小林求職記(五)深入分佈式快取
在之前王哥的輔助之下,小明的簡歷成功被內推進到了王哥所在公司。由於一面就是王哥自己,所以簡單聊聊了便過去了。接下來,二面的面試官來了。
二面面試官看上去比較年輕的消瘦,戴着一副眼鏡,頭髮比較稀疏,看上去像是有十多年經驗的樣子,兩人在一處安靜的地方坐了下來,開始了第二輪面試。
面試官:嗯嗯,你好,請先簡單自我介紹一下自己吧。
小林:嗯嗯,你好,我是XXXX,之前在XXX(此處省略200字介紹)
面試官點了點頭,一副迷之微笑的表情,然後低頭過了一遍簡歷的內容。直到看見了
「負責過電商系統的秒殺專案後端開發模組,並且對於快取有過較爲深入的研究」這麼一行字眼。
面試官:我對你這上邊寫的秒殺專案和快取研究有些感興趣,想深入瞭解一下其中的細節點。
小林:嗯嗯,好的。
面試官:先從簡單問起吧,在秒殺業務場景中,你在下單的時候是如何防止庫存超賣發生的呢?
小林:嗯嗯,首先在活動開始之前,我們會進行一次商品庫存的預熱處理,將數據庫的資訊載入到redis中,然後扣除庫存的時候會在redis裏面進行處理,最後當庫存爲0的時候,會觸發一個方法去觸發關閉前端秒殺活動的開關。每次當有使用者提交下單請求的時候,會先將請求通過mq來進行削峯,在進行扣除庫存的時候,會先更新redis裏面的庫存量,最後再統一更新db。
面試官:爲啥不直接更新db呢?
小林:像秒殺這種典型的高併發場景,直接對db層進行寫操作對數據庫的存取壓力實在是太大了,併發量過大容易壓垮數據庫。
面試官:嗯嗯,那爲什麼要把庫存儲存在redis中呢?
小林:具體有兩個原因,首先第一點, redis的併發承載能力足以應付我上家公司的秒場景所需。還有一點非常重要的就是,redis是單執行緒模型,在做庫存減1操作的時候不會出現數據競爭導致商品超賣的情況發生。
面試官似乎對小林說的這個redis單執行緒模型感到一些興趣了,於是又接着深入展開了對於快取部分的提問。
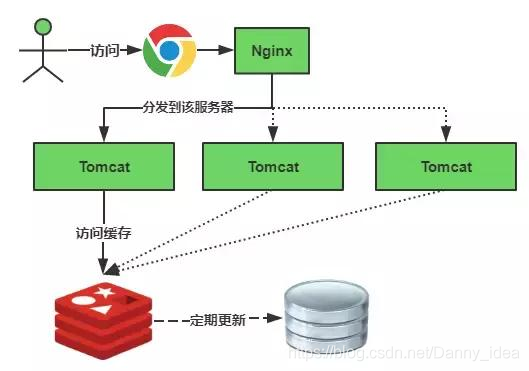
面試官:等等,既然你說了redis的併發承載能力強,但是又說是單執行緒模型,能解釋下爲什麼單執行緒模型下redis也能有較好的效能承載能力呢?
小林在面試之前正好準備了這方面的知識點內容,於是便拿出了自己以前所學習過的知識內容點進行了講解。
小林:redis採用了非阻塞網路IO模型,適合用於快速地操作邏輯。所謂的非阻塞網路io模型,這有點類似於java裏面的nio。當有多個請求發送到伺服器端的時候,實際上會有一個檔案事件處理器同時監聽多個通訊端,並且根據通訊端目前執行的任務來關聯不同的事件處理器。
這些不同的通訊端用於給事件處理器將其分發給不同的邏輯程式處理,事件處理器只需要將它們做系結即可。這些處理事件可能會併發地出現,但是io多路複用程式是會將所有產生的通訊端都存入一個 有序且同步的佇列中(單執行緒的核心點),最後redis會有逐一地對這個佇列中的元素進行處理。這裏就是爲啥單執行緒的原因。在一開始學習這塊知識點的時候,爲了更好地深入理解,我去用了nio程式來做比對。
不同的通訊端事件對應的處理器也聽類似的,例如說accept,read,write等事件,應對不同連線的時候處理邏輯也不同。
我當時是結合了實際業務來進行設計的,由於商品有多種,因此對於商品的庫存數目採用了key-value的結構,按照商品的id作爲key,庫存作爲value儲存。對於庫存的減少是採用了decr指令操作,這條指令實際上是一條原子性操作,之所以原子性操作是因爲redis的單執行緒特性。
面試官:嗯嗯,既然上邊你解釋到了redis是單執行緒模型,那麼在使用redis的時候需要注意些什麼嗎?或者說對於redis的儲存有什麼優化技巧可以講解下嗎?
這時候小林想起了之前王哥發給他的一份面試筆記,上邊記錄了很多關於redis的知識點,其中就有提及到過這一點。
小林:嗯嗯,在redis6.0之前,redis還是處於一個單執行緒的狀態,我們就拿單執行緒版本的redis來說吧。
拒絕bigkey的出現場景
首先key的值不宜設定地過大,儘量保證簡潔明瞭,減少對於記憶體的佔用。通常來說,當一個單獨儲存的value值大於10kb的時候就會被認爲是bigkey了。
實際上在redis的內部實現中,
對於 set key 「some string」 這樣的指令而言,底層的c語言會自己構建一個稱爲SDS的結構體(類似java裏面的類物件)進行儲存。
這個結構體包含了下邊資訊:
struct sdshdr {
int len;
int free;
char buf[];
}
內部沒有直接採用c語言自帶的字串,好處有以下幾點:
減少原先繁瑣的記憶體擴增問題。(會根據初始化的值,提前給出更多的空間,避免出現空間溢位問題)
通過空間預分配機制 機製來減少記憶體重分配問題。(其實記憶體重分配是一個非常複雜的過程,需要驚動到os操作系統層面的修改,
其中涉及到了非常複雜的操作,因此sds在初始化過程中儘量幫我們把這塊給優化處理)
針對bigkey而言,其實還有很多點可以注意;
1.對於hash,list,set,zset這類數據結構而言,儘量不要讓其數目超過5000個。
假設我們儲存了一個大小爲100萬元素的zset數據結構到redis中,並且設計了1小時過期的機制 機製,那麼在元素到期時候觸發
了刪除操作,這將會對redis自身造成堵塞。
2.如何避免上述在刪除過程中的堵塞情況?
首先應該從根源上避免這類設計的存在,如果實際線上數據庫存在這類數據資訊,那麼可以結合redis自身提供的機制 機製 非同步
刪除機制 機製 (需要redis4.0之後才具有)
3.bigkey是如何產生的?
常見的產生bigkey場景:
1)例如一些社交類產品,粉絲列表,爲了減少對於db的存取,會根據註冊使用者的id來系結相關的list結構儲存粉絲資訊,假若遇到了某些明星,大v,那麼如果這個list沒有做過相關的調優處理就很容易轉換爲一個bigkey。
2)假設用list來儲存使用者快取資訊,當存取量增加的時候也很容易產生bigkey。
3)將相關的數據儲存到redis的一些複雜數據結構中(list,set相關型別)的時候,需要考慮,是否每個儲存項的欄位都有必要存入,如果是無關必要的欄位則可以忽略掉。
4.如何對bigkey做優化處理?
如果線上已經有存在這種情況的話,不建議直接暴力刪除,最好是通過一些拆解手段來做平滑過濾。例如說一個list拆解爲多個list1,list2,list3,如果是個map的話也是可以拆解爲多個小map,另外提取元素的時候不要隨意用hgetall這類佔用網路頻寬資源的指令。
面試官:嗯嗯,那你們之前的專案組裏面會有做一些禁止命令的設定嗎?防止某些不安全指令在線上環境產生造成危害。
小林:額,這個我就不是很清楚了,應該是要有的,平時沒有太過注意。
面試官:嗯嗯,其實我們這邊的生產環境是會精緻實用keys,flushall,flushdb這類命令的,主要是通過rename機制 機製來禁用掉它。
ps:
可以藉助redis內部的rename機制 機製關閉危險指令的使用
通過修改redis.conf中的SECURITY項,在裡頭新增以下幾行,即可實現對危險指令的禁用
rename-command FLUSHALL ""
rename-command FLUSHDB ""
rename-command CONFIG ""
rename-command KEYS ""
對於命令的查詢推薦通過scan來替代keys
面試官:看來你對於redis還是有些研究的啊。那麼你能講解下更深一些層次的快取嗎,例如說cpu層面的快取管理機制 機製?
小林此時突然腦袋一片空白,在面試之前並沒有對操作系統底層的知識做過複習,一下子懵逼了。
小林:這塊我不是太瞭解。。
面試官:哦,那我簡單和你講解下吧。
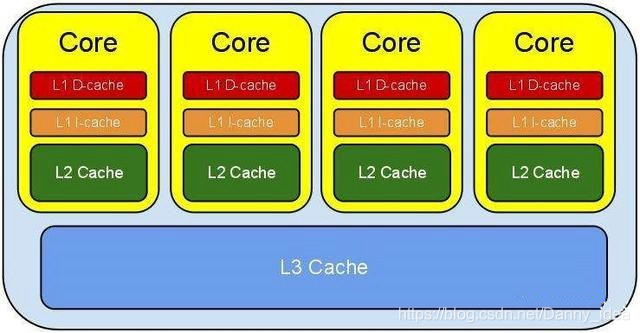
cpu內部的其實經常會需要用到記憶體中的數據做運算和讀寫操作,但是cpu的計算效能和記憶體的計算效能差距非常巨大,針對這類密集型計算的物件,後續人類發明了「快取」的概念。
早期的時候人們只發明瞭一級快取,後來又增加了L2,L3級別的快取。將快取分爲了L1,L2,L3,其速度值大小爲L3<L2<L1,當cpu需要獲取數據的時候會先從自己的暫存器中提取數據,然後再從L1中查詢,L1都能查詢的快取數據若沒有命中,則會返回到L2查詢,如果L2也查詢不到就會追溯到L3查詢,通常情況下L3中能夠命中80%的數據資訊。L3如果沒有命中數據則會到記憶體裏面查詢。
爲什麼要分這麼多級的快取?
因爲不同級別的快取速度差異都巨大,運算越快的快取製作難度越高,成本也越高。
爲什麼不把java程式儲存到cpu的多級快取中呢?
別逗了,cpu的多級快取是數據內核層面的東西,java儲存的數據是屬於jvm虛擬機器層面的玩意,兩者根本不在一個層面上,而且cpu的多級快取儲存空間相對於記憶體而言也非常小。
在面對這麼多級的快取數據中,如何保證查詢數據的正確和有效呢?於是便有了一個叫做MESI的快取一致性協定。
聽了面試官的簡單介紹後,小林似乎發現自己還是有部分知識體系存在不足之處,連上露出了尷尬而不失禮貌的微笑。
面試官: 好吧,那我們繼續。你可以講解下之前自己在秒殺專案中使用到的快取設計方案嗎?例如說一些機器的部署方面?
小林:emmmm,讓我思考一下先(腦海中瘋狂回憶以前學過的筆記內容點和工作接觸點)
(一兩分鐘後…)
嗯呢,我思緒準備好了。
之前的專案中採用的是sentinel架構來進行設計redis儲存。sentinel一共部署了三臺機器,一臺作爲主機,另外兩臺作爲從機器,每臺機器上邊都設立了一個哨兵的角色,當主節點出現異常的時候會有從節點來頂替。以前在預發佈環境曾經遇到過一個問題,當時是做容災模擬演練,當日模擬中將redis主節點和從節點之間的網路做了截斷操作,導致從節點的機器一直沒有和主節點的機器進行網路通訊,於是此時便從從機器中選定了一臺機器作爲主節點,在主從做切換期間redis服務曾經出現過異常中斷服務的情況。
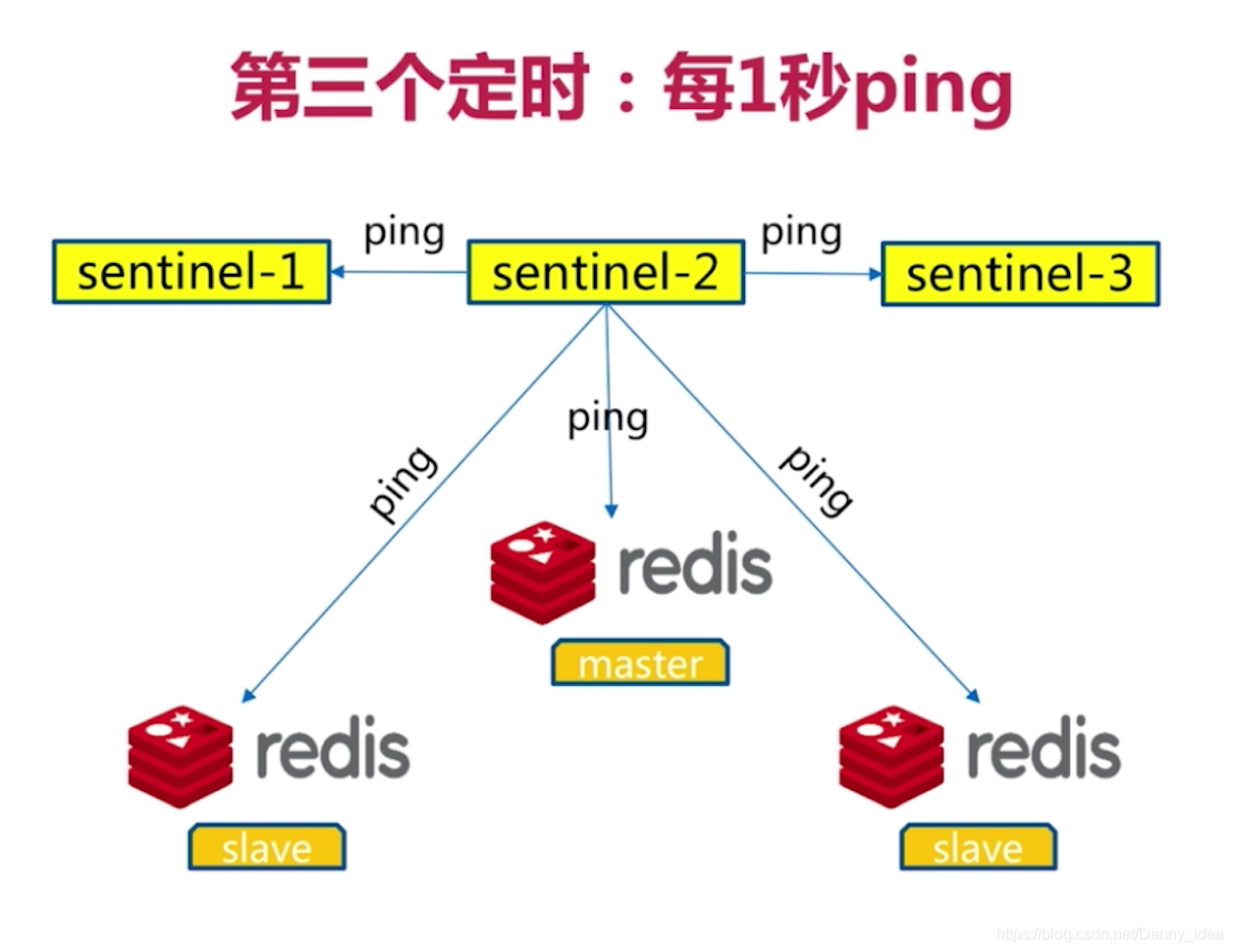
面試官:嗯嗯,那麼請你講解下redis主從切換過程中可能會遇到哪些生產的異常問題呢?
小林:嗯嗯,我大概知道那麼幾個常見的場景吧。例如說在一些結合redis用的分佈式鎖,在這一時刻可能會失效,假設說秒殺活動的高峯期,主節點掛了,那麼分佈式鎖就會失效,可能會引發後續一連串可怕的事情發生,因此對於介面的壓測和限流是非常重要的。
emm,還有的話例如說一些知識在redis中儲存並沒有實際落入db做持久化的數據也會丟失,假設一些購物車中存放的數據,可能會在主從切換中的那段時間裏面突然發現 「加入購物車」 失效了!
面試官:嗯嗯,那麼你對於主從切換中的選舉原理瞭解嗎?可以簡單介紹下嗎?
小林:emmm,這塊並不是特別瞭解。
ps:
關於redis的sentinel架構採用到的raft選舉演算法考點
面試官:好吧。那你在做redis設計的時候主要的目的還是爲了防止請求進入到db層面,在這方面還有哪些細節點也需要注意到的嗎?
小林 : 需要注意一下快取的過期時間,假設某些熱點數據是同時存入到redis的話,那麼它們的過期時間最好是能夠做成隨機值,防止出現時間到達後快取大面積失效,導致快取擊穿的情況大規模發生。
面試官:嗯嗯,關於快取的模組大概就先問到這裏吧。你還有什麼需要問我嗎?
看來這次面試似乎小林在面試官前的表現已經達到了入職的技術要求,距離成功上岸似乎還差一步之遙的感覺。
小林:嗯嗯,請問我還有機會嗎?
面試官:你先回家等下通知吧,我們這邊和hr商量一下再做決定。
未完待續….