初識爬蟲之概念認知篇
認識爬蟲
網路爬蟲(又稱爲網頁蜘蛛,網路機器人,在FOAF社羣中間,更經常的稱爲網頁追逐者),是一種按照一定的規則,自動地抓取萬維網資訊的程式或者指令碼。另外一些不常使用的名字還有螞蟻、自動索引、模擬程式或者蠕蟲。

爬蟲也分爲「善意爬蟲」和「惡意爬蟲」,比如像谷歌,百度這樣的每天都會海量的網站,來保證使用者的需要,這個是使用者和網站都很喜歡的,所以叫善意爬蟲,但是像一些「搶票軟體」「非VIP性下載」,有的時候不但會增加網站的承受壓力,還會導致一些資源隱私泄露,所以我們又稱之爲「惡意爬蟲」。
簡單來說爬蟲是一個模擬人類請求網站行爲的程式。可以自動請求網頁、並數據抓取下來,然後使用一定的規則提取有價值的數據。

專案優勢
Python:語法優美、程式碼簡潔、開發效率高、支援的模組多。相關的HTTP請求模組和HTML解析模組非常豐富。還有Scrapy和Scrapy-redis框架讓我們開發爬蟲變得異常簡單。所以現在最爲常見的就是用Python來寫爬蟲,我們可以爬取圖片,視訊,文字。在大數據的背後,我們稱之爲「數據挖掘」,做數據分析,我們沒有數據怎麼可以。
應用廣泛,優勢凸出。在今年的疫情背後,我們依賴大數據的強大,進行數據挖掘,清洗,保障了多少人的生命安全。通過大數據進行人的行蹤追查,排查,在海量的人員數據中,提取有價值的東西。這就是爬蟲的高階用武之地

基本思路
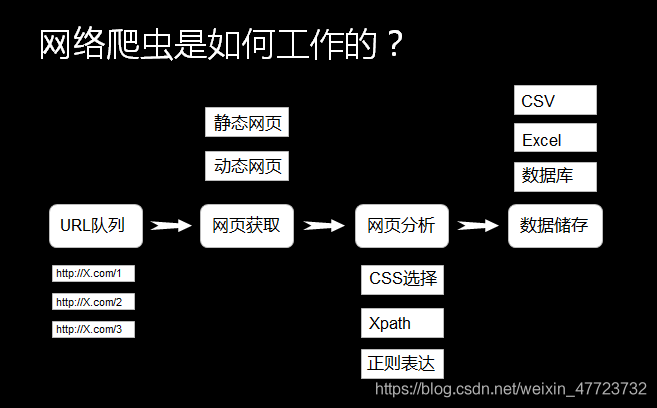
發送請求——獲得頁面——解析頁面——儲存有價值資訊
每一步都需要有紮實的語法基礎,和爬蟲庫的使用概念,我們知道如何看懂別寫的程式碼,知道如何改進別人的缺式,懂得怎樣去移植程式碼,來進行自己的一些操作。
其次就是要學會去看第三方庫的一些語法,知道如何安裝第三方庫是很重要的。
寫好一個爬蟲專案,作爲一個初學者,是非常難的,我們必須要大量的看別人的優質程式碼,爬蟲專案,知道怎樣去改善,如何做到最佳化,這個纔是我們學習的最終目的,當然在這之前,必須要學會一些知識點,不然你看都看不懂程式碼,怎麼去去優化了,哈哈哈哈!
爬蟲技術步驟
爬蟲
Web爬蟲是一種自動存取網頁的指令碼或機器人,其作用是從網頁抓取原始數據 - 終端使用者在螢幕上看到的各種元素(字元、圖片)。 其工作就像是在網頁上進行ctrl + a(全選內容),ctrl + c(複製內容),ctrl + v(貼上內容)按鈕的機器人(當然實質上不是那麼簡單)。
通常情況下,爬蟲不會停留在一個網頁上,而是根據某些預定邏輯在停止之前抓取一系列網址 。 例如,它可能會跟蹤它找到的每個鏈接,然後抓取該網站。當然在這個過程中,需要優先考慮您抓取的網站數量,以及您可以投入到任務中的資源量(儲存,處理,頻寬等)。
解析
解析意味着從數據集或文字塊中提取相關資訊元件,以便以後可以容易地存取它們並將其用於其他操作。要將網頁轉換爲實際上對研究或分析有用的數據,我們需要以一種使數據易於根據定義的參數集進行搜尋,分類和服務的方式進行解析。
儲存和檢索
最後,在獲得所需的數據並將其分解爲有用的元件之後,通過可延伸的方法來將所有提取和解析的數據儲存在數據庫或叢集中,然後建立一個允許使用者可及時查詢相關數據集或提取的功能。
爬蟲有什麼作用
1、網路數據採集
利用爬蟲自動採集網際網路中的資訊(圖片、文字、鏈接等),採集回來後進行相應的儲存與處理。並按照一定的規則和篩選標準進行數據歸類形成數據庫檔案的一個過程。但在這個過程中,首先需要明確要採集的資訊是什麼,當你將採集的條件收集得足夠精確時,採集的內容就越接近你想要的。
2、大數據分析
大數據時代,要進行數據分析,首先要有數據源,通過爬蟲技術可以獲得等多的數據源。在進行大數據分析或者進行數據挖掘的時候,數據源可以從某些提供數據統計的網站獲得,也可以從某些文獻或內部資料中獲得,但從這些獲得數據的方式,有時很難滿足我們對數據的需求,此時就可以利用爬蟲技術,自動地從網際網路中獲取需要的數據內容,並將這些數據內容作爲數據源,從而進行更深層次的數據分析。
3、網頁分析
通過對網頁數據進行爬蟲採集,在獲得網站存取量、客戶着陸頁、網頁關鍵詞權重等基本數據的情況下,分析網頁數據,從中發現訪客存取網站的規律和特點,並將這些規律與網路行銷策略等相結合,從而發現目前網路行銷活動和運營中可能存在的問題和機遇,併爲進一步修正或重新制定策略提供依據

建議
學習爬蟲前的技術準備
Python基礎語法:基礎語法﹑運算子﹑數據型別﹑流程控制﹑函數﹑物件模組﹑檔案操作﹑多執行緒﹑網路程式設計…等
W3C標準:HTML﹑CSS﹑JavaScript﹑Xpath﹑JSON
HTTP標準HTTP的請求過程﹑請求方式﹑狀態碼含義﹑頭部資訊以及Cookie狀態管理(四).數據庫MySQL﹑ MongoDB ﹑Redis…
網路爬蟲使用的技術
常用爬蟲庫:urllib requests selenium 以及scrapy爬蟲框架
在數據解析方面相應的庫包括:lxml beautifulsoup4 re pyquery…對於數據解析,主要是從 響應頁面裡提取所需的數據,常用的方法有:xpath路徑表達式, Css選擇器,正則表達式等
xpath路徑表達式,css選擇器主要用於提取結構化的數據,而正則表達式主要用於提取非結構化的數據
數據儲存:MySQL,MongoDB,Redis

總結
學習爬蟲是Python語法完成之後的最佳選擇,如果說Python語法之後,馬上就進階一些專案,這個也是不可能的,因爲爬蟲的基礎,就是在語法的基礎知識之上。