【數據結構與演算法Python描述】——Python中基於陣列的序列簡介
Python中常用的內建序列型別主要有list,str和tuple。實際上,在Python中序列可以指任何1一個可迭代物件(關於可迭代物件的概念請見Python中for回圈執行機制 機製探究以及可迭代物件、迭代器詳解),只要該可迭代物件通過實現__getitem__()方法支援使用索引方式存取元素,且實現__len__()方法返回序列的長度。
儘管list,str和tuple支援的操作十分類似,但實際上其內部的實現區別很大,鑑於後續的數據結構和演算法學習將大量使用這三種內建序列型別,因此很有必要對這三個序列型別的底層原理有一個較爲深刻的理解。
一、計算機內部儲存模型簡介
爲了能夠準確的描述Python實現序列型別的方式,首先需要簡單瞭解一下計算機的記憶體用以儲存資訊的方式:計算機以二進制位(bit)來表達資訊,最小的資訊儲存單位是位元組(byte),一個位元組一般等於8位元。
在計算機的記憶體中,以位元組爲單位的儲存單元數量衆多,爲了能夠快速地存取這些儲存單元,計算機爲這些記憶體單元進行了編號,這些編號即所謂的記憶體地址,因此可以通過如#2150或#2152來存取記憶體中的數據,且毫無疑問該基本操作的時間複雜度爲。

在實際的計算機中,記憶體地址的編號一般很長,不便於人類記憶,因此一般的高階程式語言都支援給記憶體地址起一個別名,這個別名就是變數,代表了記憶體地址,即變數是記憶體地址的別名。
對於一般的高階語言如Python,其很大的一部分功能就是維護一系列變數,進而對其進行相關操作,例如:我們可能希望一個電腦儲存由26個英文字元組成的字母表。
當然,可以使用26個不同的變數來實現這個需求,但是如果可以使用代表了一段編號連續記憶體地址的變數名來表示一個字母表,進而可結合索引值來存取字母表中對應的字母字元,這樣可能更加簡潔優雅,這種使用一段連續記憶體來表示一系列同類型數據的方式即爲陣列。
二、字串序列的記憶體模型
實際上,在Python中,字串就是典型的採用了上述陣列記憶體模型的序列型別,一個Python的字串使用2個位元組表示一個Unicode字元,因此一個6字元的字串如'SAMPLE'在記憶體中以佔用12個連續位元組的方式儲存:

上述的字串即可稱爲一個6字元的陣列,陣列中的每個儲存位置可稱爲單元,且可使用起始於0的整數索引來描述其在陣列中的位置,例如:上述通過陣列表示的字串中,索引爲4的單元儲存了字元'L',該字元佔用了記憶體地址#2154和#2155處的2個位元組。
需要注意的是,陣列模型的每一個單元佔用相同數量的位元組,這是存取陣列中的單元具有時間複雜度的基礎。
三、列表、元組的記憶體模型
在Python中,對於列表
list和元組tuple而言,直譯器採用了所謂物件參照(關於參照的概念請見Python中變數賦值的本質——「參照」的概念)陣列(array of object references)的機制 機製來表示二者的範例物件在記憶體中的模型。
上述概念較爲晦澀,這裏通過一個例子來對其進行解釋:假設現在有一套醫院的醫療資訊系統,該系統需要記錄病人所對應的牀號,如果假設醫院有200張牀,且牀的編號爲從0到199,在Python中我們知道可以簡單的用列表表示爲:
[Rene, Joseph, Janet, Jonas, Helen, Virginia, ... ]
如果我們假設Python依然使用了和字串一樣的陣列模型來表示上述列表,那麼必然地,Python直譯器必須要滿足陣列每個單元佔用相同數量位元組的要求。
問題是,列表的每一個元素都是字串,而字串天然地就有不同的長度。當然,直譯器可以爲每一個儲存字串的單元都分配足夠的空間,使之可以儲存最大長度的字串(比如爲陣列的每個單元都分配100個位元組),但是這樣會產生很大的記憶體浪費。
爲了避免上述記憶體浪費的問題,Python使用瞭如下圖所示的參照型陣列概念,即連續的陣列記憶體空間中並不直接儲存每個字串,而是儲存了每個字串所在的記憶體地址,這是因爲對於同一類(如:64位元、32位元)硬體而言,記憶體地址的長度一般都是一樣的,如對於64位元的機器,記憶體地址長度爲8個位元組。
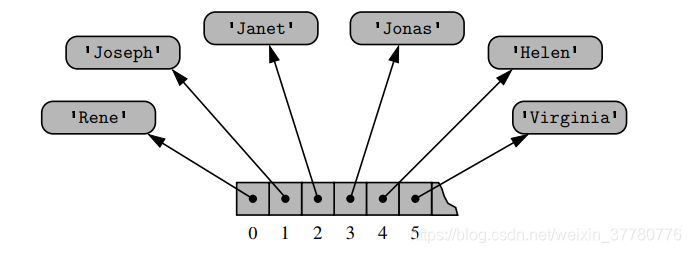
Python中的列表和元素均採用了上述參照型陣列的記憶體模型,因此基於上述分析易知:二者支援通過索引方式存取每個元素的時間複雜度爲。
更進一步地,如果上述醫療資訊系統希望通過列表儲存關於每個病人更加詳盡的資訊,可以考慮使用一個Patient類的範例來實現,從上述列表的實現原理來看,這也將遵循同樣的原則,即列表中儲存了每一個Patient範例的參照。實際上,None物件的參照同樣可以作爲列表的一個元素,來表示空置的牀位。
四、兩種記憶體模型優劣比較
針對Python中三種常見的序列型別str,list和tuple,上述分別介紹了兩種記憶體模型,爲後面討論簡單起見,後續將str對應的記憶體模型稱爲緊湊型陣列,list和tuple對應的記憶體模型稱爲參照型陣列:
- 緊湊型陣列:陣列的單元中儲存了實際的數據,如:字串的每一個字元;
- 參照型陣列:陣列的單元中儲存的是實際數據所處的記憶體地址。
關於緊湊型陣列和參照型陣列二者的優劣:
- 緊湊型陣列在儲存時比較節省記憶體,因爲參照型陣列需要額外儲存每一個元素所在的記憶體地址;
- 緊湊型陣列在計算時效率較高,因爲數據以連續的方式儲存在一片記憶體中,數據存取較爲直接,而對於參照型陣列,通過每個單元中的記憶體地址存取具體數據的過程還需額外由快取等部分處理;
- 參照型陣列比較通用,因爲緊湊型陣列的一條限制是,每一個單元所儲存的元素大小必須要求一致。
五、自定義緊湊型陣列序列
鑑於緊湊型陣列序列的優勢,Python爲開發者提供了自定義緊湊型陣列序列的模組array。如:
from array import array
primes = array('i', [2, 3, 5, 7, 11, 13, 17, 19])
上述通過array模組中的array類即建立了一個緊湊型陣列的列表,其中的每一個單元儲存了一個素數:

上述的primes變數所表示的物件所支援的各種方法和列表基本一致,只是需要注意的是:array類的__init__()方法還必需一個型別碼(type code)作爲第一個參數,該參數指明瞭儲存在陣列單元中的數據型別,例如:上述'i'表示陣列單元中將且僅將用於儲存有符號的整數。
型別程式碼允許直譯器可以準確地提前確定陣列中的每個元素將佔用多少個位元組。對於array模組,其中常見的型別碼如下表所示,該表的型別主要基於C語言(Python使用範圍最廣的一類直譯器就是用C語言寫的)的原生數據型別,雖然C語言的數據型別確切大小和系統相關,但典型的大小如下邊所示:
| 型別程式碼 | Python數據型別 | C語言數據型別 | 記憶體大小 |
|---|---|---|---|
'b' |
int |
signed char |
1 |
'B' |
int |
unsigned char |
1 |
'u' |
Unicode character |
Py_UNICODE |
2 |
'h' |
int |
signed short |
2 |
'H' |
int |
unsigned short |
2 |
'i' |
int |
signed int |
2 |
'I' |
int |
unsigned int |
2 |
'l' |
int |
signed long |
4 |
'L' |
int |
unsigned long |
4 |
'q' |
int |
signed long long |
8 |
'Q' |
int |
unsigned long long |
8 |
'f' |
float |
float |
4 |
'd' |
float |
double |
8 |
需要注意的是,array模組不支援爲使用者自定義的數據型別(如Patient類建立的病人範例)建立緊湊型陣列,要實現這樣的需求,需要使用更底層的模組ctypes。
需要注意的是,雖然字典也支援
__getitem__()和__len__()方法,但是字典通常被視爲對映而不是序列,因爲字典的查詢機制 機製是通過任意不可變型別的鍵而不是整數。 ↩︎