Java—檔案I/O操作
大多數的應用程式都需要與外部的輸入/輸出裝置I/O(Input/Output)進行數據交換。在Java中,所有的I/O機制 機製都是基於數據「流」方式進行輸入/輸出。這些「數據流」可視爲同一臺計算機不同裝置或網路中不同計算機之間流動的數據序列。如同水管裡的水流一樣,在水管的一端一點一滴地供水,而在水管的另一端看到的是一股連續不斷的水流。
Java把這些不同來源和目標的數據統一抽象爲「數據流」。當Java程式需要讀取數據時,就會開啓一個通向數據源的流,這個數據源可以是檔案、記憶體、也可以是網路連線。而當Java程式需要寫入數據時,也會開啓一個通向目的地的流,這時,數據就可以想象爲管道中「按需流動的水」。流爲操作各種物理裝置提供了一致的介面。通過開啓操作將流關聯到檔案,通過關閉流操作將流和檔案解除關聯。
這些流序列中的數據通常有兩種形式:文字流和二進制流。文字流每一個位元組存放一個ASCII碼,代表一個字元(而對於Unicode編碼來說,每兩個位元組表示一個字元)。使用文字流時,可能會發生一些字元型轉換。例如,在windows操作系統中,當輸出換行字元的時候,它可以被轉換爲回車和換行序列。二進制流,也稱位元組流,它是把數據按其記憶體中儲存的以位元組形式「原封不動」地輸出或儲存。兩者的區別與聯繫可以用下面 下麪的例子(以ASCII碼爲例)來說明。的區別與聯繫可以用下面 下麪的例子(以ASCII碼爲例)來說明。例如,有一個整型數12345,其在記憶體當中僅需要2個位元組,由於系統爲整型數據分配4個位元組,所以其高位兩個位元組均爲0,而按文字流形式輸出則佔用5個位元組,分別是「12345」這5個字元對應的ASCII碼,如圖下所示。
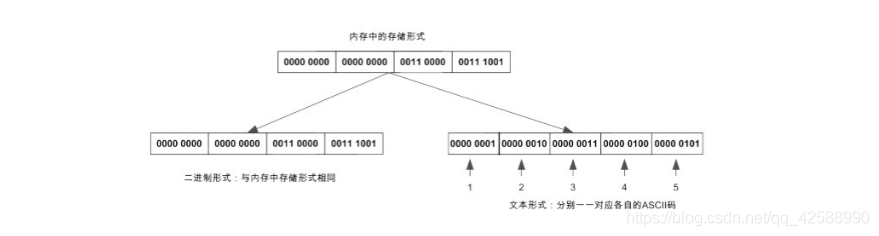
文字流形式與字元一一對應,因而便於對字元進行逐個處理,也便於輸出顯示,但一般佔用較多的記憶體空間,且花費較多的轉化時間(二進制形式與編碼之間的轉換)。需要注意的是,在Java中使用的是Unicode編碼,這是一種定長編碼,每個字元都是2位元組,因此在儲存ASCII碼時會額外浪費一個位元組的空間。
而用二進制形式輸出數值,可以節省外存空間和轉化時間,但一個位元組並不對應一個字元,不能直接輸出字元形式。兩種形式各有其優缺點,一般來講,對於純文字資訊(比如說字串),以文字形式儲存較佳;而對於數值資訊,則用二進制形式較好。
I/O流的優勢在於簡單易用,缺點是效率較低。Java的I/O流提供了讀寫數據的標準方法。Java語言中定義了許多類專門負責各種方式的輸入/輸出,這些類都被放在java.io包中。在Java類庫中,有關I/O操作的內容非常龐大:有標準輸入/輸出、檔案的操作、網路上的數據流、字串流和物件流等。
檔案操作類——File
儘管包java.io中定義的大多數類是對數據實施流式操作的,但File類例外,它用於處理檔案和檔案系統。也就是說,File類沒有指定數據怎樣從檔案讀取或向檔案儲存,它僅僅描述了檔案本身的屬性。
在java.io包之中,File類是唯一一個與檔案本身有關的操作類。它定義了一些與平臺無關的方法來操作檔案,通過呼叫File類提供的各種方法,能夠完成建立、刪除檔案,重新命名檔案,判斷檔案的讀寫許可權及檔案是否存在,設定和查詢檔案建立時間、許可權等操作。File類除了對檔案操作外,還可以將目錄當作檔案進行處理——Java中的目錄當成File物件對待。
如果要想使用File類進行操作,那麼就必須設定一個要操作檔案的路徑。下面 下麪的3個構造方法可以用來生成File物件。

在這裏,「directoryPath」表示的是檔案的路徑名,filename 是檔名,而dirObj 是一個指定目錄的File物件。
下面 下麪的例子分別用上面的3個構造方法建立了三個檔案物件:F1,F2和F3。物件F1是由僅有一個目錄路徑參數的構造方法生成的。F2是由兩個參數——路徑和檔名的構造方法生成的。第三個File物件F3的參數包括指向檔案F1的路徑及檔名。事實上,F3和F2指向相同的檔案——在根目錄(/)下的檔案abc.txt。

Java 能正確處理UNIX和Windows/DOS約定路徑分隔符。如果在Windows版本的Java下用斜線(/),路徑處理依然正確。請注意:如果在Windows/DOS下使用反斜線(\)來作爲路徑分隔符,那麼就需要在字串內使用它的跳脫序列(即兩個反斜線「\」)。Java約定是用UNIX和URL風格的斜線「/」來作路徑分隔符。
File類中定義了很多獲取File物件標準屬性的方法。例如getName( )用於返迴檔名,getParent( )返回父目錄名;exists( )方法在檔案存在的情況下返回true,反之返回false。但File類的方法是不對稱的,意思是說雖然存在可以驗證一個簡單檔案物件屬性的很多方法,但是沒有相應的方法來改變這些屬性。下表給出了部分常用的File類方法。

下面 下麪的例子演示了File類的幾個方法的使用。
File方法的使用(FileDemo.java)。



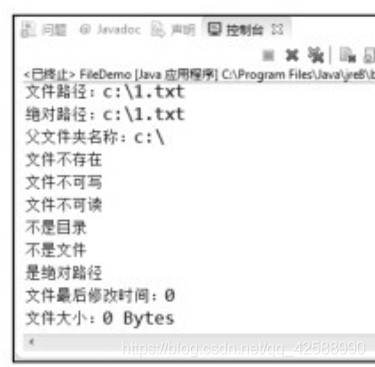
第06行,呼叫File的構造方法來建立一個File類物件f。其中第06行中路徑的分隔符用兩個「\」表示跳脫字元,這一句完全可用下面 下麪的語句代替。

07~17行來判斷檔案是否已經存在,若已經存在,則刪除之。如果不存在,則建立之,爲了防止建立過程中發生意外,用了try-catch塊來捕獲異常。18~42行對檔案的屬性進行了操作,註釋部分已經非常清楚地解釋了。
在File類中還有許多的方法,讀者沒有必要去死記這些用法,只要記住在需要的時候去查Java的API手冊就可以了。
File類只能對檔案進行一些簡單操作,如讀取檔案的屬性以及建立、刪除和更名等,但並不支援檔案內容的讀/寫。如果想對檔案進行實施讀寫操作,就必須通過輸入/輸出流來達到這一目的。
以上的程式完成了檔案的基本操作,但是在本操作之中可以發現如下的問題。
問題一:在進行操作的時候出現了延遲,因爲檔案的管理肯定還是由操作系統完成的,那麼程式通過JVM(Java虛擬機器)與操作系統進行操作,多了一層操作,所以勢必會產生一定的延遲。
問題二:在Windows之中路徑的分隔符使用「\」,而在Linux中分隔符使用「/」,而現在Java程式如果要想讓其具備可移植性,就必須考慮分隔符的問題,所以爲了解決這樣的困難,在File類中提供了一個常數:public static final Stringseparator。

在日後的開發之中,只要遇見路徑分隔符的問題,都可用separator常數來解決。
問題三:以上的程式是直接在D槽的根路徑下建立的新檔案,如果說現在有目錄的時候就發現無法直接建立檔案了,因爲檔案目錄不存在,要想建立檔案之前首先要先建立目錄。
建立一級目錄:public boolean mkdir();
建立多級目錄:public boolean mkdirs();
而如果要想建立目錄應該是根據給定路徑的父路徑纔可以建立,所以要想取得父路徑可以使用如下方法。
取得父路徑:public File getParentFile();
程式碼如下所示。
除了以上檔案的基本操作之外,在File類之中也提供了一些取得檔案資訊的方法,如下所示。
⑴ 判斷路徑是否是檔案:public boolean isFile()。
⑵ 判斷路徑是否是資料夾:public boolean isDirectory()。
⑶ 檔案大小:public long length()。
⑷ 取得檔案的最後一次修改日期:public long lastModified()。
RandomAccessFile類
除了File類之外,Java還提供了專門處理檔案的類,即RandomAccessFile(隨機存取檔案)類。該類是Java語言中功能最爲豐富的檔案存取類,它提供了衆多的檔案存取方法。RandomAccessFile類支援「隨機存取」方式,這裏「隨機」是指可以跳轉到檔案的任意位置處讀寫數據。在存取一個檔案的時候,不必把檔案從頭讀到尾,而是希望像存取一個數據庫一樣「隨心所欲」地存取一個檔案的某個部分,這時使用RandomAccessFile類就是最佳選擇。
RandomAccessFile物件類有個位置指示器,指向當前讀寫處的位置,當讀寫n個位元組後,檔案指示器將指向這n個位元組後面的下一個位元組處。剛開啓檔案時,檔案指示器指向檔案的開頭處,可以移動檔案指示器到新的位置,隨後的讀寫操作將從新的位置開始。RandomAccessFile類在數據等長記錄格式檔案的隨機(相對順序而言)讀取時有很大的優勢,但該類僅限於操作檔案,不能存取其他的IO裝置,如網路、記憶體映像等。RandomAccessFile類的構造方法如下所示。

這兩個構造方法均涉及到一個String型別的參數mode,它決定隨機儲存檔案流的操作模式,下表列出了mode的值及對應的含義。

有關RandomAccessFile類中的成員方法及使用說明請讀者參閱Java的JDK開放文件(http://docs.oracle.com/javase/8/docs/api/index.html)。下 面 是 一 個使 用 RandomAccessFile 的 例子,往檔案中寫入3名員工的資訊,然後按照第2名員工、第1名員工、第3名員工的先後順序讀出。RandomAccessFile可以以只讀或讀寫方式開啓檔案,具體使用哪種方式取決於使用者建立RandomAccessFile類物件的構造方法。

提示
當程式需要以讀寫的方式開啓一個檔案時,如果這個檔案不存在,程式會自動建立此檔案。
這裏還需要設計一個類來封裝員工資訊。一個員工資訊就是檔案中的一條記錄,而且必須保證每條記錄在檔案中的大小相同,也就是每個員工的姓名欄位在檔案中的長度是一樣的,這樣才能 纔能夠準確定位每條記錄在檔案中的具體位置。假設name中有8個字元,少於8個則補空格(這裏用"\u0000"),多於8個則去掉後面多餘的部分。由於年齡是整型數,所以不管這個數有多大,只要它不超過整型數的範圍,在記憶體中都是佔4個位元組大小。
員工資訊類的使用(RandomFileDemo.java)。



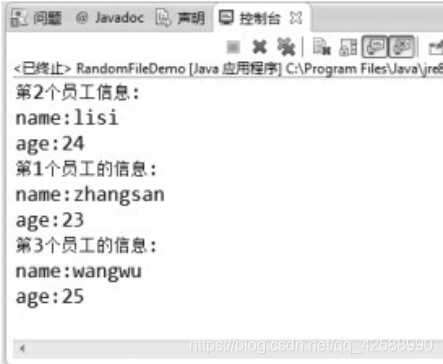
本程式完成了所要實現的功能,顯示出了RandomAccessFile類的作用。
其中43~61行是一個輔助類Employee,用以描述僱員的數據結構。第06~08行定義了3個Employee類物件e1、e2和e3。第09行定義了RandomAccessFile物件ra,它以可讀可寫「rw」的模式在D槽開啓一個名爲「employee.txt」的檔案。
在第10行中,e1物件中成員name爲String型別,String類的getBytes()方法是得到一個系統預設的編碼格式的位元組陣列。在第16行,當一個流完成工作後,一個良好的習慣就是用close()方法將其關閉。程式碼第17行,重新開啓一個流raf,它以只讀模式來存取檔案「employee.txt」。
程式碼第19行,使用skipBytes()方法是在檔案中跳過給定數量的位元組(這裏是12個位元組)。這個方法以當前的檔案指針爲基點,其跳轉的距離是相對於當前位置。對於第1個員工的資訊,其姓名佔8位元組,年齡佔4位元組,共計12個位元組。
需要注意的是,seek(long n)方法也能完成定位檔案指針在檔案中的位置。參數n確定讀寫位置距離檔案開頭的位元組個數,比如seek(0)就是定位檔案指針在開始位置。這裏的n是從檔案開頭開始的一個是絕對定位距離。
第52行出現的String.substring(int beginIndex,int endIndex)方法,可以用於取出一個字串中的部分子字串,但要注意的一個細節是:第一個int型別的參數beginIndex爲開始的索引,對應String數位中的開始位置;第二個參數endIndex是截止的索引位置,對應String中的結束位置。取得的字串長度爲:endIndex -beginIndex。子字串中的第1個字元對應的是原字串中的腳標爲beginIndex處的字元,但最後的字元對應的是原字串中的腳標爲endIndex-1處的字元,而不是endIndex處的字元。
位元組流與字元流
儘管可以使用File進行檔案的操作,但是如果要進行檔案內容的操作,在Java之中就必須通過兩類流操作完成。Java的流操作分爲位元組流和字元流兩種。字元流處理的物件單元是Unicode字元,每個Unicode字元佔據2個位元組,而位元組流輸入輸出的數據是以單個位元組(Byte)爲讀寫單位。這種流操作方式給操作一些雙位元組字元帶來了困難。字元流是由Java虛擬機器將單個位元組轉化爲2個位元組的Unicode字元,所以它對多國語言支援較好。
要將一段二進制數據,如音訊、視訊及影象等,寫入某個裝置,或者從某個裝置中讀取一段二進制數據,我們需要使用位元組流操作進行讀寫則更加方便。但如果我們操作的物件是一段文字,則使用位元組流進行操作,讀取時需將文字以位元組流的方式讀入,如果要將位元組顯示爲字元,就需要使用位元組和字元之間的轉換。運用物件導向的思想,我們需要一個直接用於操作文字數據的I/O類——字元流。字元流將位元組流進行包裝,接受字串輸入,並在底層將字元轉換爲位元組。
Java 的流式輸入/輸出建立在4個抽象類的基礎上:InputStream、OutputStream、Reader和Writer。它們用來建立具體的流式子類。儘管程式通過具體子類進行輸入/輸出操作,但頂層的類定義了所有流類的通用基本功能。
InputStream 和OutputStream被設計成位元組流類,而Reader 和Writer 則被設計成字元流類。位元組流類和字元流類形成分離的層次結構。通常來說,處理字元或字串時應使用字元流類,處理位元組或二進制物件時應使用位元組流類。
一般在操作檔案流時,不管是位元組流還是字元流,都可以按照如下的流程進行。
使用File類找到一個要操作的檔案路徑;
通過File類的物件去範例化位元組流或字元流的子類;
進行位元組(字元)的讀/寫操作;
IO流屬於資源操作,操作的最後必須關閉。
位元組流類爲處理位元組式輸入/輸出提供了豐富的環境。一個位元組流可以與其他任何型別的物件並用,包括二進制數據。這樣的多功能性使得位元組流對很多型別的程式都很重要。
位元組流包含兩個頂層抽象類:InputStream和OutputStream。所有的讀操作都繼承自一個公共超類java.io.InputStream類。所有的寫操作都繼承自一個公共超類java.io.OutputStream類。這兩個抽象類都由不同的子類來具體實現某項「個性化」的功能,完成不同類型裝置的輸入和輸出。下表列出常用的位元組流名稱及對應功能的簡單介紹。
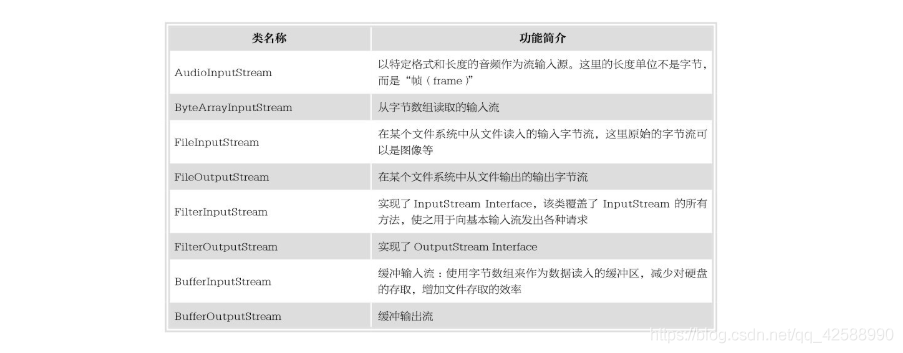
位元組輸出流——OutputStream
下面 下麪我們就從位元組輸出流OutputStream開始討論。如果要通過程式輸出內容到檔案中,則必須使用OutputStream類完成, 它是一個抽象類,它定義了流式位元組輸出模式,該類的所有方法返回一個void 值,並且在出錯的情況下,會拋出一個IOException異常。這個類的定義如下。

可以發現OutputStream類之中實現了兩個介面,這兩個介面定義如下。

一般而言,很少去關心Closeable和Flushable兩個介面,因爲OutputStream類是在JDK 1.0的時候就定義的,而上面的兩個介面是在JDK 1.5的時候才定義的,人們所關心的不是這兩個介面,而是直接觀察OutputStream類中定義的方法,下表中顯示了OutputStream的方法。

提示
上表中的多數方法由OutputStream的子類來實現。下面 下麪以其子類FileOutputStream爲例來討論這些方法的使用和不使用的情況。
對於OutputStream類而言,其本身是一個抽象類,按照物件導向的概念來解釋的話,對於抽象類要想範例化必須通過子類完成,如果說現在要操作的是檔案的輸出,則可以使用子類FileOutputStream類完成。FileOutputStream 建立了一個可以向檔案寫入位元組的類OutputStream,它常用的構造方法如下所示。

如果發生開啓檔案失敗等意外,它們都可以引發IOException或SecurityException異常。在這裏, filePath是檔案的絕對路徑,fileObj是描述該檔案的File物件。如果參數append爲true,檔案則是以設定搜尋路徑模式開啓,在原有檔案基礎上追加數據。FileOutputStream的建立不依賴於檔案是否存在。在建立物件時,FileOutputStream會在開啓輸出檔案之前就建立它。在這種情況下如果試圖開啓一個只讀檔案,則會引發一個IOException異常。
位元組輸入流——InputStream
InputStream 是一個定義了Java流式位元組輸入模式的抽象類,該類的所有方法在出錯時都會引發一個IOException 異常。下表中顯示了InputStream的方法。
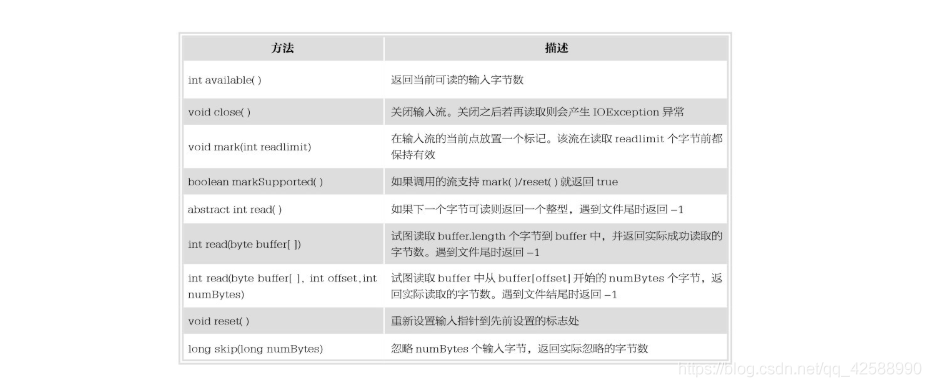
FileInputStream 類建立一個能從檔案讀取位元組的InputStream 類,它的兩個常用的構造方法如下。

這兩個構造方法都能引發FileNotFoundException異常。在這裏filepath 是檔案的絕對路徑,fileObj是描述該檔案的File物件。
下面 下麪的例子建立了兩個使用同樣磁碟檔案且各含一個上面所描述的構造方法的FileInputStream類。

儘管第1個構造方法可能更常用到,但第2個構造方法可允許在把檔案賦給輸入流之前用File方法更進一步檢查檔案。當一個FileInputStream被建立時,它可被公開讀取。
在下面 下麪的綜合例子中,首先用FileOutputStream類向檔案中寫入一個字串,然後用FileInputStream讀出寫入的內容。
下面 下麪以InputStream 的子類FileInputStream(檔案輸入流)爲例說明上述部分方法的使用。
向檔案中寫入字串並讀出(StreamDemo.java)。
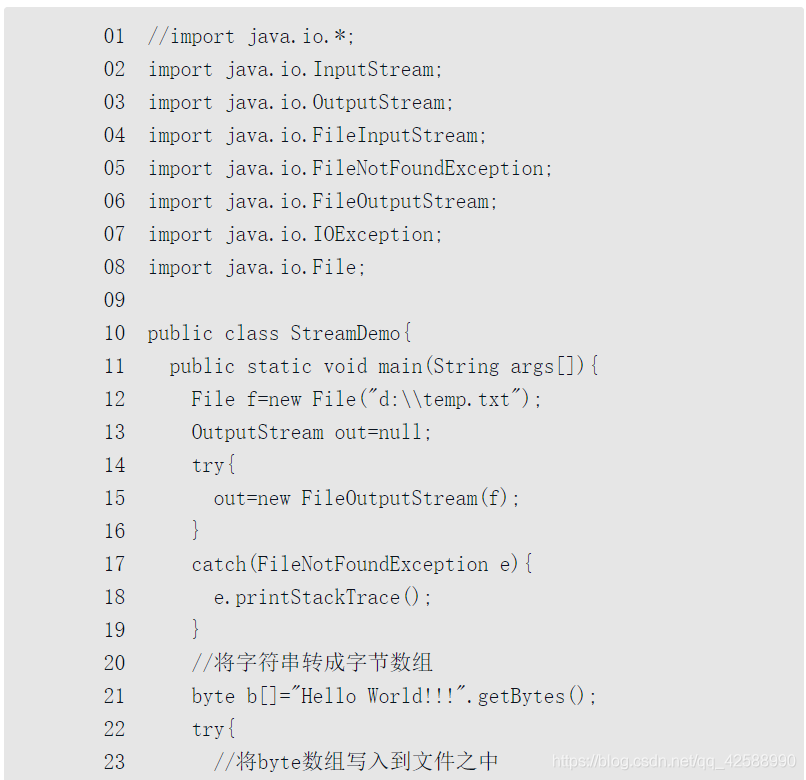


由於要用到OutputStream和InputStream及其子類,同時要用到例外處理的部分類,所以在第02~08行匯入相應的類庫。事實上,爲了「偷懶」起見,可用程式碼的第01行代替02~08行的功能。「import java.io.」中的「」是萬用字元,此處代表的是與I/O操作的所有包庫。「偷懶」(使用萬用字元)的代價是,把不需要的包庫也匯入了—有「浪費之嫌」。
其後的程式分爲兩個部分,一部分是向檔案中寫入內容(第12~32行),另一部分是從檔案中讀取內容(第34~55行)。
⑴ 第12行通過建立一個File類物件f,找到D槽下的一個temp.txt檔案,如果沒有這個檔案,則新建立之。
⑵ 向檔案寫入內容。
① 第13~ 19行通過File類的物件f作爲參數建立OutputStream的物件out(13行),然後再通過新建立子類FileOutputStream來範例化這個OutputStream物件out(15行),這屬於物件的向上型別轉型。
② 因爲位元組流主要以操作byte陣列爲主,所以第21行通過String類中的getBytes()方法,將字串轉換成一個byte陣列。需要注意的是,在Java裡,一切皆爲物件,字串「Hello World!!!」也是一個字串物件,所以它也有相應的方法可用,使用一個物件的方法的格式是:「對面名.方法」。這裏getBytes()方法的物件就是字串「Hello World!!!」。
③ 第22~27行呼叫OutputStream類中的write()方法,將byte陣列中的內容寫入到檔案中。
④ 第28~32行呼叫OutputStream類中的close()方法,關閉數據流操作。
⑶ 從檔案中讀入內容。
① 第34~ 39行通過File類的物件f來作爲參數,建立InputStream的物件in(36行),然後通過新建立的子類FileInputStream物件,來範例化這個InputStream物件in,這裏屬於物件的向上型別轉型。
② 因爲位元組流主要以操作byte陣列爲主,所以第41行宣告瞭一個1024大小的位元組(byte)陣列,此陣列用於存放讀入的數據。
③ 第43~48行呼叫InputStream類中的read()方法將檔案中的內容讀入到byte陣列中,同時返回讀入數據的個數。
④ 第49~53行呼叫InputStream類中的close()方法,關閉數據流操作。
⑤ 第55行將byte陣列轉成字串輸出。
從本範例中可以看到,大部分的方法操作時都進行了例外處理,這是因爲所使用的方法處都用try-catch關鍵字進行I/O異常捕捉。不清楚的讀者可以查詢JDK文件,屆時相信就可以明白了。
還有一點需要讀者注意,Java中,變數的使用都遵循一個原則:先定義,並初始化後,纔可以使用。但有時,在我們定義一個參照型別變數時,並無法給出一個確定的值,這時,我們可以先給變數指定一個null值。
在Java中,null常用來標識一個不確定的物件。因此可將null賦給參照型別變數,但不可以將null賦給基本型別變數。
比如:int a = null;是錯誤的。
Ojbect o = null是正確的。
程式的第13行和34行,均使用了null來初始化out和in這兩個物件。隨後,這兩個物件才被真正有意義地賦值(分別參見第行15和第36行)。學習過C/C++的讀者,可以將null理解爲C/C++中的NULL(必須大寫),即空指針。
字元輸出流——Writer
儘管位元組流提供了處理任何型別輸入/輸出操作的足夠的功能,但它們不能直接操作Unicode字元。既然Java的一個主要目標是支援「一次編寫,處處執行」,那麼支援多國語言字元的直接輸入/輸出是必要的。在這個方面上,Java中的Writer類有着重要的支撐作用。下面 下麪將從Writer抽象類開始,介紹字元輸出流及其相關子類的一些方法。
Writer 是定義流式字元輸出的抽象類,所有該類的方法都返回一個void 值並在出錯的條件下引發IOException 異常。表中給出了Writer類中方法。
下面 下麪來說明Writer抽象類的子類FileWriter的一些特性。
FileWriter 建立一個可以寫檔案的Writer 類。它最常用的3個構造方法如下所示。

它們可以引發IOException或SecurityException異常。在這裏fileName是包括檔名的絕對路徑, ile是描述該檔案的File類的物件。如果布爾型別的append爲true,則輸出的內容附加到檔案尾的。FileWriter類的建立不依賴於檔案存在與否。在建立檔案之前,FileWriter將在建立物件時開啓它來作爲輸出。如果試圖開啓一個只讀檔案,將引發一個IOException異常。
字元輸入流——Reader
Reader是定義Java的流式字元輸入模式的抽象類。Reader是專門進行輸入數據的字元操作流,這個類的定義如下。

在Reader類之中也定義了若幹個讀取數據的方法,該類的所有方法在出錯的情況下都將引發IOException 異常。下表中給出了Reader類中的主要方法。
由於Reader類是抽象類,所以要通過檔案讀取時,肯定使用的是FileReader子類,FileReader子類建立了一個可讀取檔案內容的Reader類。它最常用的構造方法如下。

每一個構造方法在無法找到開啓的檔案時,都會引發一個FileNotFoundException異常。在這裏filePath是一個檔案的完整路徑,fileObj是描述該檔案的File物件。
下面 下麪的例子將【範例(StreamDemo.java)】進行改寫,用字元流解決同樣的問題,先來看一下程式碼。
字元流的使用(CharDemo.java)。



此程式與上面範例的程式類似,也同樣分爲兩部分,一部分是向檔案中寫入內容(第06~23行),另一部分是從檔案中讀取內容(第26~45行)。
⑴ 第04行通過一個File類找到D槽下的一個temp.txt檔案。
⑵ 向檔案寫入內容。
① 第05~07行通過File類的物件去範例化Writer的物件out,此時是通過其子類FileWriter範例化的Writer物件,屬於物件的向上轉型(第07行)。
② 因爲字元流主要以操作字元爲主,所以第12行宣告瞭一個String類的物件str。
③ 第13~18行呼叫Writer類中的write()方法將字串中的內容寫入到檔案中。
④ 第19~23行呼叫Writer類中的close()方法,關閉數據流操作。
⑶ 從檔案中讀入內容。
① 第26~31行通過File類的物件去範例化Reader的物件,此時是通過其子類FileReader範例化的Reader物件,屬於物件的向上轉型。
② 因爲位元組流主要以操作char陣列爲主,所以第33行宣告瞭一個1024大小的char陣列,此陣列用於存放讀入的數據。
③ 第34~40行呼叫Reader類中的read()方法將檔案中的內容讀入到char陣列中,同時返回讀入數據的個數。
④ 第41~45行呼叫Reader類中的close()方法,關閉數據流操作。
⑤ 第47行將char陣列轉成字串輸出。
提示
讀者可以將範例CharDemo中的第19~23行註釋掉,也就是說在向檔案寫入內容之後不關閉檔案,然後直接開啓檔案,可以發現檔案中沒有任何內容,這是爲什麼?從JDK文件之中查詢FileWriter類,如下圖所示。

由上圖可以看到,FileWriter類並不是直接繼承自Writer類,而是繼承了Writer的子類(OutputStreamWriter),此類爲位元組流和字元流的轉換類,後面會介紹。也就是說真正從檔案中讀取進來的數據還是位元組,只是在記憶體中將位元組轉換成了字元。
第20行的「out.close()」的「關閉字元流」功能,可以完成將記憶體緩衝區的轉換好的字元流,重新整理輸出至(外記憶體的)檔案中。
由上面的兩個例程,可得出一個結論:字元流的操作多了一箇中間環節—用到了緩衝區,而位元組流沒有用到緩衝區,直接對檔案「實時」操作。另外,也可以用Writer類中的flush()方法強制清空緩衝區,也就是說,將第20行換成「out.flush();」,也可以保證D槽的「temp.txt」有輸出的數據。
位元組流與字元流的轉換
前面已經講過,對於數據操作,Java支援位元組流和字元流,但有時需要在位元組流和字元流之間轉換。爲此,有兩個類:
⑴ 位元組輸入流變爲字元輸入流:InputStreamReader;
⑵ 位元組輸出流變爲字元輸出流:OutputStreamWriter。
InputStreamReader用於將一個位元組流中的位元組解碼成字元,OutputStreamWriter用於將寫入的字元編碼成位元組後寫入一個位元組流。
InputStreamReader有兩個主要的構造方法。

OutputStreamWriter也有對應的兩個主要的構造方法。

爲了達到較高的轉換效率,避免頻繁地進行字元與位元組間的相互轉換,建議最好不要直接使用這兩個類來進行讀寫,而應儘量使用BufferedWriter類包裝OutputStreamWriter類,用BufferedReader類包裝InputStreamReader類。

然後,從一個實際的應用中來了解InputStreamReader的作用。怎樣用一種簡單的方式一下子就讀取到鍵盤上輸入的一整行字元呢?只要用下面 下麪的兩行程式程式碼就可以解決這個問題。

可見,構建BufferedReader物件時,必須傳遞一個Reader型別的物件作爲參數,而鍵盤對應的System.in是一個InputStream型別的物件,所以這裏需要用到一個InputStreamReader的轉換類,將System.in轉換成字元流之後,放入到字元流緩衝區之中,之後從緩衝區中每次讀入一行數據。

下面 下麪用範例來說明這一應用流程。
位元組流與字元流的轉換使用(程式碼BufferDemo.java)。
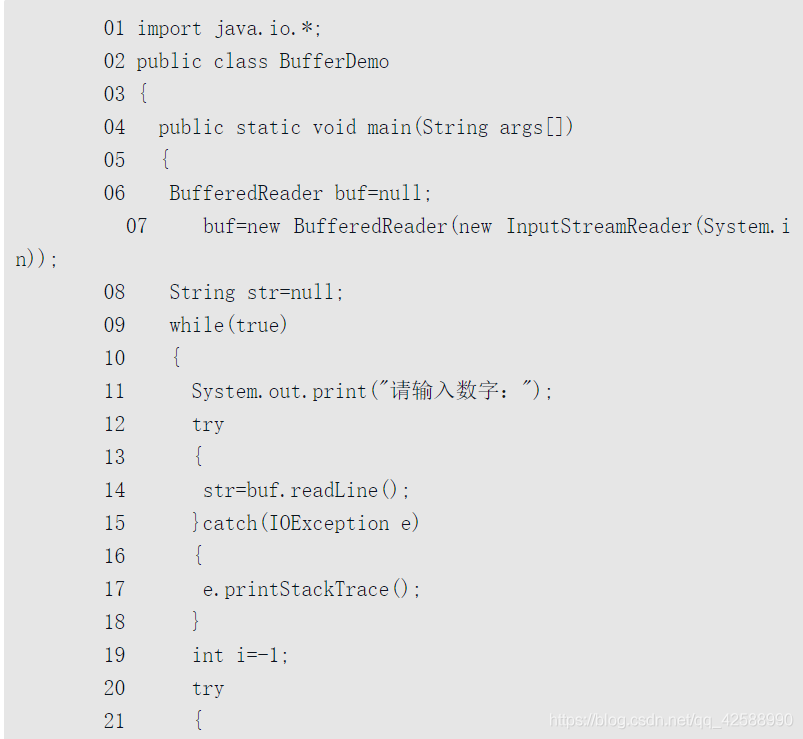

第6行和第7行對BufferedReader物件範例化。因爲現在需要從鍵盤輸入數據,因此需要使用System.in進行範例化,但System.in是屬於InputStream型別,所以使用InputStreamReader類將位元組流轉換成字元流,之後將字元流放入到BufferedReader中。
第14行通過BufferedReader類中的readLine()方法,等待鍵盤的輸入數據。
第22行通過Integer類將輸入的字串轉換成基本數據型別中的整型。
第23行將輸入的數位進行加1操作。
第24行輸出修改後的數據。
管道流
在UNIX/Linux中有一個很有用的概念——管道(pipe),它具有將一個程式的輸出當作另一個程式的輸入的能力。在Java中,它的 I/O系統建立在數據流概念之上,也可以使用「管道」流進行執行緒之間的通訊,在這個機制 機製中,輸入流和輸出流必須相連線,這樣的通訊有別於一般的共用數據(Shared Data)緩衝區通訊,其不需要一個共用的數據空間。
管道流主要用於連線兩個執行緒間的通訊。管道流也分爲位元組流(PipedInputStream、PipedOutputStream)與字元流(PipedReader、PipedWriter)兩種型別,本小節主要講解管道輸入流(PipedInputStream)和管道輸出流(PipedOutputStream)。
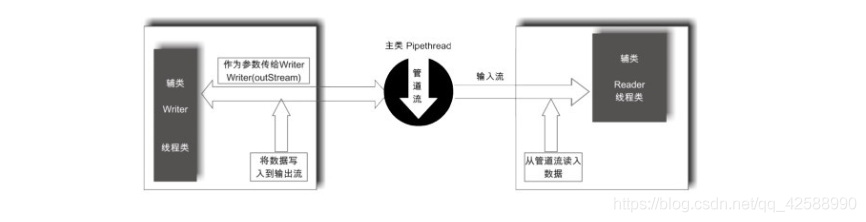
一個PipedInputStream物件必須和一個PipedOutputStream物件進行連線而產生一個通訊管道, PipedOutputStream可以向管道中寫入數據,PipedInputStream可以從管道中讀取PipedOutputStream寫入的數據。如下圖所示,這兩個類主要用來完成執行緒之間的通訊,一個執行緒的PipedInputStream物件能夠從另外一個執行緒的PipedOutputStream物件中讀取數據。
管道流的使用(PipeStreamDemo.java)。



第18~30行宣告瞭一個Sender類,此類繼承自Thread類,所以此類覆寫了Runnable介面之中的run()方法。第19行宣告瞭一個PipedOutputStream物件out,此物件用於發送資訊。
第32~46行宣告瞭一個Receiver類,此類繼承自Thread類,所以此類覆寫了Runnable介面之中的run()方法。第34行宣告瞭一個PipedInputStream物件in,此物件用於接收其他執行緒發來的資訊。
第05行和第06行分別宣告瞭Sender和Receiver的範例化物件,之後,在第07和08行分別呼叫sender.getOutputStream()和receiver.getInputStream()方法,返回各自的管道輸出流out及管道輸入流物件in,在第09行,通過呼叫管道輸出流物件out的connect()方法,將兩個管道連線在一起,之後第10和第11行,分別通過start()方法啓動執行緒。
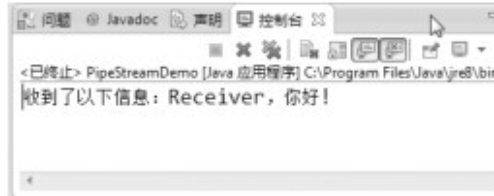
在Sender的run()方法中:在第22行,建立字串物件s,其內容爲"Receiver,你好!"。第24行通過呼叫getBytes()方法,將s物件中的字串轉換爲位元組陣列,然後將其作爲out物件的writer方法的參數,也就是將"Receiver,你好!"位元組陣列寫入到管道。
在Receiver的run()方法中:在第39行中,通過物件in的read()方法,將管道中的數據讀取至位元組陣列buf中,然後在第40行中,將位元組陣列轉換爲一個字串物件s,最後在第41行輸出該字串物件。
從而達到如下目的:將寫入到PipedOutputStream輸出流的數據,可從對應的PipedInputStream輸入流讀取。
此外,注意到第37行,宣告的位元組陣列大小爲1024,其實這是有講究的:類PipedInputStream運用的是一個1024位元組固定大小的回圈緩衝區。實際上,寫入PipedOutputStream的數據儲存到對應的 PipedInputStream的內部緩衝區。如果對應的 PipedInputStream輸入緩衝區已滿,再次企圖寫入PipedOutputStream的執行緒都將被阻塞,直至出現讀取PipedInputStream的操作從緩衝區刪除數據。
記憶體操作流
前面學習的輸入和輸入流的數據均來自於檔案。事實上,如果程式在執行的過程中要產生一些臨時檔案,可以採用虛擬檔案方式實現,Java提供了記憶體流機制 機製,可以實現類似於記憶體虛擬檔案的功能。
這樣,我們既可以從記憶體中獲取數據,也向記憶體中寫入數據,也就是說,可以將記憶體作爲數據的來源和目的地。記憶體操作流就是實現向記憶體中讀取和寫入數據的流類。
記憶體操作流一共也分爲兩組:
⑴ 位元組記憶體操作流:ByteArrayOutputStream、ByteArrayInputStream;
⑵ 字元記憶體操作流:CharArrayWriter、CharArrayReader。
在學習記憶體操作流之前,有亮點需要讀者注意:
⑴ 注意一:不管是檔案流還是記憶體流依然要滿足向上轉型的要求,都要使用到父類別方法;
⑵ 注意二:關於兩者的操作形式不同(數據的來源和目的地不同):

對於位元組記憶體操作流而言,ByteArrayInputStream主要完成將數據寫入到記憶體之中,而ByteArrayOutputStream的功能則是將記憶體中的數據輸出。此時,記憶體作爲數據的操作點,如下圖所示。
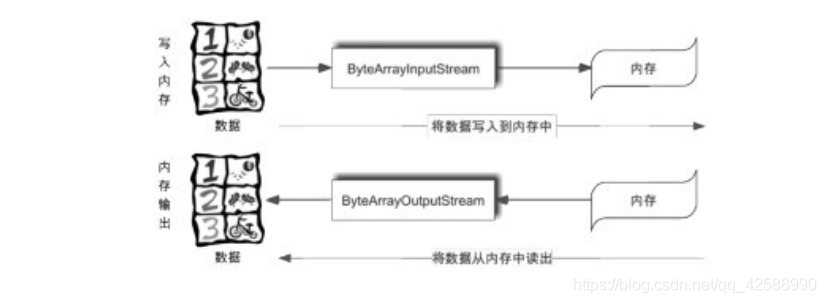
ByteArrayInputStream是輸入流(InputStream)的一種子類實現。

它有兩個構造方法,每個構造方法都需要一個位元組byte陣列來作爲其數據源。

類似地,ByteArrayOutputStream是輸出流(OutputStream)的一種子類實現,其繼承體系如下所示。

ByteArrayOutputStream類也有兩個構造方法。

在上述的兩個構造方法中,前者沒有參數,它僅僅在記憶體當中建立一個位元組陣列輸出流,而後者帶參數size,表明在記憶體當中建立一個指定大小的位元組陣列輸出流。
位元組流類的使用(ByteArrayDemo.java)。


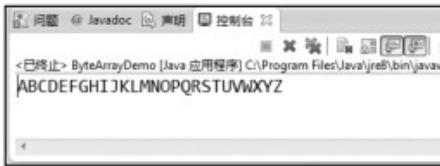
第05行,建立一個字串物件tmp,其值爲「abcdefghijklmnopqrstuvwxyz」。第06行,呼叫tmp的getBytes()方法,將tmp轉換爲位元組陣列,並將其賦值給位元組陣列src,這樣做的原因是,記憶體流操作的物件,就是位元組陣列。第07行,建立一個ByteArrayInputStream物件input,其中src作爲其構造方法的參數。
第09行,先建立一個無名ByteArrayDemo()物件,然後呼叫其自定義的方法transform()來完成位元組流的轉換。在方法transform()中(第13~28行),第18行,每次通過read()方法讀取一個字元,並賦值給c,直到c爲-1爲止,read()方法在讀到流的結尾處返回-1。第20行,呼叫Character類中的靜態方法toUpperCase(),將字元參數轉換爲大寫。第21行,呼叫write()方法,將C中對應的大寫字元輸出。
在本範例中,實施I/O操作的同時,並沒有任何的檔案產生,所以也可以把這種基於記憶體的操作理解爲操作臨時檔案。這種程式碼在現階段之中使用較少,但如果讀者日後學習到了AJAX(一種與伺服器交換數據並更新部分網頁的技術) + XML(一種可延伸標示語言)操作時就會使用。
列印流
在實際應用過程中,有時我們需要列印數據型別的值。列印流爲其他輸出流增強了功能,使它們能夠方便地列印各種數據值表示形式。
輸出問題的提出
如果我們要想進行數據的輸出,首先想到的就是要使用OutputStream類,但這個類在進行輸出數據的時候並不是十分方便。OutputStream類之中所提供的write()方法只適合輸出位元組陣列,但如果要求輸出字元、數位、日期,OutputStream類就不能很方便地勝任工作了,那麼此時該如何解決這個問題?
在Java的I/O包中,列印流是一個輸出資訊最方便的流類,它可以將原樣輸出各種型別的型別。除了輸出數據,列印流還提供兩項其他功能:⑴ 與其他輸出流不同的是,列印流的方法不會拋出IOException,其異常情況僅設定內部標誌位, 這些標誌位可通過checkError() 方法來讀取。⑵ 列印流具有自動重新整理的功能。例如,當寫入位元組陣列時,flush()方法會被自動呼叫。
列印流的使用
爲了簡化輸出的操作難度,在Java中提供了兩種列印流:PrintStream(位元組列印流)和PrintWriter (字元列印流)。
下面 下麪首先以PrintStream類爲例進行分析,觀察PrintStream類的繼承結構。
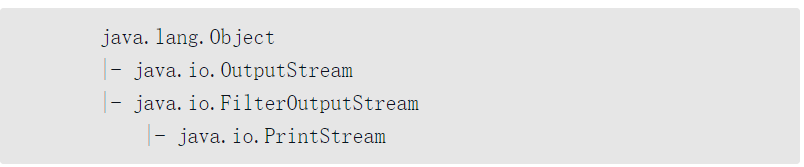
對於列印流而言,它所使用的設計模式稱爲裝飾設計模式,即將一個設計不是非常完善的功能,新增一些程式碼之後變得完善起來。
PrintStream類提供了一系列的print和println方法,可以實現將基本數據型別的格式轉換成字串輸出。在前面的程式中大量用到的「System.out.println」語句中的System.out,就是PrintStream類的一個範例物件。PrintStream有下面 下麪幾個構造方法。

其中autoflush控制在Java中遇到換行符(\n)時是否自動清空緩衝區,encoding是指定編碼方式。關於編碼方式,將在文章後面介紹。
println方法與print方法的區別是:前者會在列印完的內容後面再多列印一個換行符(\n),所以println()等於print("\n")。
Java的PrintStream物件具有多個過載的print和println方法,它們可輸出各種型別(包括Object)的數據。對於基本數據型別的數據,print和println方法會先將它們轉換成字串的形式,然後再輸出,而不是輸出原始的位元組內容,如整數221的列印結果是字元「2」、「2」、「1」所組合成的一個字串,而不是整數221在記憶體中的原始位元組數據。對於一個非基本數據型別的物件,print和println方法會先呼叫物件的toString方法,然後輸出toString方法所返回的字串。
在Java的I/O包中,提供了一個與PrintStream對應的PrintWriter類,PrintWriter類有下列幾個構造方法。

PrintWriter即使遇到換行符(\n)也不會自動清空緩衝區,只在設定了autoflush模式下使用了println方法後纔會自動清空緩衝區。PrintWriter相對PrintStream最便利的一個地方就是println方法的行爲,在Windows下的文字換行是「\r\n」,而在Linux下的文字換行是「\n」。如果希望程式能夠生成平臺相關的文字換行,而不是在各種平臺下都用「\n」作爲文字換行,那麼就應該使用PrintWriter的println方法,PrintWriter的println方法能根據不同的操作系統而生成相應的換行符。
下面 下麪的範例通過PrintWriter類向螢幕上列印資訊。
PrintWriter類向螢幕輸出資訊(SystemPrintDemo.java)。

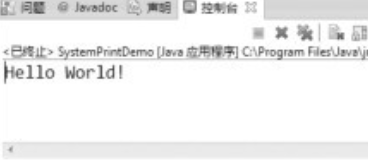
第08行通過System.out範例化PrintWriter,此時PrintWriter類的範例化物件out就具備了向螢幕輸出資訊的能力,所以在第10行呼叫print()方法時,就會將內容列印到螢幕上。
下面 下麪的範例通過PrintWriter向檔案中列印資訊。
通過PrintWriter向檔案中輸出資訊(FilePrint.java)

第07行,我們先範例化一個File類物件f。f對應D槽的一個檔案temp.txt。需要注意的是,由於安全許可權的限制,有時在Windows下的C槽通過程式建立一個檔案,是不被允許的,這時會發生一個異常中斷。
第10行通過FileWriter類範例化PrintWriter,此時PrintWriter類的範例化物件out就具備了向檔案輸出資訊的能力,所以在第17行呼叫print()方法時,就會將內容輸出到檔案之中。
在之前一直使用過的print()、println()這些「耳熟能詳」的方法在列印流這裏找到「根據地」了,這裏我們可以得出一個初步的結論:如果由程式向一個終端輸出數據時,一定要使用列印流。
列印流的更新
列印流能夠方便地執行輸出,爲了使輸出的格式更加的整潔,在JDK1.5之後,對列印流進行了更新,可以使用格式化輸出。即類似C語言中的printf()函數。提供了以下的方法。
Public PrintStream printf(String format,Object… args)
可以設定格式和多個參數。在使用此方法的時候需要使用一些佔位標記:字串(%s)、整數(%d)、小數(%f)、字元(%c)等。
下面 下麪通過範例來說明Java中格式化輸出的用法。
列印流格式化輸出(PrintFormat.java)。

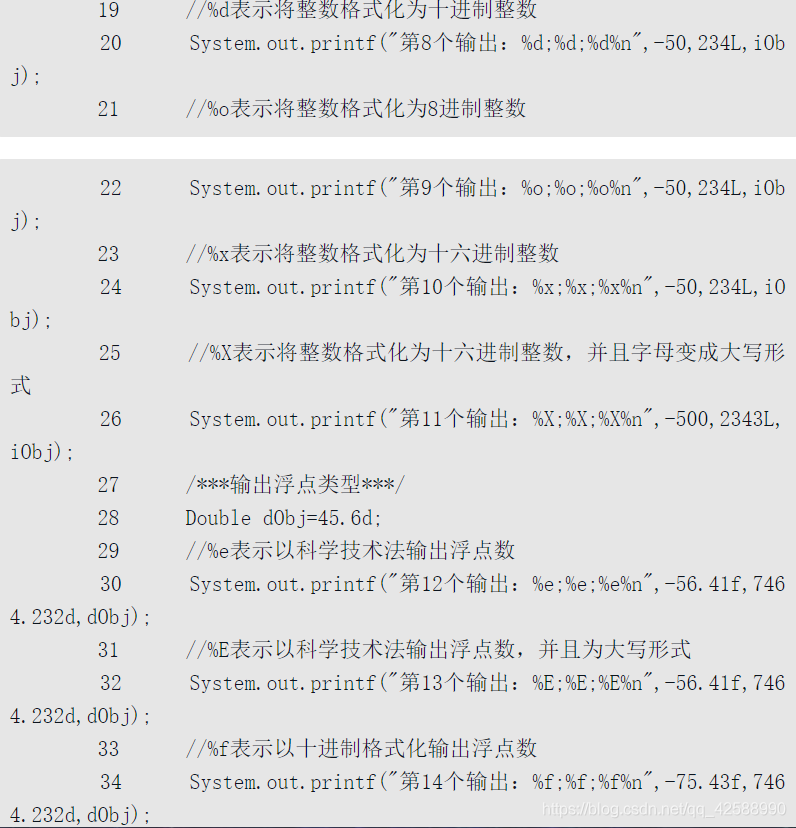

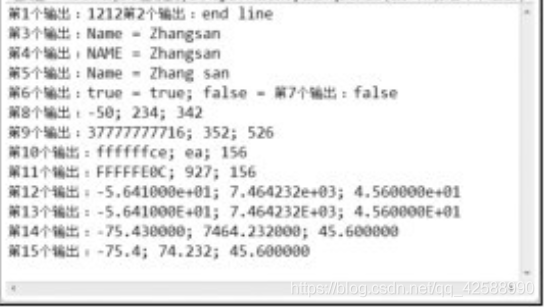
第04~16行,演示了字串的多種格式輸出。第18~26行,演示了整數的多種格式的輸出。在第13行中,System.out.printf()方法支援多個參數時,可在%s之間插入變數編號,1表示第2個字串,以此類推。第28行到36行,演示了浮點數的多種格式的輸出。具體的使用方法在註釋中已經詳細說明,這裏就不再贅述了。
合併(序列)流
SequenceInputStream類可以將多個輸入流按順序連線起來。SequenceInputStream的構造方法是使用一對輸入流或者一個輸入流的列舉(內含多個輸入流)作爲參數。

SequenceInputStream類中的主要方法如下表所示。

採用SequenceInputStream類,可以實現多個檔案的合併操作。下圖所示爲兩個檔案的合併示意圖。
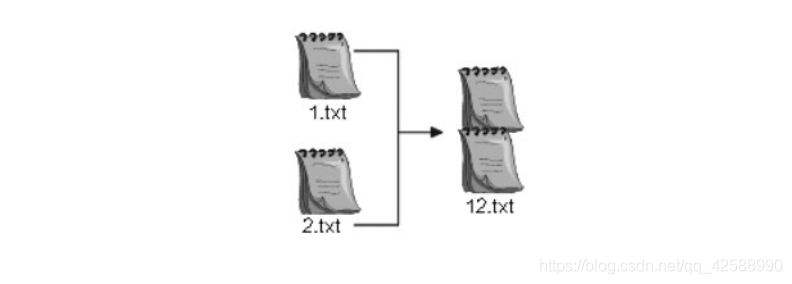
使用合併流將兩個檔案合併(SequenceDemo.java)



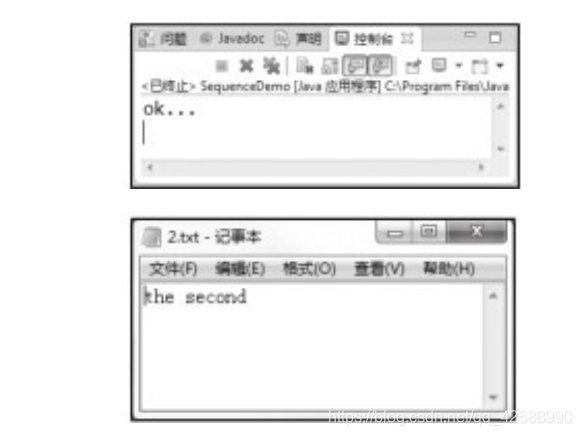

第05行,宣告瞭兩個檔案讀入流物件in1和in2,並初始化爲null。第07行,宣告瞭一個序列(合併)流s。第08行,宣告瞭一個檔案輸出流物件out。第11~12行分別構造兩個被讀入的檔案「D:\1. txt」D:\2.txt,第14行構造一個輸出檔案「D:\12.txt」。這裏有兩處需要讀者注意:
⑴ 在File類中提供了一個常數—路徑分隔符:separator,它在Windows中,自動替換爲「\」,而在Linux中自動替換爲「/」,從而在某種程度上提高了Java程式可移植性。推薦讀者用這種方式來處理路徑的分隔符。
⑵ 上述提到的檔案1.txt、2.txt和12.txt,必須是事先已經存在的,否則會發生異常「java. io.FileNotFoundException」。檔案1.txt、2.txt中的數據也是事先寫入的,12.txt程式執行前是空檔案,執行後爲上圖右下所示。如果想實現用File類開啓某個檔案,如果該檔案存在,則開啓之,如果不存在,則建立之,可以參看【範例(FileDemo.java)】的第06~17行程式碼。
第20行,將in1和in2這兩個輸入流合爲一個輸入流s。第21行,宣告瞭一個檔案輸出流out。第24行,用了一個while回圈,將合併的輸入流s中的位元組,利用read()方法,逐個讀出,並賦值爲整型變數c。如果到達輸入流的尾部,read()方法會返回-1。然後檔案輸出流物件out利用write()方法將讀出的數據c逐一寫入到對應的12.txt。
第31~49行,關閉in1、in2、s和out等流,這是爲了防止意外,做了例外處理。
System類對I/O的支援
爲了支援標準輸入輸出裝置,Java定義了3個特殊的流物件常數:
錯誤輸出:public static final PrintStream err;
系統輸出:public static final PrintStream out;
系統輸入:public static final InputStream in。
System.in通常對應鍵盤,屬於InputStream型別,程式使用System.in可以讀取從鍵盤上輸入的數據。System.out通常對應顯示器,屬於PrintStream型別,PrintStream是OutputStream的一個子類,程式使用System.out可以將數據輸出到顯示器上。鍵盤可以被當做一個特殊的輸入流,顯示器可以被當做一個特殊的輸出流。System.err則是專門用於輸出系統錯誤的物件,它可視爲特殊的System.out。按照Java原本的設計,System.err輸出的錯誤是不希望使用者看見的,而System.out的輸出是希望使用者看見的。
觀察下面 下麪的程式段:

由於第05行,「abc」是一個字串,不是Integer.parseInt()方法的合法參數,因此會拋出異常, 06行則是捕獲這個異常,07和08行則是輸出這兩個異常資訊,用Eclipse偵錯,得到如下所示的偵錯結果圖,從圖中可以發現,07和08行輸出的結果是一樣的。

字元編碼
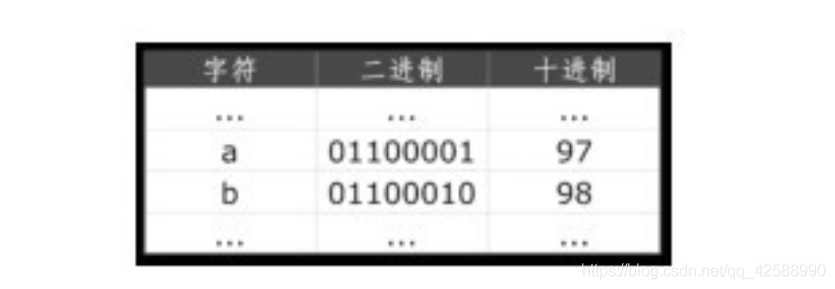
計算機裡只有數位,計算機軟體裡的一切都是用數位來表示,螢幕上顯示的一個個字元也不例外。最開始計算機是在美國使用,當時所用到的字元也就是現在鍵盤上的一些符號和少數幾個特殊的符號,每一個字元都用一個數字來表示,一個位元組所能表示的數位範圍內(0~255)足以容納所有的字元,實際上表示這些字元的數位的位元組最高位(bit)都爲0,也就是說這些數位都在0~127之間,如字元a對應數位97,字元b對應數位98等,這種字元與數位對應的編碼固定下來後,這套編碼規則被稱爲ASCII碼(美國標準資訊交換碼),如下圖所示。
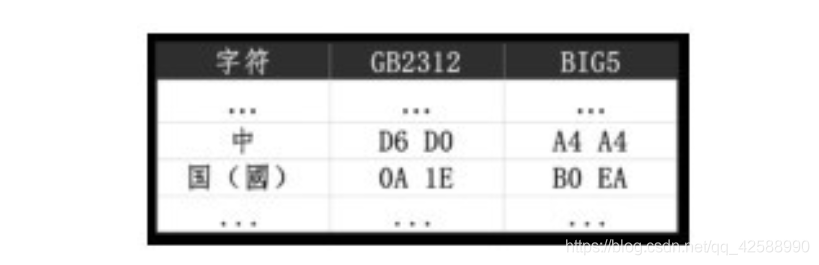
隨着計算機在其他國家的逐漸應用和普及,許多國家都把原生的字元集引入了計算機,這大大地擴充套件了計算機中字元的範圍。一個位元組所能表示的數位範圍(僅僅256個字元)是不能容納所有的中文漢字的(注:《漢語大字典》收字共54678個)。中國大陸將每一箇中文字元都用兩個位元組的數位來表示(這樣,在理論上,可以表示256×256=65536個漢字,夠漢字用了!),在這個編碼機制 機製裡,原有的ASCII碼字元的編碼保持不變,仍用一個位元組表示。爲了將一箇中文字元與兩個ASCII碼字元相區別,中文字元的每個位元組的最高位(bit)都爲1,中國大陸爲每一箇中文字元都指定了一個對應的數位(由於兩個位元組的最高位都被佔用,所以兩個位元組所能表示的漢字數量理論數爲:27×27=16384,有些偏僻的漢字就沒有被編碼,從而計算機就無法顯示和列印),並作爲標準的編碼固定了下來,這套編碼規則稱爲GBK(國標擴充套件碼,GBK就是「國標擴」的漢語拼音首字母),後來又在GBK的基礎上對更多的中文字元(包括繁體)進行了編碼,新的編碼系統就是GB2312,而GBK則是GB 2312的子集(事實上,GB 2312 也僅僅收錄 6763 個常用漢字,僅僅適用於簡體中文字)。使用中文的國家和地區很多,同樣的一個字元,如「中國」的「中」字,在中國大陸地區的編碼是十六進制的D6D0,而在中國臺灣地區的編碼則是十六進制的A4A4,臺灣地區對中文字元集的編碼規則稱爲BIG5(大五碼),如下圖所示。
在一個國家的在地化系統中出現的一個字元,通過電子郵件傳送到另外一個國家的在地化系統中,看到的就不是那個原始字元了,而是另外那個國家的一個字元或亂碼。這是因爲計算機裏面並沒有真正的字元,字元都是以數位的形式存在的,通過郵件傳送一個字元,實際上傳送的是這個字元對應的編碼數位,同一個數位在不同的國家和地區代表的很可能是不同的符號。如十六進制的D6D0在中國大陸的在地化系統中顯示爲「中」這個符號,但在伊拉克的在地化系統中就不知道對應的是一個什麼樣的伊拉克字元了,反正人們看到的不是「中」這個符號。各個國家和地區都使用各自不同的在地化字元編碼,這嚴重製約了國家和地區間在計算機使用和技術方面的交流。
爲了解決各個國家和地區使用各自不同的在地化字元編碼帶來的不便,人們將全世界所有的符號進行了統一編碼,稱之爲Unicode編碼。所有的字元不再區分國家和地區,都是人類共有的符號,如「中國」的「中」這個符號,在全世界的任何一個角落始終對應的都是一個十六進制的數位4E2D。如果所有的計算機系統都使用這種編碼方式,在中國大陸的在地化系統中顯示的「中」這個符號,發送到德國的在地化系統中,顯示的仍然是「中」這個符號,至於那個德國人能不能認識這個符號,就不是計算機所要解決的問題了。Unicode編碼的字元都佔用兩個位元組的大小,也就是說全世界所有的字元個數不會超過2的16次方(65536)。
Unicode一統天下的局面暫時還難以形成,在相當長的一段時期內,人們看到的都是在地化字元編碼與Unicode編碼共存的景象。既然在地化字元編碼與Unicode編碼共存,那就少不了涉及兩者之間的轉換問題,而Java中的字元使用的都是Unicode編碼,Java技術在通過Unicode保證跨平臺特性的前提下也支援了全擴充套件的本地平臺字元集,而顯示輸出和鍵盤輸入則都是採用的本地編碼。
除了上面講到的GB 2312/GBK和Unicode編碼外,常見的編碼方式還有:
ISO 8859-1編碼:國際通用編碼,單一位元組編碼,理論上可以表示出任意文字資訊,但對雙位元組編碼的中文表示,需要轉碼;
UTF編碼:結合了ISO 8859-1和Unicode編碼所產生的適合於現在網路傳輸的編碼。考慮到Unicode編碼不相容ISO 8859-1編碼,而且容易佔用更多的空間:因爲對於英文字母,Unicode也需要兩個位元組來表示。所以Unicode不便於傳輸和儲存。因此而產生了UTF編碼,UTF編碼相容ISO 8859-1編碼,同時也可以用來表示所有語言的字元,但UTF編碼是不等長編碼,每一個字元的長度從1~6個位元組不等。一般來講,英文字母還是用一個位元組表示,而漢字則使用三個位元組。此外,UTF編碼還自帶了簡單的校驗功能。
那麼清楚了編碼之後,就需要來解釋什麼叫亂碼:編碼和解碼不統一。那麼如果要想在開發之中處理亂碼,那麼首先就需要知道在本機預設的編碼是什麼。通過下面 下麪的程式,來看一下到底什麼是字元亂碼問題。在這裏使用String類中的get Bytes()方法,對字元進行編碼轉換。
字元編碼使用範例1(EncodingDemo.java)。

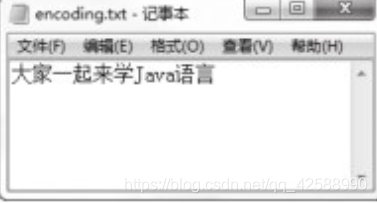
對此程式讀者應該非常清楚,但這裏與之前稍有不同的是,在將字串轉換成byte陣列的時候,用到了「GB2312」編碼。
讀到這裏讀者可能還是無法體會到字元編碼問題,那麼現在修改一下EncodingDemo程式,將字元編碼轉換成ISO8859-1,形成【範例(EncodingDemo.java)】,但在執行此程式之前,须先執行下面 下麪的【範例(SetDemo.java)】程式。

第05行通過System.getProperties()獲取系統參數,該方法返回一個屬性Properties物件,類Properties繼承自Hashtable類,而Hashtable類用於put()方法。該方法的原型是put(K key, V value),其功能是在hash表中將特定的鍵值(key)對映爲特定的值(value)。在這裏,是將鍵file. encoding(檔案編碼)對映值爲"GB2312"。
執行【範例(SetDemo.java)】程式之後,再執行【範例(EncodingDemo.java)】EncodingDemo.java程式,修改後的程式如下。

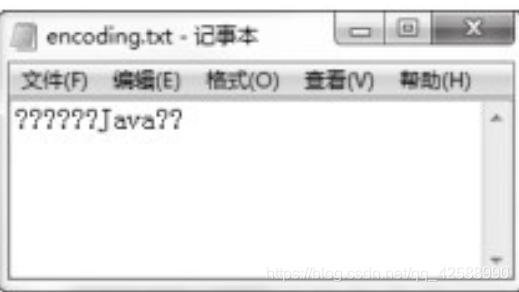
由上圖可以看到,非英文部分的字元,輸出結果出現了亂碼,這是爲什麼?這就是本節要討論的字元編碼問題。之所以會產生這樣的問題,是因爲在執行這段程式碼之前,先執行了setDemo.java程式,此程式主要是用來設定JDK環境的編碼問題,所以亂碼問題主要是由於JDK設定環境所引起的,爲什麼呢?讀者可以執行下面 下麪的程式,觀察其輸出就可以發現問題。
獲得系統的屬性(GetDemo.java)。

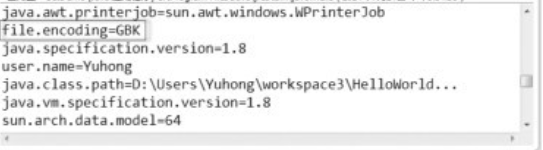
程式碼第06行,獲取系統的屬性,並用list()方法全部輸出。從輸出結果可以看到,在環境變數之中有一個file.encoding=GBK,這清楚地表明瞭所使用的是GBK編碼,而修改過的【範例(EncodingDemo.java)。】EncodingDemo.java程式中的第7行如下。

在這裏將字串「大家一起來學Java語言」的編碼換成了ISO8859-1編碼。ISO8859-1 通常叫做Latin-1,屬於單位元組編碼,最多能表示的字元範圍是0~255,其適用於拉丁語系,很明顯,ISO 8859-1編碼表示的字元範圍很窄,無法表示雙位元組編碼的中文字元,所以就造成了【範例(EncodingDemo.java)。】裡的中文字元的亂碼問題。
物件序列化
有時我們需要儲存物件,以便進一步地操作,這便用到了物件序列化。
物件序列化的基本概念
所謂的物件序列化(在某些書籍中也叫序列化),是指在記憶體之中儲存的物件轉化爲二進制數據流的形式的一種操作。通過將物件序列化,可以方便地實現物件的傳輸及儲存。但是在Java之中並不是所有的類的物件都可以被序列化,如果一個類物件需要被序列化,則此類一定要實現java. io.Serializable介面。但是這個介面裏面也沒有定義任何的方法,所以此介面依然屬於標識介面,表示一種能力。
在Java中提供有ObjectlnputStream與ObjectOutputStream這兩個類用於序列化物件的操作。這兩個類是用於儲存和讀取物件的輸入輸出流類,不難想象,只要把物件中的所有成員變數都儲存起來,就等於儲存了這個物件,之後從儲存的物件之中再將物件讀取進來就可以繼續使用此物件。ObjectInputStream與ObjectOutputStream類,用於幫助開發者完成儲存和讀取物件成員變數取值的過程,但要求讀寫或儲存的物件必須實現了Serializable介面,但Serializable介面中沒有定義任何方法,僅僅被用做一種標記,以被編譯器做特殊處理。如下範例所示。
物件序列化使用範例1(Person.java)。

在第2行中,類Person實現了Serializable介面,所以此類所定義的物件就可被序列化。
物件輸出流——ObjectOutputStream
雖然類已經實現了Serializable介面,但是如果要想真正地實現具體的序列化操作,則使用者可以使用ObjectOutputStream類完成,這個類繼承結構如下。

由上述類的繼承關係,可以發現ObjectOutputStream是OutputStream子類,因爲物件序列化之後爲二進制數據,所以只能夠依靠位元組流操作,同時在ObjectOutputStream類中定義了以下兩個方法。
⑴ 構造方法。public ObjectOutputStream(OutputStream out) throwsIOException;
⑵ 輸出物件:public final void writeObject(Object obj) throws IOException;
ObjectOutputStream 用於將物件序列化,並儲存。其操作如下。

ObjectOutputStream 接收一個OutputStream物件用於儲存待序列化的物件。然後cout呼叫writeObject 方法儲存物件。
物件輸入流——ObjectInputStream
如果希望將已被序列化的物件再反序列化回來,則就可以通過ObjectInputStream類完成,它用於讀取將序列化的物件。此類繼承關係如下。
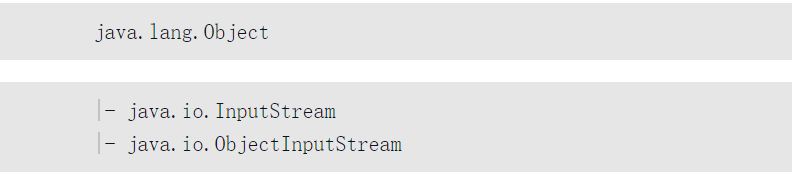
對於ObjectInputStream類之中主要使用的兩個方法如下。
⑴ 構造方法。public ObjectInputStream(InputStream in) throwsIOException;
⑵ 物件輸入:public final Object readObject() throws IOException,ClassNotFoundException;
實現物件的反序列化(讀取物件)操作如下。

ObjectInputStream接收一個InputStream物件用於儲存待序列化的物件。然後cin呼叫readObject方法讀取序列化後的物件。在日後的實際開發之中,這些序列化和反序列化的功能會由相關的容器完成。
反序列化的基本概念
反序列化實際上就是使用ObjectInputStream 類建立物件將序列化後的物件讀取出來,繼續使用此物件。下面 下麪的例子結合ObjectInputStream 和OutputStream演示如何序列化物件和反序列化物件。
物件序列化使用範例2(SerializableDemo.java)


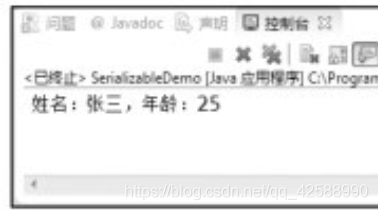
第09~14行宣告瞭一個serialize()方法,此方法用於將物件儲存在檔案之中。第10行、第11行爲ObjectOutputStream物件範例化,此物件是通過FileOutputStream物件範例化,所以此類在儲存Person物件時,向檔案中輸出。
第16~22行宣告瞭一個deserialize()方法,此方法用於從檔案中讀取已經儲存的物件。第17行、第18行爲ObjectInputStream物件範例化。第19行呼叫ObjectInputStream類中的readObject()方法,從檔案中讀入內容,之後將讀入的內容轉型爲Person類的範例。第20行直接列印Person物件範例,在列印物件時,預設呼叫Person類中的toString()方法。
第26~35行,爲【範例(Person.java)】程式碼,此處爲了本例可以獨立執行,如果【範例(Person.java)】和【範例(SerializableDemo.java)】同處於一個包(package)內,則本例的第26~35行可以忽略。
transient關鍵字
在預設情況下,當一個類物件序列化時,會將這個類中的全部屬性都儲存下來,如果不希望類中的某個屬性被序列化(或某些屬性不希望被儲存,則可以在宣告屬性之前加上transient關鍵字。下面 下麪的程式碼修改自【範例(SerializableDemo.java)】,在宣告屬性時,前面多加了一個transient關鍵字。

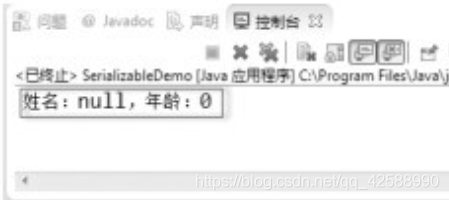
從輸出結果可以看到,Person類中的兩個屬性並沒有被儲存下來,輸出時,是直接輸出了這兩個屬性的預設值null和0。
Java 8 中有關流的新功能
1 Java.io.BufferedReader類中lines()方法。
該方法的原型爲:

該方法返回一個Stream型別的物件,其中Stream的元素是從BufferedReader流中讀出的多行字串。下面 下麪是使用該方法的範例。
Java 8 BufferReader類中lines()方法的使用(LinesTest.java)。
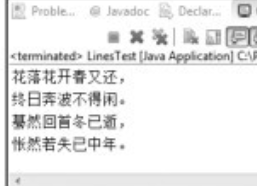
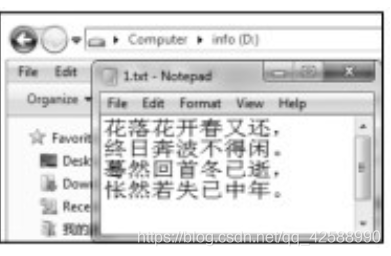
首先需要說明的是,若想本例得以正確執行,需要有兩個前提條件:⑴ 安裝Java8的編譯環境,這時在控制檯模式下即可編譯執行。但如果用Eclipse編譯執行,還需要確保爲Luna (Eclipse 4.4)及以上版本,如果是Kepler (Eclipse 4.2)版本,需要安裝支援Java 8的修補程式:在Eclipse的[Help]à [EclipseMarketplace]開啓應用商店,搜尋Java 8 Kepler,然後安裝組建,安裝完成後需要重新啓動。⑵ 要確保在第10行指定的位置事先建立相應的檔案,本例對應的檔案在「D:\1.txt」,並含有多行數據。假設其檔案內容如下圖所示。
第10行中的File.separator 表示檔案分隔符,在Windows系統裡的值爲「\」,在Unix/Linux系統的值爲「/」。程式碼第11行建立輸入流物件in。在程式碼第12行,首先建立字元流物件lines,然後用BufferedReader 物件in的lines()方法用於獲取檔案中的多行數據。第13行,用字元流物件lines的forEach方法輸出每一行數據。第14行,關閉in流。
(2) java.nio.file.Files 類

該方法的作用與lines()方法類似,獲取一個檔案中的多行內容,並以List集合的方法返回。其中的參數path(java.nio.file.Path)指向的是一個路徑,通過File類的toPath()方法可以得到一個這樣的物件。下面 下麪的範例演示的是該方法的使用。
Files類中readAllLine()方法的使用(AllLinesTest.java)。
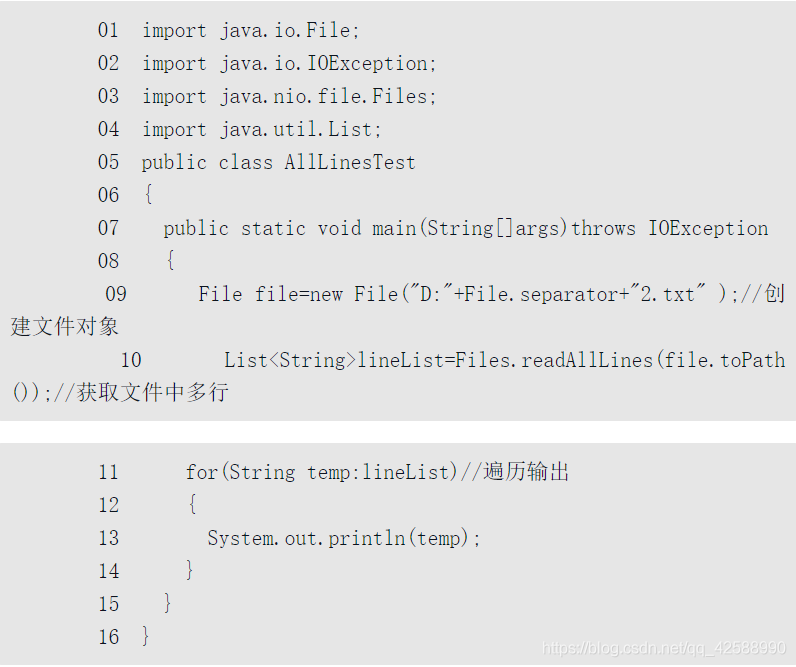
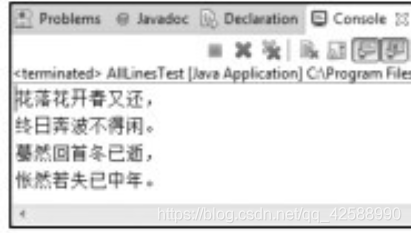
需要注意的是使用這個方法如果沒有指定字元集,則預設爲UTF-8,所以如果檔案的編碼格式不是UTF-8,則可能出現異常(編譯無法通過)或亂碼。此外,如果檔案是UTF-8格式,在處理中文的時候,還會有部分亂碼,如下圖所示。
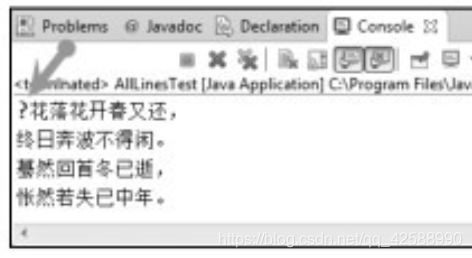
這時,需要將UTF-8格式轉換成UTF-8 without BOM格式。BOM(Byte OrderMark)表示的是位元組序標記。UTF- 8編碼的檔案中,BOM佔三個位元組。如果用記事本把一個文字檔案另存爲UTF-8編碼方式的話,用十六進制檔案編輯器(UtraEdit等)開啓這個檔案,切換到十六進制編輯狀態就可以看到開頭的FFFE標識。這個標識是用來區分UTF-8編碼檔案的好辦法。上圖中的問號」?」就是這個符號無法顯示的亂碼。
⑶ java.nio.file.Files 類

該方法的作用是按照深度優先遍歷(traversed depth-first)的原則遍歷由start作爲根目錄的檔案結構樹。並將遍歷的結果存入Stream集閤中返回,其中的每一個元素都是Path型別的檔案路徑。參數 maxDepth是表示遍歷的最大深度,如果是0,表示只遍歷根目錄,即只返回start指定的根目錄所對應的Path物件。如果想要遍歷該檔案結構中的所有層,則可以將maxDepth參數設定爲 Integer.MAX_VALUE。參數options是一個FileVisitOption型別的值,該型別是列舉型別,僅有一個列舉值-FOLLOW_LINKS 。該參數是可選的。如果不填寫該參數,那麼在遍歷到符號鏈接檔案時不會進入其所鏈接的資料夾中。如果填寫了該參數-FileVisitOption.FOLLOW_LINKS,在遍歷到符號鏈接檔案時會進入其所鏈接的資料夾中繼續遍歷。
該方法是用的範例如下。
Files類中walk()方法的使用(TestWalk.java)。

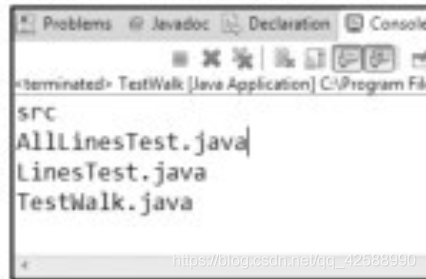
程式碼第15行,獲取第12行建立的物件file所對應的根目錄檔案樹中的所有檔案。第12行中,路徑中「./src」中「./」表示是當前目錄,這是指TestWalk.java所在的路徑。
在 JDK 1.8 中 同 時 提 供 了 一 個 public static Stream
提示
符號鏈接(symbolic link):符號鏈接又叫軟連線,是一類特殊的檔案,這個檔案包含了另一個檔案的路徑名(絕對路徑或者相對路徑),路徑可以是任意的檔案或目錄,可以鏈接到不同檔案系統的檔案。
鏈接符號的操作是透明的:對符號鏈接檔案進行讀寫的程式會表現爲直接對目標檔案進行操作,某些需要特別處理符號鏈接檔案的程式可能會識別鏈接檔案。在Windows7 中建立鏈接檔案的命令是:mklink , 具體的參數可以再DOS下輸入mklink然後回車檢視詳細介紹。
在Java 8 中,還有很多新方法,如java.nio.file.Files 類 public staticStream
1. 使用緩衝流的作用
使用位元組流對磁碟上的檔案進行操作的時候,是按位元組把檔案從磁碟中讀取到程式中來,或者是從程式寫入到磁碟中。相比操作記憶體而言,操作磁碟的速度要慢很多。因此,我們可以考慮先把檔案從硬碟讀到記憶體裏面,把它快取起來,然後再使用一個緩衝流對記憶體裏面的數據進行操作,這樣就可以提高檔案的讀寫速度。讀者朋友可以同時比較InputStream與BufferedInputStream它們在速度上的差異,從而深入理解緩衝流的優勢所在。此外,對檔案的操作完成以後,不要忘了關閉流,否則會產生一些不可預測的問題。
2. 位元組流和字元流的區別(面試題)
對於現在相同的功能發現有兩組操作類可以使用,那麼在開發中到底該使用哪種會更好呢?
關於位元組流和字元流的選擇沒有一個明確的定義要求,但是有如下的選擇參考:
⑴ Java最早提供的實際上只有位元組流,而在JDK 1.1之後才增加了字元流;
⑵ 字元數據可以方便地進行中文的處理,但是位元組數據處理起來會比較麻煩;
⑶ 在網路傳輸或者是進行數據儲存的時候,數據操作單位都是位元組,而不是字元;
⑷ 位元組流和字元流在操作形式上都是類似的,只要一種流會使用了,其他的流都可以採用同樣的方式完成;
⑸ 位元組流操作時沒有使用到緩衝區,字元流操作時需要緩衝區處理數據,字元流會在關閉的時候預設清空緩衝區,如果現在操作時沒有關閉,則使用者可以使用flush()方法手工清空緩衝區。
所以對於位元組流和字元流的選擇,我們建議:在開發中儘量都去使用位元組流進行操作,因爲位元組流可以處理圖片、音樂、文字,也可以方便地進行傳輸或者是文字的編碼轉換;如果在處理中文的時候請考慮字元流。