲知識融合的目標是產生新的知識,是對松耦合來源中的知識進行整合,構成一個合成的資源,用來補充不完全的知識和獲取新知識。[唐曉波,魏巍,et al,2015] 在總結衆多知識融合概唸的基礎上認爲知識融合是知識組織與資訊融合的交叉學科,它面向需求和創新,通過對衆多分散、異構資源上知識的獲取、匹配、整合、挖掘等處理,獲取隱含的或有價值的新知識,同時優化知識的結構和內涵,提供知識服務。
通過知識抽取獲得的資訊具有以下兩個問題:資訊之間關係扁平化,缺乏層次性與邏輯性;存在大量冗餘資訊。採用知識融合解決上述問題,主要包含兩個部分:實體鏈接、知識合併,其中,實體鏈接涉及共指消解、實體消歧兩種技術。
2.1 實體鏈接
實體鏈接(Entity Linking)是指對於從文字中抽取得到的實體物件,將其鏈接到知識庫中對應的正確實體物件的操作。其基本思想從文字中通過實體抽取得到實體項,進行共指消解、實體消歧,在確認知識庫中對應的正確實體物件之後,將該實體項鍊接到知識庫中對應實體。
- 共指消解
共指消解(Coreference Resolution)技術主要用於解決多個指稱對應同一實體物件的問題。
共指是NLP領域的概念,主要指多個名詞(包括代名詞、名詞短語)指向真實世界中的同一參照體,且這種指代脫離上下文仍然成立。
該任務通常通過混用基於實體屬性值相似度計算方法(比較描述實體的屬性和屬性值之間的異同)和基於本體語言等價推理的方法(推理不同實體標誌符間的物件共指關係)來完成。
- 實體消歧
實體消歧(Entity Disambiguation)技術主要用於解決同名實體產生歧義的問題。
該任務通常通過計算實體屬性之間的相似度,利用聚類模型來完成。
2.2 知識合併
2.1節中所述知識鏈接用於知識抽取後的半結構化數據與非結構化數據的處理,對於結構化數據,採用知識合併對冗餘資訊進行處理。
3 知識加工
知識加工主要包括三個方面的內容:本體構建、知識推理、品質評估。
3.1 本體構建
本體(Ontology)包含某個學科內的基本實體和實體之間的關係,是描述領域知識的通用概念模型。本體可以藉助本體編輯軟體手動構建,也可以以數據驅動的自動化方式構建。
3.2 知識推理
知識圖譜在完成本體構建後已經初具雛形,但知識之間的關係存在殘缺,採用知識推理進一步知識發現,從而對知識圖譜的知識進行補全。
知識推理主要分爲三大類:基於規則的推理、基於圖的推理、基於深度學習的推理。
3.3 品質評估
品質評估也是知識庫構建技術的重要組成部分,用於對知識的可信度進行量化,通過捨棄置信度較低的知識來保障知識圖譜的品質。
4 知識更新
從邏輯上看,知識圖譜的更新包括概念層的更新和數據層的更新。
- 概念層的更新
概念層的更新指新增數據後獲得了新的概念,需要自動將新的概念新增到知識圖譜的概念層中。
- 數據層的更新
數據層的更新主要是新增或更新實體、關係、屬性值,對數據層進行更新需要考慮數據源的可靠性、數據的一致性等,並選擇在各數據源中出現頻率高的事實和屬性加入知識圖譜。
知識圖譜的更新有兩種方式:全面更新、增量更新。
- 全面更新
全面更新指以更新後的全部數據爲輸入,從零開始構建知識圖譜。該方法較簡單,但資源消耗大。
- 增量更新
增量更新以當前新增數據爲輸入,向現有知識圖譜中新增新增知識。該方法較複雜,但資源消耗小。
5 通用知識圖譜應用
通用知識圖譜可以形象地看成一個面向通用領域的「結構化的百科知識庫」,其中包含了大量的現實世界中的常識性知識,覆蓋面極廣。由於現實世界的知識豐富多樣且極其龐雜,通用知識圖譜主要強調知識的廣度,通常運用百科數據進行自底向上(Top-Down)的方法進行構建。表3展示的即是常識知識庫型知識圖譜。

六、資料推薦
1、 清華大學楊玉基的「一種準確而高效的領域知識圖譜構建方法」,研究實現的衆包半自動語意標註系統, 在「四步法」中起着重要作用。相比於人工標註降低了標註難度; 相比於自動標註等方法能夠更好地保證標註品質, 還可以在標註過程中修改完善本體結構。本文還以地理學科知識圖譜爲例, 詳細介紹了「四步法」構建領域知識圖譜的過程。希望能爲其他研究者構建領域知識圖譜提供一定的借鑑。
2、華東理工大學胡芳槐的博士論文「基於多種數據源的中文知識圖譜構建方法研究」【,本文在現有知識圖譜及其本體構建研究的基礎上,研究從多種數據源中構建中文知識圖譜,在以下方面展開了研究工作:1.充分利用網際網路中的各類結構化或半結構化的資訊;2.研究如何綜合使用多種數據源構建中文知識圖譜,結合各種數據源的優勢;3.研究如何從大規模的網際網路文字中抽取知識圖譜形式的知識;4.對於行業知識圖譜的構建,研究如何利用行業內部的結構化數據;5.研究如何提供線上共同作業編輯平臺以有效地利用公衆共用知識的積極性。構建了一個知識圖譜線上編輯平臺,通過對學習演算法進行設定以啓動自動學習過程,然後在自動學習的結果上進行知識圖譜的編輯。該平臺主要優勢有:能夠支援大規模的使用者併發編輯;能夠與後臺的自動知識學習引擎結合。
3、部落格實戰推薦:
pelhans的從零開始構建知識圖譜系列文章:從零開始構建知識圖譜
浙江大學SimmerChan的實踐篇系列文章:實踐篇(一):數據準備和本體建模
4、Github六個知識圖譜實戰專案推薦
1)知識圖譜構建,自動問答,基於kg的自動問答。以疾病爲中心的一定規模醫藥領域知識圖譜,並以該知識圖譜完成自動問答與分析服務。
地址:https://github.com/liuhuanyong/QASystemOnMedicalKG
本專案立足醫藥領域,以垂直型醫藥網站爲數據來源,以疾病爲核心,構建起一個包含7類規模爲4.4萬的知識實體,11類規模約30萬實體關係的知識圖譜。 本專案將包括以下兩部分的內容:
- 基於垂直網站數據的醫藥知識圖譜構建
- 基於醫藥知識圖譜的自動問答
2)本專案提出了中文複合事件的概念與顯式模式,包括條件事件、因果事件、順承事件、反轉事件等事件抽取,並形成事理圖譜。
地址:https://github.com/liuhuanyong/ComplexEventExtraction
3)罪名法務智慧專案,內容包括856項罪名知識圖譜, 基於280萬罪名訓練庫的罪名預測,基於20W法務問答對的13類問題分類與法律資訊問答功能。
地址:https://github.com/liuhuanyong/CrimeKgAssitant
本專案將完成兩個大方向的工作: 1, 以罪名爲核心,收集相關數據,建成基本的罪名知識圖譜,法務資訊對話知識庫,案由量刑知識庫. 2, 分別基於步驟1的結果,完成以下四個方面的工作。
- 基於案由量刑知識庫的罪名預測模型
- 基於法務諮詢對話知識庫的法務問題型別分類
- 基於法務諮詢對話知識庫的法務問題自動問答服務
- 基於罪行知識圖譜的知識查詢
4)中文人物關係知識圖譜專案,內容包括中文人物關係圖譜構建,基於知識庫的數據回標,基於遠端監督與bootstrapping方法的人物關係抽取,基於知識圖譜的知識問答等應用。
地址:https://github.com/liuhuanyong/PersonRelationKnowledgeGraph
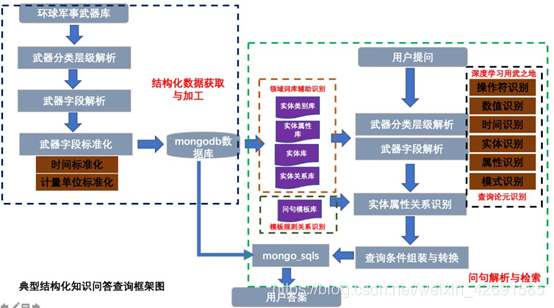
5)軍事知識圖譜。基於mongodb儲存的軍事領域知識圖譜問答專案,包括飛行器、太空裝備等8大類,100餘小類,共計5800項的軍事武器知識庫,該專案不使用圖數據庫進行儲存,通過jieba進行問句解析,問句實體項識別,基於查詢模板完成多類問題的查詢,主要是提供一種工業界的問答思想。
地址:https://github.com/liuhuanyong/QAonMilitaryKG
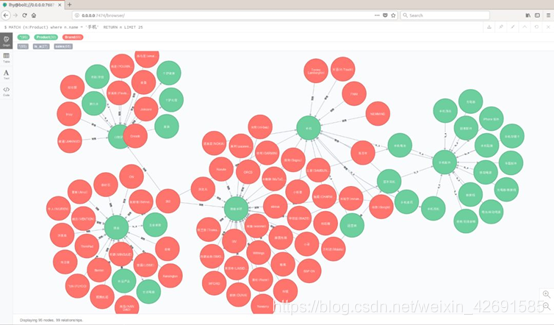
6)京東知識圖譜,基於京東網站的1300種商品上下級概念,約10萬商品品牌,約65萬品牌銷售關係,商品描述維度等知識庫,基於該知識庫可以支援商品屬性庫構建,商品銷售問答,品牌物品生產等知識查詢服務,也可用於情感分析等下遊應用。
地址:https://github.com/liuhuanyong/ProductKnowledgeGraph
參考文獻
[1] 楊玉基, 許斌, 胡家威, 仝美涵, 張鵬, 鄭莉. 一種準確而高效的領域知識圖譜構建方法[J]. 軟體學報, 2018, 29(10)
[2] 胡芳槐. 基於多種數據源的中文知識圖譜構建方法研究[D]. 華東理工大學, 2015.
[3] 2019知識圖譜標準化白皮書
[4] https://github.com/liuhuanyong/QASystemOnMedicalKG
https://github.com/liuhuanyong/ComplexEventExtraction
https://github.com/liuhuanyong/CrimeKgAssitant
https://github.com/liuhuanyong/PersonRelationKnowledgeGraph
https://github.com/liuhuanyong/QAonMilitaryKG
https://github.com/liuhuanyong/ProductKnowledgeGraph