又被奪命連環問了!從一道關於定時任務的面試題說起。
你好呀,我是歪歪。
定時任務,大家在開發的過程中肯定都是接觸過的。
歪師傅面試的時候關於定時任務一般都會問這樣的一個問題:在實際開發的過程中,你們是如何避免定時任務重複執行的呢?
什麼意思呢?
我給你上個圖你就明白了。
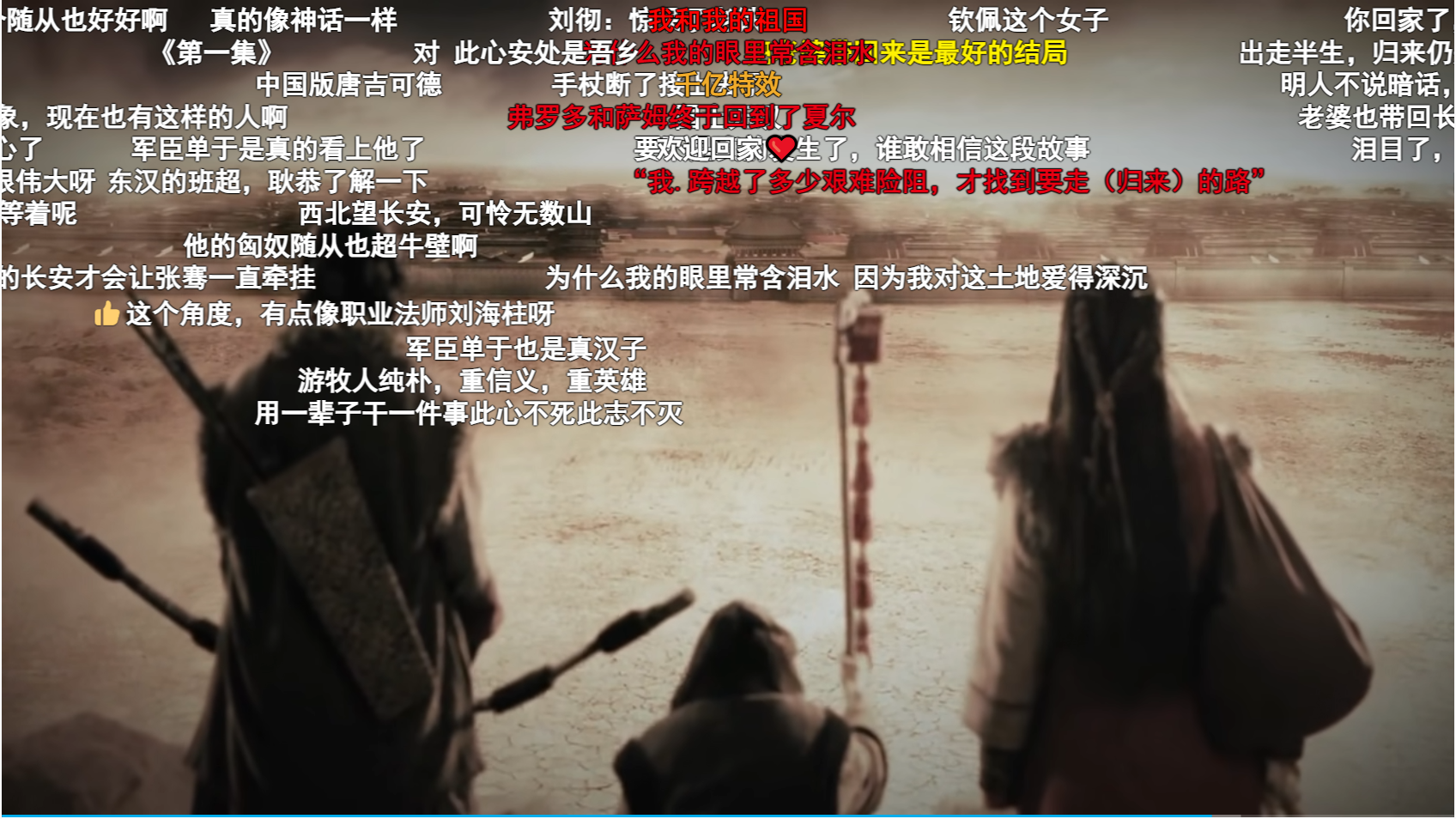
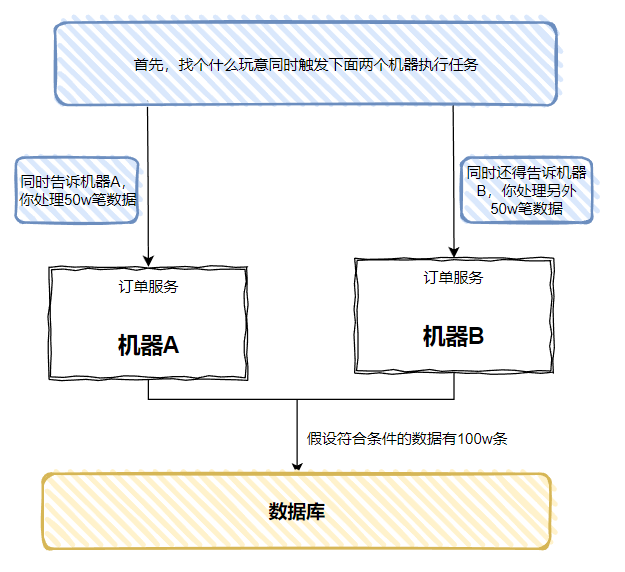
假設我們有個訂單服務的微服務,它部署在兩臺機器上:
這是一個再正常不過的部署方案了吧。
現在有一個需求來了:要從資料庫裡面獲取前一日狀態為成功的訂單,然後把這些訂單一筆筆的呼叫其他服務的介面,通知給他們。
寫程式碼的時候很簡單,基於 Quartz 框架,咔嚓幾下就能搞出一個定時任務來,虛擬碼如下:
//每天10點觸發一次
@Scheduled(cron = "0 0 10 * * ?")
public void sendOrder() {
//查詢前一日狀態為成功的訂單
List<Order> orderList = selectSuccessOrder();
for (Order order : orderList) {
//傳送訂單到資料分析服務
sendOrder(order);
}
}
測試的時候也非常的正常,看不出任何毛病。
但是一上生產就完犢子了,為什麼呢?
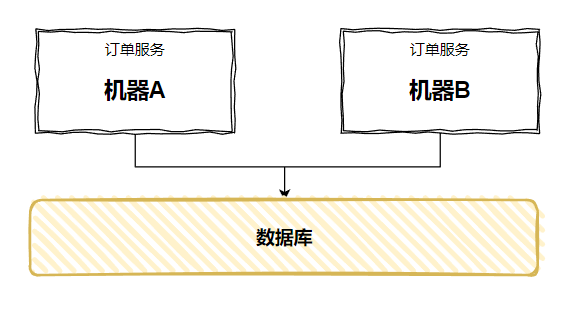
因為測試環境一般來說就只部署一臺伺服器,但是生產環境是多臺呀:
每天 10 點一到,兩臺機器都跑起來了...

同樣的邏輯跑了兩次,一下就瓜起了澀,這肯定不是我們想要的結果。
問:這個情況你怎麼處理?
在實際開發的過程中,我理解大家理論上都會遇到這個問題的。
歪師傅當年還是一個小萌新,第一次遇到這個問題的時候,是怎麼考慮的呢?
摳了摳腦袋,想到一個自己覺得非常靠譜的解決方案。
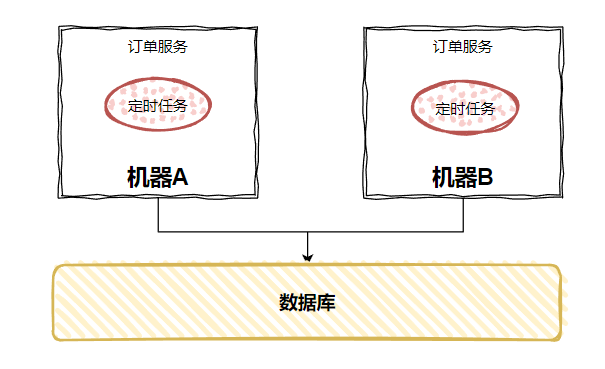
各個微服務提供介面,介面內部實現定時任務的業務邏輯。然後抽離出一個專門的定時任務微服務,在這個服務中開發定時任務,來呼叫對應的介面:
由於「定時任務微服務」只部署在一臺伺服器上,所以當定時任務的時間一到,只會發起一次 RPC 呼叫,具體呼叫哪一臺服務,由 RPC 的負載均衡來決定。
從而規避了前面提到的「觸發兩次」的問題。
當時我還覺得微服務的思想還是真是厲害,這樣一抽離之後,業務程式碼和定時邏輯徹底分離開來,橫向擴充套件也不需要考慮「多次觸發」的問題:
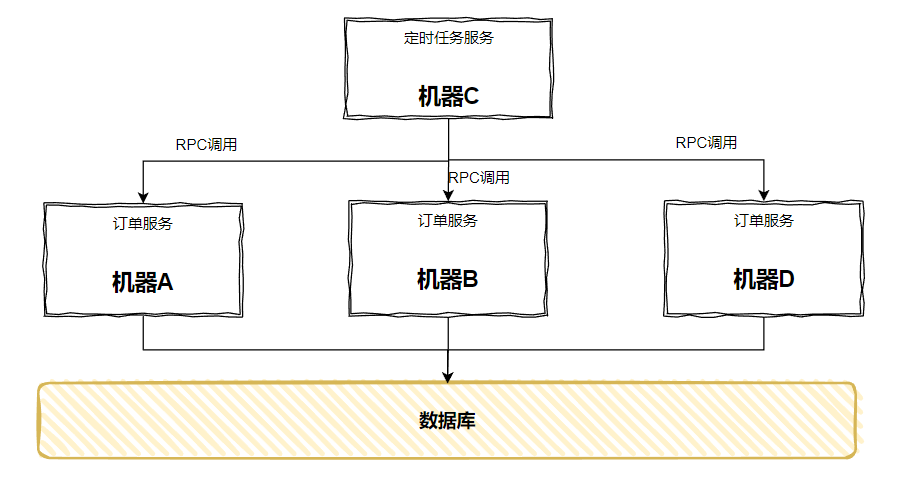
但是,問題隨著就來了:定時任務服務只部署了一臺,它有單點風險啊,它掛了,所有的定時任務不就都掛了嗎?
我知道在有的公司,實際情況就是這樣的,知道服務有單點風險,但是評估下來,覺得是可以接受的,大不了就是做好服務監控,出了問題就趕緊重啟一波服務。
所以遇到這個問題的解決方案就是:不管它。

但是,朋友,面試的時候你能這樣回答嗎,你是去調侃面試官的嗎?
所以,該怎麼辦?
單點問題,很好解決,針對「定時任務服務」多部署一臺伺服器就行了:
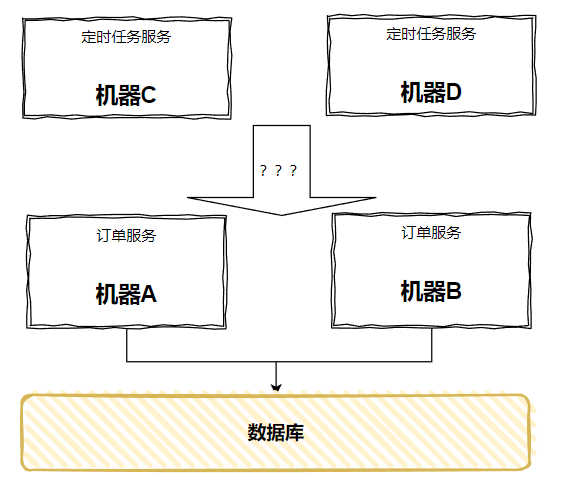
但是,呼叫關係怎麼辦呢?
時間一到,咔的一下,兩臺「定時任務服務」都跑起來了,都對下游發起了 RPC 呼叫,這不又出現了前面這樣「呼叫兩次」的問題嗎:
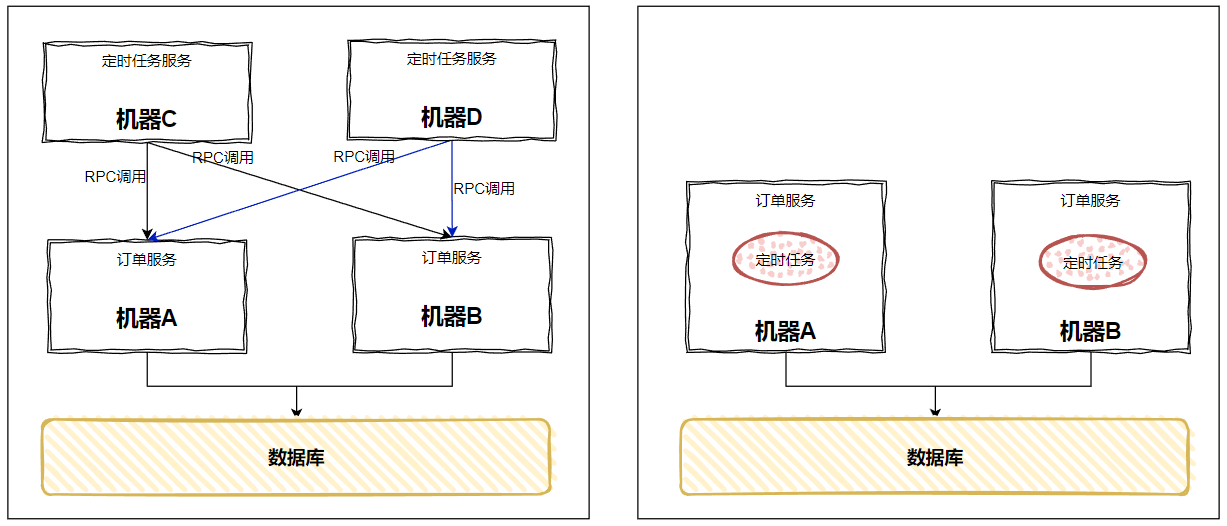
開始套娃了,你說怎麼辦?
這個時候歪師傅又摳了摳腦袋,又想到一個自己覺得非常靠譜的解決方案。
關於這個問題,我先換個殼問你:如果有多個請求過來,但是我們同一時間只想讓一個請求正常執行,請問你怎麼辦?
一般來說我們都會想到加鎖嘛。
單機的話,什麼 synchronized,ReentrantLock 這些玩意就使勁兒往上懟。
多臺服務就上分散式鎖嘛,Redis、Zookeeper 拿出來秀一秀嘛,對不對?
比如,如果我們用 Redis,怎麼做?
在發起 RPC 呼叫之前先從 Redis 裡面拿鎖,多臺機器,誰拿到了,誰就可以執行:
//每天10點觸發一次
@Scheduled(cron = "0 0 10 * * ?")
public void sendOrder() {
//獲取redis鎖
if(SET key value expireTime nx){
//拿到鎖的才能呼叫訂單服務傳送成功訂單邏輯的介面
callOrderRPC();
}
}
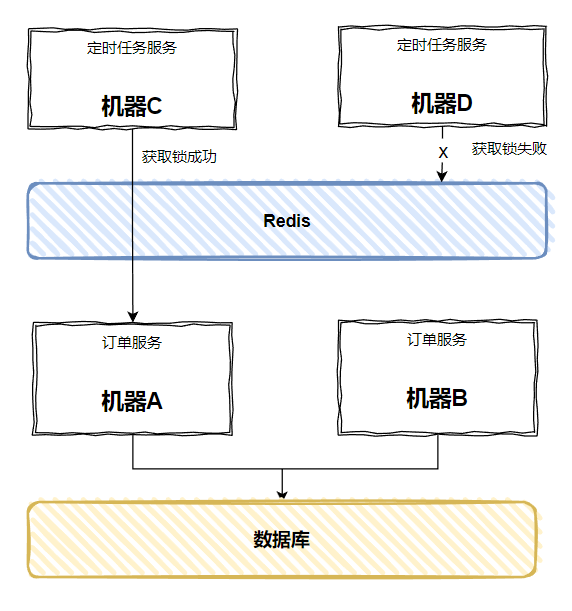
這樣即使某一臺伺服器上的服務掛了,另外一臺也能確保定時任務按時觸發,並表示非常開心:很好,沒人和我搶鎖了。
或者說基於 zookeeper 來做。
比如我們定時任務的服務啟動的時候,以服務名稱維度向 zk 申請一個臨時節點。
誰申請成功了,誰就算加鎖成功了,雖然到點之後每個定時任務都會按時觸發,但是和 Redis 同理,只有拿到鎖的範例才能執行定時任務。
沒有拿到鎖的怎麼辦呢?
監聽這個臨時節點,處於隨時待命狀態。如果當前持有鎖的服務掛了,那麼臨時節點也就沒了,相當於鎖就釋放了,就可以上手搶鎖了。
搶到鎖,就可以執行定時任務,這樣也能保證高可用。
如果是面試,針對「避免定時任務重複執行」能回答到分散式鎖這裡,我認為就可以了。
但是,朋友,這可是面試,面試一般是出連招的。
如果我突然畫風一轉,順勢提出下一個問題:
用分散式鎖,可以通過只讓一臺機器執行的方式解決重複執行的問題。現在我換個場景,問問題,如果我昨日成功的訂單資料量比較多,假設有 100w 筆吧,如果只在一臺機器上跑,即使開啟多執行緒,也需要很長的時間,而且是一臺機器忙的不行,不太機器在旁邊閒的不行。如果我想要充分把機器利用起來,讓兩臺機器都來處理這 100w 筆訂單,各自處理 50w 條,時間不就縮短了嗎?
就像是這樣:
請問,閣下又該如何應對?
ElasticJob
好了,前面鋪墊了這麼多,終於要引出 ElasticJob 這個玩意了。
這是官方檔案的地址:
https://shardingsphere.apache.org/elasticjob/current/cn/overview/
其中有一個章節叫做「彈性排程」:
彈性排程是 ElasticJob 最重要的功能,也是這款產品名稱的由來。 它是一款能夠讓任務通過分片進行水平擴充套件的任務處理系統。
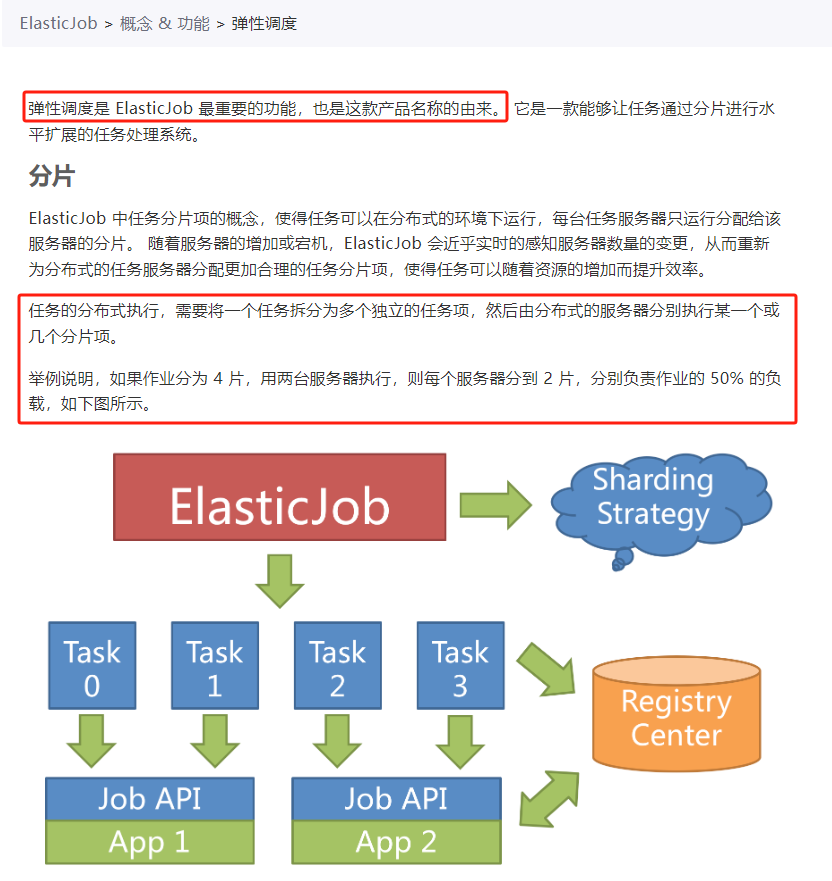
從關於「分片」的描述中,我們知道也許能在這裡找到問題的答案。
雖然答案就在眼前,但是別猴急。按照歪師傅的風格,還是得先上個 Demo 作為引子,給你抽絲剝個繭。
這裡順便吐槽一句官方檔案:
你這個「快速入門」寫的是什麼玩意,根本就不能用好吧?
quick start 不能拿來即用,對於本白嫖黨來說,是很難受的,好嗎。
害得我還得自己摸索一下,還好整體並不複雜,你按照歪師傅給你提供的「快速入門」,五分鐘足夠搭個 Demo 了。
首先,新建一個 Spring Boot 專案,在 pom 檔案中加入相關參照:
<dependency>
<groupId>org.apache.shardingsphere.elasticjob</groupId>
<artifactId>elasticjob-lite-spring-boot-starter</artifactId>
<version>3.0.1</version>
</dependency>
然後實現 SimpleJob 介面,自定義一個定時任務:
package com.example.elasticjobtest;
@Slf4j
@Component
public class SpringBootJob implements SimpleJob {
@Override
public void execute(ShardingContext shardingContext) {
log.info("SpringBootJob作業,分片總數是【{}】,當前分片是【{}】,分片引數是【{}】",
shardingContext.getShardingTotalCount(),
shardingContext.getShardingItem(),
shardingContext.getShardingParameter());
}
}
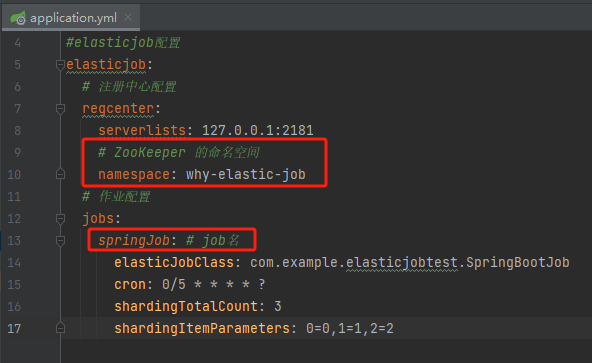
接著在 application.yml 裡面新增設定:
elasticjob:
# 註冊中心設定
regcenter:
serverlists: 127.0.0.1:2181
# ZooKeeper 的名稱空間
namespace: why-elastic-job
# 作業設定
jobs:
springJob: # job的名稱
elasticJobClass: com.example.elasticjobtest.SpringBootJob
cron: 0/5 * * * * ?
shardingTotalCount: 2
shardingItemParameters: 0=Beijing,1=Shanghai
就這幾行程式碼,Demo 就算搭完了。
你自己說,這整個流程是不是五分鐘夠夠的了?
在把服務啟動起來之前,針對 application.yml 的設定,我先多 BB 幾句。
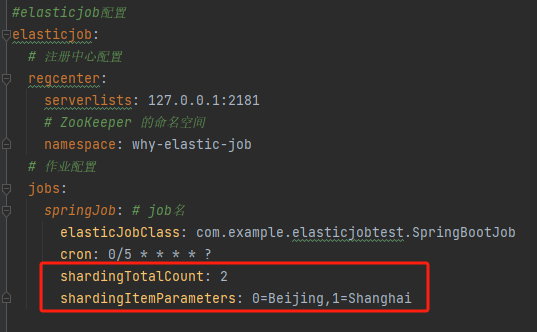
裡面這兩個玩意是什麼東西呢:
可以參考官方檔案中的描述:
https://shardingsphere.apache.org/elasticjob/current/cn/user-manual/configuration/
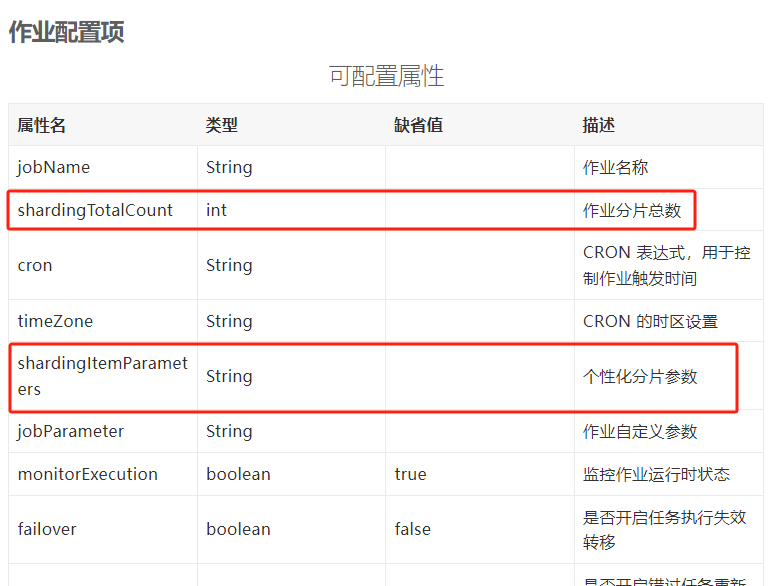
shardingTotalCount 叫做作業分片總數,這個概念非常重要,理解了這個概念,就理解了 ElasticJob 的核心理念,先按下不表。
shardingItemParameters 叫做個性化分片引數,我這裡寫的是 0=Beijing,1=Shanghai,看起來很奇怪對不對,怎麼突然冒出了北京和上海呢?
因為這也是官方檔案中的案例:

這只是範例而已,當你理解了這個概念的用途之後,就可以按照自己的需求進行「個性化」設定。
Demo 跑起來
這個是 ElasticJob 的架構示意圖:
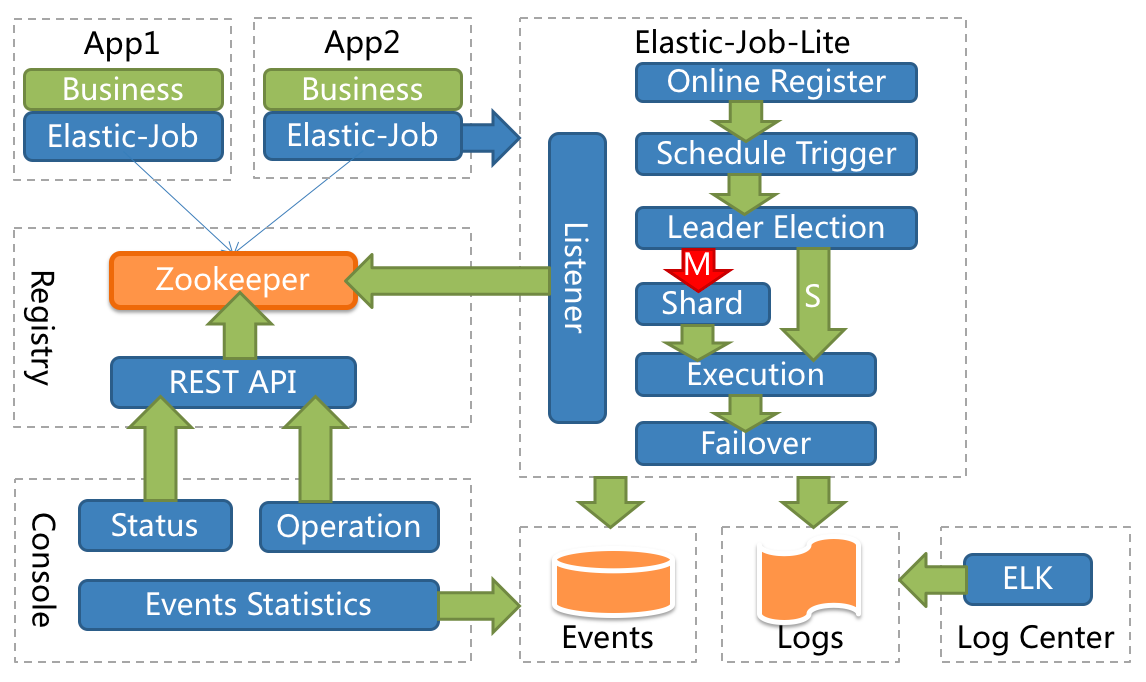
可以看到它選擇了 Zookeeper 做為自己的註冊中心,所以在啟動 Demo 之前,需要你把你原生的 Zookeeper 啟動起來。
然後把 Demo 執行起來,觀察紀錄檔輸出:
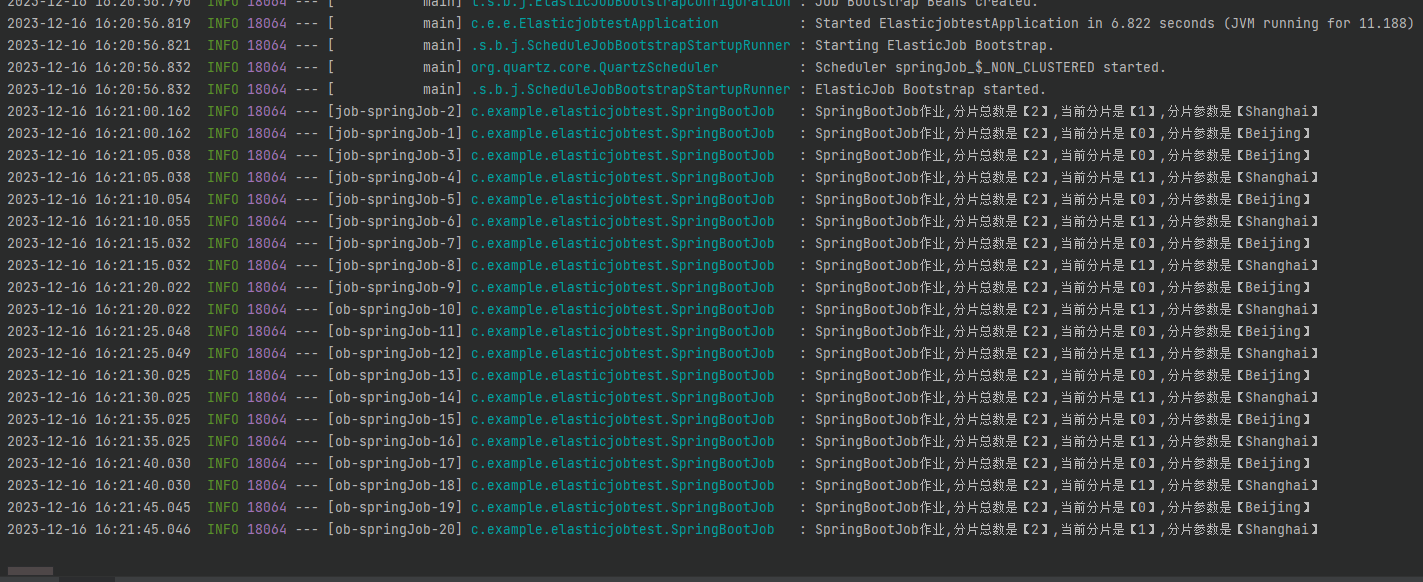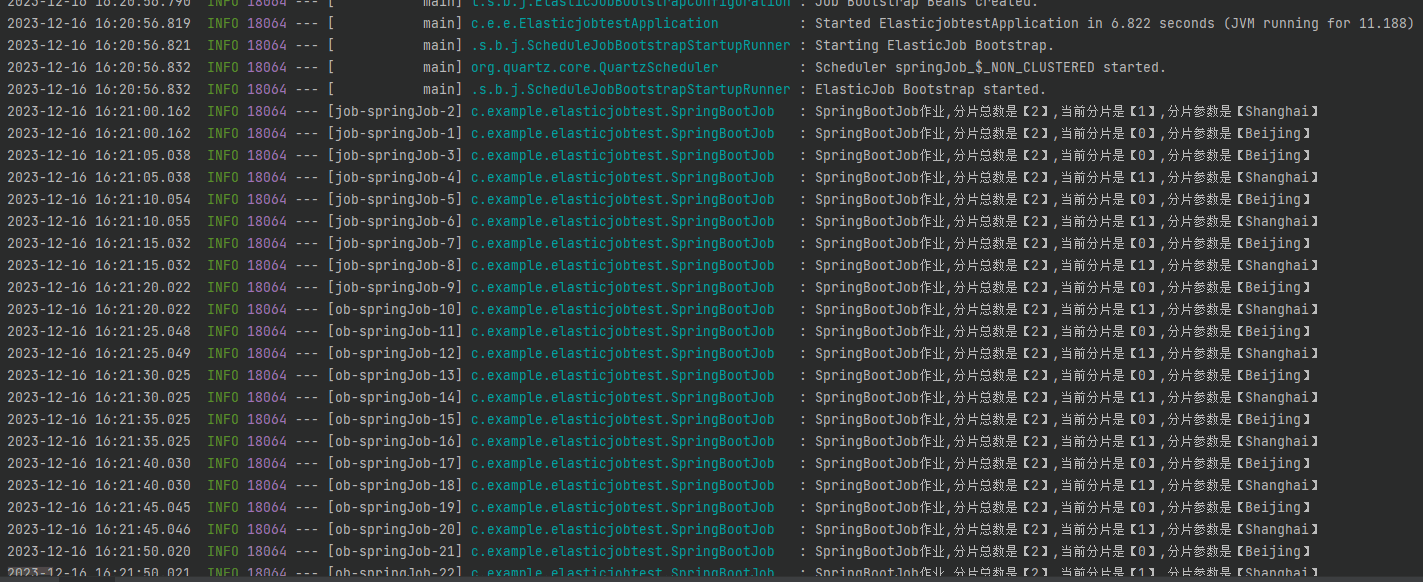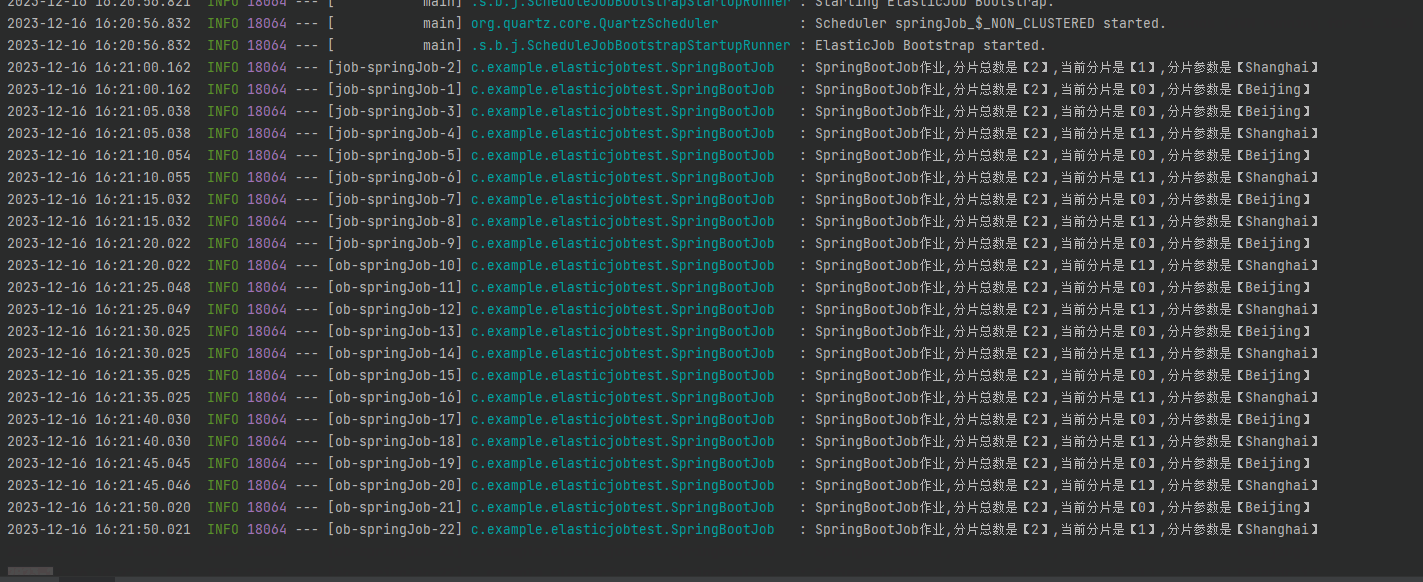
你會發現每隔 5s 就會輸出這樣的紀錄檔:
2023-12-16 16:31:45.020 SpringBootJob作業,分片總數是【2】,當前分片是【0】,分片引數是【Beijing】
2023-12-16 16:31:45.020 SpringBootJob作業,分片總數是【2】,當前分片是【1】,分片引數是【Shanghai】
怎麼樣,看到紀錄檔輸出之後是不是稍微品出了點淡淡的味道,就是那種雖然不知道怎麼回事,但是總感覺馬上就摸到門道的感覺。

保持住這種感覺,歪師傅馬上就讓你摸到門把手了。
為了模擬多個服務部署的情況,所以我們需要再多啟動一個服務。
在 Idea 裡面點選這個:
然後把「Allow multiple instances(執行多範例執行)」勾選上:
修改一下伺服器埠,避免埠衝突:
接著再次啟動 Demo,觀察一下紀錄檔:
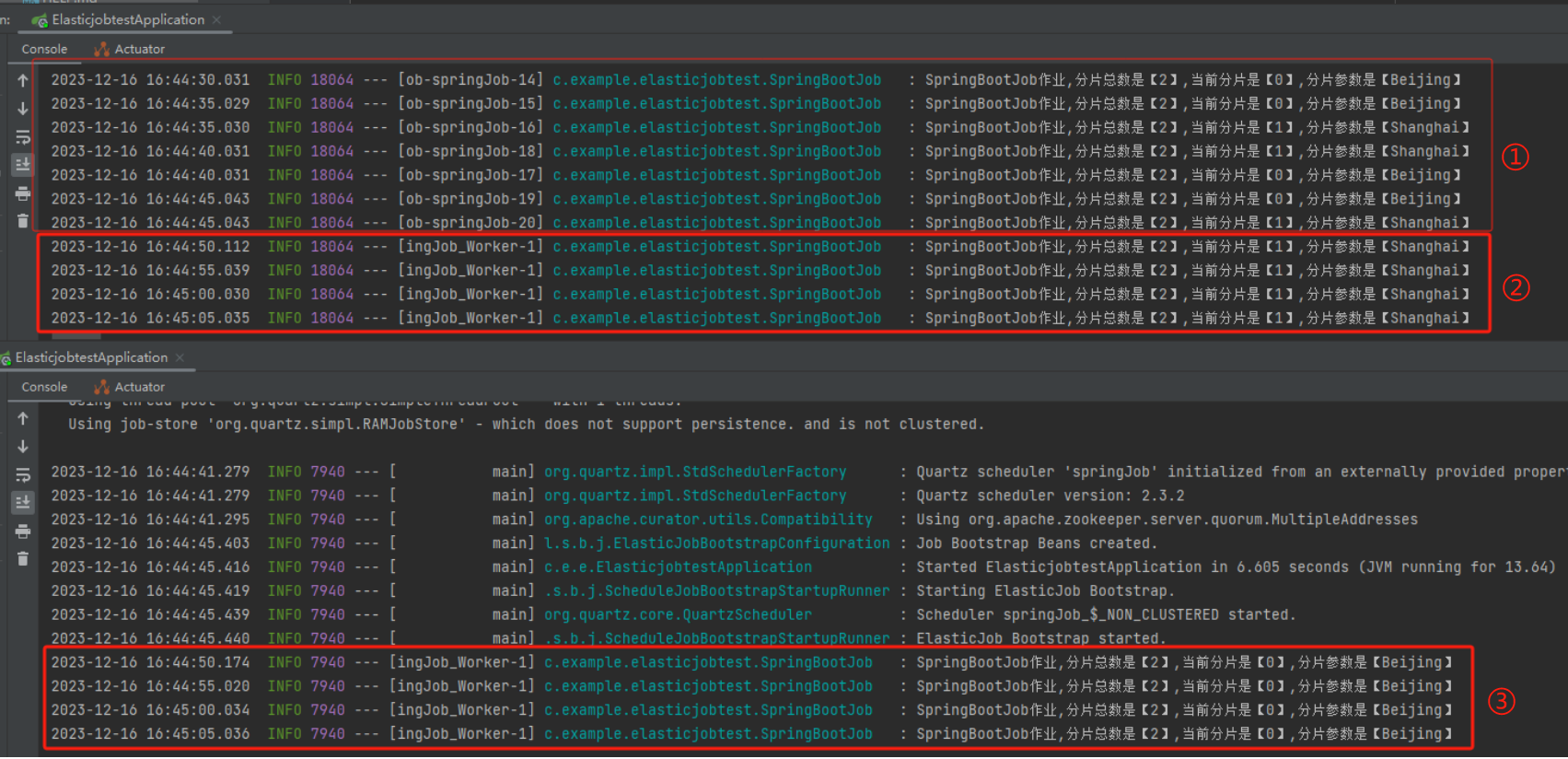
標號為 ① 的地方是僅一臺伺服器執行的情況,兩個分片都在這一個伺服器上執行。
標號為 ② 和 ③ 的地方是兩臺伺服器都執行起來的情況,同樣的程式碼、同樣的設定,跑在不同的埠而已。
一臺的紀錄檔輸出是這樣的:
SpringBootJob作業,分片總數是【2】,當前分片是【1】,分片引數是【Shanghai】
SpringBootJob作業,分片總數是【2】,當前分片是【1】,分片引數是【Shanghai】
另外一臺的紀錄檔輸出是這樣的:
SpringBootJob作業,分片總數是【2】,當前分片是【0】,分片引數是【Beijing】
SpringBootJob作業,分片總數是【2】,當前分片是【0】,分片引數是【Beijing】
可以看到,每隔五秒鐘兩臺伺服器都同時觸發了定時任務,但是一臺拿到的引數是 Shanghai,一臺拿到的引數是 Beijing。
這個時候我們再回去看面試官的這個問題:
假設有 100w 筆吧,如果只在一臺機器上跑,即使開啟多執行緒,也需要很長的時間,而且是一臺機器忙的不行,不太機器在旁邊閒的不行。如果我想要充分把機器利用起來,讓兩臺機器都來處理這 100w 筆訂單,各自處理 50w 條,時間不就縮短了嗎?
然後我再給你上個圖:
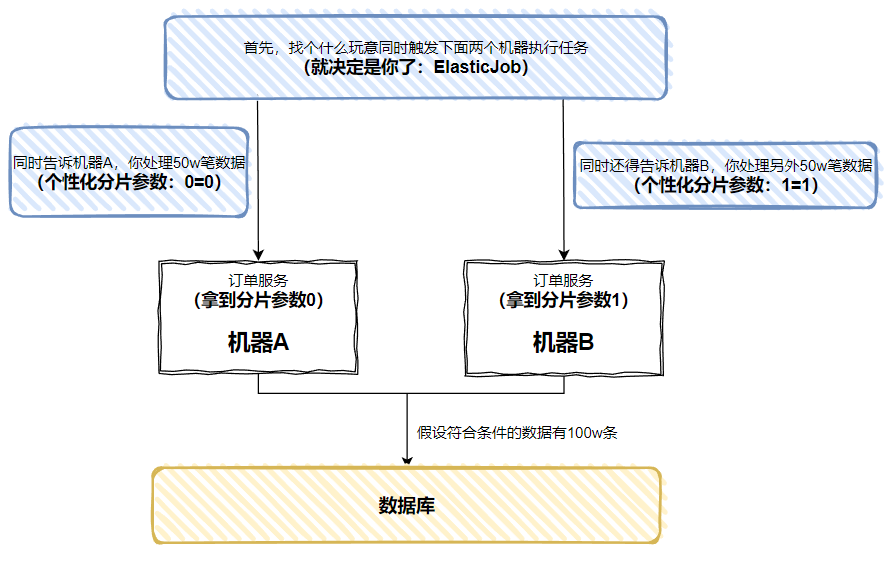
每個機器上執行的程式碼是一樣的,但是通過 ElasticJob 能讓每個機器在執行定時任務的時候,拿到不一樣的引數。
基於這個不一樣的引數,我們就能搞很多事情了嘛。
比如 100w 資料,分為兩組,一組 50w 條。假設 ID 是連續自增的,是不是可以這樣判斷奇偶數:
偶數:id % 2 == 0
奇數:id % 2 == 1
在這個表示式裡面,每個資料的 id 是確定的,而這個「2」,你看它像不像是我們的「分片數」?至於這個「0」和「1」,是不是可以通過我們的「個性化分片引數」傳遞進來?
id % 分片數 == 個性化分片引數
比如我們寫個這樣的程式碼:
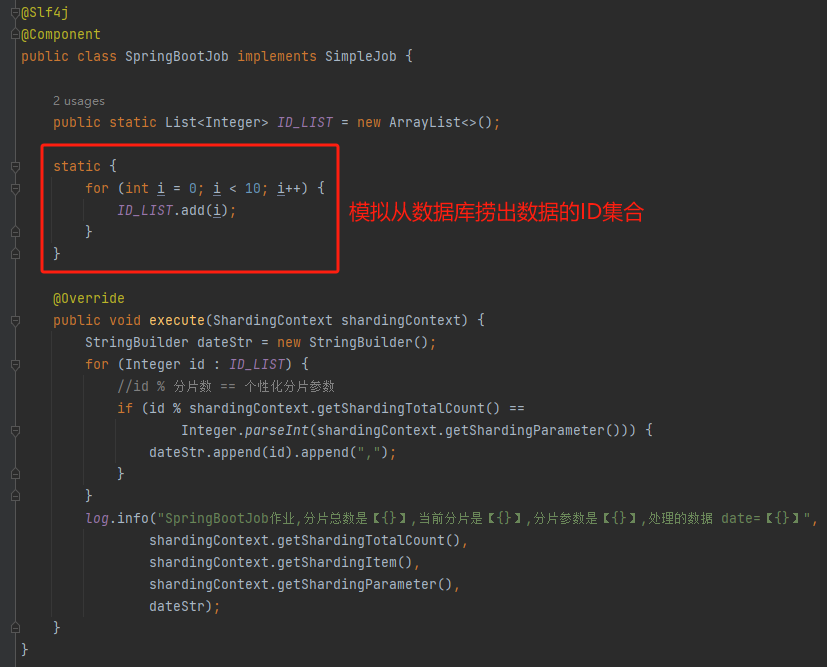
然後把作業設定改成這樣的:
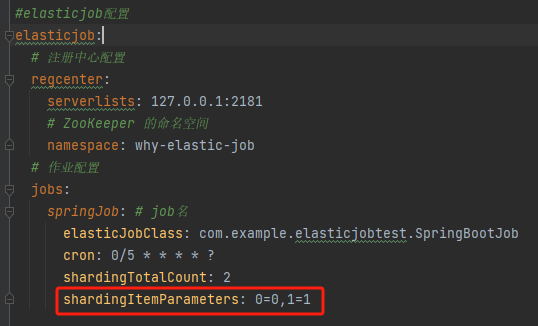
然後啟動兩個服務,我們觀察一下紀錄檔輸出:
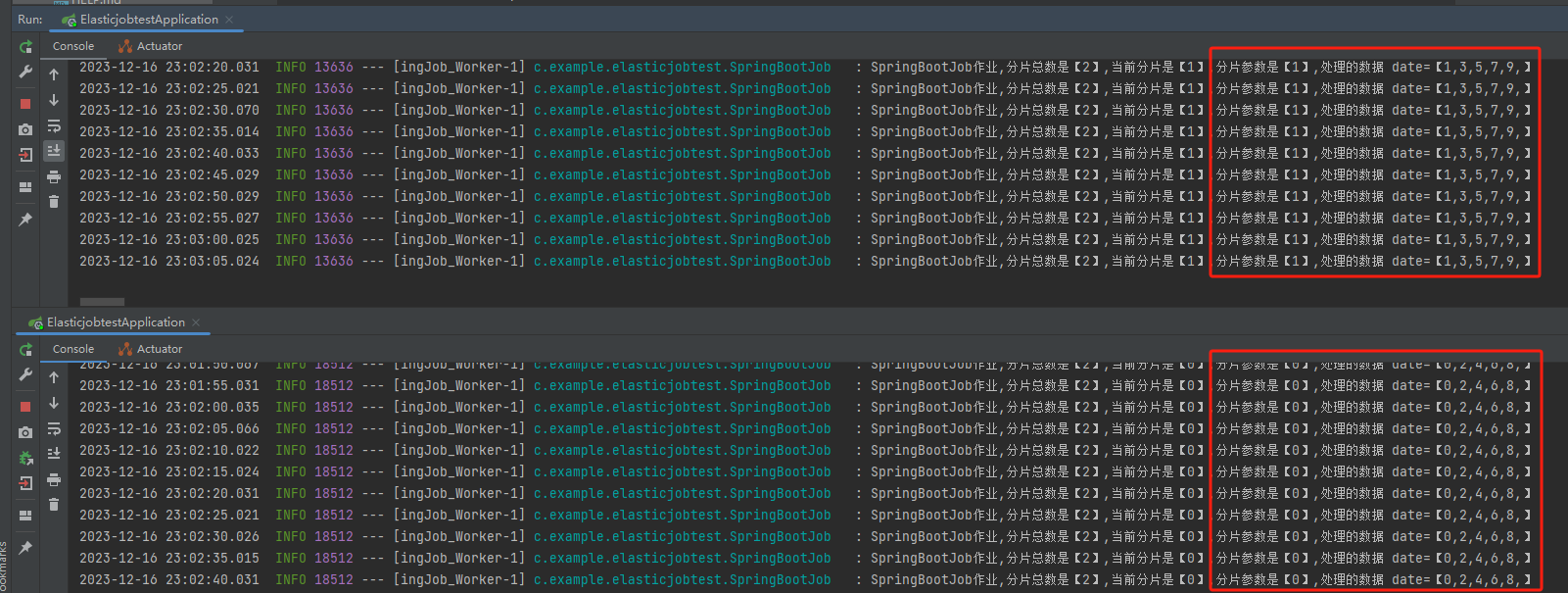
一臺機器處理的是 「1,3,5,7,9」,一臺機器處理的是「0,2,4,6,8」
剛剛面試官的問題是啥來著?
兩臺機器處理 100w 筆訂單,各自處理 50w 條?
這不就實現了嗎?

再給你看一個神奇的東西,假設我在執行時把 shardingTotalCount 修改為 3,即分片數變成 3,對應的自定義引數也進行對應的修改,會發生什麼事情呢?
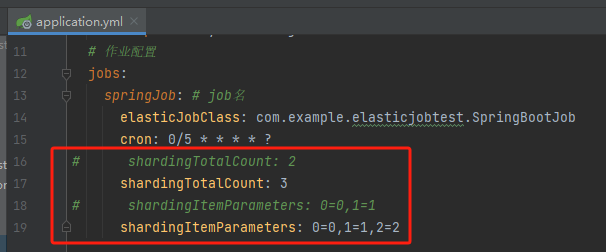
按照我們之前的這個邏輯:
id % 分片數 == 個性化分片引數
0 到 9 這十個數位分別對 3 取模,那麼就會分成下面這三組:
第一組:0,3,6,9 第二組:1,4,7 第三組:2,5,8
這個沒有任何毛病,對不對?
然後還需要特別注意的是,我說的是「在執行時」修改。
怎麼修改?
很簡單,ElasticJob 其實提供了對應的管理後臺頁面可以進行引數修改,但是我這裡偷個懶,難得去部署對應的管理後臺,,準備換個簡單的思路。
因為前面說了,ElasticJob 使用的是 zk 做為自己的註冊中心,我直接用工具連線上 zk,然後修改 zk 節點就行了。
我是怎麼知道修改 zk 的哪個節點的呢?
彆著急,等下就講,歪師傅先帶你看效果。
我這裡用的工具是 ZooInspector,修改之後直接點選儲存:
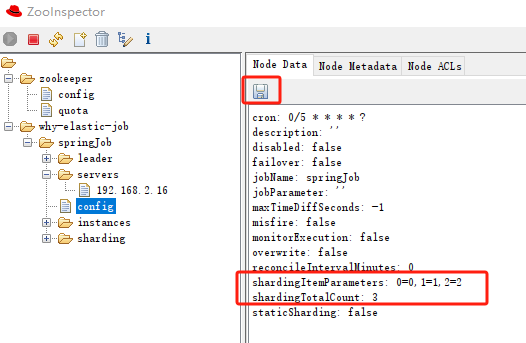
然後,朋友們,注意了,看紀錄檔輸出
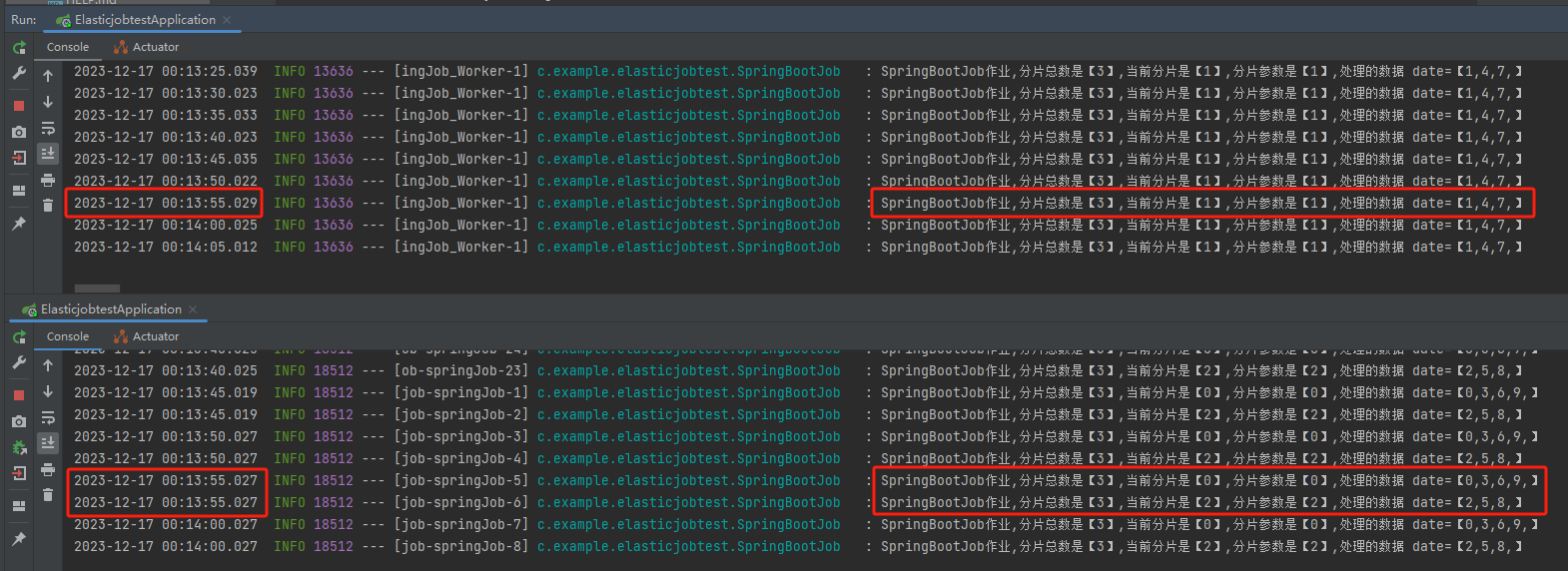
為了讓你看的更加清楚,我把關鍵紀錄檔單獨拿出來:
第一臺機器上的紀錄檔是這樣的:
分片總數是【3】,當前分片是【1】,分片引數是【1】,處理的資料 date=【1,4,7,】
第二臺機器上的紀錄檔是這樣的:
分片總數是【3】,當前分片是【0】,分片引數是【0】,處理的資料 date=【0,3,6,9,】
分片總數是【3】,當前分片是【2】,分片引數是【2】,處理的資料 date=【2,5,8,】
和我們前面推理的結果一模一樣。
好,到這裡就可以解答我的一個「按下不表」了。
首先,shardingTotalCount 叫做作業分片總數,在我前面的例子中,作業分片總數一共是 3 片:
第一組(第一片):0,3,6,9 第二組(第二片):1,4,7 第三組(第三片):2,5,8
分成三片之後,Elasticjob 怎麼知道每一片應該處理哪些資料呢?
它不知道,它也不用知道。它只需要告訴每一臺伺服器:「來,哥們,給你一個號你拿著。你們這波一共有多少多少個人,你是第幾片。」
就完事了。
因為「昨日成功的訂單」這個總的要處理的資料是不變的,所有每一臺伺服器知道一共要把這批資料分成幾片,自己是第幾片後,通過程式碼就能拿到對應的該處理的資料。
然後你再去看官方描述中關於「分片項」你大概就能知道這到底是個啥玩意了:

有的哥們比較猛,一次拿到兩個號,也沒關係,就是多處理一份資料嘛。這種情況就適用於兩臺機器的效能不一致的情況。
但是我用這個案例並不是為了引出「效能不一致」這種極少數的情況,而是為了這個...
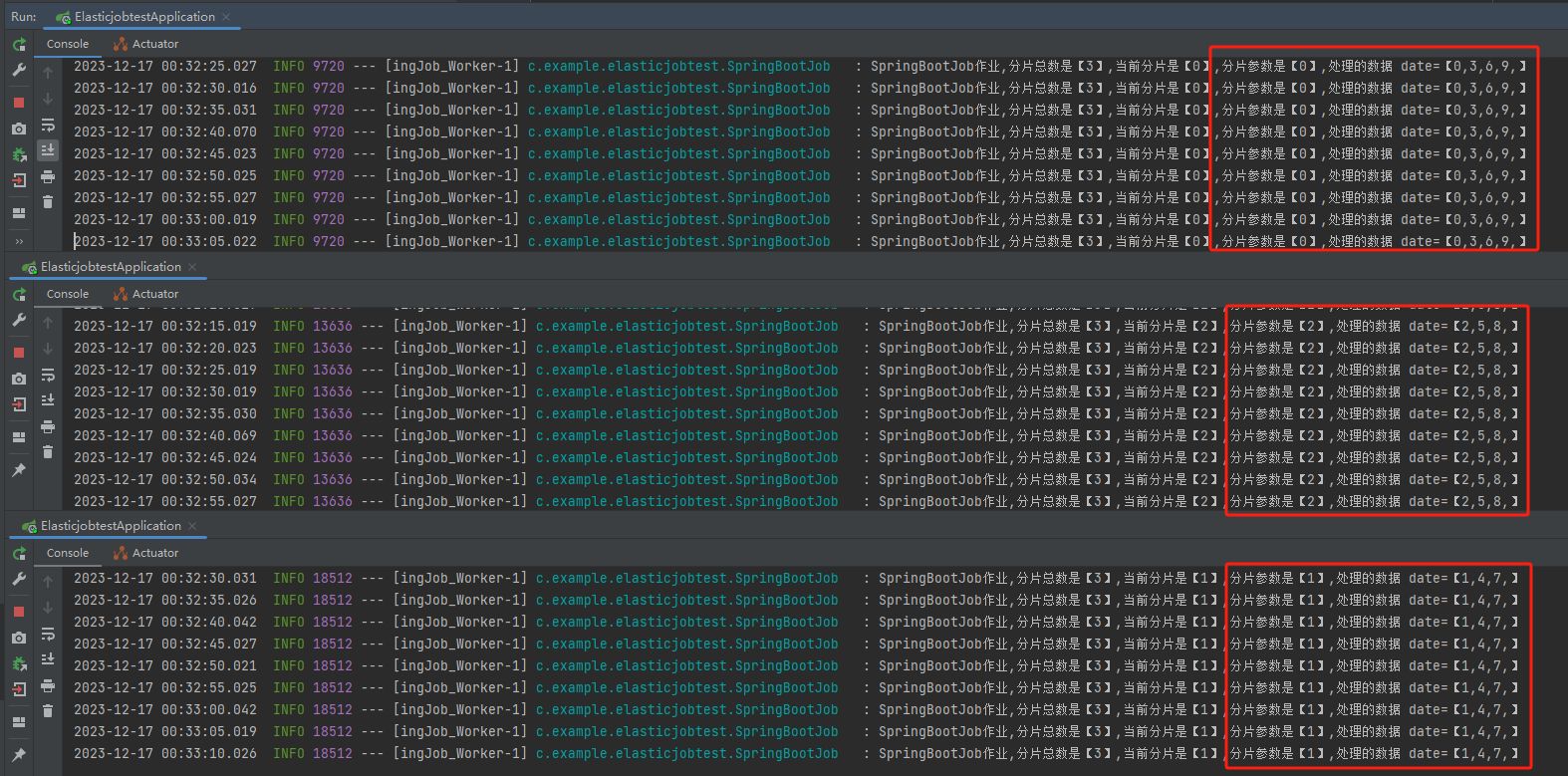
當我再啟動一個新的伺服器,當第三臺伺服器加入之後,我們啥也沒幹,它自己就開始處理任務了。
3 個分片,一臺伺服器處理一個分片的資料。
能自動加入,就能自動退出,所以假設我把一臺服務給關閉了:
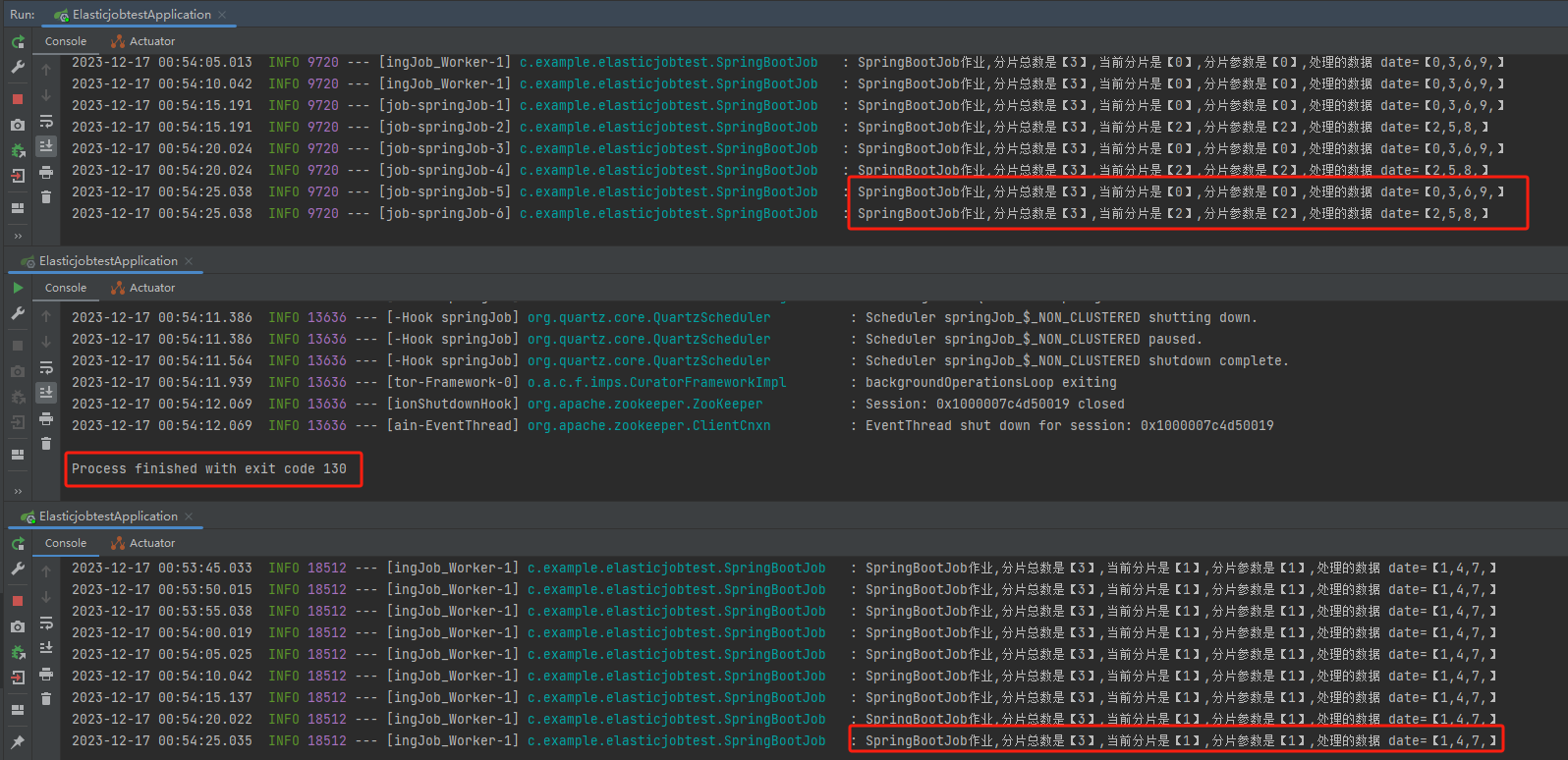
從紀錄檔可以看出來,資料並沒有丟。
第一臺機器把本來該在下線的這臺伺服器上處理的資料給接管了:
分片總數是【3】,當前分片是【2】,分片引數是【2】,處理的資料 date=【2,5,8,】
分片總數是【3】,當前分片是【0】,分片引數是【0】,處理的資料 date=【0,3,6,9,】
好了,到這裡,基本功能就算演示完成,可以適當的響起一些掌聲了。

啥原理啊?
其實關於原理,官方檔案上也按照步驟進行了比較詳細的說明:
https://shardingsphere.apache.org/elasticjob/current/cn/features/elastic/
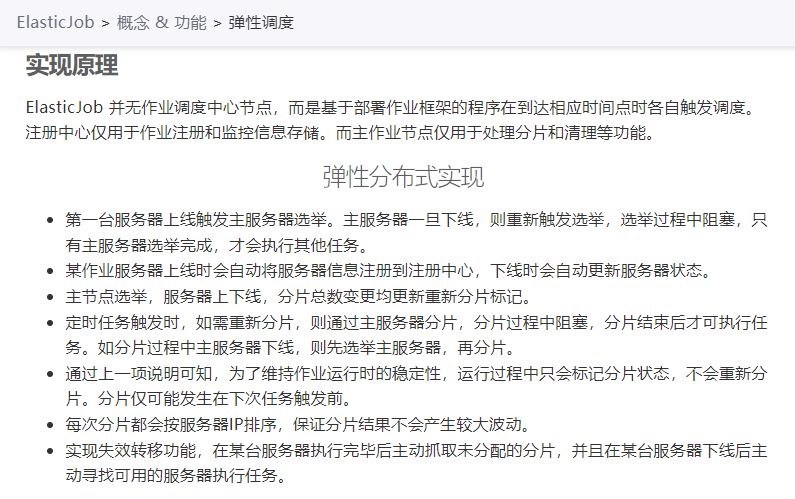
如果你不瞭解 zk 的大致工作原理、節點特性、監聽機制啥的,後面肯定會看得比較懵逼。
所以需要先去補一下這方面的資訊,對於這部分的描述和原始碼的解讀有很大幫助。
如果你能大致理解 zk 的工作原理,那麼整體讀下來其實沒有什麼特別難以理解的地方,如果要深入理解每一個步驟的話,那肯定要讀一下原始碼的。
步驟都有了,去找對應的原始碼,不就是按圖索驥,手拿把掐的事情嗎。
在閱讀原始碼之前,還有一個非常重要的東西要鋪墊一下,前面也說了:基於 zk 做的註冊中心。
所以你必須要了解「註冊中心的資料結構」是怎麼樣的,每個節點是幹啥的,才能理解程式碼裡面操作 zk 節點的時候,到底是什麼含義。
關於註冊中心的資料結構,檔案上也有介紹:
我覺得這個還是非常重要的,所以我多囉嗦幾句,主要給你看看實際的資料是怎麼樣的。
還是以我本地啟動三個服務為例。
啟動起來之後,看 zk 上註冊了這些節點:
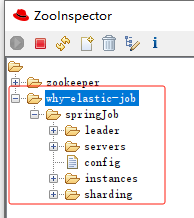
其中「why-elastic-job」和「springJob」分別是我們寫在 application.yml 裡面的 ZooKeeper 的名稱空間和 Job 名稱:
config 節點
config 節點裡面是作業設定資訊,以 YAML 格式儲存:
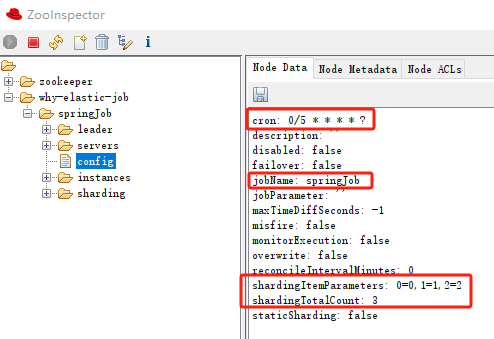
可以看到節點裡面實際的值比我們設定的多,因為有很多預設項。每個預設項是幹啥的,就自己去研究吧。
前面我說的「執行時修改」,就修改的是這個地方資訊。
我為什麼知道改這裡?
還不是官網告訴我的。
instances 節點
該節點是作業執行範例資訊,子節點是當前作業執行範例的主鍵。
作業執行範例主鍵由作業執行伺服器的 IP 地址和 PID 構成。
作業執行範例主鍵均為臨時節點,當作業範例上線時註冊,下線時自動清理。註冊中心可以監控這些節點的變化,來協調分散式作業的分片以及高可用。
具體到我們這個案例中,是這樣的:
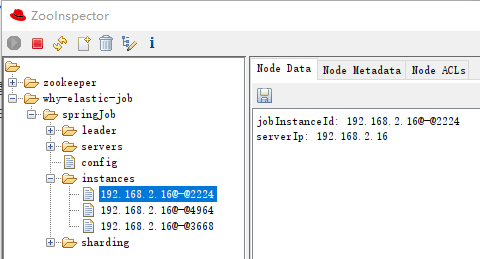
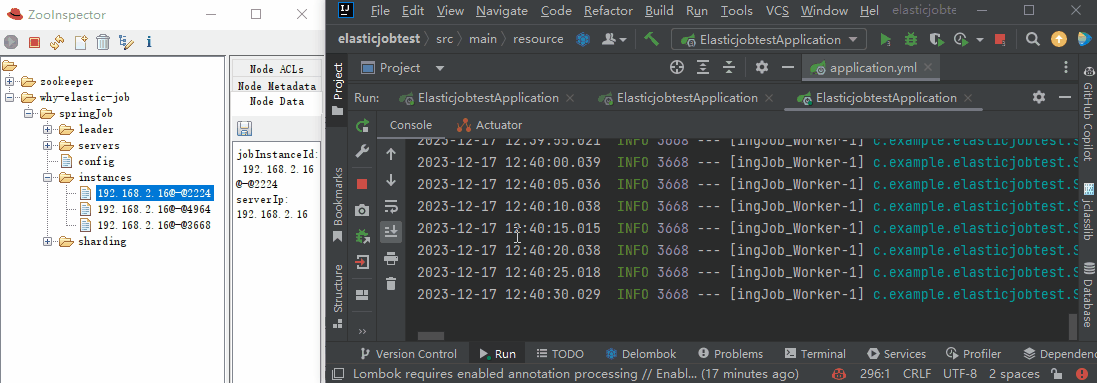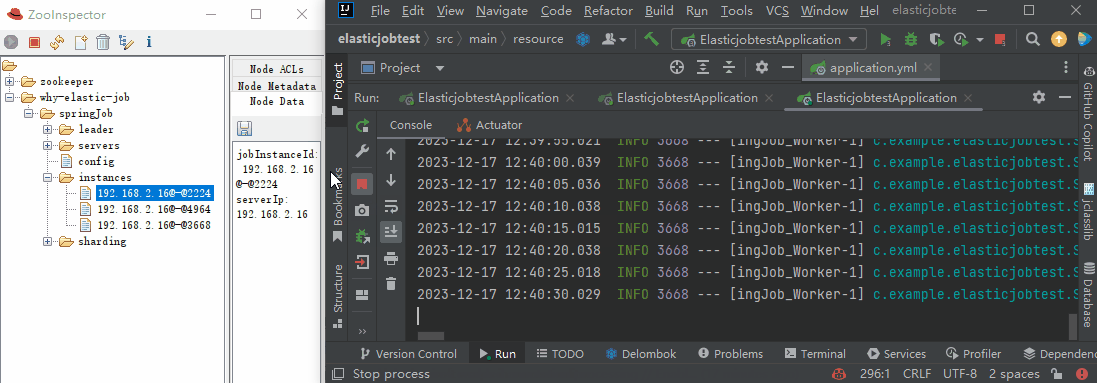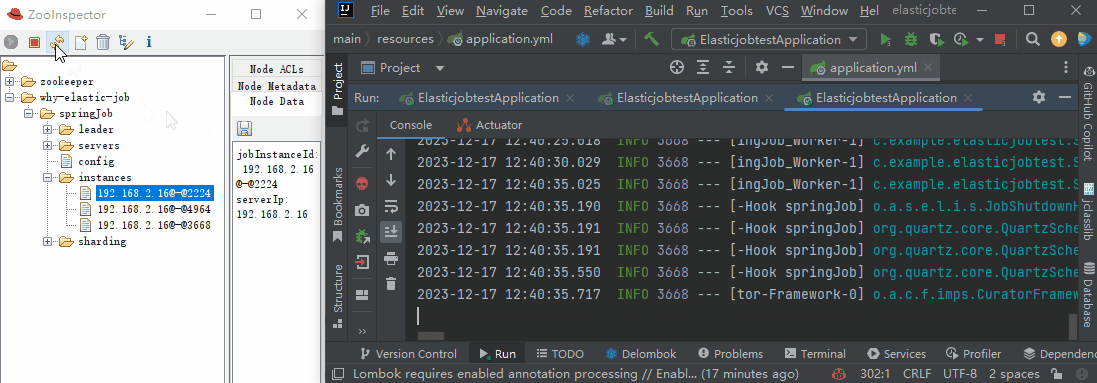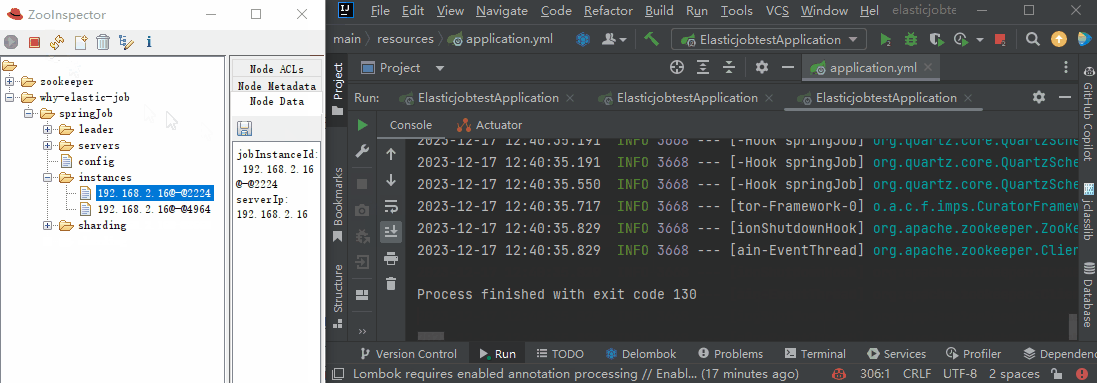
instances 下面有三個子節點,代表有三個微服務。
假設我停止執行一個服務,由於是 zk 的臨時節點,這個地方就會變成 2 個:
sharding 節點
作業分片資訊,子節點是分片項序號,從零開始,至分片總數減一。比如我們這裡就是 0 到 2:
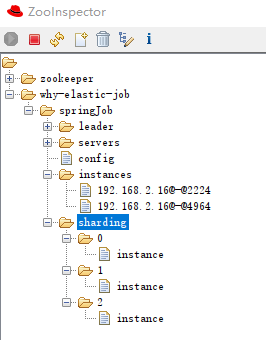
分片項序號的子節點儲存詳細資訊,每個分片項下的子節點用於控制和記錄分片執行狀態:
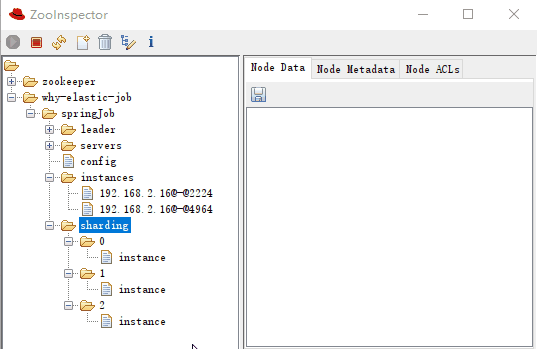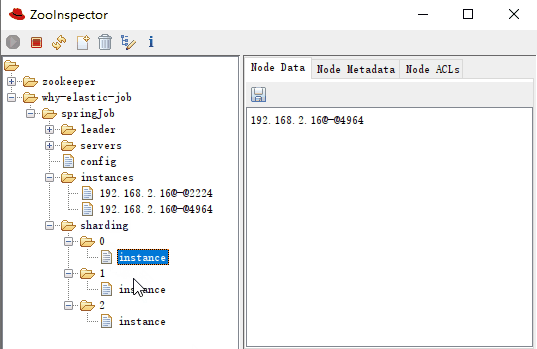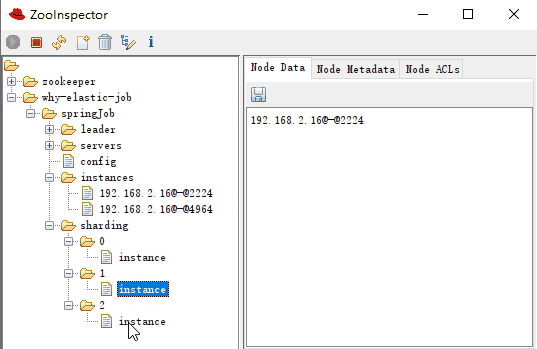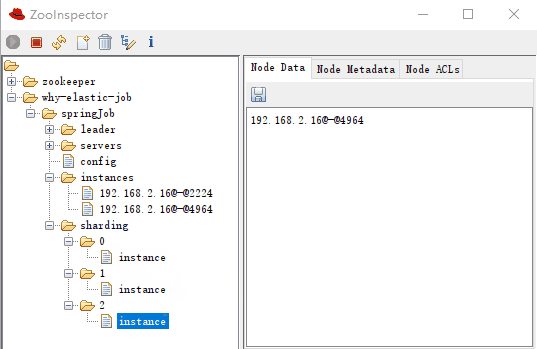
sharding-0-instance:192.168.2.16@-@4964 sharding-1-instance:192.168.2.16@-@2224 sharding-2-instance:192.168.2.16@-@4964
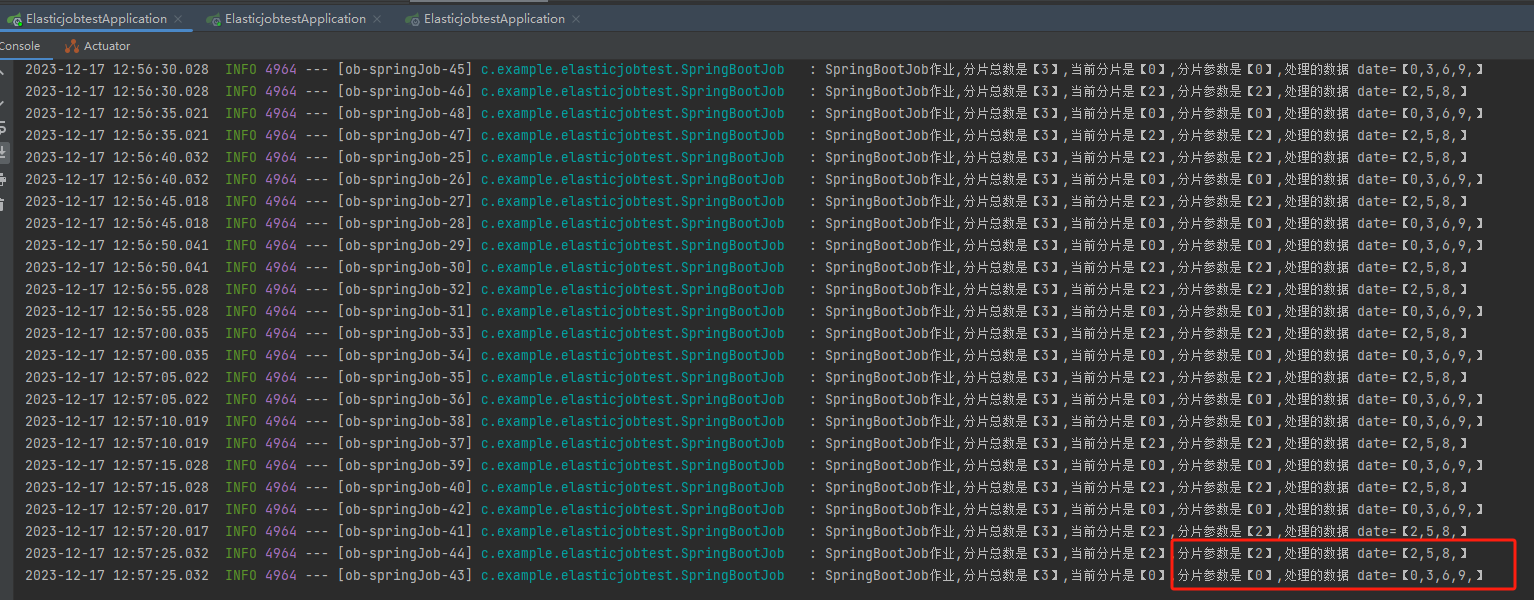
可以看到 0,2 分片是執行在同一個 instance 上的,這一點和紀錄檔是匹配的:
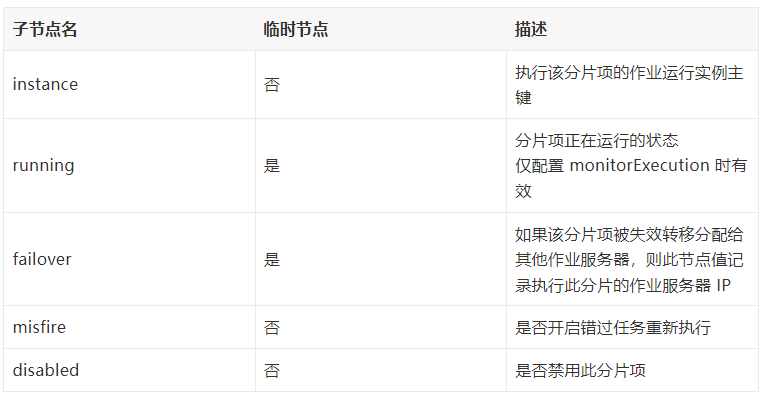
sharding 下除了 instance 節點外,可能還有其他的節點,詳細資訊說明如下:
servers 節點
作業伺服器資訊,子節點是作業伺服器的 IP 地址。
可在 IP 地址節點寫入 DISABLED 表示該伺服器禁用。
在新的雲原生架構下,servers 節點大幅弱化,僅包含控制伺服器是否可以禁用這一功能。
為了更加純粹的實現作業核心,servers 功能未來可能刪除,控制伺服器是否禁用的能力應該下放至自動化部署系統。
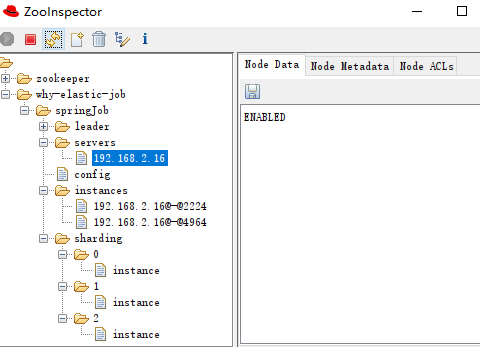
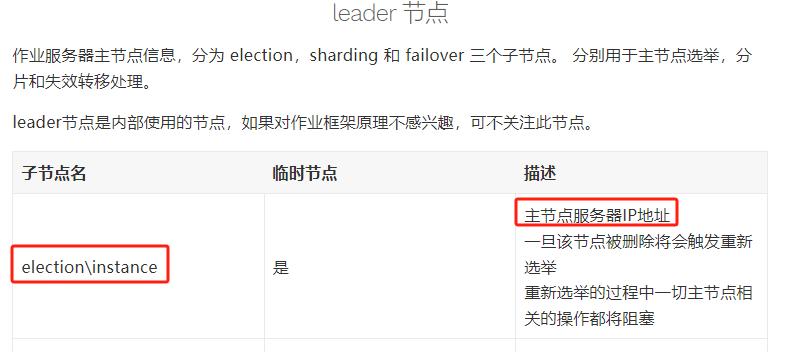
leader 節點
作業伺服器主節點資訊,下面有三個子節點:
election:用於主節點選舉 sharding:用於分片 failover:用於失效轉移處理
除了節點介紹外,在官網描述上有這樣的一句話:
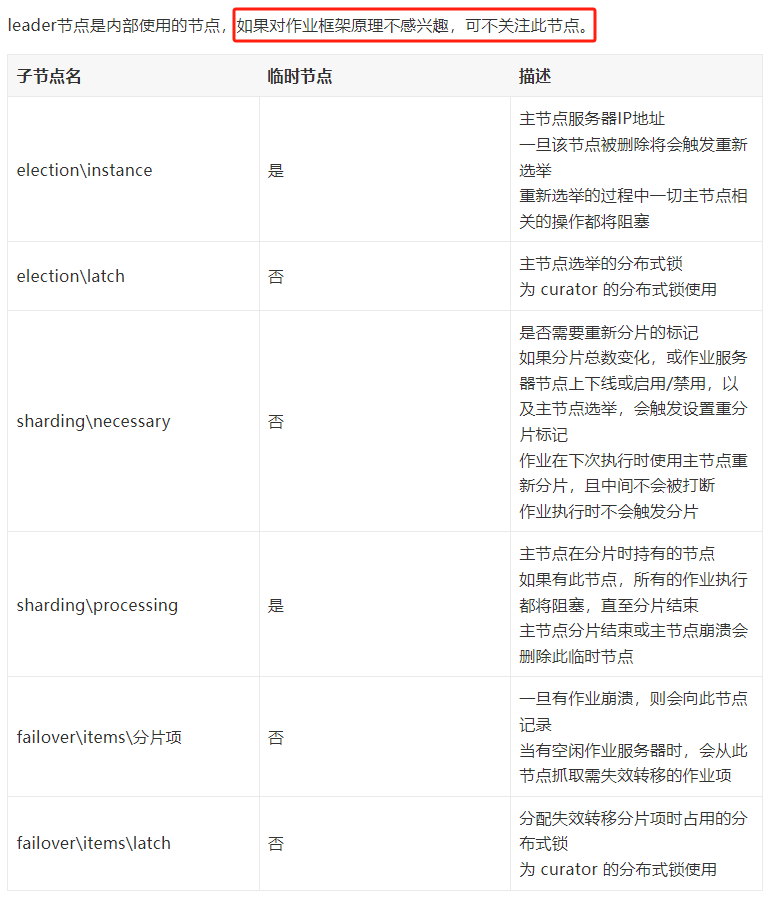
換句話說就是,如果你想了解作業,那這個節點是很重要的。看原始碼的時候,需要特別關注對於 leader 節點下的操作。
在我們的案例中,instance 裡面的資訊是這樣的:
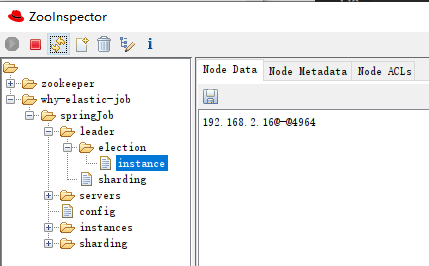
表示這個節點是主節點。
原始碼
知道了 zk 上每個節點的用處,看原始碼的時候比著看就行了。
原始碼比較多,歪師傅這裡只能帶著你做個非常簡單的導讀。
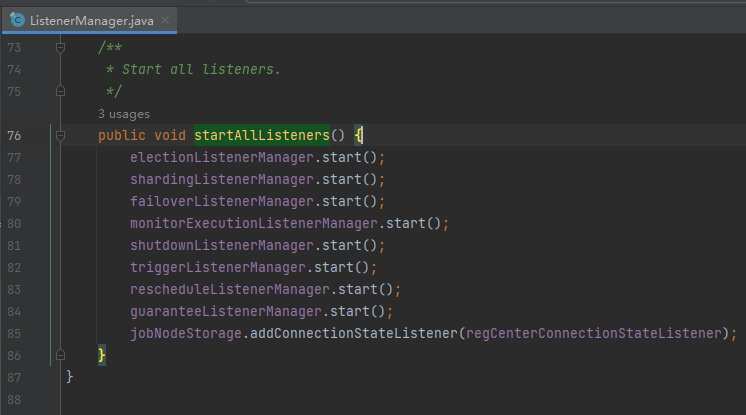
首先,因為很多邏輯都是基於 zk 節點在來做的,所以最重要的是各種各樣的 zk 節點監聽器,ElasticJob 在啟動時,會執行這個方法,開啟監聽器:
org.apache.shardingsphere.elasticjob.kernel.internal.listener.ListenerManager#startAllListeners
比如前面說的這個節點:
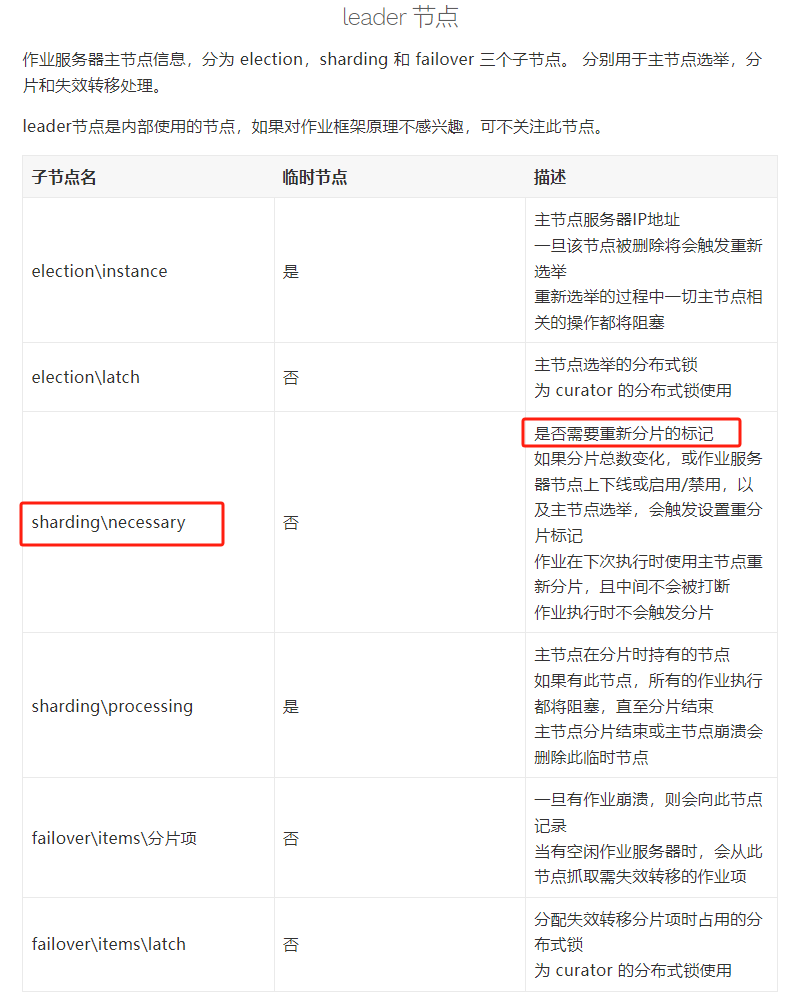
如果這個節點存在,則說明需要重新分片,對應的監聽器是這個:
shardingListenerManager.start();
那麼什麼時候會觸發「重新分片」呢?
如果分片總數變化,或作業伺服器節點上下線或啟用/禁用,以及主節點選舉,會觸發設定重分片標記 作業在下次執行時使用主節點重新分片,且中間不會被打斷作業執行時不會觸發分片
所以在 shardingListenerManager 監聽器裡面我們可以看到這兩個邏輯:
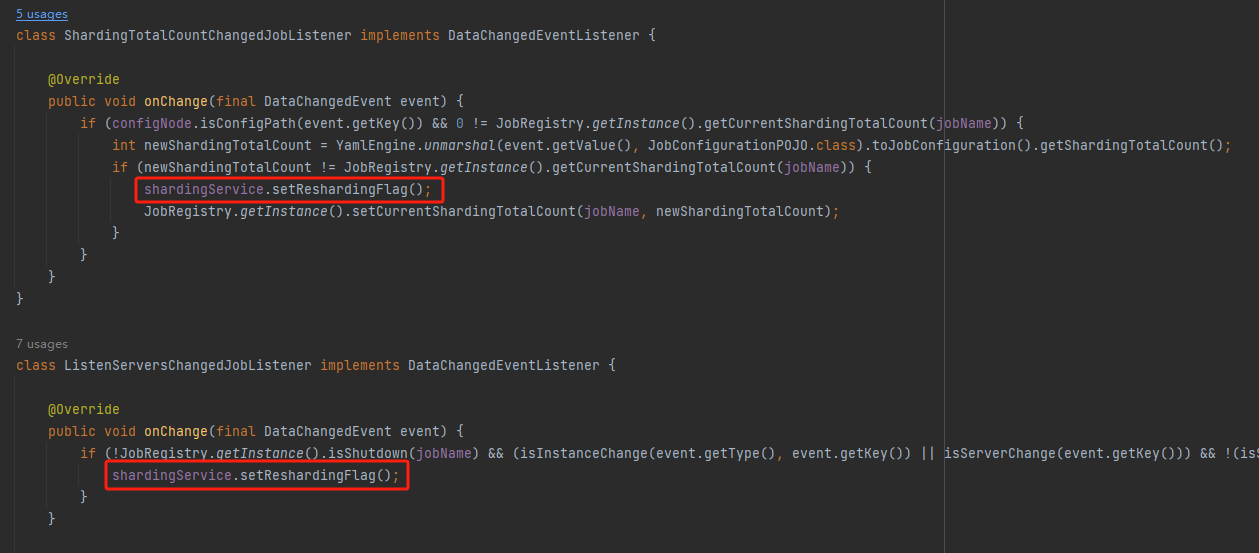
滿足條件之後,就會執行設定重新分片標識的程式碼:
shardingService.setReshardingFlag();
該方法裡面,建立了一個新的節點:
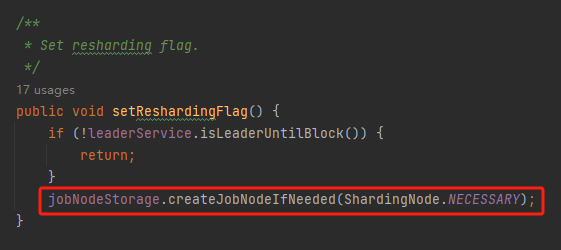
這個節點,就是它:
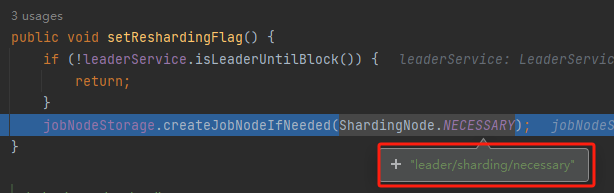
再比如,看看這個方法:
org.apache.shardingsphere.elasticjob.lite.internal.sharding.ShardingService#shardingIfNecessary
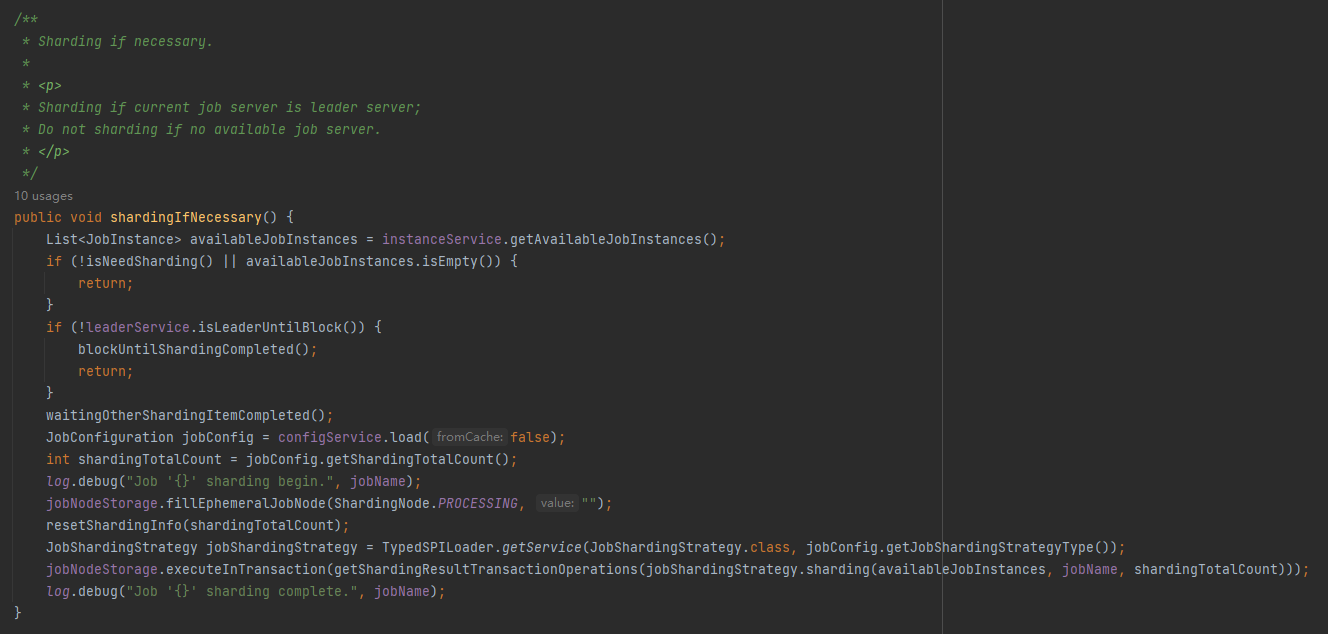
這個方法是做對作業進行分片邏輯的。
對作業進行分片,首先我們要知道當前有哪些範例在執行,對不對?
那怎麼才能知道呢?
instances 節點請求出戰:

shardingIfNecessary 方法的第一行邏輯就是讀取 instances 節點下的資料:
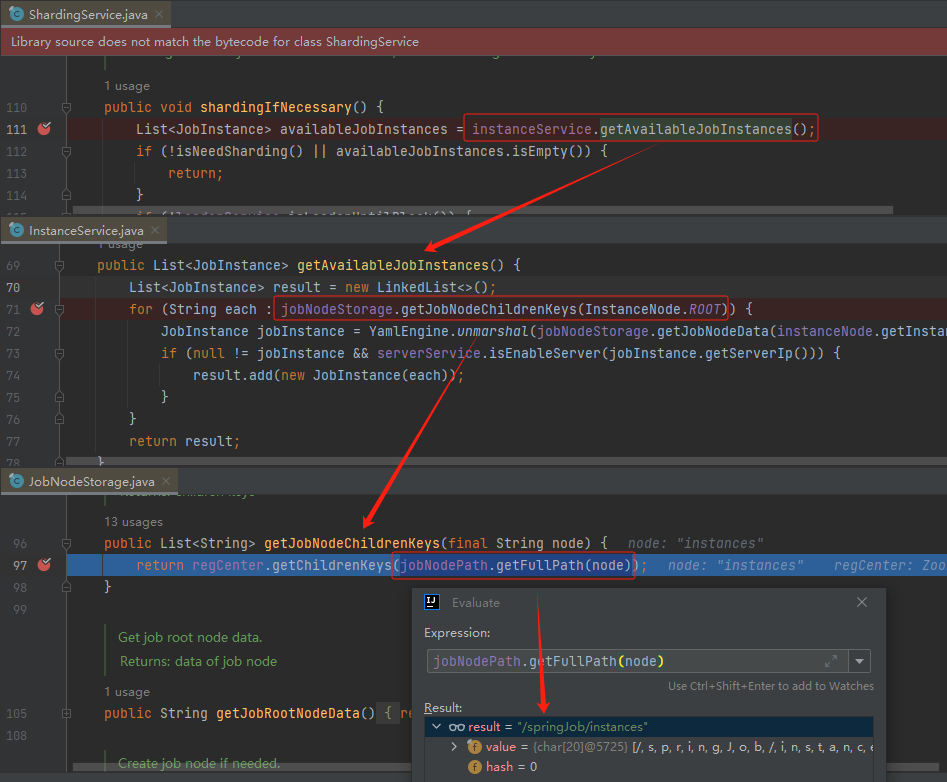
獲取到節點之後,是不是就可以分片了?
理論上是這樣的,但是彆著急,你看原始碼裡面還有這樣一個判斷:
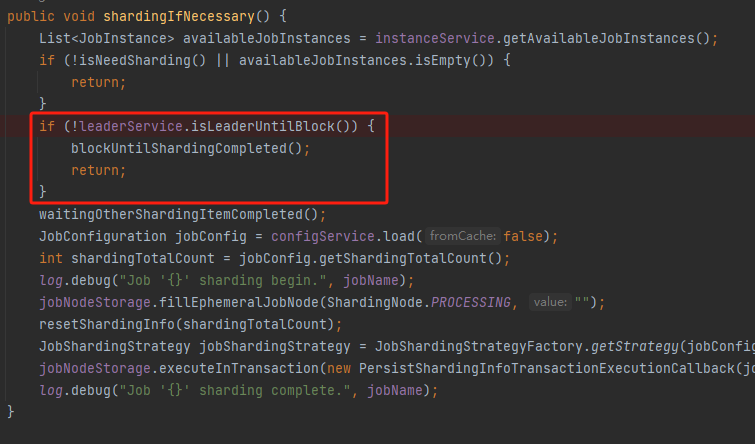
isLeaderUntilBlock,看方法名稱也知道了,看看 Leader 節點是不是到位了,如果沒到位,需要等一下 Leader 選舉結束。
怎麼判斷 Leader 節點是不是到位了?
前面檔案中說了,就是看這個節點是否存在:

對應到原始碼就是這樣的:
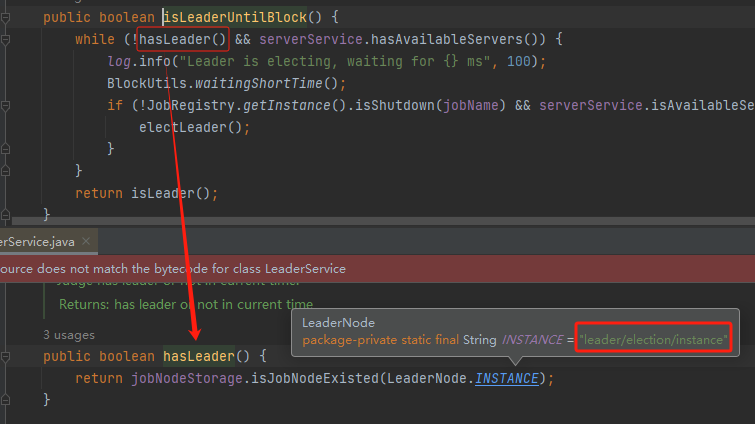
所以這就是我前面說的,你看原始碼的時候得結合 zk 節點的用途一起看,知道節點的用途就能理解原始碼裡面操作節點的目的是什麼。
然後,在這裡多說一句。
shardingIfNecessary 這個方法是讀取設定,處理分片邏輯的。
但是這個方法在每一個範例中都會執行,豈不是每個範例都會執行一次分片邏輯?
這樣處理的話,由於多個地方執行分片邏輯,就需要考慮衝突和一致性的問題,導致邏輯非常的複雜。
雖然這個方法每個範例都會執行,但是其實只需要有一個範例執行分片邏輯就行了。
那麼哪個節點來執行呢?
你肯定也猜到了,當然是主節點來幹這個事兒嘛。如果當前節點不是主節點 return 就完事了:
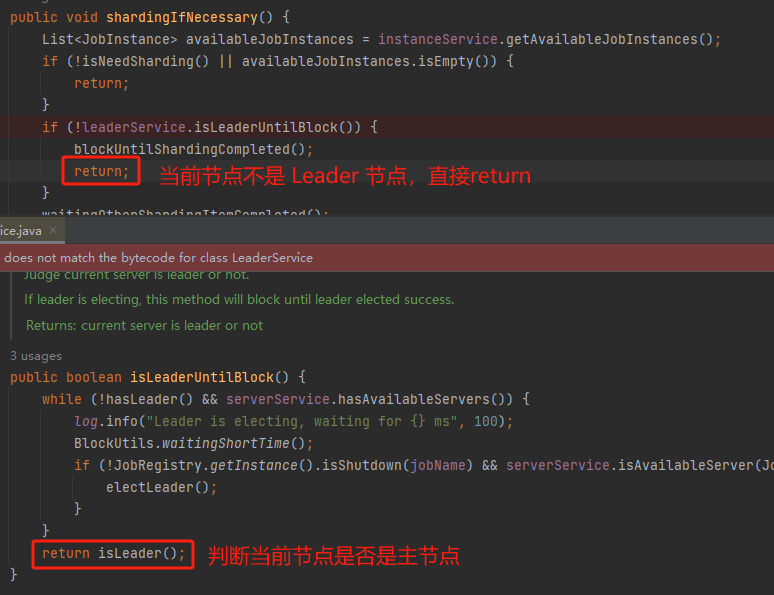
怎麼看當前節點是否是主節點呢?
前面已經出現多次了,zk 裡面記錄著的:
如果當然節點是主節點,就接著往下執行,就是「作業分片策略」了:
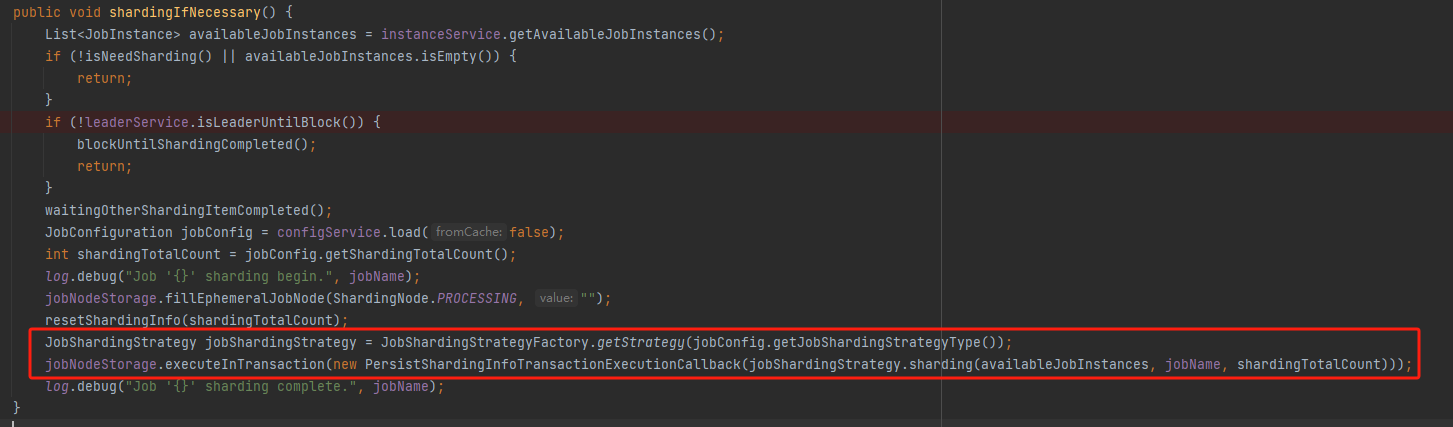
目前官方提供了三個不同的分片策略:

對應的實現類是這樣的:

邏輯都非常簡單,上手 Debug 兩次就能摸清楚。
建議直接把專案拉下來,然後從測試用例入手。
好了,原始碼導讀就到這裡了。
我覺得我已經算是告訴你關於 ElasticJob 原始碼閱讀的方式和注意點,如果你掌握到了,留言區留言「清晰」二字,支援一波。
如果你還是雲裡霧裡的,沒事,是我的問題。大膽的說出來:什麼玩意?看求不懂。呸,垃圾作者。
如果你是第一次接觸到 ElasticJob,那麼讀到這裡的時候,你的內心關於 ElasticJob 應該還有很多疑問以及不清楚的細節。
很好,帶著你的問題,去翻原始碼吧。
原始碼之下無祕密。
下面這個環節叫做[荒腔走板],技術文章後面我偶爾會記錄、分享點生活相關的事情,和技術毫無關係。我知道看起來很突兀,但是我喜歡,因為這是一個普通博主的生活氣息。
荒腔走板

這周終於是把《長安三萬裡》看了,之前一直想看,但是又被三個小時的時長勸退。
我個人覺得確實是值得豆瓣高分的。
看完之後,包括看的過程中,我老是想起之前在網上看到的一段話,關於「一顆子彈」和「教育閉環」的。
「一顆子彈」是指在《我與地壇》看到的一段書評,其內容是:一個人十三四歲的夏天,在路上撿到一支真槍,因為年少無知,天不怕地不怕,他扣下扳機。沒有人死,也沒有人受傷,他認為自己開了空槍。後來他三十歲或者更老,走在路上聽到背後隱隱約約的風聲。他停下來回過身去,子彈正中眉心。
「教育閉環」是指教育具有長期性和滯後性,起初你只能理解表層的道理,直到多年後的某個瞬間,你才能真正領悟到書上知識的真諦,此時教育的任務才算真正完成。
我小時候讀到「兩岸猿聲啼不住,輕舟已過萬重山」的時候,重點總是在「兩岸猿聲」上,想象著猿猴的叫聲是什麼樣的,那是一番怎樣有趣的畫面。
後來,甚至可以說是今年,這個電影上映之後,我才明白當年讀書的時候我忽略的「輕舟已過萬重山」背後才是有更加蜿蜒曲折、激動人心的故事。
這句詩就是當年的那一顆子彈,命中了馬上三十歲的我,至此,教育才算完成了閉環。
今年,讓我產生同樣感受的,還有當年完全忽略的這句話:孔乙己是站著喝酒而穿長衫的唯一的人穿的雖然是長衫,可是又髒又破似平十多年沒有補,也沒有洗。他對人說話,總是滿口之乎者也叫人半懂不懂的。
此外,電影中多次提到「長安」,雖然我們學的是同樣的課本,讀的是一樣的詩,但是每個人對與「長安」的認知和理解是不一樣的。
現在提到長安,我腦海中出現的第一個畫面永遠是當年看《河西走廊》紀錄片的時候那一個畫面。
第一集《使者》,張騫出使西域,被匈奴囚禁九年後同隨從堂邑父出逃,繼續西行。
靠強大意志力穿越塔克拉瑪干沙漠和帕米爾高原,到達西域。回程再次被俘,數年後帶匈奴妻子和堂邑父又一次出逃東歸。
十三年後,終於再次望到長安城,張騫匍匐在地,長跪不起。
西北望長安,可憐無數山。
這一跪,看的我眼淚婆娑。