機器學習演算法之——K最近鄰(k-Nearest Neighbor,KNN)分類演算法原理講解
K最近鄰(k-Nearest Neighbor,KNN)分類演算法詳解及Python實現
上星期寫了Kaggle競賽的詳細介紹及入門指導,但對於真正想要玩這個競賽的夥伴,機器學習中的相關演算法是必不可少的,即使是你不想獲得名次和獎牌。那麼,從本週開始,我將介紹在Kaggle比賽中的最基本的也是運用最廣的機器學習演算法,很多專案用這些基本的模型就能解決基礎問題了。
那麼今天,我們開始介紹K最近鄰(k-Nearest Neighbor,KNN)分類演算法。
k-最近鄰演算法是基於範例的學習方法中最基本的,先介紹基於範例學習的相關概念。
一、基於範例的學習
已知一系列的訓練樣例,很多學習方法爲目標函數建立起明確的一般化描述;但與此不同,基於範例的學習方法只是簡單地把訓練樣例儲存起來。
從這些範例中泛化的工作被推遲到必須分類新的範例時。每當學習器遇到一個新的查詢範例,它分析這個新範例與以前儲存的範例的關係,並據此把一個目標函數值賦給新範例。
基於範例的方法可以爲不同的待分類查詢範例建立不同的目標函數逼近。事實上,很多技術只建立目標函數的區域性逼近,將其應用於與新查詢範例鄰近的範例,而從 不建立在整個範例空間上都表現良好的逼近。當目標函數很複雜,但它可用不太複雜的區域性逼近描述時,這樣做有顯著的優勢。
基於實體方法的不足
- 分類新範例的開銷可能很大。這是因爲幾乎所有的計算都發生在分類時,而不是在第一次遇到訓練樣例時。所以,如何有效地索引訓練樣例,以減少查詢時所需計算是一個重要的實踐問題。
- 當從記憶體中檢索相似的訓練樣例時,它們一般考慮範例的所有屬性。如果目標概念僅依賴於很多屬性中的幾個時,那麼真正最「相似」的範例之間很可能相距甚遠。
二、k-最近鄰法
1. KNN演算法概述
鄰近演算法,或者說K最近鄰(K-Nearest Neighbor,KNN)分類演算法是數據挖掘分類技術中最簡單的方法之一,是著名的模式識別統計學方法,在機器學習分類演算法中佔有相當大的地位。它是一個理論上比較成熟的方法。既是最簡單的機器學習演算法之一,也是基於範例的學習方法中最基本的,又是最好的文字分類演算法之一。
所謂K最近鄰,就是k個最近的鄰居的意思,說的是每個樣本都可以用它最接近的k個鄰居來代表。Cover和Hart在1968年提出了最初的鄰近演算法。KNN是一種分類(classification)演算法,它輸入基於範例的學習(instance-based learning),屬於懶惰學習(lazy learning)即KNN沒有顯式的學習過程,也就是說沒有訓練階段,數據集事先已有了分類和特徵值,待收到新樣本後直接進行處理。與急切學習(eager learning)相對應。
2. 基本思想
KNN是通過測量不同特徵值之間的距離進行分類。
思路是:如果一個樣本在特徵空間中的k個最鄰近的樣本中的大多數屬於某一個類別,則該樣本也劃分爲這個類別。 KNN演算法中,所選擇的鄰居都是已經正確分類的物件。該方法在定類決策上只依據最鄰近的一個或者幾個樣本的類別來決定待分樣本所屬的類別。
該演算法假定所有的範例對應於N維歐式空間Ân中的點。通過計算一個點與其他所有點之間的距離,取出與該點最近的K個點,然後統計這K個點裏面所屬分類比例最大的,則這個點屬於該分類。
該演算法涉及3個主要因素:範例集、距離或相似的衡量、k的大小。
一個範例的最近鄰是根據標準歐氏距離定義的。更精確地講,把任意的範例x表示爲下面 下麪的特徵向量:
其中ar(x)表示範例x的第r個屬性值。那麼兩個範例xi和xj間的距離定義爲d(xi,xj),其中:
3. 有關KNN演算法的幾點說明
- 在最近鄰學習中,目標函數值可以爲離散值也可以爲實值。
- 我們先考慮學習以下形式的離散目標函數。其中V是有限集合{v1,…,vs}。下表給出了逼近離散目標函數的k-近鄰演算法。
- 正如下表中所指出的,這個演算法的返回值f′(xq)爲對f(xq)的估計,它就是距離xq最近的k個訓練樣例中最普遍的f值。
- 如果我們選擇k=1,那麼「1-近鄰演算法」就把f(xi)賦給(xq),其中xi是最靠近xq的訓練範例。對於較大的k值,這個演算法返回前k個最靠近的訓練範例中最普遍的f值。
逼近離散值函數f:Ân−V的k-近鄰演算法
- 訓練演算法:
對於每個訓練樣例<x,f(x)>,把這個樣例加入列表training_examples- 分類演算法:
給定一個要分類的查詢範例xq 在training_examples中選出最靠近xq的k個範例,並用x1,…,xk表示- 返回
- 其中如果a=b那麼d(a,b)=1,否則d(a,b)=0
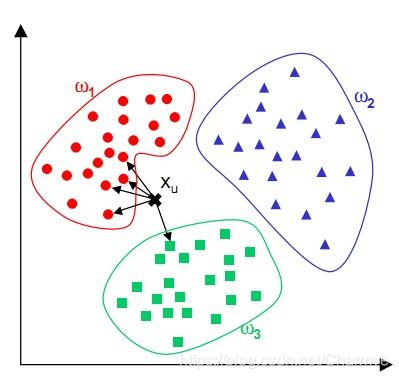
簡單來說,KNN可以看成:有那麼一堆你已經知道分類的數據,然後當一個新數據進入的時候,就開始跟訓練數據裡的每個點求距離,然後挑離這個訓練數據最近的K個點看看這幾個點屬於什麼型別,然後用少數服從多數的原則,給新數據歸類。
4. KNN演算法的決策過程
下圖中有兩種型別的樣本數據,一類是藍色的正方形,另一類是紅色的三角形,中間那個綠色的圓形是待分類數據:
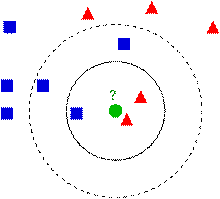
如果K=3,那麼離綠色點最近的有2個紅色的三角形和1個藍色的正方形,這三個點進行投票,於是綠色的待分類點就屬於紅色的三角形。而如果K=5,那麼離綠色點最近的有2個紅色的三角形和3個藍色的正方形,這五個點進行投票,於是綠色的待分類點就屬於藍色的正方形。
下圖則圖解了一種簡單情況下的k-最近鄰演算法,在這裏範例是二維空間中的點,目標函數具有布爾值。正反訓練樣例用「+」和「-」分別表示。圖中也畫出了一個查詢點xq。注意在這幅圖中,1-近鄰演算法把xq分類爲正例,然而5-近鄰演算法把xq分類爲反例。
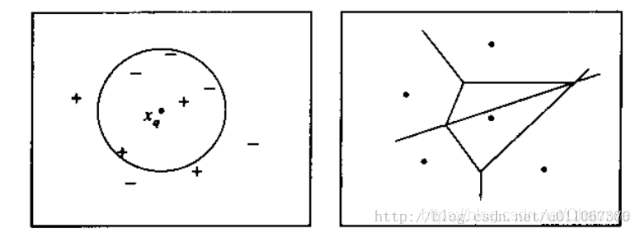
圖解說明: 左圖畫出了一系列的正反訓練樣例和一個要分類的查詢範例xq。1-近鄰演算法把xq分類爲正例,然而5-近鄰演算法把xq分類爲反例。
右圖是對於一個典型的訓練樣例集合1-近鄰演算法導致的決策面。圍繞每個訓練樣例的凸多邊形表示最靠近這個點的範例空間(即這個空間中的範例會被1-近鄰演算法賦予該訓練樣例所屬的分類)。
對前面的k-近鄰演算法作簡單的修改後,它就可被用於逼近連續值的目標函數。爲了實現這一點,我們讓演算法計算k個最接近樣例的平均值,而不是計算其中的最普遍的值。更精確地講,爲了逼近一個實值目標函數f:Rn⟶R,我們只要把演算法中的公式替換爲:
三、針對傳統KNN演算法的改進
- 快速KNN演算法。參考FKNN論述文獻(實際應用中結合lucene)
- 加權歐氏距離公式。在傳統的歐氏距離中,各特徵的權重相同,也就是認定各個特徵對於分類的貢獻是相同的,顯然這是不符合實際情況的。同等的權重使得特徵向量之間相似度計算不夠準確, 進而影響分類精度。加權歐氏距離公式,特徵權重通過靈敏度方法獲得(根據業務需求調整,例如關鍵字加權、詞性加權等)
距離加權最近鄰演算法
對k-最近鄰演算法的一個顯而易見的改進是對k個近鄰的貢獻加權,根據它們相對查詢點xq的距離,將較大的權值賦給較近的近鄰。
例如,在上表逼近離散目標函數的演算法中,我們可以根據每個近鄰與xq的距離平方的倒數加權這個近鄰的**「選舉權」**。
方法是通過用下式取代上表演算法中的公式來實現:
其中
爲了處理查詢點xq恰好匹配某個訓練樣例xi,從而導致分母爲0的情況,我們令這種情況下的 f′(xq) 等於f(xi)。如果有多個這樣的訓練樣例,我們使用它們中佔多數的分類。
我們也可以用類似的方式對實值目標函數進行距離加權,只要用下式替換上表的公式:
其中,wi的定義與之前公式中相同。
注意這個公式中的分母是一個常數,它將不同權值的貢獻歸一化(例如,它保證如果對所有的訓練樣例xi,f(xi)=c,那麼(xq)←c)。
注意以上k-近鄰演算法的所有變體都只考慮k個近鄰以分類查詢點。如果使用按距離加權,那麼允許所有的訓練樣例影響xq的分類事實上沒有壞處,因爲非常遠的範例對(xq)的影響很小。考慮所有樣例的惟一不足是會使分類執行得更慢。如果分類一個新的查詢範例時考慮所有的訓練樣例,我們稱此爲全域性(global)法。如果僅考慮最靠近的訓練樣例,我們稱此爲區域性(local)法。
四、幾個問題的解答
按距離加權的k-近鄰演算法是一種非常有效的歸納推理方法。它對訓練數據中的噪聲有很好的魯棒性,而且當給定足夠大的訓練集合時它也非常有效。注意通過取k個近鄰的加權平均,可以消除孤立的噪聲樣例的影響。
- 問題一: 近鄰間的距離會被大量的不相關屬性所支配。
應用k-近鄰演算法的一個實踐問題是,範例間的距離是根據範例的所有屬性(也就是包含範例的歐氏空間的所有座標軸)計算的。這與那些只選擇全部範例屬性的一個子集的方法不同,例如決策樹學習系統。
比如這樣一個問題:每個範例由20個屬性描述,但在這些屬性中僅有2個與它的分類是有關。在這種情況下,這兩個相關屬性的值一致的範例可能在這個20維的範例空間中相距很遠。結果,依賴這20個屬性的相似性度量會誤導k-近鄰演算法的分類。近鄰間的距離會被大量的不相關屬性所支配。這種由於存在很多不相關屬性所導致的難題,有時被稱爲維度災難(curse of dimensionality)。最近鄰方法對這個問題特別敏感。
解決方法: 當計算兩個範例間的距離時對每個屬性加權。
這相當於按比例縮放歐氏空間中的座標軸,縮短對應於不太相關屬性的座標軸,拉長對應於更相關的屬性的座標軸。每個座標軸應伸展的數量可以通過交叉驗證的方法自動決定。
- 問題二: 應用k-近鄰演算法的另外一個實踐問題是如何建立高效的索引。因爲這個演算法推遲所有的處理,直到接收到一個新的查詢,所以處理每個新查詢可能需要大量的計算。
解決方法: 目前已經開發了很多方法用來對儲存的訓練樣例進行索引,以便在增加一定儲存開銷情況下更高效地確定最近鄰。一種索引方法是kd-tree(Bentley 1975;Friedman et al. 1977),它把範例儲存在樹的葉結點內,鄰近的範例儲存在同一個或附近的結點內。通過測試新查詢xq的選定屬性,樹的內部結點把查詢xq排列到相關的葉結點。
1. 關於K的取值
K:臨近數,即在預測目標點時取幾個臨近的點來預測。
K值得選取非常重要,因爲:
-
如果當K的取值過小時,一旦有噪聲得成分存在們將會對預測產生比較大影響,例如取K值爲1時,一旦最近的一個點是噪聲,那麼就會出現偏差,K值的減小就意味着整體模型變得複雜,容易發生過擬合;
-
如果K的值取的過大時,就相當於用較大鄰域中的訓練範例進行預測,學習的近似誤差會增大。這時與輸入目標點較遠範例也會對預測起作用,使預測發生錯誤。K值的增大就意味着整體的模型變得簡單;
-
如果K==N的時候,那麼就是取全部的範例,即爲取範例中某分類下最多的點,就對預測沒有什麼實際的意義了;
K的取值儘量要取奇數,以保證在計算結果最後會產生一個較多的類別,如果取偶數可能會產生相等的情況,不利於預測。
K的取法:
常用的方法是從k=1開始,使用檢驗集估計分類器的誤差率。重複該過程,每次K增值1,允許增加一個近鄰。選取產生最小誤差率的K。
一般k的取值不超過20,上限是n的開方,隨着數據集的增大,K的值也要增大。
2. 關於距離的選取
距離就是平面上兩個點的直線距離
關於距離的度量方法,常用的有:歐幾裡得距離、餘弦值(cos), 相關度 (correlation), 曼哈頓距離 (Manhattan distance)或其他。
Euclidean Distance 定義:
兩個點或元組P1=(x1,y1)和P2=(x2,y2)的歐幾裡得距離是
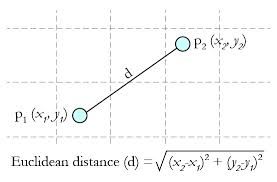
距離公式爲:(多個維度的時候是多個維度各自求差)
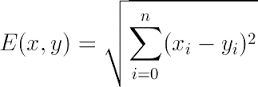
3. 相似性度量
相似性一般用空間內兩個點的距離來度量。距離越大,表示兩個越不相似。
作爲相似性度量的距離函數一般滿足下列性質:
- d(X,Y)=d(Y,X);
- d(X,Y)≦d(X,Z)+d(Z,Y);
- d(X,Y)≧0;
- d(X,Y)=0,當且僅當X=Y;
這裏,X,Y和Z是對應特徵空間中的三個點。
假設X,Y分別是N維特徵空間中的一個點,其中X=(x1,x2,…,xn)T,Y=(y1,y2,…,yn)T,d(X,Y)表示相應的距離函數,它給出了X和Y之間的距離測度。
距離的選擇有很多種,常用的距離函數如下:
- 明考斯基(Minkowsky)距離
, λ一般取整數值,不同的λ取值對應於不同的距離
- 曼哈頓(Manhattan)距離
,該距離是Minkowsky距離在λ=1時的一個特例
- Cityblock距離
,該距離是Manhattan距離的加權修正,其中wi,i=1,2,…,n是權重因子
- 歐幾裡德(Euclidean)距離(歐氏距離)
,是Minkowsky距離在λ=2時的特例
-
Canberra距離
-
Mahalanobis距離(馬式距離)
d(X,M)給出了特徵空間中的點X和M之間的一種距離測度,其中M爲某一個模式類別的均值向量,∑爲相應模式類別的協方差矩陣。
該距離測度考慮了以M爲代表的模式類別在特徵空間中的總體分佈,能夠緩解由於屬性的線性組合帶來的距離失真。易見,到M的馬式距離爲常數的點組成特徵空間中的一個超橢球面。
- 切比雪夫(Chebyshev)距離
切比雪夫距離或是L∞度量是向量空間中的一種度量,二個點之間的距離定義爲其各座標數值差的最大值。在二維空間中。以(x1,y1)和(x2,y2)二點爲例,其切比雪夫距離爲
切比雪夫距離或是L∞度量是向量空間中的一種度量,二個點之間的距離定義爲其各座標數值差的最大值。在二維空間中。以(x1,y1)和(x2,y2)二點爲例,其切比雪夫距離爲
- 平均距離
4. 消極學習與積極學習
(1) 積極學習(Eager Learning)
這種學習方式是指在進行某種判斷(例如,確定一個點的分類或者迴歸中確定某個點對應的函數值)之前,先利用訓練數據進行訓練得到一個目標函數,待需要時就只利用訓練好的函數進行決策,顯然這是一種一勞永逸的方法,SVM就屬於這種學習方式。
(2) 消極學習(Lazy Learning)
這種學習方式指不是根據樣本建立一般化的目標函數並確定其參數,而是簡單地把訓練樣本儲存起來,直到需要分類新的範例時才分析其與所儲存樣例的關係,據此確定新範例的目標函數值。也就是說這種學習方式只有到了需要決策時纔會利用已有數據進行決策,而在這之前不會經歷 Eager Learning所擁有的訓練過程。KNN就屬於這種學習方式。
比較
(3) 比較
Eager Learning考慮到了所有訓練樣本,說明它是一個全域性的近似,雖然它需要耗費訓練時間,但它的決策時間基本爲0.
Lazy Learning在決策時雖然需要計算所有樣本與查詢點的距離,但是在真正做決策時卻只用了區域性的幾個訓練數據,所以它是一個區域性的近似,然而雖然不需要訓練,它的複雜度還是需要 O(n),n 是訓練樣本的個數。由於每次決策都需要與每一個訓練樣本求距離,這引出了Lazy Learning的缺點:(1)需要的儲存空間比較大 (2)決策過程比較慢。
(4) 典型演算法
-
積極學習方法:SVM;Find-S演算法;候選消除演算法;決策樹;人工神經網路;貝葉斯方法;
-
消極學習方法:KNN;區域性加權迴歸;基於案例的推理;
五、Python實現
根據演算法的步驟,進行kNN的實現,完整程式碼如下
#!/usr/bin/env python
# -*- coding:utf-8 -*-
# Author: JYRoooy
import csv
import random
import math
import operator
# 載入數據集
def loadDataset(filename, split, trainingSet = [], testSet = []):
with open(filename, 'r') as csvfile:
lines = csv.reader(csvfile)
dataset = list(lines)
for x in range(len(dataset)-1):
for y in range(4):
dataset[x][y] = float(dataset[x][y])
if random.random() < split: #將數據集隨機劃分
trainingSet.append(dataset[x])
else:
testSet.append(dataset[x])
# 計算點之間的距離,多維度的
def euclideanDistance(instance1, instance2, length):
distance = 0
for x in range(length):
distance += pow((instance1[x]-instance2[x]), 2)
return math.sqrt(distance)
# 獲取k個鄰居
def getNeighbors(trainingSet, testInstance, k):
distances = []
length = len(testInstance)-1
for x in range(len(trainingSet)):
dist = euclideanDistance(testInstance, trainingSet[x], length)
distances.append((trainingSet[x], dist)) #獲取到測試點到其他點的距離
distances.sort(key=operator.itemgetter(1)) #對所有的距離進行排序
neighbors = []
for x in range(k): #獲取到距離最近的k個點
neighbors.append(distances[x][0])
return neighbors
# 得到這k個鄰居的分類中最多的那一類
def getResponse(neighbors):
classVotes = {}
for x in range(len(neighbors)):
response = neighbors[x][-1]
if response in classVotes:
classVotes[response] += 1
else:
classVotes[response] = 1
sortedVotes = sorted(classVotes.items(), key=operator.itemgetter(1), reverse=True)
return sortedVotes[0][0] #獲取到票數最多的類別
#計算預測的準確率
def getAccuracy(testSet, predictions):
correct = 0
for x in range(len(testSet)):
if testSet[x][-1] == predictions[x]:
correct += 1
return (correct/float(len(testSet)))*100.0
def main():
#prepare data
trainingSet = []
testSet = []
split = 0.67
loadDataset(r'irisdata.txt', split, trainingSet, testSet)
print('Trainset: ' + repr(len(trainingSet)))
print('Testset: ' + repr(len(testSet)))
#generate predictions
predictions = []
k = 3
for x in range(len(testSet)):
# trainingsettrainingSet[x]
neighbors = getNeighbors(trainingSet, testSet[x], k)
result = getResponse(neighbors)
predictions.append(result)
print ('predicted=' + repr(result) + ', actual=' + repr(testSet[x][-1]))
print('predictions: ' + repr(predictions))
accuracy = getAccuracy(testSet, predictions)
print('Accuracy: ' + repr(accuracy) + '%')
if __name__ == '__main__':
main()
六、sklearn庫的應用
我利用了sklearn庫來進行了kNN的應用(這個庫是真的很方便了,可以藉助這個庫好好學習一下,我是用KNN演算法進行了根據成績來預測,這裏用一個花瓣萼片的範例,因爲這篇主要是關於KNN的知識,所以不對sklearn的過多的分析,而且我用的還不深入