聊聊kube-scheduler如何完成排程和調整排程權重
本文分享自華為雲社群《kube-scheduler如何完成排程和調整排程權重》,作者: 可以交個朋友。
一、概述
Kube-scheduler作為k8s叢集的預設排程器,它監聽(watch機制)kube-apiserver,查詢還未排程的pod,根據排程策略將pod排程至叢集內最適合的Node
二、排程流程
首先我們通過API或者kubectl工具建立pod,kube-apiserver收到請求資訊儲存到etcd中,排程器通過watch機制監聽apiserver檢視到還未被排程的pod列表,迴圈遍歷的為每個pod嘗試分配node,這個分配過程如下:
-
kube-scheduler內Informer元件list-watch apiserver,使用spec.nodeName=""篩選出還未排程的Pod
-
預選(predicate):排程器通過Predicate演演算法過濾掉不滿足條件的節點
-
優選(priorlty):對於通過預選的節點,通過打分機制,篩選出得分最高的node
-
當排程器為Pod選擇了一個合適的節點後,將Pod和節點進行繫結(將節點名稱賦值給pod的spec.nodeName欄位)
注意:Pod.spec.nodeName用於強制約束將Pod排程到指定的Node上,通過指定nodeName可直接繞過排程器,並不會做任何的資源過濾和檢查
三、kuble-scheduler排程原理
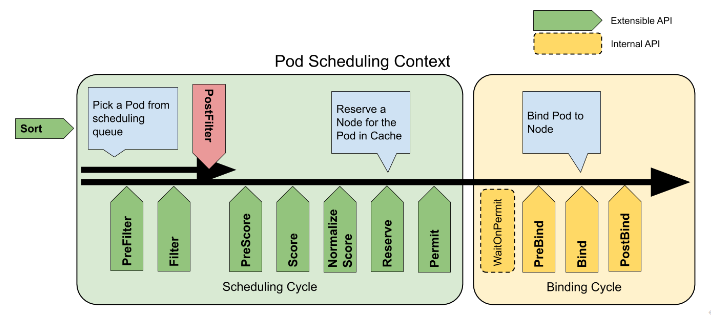
Kube-scheduler的排程框架,在 Kubernetes 裡面叫作 Scheduler Framework。Pod在排程過程中,都需要依次經過以下的各個階段,每個階段自帶排程演演算法,排程演演算法由外掛提供,也可以在指定階段開發自己的外掛。每個外掛可以在指定階段實現具體的排程演演算法,比如NodeAffinity外掛在Filter階段過濾掉與Pod不親和的節點。
-
PreFilter: 預處理 Pod 的相關資訊,或者檢查叢集或Pod 必須滿足的某些條件。如果 PreFilter 外掛返回錯誤,則排程週期將終止。
-
Filter: 過濾出不能執行該 Pod 的節點。對於每個節點,排程器將按照其設定順序呼叫這些過濾外掛。如果任何過濾外掛將節點標記為不可行,則節點直接排除,不會為該節點呼叫剩下的過濾外掛。
-
PostFilter: 在 Filter 階段後呼叫,但僅在該 Pod 沒有可行的節點時呼叫。 典型的後篩選實現是搶佔,試圖通過搶佔其他 Pod 的資源使該 Pod 可以排程。
-
PreScore: 執行評分任務以生成可評分外掛的共用狀態,如果 PreScore 外掛返回錯誤,則排程週期將終止
-
Score: 通過呼叫每個評分外掛對可排程節點評分
-
NormalizeScore: 規範每個外掛的打分在[0,100]之間
-
Reserve: 在繫結週期之前選擇保留的節點
-
Permit: 批准或拒絕pod排程週期的結果
-
PreBind: 用於執行 Pod 繫結前所需的任何工作。例如,一個預繫結外掛可能需要提供網路卷並且在允許 Pod 執行在該節點之前 將其掛載到目標節點上。
-
Bind: 用於將 Pod 繫結到節點上。直到所有的PreBind 外掛都完成,Bind 外掛才會被呼叫。
-
PostBind: 這是個資訊性的擴充套件點。繫結後外掛在 Pod 成功繫結後被呼叫。這是繫結週期的結尾,可用於清理相關的資源
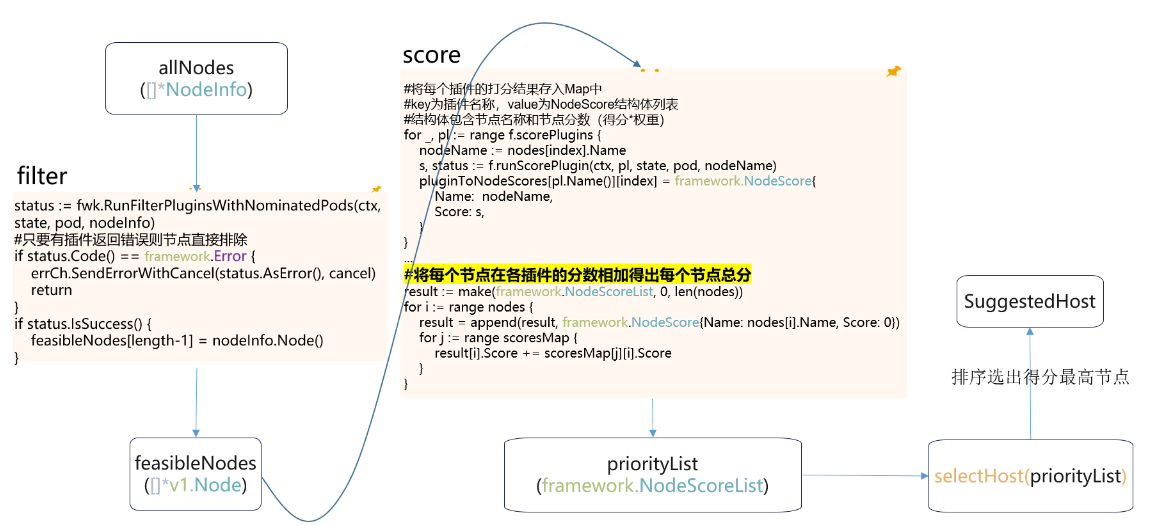
排程器預選階段對應filter,主要用於過濾不滿足Pod排程條件的節點;優選階段對應score,主要用於為每個節點打分,節點分數=外掛打分*外掛權重;然後排序選出分數最高的節點
|
排程階段 |
實現外掛名稱 |
外掛功能介紹 |
|
filter |
PodTopologySpread |
判斷節點是否滿足Pod的拓撲分佈,不滿足則過濾該節點. |
|
InterPodAffinity |
判斷節點是否滿足Pod的親和性設定,不滿足則過濾該節點 |
|
|
NodePorts |
判斷節點是否滿足Pod的埠申請,不滿足則過濾該節點 |
|
|
NodeAffinity |
判斷節點是否滿足Pod的節點親和性設定,不滿足則過濾該節點 |
|
|
VolumeBinding |
判斷節點是否滿足pv的節點親和性,並且將滿足動態建立pvc條件(比如拓撲)的節點儲存起來,以便後續階段使用 |
|
|
TaintToleration |
根據Pod容忍和節點汙點的NoSchedule和NoExecute過濾節點 |
|
|
Score |
NodeAffinity |
根據外掛權重算出得分,再根據策略權重比例算出節點分數,分數區間0~100,權重預設2 |
|
NodeResourcesBalancedAllocatio |
根據不同resource(cpu、mem、volume)對節點容量的佔比再加上對應resource的權重得到分數,分數區間0~100,權重預設1 |
|
|
ImageLocality |
根據Pod中映象大小以及映象在所有節點上的分佈來打分,分數區間0~100,權重預設1 |
|
|
InterPodAffinity |
根據外掛權重算出得分,再根據策略權重比例算出節點分數,分數區間0~100,權重預設2 |
|
|
TaintToleration |
根據PreferNoSchedule策略算出分數,分數區間0~100,權重預設3 |
|
|
NodeResourcesFit |
三種策略:LeastAllocated(分配越少得分越高)、MostAllocated(分配越多得分越高)、RequestedToCapacityRatio(請求值與容量比率) |
|
|
PodTopologySpread |
根據拓撲匹配度和權重得出分數,分數區間0~100,權重預設2 |
3.1 kubernetes 1.23版本排程器filter階段和score階段原始碼分析
3.2 修改排程器外掛預設權重範例
3.2.1 環境準備
環境:叢集中有兩個節點:k8s-0001和k8s-0002;已有工作負載nginx,排程至節點k8s-0002,工作負載test,yaml檔案如下:
apiVersion: apps/v1 kind: Deployment metadata: name: test spec: selector: matchLabels: app: test template: metadata: labels: app: test spec: containers: - name: container-1 image: nginx:latest dnsPolicy: ClusterFirst affinity: nodeAffinity: #利用節點親和使其排程至k8s-0001 preferredDuringSchedulingIgnoredDuringExecution: - weight: 1 preference: matchExpressions: - key: kubernetes.io/hostname operator: In values: - k8s-0001 podAffinity: #利用負載親和使其排程至k8s-0002 preferredDuringSchedulingIgnoredDuringExecution: - weight: 1 podAffinityTerm: labelSelector: matchExpressions: - key: app operator: In values: - nginx namespaces: - default topologyKey: kubernetes.io/hostname
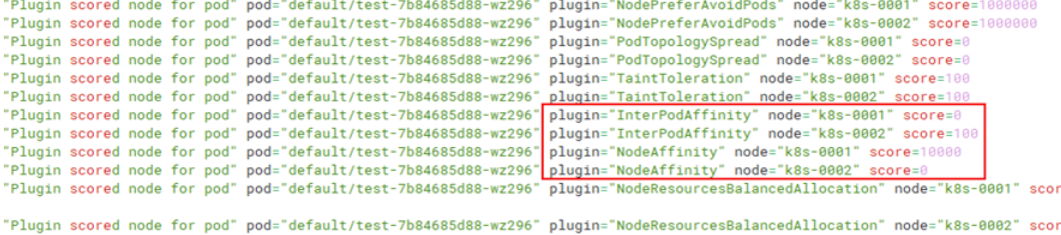
3.2.2 調整InterPodAffinity權重,使工作負載test排程至節點k8s-0002
apiVersion: v1 kind: ConfigMap metadata: name: scheduler-config namespace: kube-system data: scheduler-config.yaml: | apiVersion: kubescheduler.config.k8s.io/v1beta3 #1.23以上版本叢集可用v1beta3 kind: KubeSchedulerConfiguration profiles: - schedulerName: default-scheduler plugins: score: disabled: - name: InterPodAffinity - name: NodeAffinity enabled: - name: InterPodAffinity #提高負載親和權重 weight: 100 - name: NodeAffinity weight: 1
檢視kube-scheduler排程紀錄檔,k8s-002 score得分為打分100 * 權重 100共得10000分,排程到k8s-002節點上
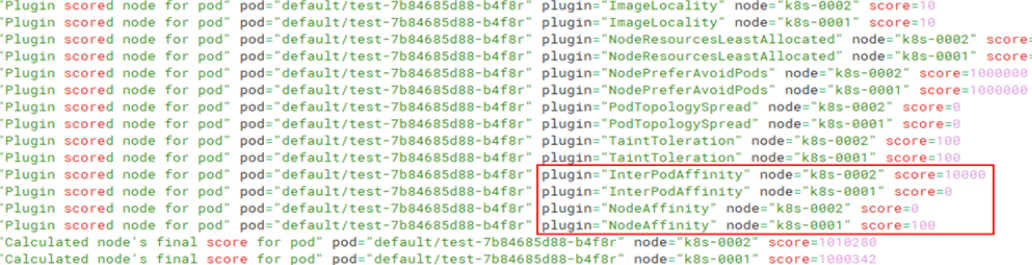
3.2.3 調整NodeAffinity權重,使工作負載test排程至節點k8s-0001
apiVersion: v1 kind: ConfigMap metadata: name: scheduler-config namespace: kube-system data: scheduler-config.yaml: | apiVersion: kubescheduler.config.k8s.io/v1beta3 kind: KubeSchedulerConfiguration profiles: - schedulerName: default-scheduler plugins: score: disabled: - name: InterPodAffinity - name: NodeAffinity enabled: - name: InterPodAffinity weight: 1 - name: NodeAffinity #提高節點親和權重 weight: 100