檔案理解的新時代:LayOutLM模型的全方位解讀
一、引言
在現代檔案處理和資訊提取領域,機器學習模型的作用日益凸顯。特別是在自然語言處理(NLP)技術快速發展的背景下,如何讓機器更加精準地理解和處理複雜檔案成為了一個挑戰。檔案不僅包含文字資訊,還包括佈局、影象等非文字元素,這些元素在傳遞資訊時起著至關重要的作用。傳統的NLP模型通常忽略了這些視覺元素,但LayOutLM模型的出現改變了這一局面。
LayOutLM模型是一種創新的深度學習模型,它結合了傳統的文書處理能力和對檔案佈局的理解,從而在處理包含豐富佈局資訊的檔案時表現出色。這種模型的設計思想源於對現實世界檔案處理需求的深刻理解。例如,在處理一份報告時,我們不僅關注報告中的文字內容,還會關注圖表、標題、段落佈局等視覺資訊。這些資訊幫助我們更好地理解檔案的結構和內容重點。
為了說明LayOutLM模型的重要性和實用性,我們可以考慮一份含有多種元素(如文字、表格、圖片)的商業合同。在這樣的檔案中,合同的條款可能以不同的字型或佈局突出顯示,而關鍵的圖表和資料則以特定的方式呈現。傳統的文字分析模型可能無法有效地識別和處理這些複雜的佈局和視覺資訊,導致資訊提取不完整或不準確。而LayOutLM模型則能夠識別這些元素,準確提取關鍵資訊,從而大大提高檔案處理的效率和準確性。
在接下來的章節中,我們將詳細探討LayOutLM模型的架構、技術實現細節以及在實際場景中的應用。通過深入瞭解LayOutLM模型,讀者將能夠更好地理解其在現代檔案理解領域的獨特價值和廣泛應用前景。
二、LayOutLM模型詳解
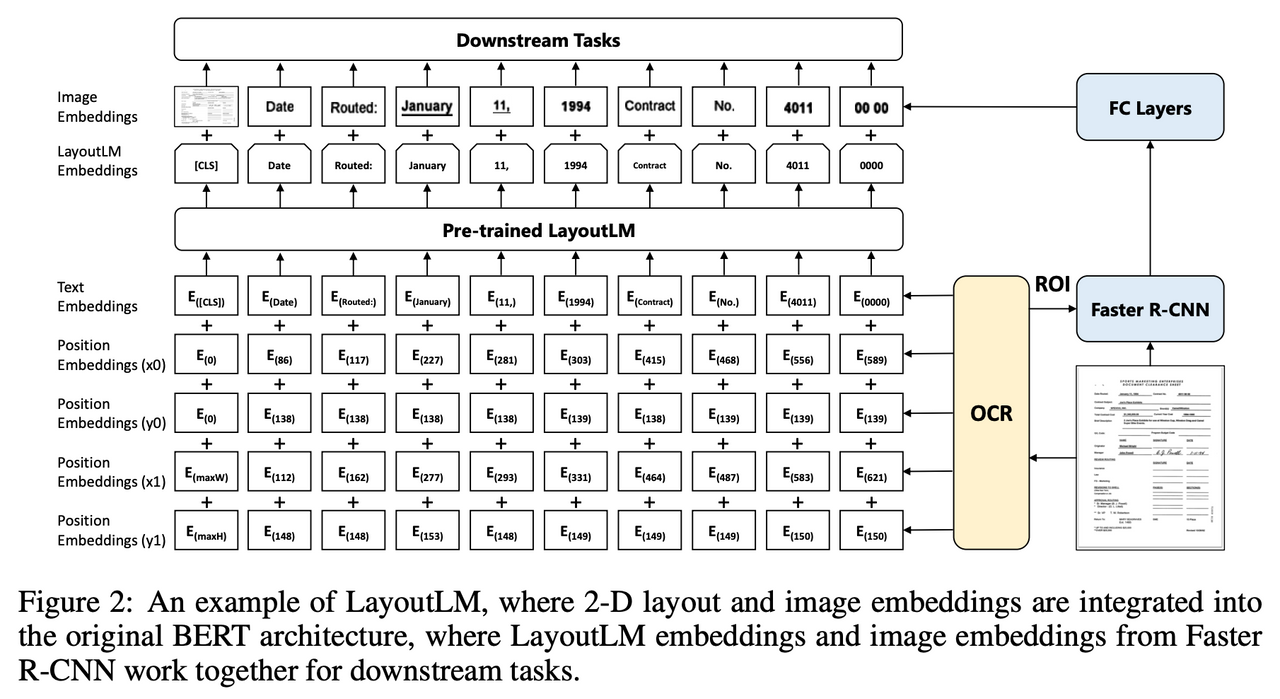
LayOutLM模型代表了自然語言處理(NLP)與計算機視覺(CV)交叉領域的一大步。它不僅理解文字內容,還融入了檔案的佈局資訊,為檔案理解帶來了革新性的進步。接下來,我們將深入探討LayOutLM模型的關鍵組成部分、工作原理和實際應用。
模型架構概覽
LayOutLM採用了與BERT類似的架構,但它在輸入表示中加入了視覺特徵。這些視覺特徵來自檔案中的每個詞的佈局資訊,如位置座標和頁面資訊。LayOutLM利用這些資訊來理解文字在視覺頁面上的分佈,這在處理表格、表單和其他佈局密集型檔案時特別有用。
輸入表示方法
在LayOutLM中,每個詞的輸入表示由以下幾部分組成:
- 文字嵌入: 類似於傳統的NLP模型,使用詞嵌入來表示文字資訊。
- 位置嵌入: 表示詞在文字序列中的位置。
- 佈局嵌入: 新增加的特徵,包括詞在頁面上的相對位置(例如左上角座標和右下角座標)。
例如,考慮一個簡單的發票檔案,包含「發票號碼」和具體的數位。LayOutLM不僅理解這些詞的語意,還能通過佈局嵌入識別數位是緊跟在「發票號碼」標籤後面的,從而有效地提取資訊。
預訓練任務和過程
LayOutLM的預訓練包括多種任務,旨在同時提高模型的語言理解和佈局理解能力。這些任務包括:
- 掩碼語言模型(MLM): 類似於BERT,部分詞被掩蓋,模型需要預測它們。
- 佈局預測: 模型不僅預測掩蓋的詞,還預測它們的佈局資訊。
微調和應用
在預訓練完成後,LayOutLM可以針對特定任務進行微調。例如,在表單理解任務中,可以用具有標註的表單資料對模型進行微調,使其更好地理解和提取表單中的資訊。
# 範例程式碼: LayOutLM模型微調
from transformers import LayoutLMForTokenClassification
# 載入預訓練的LayOutLM模型
model = LayoutLMForTokenClassification.from_pretrained('microsoft/layoutlm-base-uncased')
# 微調模型(虛擬碼)
train_dataloader = ... # 定義訓練資料
optimizer = ... # 定義優化器
for epoch in range(num_epochs):
for batch in train_dataloader:
inputs = batch['input_ids']
labels = batch['labels']
outputs = model(inputs, labels=labels)
loss = outputs.loss
loss.backward()
optimizer.step()
在這一部分,我們通過深入分析LayOutLM模型的架構和工作機制,展示了其在理解包含豐富佈局資訊的檔案方面的強大能力。通過舉例和程式碼展示,我們希望讀者能夠更全面地理解LayOutLM模型的工作原理和應用場景。在接下來的章節中,我們將進一步探討LayOutLM在實際應用中的表現和實戰指南。
三、LayOutLM在實際中的應用
LayOutLM模型不僅在理論上具有創新性,更在實際應用中顯示出其強大的能力。本節將探討LayOutLM在多個實際場景中的應用,通過具體的例證來闡明其在解決實際問題中的有效性和靈活性。
檔案分類與排序
在企業和機構的日常工作中,大量的檔案需要被分類和歸檔。傳統方法依賴於文字內容的關鍵詞搜尋,但LayOutLM可以進一步利用檔案的佈局資訊。例如,不同型別的報告、發票或合同通常具有獨特的佈局特徵。LayOutLM能夠識別這些特徵,從而更準確地將檔案分類。
資訊提取
資訊提取是LayOutLM的另一個重要應用場景。在處理髮票、收據等檔案時,關鍵資訊(如總金額、日期、專案列表)通常分佈在不同的位置,且每個檔案的佈局可能略有不同。LayOutLM利用其對佈局的理解,能夠準確地從這些檔案中提取所需資訊。例如,從一堆雜亂的發票中提取出所有的發票號碼和金額,即便它們的佈局不盡相同。
表單處理
在表單處理中,LayOutLM的應用尤為突出。不同於傳統的基於規則的處理方法,LayOutLM可以理解表單中的問題和答案的佈局關係。這使得在自動化處理問卷調查或申請表時,模型可以更加高效和準確地提取出關鍵資訊。
自動化檔案稽核
在法律和金融領域,檔案稽核是一項關鍵任務。LayOutLM可以輔助稽核人員快速地找出檔案中的關鍵條款或可能存在的問題。例如,在一份合同中,模型可以快速定位到關鍵的責任條款或特殊的免責宣告,輔助法律專業人士進行深入分析。
通過上述應用案例,可以看出LayOutLM模型在實際中的廣泛應用和顯著效果。這些例證不僅展示了LayOutLM在處理具有複雜佈局的檔案方面的能力,也說明了其在提高工作效率和準確性方面的巨大潛力。接下來的章節將進一步提供實戰指南,幫助讀者瞭解如何在自己的專案中實施和優化LayOutLM模型。
四、實戰指南
在本節中,我們將提供一個基於Python和PyTorch的實戰指南,展示如何使用LayOutLM模型進行檔案理解任務。我們將通過一個實際場景——從一組商業發票中提取關鍵資訊——來演示LayOutLM的實現和應用。
場景描述
假設我們有一批不同格式的商業發票,需要從中提取關鍵資訊,如發票號、日期、總金額等。這些發票在佈局上有所差異,但都包含了上述關鍵資訊。
輸入和輸出
- 輸入: 一批包含文字和佈局資訊的發票影象。
- 輸出: 提取的關鍵資訊,如發票號、日期和總金額。
處理過程
-
環境準備: 安裝必要的庫。
pip install transformers torch torchvision -
模型載入: 載入預訓練的LayOutLM模型。
from transformers import LayoutLMForTokenClassification, LayoutLMTokenizer model_name = 'microsoft/layoutlm-base-uncased' model = LayoutLMForTokenClassification.from_pretrained(model_name) tokenizer = LayoutLMTokenizer.from_pretrained(model_name) -
資料準備: 對發票影象進行預處理,提取文字和佈局資訊。
# 這裡是一個範例函數,用於將發票影象轉換為模型輸入 def preprocess_invoice(image_path): # 實現影象的載入和預處理,提取文字和佈局資訊 # 返回模型所需的輸入格式,如tokenized text, attention masks, 和token type ids pass # 範例:處理單個發票影象 input_data = preprocess_invoice("path_to_invoice_image.jpg") -
資訊提取: 使用LayOutLM模型提取關鍵資訊。
import torch # 調整輸入資料以適應模型 input_ids = torch.tensor([input_data["input_ids"]]) token_type_ids = torch.tensor([input_data["token_type_ids"]]) attention_mask = torch.tensor([input_data["attention_mask"]]) with torch.no_grad(): outputs = model(input_ids, token_type_ids=token_type_ids, attention_mask=attention_mask) predictions = outputs.logits.argmax(dim=2) -
結果解析: 解析模型輸出,提取和整理關鍵資訊。
# 範例函數,用於解析模型的輸出並提取資訊 def extract_info(predictions, tokens): # 實現提取關鍵資訊的邏輯 # 返回結構化的資訊,如發票號、日期和金額 pass tokens = input_data["tokens"] extracted_info = extract_info(predictions, tokens) -
後處理: 根據需要對提取的資訊進行格式化和儲存。
在以上步驟中,我們描述了使用LayOutLM模型從商業發票中提取關鍵資訊的完整過程。請注意,資料預處理和結果解析步驟將依賴於具體的應用場景和資料格式。通過這個實戰指南,讀者應該能夠理解如何在實際專案中部署和使用LayOutLM模型,從而解決複雜的檔案理解任務。
五、結論
隨著人工智慧領域的迅速發展,模型如LayOutLM的出現不僅是技術進步的象徵,更代表了我們對於資訊處理方式的深刻理解和創新。LayOutLM模型在NLP和CV的交匯點上開啟了新的可能性,為處理和理解複雜檔案提供了新的視角和工具。這一點在處理具有豐富佈局資訊的檔案時尤為明顯,它不僅提升了資訊提取的準確性,還極大地增強了處理效率。
域的獨特洞見
-
跨領域融合的趨勢: LayOutLM的成功展示了跨領域(如NLP和CV)融合的巨大潛力。這種跨學科的方法為解決複雜問題提供了新的思路,預示著未來人工智慧發展的一個重要趨勢。
-
對複雜資料的深層次理解: 傳統的NLP模型在處理僅包含文字的資料時表現出色,但在面對包含多種資料型別(如文字、影象、佈局)的複雜檔案時則顯得力不從心。LayOutLM的出現彌補了這一空缺,它的能力在於不僅理解文字內容,還能解讀檔案的視覺佈局,展示了對更復雜資料的深層次理解。
-
實用性與應用廣泛性: LayOutLM不僅在理論上具有創新性,而且在實際應用中表現出色。從商業發票的資訊提取到法律檔案的自動稽核,這些應用案例證明了其在多個行業的廣泛適用性和實用價值。
-
持續的創新與優化: 正如LayOutLM在現有技術上的進步,未來的研究可能會繼續在模型的精度、速度和靈活性上進行優化。這可能包括更高效的訓練方法、對更多種類的檔案格式的支援,以及更加智慧的上下文理解能力。
綜上所述,LayOutLM模型不僅在技術上取得了顯著的進展,更重要的是它為我們提供了一種全新的視角來看待和處理檔案資訊。隨著人工智慧技術的不斷髮展,我們可以預見到更多類似LayOutLM這樣的模型將出現,並在各個領域發揮重要作用。在此過程中,對技術的深入理解和創新思維將是推動這一領域發展的關鍵。
如有幫助,請多關注
TeahLead KrisChang,10+年的網際網路和人工智慧從業經驗,10年+技術和業務團隊管理經驗,同濟軟體工程本科,復旦工程管理碩士,阿里雲認證雲服務資深架構師,上億營收AI產品業務負責人。