R4C: A Benchmark for Evaluating RC Systems to Get the Right Answer for the Right Reason

Motivation
文章的目的是希望評估一個RC系統的內部推理,即用一種更細粒度方式體現模型確實在推理。(相比較一些datasets通過預測supporting facts來體現模型推理能力)
對於之前的一些datasets,比如經常以who開頭的提問,模型學習之後往往會從一些人名中選擇答案。這種啓發式的規則容易帶來一些bias,而模型是否真正理解了原文,我們無從得知。
另一個問題,作者提到結合多源的infos is not always necessay,其實這一點我保留懷疑,對於某些開放域的問題,多源資訊或者多文件還是比較需要的,怎麼利用,什麼時候利用,如何利用都是值得探討的問題。
最近這種hot pot QA其實也存在一些weakness。
1, 通過標籤訓練讓模型學會找到和問題相關的證據,但是從人類認知角度,並不能完全說明預測正確即推理正確。
2, 並不是所有的SFs都有助於推理,即某一個SF可能還包含其他無用資訊。如圖1。比如第一句話,
「Return to Olympus is the only album by the alternative rock band Malfunkshun 」其實包含了兩個資訊,對於Return to Olympus is the only album這個點來說,在推理的過程中是無用的,所以即使預測對了SFs,也不能很好證明模型真正在推理。
所以可不可以細化呢?
這篇文章的貢獻:
1, 以一種更細密度的方式去體現模型的推理能力。
2, 論文提出了一種新的數據,對每一個支撐實時提供了落幹個 Derivation。
3, 公開了一個衆包的框架。(就是提供了一個衆包平臺,可以對現存的數據集標註。不是討論的重點,就不細說了)
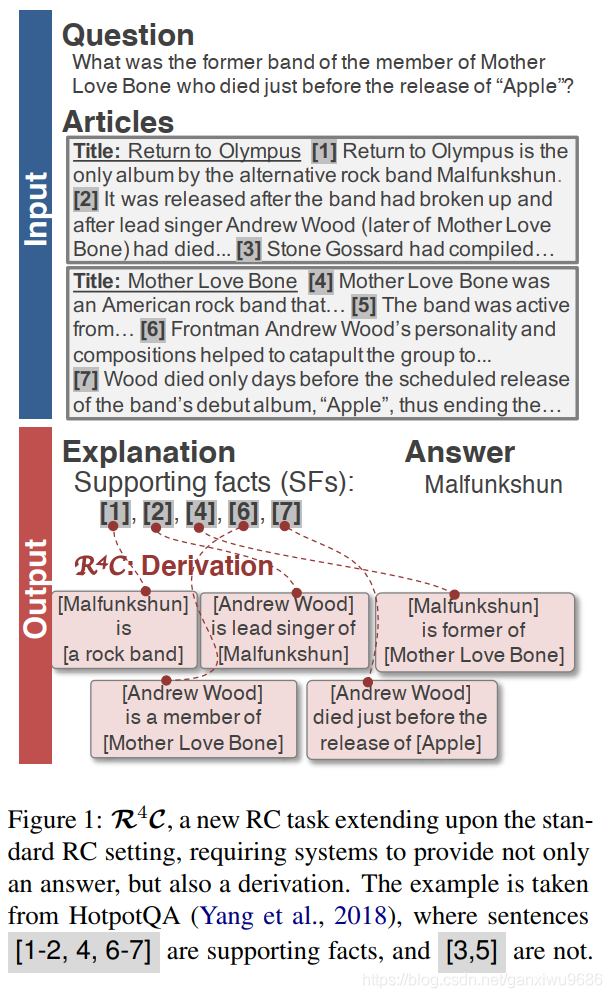
Task definition
這一部分介紹的是,通過什麼樣的形式進行推理。也就是細化到什麼程度,用什麼樣的結構表示推理的過程。
論文使用一種半結構化的form,具體來說:
Each derivation step di is defined as a relational fact, i.e. di ≡ dh i ; dr i ; dt i, where dh i , dt i are entities (noun phrases), and dr i is a verb phrase representing a relationship between dt i and dh i
類似知識圖譜裏面的三元組,比如圖1所示的那些,但是關係又不是那麼嚴格。

Note:這些derivation 中的元素是否一定會出現在文中呢?
不是的,比如leader singer of,這也就給模型輸出的derivation 不做限制,那麼怎麼取生成或者抽取derivation 是一個值得思考的問題。
Evaluation metrics
直接上圖好理解一點,文章是先介紹公式,再說如何計算,當時看的有點暈。
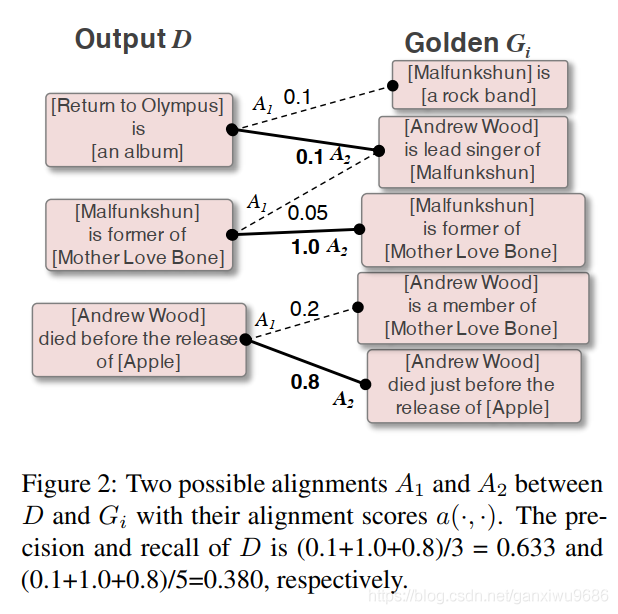
這裏就可以簡單看成兩個部分,一部分是模型輸出的output D,一部分是gold G。我們會通過各種排列組合A計算兩兩之間的相似性a(d, g)。直到滿足下列公式:
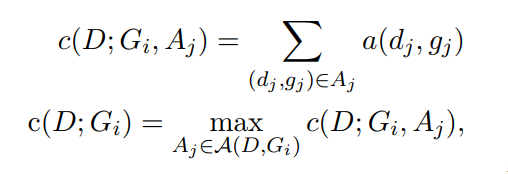
接下來我們就可以根據得到的打分,求得P,R,F,圖2也給了計算的例子:
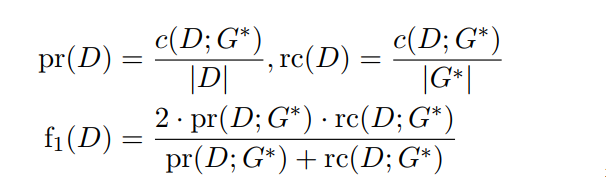
論文給出了三種計算得分的方式,其中的s文章使用 normalized Levenshtein distance :
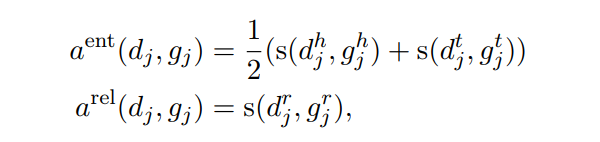
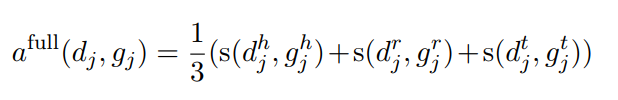
Data collection
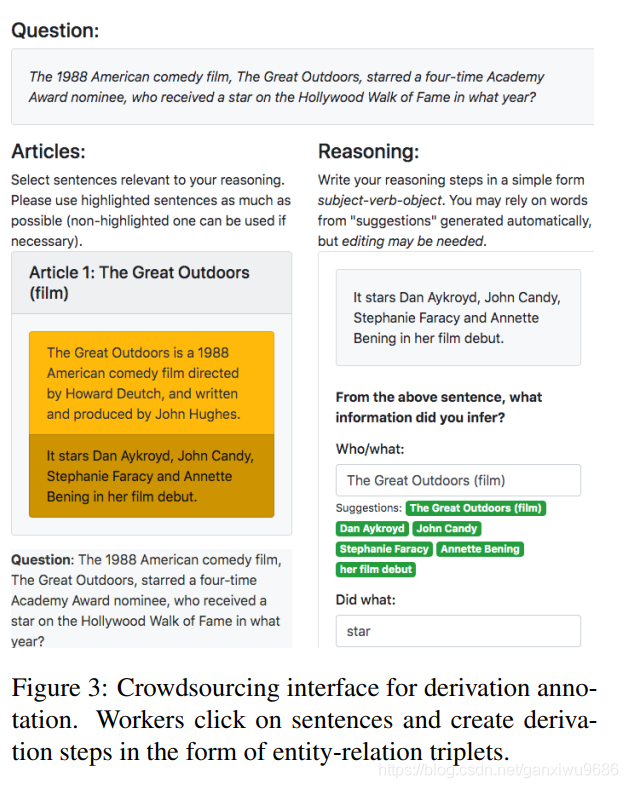
這個圖主要描述的是衆籌的一個介面。會提供一個問題一篇文章,以及裏面的一些SFs。對那些標註的人員要求他們首先能夠回答出問題,當然我們會給幾個答案的選項提供參考。對於一些錯誤的數據集可以不回答(少數)。另外對於每一個支撐事實,都要求標註者從當前的SF裏面選出對應的實體,或者短語,以及他們之間的動詞關係。最終我們對於每個問題提供了三個Derivation。
Results
這個表比較好理解:
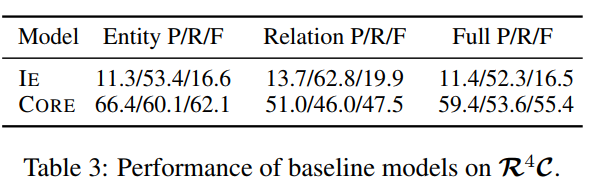
首先對於這個基線的實驗結果。IE表示的是從支撐事實裏面去抽取所有的實體以及它們的關係。CORE,表示的是從中抽取一些關鍵的資訊。(,這裏可能是拿問題的資訊對這些資訊做了一個匹配或者融合的方法吧),可以看到兩個baseline在不同的打分函數下的評價指標。
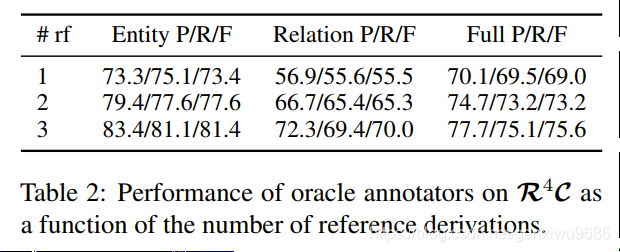
這個表我理解了一部分,縱向來看:
對於第2個實驗是想說明隨着給定的參考Derivation,數量越來越多,效果會越來越好。因爲標註的數據集裏面只提供了三個,所以這個地方的是三個的結果最好。
不知道四個會怎麼樣。哈哈
Question:
不過不太清楚這是誰和誰計算的指標,也就是D和G分別是什麼?貼出原文

Sum up
總的來說,這篇文章的目的是希望評估一個RC系統的內部推理,即用一種更細粒度方式體現模型確實在推理。他給出了一個推理的特定的形式,而不是像之前的數據集只給一些SFs。SF prediction,感覺就是個預測,並不是真正的推理。
每天努力一點點,生活進步一點點!大家晚安!^ - ^