利用python進行數據分析第十四章專案實戰一及其程式碼解析
2020-08-08 20:16:34
利用python進行數據分析第十四章專案實戰一及其程式碼解析
前言
本系 本係列是我通過利用python進行數據分析第二版的紙質書的學習加上自己的思考而進行的實戰專案。在看的過程當中一些程式碼,函數的使用產生了一些疑惑,所以會加上自己的理解,當然原參考一些文章,不過沒有找到比較詳細地有具體程式碼解析的文章,大多文章的內容與書中無二。這裏掛一個知乎上的鏈接,裏面的內容與書上是一樣的:《利用Python進行數據分析》終章·數據分析案例·學習筆記(一) - 湖邊檸檬樹的文章 - 知乎 鏈接: https://zhuanlan.zhihu.com/p/68487640
另外這只是第一節的前半部分,後面的待更新吧,其實是我碼字累了
下載問題
本書的數據集下載鏈接: https://github.com/wesm/pydata-book/tree/2nd-edition/datasets.
在做專案之前涉及到數據集的下載,如果你是第一次從github上下載的話,可能會遇到下面 下麪兩個問題
- 下載的頁面斷開鏈接無法下載 ,即點選download之後出現空白頁面,顯示斷開連線等,這種情況常見於第一次使用github下載的同學,這時需要使用管理員身份修改電腦上的host檔案,具體做法可以自行百度。
- github中下載單個資料夾 ,單個檔案直接下載即可,想直接下載一個資料夾,可以先下載svn,再在cmd,命令視窗中使用svn命令+需要下載的資料夾的網址鏈接(需要一定的修改的),然後進行下載即可。
參考https://www.runoob.com/w3cnote/svn-co-github-dir.html,跟https://blog.csdn.net/cf8833/article/details/98789632
專案一:從Bitly獲取1.USA.gov數據
有一些書上的內容我沒有打上去,如想要全書的可參考: https://zhuanlan.zhihu.com/p/68487640
- 讀取檔案
path="D:\pycsv\example.txt"
open(path).readline()
#readline()函數:讀取一行

#由上面的結果可知,是json格式,那麼我們把它的引號去掉,即爲字典了,每一行的字典放入字典列表中
import json
path="D:\pycsv\example.txt"
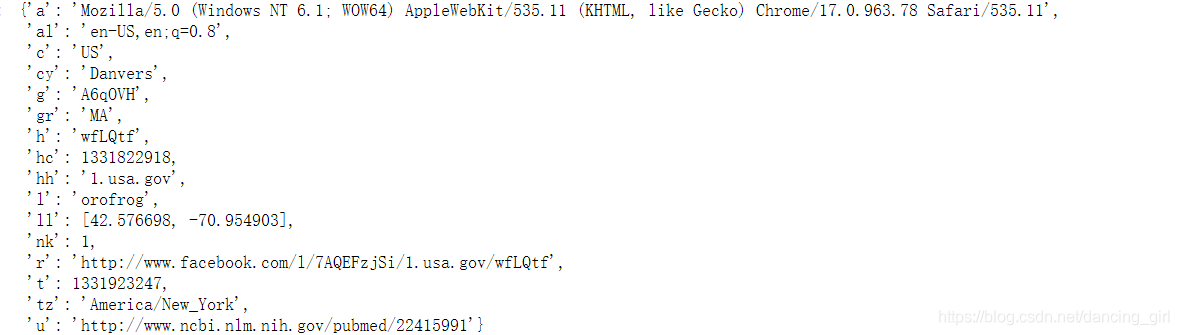
records=[json.loads(line) for line in open(path)]
records[0]
#json.loads()可以識別出字串中的json格式:去掉引號,並變成通用的json,所有語言都識別
#使用for回圈讀取每一行(字典),再接入列表records.
#records[0]取第一個元素
- 時區計數的兩種方法
要找到數據集中最常出現的時區,即tz欄位中最常出現的是誰,有兩種方法:1.使用python進行,2.使用pandas庫巧妙計數- 使用純python方法程式碼進行時區計數
#目標:要找到最常出現的tz欄位,即時區
#'tz'是列表records中的字典的一個鍵,把所有的tz欄位提取出來放入一個新的列表中
time_zones=[rec['tz'] for rec in records if 'tz' in rec] #加if是因爲並不是所有記錄都有時區'tz'欄位,如果不加會報錯
#列表遍歷用for rec in records,rec是字典。字典取值用rec['tz'],判斷鍵是否在字典中用if 'tz' in rec
time_zones[:10]#看前十條數

#現在大家的時區都儲存在time_zones列表當中了,那麼只需要對列表中出現的不同時區計數,再排序,就可以知道最多出現的時區是誰了
#把所有出現的時區和它對應出現的總次數存入字典當中
def get_counts(sequence):
counts={}
for x in sequence:
if x in counts:
counts[x] +=1
else:
counts[x]=1
return counts
#如果列表中的時區x是第一次出現,即不在counts字典中,那麼counts[時區]=1,如果已在counts中,那麼counts[時區]+1
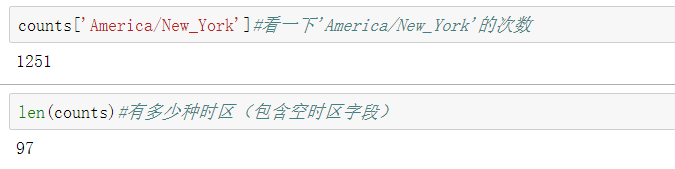
counts=get_counts(time_zones)#此時,已存入counts中
print(counts)
檢視counts的基本情況

想要前十的時區和他們的計數,做一些字典技巧
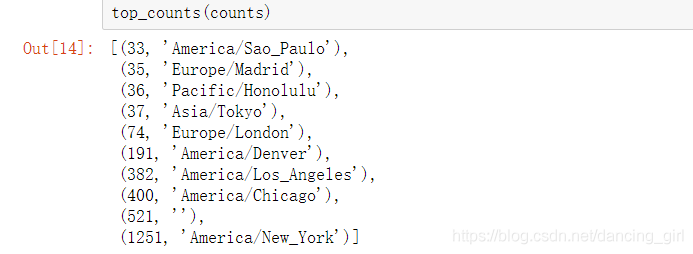
def top_counts(count_dict, n=10):
value_key_pairs = [(count, tz) for tz, count in count_dict.items()]
value_key_pairs.sort()
return value_key_pairs[-n:]
#方法top_counts是將字典中對應的每一對鍵值對都變成一個元祖存入列表value_key_pair當中,然後sort()函數對列表進行排序.
#sort()預設按列表中的元組的第一個元素進行排序,且升序排序
top_counts(counts)
下面 下麪是方法二,使用pandas
- 使用pandas方法進行時區計數
#之前得出的records是列表(裏面儲存字典)
#下面 下麪使用pandas,將records轉爲dataframe,每一個字典變成frame的一行,每一個鍵變爲一列
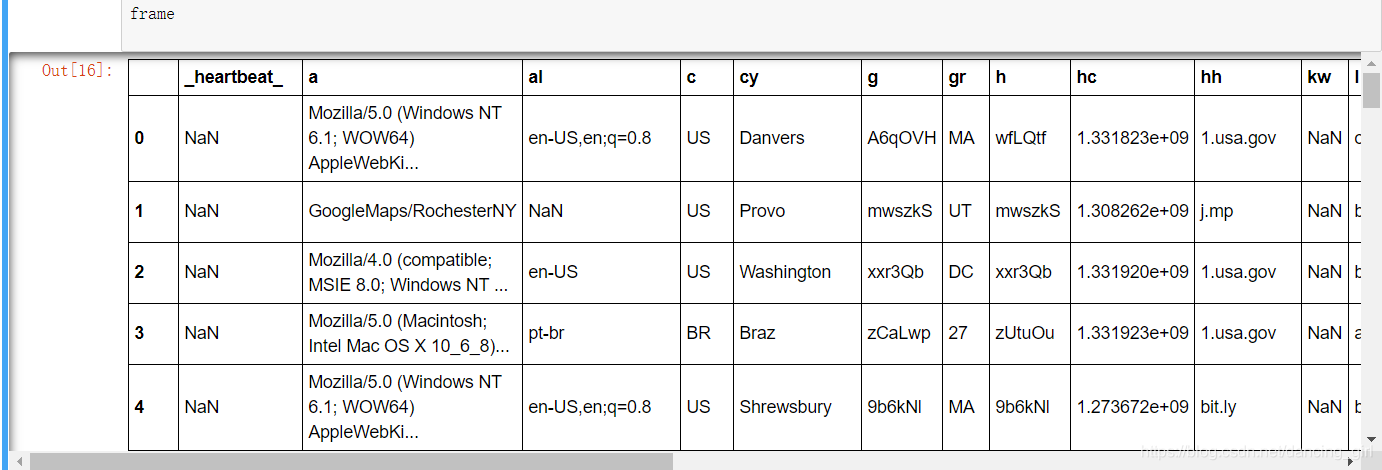
import pandas as pd
frame=pd.DataFrame(records)
frame
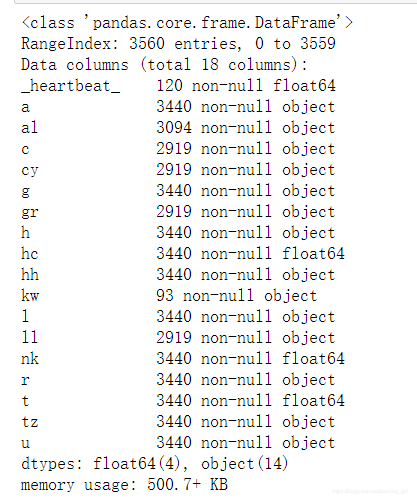
frame.info()
#使用info()函數檢視給出樣本數據的相關資訊概覽 :行數,列數,列索引,列非空值個數,列型別,記憶體佔用
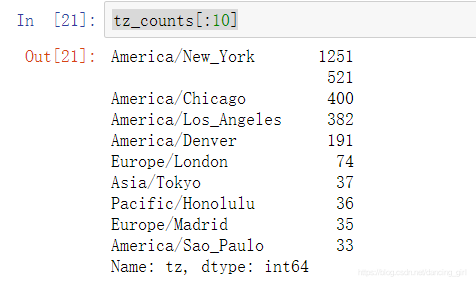
排序並檢視前十的時區
#dataframe的一列是series,用series的value_counts方法對那一列進行排序,預設從大到小
tz_counts=frame['tz'].value_counts()
tz_counts[:10]
#看前十
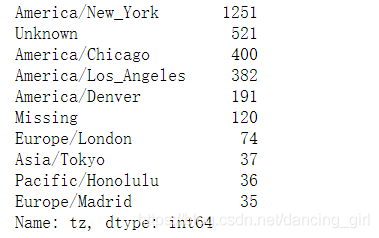
用fillna()替換缺失值,()括號當中的值爲所用來替換的值。併爲空字串使用布爾陣列索引
clean_tz = frame['tz'].fillna('Missing')
clean_tz[clean_tz == ''] = 'Unknown'
tz_counts = clean_tz.value_counts()
tz_counts[:10]
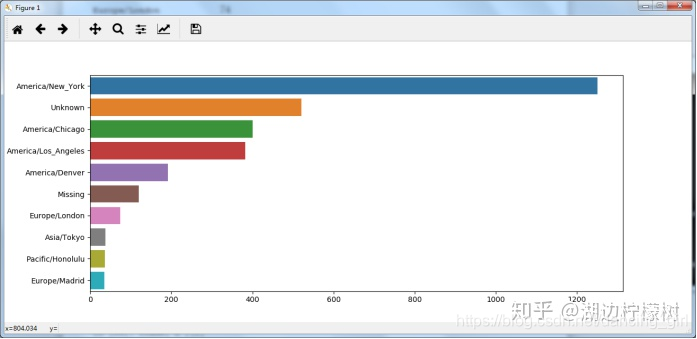
使用seaborn包進行畫圖
import seaborn as sns
subset = tz_counts[:10]
sns.barplot(y=subset.index, x=subset.values)
未完待續