【Python】第五章 類
該文章內容整理自《Python程式設計:從入門到實踐》、《流暢的Python》、以及網上各大部落格
文章目錄
類
Python是物件導向程式設計的語言,封裝、繼承、和多型是其三大特徵。對於封裝性,如將多種不同數據放到列表中就是一種數據層面的封裝;把常用的程式碼塊打包成一個函數也是一種語句層面的封裝。而類則是一種更好的封裝
類提供了一種組合數據和功能的方法。 建立一個新類意味着建立一個新的物件 型別,從而允許建立一個該型別的新範例 。和其他程式語言相比,Python 用非常少的新語法和語意將類加入到語言中。它是 C++ 和 Modula-3 中類機制 機製的結合。Python 的類提供了物件導向程式設計的所有標準特性:類繼承機制 機製允許多個基礎類別,派生類可以覆蓋它基礎類別的任何方法,一個方法可以呼叫基礎類別中相同名稱的的方法
一個類由三大組成部分,分別是
- 類名class_name
- 繼承關係class_bases
- 類的名稱空間class_dict
類的定義和範例化一般形式如下。其中__init__()爲類別建構函式。self爲類範例物件本身。另外,self只是約定俗成的名稱,並不是Python中的關鍵詞,因而可以將其宣告爲其他名稱。
class ClassName:
def __init__(self, a):
self.a = a
#def __init__(test, a):
# test.a = a
obj = ClassName()
類成員
範例屬性、類屬性和區域性變數
類是獨立的名稱空間。在類定義中,根據變數定義位置及方式的不同,類中變數分爲以下 3 種類型:
- 範例屬性:在類體中,所以函數內部,以「self.變數名」的方式定義的變數。範例屬性只能通過範例化物件名存取,無法通過類名存取。當通過範例化物件名爲類動態新增一個新屬性時,注意只是在這個範例化物件中擁有新屬性,在這個類的其他範例化物件中並不存在該新屬性
class Test :
def __init__(self, a):
self.a = a
t = Test(1)
t.b = 0 # 動態新增屬性
- 類屬性:在類體中、所有函數之外定義的變數。這些屬性屬於類,即所有類的範例化物件都共用類屬性。類屬性的呼叫、新增、和修改可通過類名進行存取。也可以通過範例化物件進行呼叫,但是當通過範例化物件進行新增或修改時,本質將不再是修改類變數的值,而是在給該物件定義新的範例屬性。同時,在類中,類屬性和範例屬性可以同名,但這種情況下使用類物件將無法呼叫類屬性,而會首選範例屬性,因此不推薦通過範例化物件名呼叫類屬性。注意類物件存在於類的__dict__屬性中,而不存在與範例化物件的__dict__屬性中
class Test :
a = "A"
def info(self):
pass
- 區域性變數:在類體中,所有函數內部,以「變數名=變數值」的方式定義的變數。當函數執行結束時區域性變數也會被銷燬
實體方法、類方法和靜態方法
在Python中,在類內定義的實體方法和類方法稱爲方法(method);而在類內定義的靜態方法和類外定義的函數稱爲函數(function)。即與類和範例有系結關係的function都屬於方法;與類和範例無系結關係的function都屬於函數
和類屬性的分類不同,類方法是通過函數修飾器進行分類的
- 實體方法:類中定義的不用任何修改的方法爲實體方法。實體方法必須包含 self 參數,用於系結呼叫此方法的範例物件。此時用type()檢視函數型別爲method,即系結方法,該方法系結範例物件,因而需要傳入 self
class Test:
def func(self):
pass
t = Test()
t.func() # 通過範例化物件呼叫實體方法
Test.func(t) # 通過類名呼叫實體方法,此時需要手動給self傳入範例化物件
print(type(t.func)) # <class 'method'>
# 通過類名動態新增實體方法,影響類的全部範例
def info1(self):
pass
Test.info1 = info1
# 通過範例化物件名動態新增實體方法,隻影響範例化物件
def info2(): # 若這裏新增self參數,在呼叫時需要手動傳入參數
pass
t.info2 = info2
- 類方法:類中定義的採用 @classmethod 修飾的方法爲類方法。類方法必須包含 cls 參數,用於系結呼叫此方法的類。和 self 一樣,cls 參數的命名也不是規定的,只是約定俗稱的習慣。類方法推薦使用類名直接呼叫,當然也可以使用範例物件來呼叫,但並不推薦使用這種方法。此時用type()檢視函數型別爲method,即系結方法,該方法系結類物件,因而需要傳入 cls
class Test:
@classmethod
def func(cls):
print("正在呼叫類方法", cls)
# 動態新增類方法
@classmethod
def info(cls):
pass
Test.info = info
- 靜態方法:類中定義的採用 @staticmethod 修飾的方法爲靜態方法。靜態方法定義在類名稱空間中,而函數則定義在全域性名稱空間中。靜態方法沒有類似 self、cls 這樣的特殊參數,因此 Python 直譯器不會對它包含的參數做任何類或物件的系結。也正因爲如此,類的靜態方法中無法呼叫任何類屬性和類方法。可通過類名或範例化物件來呼叫靜態方法。實際上,對靜態方法而言,類只相當於一個名稱空間,完全可以在類外面寫一個同樣的函數,但是這樣做就打亂了邏輯關係,也會導致以後程式碼維護困難。此時用type()檢視函數型別爲function,即非系結方法,該方法不系結物件,因而不用傳入 self 或 cls
class Test:
@staticmethod
def func(a, b):
print(a, b)
# 動態新增靜態方法
@staticmethod
def info():
pass
Test.info = info
公有成員、保護成員和私有成員
Python不同於C++會在公有和私有成員之間進行很強的區分,實際上,Python中並不提供嚴格意義上的公有成員和私有成員。爲了實現類的封裝性,Python採用下劃線命名來進行區分
- 不以下劃線開頭:表示公有成員
- 以單下劃線開頭:表示爲私有成員。類中的以單下劃線開頭的屬性和函數僅是一個提醒,表明該成員僅供內部使用,實際上外部仍能參照。但在模組中定義了以單下劃線開頭的變數和函數,並使用import引入該模組時,外部並不能參照這個變數和函數
- 以單下劃線結尾:爲了區別該名稱與關鍵詞
- 以雙下劃線開頭:表示爲私有成員,外部不能直接通過成員名參照。Python直譯器會重寫該成員名稱,將其改爲_class__member,因而外部想要存取以雙下劃線開頭的「私有成員」時,參照的名稱應該爲 _class__member
- 以雙下劃線開頭,雙下劃線結尾:表示Python內部的名字,此時直譯器並不會重寫該成員名稱。Python不建議將自己命名的方法寫爲這種形式
- 單下劃線變數:表示臨時變數。在Python互動式視窗中則可以表示爲最近一個表達式的結果。如
for _ in range(10): print("Hello")
car = ('red', 'auto', 12, 3812.4)
color, _, _, mileage = car
雙下劃線成員
Python 提供了dir() 函數,當函數不帶參數時,返回當前範圍內的變數、方法和定義的型別列表;帶參數時,返回參數的屬性、方法列表。如果參數包含方法__dir__(),該方法將被呼叫。如果參數不包含__dir__(),該方法將最大限度地收集參數資訊。如
print(dir()) # 獲得當前模組的屬性列表
# ['__builtins__', '__doc__', ...]
print(dir([ ])) # 檢視列表的方法
# ['__add__', '__class__', ...]
class a(object):
pass
print(dir(a())) # 檢視一個最簡單的類的所有屬性和方法
# ['__class__', '__delattr__', '__dict__', '__doc__', '__format__', '__getattribute__', '__hash__', '__init__', '__module__', '__new__', '__reduce__', '__reduce_ex__', '__repr__', '__setattr__', '__sizeof__', '__str__', '__subclasshook__', '__weakref__']
常見雙下劃線屬性
- __class__:表示類的型別,type(obj.__class__)返回就是type型別。obj.__class__返回的是範例化物件的類的名稱
- __module__:返回範例化物件所屬模組
- __dict__:用來儲存類所有可寫屬性的字典
- __doc__:返回類的註釋資訊。該屬性無法被繼承。可通過類名呼叫
- __slots__:用來限製爲範例物件動態新增屬性和方法,但無法限制動態地爲類新增屬性和方法。__slots__屬性值其實是一個元組,只有其中指定的元素纔可以作爲動態新增的屬性或者方法的名稱,如將類屬性__slots__ = (‘name’, ‘add’, ‘info’),此時該類的範例物件僅限於動態新增 name、add、info 這 3 個屬性以及 name()、add() 和 info() 這 3 個方法。注意,對於動態新增的方法,__slots__限制的是其方法名,並不限制參數的個數。此外,__slots__屬性只對當前所在的類起限製作用,對派生的子類不起作用。如果爲子類也設定有 __slots__屬性,那麼子類範例物件允許動態新增的屬性和方法,是子類中__slots__屬性和父類別 __slots__屬性的和
常見雙下劃線方法
- __new__():建立一個物件,範例化時會呼叫__new__()方法。__new__()方法至少要有一個參數cls,其代表要範例化的類,此參數在範例化時由直譯器自動提供。方法返回的是範例化物件,然後再由這個範例化物件呼叫__init__()方法來初始化,並且該範例化物件就是__init__()方法中的self。也就是說,__new__()創造出了物件,但是這個物件是空的,名稱空間的裝備需要通過__init__()來完成
class NewTest():
def __new__(cls, *args, **kwargs):
print("__new__")
return object.__new__(cls)
def __init__(self, a, b):
print("__init__")
self.a = a
self.b = b
# 單例模式是__new__()的一個應用,即一個類始終是有一個範例
class Foo:
__instance = False
def __new__(cls, *args, **kwargs):
if cls.__instance: return cls.__instance
cls.__instance = object.__new__(cls)
return cls.__instance
- __init__():爲建構函式,在初始化範例時呼叫
- __call__():當物件加 () 時會呼叫__call__()方法。能實現類似C++中的仿函數的功能。如下面 下麪程式。另外,可用callable(object) 函數來檢查一個物件object是否是可呼叫的。如果返回 True,object 仍然可能呼叫失敗;但如果返回 False,呼叫物件 object 絕對不會成功。 對於函數、方法、lambda 函式、 類以及實現了 __call__()方法的類範例, 它都返回 True。另外,注意__call__()是實體方法,只能通過範例化物件名加()呼叫,而不能通過類名加()呼叫
class CallTest():
def __init__(self):
print("__init__")
def __call__(self):
print("__call__")
obj = CallTest() # 觸發建構函式
obj() # 觸發__call__
- __getitem__():在中括號取值時觸發。如 obj[「a」] 時
- __setitem__():在中括號賦值時觸發。如 obj[「a」] = 1 時,但不會觸發__getitem__()。注意此時是給範例化物件新增一個範例屬性,其他範例不受影響
- __delitem__():在中括號刪除時觸發。如 del obj[「a」] 時,但不會觸發__getitem__()
class itemTest:
def __getitem__(self, item):
print('getitem執行', self.__dict__[item])
def __setitem__(self, key, value):
print('setitem執行')
self.__dict__[key] = value
def __delitem__(self, key):
print('delitem執行')
self.__dict__.pop(key)
i = itemTest()
print(i["a"] + 1)
i["a"] = 1
del i["a"]
- __getattr__():呼叫物件的一個不存在範例屬性時會觸發__getattr__()方法。此時函數返回值爲呼叫該不存在範例屬性的值,且無論在何處呼叫不存在範例屬性時都會呼叫該函數。下面 下麪三個函數同理。但實際上並不推薦人工修改這些方法
- __getattribute__():與__getattr__()方法相似,只是不管範例屬性是否存在都會執行。並且,當__getattr__()與__getattribute__()同時存在時只會執行__getattrbute__(),除非__getattribute__()在執行過程中拋出異常
- __setattr__():增加或修改物件範例屬性時會觸發__setattr__()方法。另外,Python中並不提供和C語言一樣的const常數,而一般約定全大寫變數爲const常數。若要在Python中使用const常數禁止使用者修改,可以新建一個類並修改其中的__setattr__()方法,若修改的屬性已存在,即不爲新增屬性,則拋出異常,提示錯誤
- __delattr__():刪除物件的一個範例屬性時會觸發__delattr__()方法
class AttrTest:
def __getattr__(self, item):
print("__getattr__", str(item))
# item爲該不存在屬性的名稱
return "Cannot find"
def __getattribute__(self, item):
print("__getattribute__", str(item))
# item爲該屬性的名稱
def __setattr__(self, key, value):
print("__setattr__", str(value))
# key爲變數,value爲設定值。但self.key=value,會造成死回圈
self.__dict__[key] = value
# 必須進行屬性字典的操作才能 纔能完成賦值
def __delattr__(self, item):
print("__delattr__", str(item))
# item爲該屬性的名稱
self.__dict__.pop(item)
# 必須進行屬性字典的操作才能 纔能完成刪除
obj = AttrTest()
print(obj.a) # 呼叫屬性不存在時觸發__getattr__,並且返回None
obj.a = 1 # 修改屬性時觸發__setattr__
del obj.a # 刪除屬性時觸發__delattr__
- __get__()、__set__() 和 __delete__():將在下一節描述符中介紹
- __eq__():判斷兩個物件是否相等
- __hash__():返回物件的雜湊值
class TestEH:
def __init__(self, a, b):
self.a = a
self.b = b
def __hash__(self):
print("__hash__")
return hash(self.a + self.b)
def __eq__(self, other):
print("__eq__")
return self.a == other.a and self.b == other.b
a = TestEH(1, 2)
b = TestEH(3, 4)
print(a == b) # 進行等價判斷時會呼叫__eq__()方法
s = set()
s.add(a) # 需要進行獲得物件的雜湊值時會呼叫__hash__()方法
s.add(b)
- __len__():當物件呼叫len()函數時會呼叫__len__()方法,但並不是所有物件都會事先定義好。如
class TestLen:
def __init__(self, a):
self.a = a
def __len__(self):
print("__len__")
return len(self.__dict__)
a = TestLen(1)
print(len(a)) # 呼叫__len__()方法
- __iter__()和__next__():用來構造迭代器。如模擬range()
class Range:
def __init__(self, n, stop, step):
self.n = n
self.stop = stop
self.step = step
def __next__(self):
if self.n >= self.stop:
raise StopIteration #拋出停止迭代異常
x = self.n
self.n += self.step
return x
def __iter__(self):
return self
for i in Range(1, 7, 3):
print(i)
# 或生成斐波那契數列
class Fib:
def __init__(self):
self._a = 0
self._b = 1
def __iter__(self):
return self
def __next__(self):
self._a, self._b = self._b, self._a + self._b
return self._a
for i in Fib():
if i > 100:
break
print('%s ' % i, end='')
- __format__():用來自定義格式化字串
format_dic = {
'y-m-d':'{obj.year}-{obj.mon}-{obj.day}',
'd/m/y':'{obj.day}/{obj.mon}/{obj.year}'
}
class Date:
def __init__(self,year,mon,day):
self.year = year
self.mon = mon
self.day = day
def __format__(self, format_spec):
if not format_spec or format_spec not in format_dic:
format_spec = 'y-m-d'
fm = format_dic[format_spec]
return fm.format(obj = self)
d = Date(2000, 1, 1)
print(format(d, 'y-m-d'))
- __str__():當物件呼叫str()方法時會呼叫__str__()方法。其他如__int__()、__float__()同理,在呼叫int()或float()時呼叫。另外,在直接列印範例化物件時也會呼叫__str__()方法。同時還有__repr__()方法,在呼叫repr()方法或在互動式直譯器(控制視窗)時呼叫。__str__()和__repr__()必須都返回字串。str()主要面向客戶,其目的是可讀性,返回形式爲使用者友好性和可讀性都比較高的字串形式;而repr()是面向Python直譯器或者說Python開發人員,其目的是準確性,其返回值表示Python直譯器內部的定義
class TestStr:
def __init__(self, a):
self.a = a
def __str__(self):
return str(self.a)
def __int__(self):
return self.a
def __float__(self):
return self.a
a = TestEH(1)
print(str(a)) # 此時會呼叫__str__()方法
print(int(a)) # 此時會呼叫__int__()方法
print(float(a)) # 此時會呼叫__float__()方法
- __enter__()和__exit__():上下文管理協定,即with語句,爲了讓一個物件相容with語句,必須在這個物件的類中宣告這兩個方法。出現with語句時物件的__enter__()被觸發,有返回值則賦值給as宣告的變數。而當with中程式碼塊執行完畢時執行__exit__()。__exit__()中的三個參數分別代表異常型別,異常值和追溯資訊。在出現異常時會交給__exit__()處理。如果with語句中程式碼塊出現異常,則with後的程式碼都無法執行。但若__exit__()返回值爲True,則異常會被清空,with後的語句正常執行。可用自定義open()函數進行檔案資源操作。關於上下文管理協定後面將繼續介紹
class Open:
def __init__(self, filepath, mode='r', encoding='utf-8'):
self.filepath = filepath
self.mode = mode
self.encoding = encoding
def __enter__(self):
# print('enter')
self.f = open(self.filepath, mode=self.mode, encoding=self.encoding)
return self.f
def __exit__(self, exc_type, exc_val, exc_tb):
# print('exit')
self.f.close()
return True
def __getattr__(self, item):
return getattr(self.f, item)
with Open('a.txt', 'w') as f:
print(f)
f.write('aaaaaa')
f.wasdf #拋出異常,交給__exit__處理
描述符
描述符是一個具有系結行爲的物件屬性,其屬性存取將由描述符協定中的方法覆蓋。這些方法爲 __get__()、__set__() 和 __delete__()。簡單來講,描述符是指用含有這些方法中的一些的一個類,當對這個類的範例化物件進行操作時,會自動呼叫相應的方法
- __get__(self, instance, owner):在存取該屬性時呼叫。方法返回屬性的值,若屬性不存在則返回異常。其中,instance 表示擁有該屬性的範例化物件,owner 表示擁有該屬性的類。當 instance 要存取該屬性時,會先呼叫 instance 的__getattribute__() 方法,然後由該方法在instance.__dict__中尋找(即看物件是否有該範例屬性),若找到了則以instance.__dict__[‘x’].__get__(instance, owner)的方式呼叫該方法;若沒有則去owner.__dict__中尋找(即看物件是否有該類屬性),若找到了則以owner.__dict__[‘x’].__get__(None, owner)的方式呼叫該方法
- __set__(self, instance, value):在對該屬性賦值時呼叫。不返回任何內容。其中,instance 表示擁有該屬性的範例化物件,value 表示要設定的屬性的值。當 instance 要對該屬性進行賦值時,會先呼叫 instance 的__setattr__() 方法,然後該方法以instance.__dict__[‘x’].__set__(instance, value)的方式呼叫該方法
- __delete__(self, instance):在刪除該屬性時呼叫。不返回內容。其中,instance 表示擁有該屬性的範例化物件。當 instance 要刪除該屬性時,會先呼叫 instance 的__delattr__() 方法,然後該方法會以instance.__dict__[‘x’].__delete__(instance)的方式呼叫該方法
當Python直譯器發現範例物件中有與描述符同名的屬性時,描述符優先,會覆蓋掉範例屬性。如果全定義了__get__() 方法,而沒有定義 __set__(), __delete__() 方法,則成爲數據描述符,若只定義了 __get__() 方法,則認爲是非數據描述符。數據描述符的優先順序要比非數據描述符高,且非數據描述符優先順序要比範例屬性,類屬性要低
實現方式
- 基於類建立
class Descriptor(object):
def __init__(self):
self._name = ''
def __get__(self, instance, owner):
print("__get__")
return self._name
def __set__(self, instance, value):
print("__set__")
self._name = value
def __delete__(self, instance):
print("__delete__")
del self._name
class Person(object):
def __init__(self):
self.name = Descriptor()
p = Person()
print(p.name)
# print(p.__dict__['name'].__get__(p, Person))
p.name = 'A'
# p.__dict__['name'].__set__(p, 'A')
del p.name
# p.__dict__['name'].__delete__(p)
- 使用propety()函數,其一般形式爲property([fget[, fset[, fdel[, doc]]]])。其中fget表示獲取屬性值的函數,fset表示設定屬性值的函數,fdel表示刪除屬性值函數,doc表示屬性描述資訊,可通過該屬性的__doc__檢視。但注意,在使用 property() 函數時,以上 4 個參數可以僅指定第 1 個、或者前 2 個、或者前 3 個,也可以全部指定。也就是說,property() 函數中參數的指定並不是完全隨意的。此時,對類中該屬性的操作會觸發相關函數。事實上,property()函數就是一個描述符類
class Person(object):
def __init__(self):
self._name = ''
def fget(self):
print("Getting: %s" % self._name)
return self._name
def fset(self, value):
print("Setting: %s" % value)
self._name = value.title()
def fdel(self):
print("Deleting: %s" % self._name)
del self._name
name = property(fget, fset, fdel, "I'm the property.")
p = Person()
print(p.name)
p.name = 'A'
del p.name
- 使用@property裝飾器。@property裝飾器實際上也是描述符,其主要是作用是把類中的一個方法變爲類中的一個屬性,並且使定義屬性和修改現有屬性變的更容易
class Person(object):
def __init__(self, name):
self._name = name
@property
def name(self):
print("get_name")
return self._name
@name.setter # 若不設定setter,則該屬性爲只讀
def name(self, value):
print("set_name")
self._name = value
@name.deleter
def name(self):
print("del_name")
del self._name
p = Person("A")
print(p.name) #此時是用@property修飾的函數名來作爲屬性的名稱
p.name = "B"
del p.name
描述符的使用場景
- 通過結合使用描述符,可以實現優雅的程式設計,允許建立 Setters 和 Getters 以及只讀屬性
- 根據值或型別請求進行屬性驗證
- 大量用於各種框架中,比如Django的models
繼承
繼承是一種建立新類的方式。其中,父類別又可稱爲基礎類別或超類,新建的類稱爲派生類或子類,而子類會繼承父類別的屬性和方法。注意,如果該類沒有顯式指定繼承自哪個類,則預設繼承 object 類(object 類是 Python 中所有類的父類別,即要麼是直接父類別,要麼是間接父類別)。其一般形式爲
class 類名(父類別1):
#類定義部分
多繼承
和C++的多繼承機制 機製一樣,Python中新建的類可以繼承一個或多個父類別(但和單繼承相比,多繼承容易讓程式碼邏輯複雜、思路混亂,一直備受爭議,中小型專案中較少使用,後來的 Java、C#、PHP 等乾脆取消了多繼承)。使用多繼承經常需要面臨的問題是,多個父類別中包含同名的類方法。對於這種情況,Python 的處置措施是:根據子類繼承多個父類別時這些父類別的前後次序決定,即排在前面父類別中的類方法會覆蓋排在後面父類別中的同名類方法(注意多繼承是子類同時繼承多個父類別,而多重繼承則是繼承有多個層次)
class People:
def say(self):
print("People類")
class Animal:
def say(self):
print("Animal類")
class Person(People, Animal):
pass
p = Person()
p.say()
這種繼承多個父類別的設計模式使得子類得以「混入」多種額外的功能,因而這種設計模式稱爲混入類(MixIn)。混入類避免設計多層次的複雜的繼承關係,爲程式碼重用而生,使得程式碼結構簡單清晰
如有狗狗、 蝙蝠、 鸚鵡、 鴕鳥四個子類,這四個子類都繼承父類別動物類。現對這四種動物有兩種分類方法:以能不能飛分類,和以是否爲哺乳類動物分類。若沒有多繼承,則只能動物類下有哺乳類和非哺乳類兩個子類,哺乳類下有能飛和能跑兩個子類,非哺乳類下同樣有能飛和能跑兩個子類,然後最下面 下麪纔是四種動物的子類。若分類方式增多,則繼承的子類個數會以指數遞增。而當使用多繼承時,中間哺乳類子類、非哺乳類子類,能跑子類、以及能飛子類則爲混入類,最底層的動物子類能夠同是繼承混入多個混入類。如狗類同時有哺乳類混入類以及能跑混入類
- 能用mix-in元件實現的效果,就不要使用多重繼承來做
- 將各功能實現爲可插拔的mix-in元件,然後令相關的類繼承自己需要的那些元件,即可定製該類範例所具備的行爲
- 把簡單的行爲封裝到mix-in元件裡,然後就可以用多個mix-in組合出複雜的行爲了
經典類和新式類
在Python2中,預設都是經典類,只有顯式繼承了object纔是新式類,即:
- class Person(object): pass:新式類寫法
- class Person(): pass:經典類寫法
- class Person: pass:經典類寫法
在Python3中取消了經典類,預設都是新式類,並且不必顯式的繼承object,也就是說上面三種寫法都是新式類寫法。他們最明顯的區別在於繼承搜尋的順序發生了改變,即經典類多繼承搜尋順序爲深度優先,先深入繼承樹左側查詢,然後再返回,開始查詢右側;而新式類多繼承搜尋順序爲廣度優先,先在水平方向查詢,然後再向上查詢
MRO
對於定義的類,Python會建立一個方法解析順序MRO(Method Resolution Order)列表來記錄類繼承的順序。對於單繼承來說,MRO 一般比較簡單;而對於多繼承來說,MRO 就複雜很多。Python 至少有三種不同的 MRO,下面 下麪分別以菱形繼承(D的父類別爲B和C,B和C的父類別爲A)說明
1). 經典類(classic class)的深度優先遍歷
此時查詢順序爲 [D, B, A, C, A],有些父類別可能會查詢多次,因而會增大開銷
2). Python 2.2 的新式類(new-style class)預計算
爲解決經典類 MRO 所存在的問題,Python 2.2 針對新式類提出了一種新的 MRO 計算方式,在定義類時就計算出該類的 MRO 並將其作爲類的屬性。因此新式類可以直接通過__mro__屬性獲取類的 MRO。Python 2.2 的新式類 MRO 計算方式和經典類 MRO 的計算方式非常相似,它仍然採用從左至右的深度優先遍歷,但是如果遍歷中出現重複的類,只保留最後一個。因而此時查詢順序爲 [D, B, C, A, object](因爲爲新式類,當類A、B、C、D都不存在目標方法時會繼續往父類別object查詢)
3). Python 2.3 的新式類的C3 演算法
它也是 Python 3 唯一支援的方式。針對一些比較複雜的情況,預計算方法可能並不奏效。如下圖所示
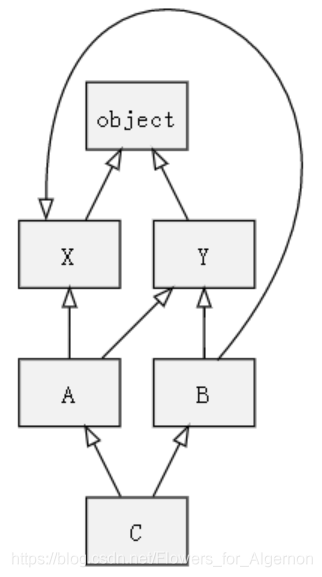
此時對於 A 來說,其搜尋順序爲[A, X, Y, object];對於 B,其搜尋順序爲 [B, Y, X, object];對於 C,其搜尋順序爲[C, A, B, Y, X, object]。也就是說,A 和 C 中 X、Y 的搜尋順序是相反的,即當 A 被繼承時,它本身的行爲、發生了改變,這很容易導致不易察覺的錯誤。此外,即使把 C 搜尋順序中 X 和 Y 互換仍然不能解決問題,這時候它又會和 B 中的搜尋順序相矛盾。其原因在於,上述繼承關係違反了線性化的單調性原則,父類別的繼承順序不同。因而Python 2.3 提出了C3 演算法。此時再按上述定義類則會產生一個異常,禁止建立具有二義性的繼承關係
在C3演算法中,Python把類 C 的 MRO 記爲 L[C] = [C1, C2,…,CN]。其中 C1 稱爲 L[C] 的頭,其餘元素 [C2,…,CN] 稱爲尾。如果一個類 C 繼承自基礎類別 B1、B2、……、BN,那麼我們可以根據以下兩步計算出 L[C]:
(1) L\[object] = \[object]
(2) L[C(B1…BN)] = [C] + merge(L[B1]…L[BN], [B1]…[BN])
merge 的計算方式如下:
(1) 檢查第一個列表的頭元素(如 L[B1] 的頭),記作 H
(2) 若 H 未出現在其它列表的尾部,則將其輸出,並將其從所有列表中刪除,然後回到步驟(1);否則,取出下一個列表的頭部記作 H,繼續該步驟
(3) 重複上述步驟,直至列表爲空或者不能再找出可以輸出的元素。如果是前一種情況,則演算法結束;如果是後一種情況,說明無法構建繼承關係,Python 會拋出異常
該方法有點類似於圖的拓撲排序,但它同時還考慮了基礎類別的出現順序。此時,A 的MRO計算方法過程爲:
L[A] = [A] + merge(L[X], L[Y], [X], [Y])
= [A] + merge([X, object], [Y, object], [X], [Y])
= [A, X] + merge([object], [Y, object], [Y])
= [A, X, Y] + merge([object], [object])
= [A, X, Y, object]
注意第3步,merge([object], [Y, object], [Y]) 中首先輸出的是 Y 而不是 object。這是因爲 object 雖然是第一個列表的頭,但是它出現在了第二個列表的尾部。所以我們會跳過第一個列表,去檢查第二個列表的頭部,也就是 Y。Y 沒有出現在其它列表的尾部,所以將其輸出
super()
super() 函數是用於呼叫已經在子類中被重寫的父類別方法。super 是用來解決多重繼承問題的,直接用類名呼叫父類別方法在使用單繼承的時候沒問題,但是如果使用多繼承,會涉及到查詢順序(MRO)、重複呼叫(鑽石繼承)等種種問題。super() 的一般形式爲 super(type[, object-or-type])。其中,type表示類,object-or-type表示 類,一般是 self。super(type, obj)返回 obj 的MRO中Type的下一個類的代理。Python3 和 Python2 中super()的區別爲,Python3 可以使用直接使用 super().xxx 代替 Python2 中的 super(type, obj).xxx
class A:
def x(self):
print('run A.x')
super().x()
print(self)
class B:
def x(self):
print('run B.x')
print(self)
class C(A,B):
def x(self):
print('run C.x')
super().x()
print(self)
C().x()
# 輸出
# run C.x
# run A.x
# run B.x
# <__main__.C object at 0x000002B5041BB710>
# <__main__.C object at 0x000002B5041BB710>
# <__main__.C object at 0x000002B5041BB710>
在呼叫了A中的x()方法之後,下一個呼叫的是B中的x()方法,在繼承結構中,類A和類B互爲兄弟關係,super()在A中呼叫的時候,最終卻呼叫其兄弟的同名方法。這是因爲在呼叫super(type, obj)時,type參數傳入的是當前的類,而obj參數則是預設傳入當前的範例物件,在super()的後續呼叫中,obj一直未變,而實際傳入的class是動態變化。不過,在首次呼叫時,MRO就已經被確定(注意整個過程只有一個範例),是obj所屬類(即C)的MRO,因此class參數的作用就是從已確定的MRO中找到位於其後緊鄰的類,作爲再次呼叫super()時查詢該方法的下一個類
因此,在子類建構函式中呼叫父類別建構函式的順序也是按照MRO的順序呼叫
通過在Python中使用super()函數,可以實現僅通過重寫無法實現的,多繼承協同工作的邏輯。如子類Final類的父類別爲Minix1、Minix2、Header類,Final類從Header類中繼承獲得屬性header列表,並且通過Minix1和Minix2類在列表header中追加屬性data1和data2
class Minix1:
def get_header(self):
print('run Minix1.get_header')
ctx = super().get_header()
ctx.append('data1')
return ctx
class Minix2:
def get_header(self):
print('run Minix2.get_header')
ctx = super().get_header()
ctx.insert(0, 'data2')
return ctx
class Header:
header = []
def get_header(self):
print('run Headers.get_header')
return self.header if self.header else []
class Final(Minix1, Minix2, Header):
def get_header(self):
return super().get_header()
Python有兩個可以判斷繼承關係的內建函數:
使用isinstance()檢查範例的型別:isinstance(obj, int),當且僅當obj.__class__是int或者派生於int的類時,返回True
使用issubclass()檢查類的繼承關係:issubclass(bool, int)返回True,因爲bool是int的子類。然而issubclass(float, int)返回False,因爲float不是int的子類
呼叫父類別屬性和方法
- 呼叫父類別屬性和方法:因爲子類已經獲得父類別所有屬性和方法,所以直接當作子類的屬性和方法呼叫即可。其他如實體方法、類方法正常呼叫即可
- 重寫父類別屬性和方法:若子類擁有和父類同名的屬性和方法,子類的屬性和方法將覆蓋掉父類別的屬性的方法(包括子類中同名但參數不同的方法)。此時若想呼叫父類別的方法,則需要呼叫super()函數,但是並不能呼叫父類別被覆蓋的屬性
- 呼叫父類別的私有屬性的方法:前面說過Python並不存在實際意義上的私有成員,只是通過改名的方法阻止外部呼叫,因而在子類中只要呼叫改名後的屬性和方法即可呼叫父類別的私有成員
- 呼叫父類別建構函式:呼叫父類別__init__()方法最好是通過super()呼叫,也可通過 Base.__init__(self)呼叫。但並不推薦這麼做,因爲在多繼承中會產生混亂
子類化內建型別
在Python2.2之後,內建型別都可以子類化。內建型別子類化是指自定義一個新類,使其繼承有類似行爲的內建類,通過重定義這個新類實現指定的功能。如果想實現與某個內建型別具有類似行爲的類時,最好的方法就是將這個內建型別子類化。當使用內建型別子類化時,它們作爲子類的速度更快,程式碼更整潔
class DopperDict(dict):
def __setitem__(self, key, value):
super(DopperDict,self).__setitem__(key, [value]*2)
d = DopperDict(one=1) # d = {'one': 1}
d['two'] = 2 # d = {'two': [2,2], 'one': 1}
d.update(three=3) # d = {'three': 3, 'two': [2,2], 'one':1}
這裏雖然重寫了__setitem__()方法,使用[]運算子會呼叫覆蓋的__setitem__()方法,按照預期工作,但繼承自dict的__init__()和update()方法忽略了被覆蓋的__setitem__()方法,one和three值並沒有重複。這就會導致初始化和賦值的時候得到的結果不一樣。因而自定義的內建型別子類應該繼承collections模組,如UserDict,UserList,UserString等。這些類做了特殊設計,因此易於拓展。但是仍不推薦重寫內建型別子類中的方法
import collections
class DopperDict(collections.UserDict):
def __setitem__(self, key, value):
super(DopperDict,self).__setitem__(key, [value]*2)
抽象基礎類別
Python中定義抽象基礎類別必須繼承abc模組的ABC類,或者使用元類方式,設定類的元類爲abc.ABCMeta來實現。同時,使用裝飾器@abc.abstractmethod定義抽象方法,並且其子類必須定義抽象方法
from abc import ABC
class A(ABC):
#class A(metaclass=abc.ABCMeta):
# 抽象實體方法
@abstractmethod
def a(self): pass
# 抽象類方法
@classmethod
@abstractmethod
def b(cls): pass
# 抽象靜態方法
@staticmethod
@abstractmethod
def c(): pass
# 抽象屬性
@property
def x(self): pass
@x.setter
@abstractmethod
def x(self, val): pass
多型
class Person(object):
def __init__(self, name, gender):
self.name = name
self.gender = gender
def whoAmI(self):
return 'I am a Person, my name is %s' % self.name
class Student(Person):
def __init__(self, name, gender, score):
super(Student, self).__init__(name, gender)
self.score = score
def whoAmI(self):
return 'I am a Student, my name is %s' % self.name
class Teacher(Person):
def __init__(self, name, gender, course):
super(Teacher, self).__init__(name, gender)
self.course = course
def whoAmI(self):
return 'I am a Teacher, my name is %s' % self.name
def who_am_i(x):
print x.whoAmI()
p = Person('Tim', 'Male')
s = Student('Bob', 'Male', 88)
t = Teacher('Alice', 'Female', 'English')
who_am_i(p)
who_am_i(s)
who_am_i(t)
由於Python是動態語言,所以,傳遞給函數 who_am_i(x)的參數 x 不一定是 Person 或 Person 的子型別。任何數據型別的範例都可以,只要它有一個whoAmI()的方法即可。這是動態語言和靜態語言(例如Java)最大的差別之一。動態語言呼叫實體方法,不檢查型別,只要方法存在,參數正確,就可以呼叫。另外,注意在 Python 中不僅實體方法支援多型,類方法同樣支援多型
動態建立類
之前說過Python能夠動態新增(系結)屬性和方法,其實,Python也能夠動態建立類。有兩個方法可以在執行時動態建立類:
- 返回巢狀類:和巢狀函數一樣,類也可以巢狀定義。因爲在Python中一切皆物件,因而函數中可以巢狀函數定義和類定義,類中也可以巢狀函數定義(即類方法成員)和類定義,並且可以重複多層巢狀
def choose_class(name):
if name == 'foo':
class Foo(object):
pass
return Foo # 返回的是類,不是類的範例
else:
class Bar(object):
pass
return Bar
MyClass = choose_class('foo')
class parent:
class child:
def __init__(self):
self.name = 'child'
child = parent.child() # 返回的是範例
- 使用type()函數構造類:Python內建函數type()的語法格式有兩種:type(obj)和type(name, bases, dict)。第一種語法格式是用來檢視某個變數(類物件)的具體型別;第二種語法格式是用來建立類,其中 name 表示類的名稱;bases 表示一個元組,其中儲存的是該類的父類別;dict 表示一個字典,用於表示類內定義的屬性或者方法。這是兩種完全不同的功能,但這在Python中是爲了保持向後相容性。事實上,在使用 class 定義類時,Python 直譯器底層依然是用 type() 來建立這個類。另外,type()函數還可以爲類動態新增屬性和方法(或者說用新的類定義覆蓋掉舊的類定義),但是在此之前的類的舊定義的範例化物件保持不變
def func(self):
pass
Test = type("Test",(object,),dict(func = func, name = "Test Class"))
t = Test()
元類
在Python當中萬物皆物件,我們用class關鍵字定義的類本身也是一個物件,可以像使用其他物件一樣使用這個類物件。而負責產生該物件的類稱之爲元類(Meta Class),元類可以簡稱爲類的類。即MyClass = MetaClass()中元類範例化物件爲自定義類物件,而MyObject = MyClass()中自定義類的範例化物件爲MyObject。而type()函數就是Python的一個內建元類,在python當中任何class定義的類其實都是type類範例化的結果。只有繼承了type類才能 纔能稱之爲一個元類,否則就是一個普通的自定義類。在Python的世界中,object是父子關係的頂端,所有的數據型別的父類別都是它;type是型別範例關係的頂端,所有物件都是它的範例的。元類type爲小寫是爲了保持一致性,如int是用來建立整數物件的類,而str是用來建立字串物件的類。Python中所有物件都有__class__屬性,它表示物件所屬的類型別,而__class__屬性也有__class__,爲type,表示類型別的型別
class MyMetaClass(type):
def __init__(self, cls_name, cls_bases, cls_dict):
print("test")
def func(self): pass
Test1 = MyMetaClass("Test1",(object,), {'func': func, 'name': "Test Class"})
# 在Python2中需要指定__metaclass__屬性
class Test2(object):
__metaclass__ = MyMetaClass
name = "Test Class"
def func(self): pass
# 在Python3中則可以在一開始宣告元類
class Test3(object, metaclass=MyMetaClass):
name = "Test Class"
def func(self): pass
在定義類,即MyClass = MetaClass()時,先找類的元類,如果找不到則往上找父類別的元類,如果也找不到則找模組的元類,如果再找不到則用Python內建的type元類。在找到元類後,就開始建立類物件,此時,先通過元類的__new__()產生一個空物件,通過元類的__init__()初始化這個類物件,最後返回這個類物件。在得到類物件後,在類物件範例化,即MyObject = MyClass()時,MyClass()中的括號表示呼叫元類的__call__()方法(MyClass對於元類來說是範例,所以MyClass()是呼叫元類的__call__()方法,而MyObject()纔是呼叫MyClass的__call__()方法)。換句話說,重寫元類的__new__()和__init__()方法能修改類物件的建立過程,而重寫原來的__call__()方法能修改類物件範例化的過程。所以之前重寫自定義類的__new__()方法來實現單例模式,這裏可通過重寫元類的__call__()方法來實現
class MyMetaClass(type):
def __init__(self, *args, **kwargs):
self.__instance = None
super().__init__(*args, **kwargs)
def __call__(self, *args, **kwargs):
if self.__instance is None:
self.__instance = super().__call__(*args, **kwargs)
return self.__instance
class MyClass(object, metaclass=MyMetaClass):
pass
t1 = MyClass()
t2 = MyClass()
print(t1 is t2)
下面 下麪給出另一個利用元類的例子。要求保證使用者設計的類必須有文件註釋,不能爲空 ;同時要求在一個類內部定義的所有函數必須有文件註釋,不能爲空
class MyMetaClass1(type):
def __init__(self, cls_name, cls_bases, cls_dict):
if '__doc__' not in cls_dict or \
len(cls_dict['__doc__'].strip()) == 0:
raise TypeError('類必須有非空文件註釋')
for key, value in cls_dict.items():
if key.startswith('__'):
continue
if not callable(value):
continue
if not value.__doc__ or \
len(value.__doc__.strip()) == 0:
raise TypeError('函數必須有非空文件註釋')
super().__init__(cls_name, cls_bases, cls_dict)
# 也可以利用__new__()方法來實現
class MyMetaClass2(type):
def __new__(cls, cls_name, cls_bases, cls_dict):
if '__doc__' not in cls_dict or \
len(cls_dict['__doc__'].strip()) == 0:
raise TypeError('類必須有非空文件註釋')
for key, value in cls_dict.items():
if key.startswith('__'):
continue
if not callable(value):
continue
if not value.__doc__ or \
len(value.__doc__.strip()) == 0:
raise TypeError('函數必須有非空文件註釋')
return super().__new__(cls, cls_name, cls_bases, cls_dict)
列舉類
Python 3中新增加了 Enum 列舉類,和普通類的用法不同,列舉類不能用來範例化物件
from enum import Enum
class Color(Enum):
red = 1 # 這些值不能在類外部修改
green = 2
blue = 3
# 存取
print(Color.red) # Color.red
print(Color['red']) # Color.red
print(Color(1)) # Color.red
print(Color.red.value) # 1
print(Color.red.name) # red
for color in Color:
print(color)
# Color.red Color.green Color.blue
for name, member in Color.__members__.items():
print(name,"-",member)
# red-Color.red green-Color.green blue-Color.blue
# 比較
print(Color.red == Color.green) # Flase
print(Color.red.name is Color.green.name) # Flase
Python允許值相同的情況,此時會將r當作red的別名,因此存取r成員最終輸出的是red。若想避免這種情況,需要用@unique 裝飾器,當列舉類中出現相同值的成員時會報 ValueError 錯誤
from enum import Enum
class Color(Enum):
red = 1
r = 1
@unique
class UniqueColor(Enum):
red = 1
r = 1
除了通過繼承 Enum 類的方法建立列舉類,還可以使用 Enum() 函數建立列舉類。此時成員的值從1開始順序賦值
from enum import Enum
Color = Enum("Color", ('red','green','blue'))
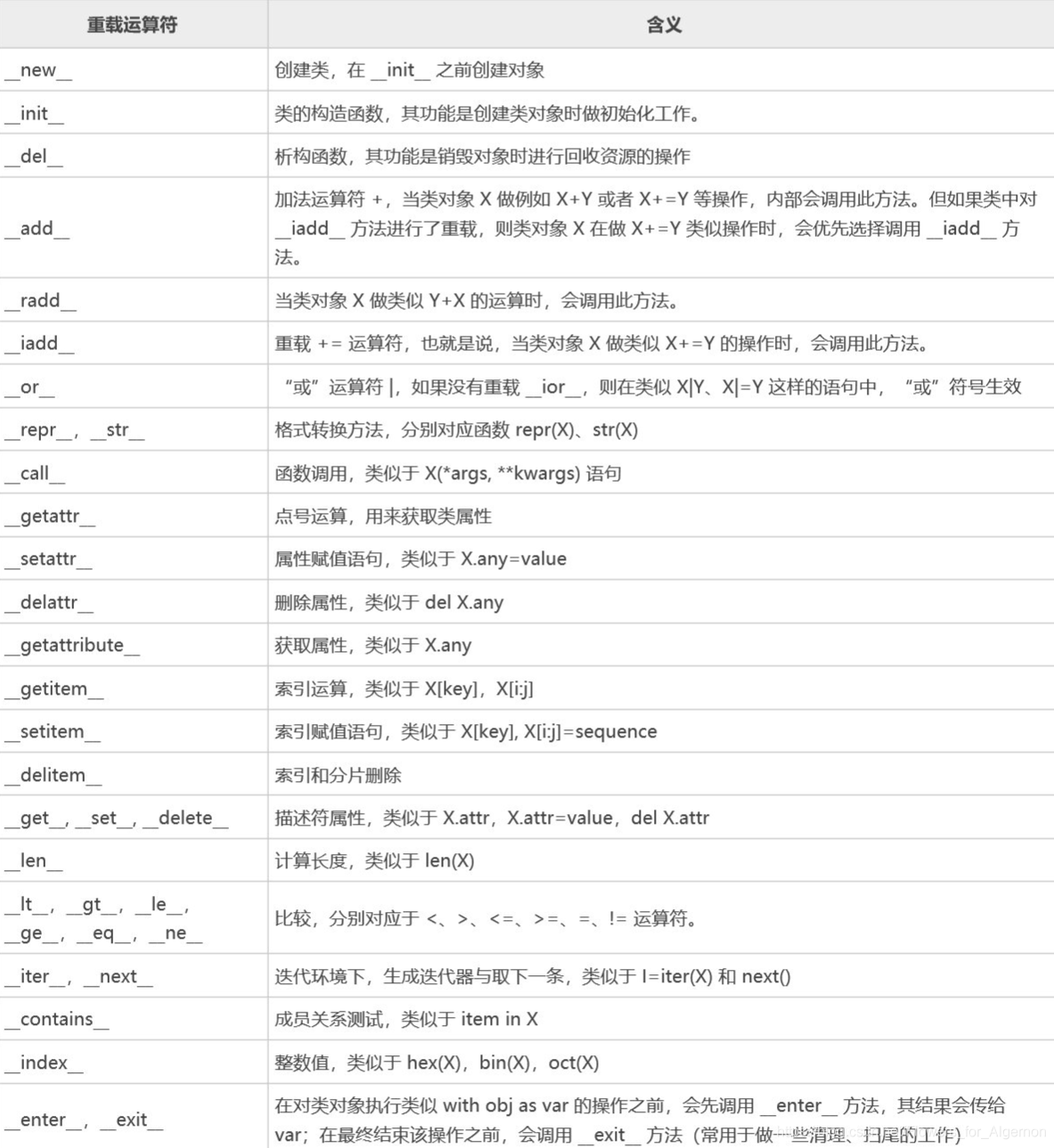
運算子過載
與C++不同,Python中過載運算子只需要重寫相應的函數就可以了
class OpTest:
def __init__(self, a):
self.a = a
def __lt__(self, record): #過載 < 號運算子
return self.a < record.a:
def __add__(self, record): #過載 + 號運算子
return OpTest(self.a + record.a)
def __str__(self):
return "a:" + str(self.a)
a = OpTest(1)
b = OpTest(2)
print(a < b)
print (a + b)
下面 下麪列出了 Python 中常用的可過載的運算子,以及各自的含義