中文自然語言處理百萬級語料庫-ChineseSemanticKB免費下載

ChineseSemanticKB,chinese semantic knowledge base, 面向中文處理的12類、百萬規模的語意常用詞典,包括34萬抽象語意庫、34萬反義語意庫、43萬同義語義庫等,可支援句子擴充套件、轉寫、事件抽象與泛化等多種應用場景。
資源整理自網路,源地址:https://github.com/liuhuanyong/ChineseSemanticKB
專案介紹
語意知識庫是自然語言處理中十分重要的一個基礎資源,與學術界追求演算法模型不同,工業界的自然語言處理對於底層的詞彙知識庫、語意知識庫等多種資源依賴度很高,具體體現在:
1、具有落地場景的自然語言處理任務都是業務高度相關,一個業務需求剛進去,需要解決的是業務的詞彙問題,無基礎詞庫,無專案冷啓動;
2、規則和正則啓動下的工業級應用,規則的擴充套件、泛化都需要底層的詞彙網路做支撐;
3、目前包括搜尋、問答、輿情監控、事件分析等應用,與標籤體系的運作關係密切,而這與先驗的底層詞彙庫依賴性很強;
4、自然語言場景越來越關注推理層面,即所謂的「認知」層面,認知背後的各種邏輯關係庫,是驅動這一決策的根本途徑;
5、當前,面向中文開源詞庫的工作存在少量、分散的狀態,無論從規模,還是品質,都需要進一步聚合;
因此,我從過往的開源工作中進一步抽離和整理,形成了中文處理的12類、百萬規模的語意常用詞典,包括34萬抽象語意庫、34萬反義語意庫、43萬同義語義庫等,用於相關下遊任務。
專案放於dict當中,可直接下載,不建議二次建庫共用,尊重開源。
詞庫的類別
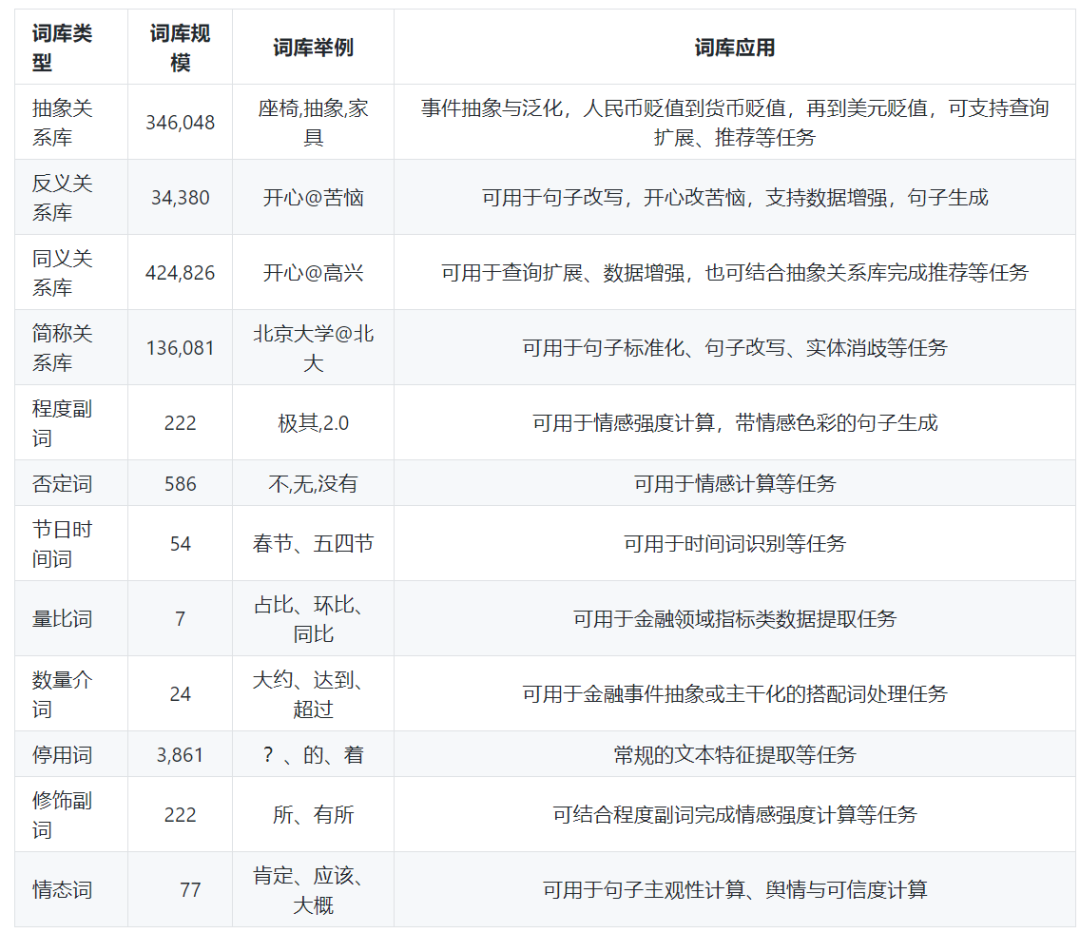
總結
1、本專案開源了一個目前可用於事件處理以及工業輿情的12類語意詞庫,總規模數目一百餘萬;
2、本專案開源的34萬抽象語意庫、34萬反義語意庫、43萬同義語義庫,在作者的實際工作中【事件處理、事理抽取、事件推理】等有重要用途;
3、中文常用語意常用詞典,均來源於公開文字+人工整理+機器抽取形成,其中若有品質不高之處,可積極批評指正;
4、中文開源事業還是要堅持做下去,儘可能地縮短自然語言處理學術界和工業界之間的鴻溝。
往期精品內容推薦
邱錫鵬DL經典教材-《神經網路與深度學習》免費pdf及ppt分享
肖桐、朱靖波老師新著-《機器翻譯統計建模與深度學習方法》中文版書籍分享
李宏毅-《深度學習/機器學習2020》中文視訊課程及ppt分享