MySQL運維9-Mycat分庫分表之列舉分片
一、列舉分片
通過在組態檔中設定可能的列舉值,指定資料分佈到不同資料節點上,這種方式就是列舉分片規則,本規則適用於按照省份,性別,狀態拆分資料等業務
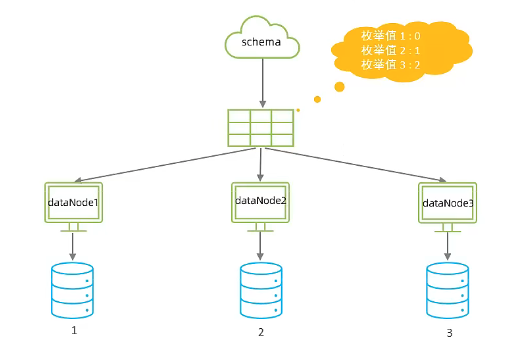
二、列舉分片案例
列舉分片需求:現有 tb_enum 表,其中有 id, username, status三個欄位,其中status值為1,2,3 當status=1時表示:未啟用,status=2時表示:已啟用,status=3時表示:已登出。現在我們就需要根據這三種狀態進行分片。
資料庫需求:還是用之前文章中建立的 hl_logs 資料庫
表需求:在 hl_logs 中重新建立表為 tb_enum
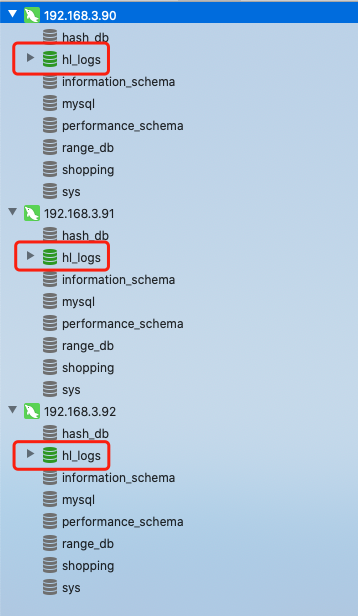
三、設定rule.xml
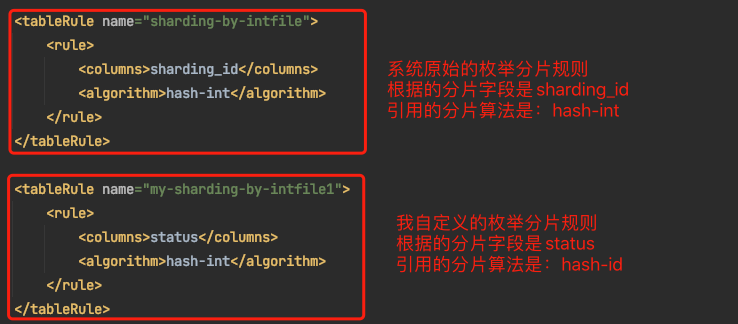
說明1:系統預設的列舉分片規則為:sharding-by-intfile
說明2:系統預設的列舉欄位是:sharding_id (可以根據需要改成自己需要的列舉欄位,但是不推薦,因為有可能多個表的列舉欄位會有衝突,請看說明4)
說明3:系統預設的列舉分片的演演算法:hsah-int
說明4:這裡我將系統的列舉演演算法複製一份改了名字為"my-sharding-by-intfile1",columns改為我需要的列舉欄位status,這樣做的原因是,因為如果一個資料庫中可能還會有其他的表根據其他列舉欄位分片,這樣就衝突了,所以為了防止多個表的列舉分片規則衝突,最好的方式就是重新複製一個新的列舉規則,改一下規則的名稱,然後再改一個列舉的欄位,只要保證列舉演演算法:hash-int不變就行了。

說明5:在function標籤中的mapFile屬性可以看出,列舉分片的設定通過partition-hash-int.txt檔案設定

說明6:修改partition-hash-int.txt檔案,其中1代表status=1,表示未啟用的使用者,寫入到索引為0的第一個資料節點中
說明7:修改partition-hash-int.txt檔案,其中2代表status=2,表示已啟用的使用者,寫入到索引為1的第二個資料節點中
說明8:修改partition-hash-int.txt檔案,其中3代表status=3,表示已登出的使用者,寫入到索引為2的第三個資料節點中
四、設定schema.xml

說明1:列舉分片的邏輯庫是hl_logs
說明2:列舉分片的邏輯表是tb_enum
說明3:dataNode同樣是dn4,dn5,dn6
說明4:列舉分片的規則是自定義的列舉規則 rule="my-sharding-by-intfile1"
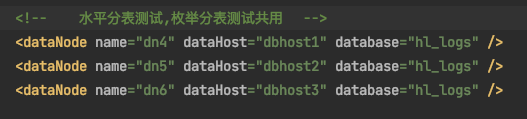
說明5:因為 tb_logs 和 tb_enum 是在同一個資料庫中,所以dataNode設定一樣,就可以共用
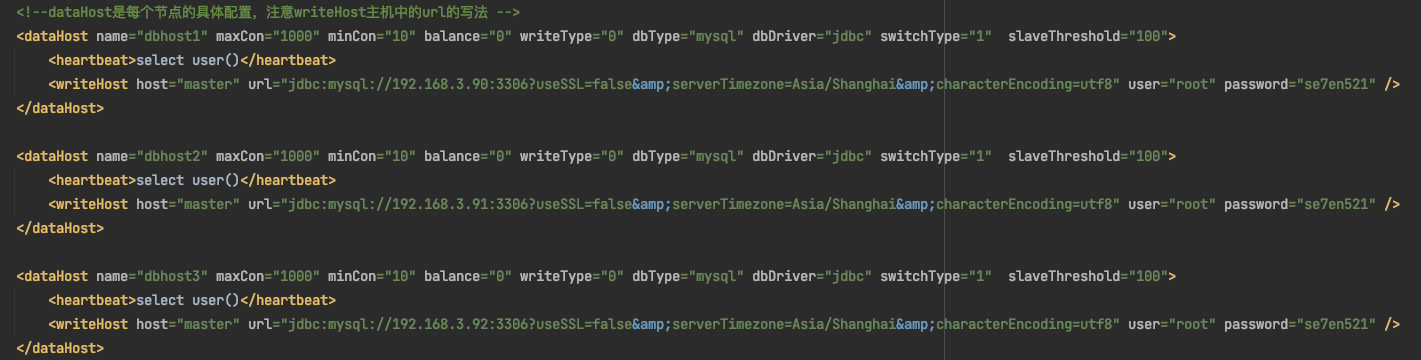
說明6:dbhost1資料節點為192,168.3.90
說明7:dbhost2資料節點為192.168.3.91
說明8:dbhost3資料節點為192.168.3.92
五、設定server.xml
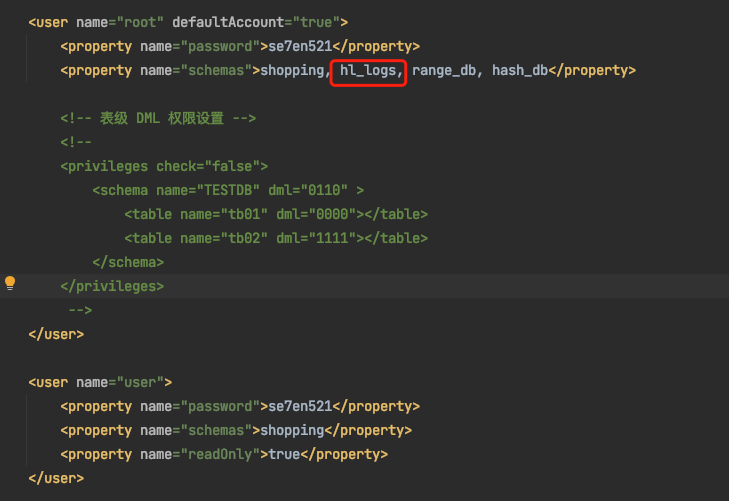
說明1:在之前的文章中已經將tb_logs表新增到root使用者的許可權中了,所以這裡不需要更改即可。
六、列舉分片測試
首先重啟Mycat
登入Mycat
檢視邏輯庫和邏輯表
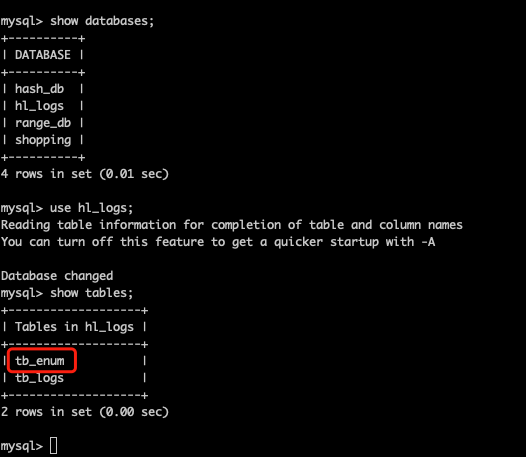
這裡的tb_enum只是邏輯庫,而在MySQL中還並沒有tb_enum這個表,需要在Mycat中建立
create table tb_enum(id bigint(20), username varchar(20), status int(2));
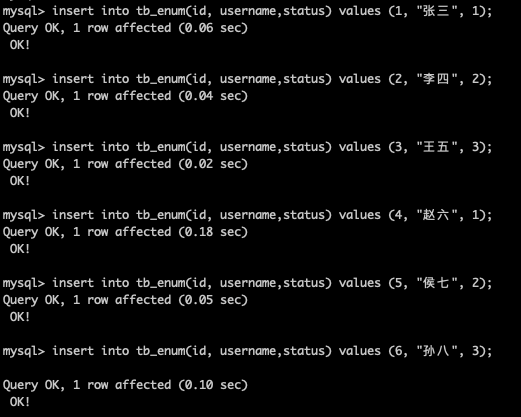
插入一下資料進行分片測試
insert into tb_enum(id, username,status) values (1, "張三", 1);
insert into tb_enum(id, username,status) values (2, "李四", 2);
insert into tb_enum(id, username,status) values (3, "王五", 3);
insert into tb_enum(id, username,status) values (4, "趙六", 1);
insert into tb_enum(id, username,status) values (5, "侯七", 2);
insert into tb_enum(id, username,status) values (6, "孫八", 3);
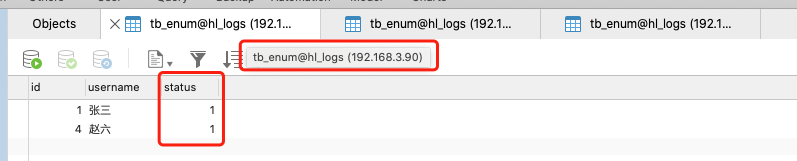
說明1:資料節點192.168.3.90上存的全部是status=1的資料

說明2:資料節點192.168.3.91上存的全部是status=2的資料

說明3:資料節點192.168.3.92上存的全部是status=3的資料
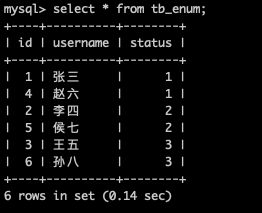
說明4:在Mycat上進行查詢的資料是,所有資料節點的全集。列舉分片是水平分庫分表的一種方式。
侯哥語錄:我曾經是一個職業教育者,現在是一個自由開發者。我希望我的分享可以和更多人一起進步。分享一段我喜歡的話給大家:"我所理解的自由不是想幹什麼就幹什麼,而是想不幹什麼就不幹什麼。當你還沒有能力說不得時候,就努力讓自己變得強大,擁有說不得權利。"