現代 CPU 技術發展
介紹
這篇文章主要是介紹CPU技術的發展,包括最近幾十年CPU效能提升和半導體工藝發展,當前技術發展方向。希望可以幫助軟體開發者理解CPU指令集和組成執行原理、CPU效能提升的現狀和瓶頸、CPU技術發展方向會如何影響軟體開發/設計的框架和程式設計思想。
提示:因為是面向軟體開發者,所以會忽略掉一些電路設計、製造工藝等底層的硬體知識。同時也不會特別深入的介紹每個知識點,只是提供一個概覽。
CPU 指令集和執行原理
當前使用最廣泛的指令集是x86、ARM、RISC-V,指令集對於CPU效能和軟體開發有多大的影響,指令集的發展方向是什麼。現代CPU內部微架構、流水線是如何設計的,為什麼CPU的控制單元和快取相比GPU複雜很多。
CPU 效能提升和未來方向
近些年CPU效能提升遇到了功耗牆的問題導致提升速度放緩,為什麼以前的優化技術都遇到了瓶頸,同時當前有哪些新的技術方向用於提高CPU的效能。
CPU 技術方向對軟體開發技術的影響
軟體最終會在CPU上執行,更好的利用CPU提供的能力進行程式設計才能帶來更好的效能。一部分CPU優化技術是內部微架構調整對軟體開發者是透明的,例如時脈頻率和IPC的提升。但是另一些優化技術需要軟體開發者進行優化,例如多核心、SIMD、DSA等。這些需要軟體開發者改造的技術會如何影響程式語言和系統框架的設計,從而影響軟體開發者的程式設計方式。
CPU 結構和原理
計算機結構
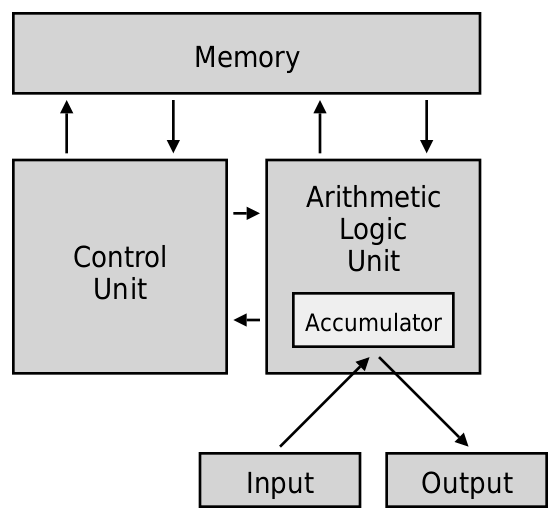
1945 年馮諾依曼提出了一種計算機實現的結構設計,現代的計算機和CPU基本上依然是基於馮諾依曼結構的思想進行實現。馮諾依曼結構定義了計算機的5個組成部分,分別是記憶體、控制單元、運算單元、輸入、輸出:
| 模組 | 功能 |
|---|---|
| 記憶體 | 記憶體是一個記憶體。操作指令和資料以二進位制的形式儲存在記憶體中。 |
| 控制單元 | 控制單元是一個協調者。控制單元按照程式指令順序從記憶體中讀取指令進行執行,將指令傳送到運算單元進行計算。同時控制單元也會協調記憶體和輸入/輸出裝置之間的資料傳輸。 |
| 運算單元 | 計算單元包含加減乘除等計算器。運算單元根據控制單元傳送的指令,從記憶體中讀取資料進行計算,計算完成後重新寫回到記憶體中。 |
| 輸入/輸出 | 輸入/輸出裝置主要是外部的一些裝置進行資料交換。輸入裝置將資料和指令輸入到計算機中,常見的輸入裝置有鍵盤、滑鼠。計算機處理後將資料輸出到外部裝置中,常見的輸出裝置有顯示器。 |
提示:還有一種不同的架構是
哈佛架構,它是一種程式指令和資料分開的計算機結構。現在L1快取中就是使用哈佛架構的思想將指令和資料快取分開儲存。
CPU 結構
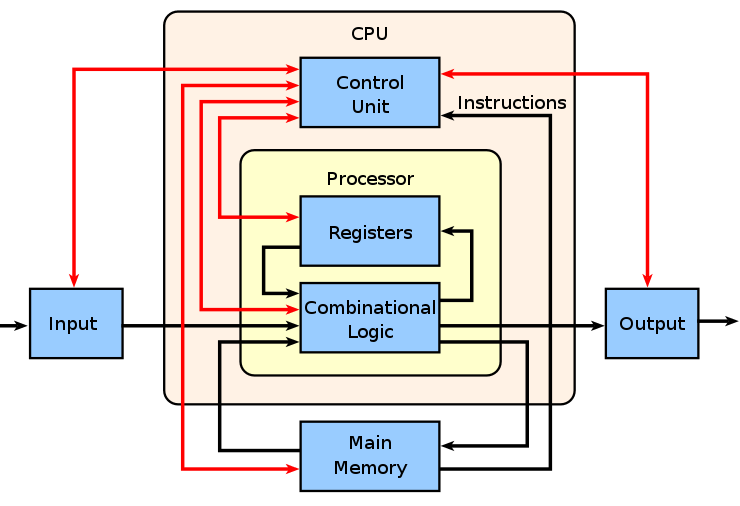
現代CPU雖然使用馮諾依曼架構思想進行設計,但是經過幾十年技術的發展非常複雜。因為記憶體不屬於CPU內部結構,現代CPU主要分為4個組成部分,分別是快取記憶體、控制單元、運算單元、暫存器。這裡先簡單介紹一下各個組成部分的功能,後面流水線實現的部分會更詳細的介紹。
快取記憶體
快取記憶體將記憶體中更頻繁使用的程式指令和資料儲存在快取記憶體中,避免每次都從記憶體讀取降低資料讀寫延遲。
多級快取- 現代CPU通常有2-3級快取,離CPU更近的快取速度更快但是容量更低。
控制單元
控制單元是CPU中最複雜的部分,負責排程和協調其他部分進行執行。排程流水線執行、例外處理等。
-
流水線排程- 分支預測、快取記憶體讀寫、指令讀取、指令解碼、指令排程執行、亂序執行、指令發射、更新暫存器 -
例外處理- 處理 CPU 執行時的各種異常
運算單元
運算單元包含大量的運算器執行計算任務,包括邏輯運算、分支、記憶體讀寫單元。
-
ALU- 算數邏輯單元負責整數加減乘除和位運算 -
FPU- 浮點單元負責浮點數運算 -
Branch- 分支單元用於分支判斷,當 CPU 支援分支預測時還需要更新分支預測快取和分支預測錯誤回滾執行 -
SIMD- 向量單元負責向量運算 -
記憶體讀寫- 記憶體單元負責記憶體讀寫,從快取中讀取資料或將資料寫回快取
暫存器
暫存器用於保持執行時的臨時資料和CPU自身的一些狀態值。
-
通用暫存器- 用於儲存臨時資料,區域性變數/函數引數/返回值等資料 -
PC- 程式計數器儲存下一條指令的地址 -
IP- 指令指標用於儲存當前執行的指令地址 -
SP- 堆疊指標用於儲存棧的地址
指令集架構
ISA(指令集架構)是一種處理器基本功能和指令集架構規範。它定義了CPU硬體可以執行的所有操作指令,指令的編解碼格式、指令型別、暫存器、記憶體定址、例外處理、許可權級別等內容。編譯器和CPU選擇一種指令集規範作為標準進行實現,這樣可以保證任意符合指令集規範編譯的程式碼都可以相同指令集規範的CPU上正常執行。ISA主要有指令集、暫存器、記憶體模型、異常中斷處理等規範定義。
指令集架構規範組成
-
指令集- 支援的操作指令、指令的編解碼格式、指令長度 -
暫存器- 支援的暫存器型別、暫存器數量 -
記憶體模型- 支援的記憶體存取方式、記憶體定址方式、記憶體一致性規則 -
異常/中斷處理- 定義了處理器如何處理異常和終端事件
指令集
指令集定義了處理器可以執行的所有操作指令和指令的編解碼格式。目前常見的指令集主要分為兩種型別,複雜指令集和精簡指令集。複雜指令集CISC主要是以x86為代表,精簡指令集RISC主要是以ARM/RISC-V為代表。
x86
x86指令集架構最早使用在Intel在1978年推出8086處理器,指令集專利由Intel和AMD擁有。目前主要是在PC/筆電和伺服器市場使用,x86的優勢在於軟體生態/相容性和高效能,劣勢在高能耗和開放性:
| 特點 | 說明 |
|---|---|
| 軟體生態 | 發展時間最久技術最成熟,積累了大量的技術和軟體。一直很注重相容性幫助它佔有了更多的市場份額,但是相容性也限制了技術升級和大量的歷史包袱需要相容增加了複雜性 |
| 效能高 | 高效能場景佔有大部分的份額 |
| 能耗高 | 同樣效能下x86相比RISC指令集需要更多的能耗,限制了在低功耗裝置上使用 |
| 開放性低 | 專利主要由Intel所有,其它廠商授權使用 |
| 晶片廠商 | Intel、AMD |
| 主要領域 | 80%+ PC/筆電、90%伺服器市場 |
x86 指令集發展
x86包含多個擴充套件指令集,指令長度至少8位可變長度。以下是x86指令集的一些重要版本更新:
| 特性 | 年份 | 說明 |
|---|---|---|
| 16 位 | 1978 | Intel 在 1978 年推出16位元指令集使用在8086處理器 |
| 32 位 | 1985 | Intel 公司推出了 x86 指令集的32位元擴充套件,可支援 32 位軟體執行 |
| 64 位 | 2003 | AMD 公司推出了 x86 指令集的64位元擴充套件,可支援 64 位軟體執行 |
| SSE | 1999 | Intel 推出了 第一代 SIMD 指令集擴充套件SSE,可支援固定 128 位資料的向量計算 |
| AVX | 2011 | Intel 推出了 第二代 SIMD 指令集擴充套件AVX,可以支援 256-512 位資料的向量計算 |
| x86s | 2023 | Intel 推出的純 64 位架構的白皮書,希望可以減少對於 16、32 位的支援降低相容性包袱 |
ARM
ARM指令集架構是英國 ARM 公司開發的一種RISC指令集架構,指令集專利由ARM公司擁有。ARM誕生於1980年代,當時的處理器都是基於CISC設計複雜度高、功耗大,ARM公司希望使用精簡的指令集實現低功耗和高效能,可以應用在嵌入式裝置和移動裝置中。
因為ARM有非常好的能效優勢,目前主要是使用在追求功耗比的嵌入式和移動裝置。ARM裝置幾乎佔據所有的手機和Pad市場。在筆電市場因為蘋果切換到ARM,同時高通和INVIDIA開始佈局ARM桌面端晶片未來也會推動ARM份額的提升,目前已經佔據了15%+的筆電市場份額。近年ARM效能和晶片設計水平逐漸提高,ARM在伺服器市場的份額逐漸提升。
不過ARM也有和x86同樣的問題就是開放性,導致ARM受到了RISC-V的挑戰。ARM指令集專利屬於ARM公司,同時ARM公司對使用指令集會有一些限制。
| 特點 | 說明 |
|---|---|
| 軟體生態 | 手機/Pad移動裝置和 Mac 系統比較完善,但是Windows平臺還是會有相容性問題使用率很低 |
| 效能高 | 峰值效能相比x86競品效能略低,不過近年也在高速發展 |
| 能耗低 | 因為ARM追求低功耗比的設計,同時大量低功耗裝置廠商的硬/軟體優化,能耗比一直領先 |
| 開放性中 | 專利由ARM所有。雖然比x86開放性會好一些,但也導致部分廠商開始嘗試完全開源的RISC-V。同時由於RISC-V的競爭,ARM也適當放寬了對於自定義指令集的限制 |
| 晶片廠商 | Apple、高通、華為、聯發科 |
| 主要領域 | 幾乎所有移動裝置、14%筆電市場、7%伺服器市場、嵌入式 |
ARM 指令集發展
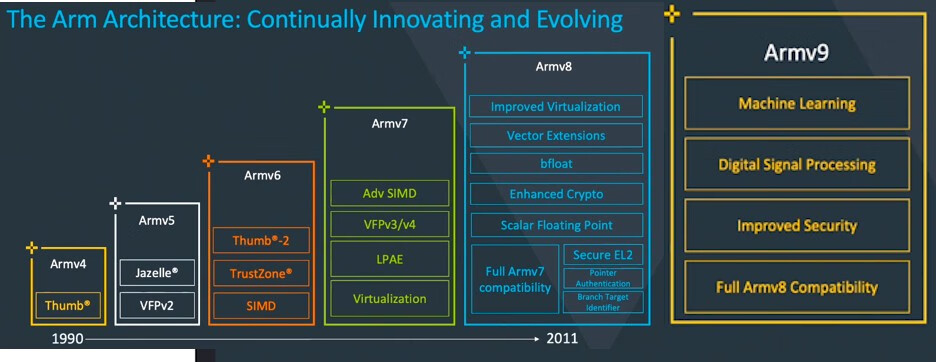
ARM包含多個擴充套件指令集,指令長度為固定32位。以下是ARM的一些重要版本更新:
| 指令集 | 版本 | 說明 |
|---|---|---|
| 32 位 | Armv1 | 1985 年 ARM 推出了32位元架構的指令集 |
| NEON | Armv7 | 2004 年 ARM 推出了第一代 SIMD 指令集擴充套件NEON,可支援固定 128 位資料的向量計算 |
| 硬體虛擬化 | Armv7 | 可支援在同一臺物理機上執行多個虛擬機器器的硬體虛擬化擴充套件 |
| 64 位 | Armv8 | 2011 年推出了64位元擴充套件,可支援 64 位軟體執行,有31個 64 位通用暫存器 |
| SSE | Armv8.2 | 2014 年 ARM 推出了第二代 SIMD 指令集擴充套件SSE,可支援可變長度 128-2048 位資料的向量計算 |
RISC-V
RISC-V架構是2010年由加州大學伯克利分校發起的開源RISC指令集架構標準。RISC-V有以下幾個優勢:
-
精簡設計- 設計非常簡單,相比x86和ARM指令集設計更加精簡,降低了複雜度和指令數量。 -
模組化設計- 採用模組化設計思想。提供精簡的基礎指令集實現基礎能力,其它包括浮點、SIMD、原子操作、位運算等指令都是通過擴充套件指令集提供。晶片設計廠商可以基於自身需求將各種指令集擴充套件模組進行組合應用到不同的場景。 -
開源-x86/ARM都需要授權才能使用,RISC-V完全開源可以免費使用不用擔心版權和專利費的問題。
RISC-V的優勢在於更先進的設計和開源,劣勢在軟體生態和晶片廠商的設計能力還需要進步:
| 特點 | 說明 |
|---|---|
| 軟體生態 | 比較弱。目前更多是用在一些嵌入式裝置或協處理器中,作業系統、軟體開發、使用者級軟體還在起步階段 |
| 效能中 | 峰值效能相比x86/ARM效能差一些,更多是因為x86/ARM晶片廠商的技術更成熟 |
| 能耗中 | 和ARM差不多,更多是因為ARM晶片廠商的技術更成熟 |
| 開放性高 | 由於開源吸引了大量晶片設計廠商的加入,支援新增自定義指令集,不過也導致了一些生態相容性問題 |
| 晶片廠商 | 主要是新型晶片設計商,所以設計能力上相比差一些 |
| 主要領域 | 1%處理器市場、嵌入式、協處理器(手機上目前已經有不少使用RISC-V指令集設計的協處理器) |
RISC-V 指令集
RISC-V有3個基礎指令集和多個擴充套件指令集,指令長度為固定32位。以下是RISI-V常見的指令集:
| 指令集 | 型別 | 說明 |
|---|---|---|
| RV32I | 基礎指令集 | 32位元整數指令集,包含 32 個 32 位的通用暫存器 |
| RV32E | 基礎指令集 | 低功耗嵌入式32位元整數指令集,包含 16 個 32 位的通用暫存器 |
| RV64I | 基礎指令集 | 64位元整數指令集,包含 32 個 64 位的通用暫存器 |
| F/D/Q | 浮點擴充套件指令集 | 單精度 32 位、雙精度 64 位、四倍精度 128 位 |
| M | 整數擴充套件指令集 | 整數乘法除法指令集 |
| A | 原子操作擴充套件指令集 | 原子操作指令集 |
| B | 位元運算擴充套件指令集 | 位元運算指令集 |
| P | SIMD 擴充套件指令集 | 固定長度的SIMD 運算 |
| V | 向量運算擴充套件指令集 | 可變長度的向量運算 |
| C | 壓縮指令擴充套件指令集 | 可將指令長度壓縮位 16 位用於低功耗場景 |
RISC-V 暫存器
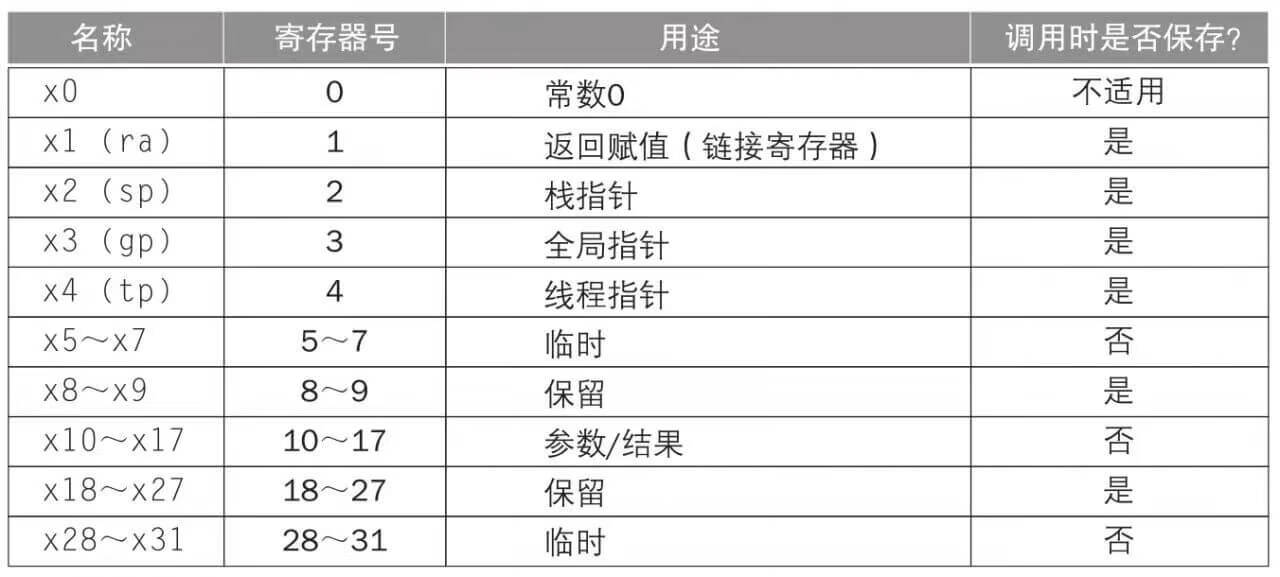
RISC-V 組合語言
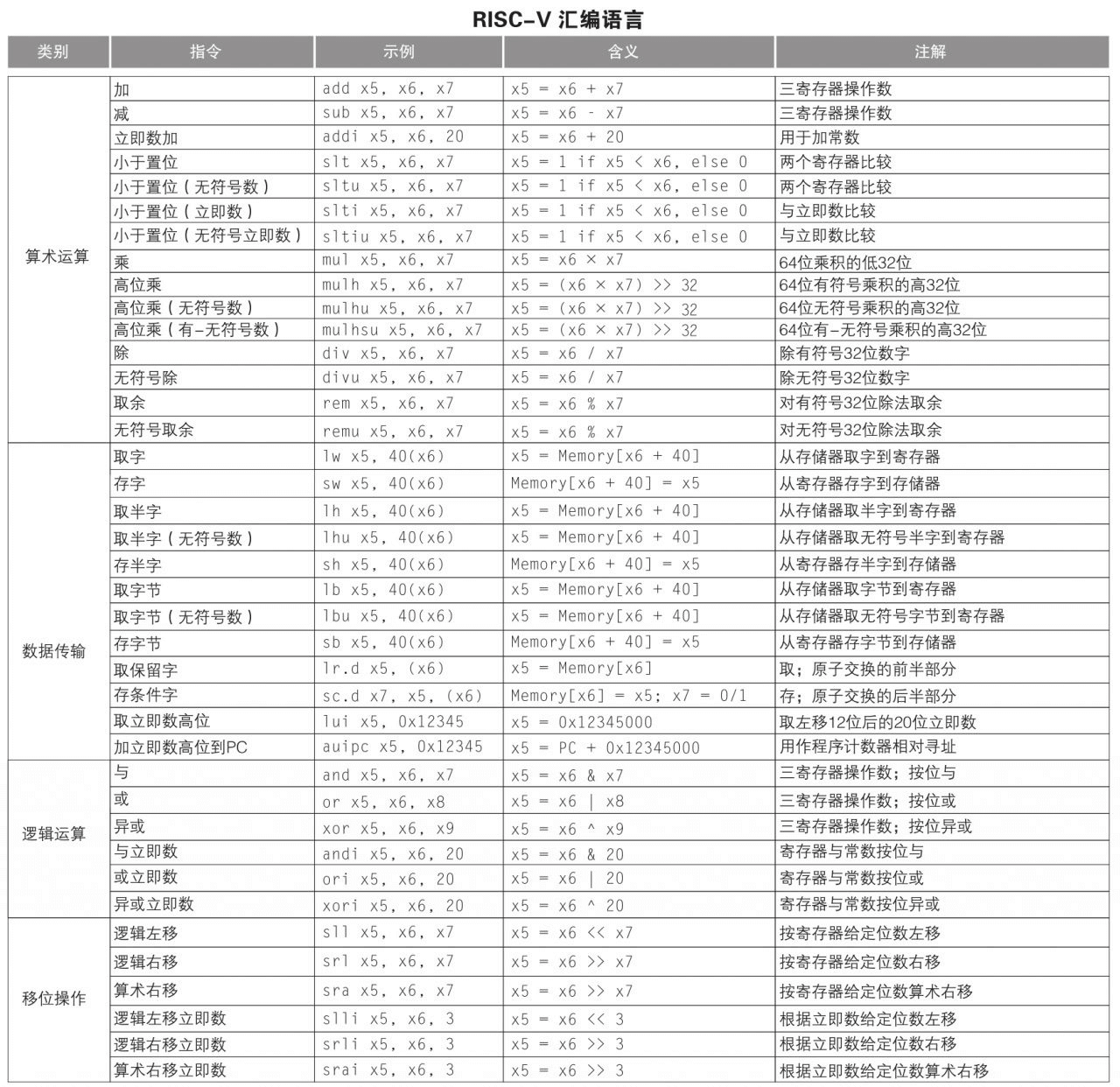
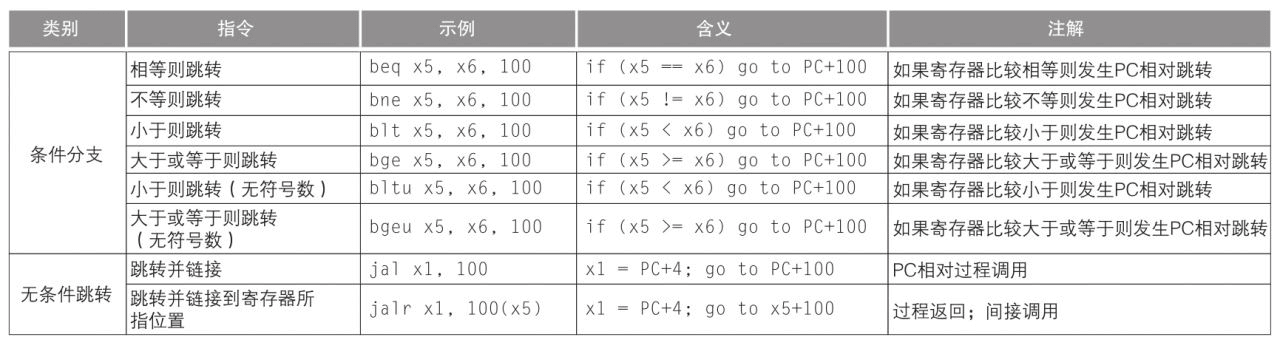
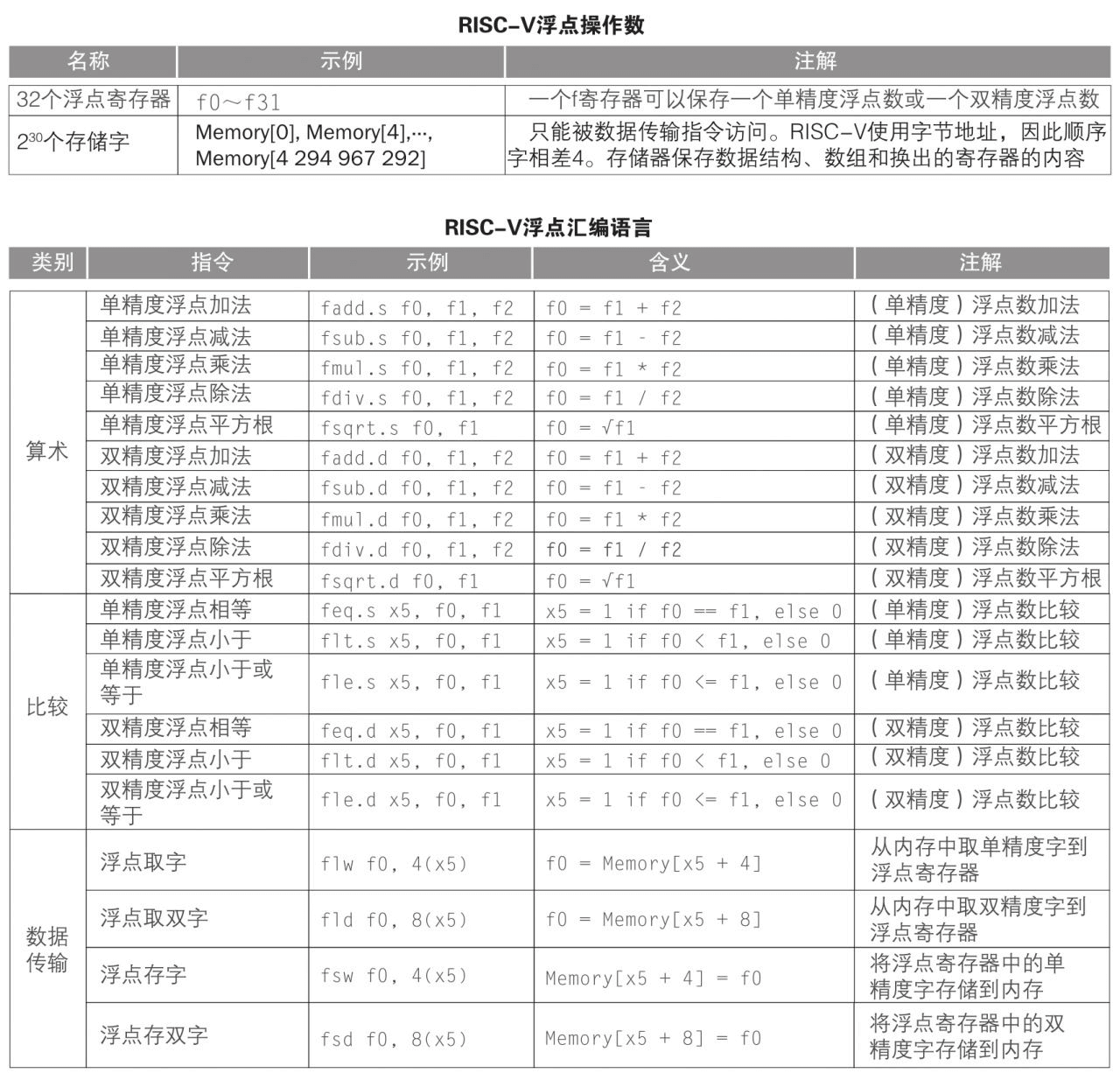
指令編碼格式
指令集規範定義了指令的二進位制格式。以ARM指令集為例,編譯器在編譯時按照指令集規範將每一個組合指令編碼成32位的二進位制指令,CPU在執行時通過解碼器按照指令集規範將二進位制指令解碼成特定的指令進行執行。
x86指令集更復雜,ARM和RISC-V更精簡。x86使用可變長度指令,至少8位+,同時x86支援更多的記憶體定址模式。ARM使用固定32位指令,至少少數幾種記憶體定址模式。
ARM指令編碼格式
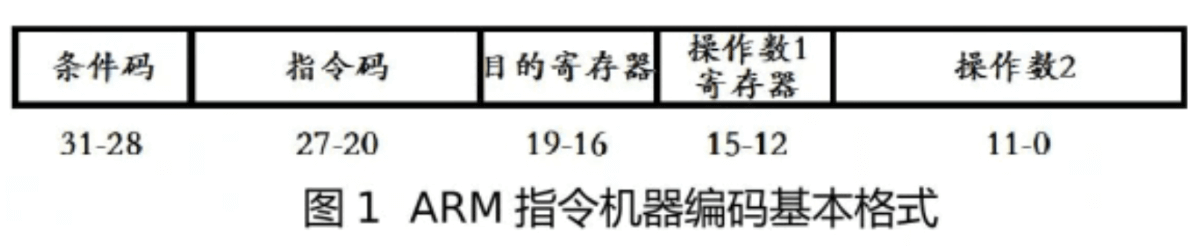
指令集對比
複雜指令集和精簡指令集
x86是複雜指令集,主要是因為x86指令數量多、複雜指令、記憶體定址方式多、指令長度不同等原因,導致硬體設計實現更復雜。使用複雜指令集主要是行業早期技術限制和相容性原因導致的:
| 原因 | 說明 |
|---|---|
| 編譯器技術落後 | 程式大多數都是以組合語言或二進位制碼進行編寫。提供一條複雜高階指令執行多個指令操作,可以使程式開發更加便利。 |
| 記憶體緊張 | 程式需要載入到記憶體中執行,記憶體不足導致需要儘可能降低程式的二進位制大小減少記憶體佔用。複雜指令是可變長度,大部分指令的二進位制位數更短,只有複雜指令會使用更長的二進位制位數,這樣可以增加指令的儲存密度降低大小。 |
| 通用暫存器少 | 由於電晶體的成本導致通用暫存器數量很少,指令會更多的直接存取記憶體。導致更多的指令支援記憶體定址,記憶體定址方式更復雜。 |
| 相容性 | 不斷增加新的指令,同時還需要完全相容老的指令,導致指令數量越來越多。 |
以上這些原因導致早期使用CSIC將更多的複雜性轉移到CPU處理,導致CPU設計複雜成本高。之後隨著半導體技術的發展可以整合更多電晶體和記憶體以及編譯器技術的發展可以更好的生成機器程式碼,1979年開始行業逐漸發現CISC有以下這些缺點:
| 原因 | 說明 |
|---|---|
| 通用暫存器數量少 | 更多的使用暫存器可以減少對記憶體的存取同時指令執行平均週期差異小也有利於流水線執行。 |
| 實現複雜度高 | 指令數量多/複雜指令,導致處理器實現複雜成本更高。同時也會增加編譯器的複雜度 |
| 不利於流水線的設計 | 處理器流水線技術可以使處理器同一個週期內並行執行多個指令和操作流程,例如指令解碼/記憶體讀寫/計算。指令長度不同和複雜指令會使解碼器更復雜,指令執行週期差異大也不利於流水線並行執行 |
| 指令使用率低 | 程式的常用指令只佔整個指令集的20%,造成了很多浪費 |
| 能效高 | 由於複雜度高需要使用更多的電晶體和複雜度,導致產生更多的功耗無法應付低功耗場景 |
以上這些缺點推動了新的指令集都使用RISC設計更有利於提高處理器的效能和能效。但是Intel因為相容性和軟體生態的考慮選擇繼續使用x86。經過這些年處理器技術的發展,x86也做了非常多的技術改進提高效能,不過由於相容性約束指令集很難緩慢的進行改進。
x86的一些技術改進:
-
降低指令複雜度- 持續減少對一些老舊指令的相容減少指令數量 -
內部使用精簡指令集的設計- 由於半導體工藝的發展晶片可以整合更多電晶體提高效能。增加了通用暫存器的數量、內部將複雜指令解碼為多條簡單指令用於流水線執行。 -
更多技術支援- 提供了很多基於Intel平臺的指令集擴充套件和開發框架,作業系統和軟體開發者可以利用這些技術提高效能。
指令差異
以下面的組合為例。RISC指令集必須將記憶體資料載入到暫存器以後才能計算,CISC指令集可以支援指令記憶體定址。所以RISC會生成更多的指令數量。
- CISC
mov eax, [num1] ; 將num1的值載入到暫存器EAX中
add eax, [num2] ; 在暫存器EAX中執行加法操作
mov [result], eax ; 將結果儲存到記憶體地址result處
- RISC
lw num1, [num1] ; 將num1的值載入到暫存器R0中
lw num2, [num2] ; 將num2的值載入到暫存器R1中
add r0, r1 ; 在暫存器R0中執行加法操作
sw r0, [result] ; 將結果儲存到記憶體地址result處
指令集架構實現對比
因為ARM和RISC-V都是精簡指令集設計上很接近,所以使用x86-64和ARM64來對比實現上的一些細節。
| 特性 | x86-64 | ARM64 | 影響 |
|---|---|---|---|
| 指令位數 | 長度不同,至少8位元 | 固定32位元 | 可變長度導致解碼器和指令讀取複雜度更高 |
| 指令數量 | 幾千個 | 幾百個 | ARM 主要是使用頻率高的基礎指令和少量指令擴充套件。x86除了基礎指令還包含大量的複雜指令,同時為了相容性需要支援很多老舊不再使用的指令 |
| 指令執行時間 | 簡單指令大部分相同 | 基本相同 | ARM大部分基礎指令執行時間都在一個時鐘週期。x86因為包含複雜指令執行時間不太一樣,複雜指令可能會解碼成多條微指令執行 |
| 通用暫存器數量 | 16 | 31 | 通用暫存器數量越多,可以將更多的臨時資料存放在暫存器中減少對記憶體的讀取提高效能 |
| 記憶體讀寫方式 | 暫存器、記憶體模式 | 暫存器操作 | x86 很多指令都可以直接操作記憶體。ARM 必須使用LOAD/STORE將記憶體讀取到暫存器或暫存器寫入到記憶體中。不過現代流水線設計x86也會解碼為多條微指令類似ARM的處理器方式 |
| 編譯器複雜度 | 中 | 高 | x86複雜度高導致編譯器實現更復雜 |
| CPU複雜度 | 高 | 中 | x86指令數量更多/長度不同/複雜指令會導致CPU複雜度更高 |
| 程式二進位制大小 | 中 | 高 | 對於x86的一條複雜指令,ARM可能會生成多條簡單指令。所以 ARM 密度更低,指令二進位制會更大導致程式更大一些 |
其他
CPU 遇到不支援的指令如何處理
指令集通常包含基礎指令集和擴充套件指令集,基礎指令集是使用最頻繁的指令,擴充套件指令集是用於一些特定場景的指令集,例如64位元和SIMD支援。通常CPU核心只會支援一部分擴充套件指令集,因為支援更多指令可能會增加額外的計算單元和暫存器,這會導致耗費更多的電晶體增加成本和功耗。同時一些使用頻率低/成本高的擴充套件指令只用在部分追求高效能的場景。以下是兩種情況:
-
不支援部分擴充套件指令集:Intel酷睿12系列開始不再支援AVX-512向量擴充套件,只有在更高階的至強處理器才支援。AVX-512需要多個512位暫存器,多個支援512位向量運算的計算單元。移除AVX-512指令擴充套件可以節省電晶體數量降低功耗或者將這些電晶體用於其他能力。 -
大小核差異化處理:高通驍龍8gen2處理器,大核只支援64位,小核支援32/64位。CPU繼續支援32位元應用執行,32位元應用可以繼續在小核上執行。但是同時支援32/64位元也會增加CPU的複雜度增加成本和功耗,所以在8gen3處理器中已經完全移除了對32位元的支援。
當CPU遇到不支援的指令如何處理,通常CPU會採用幾種處理方式:
-
丟擲異常- 直接丟擲異常停止執行。 -
模擬執行- 解碼成更簡單的指令進行模擬執行,但是可能會導致效能降低。
x86 和 ARM 的效能
當前總體來看能耗比ARM更優秀,高效能場景x86使用率更高。但是指令集對於CPU效能和功耗的影響會越來越小,製造工藝、使用場景、相容性等因素也會導致x86和ARM平臺的效能差異。
| 特性 | x86-64 | ARM64 | 影響 |
|---|---|---|---|
| 製造工藝 | 最新 7nm | 最新 3nm | Intel半導體工藝製程一直落後於臺積電,ARM 晶片大多使用臺積電最新工藝製造 |
| 使用場景 | PC、伺服器 | 移動裝置、筆電、嵌入式 | x86面向高效能設計有更強大的散熱能力,追求更高的峰值效能對於能耗的關注不夠。ARM裝置更多是面向低功耗的移動裝置,續航和散熱能力都有限,包括CPU、作業系統、裝置都會使用面向高能效的設計。例如ARM會使用SOC、大小核、統一記憶體等有利於高能效的設計,作業系統基於高能效對CPU進行排程。 |
| 相容性 | 相容性負擔重 | 相容性負擔輕 | ARM平臺最新的處理器已經不再32位,x86依然需要支援32位、部分16位元型樣、大量陳舊指令和模式 |
隨著ARM逐漸開始在高效能電腦和處理器市場佔據更多的份額,也在不斷的提升CPU效能。x86逐漸減少相容性包袱同時也更加關注能效比。可能未來我們可以更清晰的理解指令集架構導致的效能和能耗差異。
小結
現代指令集架構也在互相借鑑,指令集之間的差異越來越小。x86CPU 內部會將複雜指令解碼成多個簡單指令執行有利於超標量 CPU 指令級並行,ARM也新增更多的指令以支援更多場景,RISC-V的設計者認為ARMv8借鑑了很多RISC-V的設計。
二進位制翻譯技術的使用也越來越多。MacOS提供Rosetta 2軟體支援x86程式在ARM晶片上執行,雖然將x86指令轉換成ARM指令會導致一定的效能損耗和相容性問題(部分指令不支援),但是可以幫助大部分x86程式在ARM平臺上正常執行。同時Windows On ARM也支援x86程式在ARM晶片上模擬執行。
同時從指令集版本升級特性也能看出,近些年指令集的變更主要是在提高向量運算指令應對越來越多的AI和多媒體場景,其他指令改進很少。
處理器技術發展
處理器技術的發展主要是提高處理器的執行效能。對於如何提高處理器的效能,我們先用一個簡單的公式來度量處理器的效能:
程式執行耗時 = 指令數 / CPI / 時脈頻率
-
指令數- 程式執行需要的指令總數 -
CPI- 處理器平均每個時鐘週期可以執行的指令數量(多核心也會增加CPI) -
時脈頻率- 處理器一秒鐘可以執行的週期次數
因為指令數量無法控制,所以只能通過提高CPI和時脈頻率來提升處理器的效能。接下來我們來了解處理器通過哪些技術來提高CPI和時脈頻率。
半導體工藝、時脈頻率、能耗、電晶體數量
功耗、時脈頻率、效能
當前提升處理器效能遇到的最大的挑戰就是功耗牆。電流通過電晶體會帶來熱量,太高的功耗導致處理器溫度過高無法執行,同時移動裝置電池技術發展也非常緩慢。我們先來看看處理器動態功耗計算公式,即處理器電晶體開關切換過程中產生的能耗:
功耗 = 電晶體數量 * 電容 * 電壓^2 * 時脈頻率
提示:這裡只是一種簡單的功耗工時,還需要考慮半導體制造工藝和漏電造成的影響。
從功耗公式可以看出功耗和電晶體數量、電容、電壓、時脈頻率成正比,增加電晶體數量和提高頻率都會增加處理器的功耗。
早期半導體工藝發展通過不斷降低電晶體的尺寸可以減少電容的大小、以及降低電晶體開關切換時間,晶片可以使用更低的電壓執行,通常每次工藝提升可以使電壓降低15%。處理器製造商可以不斷在晶片上增加電晶體數量以及提高時脈頻率,同時控制功耗的增長速度。
半導體工藝發展帶來的提升
-
增加電晶體數量- 在同樣尺寸的晶片中整合更多數量的電晶體,這些增加的電晶體可以用於增加快取大小、控制單元等模組提高處理器的效能。同時也推動了 SOC 晶片的發展,在晶片內整合多核心、GPU 等單元。 -
提高時脈頻率- 提高時脈頻率可以使處理器執行的更快 -
降低電壓- 使用更低的電壓進行執行,在同樣的效能下可以降低能耗。同時更好的電晶體設計可以降低漏電。
技術定律
登納德縮放定律:1974年羅伯特·登納德發現,由於電晶體尺寸變小,在固定的晶片面積上增加電晶體的數量不會增加功耗。
摩爾定律:1965年戈登·摩爾預測,由於電晶體尺寸逐漸變小,同樣面積的晶片上電晶體數量每隔一年翻一番,1975 年改為每隔兩年翻一番。
功耗牆
從2004年開始登納德縮放定律失效。縮短電晶體柵長本來能降低電壓、提高電晶體開關頻率,但在柵長縮短到65nm左右時,電晶體開關頻率增加導致晶片功耗和溫度急劇上升。同時,柵長縮短導致漏電流急劇增加,這些電能也會轉化為熱量。目前大概40%的功耗是由於漏電導致的,即使電晶體處於關閉狀態也會增加漏電能耗。早期每一代新工藝至少可以讓電晶體柵長縮小30%,雖然現在半導體制造商繼續使用現有工藝節點乘以0.7作為下一代的節點名稱,例如 10nm、7nm、5nm、3nm,然而柵長縮小尺寸已遠遠達不到這個要求,需要二十年左右才能使電晶體數量翻一番。同時每一代新技術節點的製造成本越來越高,每代製造成本相比前一代高几倍。
小結
由於功耗牆的限制,相同電壓和電容條件下增加電晶體數量提高核心數量相比增加時脈頻率帶來的功耗影響更小。同時電晶體尺寸減少速度變緩,增加電晶體數量可能需要增加晶片的面積,但是增加晶片的面積會導致生產良率更低成本更高。處理器設計不再追求單核時鐘週期快速提升,朝著多核心方向發展通過增加核心數提高指令吞吐量並行執行提高效能。
提示:以功耗公式來計算,
1GHz=10億。Intel 2006 年推出的Core 2 E6700處理器時脈頻率2.66 GHz、2個核心、2.9億個電晶體。所以增加1個核心帶來的功耗提高比增加時脈頻率1GHz低。
CPU能效曲線
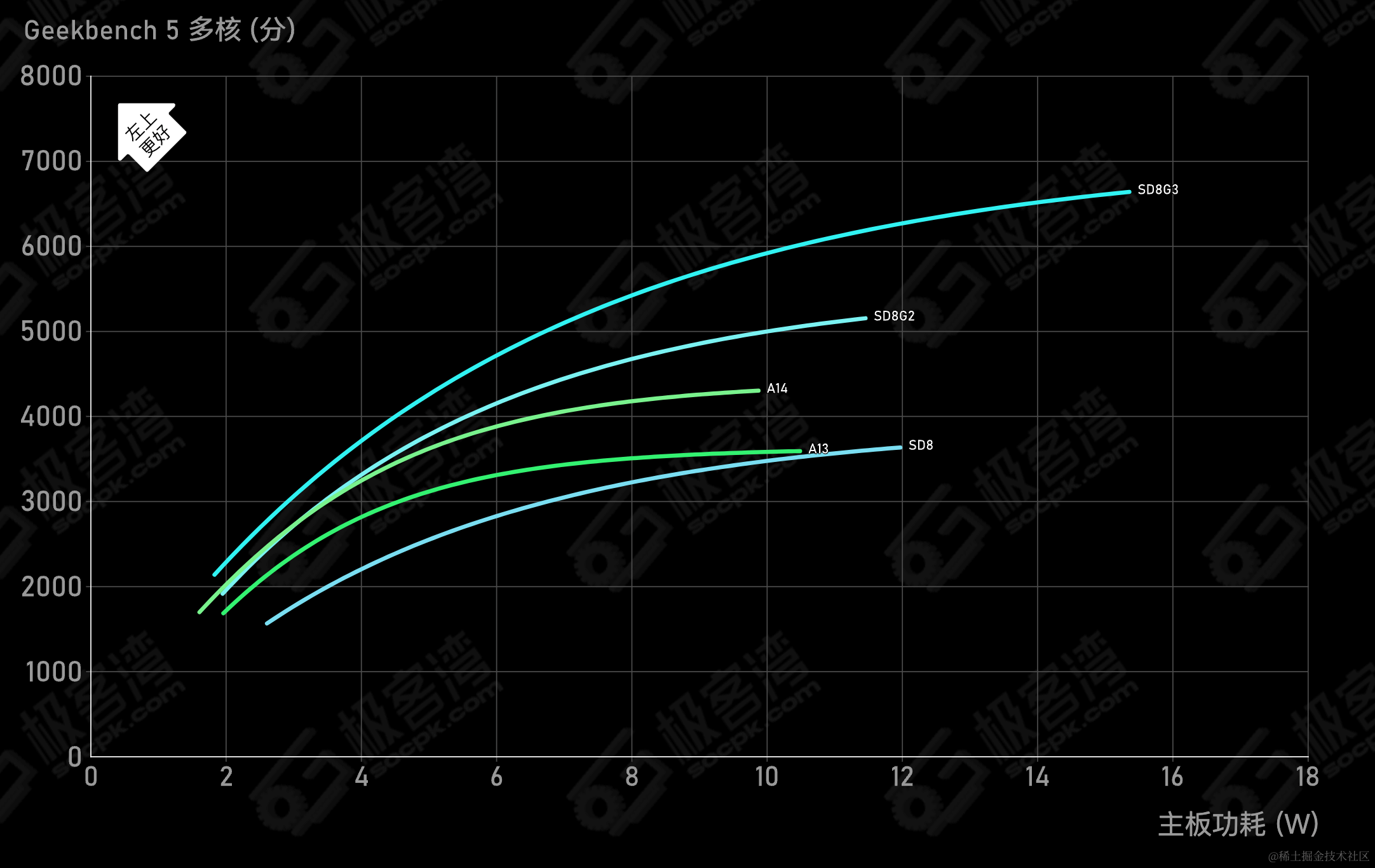
- 更高的效能需要更高的
時脈頻率和電壓執行,導致能效急劇提升
時脈頻率發展
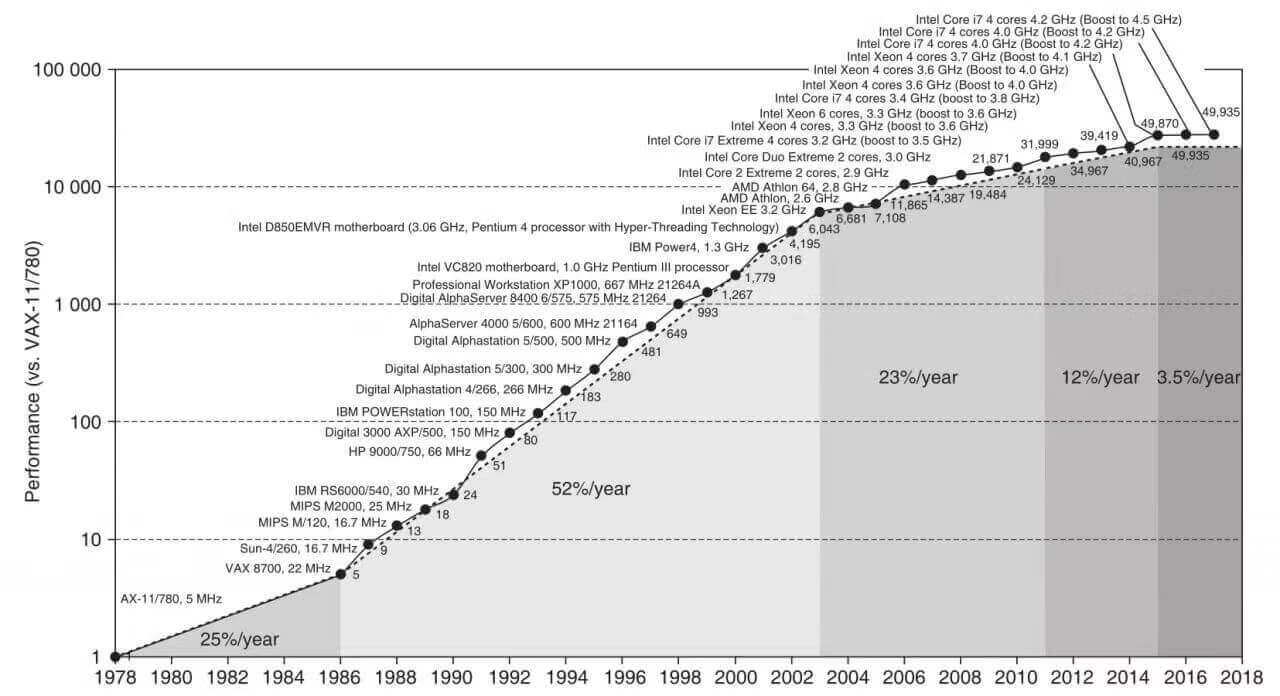
- 處理器時脈頻率提升幅度逐漸放緩
半導體工藝發展
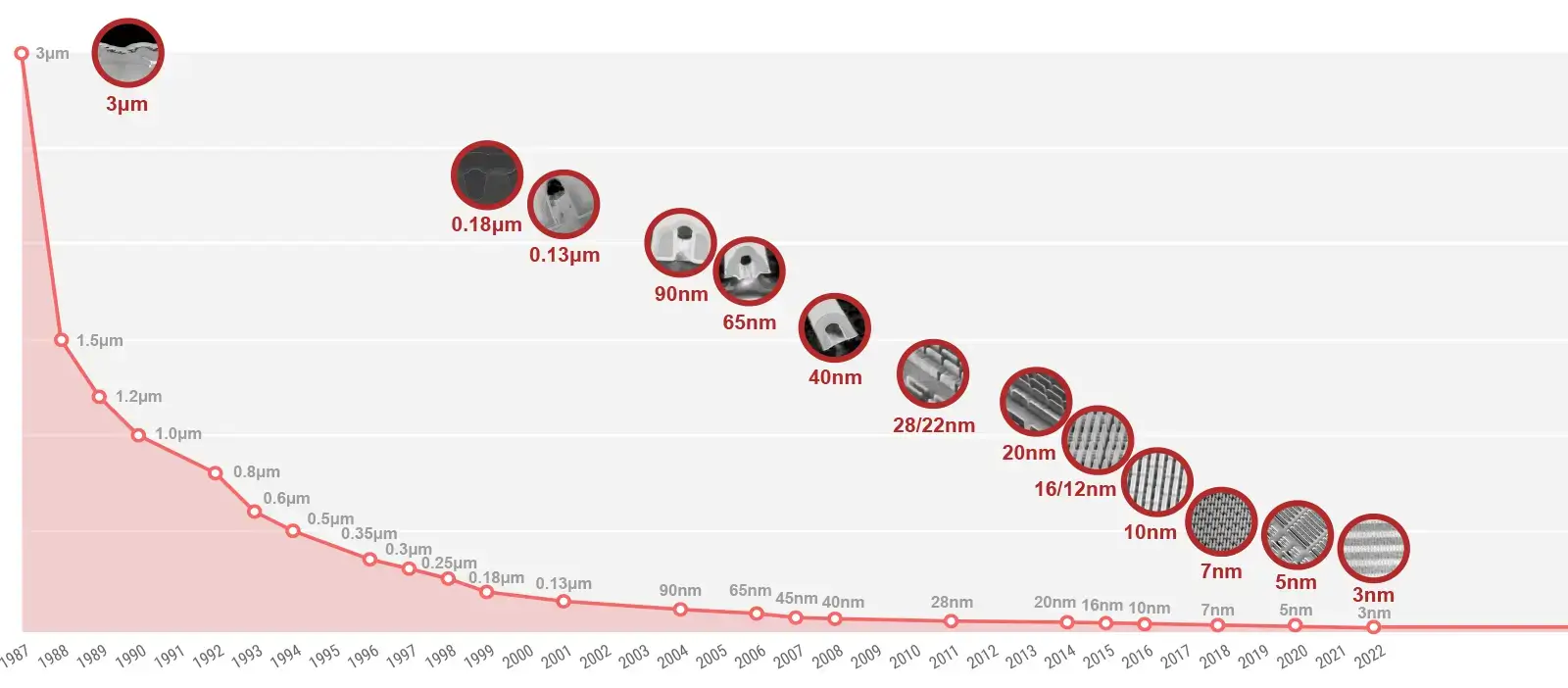
半導體工藝發展主要是依賴光刻技術進步以及更優秀的電晶體設計,下面簡單列一下最近10年半導體工藝發展的重要節點:
-
32nm-2010年Intel量產了首批32nm處理器第二代酷睿處理器,使用了林本堅發明的沉浸式光刻技術。 -
22nm-2011年Intel首先在 22 納米工藝節點上使用了胡正明發明的FinFET(鰭式場效電晶體)電晶體。FinFET減少50%+漏電並提高了效能。目前使用在22nm節點以下的半導體晶片中。 -
5nm-2020年臺積電使用ASML的新一代EUV光刻機,為蘋果生產了第一個5nm處理器A14。相比7nm工藝密度提高80%、速度提高15、能耗降低30%。 -
3nm-2022年臺積電開始量產3nm晶片。 -
2nm-2025年臺積電計劃開始量產2nm晶片,使用GAAFET(圍柵場效電晶體)代替FinFET電晶體。GAAFET可以降低漏電、降低尺寸和提高效能。
FinFET、GAAFET
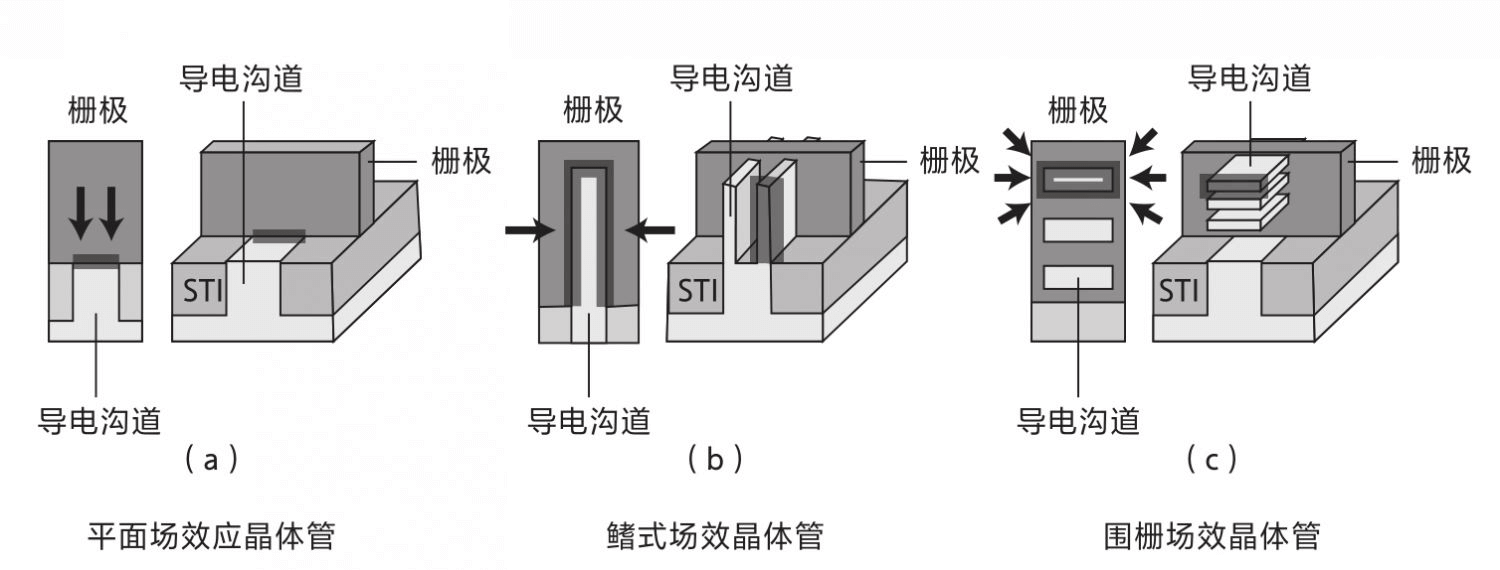
電晶體柵長髮展
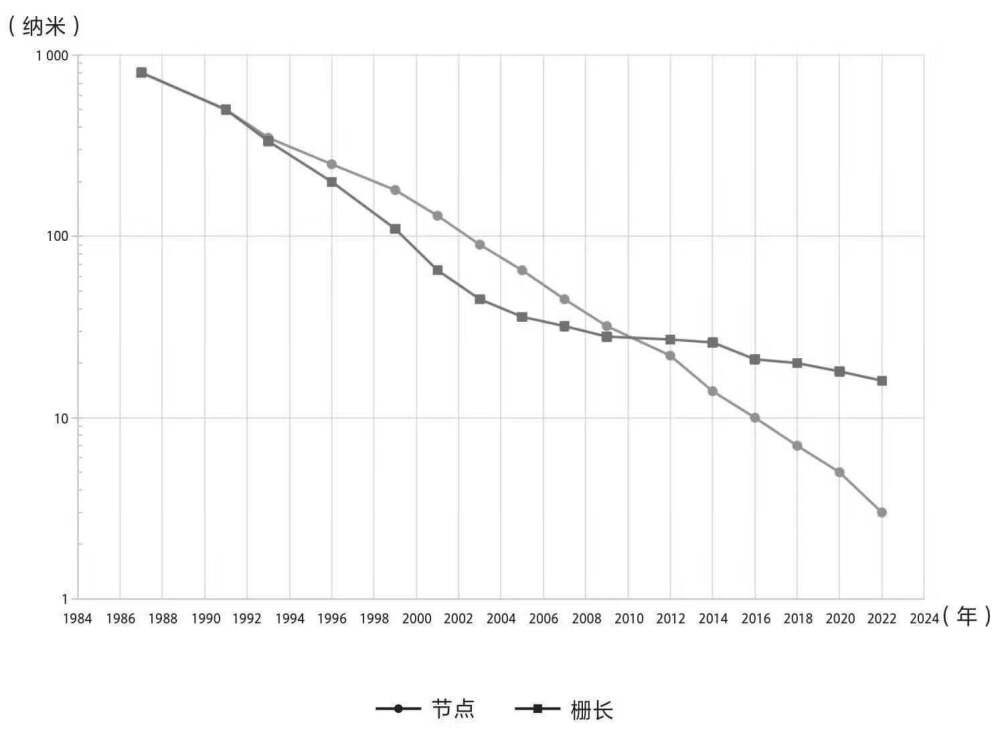
- 雖然電晶體制造技術節點在不斷降低,但是柵長縮小速度越來越慢
指令級並行:微架構和 IPC 提升
IPC提升主要是提高指令的吞吐量,通過優化處理器流水線的微架構,提高一個週期可以執行的指令數量。
流水線介紹
在理解流水線之前我們先看簡單瞭解一下程式執行的步驟。通常一個程式指令可能會經歷五個執行步驟:
-
讀取指令- 根據PC暫存器的地址,從記憶體中讀取下一條執行指令到CPU中。 -
解碼指令- 將二進位制指令解碼成具體需要執行的指令,複雜指令可能需要解碼為多條指令。 -
執行指令- 呼叫執行單元進行運算。 -
讀寫記憶體資料- 從記憶體中讀寫計算的資料。 -
寫暫存器- 將運算完的資料寫會暫存器。
早期的CPU設計只能按照程式指令的順序進行執行,每個指令都需要經過這五個執行步驟。如果每個步驟需要200ps的話,一個時鐘週期需要1000ps並且只能執行1個指令。3個指令需要3000ps。之後就誕生了流水線技術,通過在一個時鐘週期內執行多條不同指令的不同步驟,提高流水線的吞吐量實現指令集並行。雖然不能降低單個指令的耗時,但是可以降低多條指令的總耗時。
五級流水線優化執行
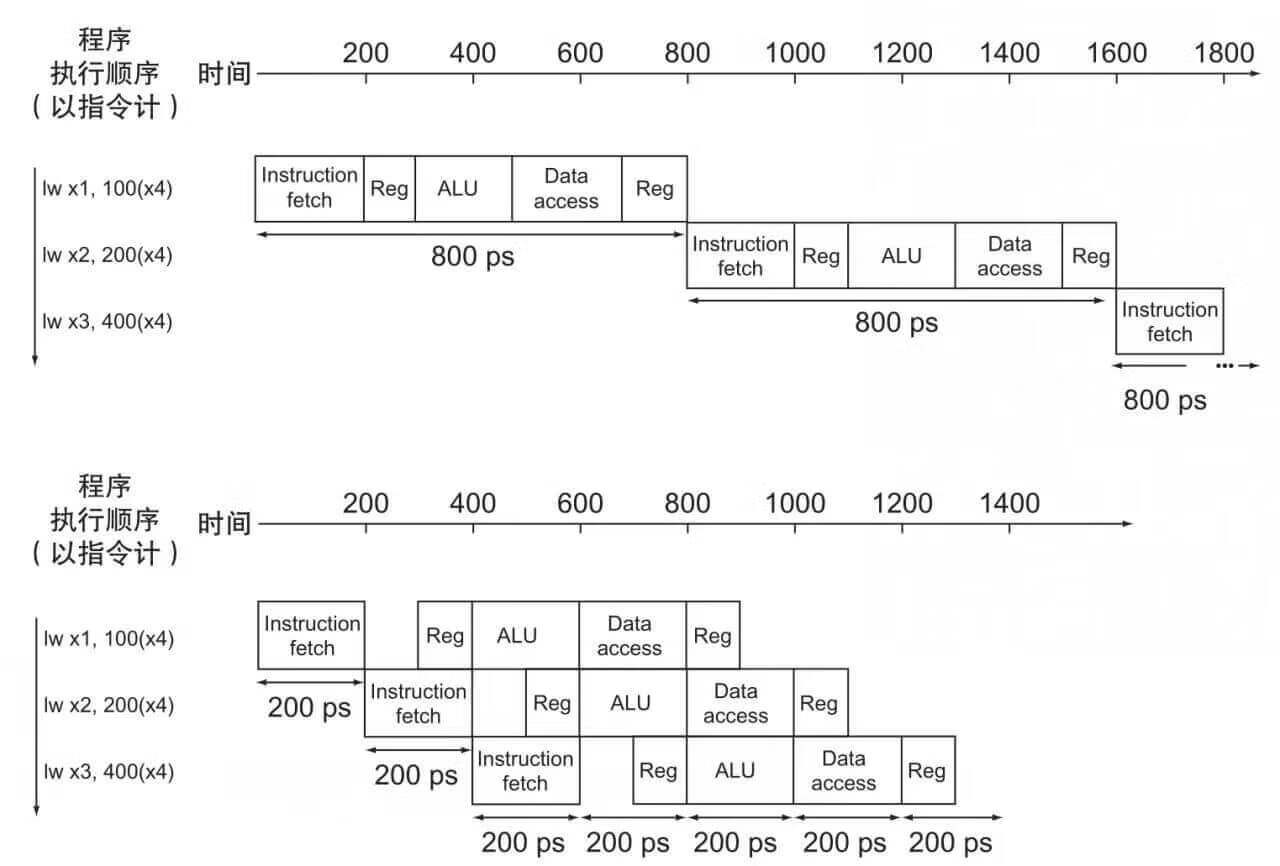
-
理想情況下三條指令在每個週期都執行多個不同的步驟,降低了三條執行執行的總耗時
-
一個時鐘週期的耗時取決於這個週期內最長耗時的操作
現代流水線設計
現代CPU核心中的流水線設計很複雜,也會導致CPU中的控制單元佔比很大。現代CPU流水線設計主要為了讓運算單元每個週期都可以滿負載執行,通常有10級流水線,加入了更多的功能模組用於增加流水線的吞吐量提高IPC。流水線通常分為前端和後端,前端主要負責讀取指令和解碼指令,後端主要負責排程發射指令和執行指令。接下來我們通過下圖的流水線範例來了解現代CPU中的流水線設計,參考了當前主流的CPU效能核心的微架構實現。
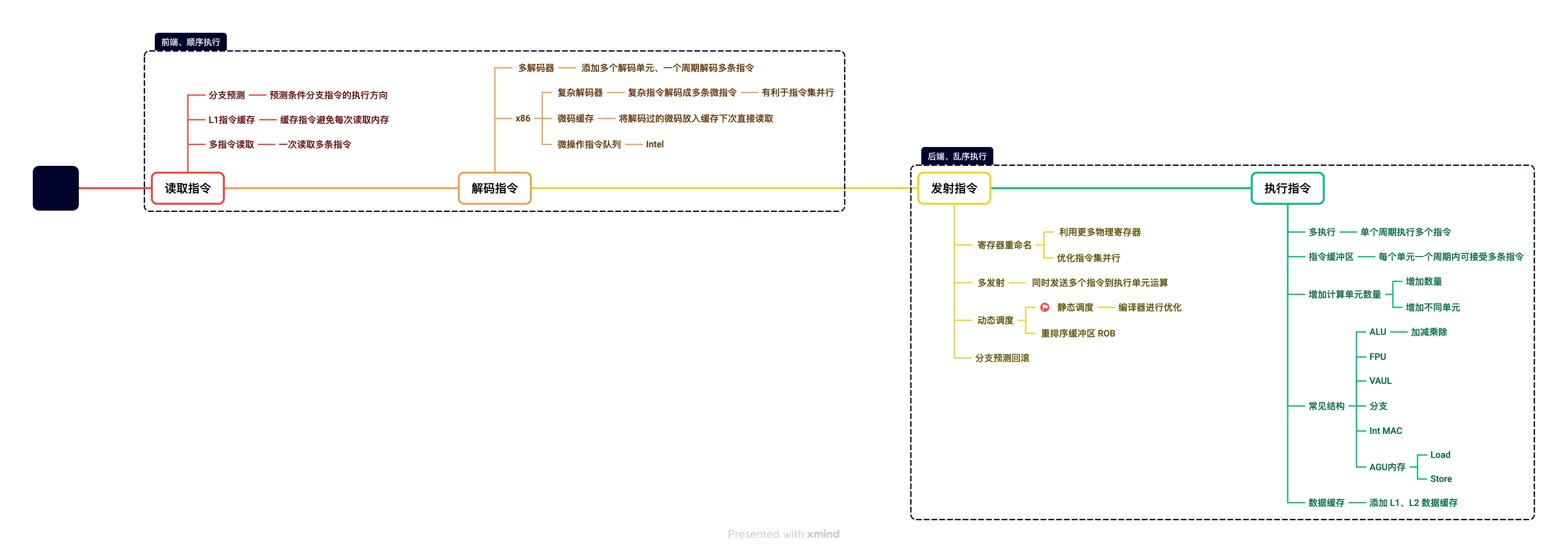
提示:
Intel最早在2004年推出了30+級流水線的CPU,但是流水線數量太長會導致微架構設計非常複雜,同時分支預測失敗懲罰更高。這些原因導致目前CPU通常使用10級左右的流水線。
讀取指令
讀取指令將記憶體中的指令讀取到CPU中的指令緩衝區中,相關的優化是為了降低讀取指令延遲和讀取更多指令到CPU中,提高流水線的吞吐量。
多指令讀取
由於從記憶體中讀取程式指令延遲比較長,現代CPU會按照PC暫存器的地址一次性讀取多條後面需要執行的程式指令CPU中,減少後續流水線空閒時間。將指令放在指令緩衝區中,等待解碼器的使用。
分支預測
由於一次性讀取多條程式指令,會遇到一個問題就是當分支判斷的時候由於分支還未執行無法知道後續分支執行的方向。通過新增分支預測單元提前預測分支可能的執行方向讀取後續需要執行的程式指令。
分支預測分為動態分支預測和靜態分支預測。高效能CPU核心都會使用動態分支預測的方式,分支預測成功率可以達到80%-90%。分支預測錯誤會導致分支預測懲罰需要回滾錯誤分支的指令執行,通常會導致10+個週期的流水線懲罰。
靜態分支預測和動態分支預測
| 型別 | 實現方式 | 優點 | 缺點 | 詳情 |
|---|---|---|---|---|
| 靜態分支預測 | 編譯器 | 實現簡單、成本低 | 預測準確性比較差 | 在編譯器中插入相關分支預測判斷 |
| 動態分支預測 | CPU | 預測成功率高 | 成本高、增加功耗 | 一種簡單實現:在每個分支執行完成的時候,將分支結果儲存到快取中進行統計。分支預測執行判斷時,根據之前這個分支的執行結果選擇概率更高的執行方向。 |
L1 指令快取
為了避免每次從記憶體中讀取指令延遲比較長,將讀取過的指令存入快取中。經常使用的指令就可以直接從快取中讀取,但是L1快取由於讀取效能的限制容量有限,通常只有幾十KB,在快取缺失的時候可能會從記憶體中讀取指令導致流水線卡頓。
TLB 快取
由於CPU存取記憶體時,會將程式空間的虛擬地址對映為實體記憶體地址,這個對映過程有一定的耗時。通過加入TLB緩衝區將轉換後的對映加入到快取中,下次讀取程式指令地址時就可以直接讀取無需再進行地址轉換。
解碼指令
解碼指令將指令緩衝區中的指令按照順序微碼為多個微操作放入微操作佇列中,相關的優化是為了降低解碼耗時和同時解碼更多的指令。
預解碼
將指令緩衝區中幾十個位元組的指令解析成多個單獨的程式指令,後續再傳送到解碼器提高解碼效率。特別是對於x86指令由於指令長度不同,預解碼階段會更加複雜。
多解碼器
解碼器將程式指令解碼成CPU微操作指令。現代CPU核心中通常會新增多個解碼器用於提高解碼效能,通常會有3-10個解碼器單個時鐘週期可以解碼多條指令。
x86平臺的複雜指令可能會生成多條微操作,所以x86處理器通常包含一個複雜指令解碼器,專門用於解碼複雜指令。x86處理器的解碼器通常比ARM更少,A17 Pro的高效能核有9個解碼器,Intel i9 14900K的高效能核心只有6個解碼器其中包含1個複雜指令解碼器。
微指令快取
x86平臺由於複雜指令的存在,解碼指令效率更低。通常會加入額外的微指令快取,將已經解碼的指令微操作對映儲存到快取中,下次可以直接讀取無需再解碼。
發射指令
多發射
一個週期內發射多個指令到運算單元,提高運算單元的吞吐量。有兩種實現多發射的排程方式,靜態排程和動態排程。現代CPU高效能核心使用動態排程一個週期可以發射6-10個指令。
靜態排程和動態排程
| 型別 | 實現方式 | 優點 | 缺點 | 詳情 |
|---|---|---|---|---|
| 靜態排程 | 編譯器 | 實現成本更低 | 效能提升一般 | 編譯器對指令的執行順序進行調整 |
| 動態排程 | CPU | 效能更好 | 成本高、增加功耗 | CPU實時對指令進行排程和發射 |
動態排程
多發射排程主要是為了提高指令發射的效率,同一個時鐘週期發射出更多的指令到計算單元,讓計算單元持續處於高負載運算狀態中提高吞吐量。一個時鐘週期內將不同的指令發射到不同的計算單元,但是需要解決流水線冒險帶來的挑戰,通常存在三種型別的流水線冒險:
-
資料冒險- 當前指令必須依賴前面一條正在執行的指令的計算結果,例如依賴前一條加法指令的計算結果,需要等待前一個指令將結果寫入到暫存器中。 -
控制冒險- 當前指令必須依賴前面一條正在執行的指令的分支判斷結果,通常使用分支預測方式進行解決。 -
結構冒險- 當前指令因為硬體資源限制導致無法執行,例如多個指令需要同時使用同一個暫存器,多個指令需要同時使用某個加法計算單元。
流水線排程過程中需要解決流水線冒險的問題,現代CPU微架構設計會通過ROB(重排序緩衝區)對執行進行動態排程,ROB越大可以儲存的指令數越多效能越好:
-
暫存器重新命名- 現代CPU核心中通常有更多的物理暫存器數量,超過指令集中定義的暫存器數量。需要對暫存器進行重新命名放置到不同的暫存器中提高指令級並行,例如兩條指令都使用同一個暫存器可以放置到不同的暫存器中進行處理。 -
指令重排序- 因為需要同時發射多條指令提高吞吐量,所以需要對指令的執行順序進行調整導致亂序執行。但是會保證最終的執行結果符合原本的預期。 -
資料預讀取- 提前將後面程式指令需要使用的記憶體資料載入到快取中,避免快取缺失導致的延時。 -
分支預測懲罰- 流水線執行過程中會將分支預測相關的指令執行結果暫時儲存,等待最終分支預測正確時才會執行完成。如果分支預測錯誤需要回滾這些錯誤預測的指令。 -
指令發射- 將對應的指令發射到計算單元
執行指令
多執行
一個時鐘週期可以並行執行不同的計算單元,只要當前計算單元有空閒。
計算單元緩衝區
將指令和指令資料發射到計算單元的緩衝區中等待執行,當計算單元空閒時即可開始執行。
增加計算單元
增加更多的整數運算、浮點運算、分支判斷和記憶體讀寫單元數量,一個時鐘週期可以執行更多的運算和記憶體讀寫操作。現代CPU效能核心通常有10+個算數單元和多個記憶體載入單元。
L1/L2 資料快取
通過L1、L2快取讀取記憶體資料,將常用的資料儲存到快取記憶體中,提高下一次讀取的效能。
主流 CPU 核心的微架構設計
現代CPU通常使用大小核設計,效能核有更復雜的流水線設計效能更好,能效核流水線設計更簡單效能會差一些。
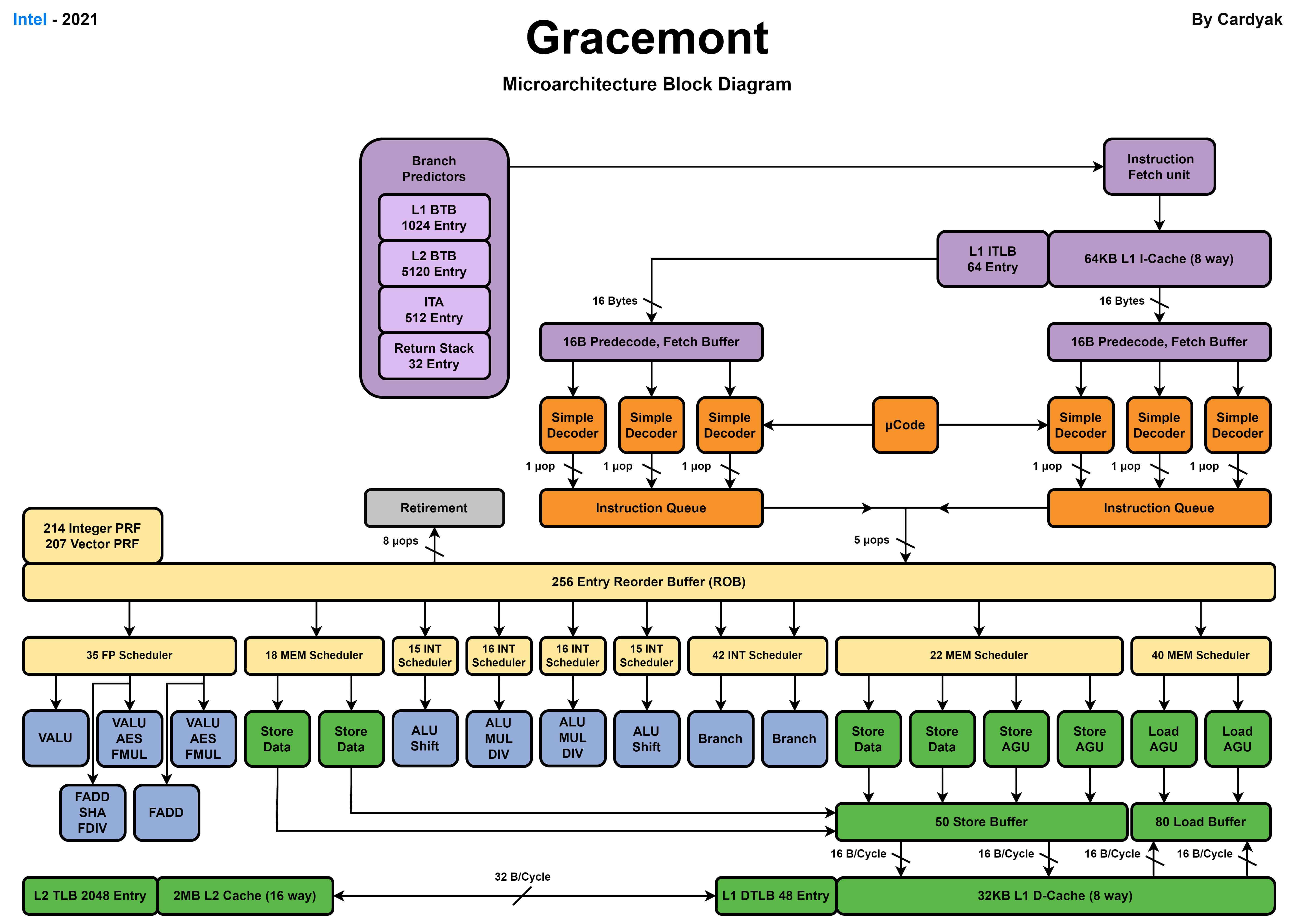
Intel
Intel最新的桌面級別處理器Core i9 14900K使用了8個Raptor Cove效能核和16個Gracemont能效核。
Raptor Cove效能核
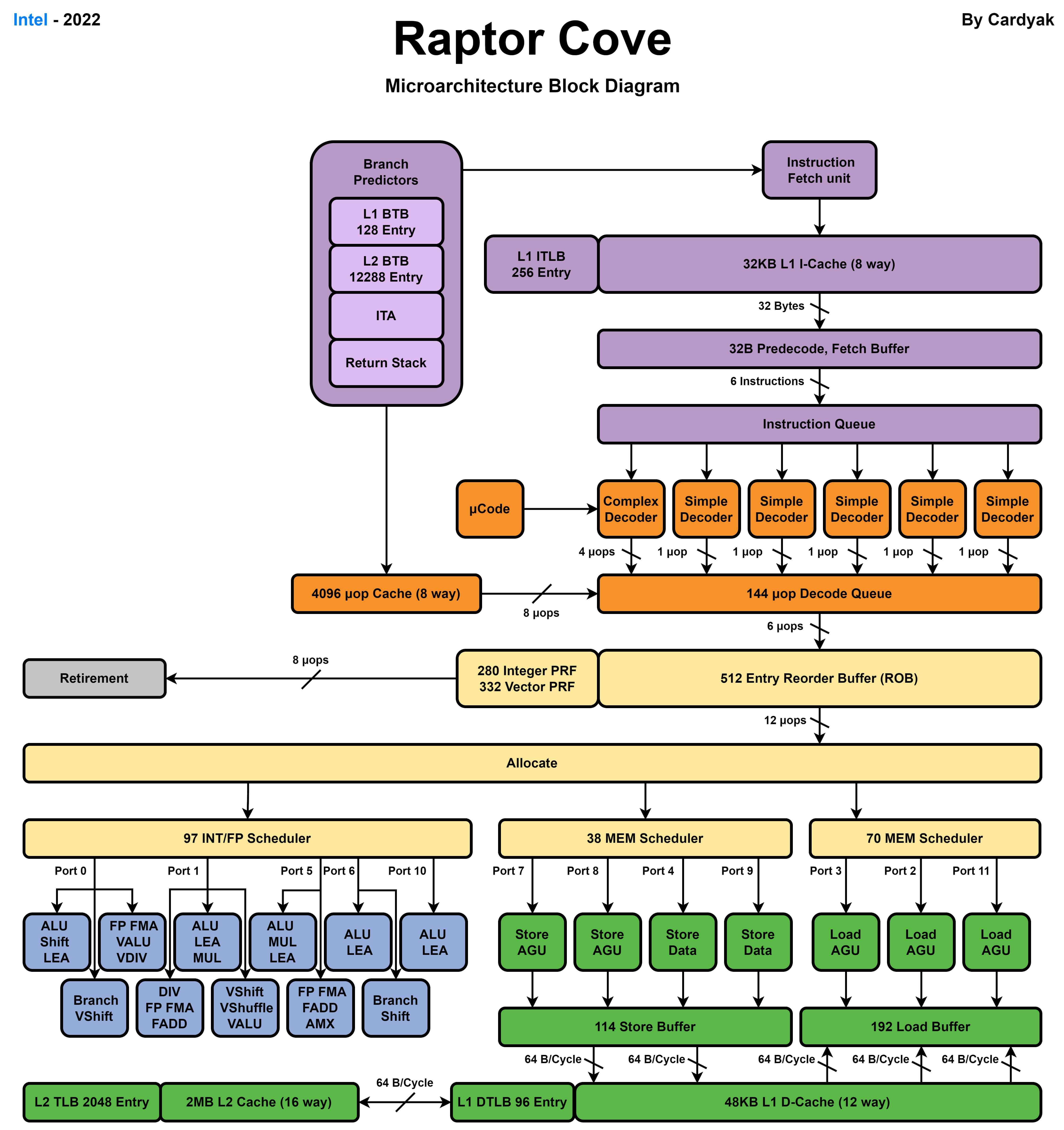
Gracemont 能效核
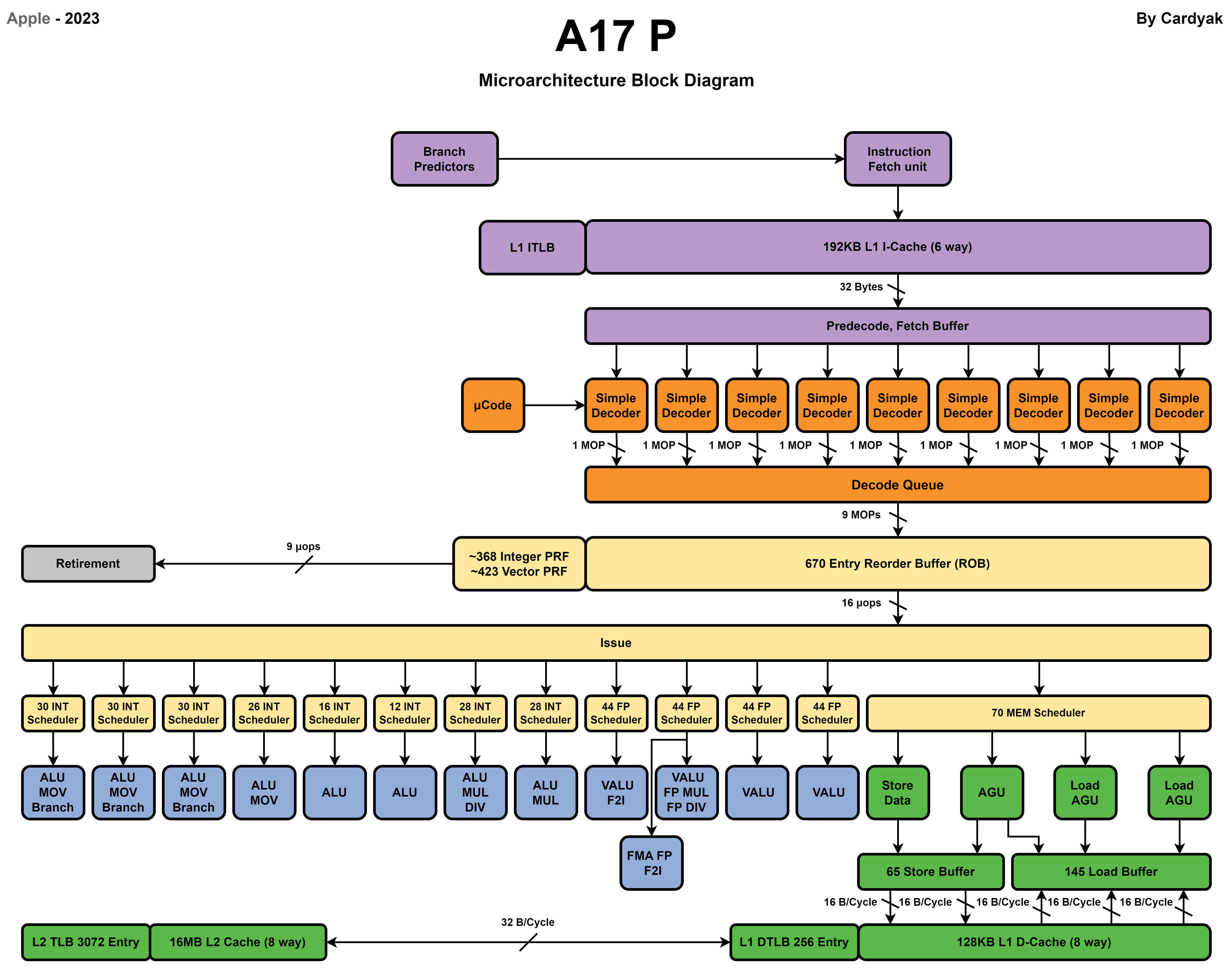
Apple
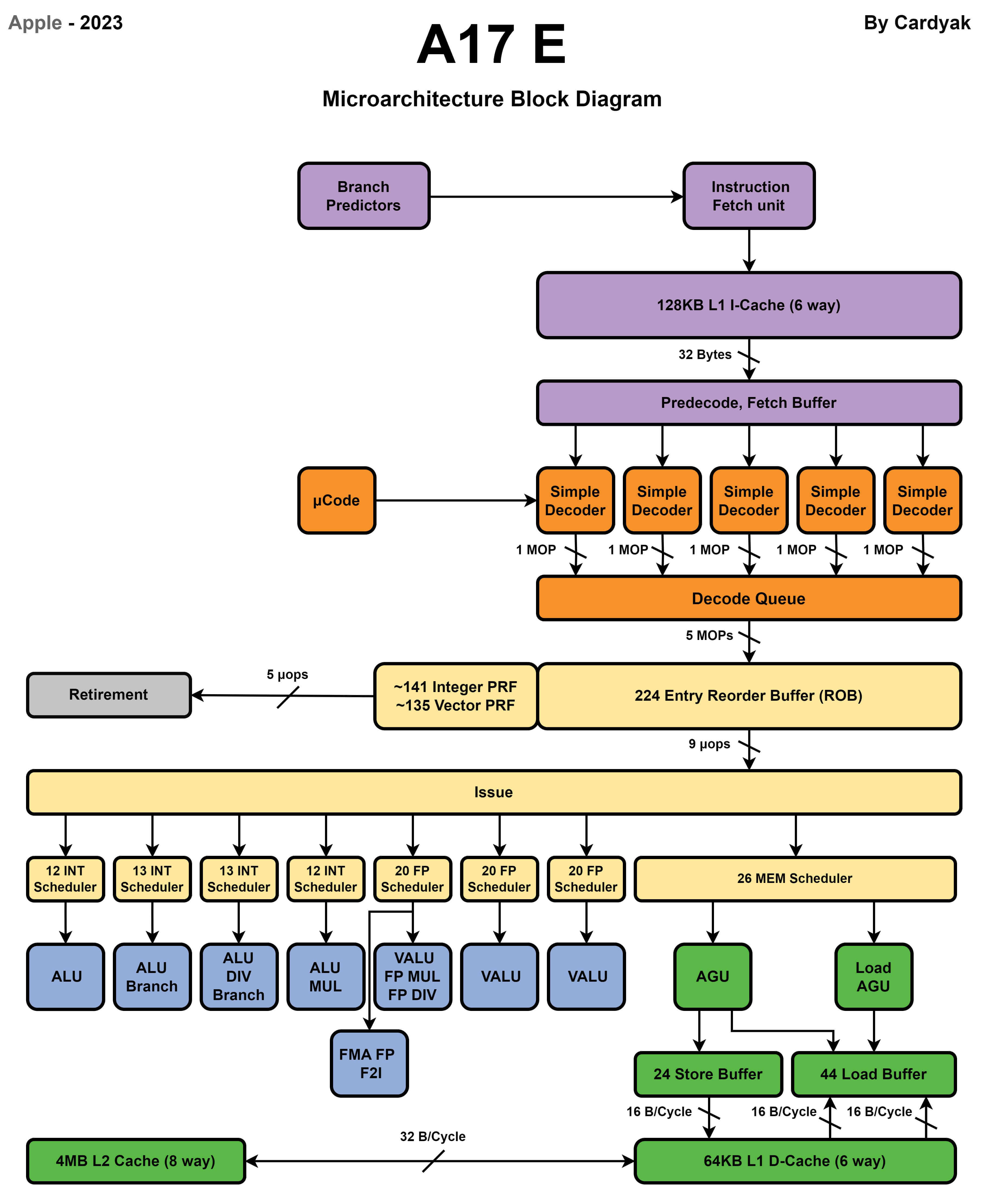
Apple最新的A17 Pro處理器使用了2個效能核和4個能效核。
效能核
能效核
ARM
高通最新的8 Gen 3處理器使用了1個X4超大核,5個A710效能核,2個A520能效核。
X4 超大核
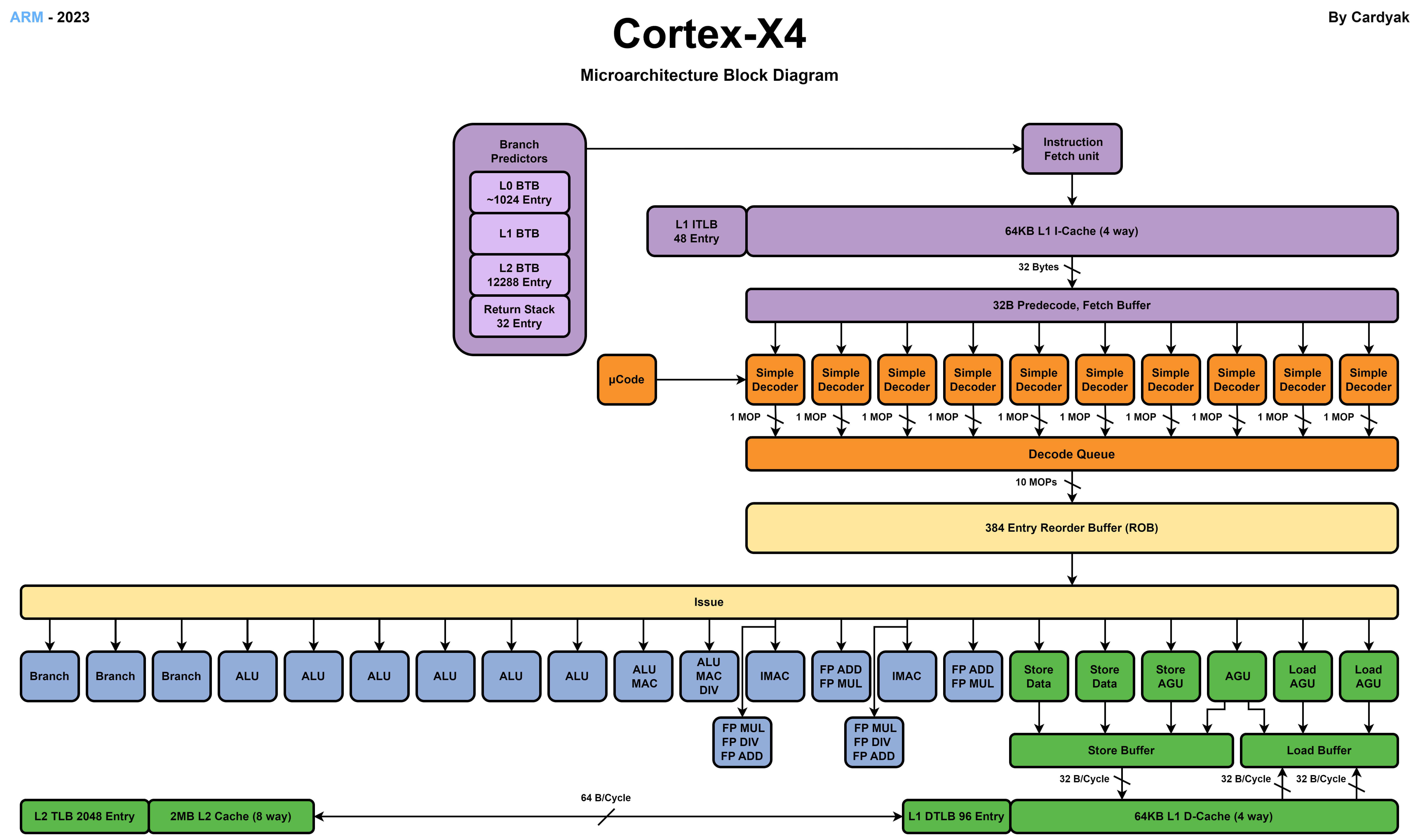
A720 效能核
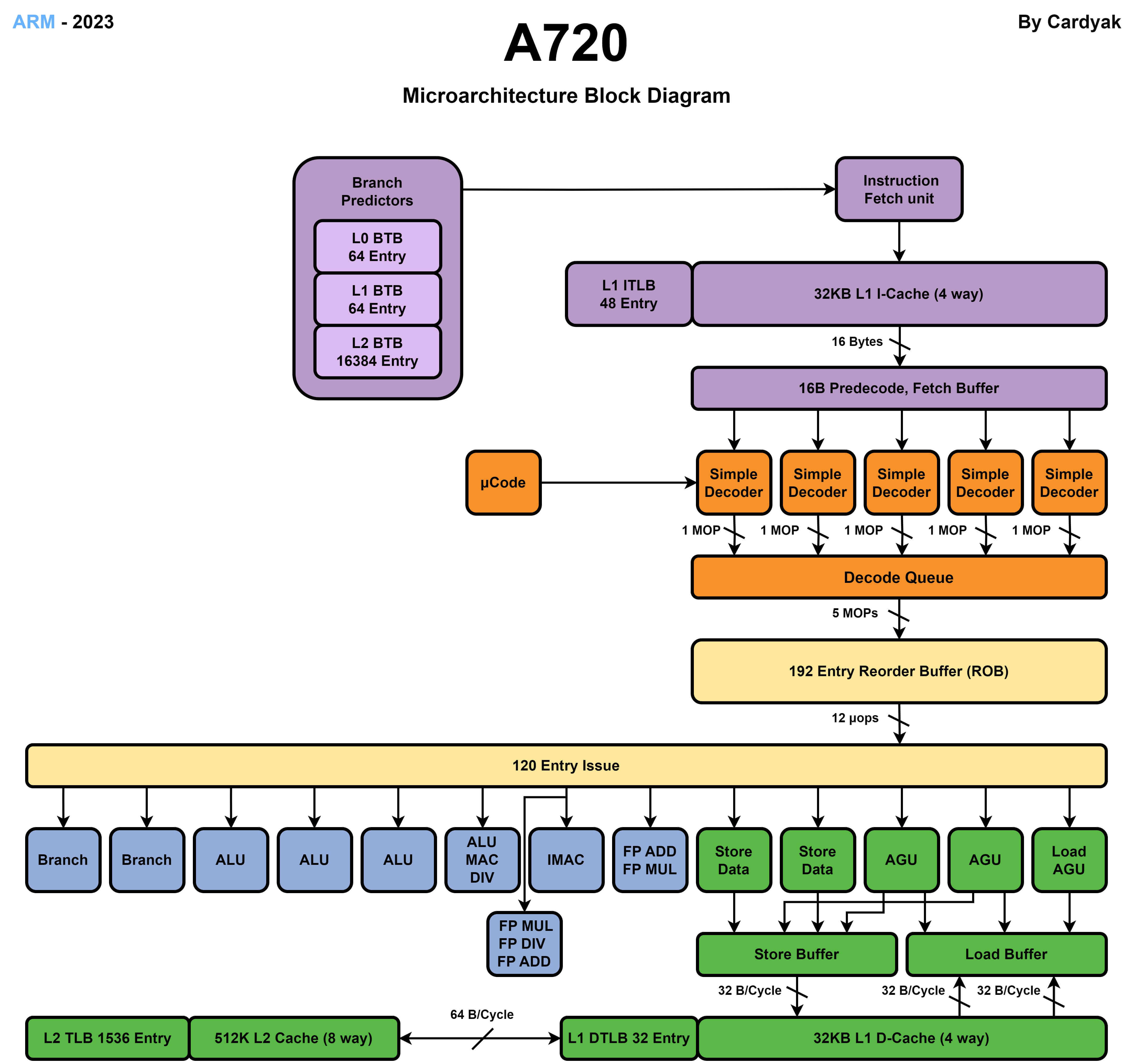
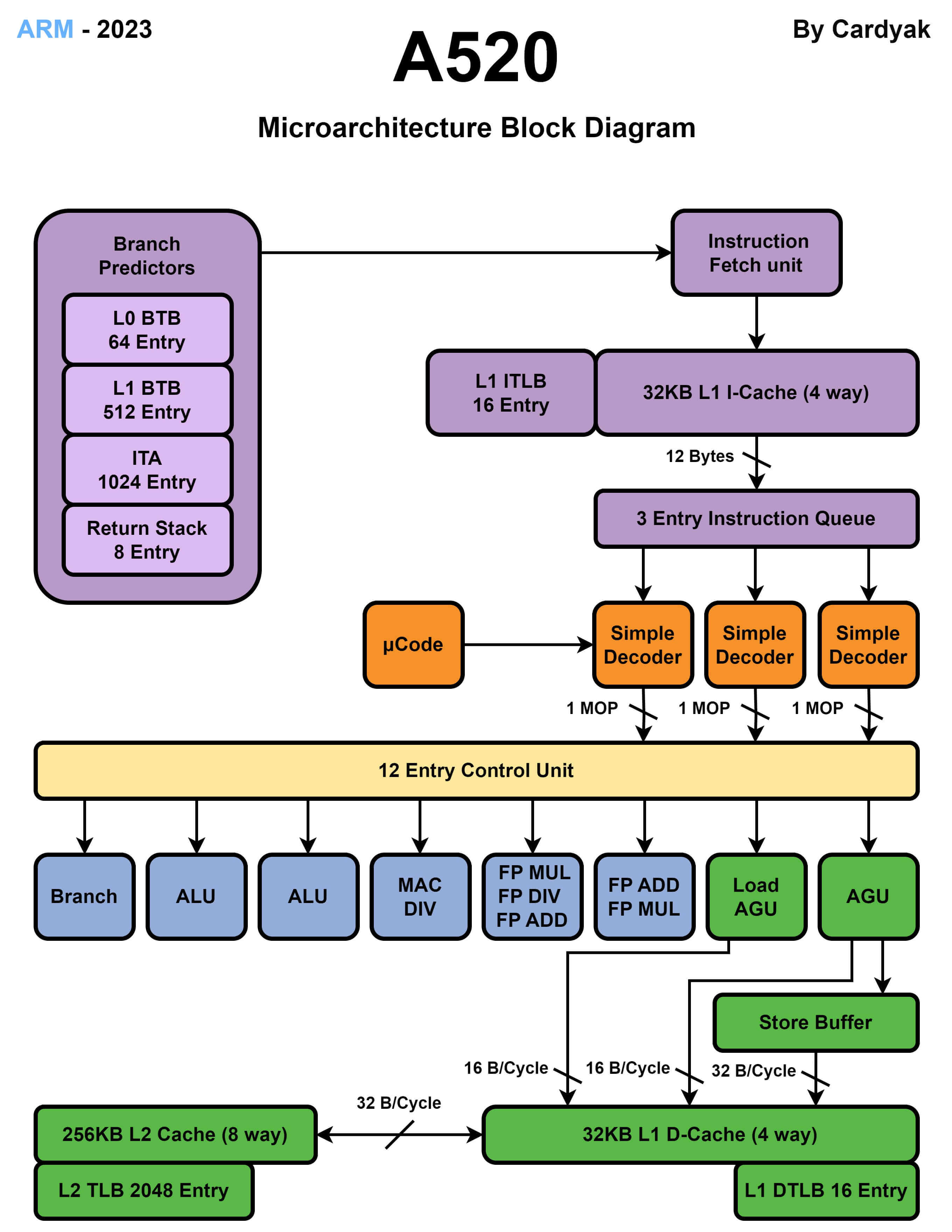
A520 能效核
小結
CPU核心微架構通過加入更多的流水線單元提高IPC,這些優化單元都需要消耗額外的電晶體數量增加能耗,同時IPC更高的核心會使用更高的時脈頻率執行。在20世紀90年代流水線技術的發展帶來了處理器效能的快速提升,但是隨著功耗牆的限制,高效能核心在效能上比能效核心快幾倍,但是在功耗上可能有幾十到上百倍的消耗。CPU技術發展不再追求大幅提高IPC來提高效能,而是轉向對電晶體更好的利用追求能耗比。
從現代CPU的微架構設計中也能看到,不同指令集的CPU在微架構上也有很多相似之處,更多的差異在解碼單元對於不同指令的解碼。
提示:
IPC高的核心需要使用更高的時脈頻率進行執行,主要是因為IPC高的核心有更復雜流水線設計和更積極的流水線排程避免流水線停頓,所以提高時脈頻率可以提升效能。IPC低的核心會遇到更多的流水線停頓,提高頻率也會導致很多週期流水線處於停頓等待記憶體讀取或分支計算完成造成浪費。
資料級並行:SIMD 和 GPU
SIMD
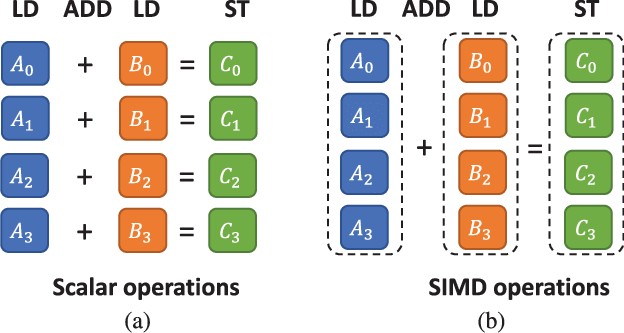
SIMD(Single instruction, multiple data)單指令多資料,是一種通過單個指令同時進行多個資料運算的方式,主要是用於音視訊、影象處理、向量運算這些計算場景。通過增加運算單元位寬、計算單元數量數量、暫存器位寬可以同時進行更多資料的運算,普通指令單個週期通常只能支援 2個資料的運算,SIMD指令單個週期可以同時幾十個資料的運算。同時一次性讀取多個記憶體資料也可以降低多次讀取記憶體資料帶來的資料延遲。大部分常見程式語言都提供對SIMD的支援,可以直接進行使用。
很多影象、音視訊等場景,通常只需要更低的資料位寬進行運算,SIMD指令可以同時進行更多資料的運算。目前x86平臺的SIMD指令發展到最新的AVX-512,運算寬度提升到 512 位,可以單指令執行 512 位的運算。ARM平臺的SIMD指令發展到SSE,最高可執行2048位的運算。
例如一個畫素值顏色通常使用 RGBA 32 位格式,Red、Green、Blue、Alpha 分別佔 8 位。一個 256 位的 SIMD 指令可以同時對 8 個顏色(32 個 8 位)進行運算,普通指令只能進行 2 個 8 位運算。
SIMD雖然帶來了效能的提升,但是晶片需要使用更多的電晶體用來支援SIMD指令更高的位寬計算和更多的暫存器數量。同時SIMD指令一次性傳輸資料量更大、指令複雜度更高、佔用更多的暫存器和運算器,也帶來了更多的計算功耗。SIMD也需要軟體開發者針對特定場景選擇使用SIMD指令進行優化才能得到效能提升。
普通運算和 SIMD 運算的區別
GPU
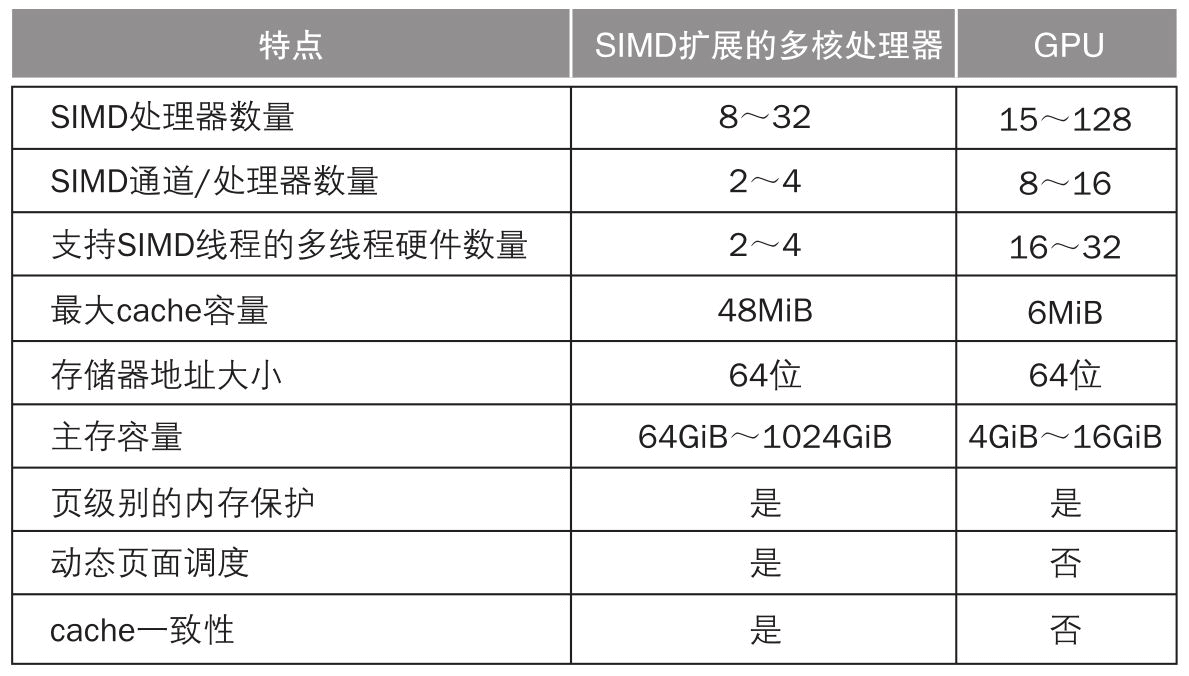
從某種角度講,SIMD和GPU的運算方式很相似。通過一次性並行處理更多的資料帶來效能提升,同時一次性讀取大量資料也可以降低記憶體資料延遲帶來的影響。GPU很像同時並行多執行緒執行SIMD的多核心處理器,只不過相比CPU設計更復雜效能更高,同時GPU的執行緒數更多、SIMD通道數更多、SIMD單元數量更多。
SIMD 和 GPU
小結
近些年更多AI運算場景增加了對於高效能向量運算的要求。雖然CPU通過新增SIMD指令增加了向量運算的能力,但是CPU本身是用於通用計算設計,CPU中只有小部分用於SIMD運算。雖然類似Pytorch、TensorFlow這些AI訓練框架都支援SIMD指令,但是使用SIMD進行大規模AI訓練相比GPU效能更低,同時成本更高。SIMD更像是傳統CPU運算的一種補充,用於簡單的小規模運算場景用於提高效能。
多執行緒並行:超執行緒、多核心
超執行緒
超執行緒是一種STM(同時多執行緒)技術,通過在單個CPU核心中模擬執行多個執行緒提高CPU的多執行緒並行能力。Intel最早在2002年推出了超執行緒技術,一個核心同時支援2個執行緒。利用SMT可以避免處理器中長延時事件導致的暫停,提高計算單元的利用率。
超執行緒技術通過給每個執行緒增加一套暫存器和PC單元,多個執行緒共用流水線中的多發射、動態排程等模組,通過暫存器重新命名和動態呼叫可以在一個週期內執行不同執行緒的多條指令。減少單個執行緒中發生類似快取缺失這樣的長延時等待事件,讓計算單元一直在執行狀態提高效能和吞吐量。
超執行緒技術會增加流水線排程的複雜度,現代CPU核心通常只支援2個執行緒的SMT。超執行緒技術需要依賴流水線的動態排程能力,所以現代CPU中通常只有高效能核心才支援。同時超執行緒技術雖然可以提高20%-30%的多執行緒效能,但是會增加7%的能耗和降低單核峰值效能。
超執行緒排程
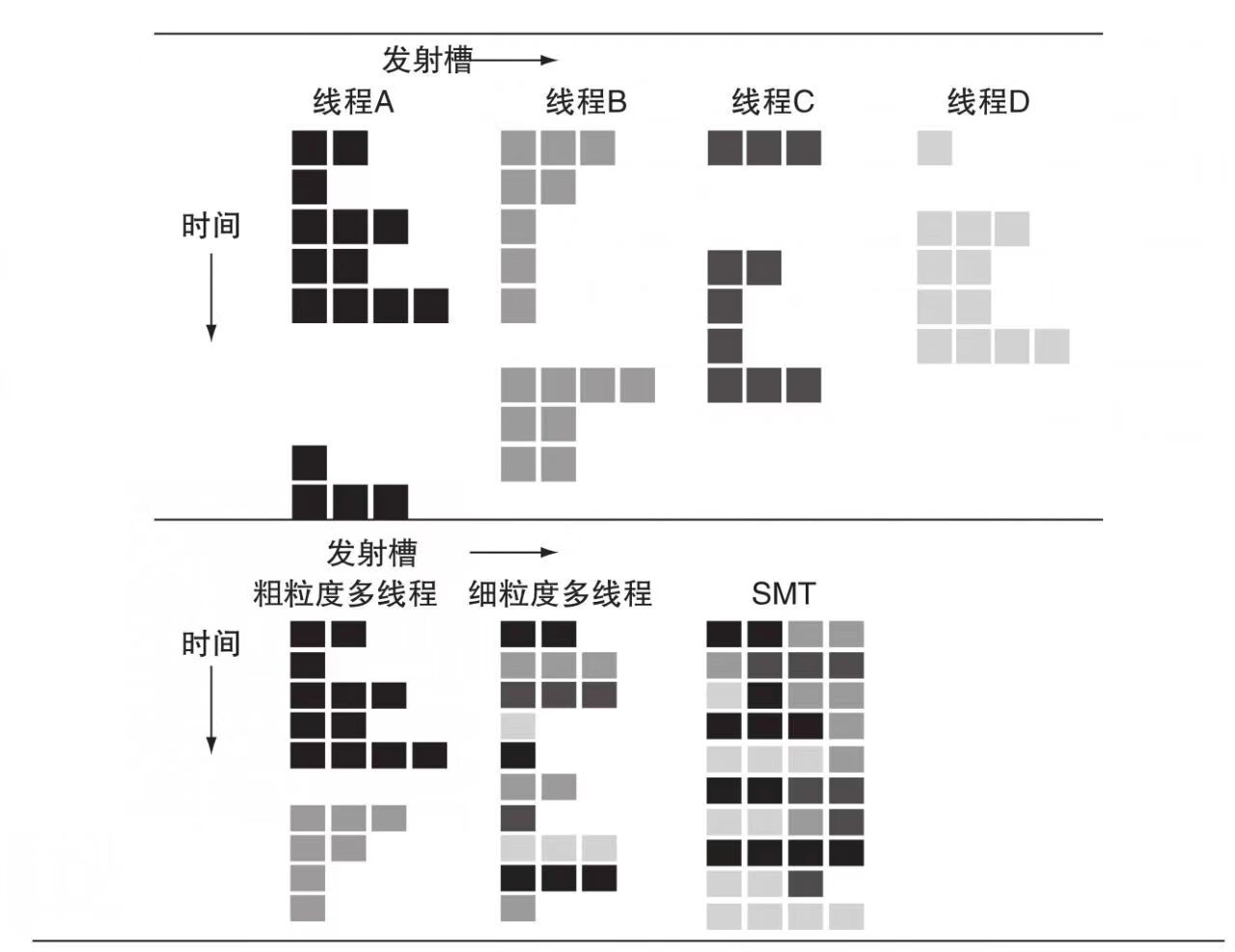
-
粗粒度多執行緒- 只有流水線發生等待事件長的停頓時才切換執行緒 -
細粒度多執行緒- 每個時鐘週期都切換執行緒
多核心
由於IPC提升和時脈頻率提升都因為功耗牆的限制而放緩,現代CPU通過提供更多的物理核心提高多執行緒並行能力提升指令吞吐量提高效能。通過增加CPU核心數帶來的多執行緒效能提升,帶來的能耗增加相比提升IPC、時脈頻率更低。現在手機端CPU中也有5-9個核心,PC 級CPU中通常有10-30個核心,伺服器CPU中核心數更多。
增加核心數可以複用核心內部的微架構設計,根據CPU的功耗、成本、效能訴求選擇核心數量。例如Intel在桌面級酷睿處理器和伺服器至強處理器可能會使用同樣的核心,只是會增加更多的核心數量。Apple在A系列和M系列晶片也會使用同樣的核心。
增加核心數也能帶來一定的能耗優勢,作業系統核心會根據運算負載動態的排程不同數量的核心進行執行,在運算負載低的時候可以排程更少的核心降低功耗。
大小核
現代CPU中通常還會使用大小核異構架構設計來提升能耗比降低功耗。效能核心用於高效能運算場景最大化執行效能,能耗核心用於日常低負載計算場景降低能耗。相同的核心會使用同樣的時脈頻率來執行,通常會共用使用L2快取。大小核的設計也增加了作業系統核心對於多核心排程的難度。
效能核心、能效核心區別
| 型別 | 效能 | 功耗 | 時脈頻率 | IPC |
|---|---|---|---|---|
| 效能核 | 高 | 高 | 更高的時脈頻率 | 複雜的流水線設計、IPC 更高 |
| 能耗核 | 中 | 中 | 更低的時脈頻率 | 簡單的流水線設計、IPC 更低(更少的解碼寬度、沒有動態排程、更少的計算單元等) |
大小核設計
小結
近些年CPU通過增加更多的核心數量提高CPU的多執行緒並行能力,但是這也帶來了一些新的問題限制了核心數一直快速增加。首先CPU核心數更多增加快取一致性的複雜度會影響效能,作業系統核心如何更好的對更多核心進行排程達到最高的能耗比。
同時對於軟體開發者來講,利用越來越多的核心進行程式設計會更復雜。程式語言以及開發框架也需要進行調整利用更多的核心。同時對於不同的軟體型別,可以利用多執行緒並行執行的部分也是不一樣的。(如果一個程式只有10%的運算工作可以並行執行,即使新增更多核心帶來的提升也很有限)
雖然增加核心數帶來的能耗增加相比IPC、時脈頻率更低,但是依然會增加功耗,功耗牆也是限制核心數增加的限制之一。
快取記憶體和記憶體提升
雖然記憶體不屬於處理器內部的結構,但是處理器執行時會依賴記憶體中的程式指令和程式資料,所以記憶體效能對處理器效能的影響很大。因為記憶體效能提升相比處理器時脈頻率提升非常緩慢,當前處理器對記憶體讀寫通常需要50-100個時鐘週期。關於記憶體存取速度的提升,一個方向是通過引入多級快取減少處理器對記憶體的直接存取,另一個方向是記憶體自身效能的提升。
引入快取記憶體
為了減少處理器對記憶體的直接存取,現代處理器引入了SDRAM(Synchronous dynamic random-access memory)儲存作為處理器的快取整合在處理器晶片中。SDRAM的優點是存取速度比記憶體快很多,缺點是功耗高、成本高(1位需要 6-7 個電晶體)、容量低。
處理器對記憶體的所有存取都通過快取進行載入,快取會儲存最近使用過的記憶體資料,這樣下次存取這些資料時就可以直接從快取中返回避免直接從記憶體中讀取。
記憶體讀寫過程
以下是一個簡單的具有二級快取的處理器記憶體讀寫過程原型,不過現代處理器設計通常會比這個過程更加複雜:
讀取
-
L1- 處理器核心需要讀取資料時,將資料記憶體地址傳送給L1快取。L1快取檢查是否有快取資料,如果L1快取中有快取資料直接返回。如果快取缺失將資料記憶體地址傳送給L2。 -
L2-L2快取檢查是否有快取資料。如果L2快取中有快取資料將資料寫入L1快取同時讀取到處理器中。如果快取缺失將資料記憶體地址傳送給記憶體。 -
記憶體- 從記憶體中讀取資料,之後分別寫入L2快取、L1快取,然後讀取到處理器中。
儲存
處理器核心將暫存器中的資料儲存到記憶體時,分別寫入L1快取、L2快取,之後儲存到記憶體中。
快取提升方向
快取效能提升方向主要是提高快取命中率、降低快取缺失耗時、降低快取命中耗時,主要是通過以下這些技能進行提升:
增加容量
增加快取的容量,快取中可以儲存的資料越多,快取命中率也就越高。功耗和成本會限制容量增長的速度,同時因為增加容量會影響存取速度,所以L1快取容量增長很慢。
使用多級快取
現代處理器通常有2-3級快取,多核處理器每個核心包含一個L1快取,L2、L3快取是多個核心共用。讀取速度L1 > L2 > L3,容量L3 > L2 > L1,成本L1 > L2 > L3。
這麼設計的目的主要是通過區域性性原理提高快取效能。L1快取關注讀取效能,將更常用的記憶體資料放到容量更小的L1快取中更快的讀取。同時L1快取設計會將指令和資料分離,提高快取效能和快取命中率。L2/L3快取關注快取缺失率,將更多的記憶體資料防止在快取中減少快取缺失耗時。
時間區域性性- 被參照過一次的記憶體資料在未來會被多次參照。
空間區域性性- 一個記憶體資料被參照,那麼未來它臨近的記憶體地址也會被參照。
現代CPU多級快取設計
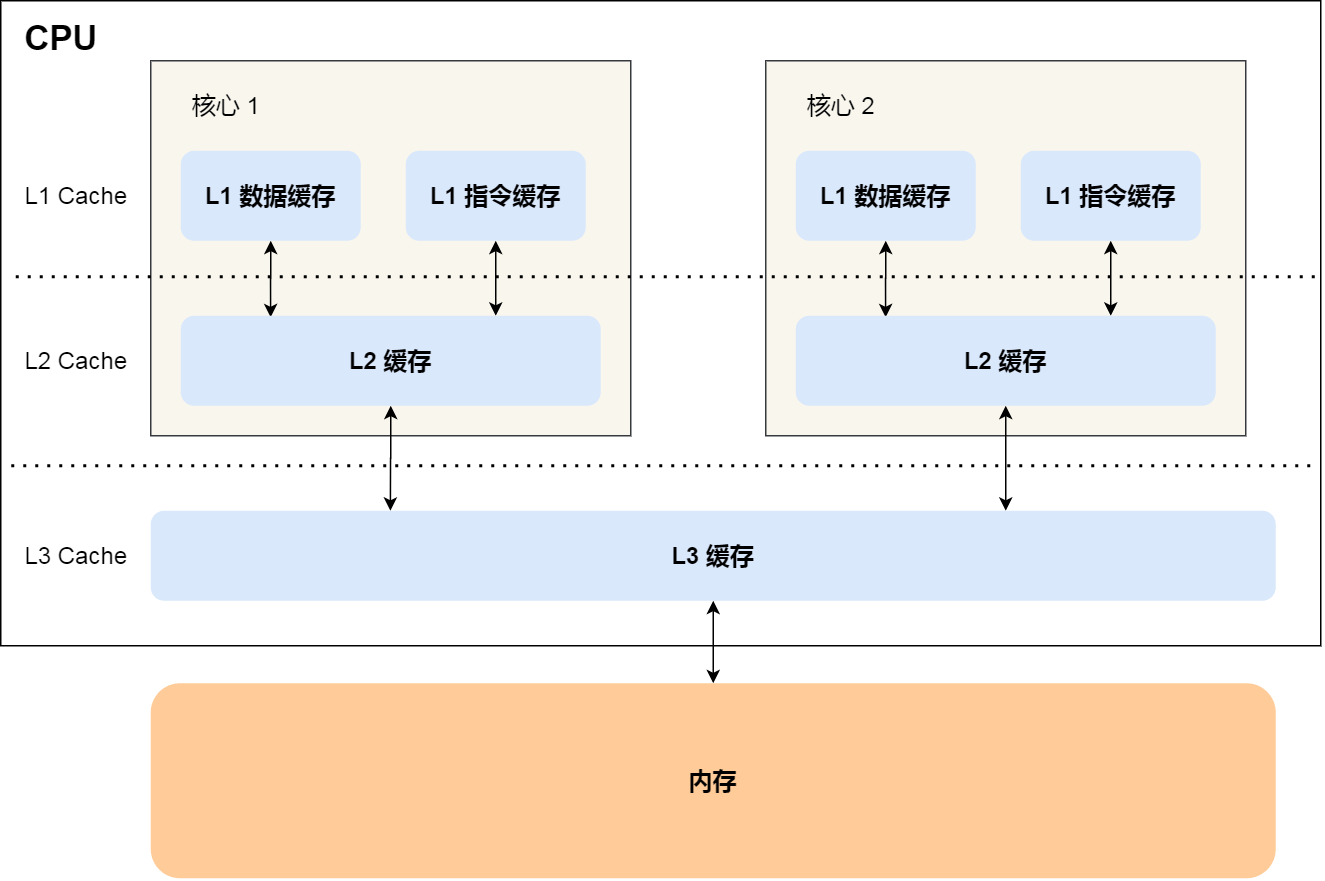
提示:通常
L1快取是單核心獨佔、L2快取可能是單核心獨佔或多核心共用、L3快取/記憶體是所有核心共用。通過MESI協定來解決快取一致性的問題。
多級快取和記憶體效能
| 儲存型別 | 存取速度 | 容量 | 功能 | |
|---|---|---|---|---|
| L1 | 1 - 5 時鐘週期 | 64 - 256 KB | 指令、資料 | - |
| L2 | 10 - 20 時鐘週期 | 512 KB - 2 MB | 資料 | A17 Pro 大核16MB |
| L3 | 20 - 50 時鐘週期 | 12 - 36 MB | 資料 | - |
| DDR | 50 - 100 時鐘週期 | 8 - 64 GB | 指令、資料 | - |
降低快取命中時間
通過更優秀的快取涉及,減少快取命中時的耗時。但是通常減少命中快取耗時和增加快取容量通常會有不可調和的矛盾。
快取預載入
根據前面流水線的介紹,現代處理器通常會對一次性讀取記憶體多條程式指令到放入快取中,同時也會提前讀取後面可能會使用的記憶體資料到快取中。但是當提前預載入到快取中的資料並沒有使用到時,會造成額外的功耗浪費。(例如分支預測錯誤)
優化快取更新演演算法
將新的資料寫入到快取時,由於容量限制通常需要替換掉舊的快取資料。常見的替換演演算法有LRU演演算法,使用更好的演演算法可以提高快取命中率。
記憶體效能提升
雖然通過加入多級快取可以提高記憶體讀寫的效能,但是處理器快取記憶體的容量很有限,遇到快取缺失時還是需要直接存取記憶體。所以對記憶體的效能提升依然很重要,記憶體效能提升主要是從以下四個方向進行提升:
-
讀取延遲- 持續減少記憶體讀取延遲,可以降低快取缺失從記憶體中讀取資料的耗時。 -
功耗- 由於移動裝置等低功耗場景的出現,對記憶體產生的功耗也有更低的要求。 -
頻寬- 因為記憶體效能提升很慢,同時現代處理器不斷的引入新的協處理器例如GPU、NPU需要進行更多的記憶體資料傳輸。增加記憶體頻寬雖然無法降低單次記憶體讀取延遲但是可以同時傳輸更多的資料。 -
成本- 更低的成本可以使商品價格更低,同時可以增加更多的記憶體容量。
更多記憶體型別
由於記憶體無法同時滿足對延遲、功耗、頻寬、成本的要求,現代記憶體逐漸發展出了多種不同的記憶體型別。針對不同的計算場景選擇使用不同型別的記憶體,主要是基於處理器對延遲、功耗、頻寬、成本的要求進行選擇。每一代記憶體新標準的推出也會逐漸提高延遲、功耗、頻寬的效能,同時降低上一代標準的成本。(通常新標準成本更高)
不同記憶體型別特點
| 型別 | 最新標準 | 延遲 | 功耗 | 頻寬 | 最大頻寬 | 面積 | 成本 | 使用場景 | 特點 |
|---|---|---|---|---|---|---|---|---|---|
| DDR | DDR5 | 低 | 中 | 低 | 64 Gbps | 中 | 低 | PC、伺服器 | 延遲最低 |
| LPDDR | LPDDR5X | 中 | 低 | 中 | 77 Gbps (8 Gen 3) | 小 | 低 | 手機、筆電 | 功耗最低 |
| GDDR | GDDR6X | 高 | 高 | 高 | 1008 Gbps(RTX 4090) | 大 | 中 | 獨立顯示卡 | 高頻寬、功耗最高、延遲最高 |
| HBM | HBM3e | 高 | 中 | 超高 | 4800 Gbps(H200) | 小 | 高 | 伺服器GPU | 頻寬最高、成本最高 |
整合封裝工藝提升
現代面向移動場景的處理器通常會將LPDDR記憶體使用3D整合封裝技術直接整合到處理器晶片上。優點是可以減少傳輸物理距離提高傳輸效能、降低功耗,缺點是無法靈活更換記憶體。
記憶體整合封裝到處理器晶片上

小結
近些年快取記憶體技術發展逐漸放緩,同時快取缺失是導致流水線停頓的主要原因之一。由於讀取延遲限制了L1快取容量的提升,L1容量提高很少。半導體工藝發展放緩,電晶體數量增長速度降低以及功耗問題,也降低了L2、L3快取容量增加的速度。同時快取記憶體的引入也給編譯器和軟體開發者帶來了更大的挑戰,如何更好的利用區域性性原理提高快取命中率:開發者需要編寫快取命中率更高的程式碼、編譯器需要生成快取命中率更高的程式指令。
提示:增加快取容量的成本很高。以A17 Pro晶片為例,總共 190 億個電晶體,因為包含
GPU、NPU等協處理器,CPU使用的電晶體數量不超過 30%。快取大小L2 20MB + L1 192KB,以一個快取位需要幾個電晶體來計算,快取大概需要耗費幾億個電晶體。
記憶體技術每一代新標準在增加頻寬、容量和能耗比上都有不錯的提升,但是讀取延遲降低緩慢很多。記憶體讀取延遲導致的記憶體牆依然是限制處理器效能的主要因素之一。因為記憶體牆的限制,現在也有一種存算一體的探索方向,將記憶體和計算單元整合在一起減少資料傳輸延遲。
現代處理器核心數越來越多,每個核心都有自己的L1快取,多個核心需要共用L2快取、L3快取、記憶體資料。多核快取一致性的複雜度越來越高,額外的開銷可能會降低讀取延遲和增加功耗,限制多核處理器的效能。
提示:從快取記憶體和記憶體上看,更小的程式體積、更小的記憶體佔用是可以增加程式的執行效能的。
SOC、DSA 和 Chiplet
SOC
SOC(System on Chip)片上系統是一種將多個不同模組封裝在一個晶片中的技術。現代CPU基本上都屬於SOC晶片,將CPU、GPU、NPU、WIFI、藍芽、Modem等模組整合到同一個晶片中。由於半導體技術的發展可以整合在晶片上的電晶體數量越來越多,可以將更多的模組整合到一個晶片中帶來整合度、效能、系統單元複用率的提升:
| 模組 | 最新標準 |
|---|---|
| 提高效能 | 不同模組整合在同一個晶片上,跨模組間通訊更快、功耗更低。手機端SOC通常會將記憶體封裝在SOC晶片上,不同模組可以使用統一記憶體的方式複用記憶體,降低記憶體在不同模組間的傳輸提高效能。 |
| 提高整合度 | 不同模組整合在同一個晶片上,相比傳統多個模組晶片的設計可以複用重複的傳輸電路或記憶體等降低成本、降低面積、降低功耗。(例如傳統CPU/GPU都有獨立記憶體,封裝到SOC中可以複用一個記憶體即可。) |
雖然帶來了效能的優勢,但是由於SOC整合了更多模組同時需要模組間互聯,晶片設計、製造複雜度更高,導致成本也更高。
SOC 組成結構
現代SOC通常由一個CPU單元、多個協處理器(NPU/GPU)、無線模組(WIFI/藍芽/蜂窩網路)、多媒體單元(ISP、DSP)、記憶體控制器、I/O 單元組成:
| 模組 | 功能 |
|---|---|
| CPU | 中央處理器 |
| GPU | 圖形渲染、高效能運算 |
| NPU | 神經網路運算、端測 AI 加速 |
| ISP | 相機感測器、拍照/視訊影象訊號處理、優化畫面質量 |
| DSP | 音視訊/圖片硬體編解碼 |
| 無線 | WIFI、藍芽、蜂窩網路的傳輸通訊、協定編解碼、連線管理 |
| Display Engine | 管理螢幕顯示、影象資料轉換為螢幕格式、影象效果/解析度優化、影格率調整 |
| 記憶體控制器 | 記憶體讀寫、記憶體地址對映、記憶體一致性、統一記憶體複用 |
| I/O | 管理輸入/輸出裝置的 I/O 讀寫 |
高通 8 gen 3

-
Hexagon Processor- AI 模組 -
FastConnect- WIFI、藍芽
Apple M3

- 從
M3的設計上可以看出,現代SOC中CPU部分佔用的矽面積不超過30%
DSA
DSA(Domain Specific Architecture)領域特定架構是一種用於特定領域計算的結算機體系。由於CPU是一種追求通用計算的電腦架構,對於特定領域計算(音視訊、圖形、AI 等)的效能和能效比都比較差。DSA通過面向特定領域計算的設計大幅提高效能和能耗比,解決CPU對於特定領域計算的效能劣勢。
DSA 設計
現代SOC中的GPU、NPU、DSP就是一種常見的DSA模組。傳統CPU通過複雜流水線設計、快取記憶體、增加暫存器位數等特性提高CPU的運算效能,但是這會導致大量的電晶體消耗增加成本和能耗。DSA通過減少這些複雜的設計提高電晶體的利用率提高能效,相比CPU執行同樣的特定領域運算可以帶來的優勢:更小的面積、更低的成本、更高的能耗比、更好的效能。
DSA 設計原則
| 特點 | 說明 | 備註 |
|---|---|---|
| 專用儲存 | 使用專用記憶體減少資料移動 | - |
| 最小化資料型別 | 使用更小位寬的資料型別來計算、節省儲存空間、運算更快 | - |
| 更多運算單元或記憶體 | 加入更多運算單元、更大的記憶體 | - |
| 並行方式 | 選擇更有利於特定領域計算的並行方式 | 例如 GPU 的並行方式 |
| 專用程式語言 | 使用面向特定領域計算的程式語言/框架進行程式設計 | - |
Chiplet
Chiplet是近幾年發展出的一種將不同的功能模組分離成小晶片,並通過先進封裝技術組合在一起的新技術。Chiplet主要是為了解決傳統SOC遇到的成本高和擴充套件性問題。
| 特點 | 說明 | 備註 |
|---|---|---|
| 降低成本 | 不同晶片可以使用不同成本的工藝製造、小晶片可以複用降低設計成本、小晶片面積更小成本更低 | - |
| 靈活性、擴充套件性 | 根據訴求靈活整合不同的小晶片滿足市場需求、3D 封裝降低晶片面積 | - |
不過Chiplet對封裝技術的要求很好,不同小晶片間的通訊設計也很複雜。目前只有少量的晶片使用了這種方式進行晶片製造。
Meteor Lake
Intel2023年推出的Meteor Lake處理器使用Chiplet封裝,CPU使用Intel4nm工藝,Graphics使用臺積電5nm工藝,SOC、IO使用臺積電6nm工藝。
小結
由於CPU通用處理器效能提升放緩和對特性領域計算的能耗比和成本問題,未來也許會加入更多的DSA模組用於提升特定領域計算的效能和能耗比。近些年PC端處理器也在效仿行動端處理器加強DSA單元能力,包括提高核顯 GPU 的效能以及加入 NPU。同時Chiplet技術的發展也可以幫助處理器整合更多的DSA單元同時降低成本。
主流 CPU 發展
Intel 處理器發展
| CPU | 頻率 | 核心數 | 執行緒數 | 指令集 | 微架構 | 工藝 | 電晶體數量 | TDP | 發行年份 | 備註 |
|---|---|---|---|---|---|---|---|---|---|---|
| Core i9-14900K | 3.2 - 6 GHz | 8 + 16 | 32 | x86-64 | Raptor Cove + Gracemont | 7 nm | - | 125 - 253W | 2023 | - |
| Core i9-13900K | 3 - 5.8 GHz | 8 + 16 | 32 | x86-64 | Raptor Cove + Gracemont | 7 nm | - | 125 - 253W | 2022 | - |
| Core i9-12900K | 3.2 - 5.2 GHz | 8 + 8 | 24 | x86-64 | Golden Cove + Gracemont | 7 nm | - | 125 - 241W | 2021 | 引入大小核混合架構、支援 DDR5 |
| Core i9-11900K | 3.5 - 5.3 GHz | 8 | 16 | x86-64 | Cypress Cove 待確定 | 10 nm | - | 95 - 125 W | 2021 | - |
| Core i7-6700K | 4 - 4.2 GHz | 4 | 8 | x86-64 | Skylake | 14 nm | - | 91 W | 2015 | - |
| Core i7-4790K | 4 - 4.4 GHz | 4 | 8 | x86-64 | Haswell | 22 nm | - | 88 W | 2014 | - |
| Core i7-990X | 3.4 - 3.7 GHz | 6 | 12 | x86-64 | Westmere | 32 nm | 12 億 | 130 W | 2011 | - |
| Core 2 E6700 | 2.66 GHz | 2 | 2 | x86-64 | Conroe | 65 nm | 2.9 億 | 65 W | 2006 | 引入雙核心 |
| Pentium D Processor 840 | 3.2 GHz | 2 | 2 | x86-64 | NetBurst | 90 nm | 2.3 億 | - | 2005 | - |
| Pentium 4 Extreme Edition | 3.4 GHz | 1 | 2 | x86-32 | NetBurst | 130 nm | - | 110W | 2004 | 引入超執行緒 |
| Pentium 4 2.8 GHz | 2.8 GHz | 1 | 1 | x86-32 | NetBurst | 130 nm | 5500 萬 | - | 2002 | - |
| Pentium 3 Processor 1.1 GHz | 1.1 GHz | 1 | 1 | x86-32 | P6 | 180 nm | - | 33 W | 2000 | - |
| Pentium Pro 200 MHz | 200 MHz | 1 | 1 | x86-32 | P6 | 500 nm | 550萬 | 35W | 1995 | 微解碼轉換、動態呼叫、亂序執行、推測執行、引入二級快取、SSE、支援暫存器更名 |
| Pentium | 60 MHz | 1 | 1 | x86-32 | P5 | 800 nm | 310 萬 | - | 1993 | - |
| 80486 | 25 MHz | 1 | 1 | x86-32 | i486 | 1 um | 100萬 | - | 1989 | - |
| 80386 | 20 MHz | 1 | 1 | x86-32 | - | 1.5 um | 27.5萬 | - | 1985 | 加入6級流水線 |
| 80286 | 12.5 MHz | 1 | 1 | x86-16 | - | 1.5 um | 13.4 萬 | - | 1982 | - |
| 80186 | 6 MHz | 1 | 1 | x86-16 | - | 2 um | 5.5 萬 | - | 1982 | - |
| 8086 | 5 MHz | 1 | 1 | x86-16 | - | 3 um | 2.9 萬 | 2 W | 1978 | 第一個 x86 架構處理器、16 位、引入8個通用暫存器、分段記憶體 |
| 8085 | 3 MHz | 1 | 1 | 8085 | - | 3 um | 6500 | - | 1976 | - |
| 8080 | 2 MHz | 1 | 1 | 8080 | - | 6 um | 4500 | - | 1974 | 不相容 8008 |
| 8008 | 0.5 MHz | 1 | 1 | 8008 | - | 10 um | 3500 | 1 - 2 W | 1972 | 第一個 8 位可程式化處理器 |
最新 CPU 微架構對比
| 代號 | 型別 | 指令集 | 執行緒數 | 解碼寬度 | ROB | 發射寬度 | 分支預測懲罰 | L1 快取 | L2 快取 | SIMD | IPC |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Raptor Cove | Intel 效能核 | x86-64 | 2(超執行緒) | 6 | 512 | 6 | 8 | 48 KB(D)、32 KB(I) | 2 MB | AVX 512 | 3.525、4.23(超執行緒) |
| Gracemont | Intel 能效核 | x86-64 | 1 | 6 | 256 | 6 | 8 | 32 KB(D)、64 KB(I) | 2 MB(共用) | AVX 256 | 2.52 |
| A520 | ARM 小核 | ARMv9 | 1 | 3 | 0 | 3 | - | 64 KB(D)、32 KB(I) | 256 KB | SVE | 0.94 |
| A720 | ARM 大核 | ARMv9 | 1 | 5 | 192 | 5 | - | 64 KB(D)、32 KB(I) | 512 KB | SVE | 3.03 |
| X4 | ARM 超大核 | ARMv9 | 1 | 10 | 384 | 10 | - | 64 KB(D)、64 KB(I) | 2 MB | SVE | 4.4 |
| A17 E | Apple 能效核 | ARMv8 | 1 | 5 | 224 | 5 | 5 | 128 KB(D) + 64 KB(I) | 4 MB(共用) | NEON | 3.05 |
| A17 P | Apple 效能核 | ARMv8 | 1 | 9 | 670 | 9 | 9 | 64 KB(D)、128 KB(I) | 16 MB(共用) | NEON | 5.06 |
對開發者的影響
更多核心數
CPU核心數越來越多,軟體開發者需要使用面向多執行緒的利用更多的核心並行才能提高程式執行的效能。同時也可以導致程式語言、程式設計正規化、框架的一些改變:
-
多執行緒程式設計- 更多的使用到多執行緒程式設計利用多核的效能 -
簡化並行程式設計- 程式語言提供了更多特性簡化並行程式設計,例如async/await函數、結構化並行 -
非同步程式設計- 更多的跨執行緒非同步呼叫 -
非共用記憶體的並行模型- 可以減少資料競爭、減少執行緒鎖使用、減少執行緒切換的耗時,Go、Rust、Swift語言都提供了類似的並行模型 -
UI框架- 傳統UI框架都是基於單執行緒模型設計,UI框架和瀏覽器需要更好的利用多核心的效能優勢。同時非UI操作需要更多考慮多執行緒的利用減少主執行緒的消耗 -
函數語言程式設計- 函數語言程式設計更有利於並行執行變得更流行
SIMD、DSA單元
SOC不斷增加更多的DSA單元增加特定領域運算的能耗比,未來可能需要面向更多不同型別的處理器進行程式設計,不同的處理器會導致程式語言和程式設計正規化的改變。
硬體效能提升放緩
CPU效能提升放緩帶給軟體的效能提升更少,同時軟體自身功能不斷增加對於效能的消耗,軟體追求更高的效能提升就需要做更多的軟體效能優化。
-
AOT- 類似Java、C#、JS這些傳統的解釋執行程式語言開始追求AOT編譯提高效能,新的程式語言通常也會支援AOT編譯 -
簡化記憶體管理- 簡化傳統的自動記憶體管理方式,使用更簡單的記憶體管理方式。例如Rust的所有權更多利用編譯器去檢查記憶體安全 -
值型別- 更多的值型別使用,棧上的值型別效能更好 -
編譯器- 編譯器利用靜態優化生成效能更好的程式碼減少執行時消耗,靜態型別系統、靜態方法派發
相關連結
作者:京東零售 何驍
來源:京東雲開發者社群 轉載請註明來源