比較詳細的java基礎之物件導向概念整理
物件導向的3個特徵
封裝、繼承,多型
封裝:把客觀的事物封裝成類,包括數據和方法。封裝把物件的設計者和物件的使用者分開,這樣有助於提高類和系統的安全性。
繼承:繼承就是指建立一個新的類,也就是派生類,繼承原有的類的數據和方法,也可以重新定義或者新增數據和方法。
多型:指的是,同一個操作作用於不同類中,將會產生不同的反應。也就是不同類的物件接收到相同訊息時,將會得到不一樣的結果。
什麼是物件導向?
物件導向程式設計是一種抽象思維,就是針對現實中客觀的事物,例如人,小貓等。定義人和小貓一些屬性,還有動作(也就是方法)。我們可以針對這些屬性以及方法進行相應的操作,還可以規定人這個物件跟貓這個物件的一些關係。這樣可以降低程式碼的耦合度,使程式更加的靈活。
程式碼中如何實現多型?
- 介面實現
- 繼承父類別重寫方法
- 同一個類中進行方法的過載
介面的意義
規範、擴充套件、回撥
多型的好處
多型可以允許不同類物件對同一個訊息作出不同的反應,也就是多個子類物件繼承父類別物件,但是可以重新定義父類別的方法,做到「一個介面,多種實現」。
好處總結有2點
- 提高了程式碼的維護性(繼承保證)
- 提高了程式碼的擴充套件性(多型保證)
抽象類的意義
爲其他子類提供一個公共的型別
封裝子類中重複定義的內容
定義抽象方法,子類雖然有不同的實現,但是定義時一致的
介面跟抽象類的區別
|
比較 |
抽象類 |
介面 |
|
預設方法 |
抽象類可以有預設的方法實現 |
java 8之前,介面中不存在方法的實現. |
|
實現方式 |
子類使用extends關鍵字來繼承抽象類.如果子類不是抽象類,子類需要提供抽象類中所宣告方法的實現 |
子類使用implements來實現介面,需要提供介面中所有宣告的實現 |
|
構造器 |
抽象類中可以有構造器, |
介面中不能 |
|
存取修飾符 |
抽象方法可以有public,protected和default等修飾 |
介面預設是public,不能使用其他修飾符 |
|
多繼承 |
一個子類只能存在一個父類別 |
一個子類可以存在多個介面 |
|
存取新方法 |
想抽象類中新增新方法,可以提供預設的實現,因此可以不修改子類現有的程式碼 |
如果往介面中新增新方法,則子類中需要實現該方法. |
父類別的靜態方法能否被子類重寫
不能。重寫只適用於實體方法,不能用於靜態方法,而子類當中含有和父類別相同名的靜態方法,我們一般稱之爲隱藏。
什麼是不可變物件
不可變物件指物件一旦被建立,狀態就不能再改變。任何修改都會建立一個新的物件,如 String、Integer及其它包裝類。不可變物件不會改變內部狀態,是執行緒安全地,我們可以在多執行緒中安全地共用使用。
靜態變數和範例變數的區別?
靜態變數儲存在方法區,屬於類所有。範例變數儲存在堆當中,其參照存在當前執行緒棧。
在語法定義上有區別:靜態變數前要加上static關鍵字,而範例變數前則不加。
在程式運算上有區別:範例變數屬於某個物件的屬性,必須建立了範例物件,其中的範例變數纔會被分配空間,才能 纔能使用這個範例變數。
靜態的變數不屬於某個範例變數,而是屬於類,所以也稱爲類變數,只要程式載入了類的位元組碼,不用建立任何的範例的物件,靜態變數就會被分配空間,靜態變數就可以被使用了。總之,範例變數必須建立物件後纔可以通過這個物件來使用,靜態變數則可以直接的使用類名來參照。
能否建立一個包含可變物件的不可變物件?
當然可以建立一個包含可變物件的不可變物件的,你只需要謹慎一點,不要共用可變物件的參照就可以了,如果需要變化時,就返回原物件的一個拷貝。最常見的例子就是物件中包含一個日期物件的參照。
物件導向和麪向過程的區別
程序導向
優點:效能比物件導向高,因爲類呼叫的時候需要範例化,開銷比較大,耗費資源。像微控制器、嵌入式、Linux等考慮效能的一般採用程序導向開發。
缺點:沒有物件導向易維護、易複用、易擴充套件
物件導向
優點:易維護、易複用、易擴充套件,由於物件導向有封裝、繼承、多型的特徵,可以設計出低耦合的系統,讓系統更加的靈活、更加的易於維護。
缺點:效能比物件導向低
值傳遞和參照傳遞
對於基本型別來說,傳遞都是值傳遞
基本型別有:boolean(1)、byte(8)、short(16)、char(16)、int(32)、float(32)、double(64)、long(64) //注,後面數位代表位數,1位元組 = 8位元
值傳遞:
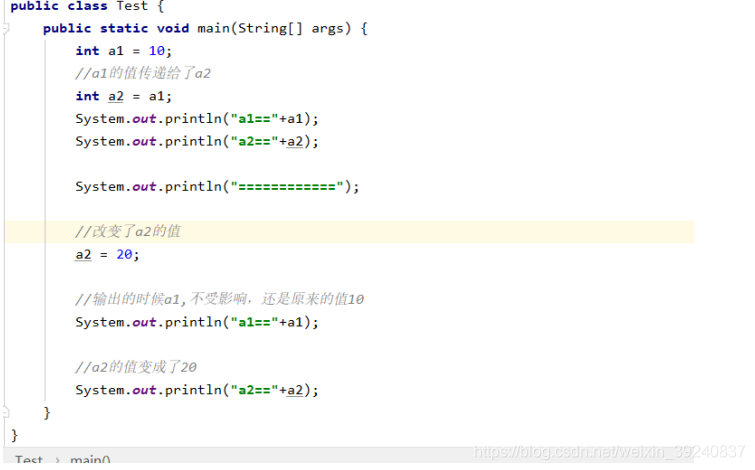
結果

由上面可以看出來,int型別的傳遞,當a2的值發生改變的時候,a1的值並不會受到影響,也就是說,基本型別的傳遞是根據值來傳遞的,傳遞之後,各個變數之間的值的改變不相互影響。
參照傳遞:
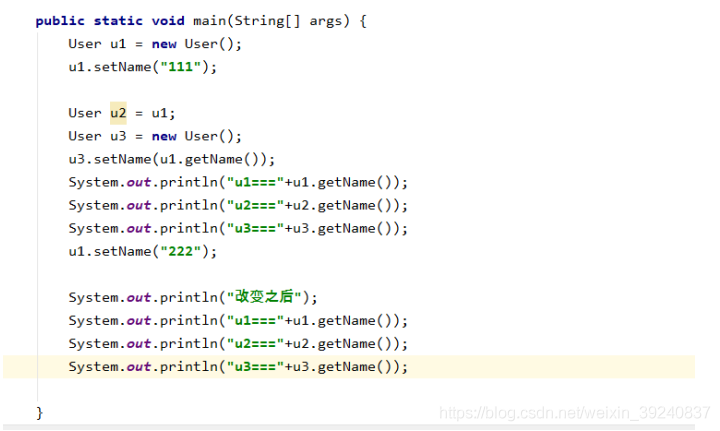
建立一個物件User,裏面有name屬性,進行測試
結果:

結論:從上面的結果可以看出來,將u1物件賦給u2,實際上u1和u2都是指向同一個地址,所以當u1,u2的值任何一個改變的時候,另外一個跟着改變,因爲是同一個地址。跟u3重新new一個物件不同,u3是開闢了另外的一個地址,所以當u1,u2改變的時候,u3是不會跟着改變的。一般認爲,Java 內的傳遞都是值傳遞,Java 中範例物件的傳遞是參照傳遞。
switch中能否使用string做參數
在jdk 1.7之前,switch只能支援byte, short, char, int或者其對應的封裝類以及Enum型別。從jdk 1.7之後switch開始支援String。
switch能否作用在byte, long上?
可以用在byte上,但是不能用在long上。
在switch(expr1)中,expr1只能是一個整數表達式或者列舉常數(更大字型),整數表達式可以是int基本型別或Integer包裝型別,由於,byte,short,char都可以隱含轉換爲int,所以,這些型別以及這些型別的包裝型別也是可以的。顯然,long和String型別都不符合sitch的語法規定,並且不能被隱式轉換成int型別,所以,它們不能作用於swtich語句中。
Java記憶體分配之堆、棧、常數池
Java記憶體分配主要包括以下幾個區域:
1. 暫存器:我們在程式中無法控制
2. 棧:存放基本型別的數據和物件的參照,但物件本身不存放在棧中,而是存放在堆中
3. 堆:存放用new產生的數據
4. 靜態域:存放在物件中用static定義的靜態成員
5. 常數池:存放常數
6. 非RAM(隨機存取記憶體)儲存:硬碟等永久儲存空間
Java記憶體分配中的棧
在函數中定義的一些基本型別的變數數據和物件的參照變數都在函數的棧記憶體中分配。當在一段程式碼塊定義一個變數時,Java就在棧中爲這個變數分配記憶體空間,當該變數退出該作用域後,Java會自動釋放掉爲該變數所分配的記憶體空間,該記憶體空間可以立即被另作他用。
Java記憶體分配中的堆
堆記憶體用來存放由new建立的物件和陣列。 在堆中分配的記憶體,由Java虛擬機器的自動垃圾回收器來管理。
在堆中產生了一個數組或物件後,還可以 在棧中定義一個特殊的變數,讓棧中這個變數的取值等於陣列或物件在堆記憶體中的首地址,棧中的這個變數就成了陣列或物件的參照變數。參照變數就相當於是爲陣列或物件起的一個名稱,以後就可以在程式中使用棧中的參照變數來存取堆中的陣列或物件。參照變數就相當於是爲陣列或者物件起的一個名稱。
參照變數是普通的變數,定義時在棧中分配,參照變數在程式執行到其作用域之外後被釋放。而陣列和物件本身在堆中分配,即使程式執行到使用 new 產生陣列或者物件的語句所在的程式碼塊之外,陣列和物件本身佔據的記憶體不會被釋放,陣列和物件在沒有參照變數指向它的時候,才變爲垃圾,不能在被使用,但仍 然佔據記憶體空間不放,在隨後的一個不確定的時間被垃圾回收器收走(釋放掉)。這也是 Java 比較佔記憶體的原因。
實際上,棧中的變數指向堆記憶體中的變數,這就是Java中的指針!
常數池 (constant pool)
常數池指的是在編譯期被確定,並被儲存在已編譯的.class檔案中的一些數據。除了包含程式碼中所定義的各種基本型別(如int、long等等)和物件型(如String及陣列)的常數值(final)還包含一些以文字形式出現的符號參照,比如:
類和介面的全限定名;
欄位的名稱和描述符;
虛擬機器必須爲每個被裝載的型別維護一個常數池。常數池就是該型別所用到常數的一個有序集和,包括直接常數(string,integer和 float ing point常數)和對其他型別,欄位和方法的符號參照。
對於String常數,它的值是在常數池中的。而JVM中的常數池在記憶體當中是以表的形式存在的, 對於String型別,有一張固定長度的CONSTANT_String_info表用來儲存文字字串值,注意:該表只儲存文字字串值,不儲存符號引 用。說到這裏,對常數池中的字串值的儲存位置應該有一個比較明瞭的理解了。
在程式執行的時候,常數池會儲存在Method Area,而不是堆中。
堆與棧
Java的堆是一個執行時數據區,類的(物件從中分配空間。這些物件通過new、newarray、 anewarray和multianewarray等指令建立,它們不需要程式程式碼來顯式的釋放。堆是由垃圾回收來負責的,堆的優勢是可以動態地分配記憶體大小,生存期也不必事先告訴編譯器,因爲它是在執行時動態分配記憶體的,Java的垃圾收集器會自動收走這些不再使用的數據。但缺點是,由於要在執行時動態 分配記憶體,存取速度較慢。
棧的優勢是,存取速度比堆要快,僅次於暫存器,棧數據可以共用。但缺點是,存在棧中的數據大小與生存期必須是確定的,缺乏靈活性。棧中主要存放一些基本型別的變數數據(int, short, long, byte, float, double, boolean, char)和物件控制代碼(參照)。
這裏我們主要關心棧,堆和常數池,對於棧和常數池中的物件可以共用,對於堆中的物件不可以共用。棧中的數據大小和生命週期是可以確定的,當沒有參照指向數據時,這個數據就會消失。堆中的物件的由垃圾回收器負責回收,因此大小和生命週期不需要確定,具有很大的靈活性。
字串記憶體分配
對於字串,其物件的參照都是儲存在棧中的,如果是編譯期已經建立好(直接用雙引號定義的)的就儲存在常數池中,如果是執行期(new出來的)才能 纔能確定的就儲存在堆中。對於equals相等的字串,在常數池中永遠只有一份,在堆中有多份。
如以下程式碼:
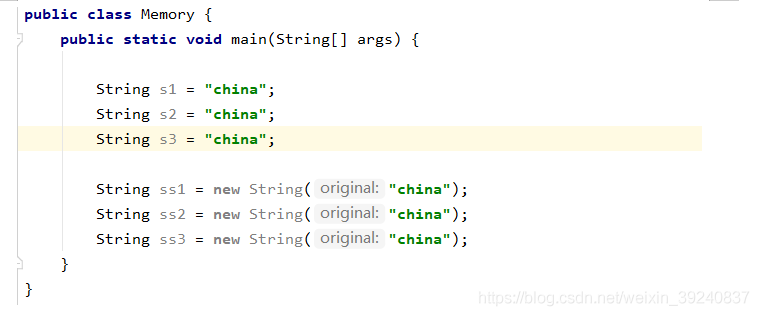
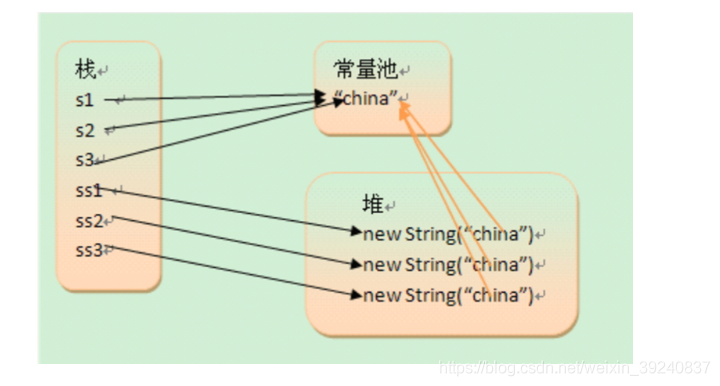
這裏解釋一下橙色這3個箭頭,對於通過new產生一個字串(假設爲「china」)時,會先去常數池中查詢是否已經有了「china」物件,如果沒有則在常數池中建立一個此字串物件,然後堆中再建立一個常數池中此」china」物件的拷貝物件。
這也就是有道面試題:String s = new String(「xyz」);產生幾個物件?一個或兩個,如果常數池中原來沒有」xyz」,就是兩個。
存在於.class檔案中的常數池,在執行期被JVM裝載,並且可以擴充。String的 intern()方法就是擴充常數池的 一個方法;當一個String範例str呼叫intern()方法時,Java 查詢常數池中是否有相同Unicode的字串常數,如果有,則返回其的參照,如果沒有,則在常數池中增加一個Unicode等於str的字串並返回它的參照
如下程式碼:

輸出結果:
false
false
true
True
String常數池問題的幾個例子:
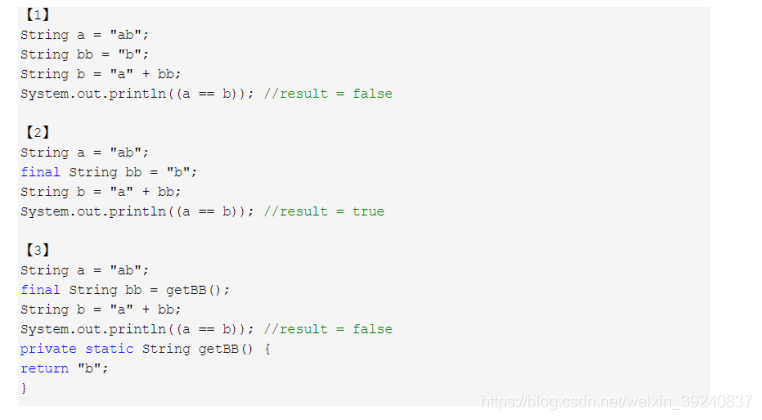
分析:
【1】中,JVM對於字串參照,由於在字串的"+"連線中,有字串參照存在,而參照的值在程式編譯期是無法確定的,即"a" + bb無法被編譯器優化,只有在程式執行期來動態分配並將連線後的新地址賦給b。所以上面程式的結果也就爲false。
【2】和【1】中唯一不同的是bb字串加了final修飾,對於final修飾的變數,它在編譯時被解析爲常數值的一個本地拷貝儲存到自己的常數池中或嵌入到它的位元組碼流中。所以此時的"a" + bb和"a" + "b"效果是一樣的。故上面程式的結果爲true。
【3】JVM對於字串參照bb,它的值在編譯期無法確定,只有在程式執行期呼叫方法後,將方法的返回值和"a"來動態連線並分配地址爲b,故上面程式的結果爲false。
結論:
字串是一個特殊包裝類,其參照是存放在棧裡的,而物件內容必須根據建立方式不同定(常數池和堆).有的是編譯期就已經建立好,存放在字串常 量池中,而有的是執行時才被建立.使用new關鍵字,存放在堆中。
基礎型別的變數和常數在記憶體中的分配
對於基礎型別的變數和常數,變數和參照儲存在棧中,常數儲存在常數池中。
如以下程式碼:
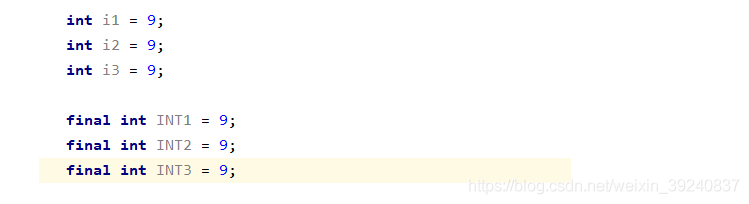
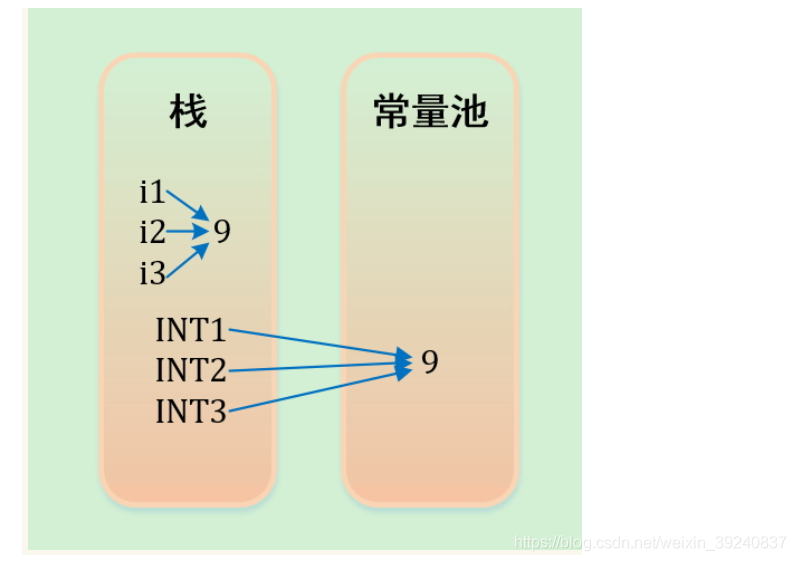
編譯器先處理int i1 = 9;首先它會在棧中建立一個變數爲i1的參照,然後查詢棧中是否有9這個值,如果沒找到,就將9存放進來,然後將i1指向9。接着處理int i2 = 9;在建立完i2的參照變數後,因爲在棧中已經有9這個值,便將i2直接指向9。這樣,就出現了i1與i2同時均指向9的情況。最後i3也指向這個9。
java當中的四種參照
強參照,軟參照,弱參照,虛參照。不同的參照型別主要體現在GC上:
強參照:如果一個物件具有強參照,它就不會被垃圾回收器回收。即使當前記憶體空間不足,JVM也不會回收它,而是拋出 OutOfMemoryError 錯誤,使程式異常終止。如果想中斷強參照和某個物件之間的關聯,可以顯式地將參照賦值爲null,這樣一來的話,JVM在合適的時間就會回收該物件。
軟參照:在使用軟參照時,如果記憶體的空間足夠,軟參照就能繼續被使用,而不會被垃圾回收器回收,只有在記憶體不足時,軟參照纔會被垃圾回收器回收。
弱參照:具有弱參照的物件擁有的生命週期更短暫。因爲當 JVM 進行垃圾回收,一旦發現弱參照物件,無論當前記憶體空間是否充足,都會將弱參照回收。不過由於垃圾回收器是一個優先順序較低的執行緒,所以並不一定能迅速發現弱參照物件。
虛參照:顧名思義,就是形同虛設,如果一個物件僅持有虛參照,那麼它相當於沒有參照,在任何時候都可能被垃圾回收器回收。
WeakReference與SoftReference的區別?
雖然 WeakReference 與 SoftReference 都有利於提高 GC 和 記憶體的效率,但是 WeakReference ,一旦失去最後一個強參照,就會被 GC 回收,而軟參照雖然不能阻止被回收,但是可以延遲到 JVM 記憶體不足的時候。
爲什麼要有不同的參照型別
在Java中有時候我們需要適當的控制物件被回收的時機,因此就誕生了不同的參照型別,可以說不同的參照型別實則是對GC回收時機不可控的妥協。有以下幾個使用場景可以充分的說明:
利用軟參照和弱參照解決OOM問題:用一個HashMap來儲存圖片的路徑和相應圖片物件關聯的軟參照之間的對映關係,在記憶體不足時,JVM會自動回收這些快取圖片物件所佔用的空間,從而有效地避免了OOM的問題.
equals()和hashcode()的聯繫
hashCode()是Object類的一個方法,返回一個雜湊值。如果兩個物件根據equal()方法比較相等,那麼呼叫這兩個物件中任意一個物件的hashCode()方法必須產生相同的雜湊值。
如果兩個物件根據eqaul()方法比較不相等,那麼產生的雜湊值不一定相等(碰撞的情況下還是會相等的。)
a.hashCode()有什麼用?
將物件放入到集閤中時,首先判斷要放入物件的hashcode是否已經在集閤中存在,不存在則直接放入集合。如果hashcode相等,然後通過equal()方法判斷要放入物件與集閤中的任意物件是否相等:如果equal()判斷不相等,直接將該元素放入集閤中,否則不放入。
有沒有可能兩個不相等的物件有相同的hashcode
有可能,兩個不相等的物件可能會有相同的 hashcode 值,這就是爲什麼在 hashmap 中會有衝突。如果兩個物件相等,必須有相同的hashcode 值,反之不成立。
可以在hashcode中使用亂數字嗎?
不行,因爲同一物件的 hashcode 值必須是相同的
a==b與a.equals(b)有什麼區別
如果a 和b 都是物件,則 a==b 是比較兩個物件的參照,只有當 a 和 b 指向的是堆中的同一個物件纔會返回 true,而 a.equals(b) 是進行邏輯比較,所以通常需要重寫該方法來提供邏輯一致性的比較。例如,String 類重寫 equals() 方法,所以可以用於兩個不同對象,但是包含的字母相同的比較。
基本型別比較用==,比較的是他們的值。預設下,物件用==比較時,比較的是記憶體地址,如果需要比較物件內容,需要重寫equal方法。
什麼是自動拆裝箱?
自動裝箱和拆箱,就是基本型別和參照型別之間的轉換。
把基本數據型別轉換成包裝類的過程就是打包裝,爲裝箱。
把包裝類轉換成基本數據型別的過程就是拆包裝,爲拆箱。
爲什麼要轉換?
如果你在 Java5 下進行過程式設計的話,你一定不會陌生這一點,你不能直接地向集合( Collection )中放入原始型別值,因爲集合只接收物件。
通常這種情況下你的做法是,將這些原始型別的值轉換成物件,然後將這些轉換的物件放入集閤中。使用 Integer、Double、Boolean 等這些類,我們可以將原始型別值轉換成對應的物件,但是從某些程度可能使得程式碼不是那麼簡潔精煉。
爲了讓程式碼簡練,Java5 引入了具有在原始型別和物件型別自動轉換的裝箱和拆箱機制 機製。
但是自動裝箱和拆箱並非完美,在使用時需要有一些注意事項,如果沒有搞明白自動裝箱和拆箱,可能會引起難以察覺的 Bug 。
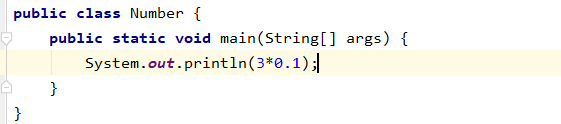
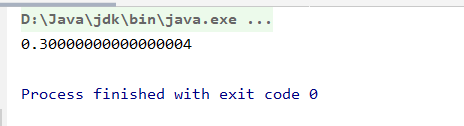
3*0.1==0.3返回值是什麼
false,因爲有些浮點數不能完全精確的表示出來。
a=a+b與a+=b有什麼區別嗎?
+=操作符會進行隱式自動型別轉換,此處a+=b隱式的將加操作的結果型別強制轉換爲持有結果的型別,而a=a+b則不會自動進行型別轉換。如:
byte a = 127;
byte b = 127;
b = a + b; // error : cannot convert from int to byte
b += a; // ok
(譯者注:這個地方應該表述的有誤,其實無論 a+b 的值爲多少,編譯器都會報錯,因爲 a+b 操作會將 a、b 提升爲 int 型別,所以將 int 型別賦值給 byte 就會編譯出錯)
short s1= 1; s1 = s1 + 1; 該段程式碼是否有錯,有的話怎麼改?
有錯誤,short型別在進行運算時會自動提升爲int型別,也就是說s1+1的運算結果是int型別。
陣列有沒有length()這個方法? String有沒有length()這個方法
答: 陣列沒有length()這個方法,有length的屬性。String有有length()這個方法
Overload和Override的區別。Overloaded的方法是否可以改變返回值的型別
答: 方法的重寫Overriding和過載Overloading是Java多型性的不同表現。重寫Overriding是父類別與子類之間多型性的一種表現,過載Overloading是一個類中多型性的一種表現。如果在子類中定義某方法與其父類別有相同的名稱和參數,我們說該方法被重寫 (Overriding)。如果在一個類中定義了多個同名的方法,它們或有不同的參數個數或有不同的參數型別,則稱爲方法的過載(Overloading)。Overloaded的方法是可以改變返回值的型別
int 和 Integer 有什麼區別
答: Java 提供兩種不同的型別:參照型別和原始型別(或內建型別)。Int是java的原始數據型別,Integer是java爲int提供的封裝類。Java爲每個原始型別提供了封裝類。參照型別和原始型別具有不同的特徵和用法,它們包括:大小和速度問題,這種型別以哪種型別的數據結構儲存,當參照型別和原始型別用作某個類的範例數據時所指定的預設值。物件參照範例變數的預設值爲 null,而原始型別範例變數的預設值與它們的型別有關
& 和 &&的區別
&運算子有兩種用法:(1)按位元與;(2)邏輯與。&&運算子是短路與運算。邏輯與跟短路與的差別是非常巨大的,雖然二者都要求運算子左右兩端的布爾值都是true整個表達式的值纔是true。&&之所以稱爲短路運算是因爲,如果&&左邊的表達式的值是false,右邊的表達式會被直接短路掉,不會進行運算。很多時候我們可能都需要用&&而不是&,例如在驗證使用者登錄時判定使用者名稱不是null而且不是空字串,應當寫爲:username != null &&!username.equals(「」),二者的順序不能交換,更不能用&運算子,因爲第一個條件如果不成立,根本不能進行字串的equals比較,否則會產生NullPointerException異常。注意:邏輯或運算子(|)和短路或運算子(||)的差別也是如此。
一個java檔案內部可以有類?(非內部類)
只能有一個public公共類,但是可以有多個default修飾的類。
如何正確的退出多層巢狀回圈?
使用標號和break;
通過在外層回圈中新增識別符號
內部類的作用
內部類可以有多個範例,每個範例都有自己的狀態資訊,並且與其他外圍物件的資訊相互獨立.在單個外圍類當中,可以讓多個內部類以不同的方式實現同一介面,或者繼承同一個類.建立內部類物件的時刻不依賴於外部類物件的建立。內部類並沒有令人疑惑的」is-a」管系,它就像是一個獨立的實體。
內部類提供了更好的封裝,除了該外圍類,其他類都不能存取。
clone()是哪個類的方法?
java.lang.Cloneable 是一個標示性介面,不包含任何方法,clone 方法在 object 類中定義。並且需要知道 clone() 方法是一個本地方法,這意味着它是由 c 或 c++ 或 其他本地語言實現的。
深拷貝和淺拷貝的區別是什麼?
淺拷貝:被複制物件的所有變數都含有與原來的物件相同的值,而所有的對其他物件的參照仍然指向原來的物件。換言之,淺拷貝僅僅複製所考慮的物件,而不復制它所參照的物件。
深拷貝:被複制物件的所有變數都含有與原來的物件相同的值,而那些參照其他物件的變數將指向被複制過的新物件,而不再是原有的那些被參照的物件。換言之,深拷貝把要複製的物件所參照的物件都複製了一遍。
static都有哪些用法?
被static所修飾的變數/方法都屬於類的靜態資源,類範例所共用。
static也用於靜態塊,多用於初始化操作:
此外static也多用於修飾內部類,此時稱之爲靜態內部類。
最後一種用法就是靜態導包,可以用來指定匯入某個類中的靜態資源,並且不需要使用類名。資源名,可以直接使用資源名,比如:
final有哪些用法
final也是很多面試喜歡問的地方,能回答下以下三點就不錯了:
1.被final修飾的類不可以被繼承
2.被final修飾的方法不可以被重寫
3.被final修飾的變數不可以被改變。如果修飾參照,那麼表示參照不可變,參照指向的內容可變。
4.被final修飾的方法,JVM會嘗試將其內聯,以提高執行效率
5.被final修飾的常數,在編譯階段會存入常數池中。
回答出編譯器對final域要遵守的兩個重排序規則更好:
1.在建構函式內對一個final域的寫入,與隨後把這個被構造物件的參照賦值給一個參照變數,這兩個操作之間不能重排序。
2.初次讀一個包含final域的物件的參照,與隨後初次讀這個final域,這兩個操作之間不能重排序。
String, StringBuffer和StringBuilder區別
String是字串常數,final修飾:StringBuffer字串變數(執行緒安全);
StringBuilder 字串變數(執行緒不安全)。
String和StringBuffer
String和StringBuffer主要區別是效能:String是不可變物件,每次對String型別進行操作都等同於產生了一個新的String物件,然後指向新的String物件。所以儘量不在對String進行大量的拼接操作,否則會產生很多臨時物件,導致GC開始工作,影響系統效能。
StringBuffer是對物件本身操作,而不是產生新的物件,因此在有大量拼接的情況下,我們建議使用StringBuffer。
但是需要注意現在JVM會對String拼接做一定的優化:
String s=「This is only 」+」simple」+」test」會被虛擬機器直接優化成String s=「This is only simple test」,此時就不存在拼接過程。
StringBuffer和StringBuilder
StringBuffer是執行緒安全的可變字串,其內部實現是可變陣列。StringBuilder是jdk 1.5新增的,其功能和StringBuffer類似,但是非執行緒安全。因此,在沒有多執行緒問題的前提下,使用StringBuilder會取得更好的效能。
什麼是編譯器常數?使用它有什麼風險?
公共靜態不可變(public static final )變數也就是我們所說的編譯期常數,這裏的 public 可選的。實際上這些變數在編譯時會被替換掉,因爲編譯器知道這些變數的值,並且知道這些變數在執行時不能改變。這種方式存在的一個問題是你使用了一個內部的或第三方庫中的公有編譯時常數,但是這個值後面被其他人改變了,但是你的用戶端仍然在使用老的值,甚至你已經部署了一個新的jar。爲了避免這種情況,當你在更新依賴 JAR 檔案時,確保重新編譯你的程式。
java當中使用什麼型別表示價格比較好?
如果不是特別關心記憶體和效能的話,使用BigDecimal,否則使用預定義精度的 double 型別。
如何將byte轉爲String
可以使用 String 接收 byte[] 參數的構造器來進行轉換,需要注意的點是要使用的正確的編碼,否則會使用平臺預設編碼,這個編碼可能跟原來的編碼相同,也可能不同。
可以將int強轉爲byte型別麼?會產生什麼問題?
我們可以做強制轉換,但是Java中int是32位元的而byte是8 位的,所以,如果強制轉化int型別的高24位元將會被丟棄,byte 型別的範圍是從-128到128
Java 中 ++ 操作符是執行緒安全的嗎?
不是執行緒安全的操作。它涉及到多個指令,如讀取變數值,增加,然後儲存回記憶體,這個過程可能會出現多個執行緒交差。
final、finalize 和 finally 的不同之處?
final 是一個修飾符,可以修飾變數、方法和類。如果 final 修飾變數,意味着該變數的值在初始化後不能被改變。Java 技術允許使用 finalize() 方法在垃圾收集器將物件從記憶體中清除出去之前做必要的清理工作。這個方法是由垃圾收集器在確定這個物件沒有被參照時對這個物件呼叫的,但是什麼時候呼叫 finalize 沒有保證。finally 是一個關鍵字,與 try 和 catch 一起用於異常的處理。finally 塊一定會被執行,無論在 try 塊中是否有發生異常。
是否可以在static環境中存取非static變數?
static變數在Java中是屬於類的,它在所有的範例中的值是一樣的。當類被Java虛擬機器載入的時候,會對static變數進行初始化。如果你的程式碼嘗試不用範例來存取非static的變數,編譯器會報錯,因爲這些變數還沒有被建立出來,還沒有跟任何範例關聯上。
Java中,什麼是構造方法?什麼是構造方法過載?什麼是複製構造方法?
當新物件被建立的時候,構造方法會被呼叫。每一個類都有構造方法。在程式設計師沒有給類提供構造方法的情況下,Java編譯器會爲這個類建立一個預設的構造方法。
Java中構造方法過載和方法過載很相似。可以爲一個類建立多個構造方法。每一個構造方法必須有它自己唯一的參數列表。
Java不支援像C++中那樣的複製構造方法,這個不同點是因爲如果你不自己寫構造方法的情況下,Java不會建立預設的複製構造方法。
Java支援多繼承麼?
Java中類不支援多繼承,只支援單繼承(即一個類只有一個父類別)。 但是java中的介面支援多繼承,,即一個子介面可以有多個父介面。(介面的作用是用來擴充套件物件的功能,一個子介面繼承多個父介面,說明子介面擴充套件了多個功能,當類實現介面時,類就擴充套件了相應的功能)。
Java反射機制 機製的作用:
1)在執行時判斷任意一個物件所屬的類。
2)在執行時判斷任意一個類所具有的成員變數和方法。
3)在執行時任意呼叫一個物件的方法
4)在執行時構造任意一個類的物件
什麼是反射機制 機製?
簡單說,反射機制 機製值得是程式在執行時能夠獲取自身的資訊。在java中,只要給定類的名字,那麼就可以通過反射機制 機製來獲得類的所有資訊。
哪裏用到反射機制 機製?
jdbc中有一行程式碼:Class.forName('com.MySQL.jdbc.Driver.class').newInstance();那個時候只知道生成驅動物件範例,後來才知道,這就是反射,現在
很多框架都用到反射機制 機製,hibernate,struts都是用反射機制 機製實現的。
反射機制 機製的優缺點?
靜態編譯:在編譯時確定型別,系結物件,即通過
動態編譯:執行時確定型別,系結物件。動態編譯最大限度的發揮了java的靈活性,體現了多型的應用,有利於降低類之間的耦合性。
一句話,反射機制 機製的優點就是可以實現動態建立物件和編譯,體現出很大的靈活性,特別是在J2EE的開發中
它的靈活性就表現的十分明顯。比如,一個大型的軟體,不可能一次就把把它設計的很完美,當這個程式編
譯後,發佈了,當發現需要更新某些功能時,我們不可能要使用者把以前的解除安裝,再重新安裝新的版本,假如
這樣的話,這個軟體肯定是沒有多少人用的。採用靜態的話,需要把整個程式重新編譯一次纔可以實現功能
的更新,而採用反射機制 機製的話,它就可以不用解除安裝,只需要在執行時才動態的建立和編譯,就可以實現該功
能。
它的缺點是對效能有影響。使用反射基本上是一種解釋操作,我們可以告訴JVM,我們希望做什麼並且它
滿足我們的要求。這類操作總是慢於只直接執行相同的操作。
什麼是動態代理
代理類在程式執行時建立的代理方式被成爲 動態代理。 也就是說,這種情況下,代理類並不是在Java程式碼中定義的,而是在執行時根據我們在Java程式碼中的「指示」動態生成的。相比於靜態代理, 動態代理的優勢在於可以很方便的對代理類的函數進行統一的處理,而不用修改每個代理類的函數。
error和exception有什麼區別
error表示系統級的錯誤,是java執行環境內部錯誤或者硬體問題,不能指望程式來處理這樣的問題,除了退出運行外別無選擇,它是Java虛擬機器拋出的。
exception 表示程式需要捕捉、需要處理的異常,是由與程式設計的不完善而出現的問題,程式必須處理的問題
執行時異常和一般異常有何不同
Java提供了兩類主要的異常:runtimeException和checkedException
一般異常(checkedException)主要是指IO異常、SQL異常等。對於這種異常,JVM要求我們必須對其進行cathc處理,所以,面對這種異常,不管我們是否願意,都是要寫一大堆的catch塊去處理可能出現的異常。
執行時異常(runtimeException)我們一般不處理,當出現這類異常的時候程式會由虛擬機器接管。比如,我們從來沒有去處理過NullPointerException,而且這個異常還是最常見的異常之一。
出現執行時異常的時候,程式會將異常一直向上拋,一直拋到遇到處理程式碼,如果沒有catch塊進行處理,到了最上層,如果是多執行緒就有Thread.run()拋出,如果不是多執行緒那麼就由main.run()拋出。拋出之後,如果是執行緒,那麼該執行緒也就終止了,如果是主程式,那麼該程式也就終止了。
其實執行時異常的也是繼承自Exception,也可以用catch塊對其處理,只是我們一般不處理罷了,也就是說,如果不對執行時異常進行catch處理,那麼結果不是執行緒退出就是主程式終止。
如果不想終止,那麼我們就必須捕獲所有可能出現的執行時異常。如果程式中出現了異常數據,但是它不影響下面 下麪的程式執行,那麼我們就該在catch塊裏面將異常數據捨棄,然後記錄日誌。如果,它影響到了下面 下麪的程式執行,那麼還是程式退出比較好些。
Java中例外處理機制 機製的原理
Java通過物件導向的方式對異常進行處理,Java把異常按照不同的型別進行分類,並提供了良好的介面。當一個方法出現異常後就會拋出一個異常物件,該物件中包含有異常資訊,呼叫這個物件的方法可以捕獲到這個異常並對異常進行處理。Java的例外處理是通過5個關鍵詞來實現的:try catch throw throws finally。
一般情況下是用try來執行一段程式,如果出現異常,系統會拋出(throws),我們可以通過它的型別來捕捉它,或最後由預設處理器來處理它(finally)。
try:用來指定一塊預防所有異常的程式
catch:緊跟在try後面,用來捕獲異常
throw:用來明確的拋出一個異常
throws:用來標明一個成員函數可能拋出的各種異常
finally:確保一段程式碼無論發生什麼異常都會被執行的一段程式碼。
你平時在專案中是怎樣對異常進行處理的。
(1)儘量避免出現runtimeException 。例如對於可能出現空指針的程式碼,帶使用物件之前一定要判斷一下該物件是否爲空,必要的時候對runtimeException
也進行try catch處理。
(2)進行try catch處理的時候要在catch程式碼塊中對異常資訊進行記錄,通過呼叫異常類的相關方法獲取到異常的相關資訊,返回到web端,不僅要給使用者良好
的使用者體驗,也要能幫助程式設計師良好的定位異常出現的位置及原因。例如,以前做的一個專案,程式遇到異常頁面會顯示一個圖片告訴使用者哪些操作導致程式出現
了什麼異常,同時圖片上有一個按鈕用來點選展示異常的詳細資訊給程式設計師看的。
final、finally、finalize的區別
(1)、final用於宣告變數、方法和類的,分別表示變數值不可變,方法不可覆蓋,類不可以繼承
(2)、finally是例外處理中的一個關鍵字,表示finally{}裏面的程式碼一定要執行
(3)、finalize是Object類的一個方法,在垃圾回收的時候會呼叫被回收物件的此方法。
try()裏面有一個return語句,那麼後面的finally{}裏面的code會不會被執行,什麼時候執行,是在return前還是return後?
你曾經自定義實現過異常嗎?怎麼寫的?
1、自定義異常的步驟
(1)繼承 Exception 或 RuntimeException
(2)定義構造方法
(3)使用異常
2、自定義異常類
/**IllegalAgeException:非法年齡異常,繼承Exception類*/
class IllegalAgeException extends Exception {
//預設構造器
public IllegalAgeException() {
}
//帶有詳細資訊的構造器,資訊儲存在message中
public IllegalAgeException(String message) {
super(message);
}
}
3、自定義異常類的使用
class Person {
private String name;
private int age;
public void setName(String name) {
this.name = name;
}
public void setAge(int age) throws IllegalAgeException {
if (age < 0) {
throw new IllegalAgeException("人的年齡不應該爲負數");
}
this.age = age;
}
public String toString() {
return "name is " + name + " and age is " + age;
}
}
public class TestMyException {
public static void main(String[] args) {
Person p = new Person();
try {
p.setName("Lincoln");
p.setAge(-1);
} catch (IllegalAgeException e) {
e.printStackTrace();
System.exit(-1);
}
System.out.println(p);
}
}
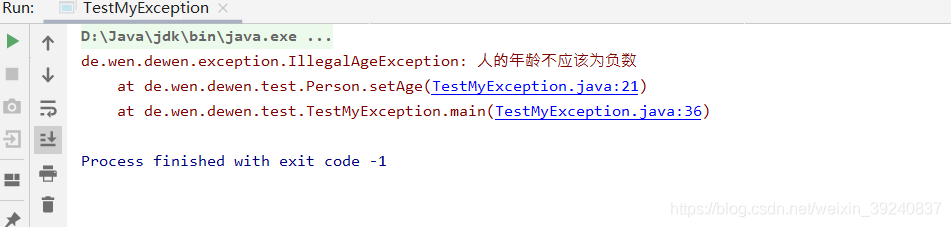
執行結果:
throw和throws有什麼區別?
拋出異常有三種形式,一是throw,一個throws,還有一種系統自動拋異常。
下面 下麪它們之間的異同
一、系統自動拋異常
當程式語句出現一些邏輯錯誤、主義錯誤或型別轉換錯誤時,系統會自動拋出異常
二、throw
1、throw是語句拋出一個異常,一般是在程式碼塊的內部,當程式 現某種邏輯錯誤時由程式設計師主動拋出某種特定型別的異常
2、定義在方法體內
3、建立的是一個異常物件
4、確定了發生哪種異常纔可以使用
三、throws
1、在方法參數列表後,throws後可以跟着多個異常名,表示拋出的異常用逗號隔開
2、表示向呼叫該類的位置拋出異常,不在該類解決
3、可能發生哪種異常
throws用在方法宣告後面,跟的是異常類名,throw用在方法體內,跟的是異常物件名。
throws可以跟多個異常類名,用逗號隔開,throw只能拋出一個異常物件名。
throws表示拋出異常,由該方法的呼叫者來處理,throw表示拋出異常,由方法體內的語句處理。
throws表示出現異常的一種可能性,並不一定會發生這些異常,throw則是拋出了異常,執行throw則一定拋出了某種異常。
四、異常
異常概述:
異常:異常是指在程式的執行過程中所發生的不正常的事件,它會中斷正在執行的程式。簡單來說就是程式出現了不正常的情況。異常本質就是Java當中對可能出現的問題進行描述的一種物件體現。
例外處理的時候,finally程式碼塊的重要性是什麼?
無論是否拋出異常,finally程式碼塊總是會被執行。就算是沒有catch語句同時又拋出異常的情況下,finally程式碼塊仍然會被執行。最後要說的是,finally程式碼塊主要用來釋放資源,比如:I/O緩衝區,數據庫連線。
異常的使用的注意地方?
不要將例外處理用於正常的控制流(設計良好的 API 不應該強迫它的呼叫者爲了正常的控制流而使用異常)。
對可以恢復的情況使用受檢異常,對程式設計錯誤使用執行時異常。
避免不必要的使用受檢異常(可以通過一些狀態檢測手段來避免異常的發生)。
優先使用標準的異常。
每個方法拋出的異常都要有文件。
保持異常的原子性
不要在 catch 中忽略掉捕獲到的異常。
請列出 5 個執行時異常?
NullPointerException
IndexOutOfBoundsException
ClassCastException
ArrayStoreException 當你試圖將錯誤型別的物件儲存到一個物件陣列時拋出的異常
BufferOverflowException 寫入的長度超出了允許的長度
反射的概述
JAVA反射機制 機製是在執行狀態中,對於任意一個類,都能夠知道這個類的所有屬性和方法;對於任意一個物件,都能夠呼叫它的任意一個方法和屬性;這種動態獲取的資訊以及動態呼叫物件的方法的功能稱爲java語言的反射機制 機製。
反射就java中class.forName()和classLoader都可用來對類進行載入。
class.forName()前者除了將類的.class檔案載入到jvm中之外,還會對類進行解釋,執行類中的static塊。
而classLoader只幹一件事情,就是將.class檔案載入到jvm中,不會執行static中的內容,只有在newInstance纔會去執行static塊。是把java類中的各種成分對映成一個個的Java物件
反射的功能:
在執行時構造一個類的物件。
判斷一個類所具有的成員變數和方法。
呼叫一個物件的方法。
生成動態代理。
反射的應用很多,很多框架都有用到:
反射的用途:
Spring 框架的 IoC 基於反射建立物件和設定依賴屬性。
Spring MVC 的請求呼叫對應方法,也是通過反射。
JDBC 的 Class#forName(String className) 方法,也是使用反射。
反射中,Class.forName 和 ClassLoader 區別
java中class.forName()和classLoader都可用來對類進行載入。
class.forName()前者除了將類的.class檔案載入到jvm中之外,還會對類進行解釋,執行類中的static塊。
而classLoader只幹一件事情,就是將.class檔案載入到jvm中,不會執行static中的內容,只有在newInstance纔會去執行static塊。
Java動態代理的兩種實現方法
jdk動態代理是由java內部的反射機制 機製來實現的,cglib動態代理底層則是藉助asm來實現的。
總的來說,反射機制 機製在生成類的過程中比較高效,而asm在生成類之後的相關執行過程中比較高效(可以通過將asm生成的類進行快取,這樣解決asm生成類過程低效問題)。還有一點必須注意:jdk動態代理的應用前提,必須是目標類基於統一的介面。如果沒有上述前提,jdk動態代理不能應用。由此可以看出,jdk動態代理有一定的侷限性,cglib這種第三方類庫實現的動態代理應用更加廣泛,且在效率上更有優勢。。
jdk動態代理是jdk原生就支援的一種代理方式,它的實現原理,就是通過讓target類和代理類實現同一介面,代理類持有target物件,來達到方法攔截的作用,這樣通過介面的方式有兩個弊端,一個是必須保證target類有介面,第二個是如果想要對target類的方法進行代理攔截,那麼就要保證這些方法都要在介面中宣告,實現上略微有點限制。
Cglib是一個優秀的動態代理框架,它的底層使用ASM在記憶體中動態的生成被代理類的子類,使用CGLIB即使代理類沒有實現任何介面也可以實現動態代理功能。CGLIB具有簡單易用,它的執行速度要遠遠快於JDK的Proxy動態代理:
爲什麼要用動態代理
他可以在不修改別代理物件程式碼的基礎上,通過擴充套件代理類,進行一些功能的附加與增強
靜態代理與動態代理的區別
動態代理使我們免於去重寫介面中的方法,而着重於去擴充套件相應的功能或是方法的增強,與靜態代理相比簡單了不少,減少了專案中的業務量
動態代理機制 機製
Proxy這個類的作用就是用來動態建立一個代理物件的類。每一個動態代理類都必須要實現InvocationHandler這個介面,並且每個代理類的範例都關聯到了一個handler,當我們通過代理物件呼叫一個方法的時候,這個方法的呼叫就會被轉發爲由InvocationHandler這個介面的 invoke 方法來進行呼叫。
什麼是 Java 序列化?
序列化就是一種用來處理物件流的機制 機製,所謂物件流也就是將物件的內容進行流化。
可以對流化後的物件進行讀寫操作,也可將流化後的物件傳輸於網路之間。
序列化是爲了解決在對物件流進行讀寫操作時所引發的問題。
反序列化的過程,則是和序列化相反的過程。
另外,我們不能將序列化侷限在 Java 物件轉換成二進制陣列,例如說,我們將一個 Java 物件,轉換成 JSON 字串,或者 XML 字串,這也可以理解爲是序列化。
如何實現 Java 序列化?
如下的方式,就是 Java 內建的序列化方案,實際場景下,我們可以自定義序列化的方案,例如說 Google Protobuf 。
將需要被序列化的類,實現 Serializable 介面,該介面沒有需要實現的方法,implements Serializable 只是爲了標註該物件是可被序列化的。
序列化
然後,使用一個輸出流(如:FileOutputStream)來構造一個 ObjectOutputStream(物件流)物件
接着,使用 ObjectOutputStream 物件的 #writeObject(Object obj) 方法,就可以將參數爲 obj 的物件寫出(即儲存其狀態)。
反序列化
要恢復的話則用輸入流。
Java 序列話中,如果有些欄位不想進行序列化怎麼辦?
對於不想進行序列化的變數,使用 transient 關鍵字修飾。
當物件被序列化時,阻止範例中那些用此關鍵字修飾的的變數序列化。
當物件被反序列化時,被 transient 修飾的變數值不會被持久化和恢復。
transient 只能修飾變數,不能修飾類和方法。
Comparable 和 Comparator 的區別?
Comparable 介面,在 java.lang 包下,用於當前物件和其它物件的比較,所以它有一個 #compareTo(Object obj) 方法用來排序,該方法只有一個參數。
Comparator 介面,在 java.util 包下,用於傳入的兩個物件的比較,所以它有一個 #compare(Object obj1, Object obj2) 方法用來排序,該方法有兩個參數