一文帶你由淺入深理解Redis!
Windows Redis
安裝
鏈接: pan.baidu.com/s/1MJnzX_qR… 提取碼: 2c6w 複製這段內容後開啓百度網路硬碟手機App,操作更方便哦
無腦下一步即可
使用
出現錯誤:
creating server tcp listening socket 127.0.0.1:6379: bind No error
解決方案:
- redis-cli.exe
- shutdown
- exit
- redis-server.exe redis.windows.conf
啓動:redis-server.exe redis.windows.conf
用戶端啓動:redis-cli.exe (不修改設定的話預設即可)
redis-cli.exe -h 127.0.0.1 -p 6379 -a password
基本檔案說明
| 可執行檔案 | 作用說明 |
|---|---|
| redis-server | redis服務 |
| redis-cli | redis命令列工具 |
| redis-benchmark | 基準效能測試工具 |
| redis-check-aof | AOF持久化檔案檢測和修復工具 |
| redis-check-dump | RDB持久化檔案檢測和修復工具 |
| redis-sentinel | 啓動哨兵 |
| redis-trib | cluster叢集構建工具 |
基礎命令
| 命令 | 說明 |
|---|---|
| keys * | redis允許模糊查詢key 有3個萬用字元 *、?、[] |
| del key | 刪除key |
| exists kxm | 判斷是否存在 |
| expire key 20 | 設定過期時間 - 秒 |
| pexpire key 20000 | 設定過期時間 - 毫秒 |
| move kxm 2 | 移動key到指定位置庫中 2號庫 |
| persist key | 移除過期時間,key將會永久存在 成功設定返回1 否則返回0 |
| pttl key | 以毫秒爲單位返回 key 的剩餘的過期時間 |
| ttl key | 以秒爲單位,返回給定 key 的剩餘生存時間 |
| randomkey | 從當前數據庫中隨機返回一個 key |
| rename key newkxy | 更改key的名字,如果重複了會覆蓋 |
| renamenx kxm key | 僅當 newkey 不存在時,將 key 改名爲 newkey |
| type key | 返回 key 所儲存的值的型別 |
| select 0 | 選擇第一個庫 |
| ping | 返回PONG 表示連線正常 |
| quit | 關閉當前連線 |
字串命令
| 命令 | 說明 |
|---|---|
| set key aaa | 設定指定 key 的值 |
| get key | 獲取指定 key 的值 |
| getrange key 0 1 | 返回 key 中字串值的子字元 包含 0 和 1 包含關係 |
| getset key aaaaaaaa | 將給定 key 的值設爲 value ,並返回 key 的舊值(old value) |
| mget key kxm | 獲取所有(一個或多個)給定 key 的值 |
| setex test 5 「this is my test」 | 將值 value 關聯到 key ,並將 key 的過期時間設爲 seconds (以秒爲單位) |
| setnx test test | 只有在 key 不存在時設定 key 的值 (用於分佈式鎖) |
| strlen test | 返回 key 所儲存的字串值的長度 |
| mset key1 「1」 key2 「2」 | 同時設定一個或多個 key-value 對 |
| msetnx key3 「a」 key2 「b」 | 同時設定一個或多個 key-value 對,當且僅當所有給定 key 都不存在 其中一個失敗則全部失敗 |
| incr key | 將 key 中儲存的數位值增一 -> key的值 比如爲 數位型別字串 返回增加後的結果 |
| incrby num 1000 | 將 key 中儲存的數位值增指定的值 -> key的值 比如爲 數位型別字串 返回增加後的結果 |
| decr key | 同 -> 減一 |
| decrby num 500 | 同 -> 減指定值 |
| append key 1123123 | 如果 key 已經存在並且是一個字串, APPEND 命令將指定的 value 追加到該 key 原來值(value)的末尾 返回字串長度 |
雜湊(Hash)命令
| 命令 | 說明 |
|---|---|
| hdel key field1 [field2] | 刪除一個或多個雜湊表欄位 |
| hexistskey field | 檢視雜湊表 key 中,指定的欄位是否存在 |
| hget key field | 獲取儲存在雜湊表中指定欄位的值 |
| hgetall key | 獲取在雜湊表中指定 key 的所有欄位和值 |
| hincrby hash yeary 1 | 爲雜湊表 key 中的指定欄位的整數值加上增量 increment |
| hkeys hash | 獲取所有雜湊表中的欄位 |
| hlen hash | 獲取雜湊表中欄位的數量 |
| hmget hash name year | 獲取所有給定欄位的值 |
| hmset hash name 「i am kxm」 year 24 | 同時將多個 field-value (域-值)對設定到雜湊表 key 中 |
| hset hash name kxm | 將雜湊表 key 中的欄位 field 的值設爲 value |
| hsetnx key field value | 只有在欄位 field 不存在時,設定雜湊表欄位的值 |
| hvals hash | 獲取雜湊表中所有值 |
| hexists hash name | 是否存在 |
編碼: field value 值由 ziplist 及 hashtable 兩種編碼格式
欄位較少的時候採用ziplist,欄位較多的時候會變成hashtable編碼
列表(List)命令
Redis列表是簡單的字串列表,按照插入順序排序。你可以新增一個元素到列表的頭部(左邊)或者尾部(右邊)
一個列表最多可以包含 232 - 1 個元素 (4294967295, 每個列表超過40億個元素)
容量 -> 集合,有序集合也是如此
| 命令 | 說明 |
|---|---|
| lpush list php | 將一個值插入到列表頭部 返回列表長度 |
| lindex list 0 | 通過索引獲取列表中的元素 |
| blpop key1 [key2 ] timeout | 移出並獲取列表的第一個元素, 如果列表沒有元素會阻塞列表直到等待超時或發現可彈出元素爲止 |
| brpop key1 [key2 ] timeout | 移出並獲取列表的最後一個元素, 如果列表沒有元素會阻塞列表直到等待超時或發現可彈出元素爲止 |
| linsert list before 3 4 | 在值 3 前插入 4 前即爲頂 |
| linsert list after 4 5 | 在值4 後插入5 |
| llen list | 獲取列表長度 |
| lpop list | 移出並獲取列表的第一個元素 |
| lpush list c++ c | 將一個或多個值插入到列表頭部 |
| lrange list 0 1 | 獲取列表指定範圍內的元素 包含0和1 -1 代表所有 (lrange list 0 -1) |
| lrem list 1 c | 移除list 集閤中 值爲 c 的 一個元素, 1 代表count 即移除幾個 |
| lset list 0 「this is update」 | 通過索引設定列表元素的值 |
| ltrim list 1 5 | 對一個列表進行修剪(trim),就是說,讓列表只保留指定區間內的元素,不在指定區間之內的元素都將被刪除 |
| rpop list | 移除列表的最後一個元素,返回值爲移除的元素 |
| rpush list newvalue3 | 從底部新增新值 |
| rpoplpush list list2 | 轉移列表的數據 |
集合(Set)命令
Set 是 String 型別的無序集合。集合成員是唯一的,這就意味着集閤中不能出現重複的數據
| 命令 | 說明 |
|---|---|
| sadd set java php c c++ python | 向集合新增一個或多個成員 |
| scard set | 獲取集合的成員數 |
| sdiff key1 [key2] | 返回給定所有集合的差集 數學含義差集 |
| sdiffstore curr set newset (sdiffstore destination key1 [key2]) | 把set和 newset的差值儲存到curr中 |
| sinter set newset | 返回給定所有集合的交集 |
| sinterstore curr set newset (sinterstoredestination key1 [key2]) | 同 |
| sismember set c# | 判斷 member 元素是否是集合 key 的成員 |
| smembers set | 返回集閤中的所有成員 |
| srandmember set 2 | 隨機抽取兩個key (抽獎實現美滋滋) |
| smove set newtest java (smove source destination member) | 將 member 元素從 source 集合移動到 destination 集合 |
| sunion set newset | 返回所有給定集合的並集 |
| srem set java | 刪除 |
| spop set | 從集閤中彈出一個元素 |
| sdiff | sinter | sunion | 操作:集合間運算:差集 |
有序集合(sorted set)命令
Redis 有序集合和集合一樣也是string型別元素的集合,且不允許重複的成員。
不同的是每個元素都會關聯一個double型別的分數。redis正是通過分數來爲集閤中的成員進行從小到大的排序。
有序集合的成員是唯一的,但分數(score)卻可以重複。
| 命令 | 說明 |
|---|---|
| zadd sort 1 java 2 python | 向有序集合新增一個或多個成員,或者更新已存在成員的分數 |
| zcard sort | 獲取有序集合的成員數 |
| zcount sort 0 1 | 計算在有序集閤中指定區間分數的成員數 |
| zincrby sort 500 java | 有序集閤中對指定成員的分數加上增量 increment |
| zscore sort java | 返回有序集中,成員的分數值 |
| zrange sort 0 -1 | 獲取指定序號的值,-1代表全部 |
| zrangebyscore sort 0 5 | 分數符合範圍的值 |
| zrangebyscore sort 0 5 limit 0 1 | 分頁 limit 0代表頁碼,1代表每頁顯示數量 |
| zrem sort java | 移除元素 |
| zremrangebyrank sort 0 1 | 按照排名範圍刪除元素 |
| zremrangebyscore sort 0 1 | 按照分數範圍刪除元素 |
| zrevrank sort c# | 返回有序集閤中指定成員的排名,有序整合員按分數值遞減(從大到小)排序 |
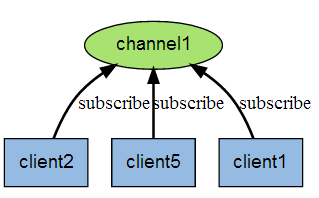
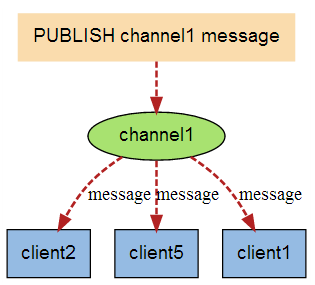
發佈訂閱
開啓兩個用戶端
A用戶端訂閱頻道: subscribe redisChat (頻道名字爲 redisChat)
B用戶端發佈內容: publish redisChat 「Hello, this is my wor」 (內容是 hello…)
A用戶端即爲自動收到內容, 原理圖如下:
| 命令 | 說明 |
|---|---|
| pubsub channels | 檢視當前redis 有多少個頻道 |
| pubsub numsub chat1 | 檢視某個頻道的訂閱者數量 |
| unsubscrible chat1 | 退訂指定頻道 |
| psubscribe java.* | 訂閱一組頻道 |
Redis 事務
Redis 事務可以一次執行多個命令, 並且帶有以下三個重要的保證:
- 批次操作在發送 EXEC 命令前被放入佇列快取
- 收到 EXEC 命令後進入事務執行,事務中任意命令執行失敗,其餘的命令依然被執行
- 在事務執行過程,其他用戶端提交的命令請求不會插入到事務執行命令序列中
一個事務從開始到執行會經歷以下三個階段:
- 開始事務
- 命令入隊
- 執行事務
注意:redis事務和數據庫事務不同,redis事務出錯後最大的特點是,一剩下的命令會繼續執行,二出錯的數據不會回滾
| 命令 | 說明 |
|---|---|
| multi | 標記一個事務開始 |
| exec | 執行事務 |
| discard | 事務開始後輸入命令入隊過程中,中止事務 |
| watch key | 監視一個(或多個) key ,如果在事務執行之前這個(或這些) key 被其他命令所改動,那麼事務將被打斷 |
| unwatch | 取消 WATCH 命令對所有 key 的監視 |
Redis 伺服器命令
| 命令 | 說明 |
|---|---|
| flushall | 刪除所有數據庫的所有key |
| flushdb | 刪除當前數據庫的所有key |
| save | 同步儲存數據到硬碟 |
Redis 數據備份與恢復
Redis SAVE 命令用於建立當前數據庫的備份
如果需要恢復數據,只需將備份檔案 (dump.rdb) 移動到 redis 安裝目錄並啓動服務即可。獲取 redis 目錄可以使用 CONFIG 命令
Redis 效能測試
redis 效能測試的基本命令如下:
redis目錄執行:redis-benchmark [option] [option value]
// 會返回各種操作的效能報告(100連線,10000請求)
redis-benchmark -h 127.0.0.1 -p 6379 -c 100 -n 10000
// 100個位元組作爲value值進行壓測
redis-benchmark -h 127.0.0.1 -p 6379 -q -d 100
複製程式碼
Java Redis
Jedis
<!-- jedis -->
<dependency>
<groupId>redis.clients</groupId>
<artifactId>jedis</artifactId>
<version>2.8.2</version>
</dependency>
複製程式碼
Jedis設定
############# redis Config #############
# Redis數據庫索引(預設爲0)
spring.redis.database=0
# Redis伺服器地址
spring.redis.host=120.79.88.17
# Redis伺服器連線埠
spring.redis.port=6379
# Redis伺服器連線密碼(預設爲空)
spring.redis.password=123456
# 連線池中的最大空閒連線
spring.redis.jedis.pool.max-idle=8
# 連線池中的最小空閒連線
spring.redis.jedis.pool.min-idle=0
複製程式碼
JedisConfig
@Configuration
public class JedisConfig extends CachingConfigurerSupport {
@Value("${spring.redis.host}")
private String host;
@Value("${spring.redis.port}")
private int port;
@Value("${spring.redis.password}")
private String password;
@Value("${spring.redis.max-idle}")
private Integer maxIdle;
@Value("${spring.redis.min-idle}")
private Integer minIdle;
@Bean
public JedisPool redisPoolFactory(){
JedisPoolConfig jedisPoolConfig = new JedisPoolConfig();
jedisPoolConfig.setMaxIdle(maxIdle);
jedisPoolConfig.setMinIdle(minIdle);
jedisPoolConfig.setMaxWaitMillis(3000L);
int timeOut = 3;
return new JedisPool(jedisPoolConfig, host, port, timeOut, password);
}
}
複製程式碼
基礎使用
@RunWith(SpringRunner.class)
@SpringBootTest(classes = KerwinBootsApplication.class)
public class ApplicationTests {
@Resource
JedisPool jedisPool;
@Test
public void testJedis () {
Jedis jedis = jedisPool.getResource();
jedis.set("year", String.valueOf(24));
}
}
複製程式碼
SpringBoot redis staeter RedisTemplate
<!-- redis -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>
<!-- redis 2.X 更換爲commons-pool2 連線池 -->
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-pool2</artifactId>
</dependency>
複製程式碼
############# redis Config #############
# Redis數據庫索引(預設爲0)
spring.redis.database=0
# Redis伺服器地址
spring.redis.host=120.79.88.17
# Redis伺服器連線埠
spring.redis.port=6379
# Redis伺服器連線密碼(預設爲空)
spring.redis.password=123456
# 連線池最大連線數(使用負值表示沒有限制)
spring.redis.jedis.pool.max-active=200
# 連線池最大阻塞等待時間(使用負值表示沒有限制)
spring.redis.jedis.pool.max-wait=1000ms
# 連線池中的最大空閒連線
spring.redis.jedis.pool.max-idle=8
# 連線池中的最小空閒連線
spring.redis.jedis.pool.min-idle=0
# 連線超時時間(毫秒)
spring.redis.timeout=1000ms
複製程式碼
// Cache註解設定類
@Configuration
public class RedisCacheConfig {
@Bean
public KeyGenerator simpleKeyGenerator() {
return (o, method, objects) -> {
StringBuilder stringBuilder = new StringBuilder();
stringBuilder.append(o.getClass().getSimpleName());
stringBuilder.append(".");
stringBuilder.append(method.getName());
stringBuilder.append("[");
for (Object obj : objects) {
stringBuilder.append(obj.toString());
}
stringBuilder.append("]");
return stringBuilder.toString();
};
}
@Bean
public CacheManager cacheManager(RedisConnectionFactory redisConnectionFactory) {
return new RedisCacheManager(
RedisCacheWriter.nonLockingRedisCacheWriter(redisConnectionFactory),
// 預設策略,未設定的 key 會使用這個
this.getRedisCacheConfigurationWithTtl(15),
// 指定 key 策略
this.getRedisCacheConfigurationMap()
);
}
private Map<String, RedisCacheConfiguration> getRedisCacheConfigurationMap() {
Map<String, RedisCacheConfiguration> redisCacheConfigurationMap = new HashMap<>(16);
redisCacheConfigurationMap.put("redisTest", this.getRedisCacheConfigurationWithTtl(15));
return redisCacheConfigurationMap;
}
private RedisCacheConfiguration getRedisCacheConfigurationWithTtl(Integer seconds) {
Jackson2JsonRedisSerializer<Object> jackson2JsonRedisSerializer = new Jackson2JsonRedisSerializer<>(Object.class);
ObjectMapper om = new ObjectMapper();
om.setVisibility(PropertyAccessor.ALL, JsonAutoDetect.Visibility.ANY);
om.enableDefaultTyping(ObjectMapper.DefaultTyping.NON_FINAL);
jackson2JsonRedisSerializer.setObjectMapper(om);
RedisCacheConfiguration redisCacheConfiguration = RedisCacheConfiguration.defaultCacheConfig();
redisCacheConfiguration = redisCacheConfiguration.serializeValuesWith(
RedisSerializationContext
.SerializationPair
.fromSerializer(jackson2JsonRedisSerializer)
).entryTtl(Duration.ofSeconds(seconds));
return redisCacheConfiguration;
}
}
複製程式碼
// RedisAutoConfiguration
@Configuration
@EnableCaching
public class RedisConfig {
@Bean
@SuppressWarnings("all")
public RedisTemplate<String, Object> redisTemplate(RedisConnectionFactory factory) {
RedisTemplate<String, Object> template = new RedisTemplate<String, Object>();
template.setConnectionFactory(factory);
Jackson2JsonRedisSerializer jackson2JsonRedisSerializer = new Jackson2JsonRedisSerializer(Object.class);
ObjectMapper om = new ObjectMapper();
om.setVisibility(PropertyAccessor.ALL, JsonAutoDetect.Visibility.ANY);
om.enableDefaultTyping(ObjectMapper.DefaultTyping.NON_FINAL);
jackson2JsonRedisSerializer.setObjectMapper(om);
StringRedisSerializer stringRedisSerializer = new StringRedisSerializer();
// key採用String的序列化方式
template.setKeySerializer(stringRedisSerializer);
// hash的key也採用String的序列化方式
template.setHashKeySerializer(stringRedisSerializer);
// value序列化方式採用jackson
template.setValueSerializer(jackson2JsonRedisSerializer);
// hash的value序列化方式採用jackson
template.setHashValueSerializer(jackson2JsonRedisSerializer);
template.afterPropertiesSet();
return template;
}
}
複製程式碼
// 基礎使用
@Resource
RedisTemplate<String,Object> redisTemplate;
redisTemplate.opsForList().rightPush("user:1:order", dataList.get(3).get("key").toString());
// 註解使用
@Cacheable(value = "redisTest")
public TestBean testBeanAnnotation () {}
複製程式碼
Redis使用場景
| 型別 | 適用場景 |
|---|---|
| String | 快取,限流,計數器,分佈式鎖,分佈式session |
| Hash | 儲存使用者資訊,使用者主頁存取量,組合查詢 |
| List | 微博關注人時間軸列表,簡單佇列 |
| Set | 贊,踩,標籤,好友關係 |
| Zset | 排行榜 |
或者簡單訊息佇列,發佈訂閱實施訊息系統等等
String - 快取
// 1.Cacheable 註解
// controller 呼叫 service 時自動判斷有沒有快取,如果有就走redis快取直接返回,如果沒有則數據庫然後自動放入redis中
// 可以設定過期時間,KEY生成規則 (KEY生成規則基於 參數的toString方法)
@Cacheable(value = "yearScore", key = "#yearScore")
@Override
public List<YearScore> findBy (YearScore yearScore) {}
// 2.手動用快取
if (redis.hasKey(???) {
return ....
}
redis.set(find from DB)...
複製程式碼
String - 限流 | 計數器
// 注:這只是一個最簡單的Demo 效率低,耗時舊,但核心就是這個意思
// 計數器也是利用單執行緒incr...等等
@RequestMapping("/redisLimit")
public String testRedisLimit(String uuid) {
if (jedis.get(uuid) != null) {
Long incr = jedis.incr(uuid);
if (incr > MAX_LIMITTIME) {
return "Failure Request";
} else {
return "Success Request";
}
}
// 設定Key 起始請求爲1,10秒過期 -> 實際寫法肯定封裝過,這裏就是隨便一寫
jedis.set(uuid, "1");
jedis.expire(uuid, 10);
return "Success Request";
}
複製程式碼
String - 分佈式鎖 (重點)
/***
* 核心思路:
* 分佈式服務呼叫時setnx,返回1證明拿到,用完了刪除,返回0就證明被鎖,等...
* SET KEY value [EX seconds] [PX milliseconds] [NX|XX]
* EX second:設定鍵的過期時間爲second秒
* PX millisecond:設定鍵的過期時間爲millisecond毫秒
* NX:只在鍵不存在時,纔對鍵進行設定操作
* XX:只在鍵已經存在時,纔對鍵進行設定操作
*
* 1.設定鎖
* A. 分佈式業務統一Key
* B. 設定Key過期時間
* C. 設定隨機value,利用ThreadLocal 執行緒私有儲存隨機value
*
* 2.業務處理
* ...
*
* 3.解鎖
* A. 無論如何必須解鎖 - finally (超時時間和finally 雙保證)
* B. 要對比是否是本執行緒上的鎖,所以要對比執行緒私有value和儲存的value是否一致(避免把別人加鎖的東西刪除了)
*/
@RequestMapping("/redisLock")
public String testRedisLock () {
try {
for(;;){
RedisContextHolder.clear();
String uuid = UUID.randomUUID().toString();
String set = jedis.set(KEY, uuid, "NX", "EX", 1000);
RedisContextHolder.setValue(uuid);
if (!"OK".equals(set)) {
// 進入回圈-可以短時間休眠
} else {
// 獲取鎖成功 Do Somethings....
break;
}
}
} finally {
// 解鎖 -> 保證獲取數據,判斷一致以及刪除數據三個操作是原子的, 因此如下寫法是不符合的
/*if (RedisContextHolder.getValue() != null && jedis.get(KEY) != null && RedisContextHolder.getValue().equals(jedis.get(KEY))) {
jedis.del(KEY);
}*/
// 正確姿勢 -> 使用Lua指令碼,保證原子性
String luaScript = "if redis.call('get', KEYS[1]) == ARGV[1] then return redis.call('del',KEYS[1]) else return 0 end";
Object eval = jedis.eval(luaScript, Collections.singletonList(KEY), Collections.singletonList(RedisContextHolder.getValue()));
}
return "鎖建立成功-業務處理成功";
}
複製程式碼
String - 分佈式Session(重點)
// 1.首先明白爲什麼需要分佈式session -> nginx負載均衡 分發到不同的Tomcat,即使利用IP分發,可以利用request獲取session,但是其中一個掛了,怎麼辦?? 所以需要分佈式session
注意理解其中的區別 A服務-使用者校驗服務 B服務-業務層
情況A:
A,B 服務單機部署:
cookie:登錄成功後,儲存資訊到cookie,A服務自身通過request設定session,獲取session,B服務通過唯一key或者userid 查詢數據庫獲取使用者資訊
cookie+redis:登錄成功後,儲存資訊到cookie,A服務自身通過request設定session,獲取session,B服務通過唯一key或者userid 查詢redis獲取使用者資訊
情況B:
A服務多節點部署,B服務多節點部署
B服務獲取使用者資訊的方式其實是不重要的,必然要查,要麼從數據庫,要麼從cookie
A服務:登錄成功後,儲存唯一key到cookie, 與此同時,A服務需要把session(KEY-UserInfo)同步到redis中,不能存在單純的request(否則nginx分發到另一個伺服器就完犢子了)
官方實現:
spring-session-data-redis
有一個內建攔截器,攔截request,session通過redis互動,普通使用程式碼依然是request.getSession.... 但是實際上這個session的值已經被該元件攔截,通過redis進行同步了
複製程式碼
List 簡單佇列-棧
// 說白了利用redis - list數據結構 支援從左從右push,從左從右pop
@Component
public class RedisStack {
@Resource
Jedis jedis;
private final static String KEY = "Stack";
/** push **/
public void push (String value) {
jedis.lpush(KEY, value);
}
/** pop **/
public String pop () {
return jedis.lpop(KEY);
}
}
複製程式碼
@Component
public class RedisQueue {
@Resource
JedisPool jedisPool;
private final static String KEY = "Queue";
/** push **/
public void push (String value) {
Jedis jedis = jedisPool.getResource();
jedis.lpush(KEY, value);
}
/** pop **/
public String pop () {
Jedis jedis = jedisPool.getResource();
return jedis.rpop(KEY);
}
}
複製程式碼
List 社交類APP - 好友列表
根據時間顯示好友,多個好友列表,求交集,並集 顯示共同好友等等...
疑問:難道大廠真的用redis存這些數據嗎???多大的量啊... 我個人認爲實際是數據庫存使用者id,然後用演算法去處理,更省空間
複製程式碼
Set 抽獎 | 好友關係(合,並,交集)
// 插入key 及使用者id
sadd cat:1 001 002 003 004 005 006
// 返回抽獎參與人數
scard cat:1
// 隨機抽取一個
srandmember cat:1
// 隨機抽取一人,並移除
spop cat:1
複製程式碼
Zset 排行榜
根據分數實現有序列表
微博熱搜:每點選一次 分數+1 即可
--- 不用數據庫目的是因爲避免order by 進行全表掃描
複製程式碼
常見面試題
Q1:爲什麼Redis能這麼快
1.Redis完全基於記憶體,絕大部分請求是純粹的記憶體操作,執行效率高。
2.Redis使用單進程單執行緒模型的(K,V)數據庫,將數據儲存在記憶體中,存取均不會受到硬碟IO的限制,因此其執行速度極快,另外單執行緒也能處理高併發請求,還可以避免頻繁上下文切換和鎖的競爭,同時由於單執行緒操作,也可以避免各種鎖的使用,進一步提高效率
3.數據結構簡單,對數據操作也簡單,Redis不使用表,不會強制使用者對各個關係進行關聯,不會有複雜的關係限制,其儲存結構就是鍵值對,類似於HashMap,HashMap最大的優點就是存取的時間複雜度爲O(1)
5.C語言編寫,效率更高
6.Redis使用多路I/O複用模型,爲非阻塞IO
7.有專門設計的RESP協定
複製程式碼
針對第四點進行說明 ->
常見的IO模型有四種:
- 同步阻塞IO(Blocking IO):即傳統的IO模型。
- 同步非阻塞IO(Non-blocking IO):預設建立的socket都是阻塞的,非阻塞IO要求socket被設定爲NONBLOCK。注意這裏所說的NIO並非Java的NIO(New IO)庫。
- IO多路複用(IO Multiplexing):即經典的Reactor設計模式,有時也稱爲非同步阻塞IO,Java中的Selector和Linux中的epoll都是這種模型。
- 非同步IO(Asynchronous IO):即經典的Proactor設計模式,也稱爲非同步非阻塞IO
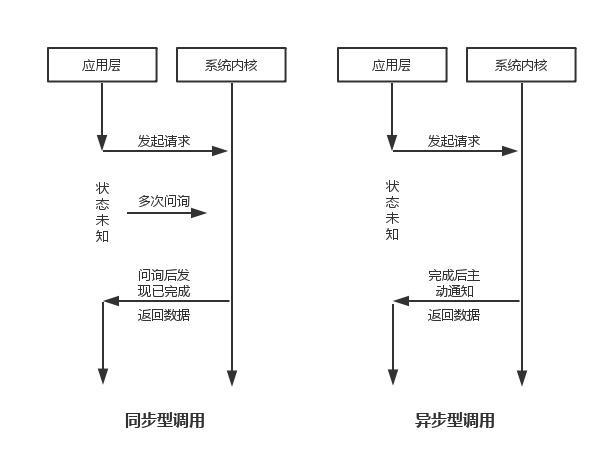
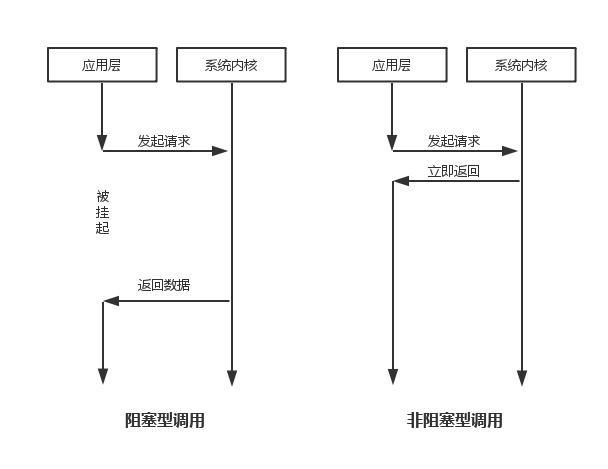
同步非同步,阻塞非阻塞的概念:
假設Redis採用同步阻塞IO:
Redis主程式(伺服器端 單執行緒)-> 多個用戶端連線(真實情況是如開發人員連線redis,程式 redispool連線redis),這每一個都對應着一個用戶端,假設爲100個用戶端,其中一個進行互動時候,如果採用同步阻塞式,那麼剩下的99個都需要原地等待,這勢必是不科學的。
IO多路複用
Redis 採用 I/O 多路複用模型
I/O 多路複用模型中,最重要的函數呼叫就是
select,該方法的能夠同時監控多個檔案描述符的可讀可寫情況,當其中的某些檔案描述符可讀或者可寫時,select方法就會返回可讀以及可寫的檔案描述符個數注:redis預設使用的是更加優化的演算法:epoll
select poll epoll 操作方式 遍歷 遍歷 回撥 底層實現 陣列 鏈表 雜湊表 IO效率 每次呼叫都進行線性遍歷,時間複雜度爲O(n) 每次呼叫都進行線性遍歷,時間複雜度爲O(n) 事件通知方式,每當fd就緒,系統註冊的回撥函數就會被呼叫,將就緒fd放到readyList裏面,時間複雜度O(1) 最大連線數 1024(x86)或2048(x64) 無上限 無上限 所以我們可以說Redis是這樣的:伺服器端單執行緒毫無疑問,多用戶端連線時候,如果用戶端沒有發起任何動作,則伺服器端會把其視爲不活躍的IO流,將其掛起,當有真正的動作時,會通過回撥的方式執行相應的事件
Q2:從海量Key裡查詢出某一個固定字首的Key
A. 笨辦法:KEYS [pattern] 注意key很多的話,這樣做肯定會出問題,造成redis崩潰
B. SCAN cursor [MATCH pattern][COUNT count] 遊標方式查詢
Q3:如何通過Redis實現分佈式鎖
見上文
複製程式碼
Q4:如何實現非同步佇列
上文說到利用 redis-list 實現佇列
假設場景:A服務生產數據 - B服務消費數據,即可利用此種模型構造-生產消費者模型
1. 使用Redis中的List作爲佇列
2.使用BLPOP key [key...] timeout -> LPOP key [key ...] timeout:阻塞直到佇列有訊息或者超時
(方案二:解決方案一中,拿數據的時,生產者尚未生產的情況)
3.pub/sub:主題訂閱者模式
基於reds的終極方案,上文有介紹,基於發佈/訂閱模式
缺點:訊息的發佈是無狀態的,無法保證可達。對於發佈者來說,訊息是「即發即失」的,此時如果某個消費者在生產者發佈訊息時下線,重新上線之後,是無法接收該訊息的,要解決該問題需要使用專業的訊息佇列
複製程式碼
Q5:Redis支援的數據型別?
見上文
複製程式碼
Q6:什麼是Redis持久化?Redis有哪幾種持久化方式?優缺點是什麼?
持久化就是把記憶體的數據寫到磁碟中去,防止服務宕機了記憶體數據丟失。
Redis 提供了兩種持久化方式:RDB(預設) 和AOF
RDB:
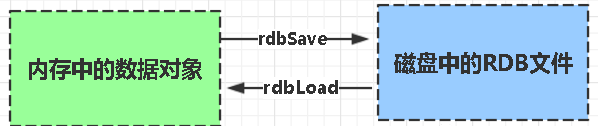
rdb是Redis DataBase縮寫
功能核心函數rdbSave(生成RDB檔案)和rdbLoad(從檔案載入記憶體)兩個函數
RDB: 把當前進程數據生成快照檔案儲存到硬碟的過程。分爲手動觸發和自動觸發
手動觸發 -> save (不推薦,阻塞嚴重) bgsave -> (save的優化版,微秒級阻塞)
shutdowm 關閉服務時,如果沒有設定AOF,則會使用bgsave持久化數據bgsave - 工作原理
會從當前父進程fork一個子進程,然後生成rdb檔案
缺點:頻率低,無法做到實時持久化
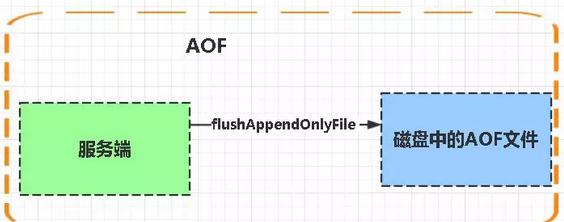
AOF:
Aof是Append-only file縮寫,AOF檔案儲存的也是RESP協定
每當執行伺服器(定時)任務或者函數時flushAppendOnlyFile 函數都會被呼叫, 這個函數執行以下兩個工作
aof寫入儲存:
WRITE:根據條件,將 aof_buf 中的快取寫入到 AOF 檔案
SAVE:根據條件,呼叫 fsync 或 fdatasync 函數,將 AOF 檔案儲存到磁碟中。
儲存結構:
內容是redis通訊協定(RESP )格式的命令文字儲存
原理:
相當於儲存了redis的執行命令(類似mysql的sql語句日誌),數據的完整性和一致性更高
比較:
1、aof檔案比rdb更新頻率高
2、aof比rdb更安全
3、rdb效能更好
PS:正確停止redis服務 應該基於連線命令 加再上 shutdown -> 否則數據持久化會出現問題
Q7:redis通訊協定(RESP)
Redis 即 REmote Dictionary Server (遠端字典服務);
而Redis的協議規範是 Redis Serialization Protocol (Redis序列化協定)
RESP 是redis用戶端和伺服器端之前使用的一種通訊協定;
RESP 的特點:實現簡單、快速解析、可讀性好
協定如下:
用戶端以規定格式的形式發送命令給伺服器
set key value 協定翻譯如下: * 3 -> 表示以下有幾組命令 $ 3 -> 表示命令長度是3 SET $6 -> 表示長度是6 keykey $5 -> 表示長度是5 value 完整即: * 3 $ 3 SET $6 keykey $5 value 複製程式碼
伺服器在執行最後一條命令後,返回結果,返回格式如下:
For Simple Strings the first byte of the reply is 「+」 回覆 回復
For Errors the first byte of the reply is 「-」 錯誤
For Integers the first byte of the reply is 「:」 整數
For Bulk Strings the first byte of the reply is 「$」 字串
For Arrays the first byte of the reply is 「*」 陣列
// 僞造6379 redis-伺服器端,監聽 jedis發送的協定內容
public class SocketApp {
/***
* 監聽 6379 傳輸的數據
* JVM埠需要進行設定
*/
public static void main(String[] args) {
try {
ServerSocket serverSocket = new ServerSocket(6379);
Socket redis = serverSocket.accept();
byte[] result = new byte[2048];
redis.getInputStream().read(result);
System.out.println(new String(result));
} catch (Exception e) {
e.printStackTrace();
}
}
}
// jedis連線-發送命令
public class App {
public static void main(String[] args){
Jedis jedis = new Jedis("127.0.0.1");
jedis.set("key", "This is value.");
jedis.close();
}
}
// 監聽命令內容如下:
*3
$3
SET
$3
key
$14
複製程式碼
Q8:redis架構有哪些
單節點
主從複製
Master-slave 主從賦值,此種結構可以考慮關閉master的持久化,只讓從數據庫進行持久化,另外可以通過讀寫分離,緩解主伺服器壓力
複製程式碼
哨兵
Redis sentinel 是一個分佈式系統中監控 redis 主從伺服器,並在主伺服器下線時自動進行故障轉移。其中三個特性:
監控(Monitoring): Sentinel 會不斷地檢查你的主伺服器和從伺服器是否運作正常。
提醒(Notification): 當被監控的某個 Redis 伺服器出現問題時, Sentinel 可以通過 API 向管理員或者其他應用程式發送通知。
自動故障遷移(Automatic failover): 當一個主伺服器不能正常工作時, Sentinel 會開始一次自動故障遷移操作。
特點:
1、保證高可用
2、監控各個節點
3、自動故障遷移
缺點:主從模式,切換需要時間丟數據
沒有解決 master 寫的壓力
複製程式碼
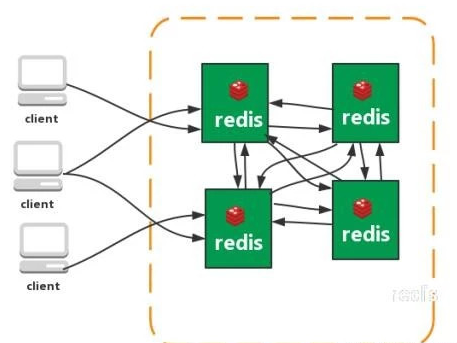
叢集
從redis 3.0之後版本支援redis-cluster叢集,Redis-Cluster採用無中心結構,每個節點儲存數據和整個叢集狀態,每個節點都和其他所有節點連線。
特點:
1、無中心架構(不存在哪個節點影響效能瓶頸),少了 proxy 層。
2、數據按照 slot 儲存分佈在多個節點,節點間數據共用,可動態調整數據分佈。
3、可延伸性,可線性擴充套件到 1000 個節點,節點可動態新增或刪除。
4、高可用性,部分節點不可用時,叢集仍可用。通過增加 Slave 做備份數據副本
5、實現故障自動 failover,節點之間通過 gossip 協定交換狀態資訊,用投票機制 機製完成 Slave到 Master 的角色提升。
缺點:
1、資源隔離性較差,容易出現相互影響的情況。
2、數據通過非同步複製,不保證數據的強一致性
Q9:Redis叢集-如何從海量數據裡快速找到所需?
-
分片
按照某種規則去劃分數據,分散儲存在多個節點上。通過將數據分到多個Redis伺服器上,來減輕單個Redis伺服器的壓力。
-
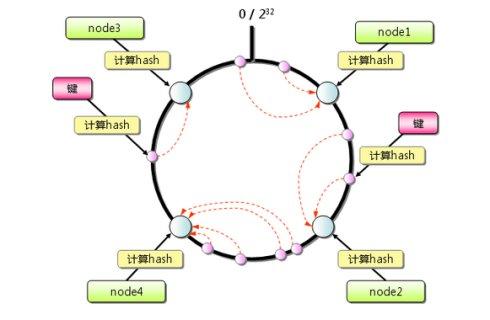
一致性Hash演算法
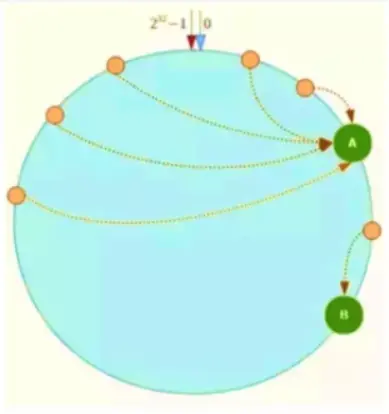
既然要將數據進行分片,那麼通常的做法就是獲取節點的Hash值,然後根據節點數求模,但這樣的方法有明顯的弊端,當Redis節點數需要動態增加或減少的時候,會造成大量的Key無法被命中。所以Redis中引入了一致性Hash演算法。該演算法對2^32 取模,將Hash值空間組成虛擬的圓環,整個圓環按順時針方向組織,每個節點依次爲0、1、2…2^32-1,之後將每個伺服器進行Hash運算,確定伺服器在這個Hash環上的地址,確定了伺服器地址後,對數據使用同樣的Hash演算法,將數據定位到特定的Redis伺服器上。如果定位到的地方沒有Redis伺服器範例,則繼續順時針尋找,找到的第一臺伺服器即該數據最終的伺服器位置。
Hash環的數據傾斜問題
Hash環在伺服器節點很少的時候,容易遇到伺服器節點不均勻的問題,這會造成數據傾斜,數據傾斜指的是被快取的物件大部分集中在Redis叢集的其中一臺或幾臺伺服器上。
如上圖,一致性Hash演算法運算後的數據大部分被存放在A節點上,而B節點只存放了少量的數據,久而久之A節點將被撐爆。 引入虛擬節點
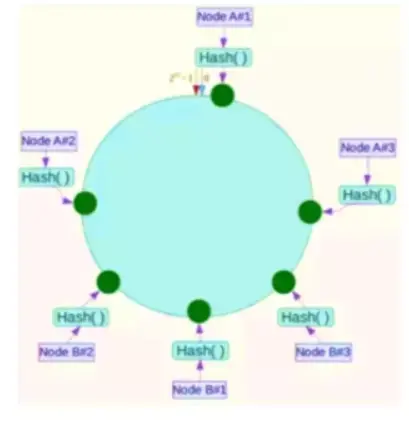
例如上圖:將NodeA和NodeB兩個節點分爲Node A#1-A#3 NodeB#1-B#3。
Q10:什麼是快取穿透?如何避免?什麼是快取雪崩?如何避免?什麼是快取擊穿?如何避免?
快取穿透
一般的快取系統,都是按照key去快取查詢,如果不存在對應的value,就應該去後端系統查詢(比如DB)。一些惡意的請求會故意查詢不存在的key,請求量很大,就會對後端系統造成很大的壓力。這就叫做快取穿透。
如何避免?
1:對查詢結果爲空的情況也進行快取,快取時間設定短一點,或者該key對應的數據insert了之後清除快取。
2:對一定不存在的key進行過濾。可以把所有的可能存在的key放到一個大的Bitmap中,查詢時通過該bitmap過濾。
3:由於請求參數是不合法的(每次都請求不存在的參數),於是我們可以使用布隆過濾器(Bloomfilter)或壓縮filter提前進行攔截,不合法就不讓這個請求進入到數據庫層
快取雪崩
當快取伺服器重新啓動或者大量快取集中在某一個時間段失效,這樣在失效的時候,會給後端系統帶來很大壓力。導致系統崩潰。
如何避免?
1:在快取失效後,通過加鎖或者佇列來控制讀數據庫寫快取的執行緒數量。比如對某個key只允許一個執行緒查詢數據和寫快取,其他執行緒等待。
2:做二級快取,A1爲原始快取,A2爲拷貝快取,A1失效時,可以存取A2,A1快取失效時間設定爲短期,A2設定爲長期
3:不同的key,設定不同的過期時間,讓快取失效的時間點儘量均勻。
4:啓用限流策略,儘量避免數據庫被幹掉
快取擊穿
概念 一個存在的key,在快取過期的一刻,同時有大量的請求,這些請求都會擊穿到DB,造成瞬時DB請求量大、壓力驟增。
解決方案 A. 在存取key之前,採用SETNX(set if not exists)來設定另一個短期key來鎖住當前key的存取,存取結束再刪除該短期key
B. 服務層處理 - 方法加鎖 + 雙重校驗:
// 鎖-範例 private Lock lock = new ReentrantLock(); public String getProductImgUrlById(String id){ // 獲取快取 String product = jedisClient.get(PRODUCT_KEY + id); if (null == product) { // 如果沒有獲取鎖等待3秒,SECONDS代表:秒 try { if (lock.tryLock(3, TimeUnit.SECONDS)) { try { // 獲取鎖後再查一次,查到了直接返回結果 product = jedisClient.get(PRODUCT_KEY + id); if (null == product) { // .... } return product; } catch (Exception e) { product = jedisClient.get(PRODUCT_KEY + id); } finally { // 釋放鎖(成功、失敗都必須釋放,如果是lock.tryLock()方法會一直阻塞在這) lock.unlock(); } } else { product = jedisClient.get(PRODUCT_KEY + id); } } catch (InterruptedException e) { product = jedisClient.get(PRODUCT_KEY + id); } } return product; } 複製程式碼
| 解釋 | 基礎解決方案 | |
|---|---|---|
| 快取穿透 | 存取一個不存在的key,快取不起作用,請求會穿透到DB,流量大時DB會掛掉 | 1.採用布隆過濾器,使用一個足夠大的bitmap,用於儲存可能存取的key,不存在的key直接被過濾; 2.存取key未在DB查詢到值,也將空值寫進快取,但可以設定較短過期時間 |
| 快取雪崩 | 大量的key設定了相同的過期時間,導致在快取在同一時刻全部失效,造成瞬時DB請求量大、壓力驟增,引起雪崩 | 可以給快取設定過期時間時加上一個隨機值時間,使得每個key的過期時間分佈開來,不會集中在同一時刻失效 |
| 快取擊穿 | 一個存在的key,在快取過期的一刻,同時有大量的請求,這些請求都會擊穿到DB,造成瞬時DB請求量大、壓力驟增 | 在存取key之前,採用SETNX(set if not exists)來設定另一個短期key來鎖住當前key的存取,存取結束再刪除該短期key |
Q11:快取與數據庫雙寫一致
如果僅僅是讀數據,沒有此類問題
如果是新增數據,也沒有此類問題
當數據需要更新時,如何保證快取與數據庫的雙寫一致性?
三種更新策略:
- 先更新數據庫,再更新快取 ->
- 先刪除快取,再更新數據庫
- 先更新數據庫,再刪除快取
方案一:併發的時候,執行順序無法保證,可能A先更新數據庫,但B後更新數據庫但先更新快取
加鎖的話,確實可以避免,但這樣吞吐量會下降,可以根據業務場景考慮
方案二:該方案會導致不一致的原因是。同時有一個請求A進行更新操作,另一個請求B進行查詢操作。那麼會出現如下情形: (1)請求A進行寫操作,刪除快取 (2)請求B查詢發現快取不存在 (3)請求B去數據庫查詢得到舊值 (4)請求B將舊值寫入快取 (5)請求A將新值寫入數據庫
因此採用:採用延時雙刪策略 即進入邏輯就刪除Key,執行完操作,延時再刪除key
方案三:更新數據庫 - 刪除快取 可能出現問題的場景:
(1)快取剛好失效 (2)請求A查詢數據庫,得一箇舊值 (3)請求B將新值寫入數據庫 (4)請求B刪除快取 (5)請求A將查到的舊值寫入快取
先天條件要求:請求第二步的讀取操作耗時要大於更新操作,條件較爲苛刻
但如果真的發生怎麼處理?
A. 給鍵設定合理的過期時間
B. 非同步延時刪除key
Q12:何保證Redis中的數據都是熱點數據
A. 可以通過手工或者主動方式,去載入熱點數據
B. Redis有其自己的數據淘汰策略:
redis 記憶體數據集大小上升到一定大小的時候,就會施行數據淘汰策略(回收策略)。redis 提供 6種數據淘汰策略:
- volatile-lru:從已設定過期時間的數據集(server.db[i].expires)中挑選最近最少使用的數據淘汰
- volatile-ttl:從已設定過期時間的數據集(server.db[i].expires)中挑選將要過期的數據淘汰
- volatile-random:從已設定過期時間的數據集(server.db[i].expires)中任意選擇數據淘汰
- allkeys-lru:從數據集(server.db[i].dict)中挑選最近最少使用的數據淘汰
- allkeys-random:從數據集(server.db[i].dict)中任意選擇數據淘汰
- no-enviction(驅逐):禁止驅逐數據
Q13:Redis的併發競爭問題如何解決?
即多執行緒同時操作統一Key的解決辦法:
Redis爲單進程單執行緒模式,採用佇列模式將併發存取變爲序列存取。Redis本身沒有鎖的概念,Redis對於多個用戶端連線並不存在競爭,但是在Jedis用戶端對Redis進行併發存取時會發生連線超時、數據轉換錯誤、阻塞、用戶端關閉連線等問題,這些問題均是由於用戶端連線混亂造成
對此有多種解決方法:
A:條件允許的情況下,請使用redis自帶的incr命令,decr命令
B:樂觀鎖方式
watch price
get price $price
$price = $price + 10
multi
set price $price
exec
C:針對用戶端,操作同一個key的時候,進行加鎖處理
D:場景允許的話,使用setnx 實現
複製程式碼
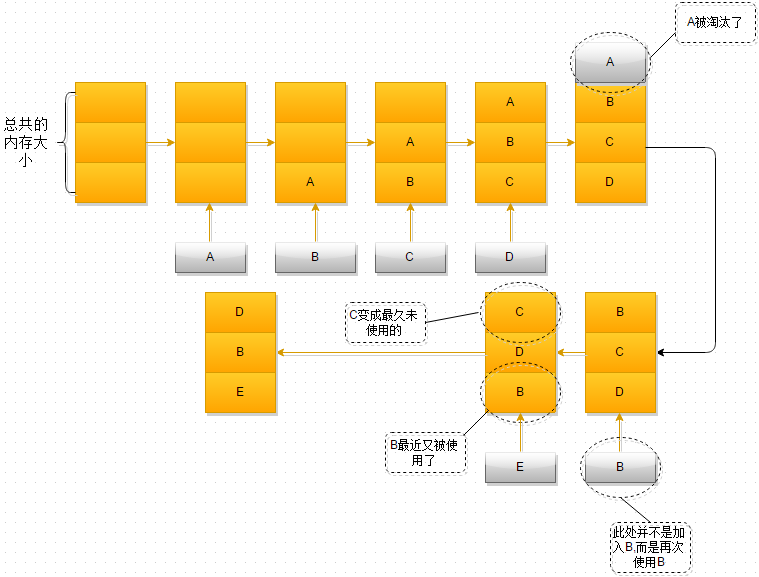
Q14:Redis回收進程如何工作的? Redis回收使用的是什麼演算法?
Q12 中提到過,當所需記憶體超過設定的最大記憶體時,redis會啓用數據淘汰規則
預設規則是:# maxmemory-policy noeviction
即只允許讀,無法繼續新增key
因此常需要設定淘汰策略,比如LRU演算法
LRU演算法最爲精典的實現,就是HashMap+Double LinkedList,時間複雜度爲O(1)
Q15:Redis大批次增加數據
參考文章:www.cnblogs.com/PatrickLiu/…
使用管道模式,執行的命令如下所示:
cat data.txt | redis-cli --pipe 複製程式碼data.txt文字:
SET Key0 Value0 SET Key1 Value1 ... SET KeyN ValueN # 或者是 RESP協定內容 - 注意檔案編碼!!! *8 $5 HMSET $8 person:1 $2 id $1 1 複製程式碼這將產生類似於這樣的輸出:
All data transferred. Waiting for the last reply... Last reply received from server. errors: 0, replies: 1000000 複製程式碼redis-cli實用程式還將確保只將從Redis範例收到的錯誤重定向到標準輸出
演示:
cat redis_commands.txt | redis-cli -h 192.168.127.130 -p 6379 [-a "password"] -n 0 --pipe All data transferred.Waiting for the last reply... Last reply received from server. errors:0,replies:10000000 複製程式碼
mysql數據快速匯入到redis 實戰:檔案詳情:可見Redis-通道實戰博文:www.cnblogs.com/tommy-huang…
# 1.準備一個table create database if not exists `test`; use `test`; CREATE TABLE `person` ( `id` int(10) unsigned NOT NULL AUTO_INCREMENT, `name` varchar(200) NOT NULL, `age` varchar(200) NOT NULL, PRIMARY KEY (`id`) ) ENGINE=MyISAM AUTO_INCREMENT=1 DEFAULT CHARSET=utf8; # 2.插入七八萬條數據 # 3.SQL查詢,將其轉化爲 RESP協定命令 Linux 版本: -> 不要在windows環境試,沒啥意義 SELECT CONCAT( "*8\r\n", '$',LENGTH(redis_cmd),'\r\n',redis_cmd,'\r\n', '$',LENGTH(redis_key),'\r\n',redis_key,'\r\n', '$',LENGTH(hkey1),'\r\n',hkey1,'\r\n','$',LENGTH(hval1),'\r\n',hval1,'\r\n', '$',LENGTH(hkey2),'\r\n',hkey2,'\r\n','$',LENGTH(hval2),'\r\n',hval2,'\r\n', '$',LENGTH(hkey3),'\r\n',hkey3,'\r\n','$',LENGTH(hval3),'\r\n',hval3,'\r' )FROM( SELECT 'HMSET' AS redis_cmd, concat_ws(':','person', id) AS redis_key, 'id' AS hkey1, id AS hval1, 'name' AS hkey2, name AS hval2, 'age' AS hkey3, age AS hval3 From person )AS t # 4.如果用的就是線上數據庫+線上Linux -> 把sql存到 order.sql,進行執行 mysql -uroot -p123456 test --default-character-set=utf8 --skip-column-names --raw < order.sql | redis-cli -h 127.0.0.1 -p 6379 -a 123456 --pipe # 5.本地數據庫+線上redis 利用Navicat導出數據 -> data.txt,清理格式(導出來的數據裏面各種 " 符號),全域性替換即可 cat data.txt | redis-cli -h 127.0.0.1 -p 6379 -a 123456 --pipe 81921條數據 一瞬間匯入完成 注意事項: RESP協定要求,不要有莫名其妙的字元,注意檔案型別是Unix編碼型別 複製程式碼
Q16:延申:布隆過濾器
數據結構及演算法篇 / 布隆過濾器
Redis 實現
redis 4.X 以上 提供 布隆過濾器外掛
centos中安裝redis外掛bloom-filter:blog.csdn.net/u013030276/…
語法:[bf.add key options]
語法:[bf.exists key options]
注意:
redis 布隆過濾器提供的是 最大記憶體512M,2億數據,萬分之一的誤差率
Q17:Lua指令碼相關
使用Lua指令碼的好處:
- 減少網路開銷。可以將多個請求通過指令碼的形式一次發送,減少網路時延
- 原子操作,redis會將整個指令碼作爲一個整體執行,中間不會被其他命令插入。因此在編寫指令碼的過程中無需擔心會出現競態條件,無需使用事務
- 複用,用戶端發送的指令碼會永久存在redis中,這樣,其他用戶端可以複用這一指令碼而不需要使用程式碼完成相同的邏輯
@RequestMapping("/testLua")
public String testLua () {
String key = "mylock";
String value = "xxxxxxxxxxxxxxx";
// if redis.call('get', KEYS[1]) == ARGV[1]
// then
// return redis.call('del', KEYS[1])
// else
// return 0
// end
// lua指令碼,用來釋放分佈式鎖 - 如果使用的較多,可以封裝到檔案中, 再進行呼叫
String luaScript = "if redis.call('get', KEYS[1]) == ARGV[1] then return redis.call('del',KEYS[1]) else return 0 end";
Object eval = jedis.eval(luaScript, Collections.singletonList(key), Collections.singletonList(value));
return eval.toString();
}
複製程式碼
Q18:效能相關 - Redis慢查詢分析
redis 命令會放在redis內建佇列中,然後主執行緒一個個執行,因此 其中一個 命令執行時間過長,會造成成批次的阻塞
命令:slowlog get 獲取慢查詢記錄 slowlog len 獲取慢查詢記錄量 (慢查詢佇列是先進先出的,因此新的值在滿載的時候,舊的會出去)Redis 慢查詢 -> 執行階段耗時過長
conf檔案設定:slowlog-low-slower-than 10000 -> 10000微秒,10毫秒 (預設) 0 -> 記錄所有命令 -1 -> 不記錄命令 slow-max-len 存放的最大條數
慢查詢導致原因: value 值過大,解決辦法:數據分段(更細顆粒度存放數據)
Q19:如何提高Redis處理效率? 基於Jedis 的批次操作 Pipelined
Jedis jedis = new Jedis("127.0.0.1", 6379);
Pipeline pipelined = jedis.pipelined();
for (String key : keys) {
pipelined.del(key);
}
pipelined.sync();
jedis.close();
// pipelined 實際是封裝過一層的指令集 -> 實際應用的還是單條指令,但是節省了網路傳輸開銷(伺服器端到Redis環境的網路開銷)
複製程式碼
最後
作者:Kerwin_
鏈接:https://juejin.im/post/6857667542652190728
來源:掘金
ic String testLua () {
String key = "mylock";
String value = "xxxxxxxxxxxxxxx";
// if redis.call('get', KEYS[1]) == ARGV[1]
// then
// return redis.call('del', KEYS[1])
// else
// return 0
// end
// lua指令碼,用來釋放分佈式鎖 - 如果使用的較多,可以封裝到檔案中, 再進行呼叫
String luaScript = "if redis.call('get', KEYS[1]) == ARGV[1] then return redis.call('del',KEYS[1]) else return 0 end";
Object eval = jedis.eval(luaScript, Collections.singletonList(key), Collections.singletonList(value));
return eval.toString();
}
複製程式碼
### Q18:效能相關 - Redis慢查詢分析
> redis 命令會放在redis內建佇列中,然後主執行緒一個個執行,因此 其中一個 命令執行時間過長,會造成成批次的阻塞
>
> `命令:`slowlog get 獲取慢查詢記錄 slowlog len 獲取慢查詢記錄量 (慢查詢佇列是先進先出的,因此新的值在滿載的時候,舊的會出去)
>
> Redis 慢查詢 -> 執行階段耗時過長
>
> `conf檔案設定: ` slowlog-low-slower-than 10000 -> 10000微秒,10毫秒 (預設) 0 -> 記錄所有命令 -1 -> 不記錄命令 slow-max-len 存放的最大條數
>
> `慢查詢導致原因: value 值過大,解決辦法:` 數據分段(更細顆粒度存放數據)
### Q19:如何提高Redis處理效率? 基於Jedis 的批次操作 Pipelined
```java
Jedis jedis = new Jedis("127.0.0.1", 6379);
Pipeline pipelined = jedis.pipelined();
for (String key : keys) {
pipelined.del(key);
}
pipelined.sync();
jedis.close();
// pipelined 實際是封裝過一層的指令集 -> 實際應用的還是單條指令,但是節省了網路傳輸開銷(伺服器端到Redis環境的網路開銷)
複製程式碼