Json概述以及python對json的相關操作(至尊寶錯過了紫霞仙子,難道你也要錯過python對json的相關操作嗎?)
Json概述以及Python對json的相關操作:
什麼是json:
JSON(JavaScript Object Notation) 是一種輕量級的數據交換格式。易於人閱讀和編寫。同時也易於機器解析和生成。它基於JavaScript Programming Language, Standard ECMA-262 3rd Edition - December 1999的一個子集。JSON採用完全獨立於語言的文字格式,但是也使用了類似於C語言家族的習慣(包括C, C++, C#, Java, JavaScript, Perl, Python等)。這些特性使JSON成爲理想的數據交換語言。
JSON建構於兩種結構:
「名稱/值」對的集合(A collection of name/value pairs)。不同的語言中,它被理解爲物件(object),紀錄(record),結構(struct),字典(dictionary),雜湊表(hash table),有鍵列表(keyed list),或者關聯陣列 (associative array)。
值的有序列表(An ordered list of values)。在大部分語言中,它被理解爲陣列(array)。
這些都是常見的數據結構。事實上大部分現代計算機語言都以某種形式支援它們。這使得一種數據格式在同樣基於這些結構的程式語言之間交換成爲可能。
jso官方說明參見:http://json.org/
Python操作json的標準api庫參考:http://docs.python.org/library/json.html
對簡單數據型別的encoding 和 decoding:
使用簡單的json.dumps方法對簡單數據型別進行編碼,例如:
|
1 2 3 4 5 6 |
|
輸出:
[[1, 2, 3], 123, 123.123, 'abc', {'key2': (4, 5, 6), 'key1': (1, 2, 3)}]
[[1, 2, 3], 123, 123.123, "abc", {"key2": [4, 5, 6], "key1": [1, 2, 3]}]
通過輸出的結果可以看出,簡單型別通過encode之後跟其原始的repr()輸出結果非常相似,但是有些數據型別進行了改變,例如上例中的元組則轉換爲了列表。在json的編碼過程中,會存在從python原始型別向json型別的轉化過程,具體的轉化對照如下:

json.dumps()方法返回了一個str物件encodedjson,我們接下來在對encodedjson進行decode,得到原始數據,需要使用的json.loads()函數:
|
1 2 3 4 |
|
輸出:
<type 'list'>
[1, 2, 3]
[[1, 2, 3], 123, 123.123, u'abc', {u'key2': [4, 5, 6], u'key1': [1, 2, 3]}]
loads方法返回了原始的物件,但是仍然發生了一些數據型別的轉化。比如,上例中‘abc’轉化爲了unicode型別。從json到python的型別轉化對照如下:
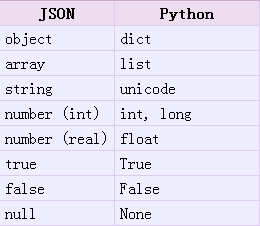
json.dumps方法提供了很多好用的參數可供選擇,比較常用的有sort_keys(對dict物件進行排序,我們知道預設dict是無序存放的),separators,indent等參數。
排序功能使得儲存的數據更加有利於觀察,也使得對json輸出的物件進行比較,例如:
|
1 2 3 4 5 6 7 8 9 10 |
|
輸出:
{"a": 123, "b": 789, "c": 456}
{"a": 123, "c": 456, "b": 789}
{"a": 123, "b": 789, "c": 456}
False
True
上例中,本來data1和data2數據應該是一樣的,但是由於dict儲存的無序特性,造成兩者無法比較。因此兩者可以通過排序後的結果進行儲存就避免了數據比較不一致的情況發生,但是排序後再進行儲存,系統必定要多做一些事情,也一定會因此造成一定的效能消耗,所以適當排序是很重要的。
indent參數是縮排的意思,它可以使得數據儲存的格式變得更加優雅。
|
1 2 3 |
|
輸出:
{
"a": 123,
"b": 789,
"c": 456
}
輸出的數據被格式化之後,變得可讀性更強,但是卻是通過增加一些冗餘的空白格來進行填充的。json主要是作爲一種數據通訊的格式存在的,而網路通訊是很在乎數據的大小的,無用的空格會佔據很多通訊頻寬,所以適當時候也要對數據進行壓縮。separator參數可以起到這樣的作用,該參數傳遞是一個元組,包含分割物件的字串。
|
1 2 3 4 5 |
|
輸出:
DATA: {'a': 123, 'c': 456, 'b': 789}
repr(data) : 30
dumps(data) : 30
dumps(data, indent=2) : 46
dumps(data, separators): 25
通過移除多餘的空白符,達到了壓縮數據的目的,而且效果還是比較明顯的。
另一個比較有用的dumps參數是skipkeys,預設爲False。 dumps方法儲存dict物件時,key必須是str型別,如果出現了其他型別的話,那麼會產生TypeError異常,如果開啓該參數,設爲True的話,則會比較優雅的過度。
|
1 2 |
|
輸出:
{"c": 456, "b": 789}
處理自己的數據型別
免費領取Python自動化學習資料 工具,面試寶典面試技巧,加QQ羣,785128166,羣內還會大佬技術交流
json模組不僅可以處理普通的python內建型別,也可以處理我們自定義的數據型別,而往往處理自定義的物件是很常用的。
首先,我們定義一個類Person。
|
1 2 3 4 5 6 7 8 9 |
|
如果直接通過json.dumps方法對Person的範例進行處理的話,會報錯,因爲json無法支援這樣的自動轉化。通過上面所提到的json和python的型別轉化對照表,可以發現,object型別是和dict相關聯的,所以我們需要把我們自定義的型別轉化爲dict,然後再進行處理。這裏,有兩種方法可以使用。
方法一:自己寫轉化函數
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 |
|
上面程式碼已經寫的很清楚了,實質就是自定義object型別和dict型別進行轉化。object2dict函數將物件模組名、類名以及__dict__儲存在dict物件裡,並返回。dict2object函數則是反解出模組名、類名、參數,建立新的物件並返回。在json.dumps 方法中增加default參數,該參數表示在轉化過程中呼叫指定的函數,同樣在decode過程中json.loads方法增加object_hook,指定轉化函數。
方法二:繼承JSONEncoder和JSONDecoder類,覆寫相關方法
JSONEncoder類負責編碼,主要是通過其default函數進行轉化,我們可以override該方法。同理對於JSONDecoder。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 |
|
對於JSONDecoder類方法,稍微有點不同,但是改寫起來也不是很麻煩。看程式碼應該就比較清楚了。