MySQL運維11-Mycat分庫分表之應用指定分片
一、應用指定分片
說明1:子字串分片有一個侷限性,就是擷取的子字串必須是數位,而且要從擷取的數位0:代表第一個資料節點,1:代表第二個資料節點,以此類推,因為資料節點的下標是從0開始的。
說明2:子字串分片的規則是rule="sharding-by-substring"
說明3:function中的startIndex是擷取子字串的開始擷取的索引位置,即從第一個位置開始擷取。
說明4:function中的size是擷取長度
說明5:partitionCount是分片數量,注意分片的索引從0開始,所以這裡partitionCount=3,即第一個資料分片的值為0,第二個資料分片的值為1,第三個資料分片的值為2
說明6:defaultPartition是預設的資料儲存的資料節點,即如果萬一出現了不符合的擷取資料,都會存放在這個預設資料節點上,例如現在有一個擷取子字串為5開頭的資料,就會放在這個預設資料節點上。
二、準備工作
應用指定分片需求:基於邏輯庫hl_logs,建立邏輯表tb_school,裡面包括id,name,age等欄位,其中小學部的學生id以1開頭,中學部的學生id以2開頭,高中部的學生id以3開頭
三、設定rule.xml
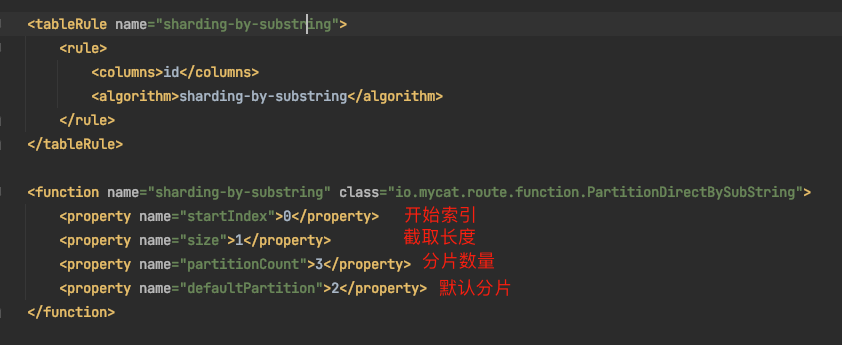
<tableRule name="sharding-by-substring"> <rule> <columns>id</columns> <algorithm>sharding-by-substring</algorithm> </rule> </tableRule>
說明1:該分片方法沒有在rule.xml範例中展示出來,所以需要我們手動在rule.xml檔案中,新增上該規則。
<function name="sharding-by-substring" class="io.mycat.route.function.PartitionDirectBySubString"> <property name="startIndex">0</property> <property name="size">1</property> <property name="partitionCount">3</property> <property name="defaultPartition">2</property> </function>
說明2:該分片方法的function參照也沒有在rule.xml的範例中展示出來,同樣需要我們手動新增上function的實現
說明3:function中的startIndex是擷取子字串的開始擷取的索引位置,即從第一個位置開始擷取。
說明4:function中的size是擷取長度
說明5:partitionCount是分片數量,注意分片的索引從0開始,所以這裡partitionCount=3,即第一個資料分片的值為0,第二個資料分片的值為1,第三個資料分片的值為2
說明6:defaultPartition是預設的資料儲存的資料節點,即如果萬一出現了不符合的擷取資料,都會存放在這個預設資料節點上,例如現在有一個擷取子字串為5開頭的資料,就會放在這個預設資料節點上。
四、設定schema.xml
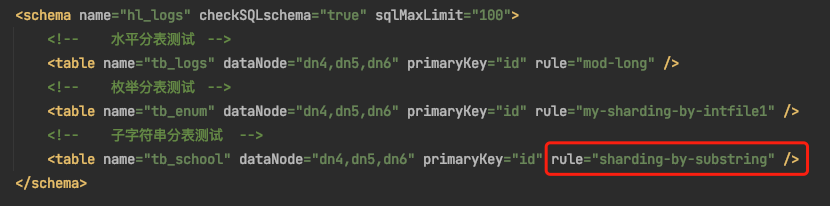
說明1:邏輯庫為hl_logs
說明2:邏輯表為tb_school
說明3:分片規則我們改手動實現的"sharding-by-substring"
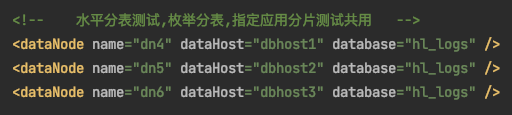

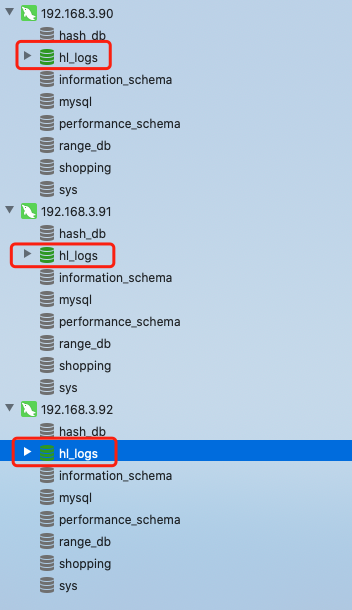
說明4:dn10對應的是dbhost1即192.168.3.90分片
說明5:dn11對應的是dbhost2即192.168.3.91分片
說明6:dn12對應的是dbhost3即192.168.3.92分片
五、設定server.xml
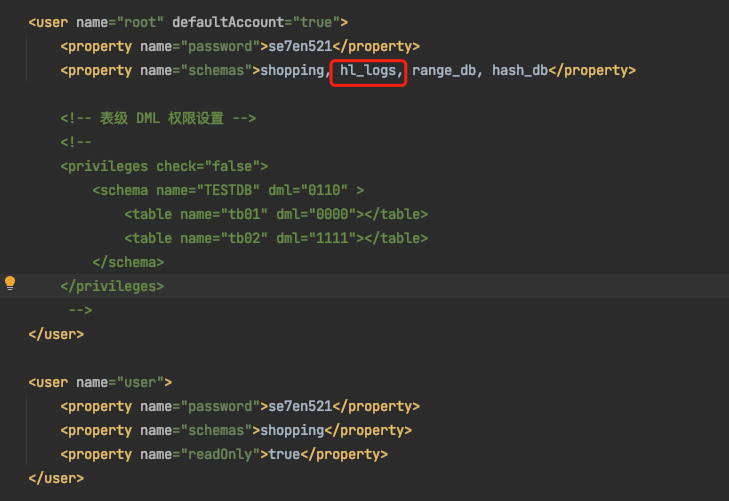
說明1:在之前的文章中已經將tb_logs表新增到root使用者的許可權中了,所以這裡不需要更改即可。
六、應用指定分片測試
首先重啟Mycat
登入Mycat
檢視邏輯庫和邏輯表
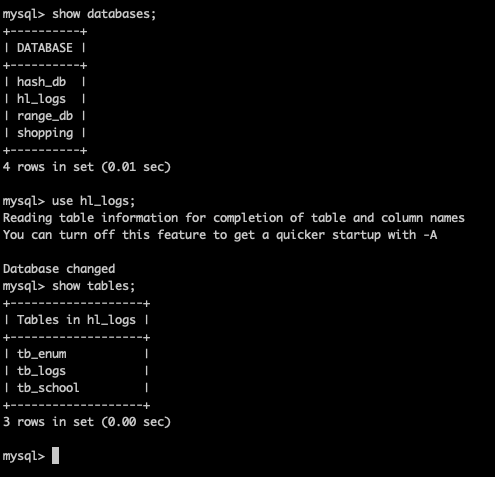
這裡的tb_school只是邏輯庫,而在MySQL中還並沒有tb_school這個表,需要在Mycat中建立
create table tb_school(id varchar(5), name varchar(20), age int);
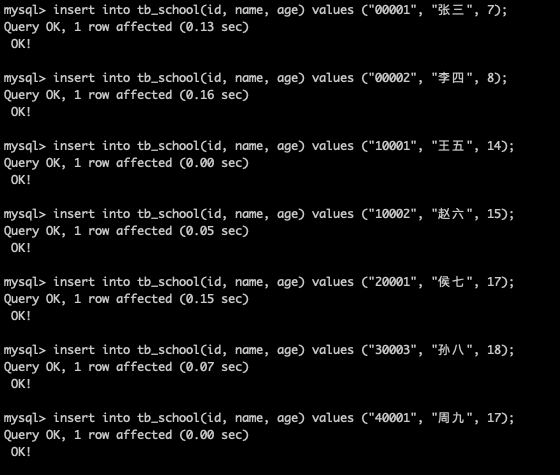
插入資料進行測試:這裡插入一組資料進行測試:
insert into tb_school(id, name, age) values ("00001", "張三", 7); insert into tb_school(id, name, age) values ("00002", "李四", 8); insert into tb_school(id, name, age) values ("10001", "王五", 14); insert into tb_school(id, name, age) values ("10002", "趙六", 15); insert into tb_school(id, name, age) values ("20001", "侯七", 17); insert into tb_school(id, name, age) values ("30003", "孫八", 18); insert into tb_school(id, name, age) values ("40001", "周九", 17);
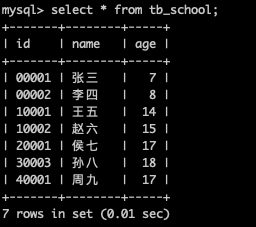
說明1:這裡的id要求是字串型別的
說明2:id雖然是字串型別的,但是我們要擷取的第一位還必須是數位,所以這中分片方式比較苛刻

說明3:第一個資料節點192.168.3.90裡面儲存的資料全部是id以0開頭的資料

說明4:第二個資料節點192.168.3.91裡面儲存的資料全部是id以1開頭的資料

說明5: 第三個資料節點的索引是2,所以第三個資料節點是預設資料階段,這裡面儲存了id以2開頭的資料,可其他不滿足分片規則的資料,例如id擷取第一個字串3和4,就不滿足資料分片下標0,1,2的規則,就只能進入到預設的這個資料節點中。也可以理解為預設的資料節點是兜底的分片
說明6:其實這個應用指定字串擷取的方式和列舉分片有同工異曲的效果,只是不用在單獨建立一個列舉欄位了。
說明7:在Mycat上進行查詢的資料是,所有資料節點的全集。應用指定分片是水平分庫分表的一種方式。
侯哥語錄:我曾經是一個職業教育者,現在是一個自由開發者。我希望我的分享可以和更多人一起進步。分享一段我喜歡的話給大家:"我所理解的自由不是想幹什麼就幹什麼,而是想不幹什麼就不幹什麼。當你還沒有能力說不得時候,就努力讓自己變得強大,擁有說不得權利。"