vivo 容器平臺資源運營實踐
作者:vivo 網際網路伺服器團隊 - Chen Han
容器平臺針對業務資源申請值偏大的運營問題,通過靜態超賣和動態超賣兩種技術方案,使業務資源申請值趨於合理化,提高平臺資源裝箱率和資源利用率。
一、背景
在Kubernetes中,容器申請資源有request和limit概念來描述資源請求的最小值和最大值。
-
requests值在容器排程時會結合節點的資源容量(capacity)進行匹配選擇節點。
-
limits表示容器在節點執行時可以使用的資源上限,當嘗試超用資源時,CPU會被約束(throttled),記憶體會終止(oom-kill)。
總體而言,在排程的時候requests比較重要,在執行時limits比較重要。在實際使用時,容器資源規格 request 和 limit 的設定規格也一直都讓Kubernetes的使用者飽受困擾:
-
對業務運維人員:希望預留相當數量的資源冗餘來應對上下游鏈路的負載波動,保障線上應用的穩定性。
-
對平臺人員:叢集的資源裝箱率高,節點利用率低,存在大量的空閒資源無法排程,造成算力浪費。
二、現狀
2.1 vivo容器平臺介紹
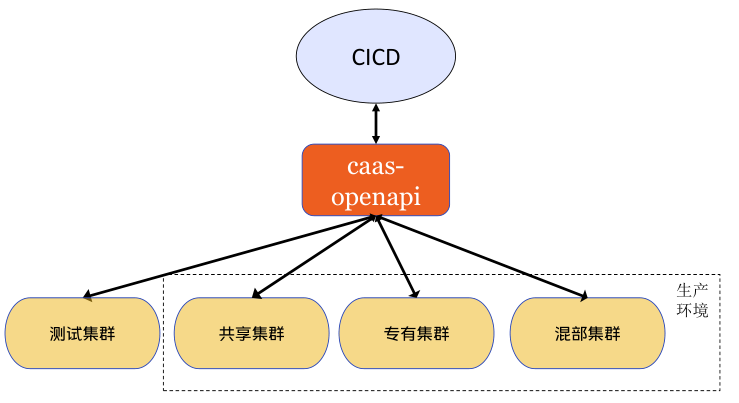
vivo容器平臺基於Kubernetes技術對內部業務提供容器服務。內部業務統一在CICD平臺部署和管理容器資源,容器平臺自研的caas-openapi元件提供restful介面與CICD互動。
平臺通過標籤,從資源維度邏輯上可以分為測試池、共用池、專有池、混部池。
-
測試池:為業務部署容器測試,一般非現網業務,為業務測試提供便利。
-
共用池:為業務不感知物理機,類似公有云全託管容器服務。
-
專有池:為業務獨享物理機,類似公有云半托管容器服務,業務方獨佔資源,容器平臺維護。
-
混部池:為業務獨享物理機,在專有池基礎上,混部離線業務,緩解離線資源缺口,提升整機利用率。
2.2 資源部署現狀和問題
vivo容器平臺的所有線上業務部署均要求設定request和limit,且request <= limit,預設情況request等於limit。在共用池中,常見業務request設定會出現如下情況:
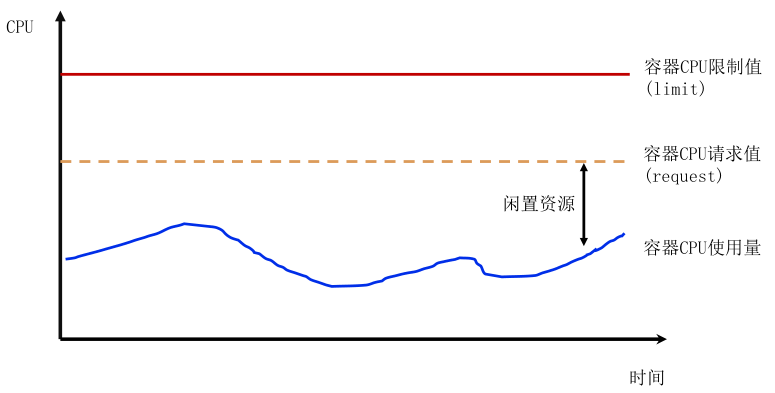
(1) 較少情況,業務設定較低的 request 值,而實際使用資源遠大於它的 request 值,若大量pod排程一個節點,加劇節點熱點問題影響同節點其他業務。
(2)大多情況,業務按最大資源需求設定較高的 request 值,而實際使用資源長期遠小於它的 request 值。業務側賬單成本高(按request計費),且容器異常退出時,重排程時可能因為平臺空閒資源碎片,導致大規格容器無法排程。這會導致,平臺側可排程資源少,但平臺整體節點資源利用率偏低。
對平臺和使用者方,request值設定合理很重要,但平臺無法直接判斷使用者設定request值合理性,所以無法首次部署時硬限制。
2.3 資源規格合理性思考
2.3.1 request怎麼樣才是合理設定
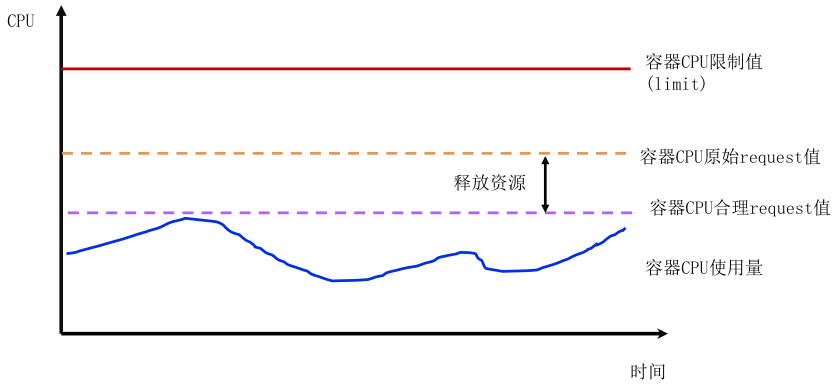
request值接近業務實際使用量,例如使用者申請request為2核,limit為4核,實際真實使用量最多1核,那麼合理request值設定為1核附近。但是業務真實使用量只有執行一段時間後才能評估,屬於後驗知識。
2.3.2 保障資源最大使用量
不修改limit值就能保障業務最大使用量符合業務預期。
三、解決方案探索
3.1 靜態超賣方案
思路:
靜態超賣方案是將CICD使用者申請規格的request按一定比例降低,根據平臺運營經驗設定不同叢集不同機房不同環境的靜態係數,由caas-openapi元件自動修改。如下圖:
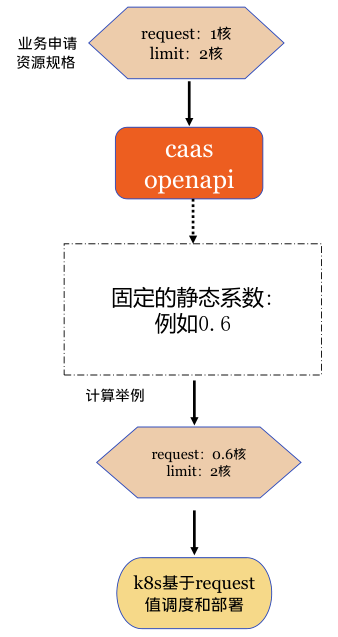
優點:
首次部署時可以應用,實現簡單。
缺點:
生產環境係數設定保守,導致request依然偏大,且由於記憶體是不可壓縮資源,實際實施時為避免業務範例記憶體oom-kill,靜態超賣只開啟了cpu維度,未開啟記憶體靜態超賣。
3.2 動態超賣方案
3.2.1 方案思路
開發caas-recommender元件,基於業務監控資料的真實資源用量來修正業務request值。
-
從監控元件拉取各個容器資源的真實使用量。
-
通過演演算法模型得到業務申請量的推薦值。
-
業務重新部署時,使用推薦值修改業務request值。
3.2.2 半衰期滑動視窗模型
結合容器業務的特點,對推薦演演算法有如下要求:
-
當workload負載上升時,結果需要快速響應變化,即越新的資料對演演算法模型的影響越大;
-
當workload負載下降時,結果需要推遲體現,即越舊的資料對演演算法結果的影響越小。
半衰期滑動視窗模型可以根據資料的時效性對其權重進行衰減,可以滿足上述要求。
詳細描述參考:google Borg Autopilot的moving window模型,參看原論文>>
公式如下:
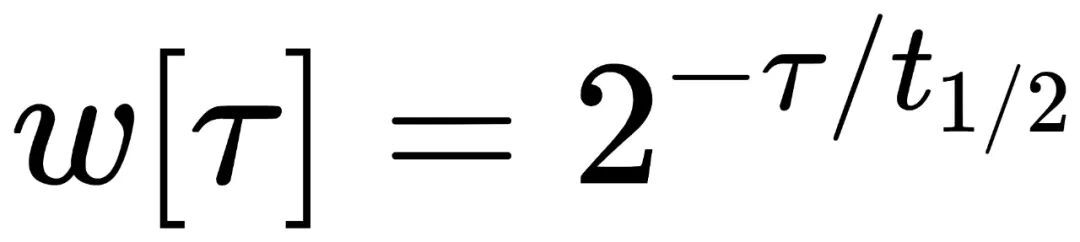
其中 τ 為資料樣本的時間點,t1/2 為半衰期,表示每經過 t1/2 時間間隔,前一個 t1/2 時間視窗內資料樣本的權重就降低一半。
-
核心理念:在參考時間點之前的資料點,離的越遠權重越低。在參考時間點之後的資料點權重越高。
-
半衰期halfLife:經過時間halfLife後,權重值降低到一半。預設的halfLife為24小時。
-
資料點的時間timestamp:監控資料的時間戳。
-
參考時間referenceTimestamp:監控資料上的某個時間(一般是監控時間最近的零點00:00)。
-
衰減係數decayFactor:2^((timestamp-referenceTimestamp)/halfLife)
-
cpu資源的固定權重:CPU 使用量資料對應的固定權重是基於容器 CPU request 值確定的。當 CPU request 增加時,對應的固定權重也隨之增加,舊的樣本資料固定權重將相對減少。
-
memory資源的固定權重:由於記憶體為不可壓縮資源,而記憶體使用量樣本對應的固定權重係數為1.0。
-
資料點權重 = 固定權重*衰減係數:例如現在的資料點的權重為1,那麼24小時之前的監控資料點的權重為0.5,48小時前的資料點的權重為0.25,48小時後的資料權重為4。
3.2.3 指數直方圖計算推薦值
caas-recommender每個掃描週期(預設1min)從 metrics server 或 prometheus 中獲取帶時間戳的樣本資料,如 container 維度的 CPU、Memory 資源使用等。樣本資料結合權重值,為每個workload構建指數直方圖,指數直方圖中每個桶的大小以指數速率逐步提升。指數直方圖的樣本儲存方式也便於定期checkpoint儲存,可以顯著提升程式recover效能。如下圖:
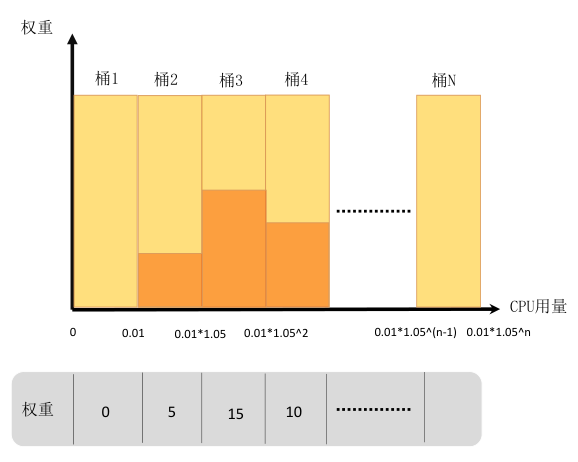
- 指數直方圖的橫軸定義為資源量,縱軸定義為對應權重,資源量統計間隔以5%左右的幅度增加。
-
桶的下標為N,桶的大小是指數增加的bucketSize=0.01*(1.05^N),下標為0的桶的大小為0.01,容納範圍為[0,0.01),下標為1的桶的大小為0.01*1.05^1=0.0105,容納範圍[0.01-0.0205)。[0.01,173]只需要兩百個桶即可完整儲存。
-
將每個資料點,按照數值大小丟到對應的桶中。
-
當某個桶裡增加了一個資料點,則這個桶的權重增加固定權重*衰減係數,所有桶的權重也增加固定權重*衰減係數。
-
計算出W(95)=95%*所有桶的總權重,如上圖僅考慮前4個桶,總權重為20,w(95)權重為19。
-
從最小的桶到最大桶開始累加桶的權重,這個權重記為S,當S>=W(95)時候,這個時候桶的下標為N,那麼下標為N+1桶的最小邊界值就是95百分位值,如上圖N=3時,S>=W(95),95百分位值即為0.01*1.05^2。
比如CPU波動較大且可壓縮,採用95%分位值(P95),記憶體採用99%分位值(P99)。最終得到workload的資源推薦值。
3.2.4 caas-recommender元件流程圖
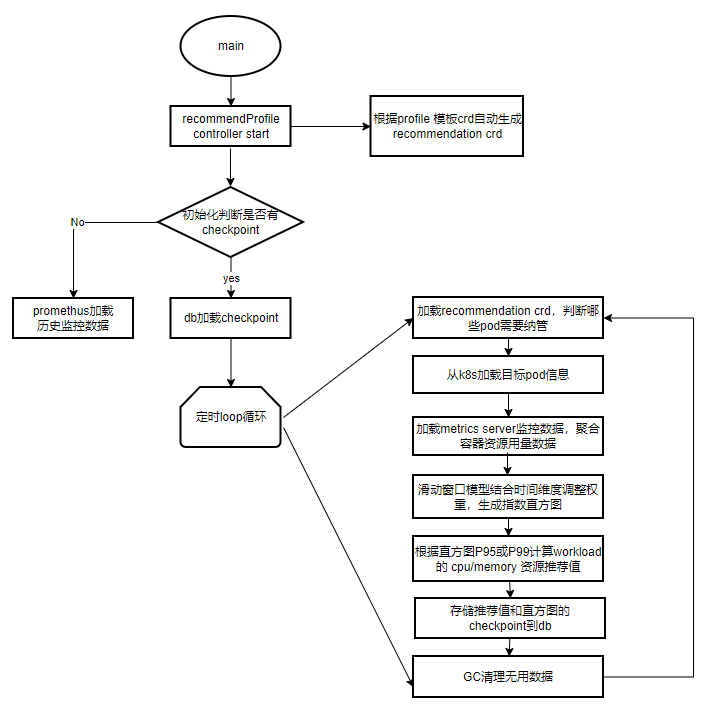
1. 啟動controller:profile Controller監聽profile template crd,根據profile crd建立相應維度的recommendation crd,可支援namepace\workload\pod維度。
2. 初始化:判斷是否有checkpoint,若無,可以選擇從prometheus拉取資料構建直方圖。若有,由checkpoint直接recover。
3. loop迴圈:
-
從recommendation crd中判斷哪些pod需要納管(pod labels)
-
根據pod label從Kubernetes獲取pod資訊
-
根據pod的namespace從metrics server拉取監控資料,由container資料匯聚成pod用量資料。
-
構建指數直方圖,填充pod用量資料和權重值。
-
根據直方圖的分位值計算推薦值
-
儲存推薦值和直方圖chekpoint
-
gc需要刪除的recommendation crd或者直方圖記憶體等無用資料。
4.支援原生workload常用型別,拓展支援了OpenKruise相關workload型別。
3.2.5 推薦值校正規則
-
推薦值 = 模型推薦值 * 擴大倍數(可設定)
-
推薦值 < 原生request值:按照推薦值修改
-
推薦值 > 原始request值: 按照原始request修改
-
記憶體是否修改可以通過設定
-
不修改workload的limit值
3.3 HPA利用率計算邏輯改造
Pod 水平自動擴縮(Horizontal Pod Autoscaler, 簡稱 HPA)可以基於 CPU/MEM 利用率自動擴縮workload的Pod數量,也可以基於其他應程式提供的自定義度量指標來執行自動擴縮。
原生Kubernetes的HPA擴縮容利用率計算方式是基於request值。若資源超賣,request值被修改後,那麼業務設定的HPA失靈,導致容器不符合預期擴縮容。
關於HPA是基於request還是基於limit,目前Kubernetes社群還存在爭論,相關 issue 見72811。若需要使用limit計算利用率,可以修改kube-controller-manager原始碼,或者使用自定義指標來代替。
vivo容器平臺相容業務物理機利用率邏輯,規定內部統一監控系統的Pod利用率均基於limit計算。
HPA改造思路:通過修改kube-controller-manager原始碼方式實現基於limit維度計算。
-
在pod annotation中記錄設定值資訊(request值和limit值),以及維度資訊(request或limit維度)。
-
controller計算pod資源時,判斷是否有指定annotation,若有,解析annotation記錄值和維度資訊計算利用率,若無,使用原生邏輯。
通過上述方式解耦HPA與pod request值,這樣平臺的資源超賣功能修改request不影響HPA自動擴縮預期。
3.4 專有池支援超賣能力
專有池物理機由業務自行運維管理,從平臺角度,不應該隨意修改業務的容器request規格。但是專有池業務也有降低容器規格,部署更多業務,複用資源,提高整機利用率的需求。平臺預設所有共用池自動開啟超賣能力,專有池可設定選擇開啟超賣能力。
-
可自定義開啟超賣型別:靜態、動態、靜態+動態。
-
可自定義靜態係數、動態超賣擴大系數。
-
可設定是否自動修改超賣值,當不自動生效可通過介面查詢推薦值,由業務自行修改。
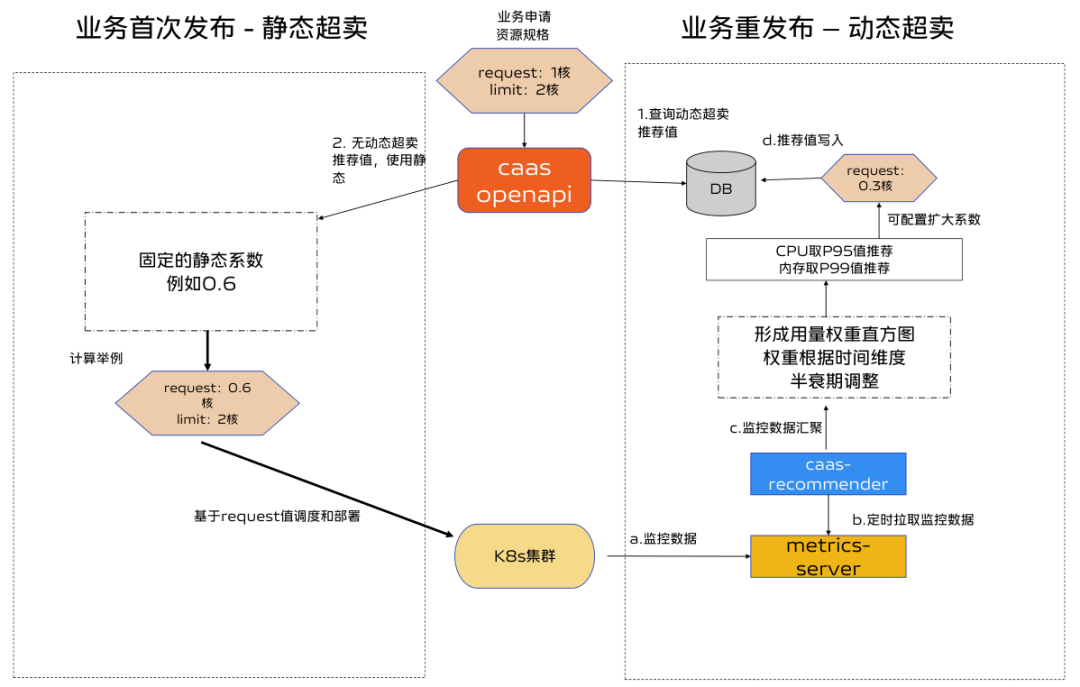
3.5 整體方案
首次部署:
根據先驗知識評估,通過固定靜態係數修改request值,再根據部署後各個pod監控用量資料,生成workload的request推薦值。
再次部署:
若有推薦值,使用推薦值部署。無推薦值或者推薦值未生效時,使用靜態係數。
四、效果和收益
4.1 測試叢集收益
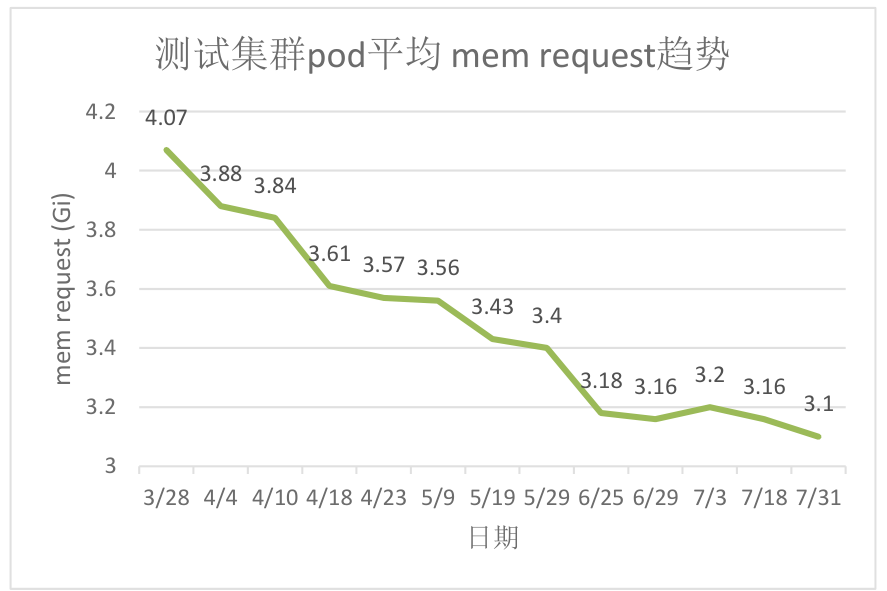
原測試機器的靜態超賣係數很低,且只縮減cpu維度資源,導致叢集記憶體成為資源瓶頸。
開啟動態超賣能力4個月後,納管90%的workload,節點pod平均記憶體request由4.07Gi下降到3.1Gi,記憶體平臺裝箱率降低10%,有效緩解叢集記憶體不足問題。
4.2 共用池生產叢集收益
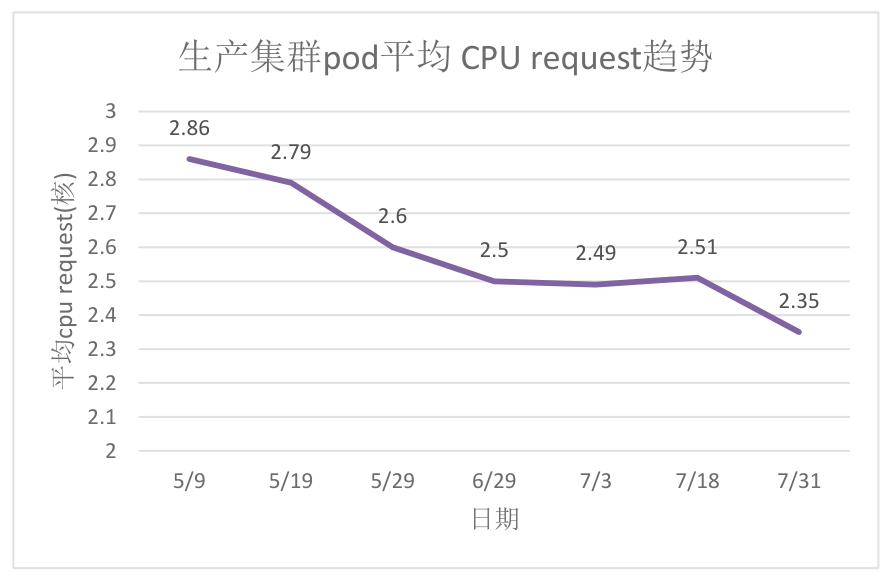
原生產叢集靜態超賣係數較高,CPU資源裝箱率高,導致叢集的CPU成為瓶頸。
開啟動態超賣能力3個月後,納管60%的workload,節點pod平均cpu request由2.86降低為2.35,整體cpu利用率相比未開啟前提升8%左右。
五、總結與展望
vivo容器平臺通過資源超賣方案,將業務容器的request降低到合理值,降低業務使用成本,緩解了叢集資源不足問題,達到了提升節點利用率目的。但是當前僅在生產叢集開啟了CPU資源超賣,規劃近期開啟記憶體資源超賣。
未來基於上述方法,可以納管更多維度,比如GPU卡利用率再結合GPU虛擬化能力,從而提高GPU資源共用效率。根據動態超賣推薦值可以用於構建人物誌,區分業務是計算型或記憶體型,方便平臺更好理解使用者特性,輔助資源排程等。
參考資料: