ResNet: Deep Residual Learning for Image Recognition (2015) 全文翻譯
作者
Kaiming He,Xiangyu Zhang,Shaoqing Ren,Jian Sun
(Microsoft Research {kahe, v-xiangz, v-shren, jiansun}@microsoft.com)
摘要
更深的神經網路更難訓練。 我們提出了一種殘差的學習框架,以簡化比以前使用的網路更深入的網路訓練。 我們顯式地將層重新設定爲參考層輸入學習剩餘函數,而不是學習未參考函數。 我們提供了全面的經驗證據,表明這些殘差網路更易於優化,並且可以通過深度的增加而獲得準確性。 在ImageNet數據集上,我們評估深度最大爲152層的殘差網路-比VGG網路深8倍,但仍具有較低的複雜度。 這些殘留網路的整體在ImageNet測試集上實現3.57%的誤差。 該結果在ILSVRC 2015分類任務中獲得第一名。 我們還將介紹具有100和1000層的CIFAR-10的分析。
表示的深度對於許多視覺識別任務至關重要。 僅由於我們的深度表示,我們在COCO物件檢測數據集上獲得了28%的相對改進。 深度殘差網是我們向ILSVRC&COCO 2015競賽1提交的基礎,在該競賽中,我們還獲得了ImageNet檢測,ImageNet在地化,COCO檢測和COCO分割等任務的第一名。( http://image-net.org/challenges/LSVRC/2015/ and http://mscoco.org/dataset/#detections-challenge2015.)
1. 引言
深度折積神經網路爲影象分類帶來了一系列突破。 深度網路自然地以端到端的多層方式整合了低/中/高階功能和分類器,並且功能的「級別」可以通過堆疊的層數(深度)來豐富。 最近的證據表明,網路深度至關重要,在具有挑戰性的ImageNet數據集上的領先結果都採用了「非常深」的模型,深度爲16到30。 許多其他非平凡的視覺識別任務也從非常深入的模型中受益匪淺。
在深度意義的驅動下,出現了一個問題:學習更好的網路是否像堆疊更多的層一樣容易? 回答這個問題的一個障礙是臭名昭著的梯度消失/爆炸問題,從一開始就阻礙了收斂。 但是,此問題已通過歸一化初始化層和中間歸一化層得到了很大解決,這使具有數十個層的網路能夠開始進行反向傳播的隨機梯度下降(SGD)收斂。
當更深的網路能夠開始融合時,就會出現降級問題:隨着網路深度的增加,精度達到飽和(這可能不足爲奇),然後迅速降級。 出乎意料的是,這種降級不是由過度擬合引起的,並且在我們的實驗中報告並充分驗證了,將更多層新增到適當深度的模型中會導致更高的訓練誤差。 圖1顯示了一個典型範例。
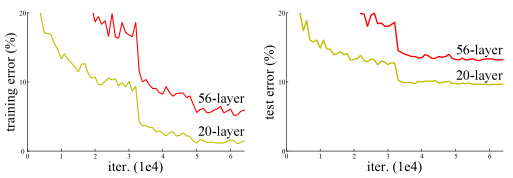
圖1. 在帶有20層和56層「普通」網路的CIFAR-10上的訓練錯誤(左)和測試錯誤(右)。 較深的網路具有較高的訓練錯誤,從而導致測試錯誤。 ImageNet上的類似現象如圖4所示
訓練準確性的下降表明並非所有系統都同樣容易優化。 讓我們考慮一個較淺的體系結構及其更深的對應結構,它會在其上新增更多層。 通過構建更深層的模型,可以找到一種解決方案:新增的層是身份對映,而其他層是從學習的淺層模型中複製的。 該構造解決方案的存在表明,較深的模型不會比淺模型產生更高的訓練誤差。 但是實驗表明,我們現有的求解器無法找到比構造的解決方案好或更好的解決方案(或無法在可行的時間內找到解決方案)。
在本文中,我們通過引入深度殘差學習框架來解決退化問題。 而不是希望每個堆疊的層都直接適合所需的基礎對映,我們明確讓這些層適合殘差對映。 形式上,將所需的基礎對映表示爲,我們讓堆疊的非線性層適合的另一個對映。 原始對映將重鑄爲。 我們假設優化殘差對映比優化原始未參照對映要容易。 極端地,如果身份對映是最佳的,則將殘差推到零比通過非線性層堆疊擬合身份對映要容易。
公式可通過具有「快捷連線」的前饋神經網路來實現(圖2)。快捷連線是跳過一層或多層的連線。 在我們的情況下,快捷方式連線僅執行身份對映,並將其輸出新增到堆疊層的輸出中(圖2)。身份快捷方式連線既不增加額外的參數,也不增加計算複雜度。 整個網路仍然可以通過SGD反向傳播進行端到端訓練,並且可以使用通用庫(例如Caffe)輕鬆實現,而無需修改求解器。
我們在ImageNet上進行了全面的實驗,以顯示退化問題並評估我們的方法。 我們表明:1)我們極深的殘差網路很容易優化,但是當深度增加時,對應的「普通」網路(簡單地堆疊層)顯示出更高的訓練誤差; 2)我們的深層殘差網路可以通過大大增加深度來輕鬆享受精度提升,從而產生比以前的網路更好的結果。
CIFAR-10集上也顯示了類似的現象,這表明優化困難和我們方法的效果不僅類似於特定數據集。 我們在這個數據集上成功地訓練了100多個層的模型,並探索了1000多個層的模型。
在ImageNet分類數據集中,我們通過極深的殘差網路獲得了出色的結果。 我們的152層殘差網路是ImageNet上展示的最深的網路,同時其複雜度仍低於VGG網路。 我們的合奏在ImageNet測試集上的前5個錯誤的錯誤率爲3.57%,並在ILSVRC 2015分類競賽中獲得第一名。 極深的表示法在其他識別任務上也具有出色的泛化效能,使我們在ILSVRC和COCO 2015競賽中進一步贏得了第一名:ImageNet檢測,ImageNet在地化,COCO檢測和COCO細分。 有力的證據表明,殘差學習原理是通用的,我們希望它適用於其他視覺和非視覺問題。
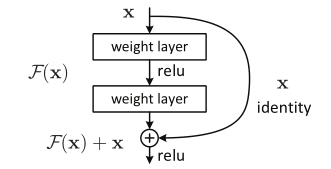
圖2. 殘差學習:構造塊
2. 相關工作
殘差表示。 在影象識別中,VLAD是通過相對於字典的殘差向量進行編碼的表示形式,Fisher Vector可以表示爲VLAD的概率版本。 它們都是用於影象檢索和分類的有力的淺層表示。 對於向量量化,編碼殘差向量顯示比編碼原始向量更有效。
在低階視覺和計算機圖學中,爲了求解偏微分方程(PDE),廣泛使用的Multigrid方法將系統重新構建爲多個尺度的子問題,其中每個子問題都負責較大和較小尺度之間的殘差解。 Multigrid的替代方法是分層基礎預處理,它依賴於表示兩個尺度之間殘差向量的變數。 已經表明,這些求解器的收斂速度比不知道解決方案剩餘性質的標準求解器快得多。 這些方法表明,良好的重構或預處理可以簡化優化過程。
**短路連線。**導致快捷連線的實踐和理論已經研究了很長時間。 訓練多層感知器(MLP)的早期實踐是新增從網路輸入連線到輸出的線性層。 在[44,24]中,一些中間層直接連線到輔助分類器,以解決消失/爆炸梯度。 [39,38,31,47]的論文提出了通過快捷連線實現對層響應,梯度和傳播誤差進行居中的方法。 在[44]中,「起始」層由快捷分支和一些更深的分支組成。
與我們的工作同時,「高速公路網路」提供具有選通功能的快捷連線。 與我們的不帶參數的身份快捷方式相反,這些門取決於數據並具有參數。 當封閉的快捷方式「關閉」(接近零)時,高速公路網路中的圖層表示非殘留功能。 相反,我們的公式總是學習殘差函數。 我們的身份快捷鍵永遠不會關閉,所有資訊始終都會通過傳遞,還需要學習其他殘餘功能。 另外,高速公路網路還沒有顯示出深度極大增加(例如,超過100層)的準確性。
3. 深度殘差學習
3.1 殘差學習
讓我們將視爲由一些堆疊層(不一定是整個網路)擬合的基礎對映,其中x表示這些層中的第一層的輸入。 如果假設多個非線性層可以漸近逼近複雜函數(但是,這個假設仍然是一個懸而未決的問題。 參見[28]),則等效於假設它們可以漸近逼近殘差函數,即(假設輸入和輸出的維數相同)。因此,我們沒有讓堆疊的層逼近,而是明確讓這些層逼近殘差函數。 因此,原始函數變爲。儘管兩種形式都應能夠漸近地逼近所需的函數(如假設),但學習的難易程度可能有所不同。
關於降級問題的反直覺現象促使這種重新形成(圖1,左)。 正如我們在導言中討論的那樣,如果可以將新增的層構造爲身份對映,則更深的模型的訓練誤差應不大於其較淺的對應部分。 退化問題表明,求解器可能難以通過多個非線性層來逼近身份對映。 通過殘差學習的重構,如果身份對映是最佳的,則求解器可以簡單地將多個非線性層的權重逼近零以逼近身份對映。
在實際情況下,身份對映不太可能是最佳的,但是我們的重新制定可能有助於解決問題。 如果最優函數比零對映更接近恆等對映,則求解器參考恆等對映來查詢擾動應該比學習新函數更容易。 我們通過實驗(圖7)表明,所學習的殘差函數通常具有較小的響應,這表明身份對映提供了合理的預處理。
3.2 通過短路方式進行身份對映
我們對每幾個堆疊的層採用殘差學習。構造塊如圖2所示。在形式上,在本文中,我們考慮定義爲:
這裏的和是所考慮層的輸入和輸出向量。函數表示要學習的殘差對映。對於圖2中具有兩層的範例,,其中表示ReLU,並且爲了簡化符號省略了偏置。操作通過短路連線和逐元素加法執行。在加法之後我們採用第二個非線性度(即,見圖2)。
公式(1)中的短路連線既沒有引入額外的參數,也沒有引入計算複雜性。 這不僅在實踐中具有吸引力,而且在我們比較普通網路和殘差網路時也很重要。 我們可以公平地比較同時具有相同數量的參數,深度,寬度和計算成本(除了可以忽略的逐元素加法)的普通/殘差網路。
x和F的維度在等式(1)中必須相等。 如果不是這種情況(例如,在更改輸入/輸出通道時),我們可以通過短路方式連線來執行線性投影以匹配尺寸:
我們也可以在等式(1)中使用平方矩陣。但是我們將通過實驗證明,身份對映足以解決降級問題並且很經濟,因此僅在匹配尺寸時使用。
殘差函數F的形式是靈活的。本文中的實驗涉及一個具有兩層或三層的函數F(圖5),而更多的層是可能的。 但是,如果F僅具有單層,則等式(1)類似於線性層:,對此我們沒有觀察到優點。
我們還注意到,儘管爲簡化起見,上述符號是關於全連線層的,但它們也適用於折積層。 函數可以表示多個折積層。在兩個功能圖上逐個通道執行逐元素加法。
3.3 網路架構
我們已經測試了各種平原/殘差網路,並觀察到了一致的現象。爲了提供討論範例,我們描述了ImageNet的兩個模型,如下所示。
普通網路。 我們簡單的基線(圖3,中間)主要受到VGG網路原理(圖3,左)的啓發。 折積層通常具有3×3的過濾器,並遵循兩個簡單的設計規則:(i)對於相同的輸出要素圖大小,這些層具有相同的過濾器數; (ii)如果特徵圖的大小減半,則過濾器的數量將增加一倍,以保持每層的時間複雜度。 我們直接通過步長爲2的折積層執行下採樣。網路以全域性平均池化層和帶有softmax的1000路全連線層結束。 圖3中的加重層總數爲34(中)。
值得注意的是,我們的模型比VGG網路具有更少的過濾器和更低的複雜度(圖3,左)。 我們的34層基準具有36億個FLOP(乘法加法),僅佔VGG-19(196億個FLOP)的18%。
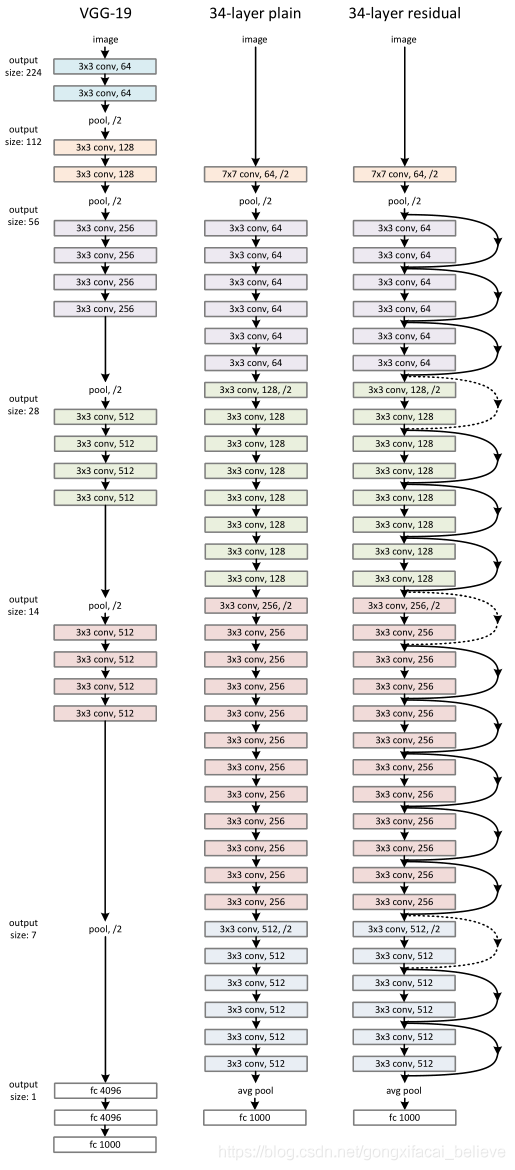
圖3. ImageNet的範例網路架構。 左:作爲參考的VGG-19模型(196億個FLOP)。 中:包含34個參數層(36億個FLOP)的普通網路。 右圖:一個具有34個參數層的殘差網路(36億個FLOP)。 虛線快捷方式會增加尺寸。 表1顯示了更多詳細資訊和其他變體
殘差網路。 在上面的普通網路的基礎上,我們插入快捷方式連線(圖3,右),將網路變成其對應的剩餘版本。 當輸入和輸出的尺寸相同時,可以直接使用標識快捷方式(等式(1))(圖3中的實線快捷方式)。 當維度增加時(圖3中的虛線快捷方式),我們考慮兩個選項:(A)快捷方式仍然執行身份對映,併爲增加維度填充了額外的零條目。 此選項不引入任何額外的參數。 (B)等式(2)中的投影快捷方式用於匹配尺寸(按1×1折積完成)。 對於這兩個選項,當快捷方式跨越兩種尺寸的特徵圖時,步幅爲2。
3.4 實現
我們對ImageNet的實現遵循[21,41]中的做法。 調整影象大小,並在[256,480]中隨機採樣其較短的一面以進行縮放。 從影象或其水平翻轉中隨機採樣224×224作物,並減去每畫素均值。 使用[21]中的標準色彩增強。 在每次折積之後和啓用之前,我們都採用批次歸一化(BN)[16]。 我們按照[13]中的方法初始化權重,並從頭開始訓練所有普通/殘差網路。 我們使用最小批次爲256的SGD。學習率從0.1開始,當誤差平穩時除以10,並且訓練模型的次數最多爲次迭代。 我們使用0.0001的權重衰減和0.9的動量。 按照[16]中的做法,我們不使用dropout。
在測試中,爲了進行比較研究,我們採用了標準的10種作物測試。 爲了獲得最佳結果,我們採用[41,13]中的全折積形式,並在多個尺度上平均分數(影象被調整大小,使得較短的邊在{224,256,384,480,640}中)。
4. 實驗
4.1 ImageNet影象分類
我們在包含1000個類的ImageNet 2012分類數據集中評估我們的方法。 在128萬張訓練影象上訓練模型,並在50k驗證影象上進行評估。 我們還將在測試伺服器報告的10萬張測試影象上獲得最終結果。我們評估了top-1和top-5的錯誤率。
普通網路。 我們首先評估18層和34層普通網。 34層普通網在圖3中(中)。 18層普通網具有類似的形式。 有關詳細架構,請參見表1。
表2中的結果表明,較深的34層普通網比較淺的18層普通網具有更高的驗證誤差。 爲了揭示原因,在圖4(左)中,我們比較了他們在訓練過程中的訓練/驗證錯誤。 我們已經觀察到退化問題-儘管18層普通網路的解決方案空間是34層普通網路的子空間,但在整個訓練過程中34層普通網路具有較高的訓練誤差。
我們認爲,這種優化困難不太可能是由消失的梯度引起的。 這些普通網路使用BN進行訓練,可確保前向傳播的信號具有非零的方差。 我們還驗證了向後傳播的梯度具有BN的健康規範。 因此,前進或後退信號都不會消失。 實際上,34層普通網路仍然可以達到競爭精度(表3),這表明求解器在某種程度上可以工作。 我們推測,深平原網路可能具有指數級的收斂速度,這會影響訓練誤差的降低(我們已經嘗試了更多的訓練迭代(3x),並且仍然觀察到了退化問題,這表明僅通過使用更多的迭代就無法解決該問題)。將來將研究這種優化困難的原因。
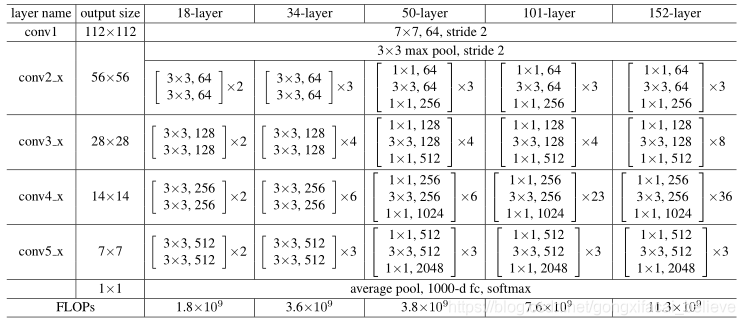
表1. ImageNet的體系結構。括號中顯示了構造塊(另請參見圖5),其中堆疊了許多塊。 下採樣由conv3_1,conv4_1和conv5_1執行,步長爲2
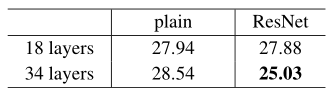
表2. ImageNet驗證中的前1個錯誤(%,10次裁剪測試)。ResNet與參照網路相比沒有額外的參數。圖4顯示了訓練過程
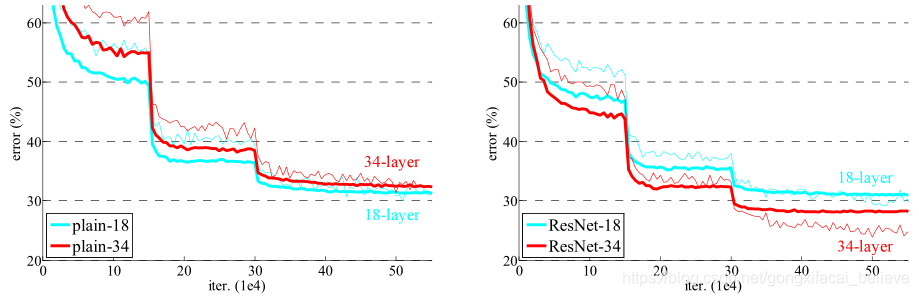
圖4. ImageNet訓練。 細曲線表示訓練誤差,粗曲線表示中心農作物的驗證誤差。 左:18和34層的普通網路。 右:18和34層的ResNet。 在該圖中,殘差網路與普通網路相比沒有額外的參數
殘差網路。 接下來,我們評估18層和34層殘差網路(ResNets)。 基線架構與上述普通網路相同,希望將快捷連線新增到圖3(右)中的每對3×3過濾器中。 在第一個比較中(右表2和圖4),我們將身份對映用於所有快捷方式,將零填充用於增加尺寸(選項A)。 因此,與普通副本相比,它們沒有額外的參數。
我們從表2和圖4中獲得了三個主要觀察結果。首先,這種情況通過殘差學習得以逆轉– 34層ResNet優於18層ResNet(降低了2.8%)。 更重要的是,34層ResNet表現出較低的訓練誤差,並且可以推廣到驗證數據。 這表明在這種情況下可以很好地解決退化問題,並且我們設法從增加的深度中獲得準確性的提高。
其次,與普通的相比,34層ResNet將top-1錯誤減少了3.5%(表2),這是由於成功減少了訓練錯誤(圖4右與左)。 這項比較驗證了殘留學習在極深系統上的有效性。
最後,我們還注意到18層普通/殘差網路比較準確(表2),但18層ResNet收斂更快(圖4右與左)。當網「不是太深」(此處爲18層)時,當前的SGD解算器仍然能夠爲純網找到良好的解決方案。 在這種情況下,ResNet通過在早期提供更快的收斂來簡化優化。
識別與投影短路。 我們已經證明,無參數的身份快捷方式有助於培訓。 接下來,我們研究投影快捷方式(等式(2))。 在表3中,我們比較了三個選項:(A)零填充快捷方式用於增加尺寸,並且所有快捷方式都是無參數的(與表2和右圖4相同); (B)投影快捷方式用於增加尺寸,其他快捷方式是標識。(C)所有快捷方式都是投影。
表3顯示,所有三個選項都比普通選項好得多。 B比A稍好。我們認爲這是因爲A中的零填充維確實沒有殘留學習。 C比B好一點,我們將其歸因於許多(十三)投影快捷方式引入的額外參數。 但是,A / B / C之間的細微差異表明,投影捷徑對於解決降級問題並不是必不可少的。 因此,在本文的其餘部分中,我們不會使用選項C來減少記憶體/時間的複雜性和模型大小。 身份快捷方式對於不增加下面 下麪介紹的瓶頸架構的複雜性特別重要。
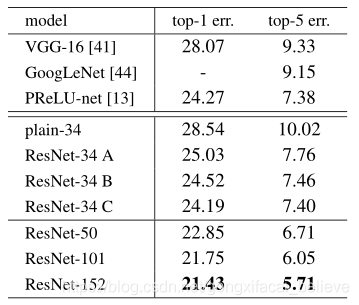
表3. ImageNet驗證的錯誤率(%,10次裁剪測試)。 VGG-16基於我們的測試。 ResNet-50 / 101/152是選項B的選項,僅使用投影來增加尺寸
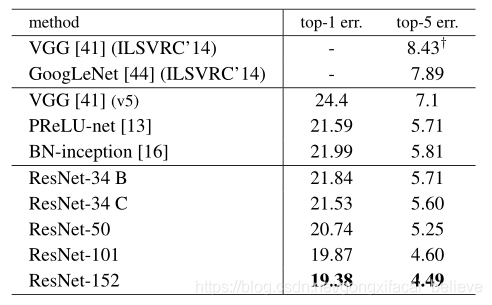
表4. ImageNet驗證集上單模型結果的錯誤率(%)(測試集上報告的除外)

表5. 錯誤率(%)。 前5個錯誤位於ImageNet的測試集中,並由測試伺服器報告
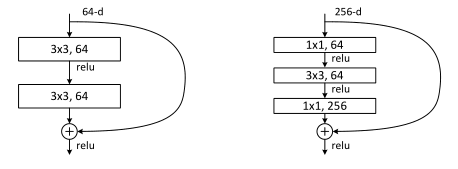
圖5. ImageNet的更深的殘差函數F。 左:ResNet-34的構造塊(在56×56特徵圖上),如圖3所示。右:ResNet-50 / 101/152的「瓶頸」構造塊
更深的瓶頸架構。 接下來,我們將介紹ImageNet的更深層網路。 由於擔心我們可以負擔得起的培訓時間,我們將構造塊修改爲瓶頸設計(更深的非瓶頸ResNets(例如,圖5左)也可以通過增加深度來獲得準確性(如CIFAR-10所示),但不如瓶頸ResNets經濟。 因此,瓶頸設計的使用主要是出於實際考慮。 我們進一步注意到,瓶頸設計也見證了普通網的退化問題)。對於每個殘差函數F,我們使用3層而不是2層的堆疊(圖5)。 這三層是1×1、3×3和1×1折積,其中1×1層負責減小然後增加(還原)尺寸,從而使3×3層成爲輸入/輸出尺寸較小的瓶頸 。 圖5顯示了一個範例,其中兩種設計都具有相似的時間複雜度。
無參數標識快捷方式對於瓶頸體系結構特別重要。 如果將圖5(右)中的身份快捷方式替換爲投影,則可以顯示時間複雜度和模型大小增加了一倍,因爲快捷方式連線到兩個高維端。 因此,身份快捷方式可以爲瓶頸設計提供更有效的模型。
**50層ResNet:**我們將3層瓶頸模組替換爲34層網路中的每個2層模組,從而得到50層ResNet(表1)。 我們使用選項B來增加尺寸。 該模型具有38億個FLOP。
101層和152層ResNet: 我們通過使用更多的3層塊來構建101層和152層ResNet(表1)。 值得注意的是,儘管深度顯着增加,但152層ResNet(113億個FLOP)的複雜度仍低於VGG-16 / 19網(153.96億個FLOP)。
50/101/152層ResNet比34層ResNet準確度高(表3和表4)。 我們沒有觀察到降級問題,因此深度的增加大大提高了精度。 所有評估指標都證明了深度的好處(表3和表4)。
與最新方法的比較。 在表4中,我們與以前的最佳單模型結果進行了比較。 我們的基準34層ResNet獲得了非常具有競爭力的準確性。 我們的152層ResNet的單模型top-5驗證錯誤爲4.49%。 該單模型結果優於所有之前的整體結果(表5)。 我們將六個不同深度的模型組合在一起,形成一個整體(提交時只有兩個152層模型)。 這導致測試集上3.5-5的top-5錯誤(表5)。該作品在ILSVRC 2015中獲得第一名。
4.2 CIFAR-10與分析
我們對CIFAR-10數據集進行了更多研究,該數據集包含10個類別的5萬個訓練影象和1萬個測試影象。 我們介紹在訓練集上訓練的實驗,並在測試集上進行評估。 我們的重點是極度深度的網路的行爲,而不是推動最先進的結果,因此我們有意使用瞭如下的簡單架構。
普通/殘留體系結構遵循圖3中的形式(中間/右側)。 網路輸入爲32×32影象,每畫素均值被減去。 第一層是3×3折積。 然後,我們分別在大小爲{32,16,8}的特徵圖上使用具有3×3折積的6n層堆疊,每個特徵圖尺寸爲2n層。 過濾器的數量分別爲{16,32,64}。 二次採樣通過步幅爲2的折積執行。網路以全域性平均池,10路全連線層和softmax結尾。 總共有6n + 2個堆疊的加權層。 下表總結了體系結構:
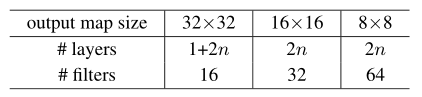
使用快捷方式連線時,它們連線到成對的3×3層對(總共3n個快捷方式)。 在此數據集上,我們在所有情況下都使用了身份快捷方式(即選項A),因此我們的殘差模型的深度,寬度和參數數量與普通模型完全相同。
我們使用0.0001的權重衰減和0.9的動量,並在[13]和BN中採用權重初始化,但是沒有丟失。 這些模型在兩個GPU上的最小批次爲128。 我們從0.1的學習率開始,在32k和48k迭代中將其除以10,然後在64k迭代中終止訓練,這是由45k / 5k的火車/ val分配決定的。 我們遵循[24]中的簡單數據增強進行訓練:在每側填充4個畫素,並從填充的影象或其水平翻轉中隨機採樣32×32的作物。 爲了進行測試,我們僅評估原始32×32影象的單個檢視。
我們比較n = {3,5,7,9},得出20、32、44和56層網路。 圖6(左)顯示了普通網路的行爲。 較深的平原網會增加深度,並且在深入時會表現出較高的訓練誤差。 這種現象類似於ImageNet(圖4,左)和MNIST(參見[42])上的現象,表明這種優化困難是一個基本問題。
圖6(中)顯示了ResNets的行爲。 同樣類似於ImageNet的情況(圖4,右),我們的ResNet設法克服了優化難題,並證明了深度增加時精度的提高。
我們進一步探索n = 18導致110層ResNet。 在這種情況下,我們發現初始學習速率0.1太大,無法開始收斂5。 因此,我們使用0.01來預熱訓練,直到訓練誤差低於80%(約400次迭代),然後返回0.1並繼續訓練。 其餘的學習時間表與之前一樣。 這個110層的網路可以很好地融合(圖6,中間)。 它的參數比其他深層和瘦網路(例如FitNet和Highway)(表6)少,但仍屬於最新結果(6.43%,表6)。
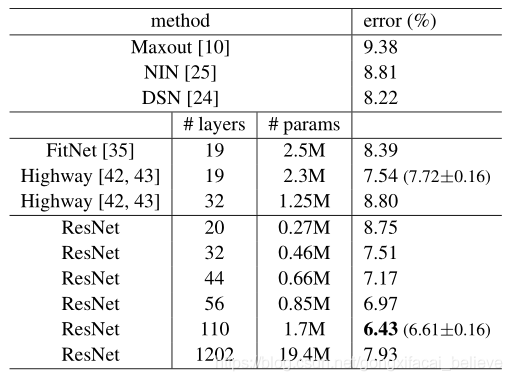
表6. CIFAR-10測試儀上的分類錯誤。 所有方法都具有數據增強功能。 對於ResNet-110,我們將其執行5次並顯示爲[best(mean±std)」,如[43]所示
響應層分析。 圖7顯示了層響應的標準偏差(std)。 響應是BN之後以及其他非線性(ReLU /加法)之前每個3×3層的輸出。 對於ResNet,此分析揭示了殘差函數的響應強度。 圖7顯示ResNet的響應通常比普通響應小。 這些結果支援我們的基本動機(第3.1節),即與非殘差函數相比,殘差函數通常可能更接近於零。 我們還注意到,更深的ResNet具有較小的響應幅度,如圖7中ResNet-20、56和110的比較所證明的。當有更多層時,ResNets的單個層往往會較少地修改信號。
探索超過1000層。 我們探索了一個超過1000層的深度模型。 我們將n設定爲200,這將導致1202層網路的執行,如上所述。 我們的方法沒有優化困難,該層網路能夠實現訓練誤差<0.1%(圖6,右)。其測試誤差仍然相當不錯(7.93%,表6)。
但是,在如此積極的深度模型上仍然存在未解決的問題。 儘管這兩個1202層網路的訓練誤差相似,但它們的測試結果卻比我們的110層網路的測試結果差。 我們認爲這是由於過度擬合。 對於這個小的數據集,1202層網路可能會不必要地大(19.4M)。 應用強正則化(例如maxout或dropout)以在此數據集上獲得最佳結果([10、25、24、35])。 在本文中,我們不使用maxout / dropout,而只是通過設計通過深度和精簡架構強加正則化,而不會分散對優化困難的關注。 但是,結合更強的正則化可能會改善結果,我們將在以後進行研究。
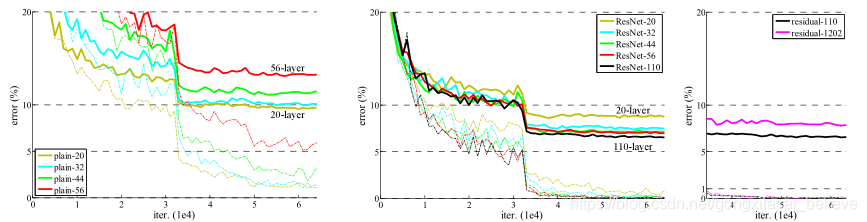
圖6. 在CIFAR-10上的訓練。 虛線表示訓練錯誤,而粗線表示測試錯誤。 左:普通網路。 Plain-110的錯誤高於60%,並且不顯示。 中:ResNets。 右:具有110和1202層的ResNet
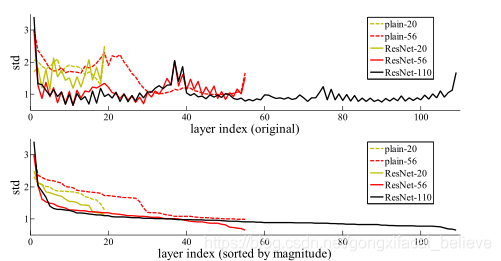
圖7. CIFAR-10上層響應的標準偏差(std)。 響應是BN之後和非線性之前每個3×3層的輸出。 頂部:圖層以其原始順序顯示。 下:響應按降序排列
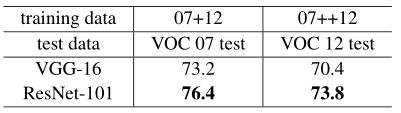
表7. 使用基準Faster R-CNN在PASCAL VOC 2007/2012測試集中進行的物件檢測mAP(%)。 另請參見表10和11,以獲得更好的結果

表8. 使用基線Faster R-CNN在COCO驗證集上進行的物件檢測mAP(%)。 另請參見表9,以獲得更好的結果
4.3 PASCAL和MS COCO上的目標檢測
我們的方法在其他識別任務上具有良好的泛化效能。 表7和8顯示了PASCAL VOC 2007和2012以及COCO上的物件檢測基準結果。 我們採用Faster R-CNN作爲檢測方法。 在這裏,我們對用ResNet-101替換VGG-16的改進感興趣。 使用這兩種模型的檢測實現方式(請參閱附錄)是相同的,因此只能將收益歸因於更好的網路。 最值得注意的是,在具有挑戰性的COCO數據集上,我們的COCO標準指標(mAP @ [.5,.95])增加了6.0%,相對提高了28%。 該收益完全歸因於所學的表示。
基於深層殘差網路,我們在ILSVRC和COCO 2015競賽的多個賽道上均獲得了第一名:ImageNet檢測,ImageNet在地化,COCO檢測和COCO分割。 詳細資訊在附錄中。

A. 目標檢測基線
在本節中,我們介紹基於基線Faster R-CNN系統的檢測方法。 這些模型由ImageNet分類模型初始化,然後根據目標檢測數據進行微調。 在ILSVRC和COCO 2015檢測競賽時,我們已經對ResNet-50 / 101進行了試驗。
與[32]中使用的VGG-16不同,我們的ResNet沒有隱藏的fc層。 我們採用「 Conv特徵圖上的網路」(NoC)的思想來解決此問題。 我們使用影象上的步幅不大於16個畫素的圖層(即conv1,conv2_x,conv3_x和conv4_x,在ResNet-101中總共91個conv圖層;表1)計算全影象共用conv特徵圖。 我們認爲這些層類似於VGG-16中的13個conv層,這樣做,ResNet和VGG-16都具有相同總步幅(16畫素)的conv特徵圖。 這些層由區域提議網路(RPN,生成300個提議)和快速R-CNN檢測網路共用。 RoI池在conv5_1之前執行。 在此RoI合併功能中,每個區域都採用了conv5_x和up的所有層,起到了VGG-16的fc層的作用。 最終的分類層被兩個同級層替代(分類和框迴歸)。
對於BN層的使用,在預訓練之後,我們爲ImageNet訓練集上的每個層計算BN統計資訊(均值和方差)。 然後在微調過程中將BN層固定以進行物件檢測。 這樣,BN層變爲具有恆定偏移量和比例的線性啓用,並且不會通過微調更新BN統計資訊。 我們修復BN層主要是爲了減少Faster R-CNN訓練中的記憶體消耗。
PASCAL VOC
按照[7,32],對於PASCAL VOC 2007測試集,我們使用VOC 2007中的5k火車影象和VOC 2012中的16k火車影象進行訓練(「 07 + 12」)。 對於PASCAL VOC 2012測試集,我們使用VOC 2007中的10k trainval + test影象和VOC 2012中的16k trainval影象進行訓練(「 07 ++ 12」)。 用於訓練Faster R-CNN的超參數與[32]中的相同。 表7示出了結果。 與VGG-16相比,ResNet-101將mAP改善了3%以上。 這一收益完全是由於ResNet學會了改進的功能。
MS COCO
MS COCO數據集[26]涉及80個物件類別。 我們評估了PASCAL VOC指標(mAP @ IoU = 0.5)和標準COCO指標(mAP @ IoU = .5:.05:.95)。 我們將火車上的80k影象用於訓練,將val上的40k影象用於評估。 我們的COCO檢測系統與PASCAL VOC相似。 我們使用8-GPU實現訓練COCO模型,因此RPN步驟的最小批次大小爲8張影象(即每個GPU 1個),而Fast R-CNN步驟的最小批次大小爲16張影象。 RPN步驟和Fast R-CNN步驟均以0.001的學習率進行240k迭代的訓練,然後以0.0001進行80k迭代的訓練。
表8顯示了MS COCO驗證集的結果。 ResNet-101的mAP @ [。5,.95]比VGG-16增加了6%,相對改善了28%,這完全歸功於更好的網路所瞭解的功能。 值得注意的是,mAP @ [。5,.95]的絕對增長(6.0%)與mAP @ .5的絕對增長(6.9%)差不多。 這表明更深的網路可以同時提高識別能力和定位能力。
B. 目標檢測的改進
爲了完整起見,我們報告了比賽的改進。 這些改進基於深層功能,因此應該從殘差學習中受益。
MS COCO
盒子精修。 我們的盒子精煉部分遵循[6]中的迭代定位。 在Faster R-CNN中,最終輸出是一個迴歸框,不同於其提案框。 因此,爲了進行推斷,我們從迴歸框中合併了一個新功能,並獲得了新的分類得分和新的迴歸框中。 我們將這300個新的預測與原始的300個預測結合在一起。 使用IoU閾值0.3將非最大抑制(NMS)應用於預測框的並集,然後進行框投票。 盒子精修可將mAP提高約2個點(表9)。
全域性環境。 我們在快速R-CNN步驟中結合了全域性上下文。 給定完整影象的轉換特徵圖,我們通過全域性空間金字塔池(帶有「單級」金字塔)對特徵進行池化,可以使用整個影象的邊界框作爲RoI來實現爲「 RoI」池。 將此合併的功能饋入後RoI層以獲得全域性上下文功能。 此全域性特徵與原始的按區域特徵連線在一起,然後是同級分類和框迴歸圖層。 這種新結構經過端到端的培訓。 全域性環境將mAP @ .5提高了約1個點(表9)。
多尺度測試。 在上面,所有結果都是通過[32]中的單尺度訓練/測試獲得的,其中影象的短邊是s = 600畫素。 在[12,7]中通過從要素金字塔中選擇比例來開發多尺度訓練/測試,在[33]中通過使用maxout層來開發多尺度訓練/測試。 在我們當前的實現中,我們根據[33]進行了多尺度測試; 由於時間有限,我們尚未進行多尺度培訓。 此外,我們僅針對Fast R-CNN步驟(但尚未針對RPN步驟)執行多尺度測試。 通過訓練有素的模型,我們可以在影象金字塔上計算出conv特徵圖,其中影象的短邊爲s∈{200,400,600,800,1000}。 我們從[33]之後的金字塔中選擇兩個相鄰的比例尺。 RoI池和後續層在這兩個比例尺的特徵圖上執行,並由maxout合併,如[33]中所述。 多尺度測試將mAP提高了2個百分點(表9)。
使用驗證數據。 接下來,我們使用80k + 40k trainval集進行訓練,並使用20k test-dev集進行評估。 測試開發集沒有公開可用的基礎事實,結果由評估伺服器報告。 在此設定下,結果的mAP @ .5爲55.7%,mAP @ [。5,.95]爲34.9%(表9)。 這是我們的單模型結果。
整合。 在Faster R-CNN中,該系統旨在學習區域建議以及物件分類器,因此可以使用整合來完成這兩項任務。 我們使用整體建議區域,建議的聯合集由按區域分類的整體處理。 表9顯示了基於3個網路的合計結果。 在測試開發集上,mAP分別爲59.0%和37.4%。 該結果在COCO 2015的檢測任務中獲得了第一名。
PASCAL VOC
我們基於上述模型重新存取PASCAL VOC數據集。 使用COCO數據集上的單個模型(表9中的55.7%mAP @ .5),我們可以在PASCAL VOC集上微調該模型。 盒子改進,上下文和多尺度測試的改進也被採用。 這樣一來,我們在PASCAL VOC 2007(表10)和PASCAL VOC 2012(表11)上實現了85.6%的mAP(http://host.robots.ox.ac.uk:8080/anonymous/3OJ4OJ.html,
提交於2015-11-26)。PASCAL VOC 2012的結果比以前的最新結果高10點。
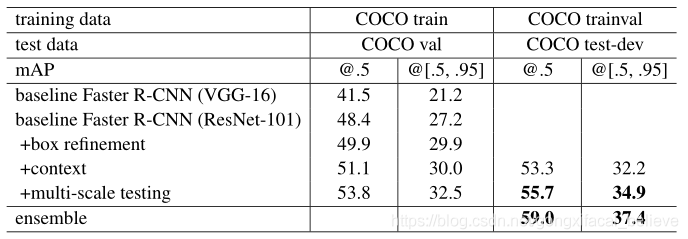
表9. 使用Faster R-CNN和ResNet-101在MS COCO上的目標檢測改進

表10. PASCAL VOC 2007測試集的檢測結果。 基線是Faster R-CNN系統。 表9中的「基準+++」系統包括框優化,上下文和多尺度測試

表11. 在PASCAL VOC 2012測試集上的檢測結果(http://host.robots.ox.ac.uk:8080/leaderboard/displaylb.php?challengeid=11&compid=4)。 基線是Faster R-CNN系統。 表9中的「基準+++」系統包括框優化,上下文和多尺度測試

表12. 我們在ImageNet檢測數據集上的結果(mAP,%)。 我們的檢測系統是Faster R-CNN,使用ResNet-101進行了表9的改進
ImageNet檢測
ImageNet檢測(DET)任務涉及200個物件類別。 精度由mAP @ .5評估。 我們針對ImageNet DET的物件檢測演算法與表9中針對MS COCO的物件檢測演算法相同。網路在1000類ImageNet分類集上進行了預訓練,並在DET數據上進行了微調。 在[8]之後,我們將驗證集分爲兩部分(val1 / val2)。 我們使用DET訓練集和val1集微調檢測模型。 val2集用於驗證。 我們不會使用其他ILSVRC 2015數據。 我們使用ResNet-101的單個模型具有58.8%的mAP,而我們的3個模型的集合在DET測試集上具有62.1%的mAP(表12)。 該結果在ILSVRC 2015的ImageNet檢測任務中獲得了第一名,以8.5點(絕對值)超過了第二名。
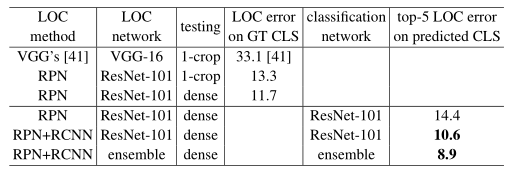
表13. ImageNet驗證上的在地化錯誤(%)。 在「 GT類的LOC錯誤」列中,使用了地面真實性類。 在「測試」列中,「 1-crop」表示對224×224畫素的中心作物進行測試,「 dense」表示密集(完全折積)和多尺度測試
C. ImageNet在地化
ImageNet在地化(LOC)任務需要對物件進行分類和在地化。 [40,41]之後,我們假設首先採用影象級分類器來預測影象的類別標籤,而定位演算法僅根據預測的類別來說明邊界框的預測。 我們採用「每班級迴歸」(PCR)策略,爲每個班級學習邊界框迴歸器。 我們預訓練網路以進行ImageNet分類,然後對其進行微調以進行在地化。 我們在提供的1000級ImageNet訓練集中訓練網路。
我們的定位演算法基於[32]的RPN框架,並做了一些修改。 與[32]中的與類別無關的方法不同,我們的在地化RPN是按類設計的。 該RPN以兩個同級1×1折積層結束,用於二進制分類(cls)和框迴歸(reg),如[32]所示。 與[32]相反,cls和reg層都屬於每個類。 具體來說,cls層具有1000-d輸出,並且每個維度都是用於預測是否爲物件類的二進制邏輯迴歸。 reg層具有1000×4-d輸出,該輸出由1000類的框式迴歸組成。 如[32],我們的邊界框迴歸是在每個位置參考多個平移不變的「錨」框。
與我們的ImageNet分類訓練(第3.4節)一樣,我們隨機抽取224×224種作物進行數據增強。 我們使用256幅影象的小批次大小進行微調。 爲避免負樣本佔主導地位,每個影象隨機採樣8個錨點,其中採樣的正錨點和負錨點的比例爲1:1。 爲了進行測試,將網路完全折積地應用到影象上。
表13比較了在地化結果。 繼[41]之後,我們首先使用地面真理類作爲分類預測來執行「 oracle」測試。 VGG的論文使用地面實況類報告了33.1%的中心裁剪誤差(表13)。 在相同的設定下,我們使用ResNet-101 net的RPN方法將中心裁切誤差顯着降低到13.3%。 此比較證明了我們框架的出色效能。 通過密集(完全折積)和多尺度測試,我們的ResNet-101使用地面真理類的錯誤率爲11.7%。 使用ResNet-101預測類別(前5名分類錯誤爲4.6%,表4),前5名在地化錯誤爲14.4%。
以上結果僅基於Faster R-CNN中的提案網路(RPN)。 可以在Faster R-CNN中使用檢測網路(Fast R-CNN)來改善結果。 但是我們注意到,在該數據集上,一張影象通常只包含一個主要物件,並且投標區域彼此高度重疊,因此具有非常相似的RoI合併特徵。 結果,Fast R-CNN的以影象爲中心的訓練會生成小變化的樣本,這對於隨機訓練而言可能是不希望的。 因此,在我們當前的實驗中,我們使用以RoI爲中心的原始R-CNN代替了Fast R-CNN。
我們的R-CNN實現如下。 我們在訓練影象上應用如上訓練的每類RPN,以預測地面實況類的邊界框。 這些預測框起着與類有關的提議的作用。 對於每個訓練影象,將獲得最高評分的200個建議作爲訓練樣本,以訓練R-CNN分類器。 影象區域從提案中裁剪出來,變形爲224×224畫素,然後像R-CNN中一樣輸入到分類網路中。 該網路的輸出由cls和reg的兩個同級fc層組成,也是每類的形式。 該R-CNN網路在訓練集上進行了微調,使用以RoI爲中心的256的小批次大小。 爲了進行測試,RPN爲每個預測的課程生成得分最高的200個建議,並且R-CNN網路用於更新這些建議的分數和方框位置。
此方法將前5位的定位錯誤降低到10.6%(表13)。 這是我們在驗證集上的單模型結果。 使用網路整合進行分類和在地化,我們在測試集上實現了9.0%的top-5在地化誤差。 該數位明顯優於ILSVRC 14結果(表14),相對誤差降低了64%。 該結果在ILSVRC 2015的ImageNet在地化任務中獲得了第一名。