同樣的SQL,怎麼突然就慢了?
本篇文章素材來源於某銀行系統的一次效能問題分析。
許久沒寫這種troubleshooting型別的技術文章了,因為曾在服務公司呆過多年,工作原因,這方面之前做的多,聽的更多,導致已經達到在自己認知維度下的一個小瓶頸,純技術型的問題,稍微常見的基本都遇到過,非常少見的也基本是bug類(軟體缺陷只能通過修補程式或一些workaround的方式繞過去),感覺實在是沒啥可寫的。
另外注意,我這裡說的「常見」指的是所有客戶群中相對常見,而對單個具體客戶而言,就非常可能從沒有見過,這也是純甲方技術人員(這裡的純甲方是指畢業就在一個甲方呆著,只能看到自己公司系統執行情況)的侷限性,在早些年時,一些行業前輩們還會建議新的技術從業者即使想去甲方,也要先在乙方吃幾年苦,能多見一些場景,再去甲方,這樣會有比較準確的判斷力,不至於輕易被乙方忽悠,也不會瞎挑毛病挑不到點子上讓人鄙視。
前些日子有客戶遇到問題,申請出差過去現場幫客戶分析解決了,這個分析過程還是有些意思的,但最終結論簡單來說就是DPR(直接路徑讀)問題,定位那一刻就覺得沒啥可寫的了,相關文章也太多了,今天突然想換個思路,看能否以故事線的方式來呈現這個問題,並解釋所有技術細節,試圖能夠讓所有人(包括技術小白)都能看得懂,所有使用者相關資訊均已做遮蔽處理。
首先你要忘掉這是個DPR的問題,讓我們一起體會下這個分析問題的歷程。
起初是被同事叫來幫忙一起分析客戶問題,搞了一個微信群,客戶先發了一些所謂異常時間的AWR、ASH、ADDM報告。
說明環境是普通X86伺服器上的一套Oracle RAC資料庫,版本是11.2.0.4,有應用修補程式,觸發BUG風險相對較低。嗯,還是要強調下,這裡說的低只是說主觀感覺上,因為11g已經摸爬滾打了那麼多年,無數客戶曾趟出的bug也都做了修復,遇到新bug的概率相對小而已,但並不是遇不到,一旦運氣不好遇到就麻煩了,所以我們現在會強烈建議你升級到現有的LTS(長期支援版本)19c,可不要再用11g了。
這裡提到非常有用的報告:
- AWR(Automatic Workload Repository)
- ASH(Active Session History)
- ADDM(Automatic Database Diagnostic Monitor)
其中ADDM相對用的少,它可以自動分析 AWR 中的效能資料,識別潛在的效能問題,並生成相應的建議報告。對於複雜問題可能不夠準確,但至少也能給我們提供一個思路。
AWR可以記錄某個時段下的真實負載情況,ASH可以在某個時段下看到是哪些對談在執行,非常好用,對等待事件的細緻劃分程度,也是其他資料庫夢寐以求的東西。
和應用配合明確這個業務感知慢的SQL是否是AWR中顯示的Top SQL,同時明確對應的具體sql_id,開始深入分析。
起初明確的sql_id,有一個對應的是一個儲存過程,但此時沒有進一步去查。
因為另外一個sql_id被認為更值得關注,這是一條簡單的SQL,查詢一個分割區表,謂詞條件只有一個定位到某一天的日期,該表是按月分割區的。該SQL奇怪是正常的時候1分鐘以內完成,異常的時候要接近10分鐘完成,前者客戶認為正常可接受,後者認為無法接受。
同樣的SQL,查詢不同日期,效率差距如此明顯,另外客戶反饋每天資料量基本相當,並沒有數量級的差異。
此時最先想要排查的是是否有不同的執行計劃?
可結果並不是,執行計劃雖然是全表掃,但是前後並沒有任何變化。
當時給的AWR中,我也看了IO部分,但只有3.3G的量級,感覺影響並不大,就忽略掉了。
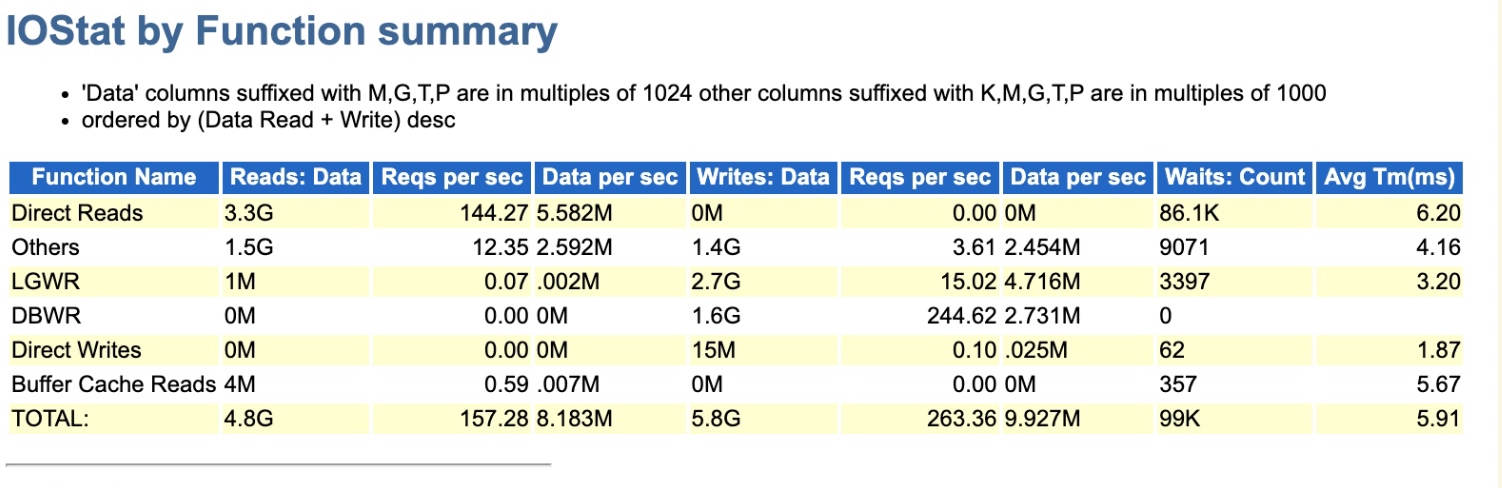
後來去現場,實際動手分析發現,其實故障時刻遠沒有之前的AWR報告那樣輕描淡寫,重新收集後續故障時刻的AWR(1小時間隔)可以看到此時的DPR非常顯著,達到了314G+,要是之前做緊急救援服務,看到這就已經結束了,直接憑藉經驗斷定,DPR禁用掉再看效果。因為再慢的話,會影響其他客戶問題的處理進度。
其實那種憑藉歷史經驗直接判斷問題雖然有很快很厲害的感覺,但卻是不嚴謹的,現在我們要進一步確認細節,確認是否是這個問題。既然是DPR,再看TOP SQL中通過Reads的排序,發現Top 2都值得關注,因為物理讀幾千萬,和後面SQL存在數量級上的差異:
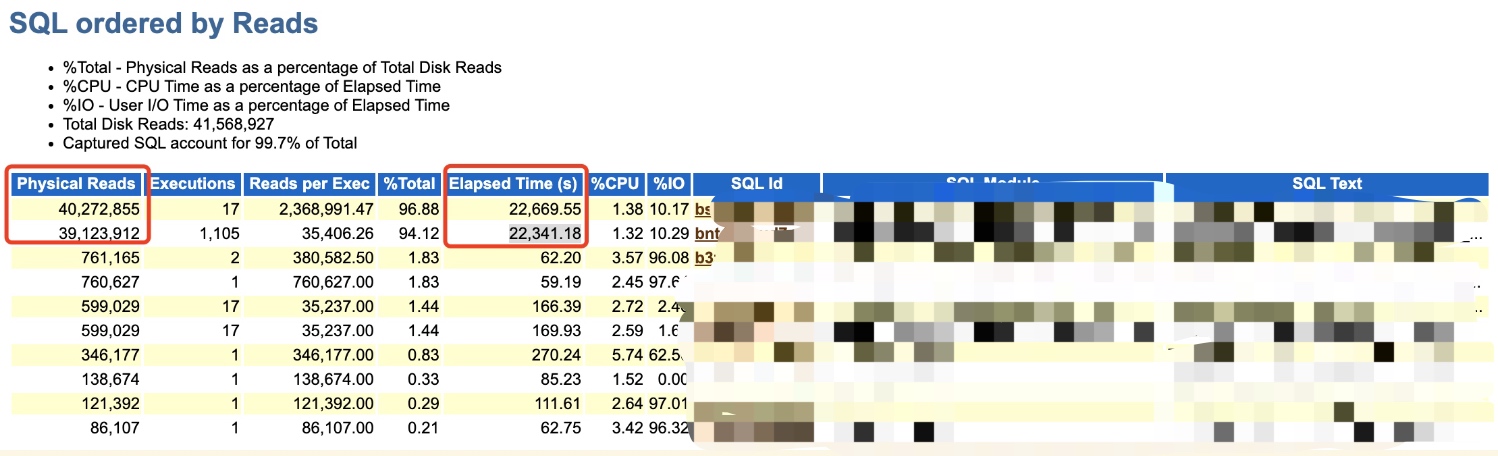
Top 1是一個儲存過程,Top 2是一個SQL,經確認這個SQL也是儲存過程之內的一條SQL,但是並不是之前我們分析的那條SQL,說明之前提供的方向有一定錯誤。這也說明這個Top 2才是問題根本。
同時配合ASH也可以看到的確就是這SQL引發的DPR,導致效能嚴重下降。
到這裡就可以相對穩妥的結案了。
可是呢,好巧不巧的在我介入分析之前,故障後應用側試著調整了索引,變得可接受,但後來又變差,又重建索引,又重啟了資料庫,一系列操作,導致業務表現變好了,但是問題到底有沒有解決,有沒有隱患,都未可知。解釋這一系列的問題,還需要繼續深入分析更多的資料,找到證據證明這一切的因果。
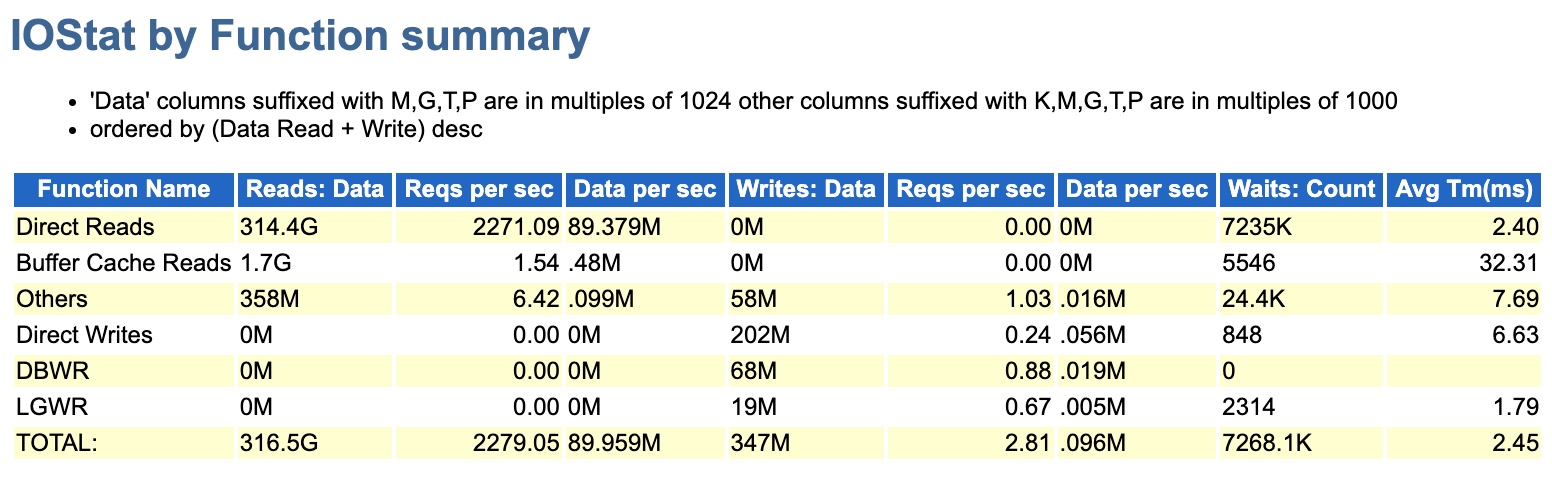
首先,看看所謂變好的時刻,拿到AWR可以看到確實是沒有千萬級別的物理讀了,而且問題SQL都不在TOP SQL中了。
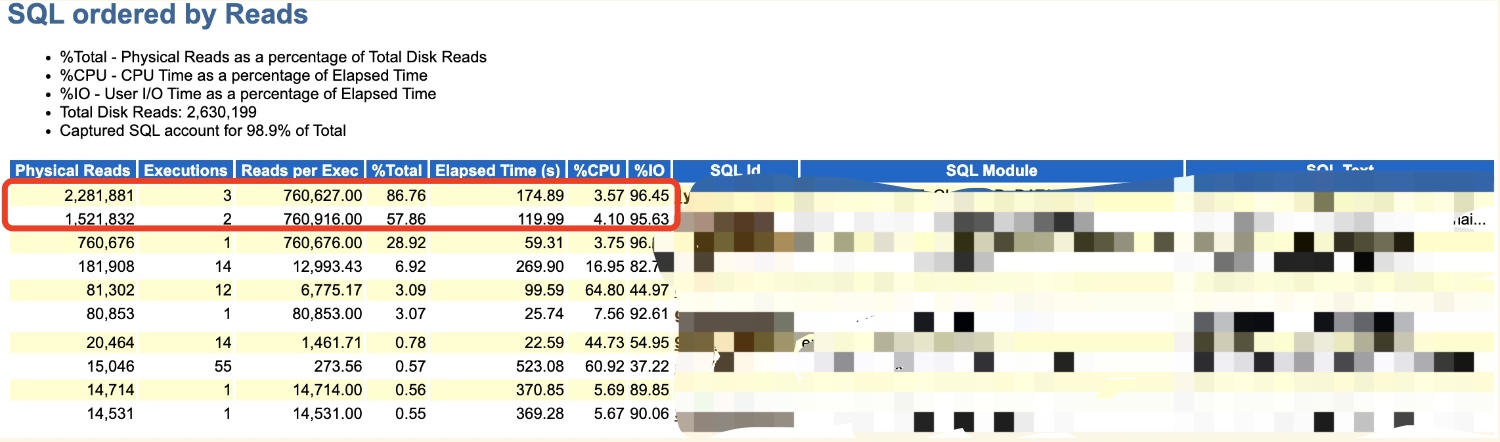
而DPR呢,期間也下降到了18G的情況,比300多G那會兒是好太多了。也說明為什麼最早3G多我會忽略,因為真的太小沒太大影響,也不值當考慮。
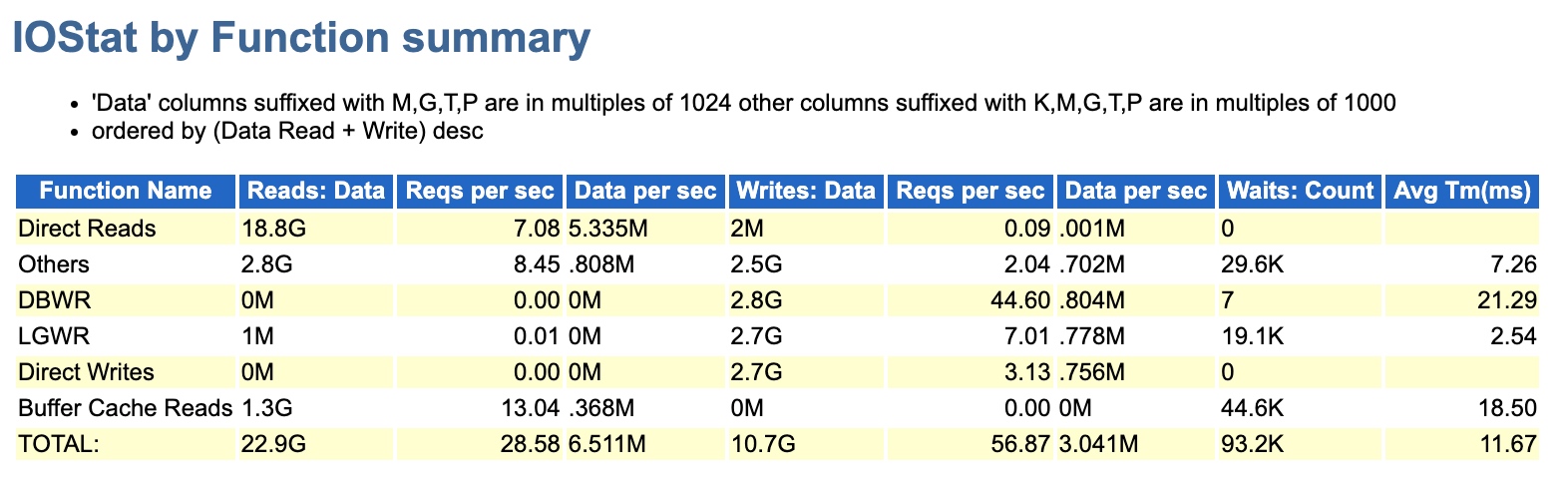
下面來看這一系列的問題:
-
1.調整了索引,變得可接受
是因為有索引後,執行計劃走了索引,沒有引發這個SQL的DPR,所以效果變好。 -
2.但後來又變差
這裡是因為執行計劃又走錯了,走回全表掃導致引發DPR。
看下面這個查詢結果,我們可以看到在變差的時段,全都是走了全表掃的372開頭(PLAN HASH VALUE)的這個執行計劃,而這個執行計劃是DPR的方式,所以,雖然執行數千次,但是每次平均的DISK讀都相當。
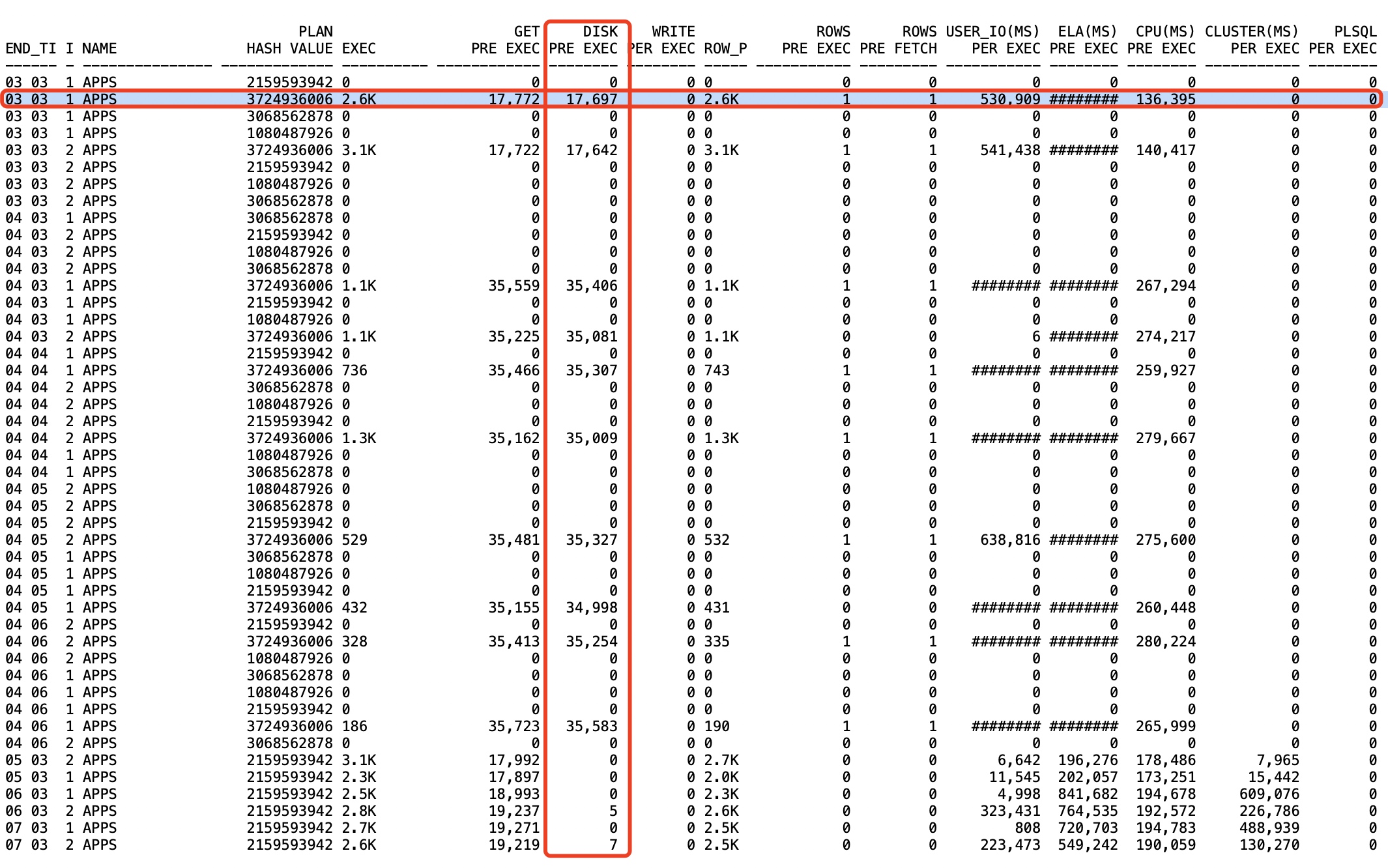
- 3.又重建索引,又重啟了資料庫
這個操作其實就是碰巧了,重啟後走了好的執行計劃,但以後不穩定的因素依然存在。
可是現在要如何來做呢?
其實在這個客戶的系統情況下,討論後還是建議要禁用DPR,因為DPR的設計初衷是,讓那些偶爾存取的大表可以不對buffer cache產生大沖擊,而預設這類大表操作次數是很小的,所以是好的設計。
但這個案例中,表不會特別大,也就是剛好超過「_small_table_threshold」的設定,但是卻存取數千次,走DPR是一種災難。
關閉Oracle 11g的DPR特性可參考:
https://www.cnblogs.com/jyzhao/p/6724299.html
簡單來說,資料庫不重啟的話,就動態去設定這個隱藏引數:「_serial_direct_read」,相關操作參考:
--查詢隱藏引數設定情況: SELECT x.ksppinm NAME, y.ksppstvl VALUE, x.ksppdesc describ FROM SYS.x$ksppi x, SYS.x$ksppcv y WHERE x.inst_id = USERENV ('Instance') AND y.inst_id = USERENV ('Instance') AND x.indx = y.indx AND (x.ksppinm ='_small_table_threshold' or x.ksppinm='_serial_direct_read');--setting:設定隱藏引數為NEVER
alter system set "_serial_direct_read"=never;--rollback:設定隱藏引數為預設值
alter system set "_serial_direct_read"=auto;
alter system reset "_serial_direct_read";--永久生效:
SQL> show parameter event
SQL> alter system set event='10949 trace name context forever,level 1' sid='*' scope=spfile;
--其實也可以session級別更改,影響更小:
alter session set "_serial_direct_read"=never;
回顧下最初問題:同樣的SQL,怎麼突然就慢了?
執行計劃沒變時,是因為DPR這個特性導致,新分割區雖然資料量和歷史相當,但blocks卻明顯增多,超過了小表閾值。
後續建了索引變好,後又變壞,是因為有時候選錯執行計劃導致又走了全表掃又觸發了DPR。
其實如果再想深究探索,還有好多可以思考的,比如,為什麼新分割區雖然資料量和歷史相當,但blocks卻明顯增多?比如為何建立索引後有時又選錯執行計劃等等。只要你願意,就又能探索到好多知識,即便Oracle已經非常成熟,但Oracle DBA也同樣可以做的有技術深度。
最後要說的是,任何隱藏引數都是不建議使用者主動去設定的,DPR這個雖然在很多服務商都建議最佳實踐中都關閉,但是真正正確的開啟方式是,要分情況,要在廠商指導下進行操作。比如舉個極端的例子,如果使用者使用Exadata一體機,上來就把DRP給關了,那就有些暴殄天物了,即便不是一體機,也看你的系統實際情況來決定,有些特性其實還是很好的,只是特定的一些場景下不適用而已,不過要真正分的清說的明這些內容,就還是要修煉自己的內功的。