grep 正則表達式
簡單的說,正則表達式就是處理字串的方法,他是以行爲單位來進行字串的處理行爲, 正則表達式通過一些特殊符號的輔助,可以讓使用者輕易的達到「搜尋/刪除/取代」某特定字串的處理程式!
正則表達式基本上是一種「表達式」, 只要工具程式支援這種表達式,那麼該工具程式就可以用來作爲正則表達式的字串處理之用。 例如 vi, grep, awk ,sed 等等工具,因爲她們有支援正則表達式, 所以,這些工具就可以使用正則表達式的特殊字元來進行字串的處理。但例如 cp, ls 等指令並未支援正則表達式, 所以就只能使用 Bash 自己本身的萬用字元而已。
是 Linux 基礎當中的基礎,如果學成了之後,一定是「大大的有幫助」的!這就好像是金庸小說裏面的學武難關:任督二脈! 打通任督二脈之後,武功立刻成倍成長!
**
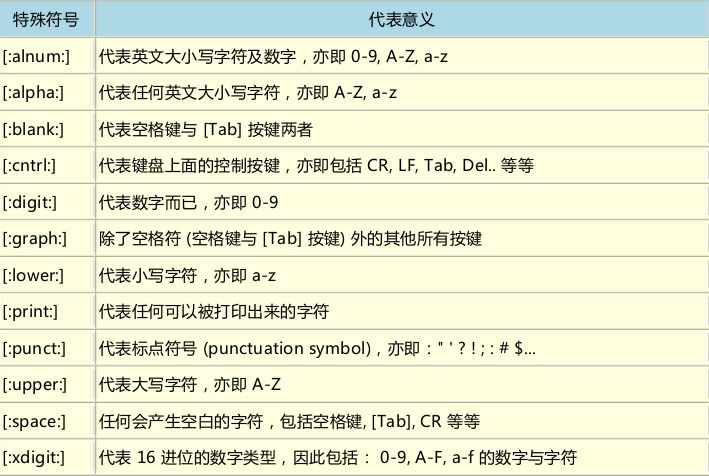
- 常用特殊符號
[:alnum:] 代表所有的大小寫英文字元和數位 0-9 A—Z a-z
[:alpha:] 代表任意英文大小寫字元 A-Z a-z
[:lower:] 代表小寫字元 a-z
[:upper:] 代表大寫字元 A-Z
[:digit:] 代表數位 0-9
示列
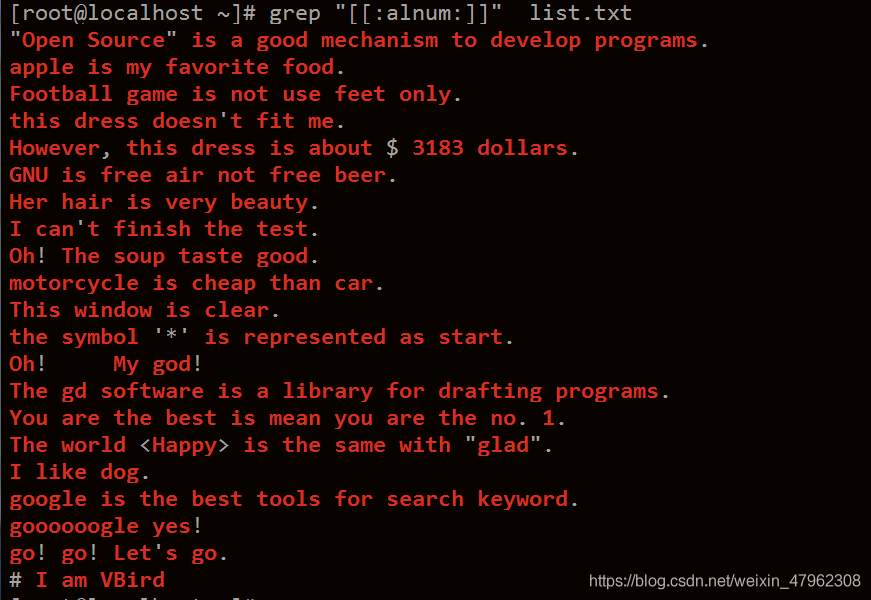

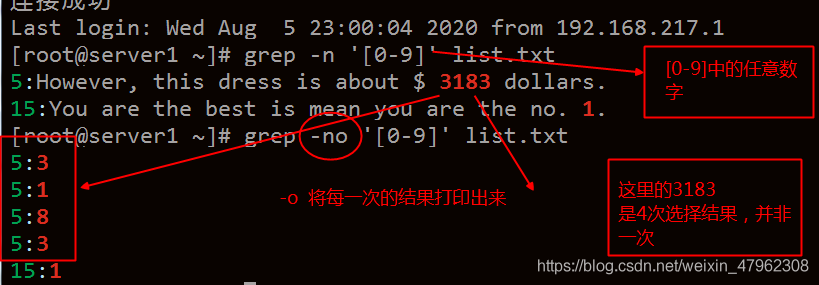
使用grep 正則表達式 時,常用 列印方式 -o -n -v -l
如下:
-n 顯示行號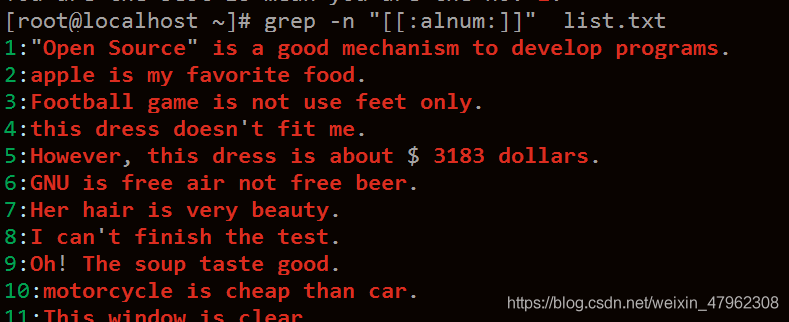
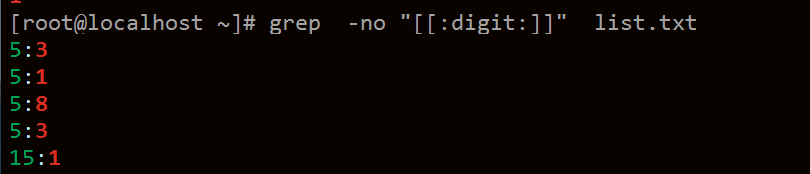
-o 提出找到的所有內容
可以看到配合n使用,看到列印出的內容可以使同一行的內容
-v 不列印搜尋內容所在的整行內容
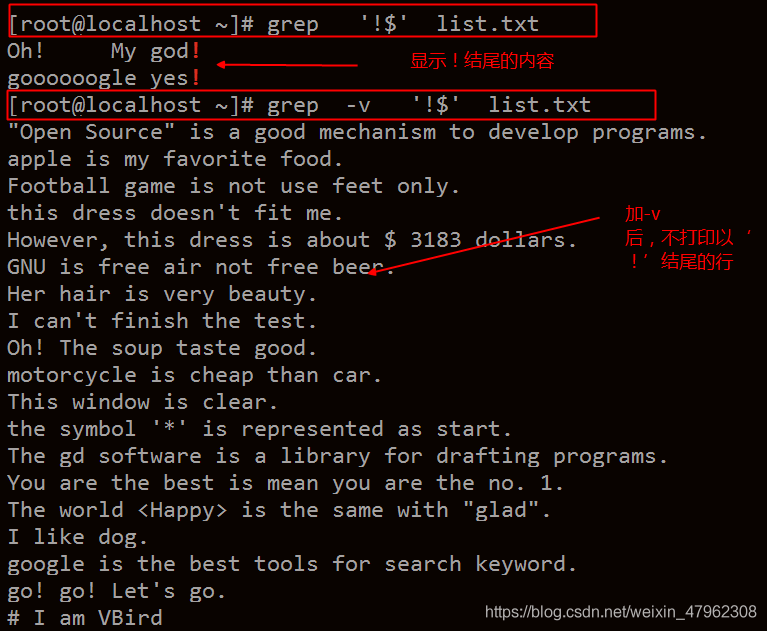
-l 顯示所在的檔名

- 正則字元

範例:







注意是 ‘ * ’ 的前一個字元
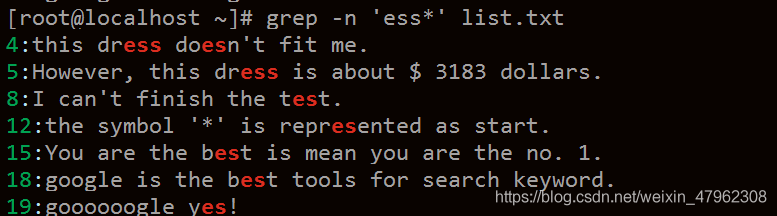

注意:是**[ ]** 裏面的其中一個






注意是前一個字元。 列子的前一個RE字元是 o 。
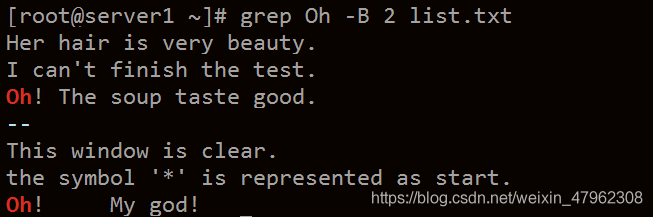
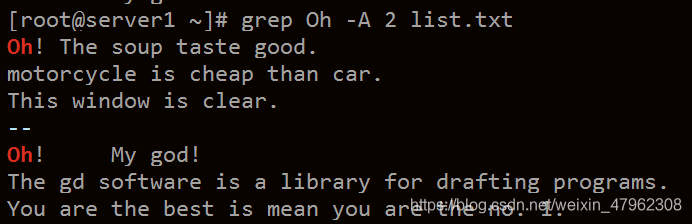
grep / A / B /C
-A n 把匹配成功行之後的n行也同時列出。 A 就是 after 的首字母
就是 之後 的意思
-B n 把匹配成功行之前的n行也同時列出。B 就是 before 的首字母
就是 之前 的意思
-C n 把匹配成功前後各n行也同時列出
grep -o -c nologin /etc/passwd -c 有統計總數的效果

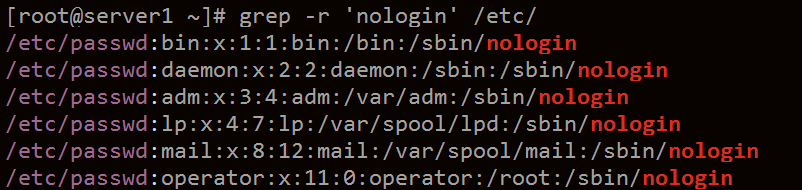
grep -r ‘nologin’ /etc/ 遞回查詢,就是在一個目錄下查詢
在etc 目錄下查詢nologin 列印出含nologin檔案內容,及對應的路徑。 grep -r可以查詢檔案內容。find 查檔名
注意
搜尋 oo 但其前面不要有g
grep -n '[^g]oo' regular_repress.txt
注意:當搜尋的行內含有要符合搜尋條件時後,此行就會忽略 明確不要的條件,比如以上的例子就可能會搜尋到下面 下麪的內容
3:tool is a good tool
8:goooooogle
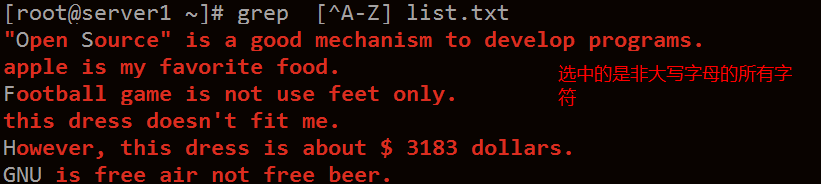
注意 : 符號 ^ 在 [] 內時是取反的意思,在 [] 之外是行首的意思
顯示行首不是#和;的行
grep '^[^#;]' regular_repress.txt
找到以 . 結尾的行
grep -n ‘\.$’ regular_repress.txt
需要用
\進行轉意
查詢 開頭是 g 和結尾也是 g ,中間的字元可有可無
grep -n 'g.*g' regular_repress.txt
.代表一個任意字元
*代表重複零到多個在 其前面的一個字元
.*代表零個或多個任意字元
查詢以a爲開頭的任意檔名
方法一:
萬用字元
ls -l a*
擴充套件正則

支援擴充套件正則的工具
grep -E
egrep
sed
awk
寫出匹配日期格式 YYYY-MM-DD 的正則表達式
[root@sharkyun ~]# echo "2019-12-30" |grep -E '[1-9][0-9]{3}-((0[1-9])|(1[0-2]))-((0[1-9])|([12][0-9])|(3[01]))'
2019-12-30
[root@sharkyun ~]# echo "1919-12-30" |grep -E '[1-9][0-9]{3}-((0[1-9])|(1[0-2]))-((0[1-9])|([12][0-9])|(3[01]))'
1919-12-30
正則高階部分: 貪婪|非貪婪(擴充套件)
貪婪 就是儘可能的多匹配
非貪婪 就是儘可能的少匹配,只需要在一些表示量詞(就是次數)的後面加上
?, 比如:.*?+?
預設是貪婪模式
例如:
adanndddddda ada 滿足 a.*a 。 但是會列印出 adanndddddda
這就是貪婪模式。

grep 實現非貪婪
grep 或者 egrep 預設都是貪婪模式,不支援非貪婪模式。 要想實現非貪婪需要使用-P參數,這會使用Perl語言環境的正則
grep -P

注意 " ? "是加在量詞(次數)的後面