如何快速優化幾千萬資料量的訂單表
前言
為了保證有一個更健康的身體,所以慢慢降低了更新頻率,在有了更多休息時間的前提下,思考了一下接下來準備分享的一些內容。
決定在更新一些技術乾貨的同時,會穿插一些架構知識,放在單獨的專欄裡面,希望大家能喜歡,裡面包含了這些年工作中遇到的一些內容,以及自己充電後總結的一些知識,希望大家會喜歡。
標題做了較為詳細的劃分,大家不必一次看完,以免視覺疲勞。
場景
本篇分享以前在廣州一家網際網路公司工作時遇到的狀況及解決方案,這家公司有一個專案是SOA的架構,這個架構那幾年是很流行的,哪怕是現在我依然認為這個理念在當時比較先進。
我在這家公司待的時間不長,但因為平臺不錯,確實學習和實踐了一點東西,所以整理一下分享給大家。
當時的專案背景大概是這樣,這家公司用的是某軟提供的方案(這公司賊喜歡提供方案且要錢多,忍不住吐槽哈),專案已經執行3年多,整體穩定。
資料庫是MySQL,訂單表的資料量已經達到3000多萬條記錄,並且隨著專案的推廣,最近那一年訂單表資料量也在快速增長。
結果就是,客戶方查詢訂單相關的業務時速度越來越慢,後期不論開啟還是重新整理都差不多要七八秒。
可以說已經嚴重影響了客戶體驗,降低了對方日常辦事的效率,要求我們儘快解決,且敦促我們這是一件優先順序非常高的事情。
在客戶和公司領導的雙重壓力下,如何快速優化幾千萬資料的訂單表,對於當時的團隊著實是一個難題擺在面前。
我依稀記得自己當時還比較青澀,更多的是一個聽眾,不敢參與深入討論哈哈。
整體方案
首先常規方案能想到的無非是這些:增加合理的資料庫索引、優化核心SQL語句、優化程式碼等。
我這裡可以告訴大家,一般的IT公司,但凡團隊Leader是個有經驗的人,這些基礎方案都是會提前做的,會對專案上線後可能遇到的瓶頸有個基本的評估,因為真正運營週期變長以後,資料量逐漸增多,修改生產庫是一種風險操作。
我不知道大家有沒有過給某個生產庫資料量比較大的表新增欄位或索引的經歷,而且是在白天上班操作,或者說你自己見過別人這麼幹,我只能說……這些都是狠人,要對其常懷敬畏之心。
我目前所在的公司就比較規範,研發人員建表時一定要提交申請走流程,且附帶合理的索引,一起提交稽核,最終通過了才能由主管稽核執行。
至於這種流程怎麼走,其實工具挺多,我這裡就提一個用過的開源專案:Yearning,大家可以自己去了解下。
話題扯回來,正因前面所講,在當前的問題下,這些基礎方案實際上已經存在,在這裡顯然是用不上了,加上緊急問題緊急處理,沒有那麼多時間給你去對既有架構大動干戈。
因此,當時立馬能想到且有效的臨時性方案迅速在團隊討論中率先冒出來,就是資料庫分割區。
1、資料庫分割區
理解資料庫分割區,只需要記住以下兩點:
- 資料庫分割區是把一張表的資料
分在了不同的硬碟上,但仍是一張表,說硬碟可能不完全準確,但就這樣理解是最容易的。 - 不要把資料庫分割區和分庫分表混淆,一個是
資料庫級別的操作,一個是代理工具的操作,前者限制較多,後者更靈活。
知道這兩點其實就足夠了,資料庫分割區和分庫分表也是面試中喜歡問的,因為確實有一些類似的地方。
好了,有了基本認識,那接下來就說下資料庫分割區如何操作的,先看個圖有個畫面。
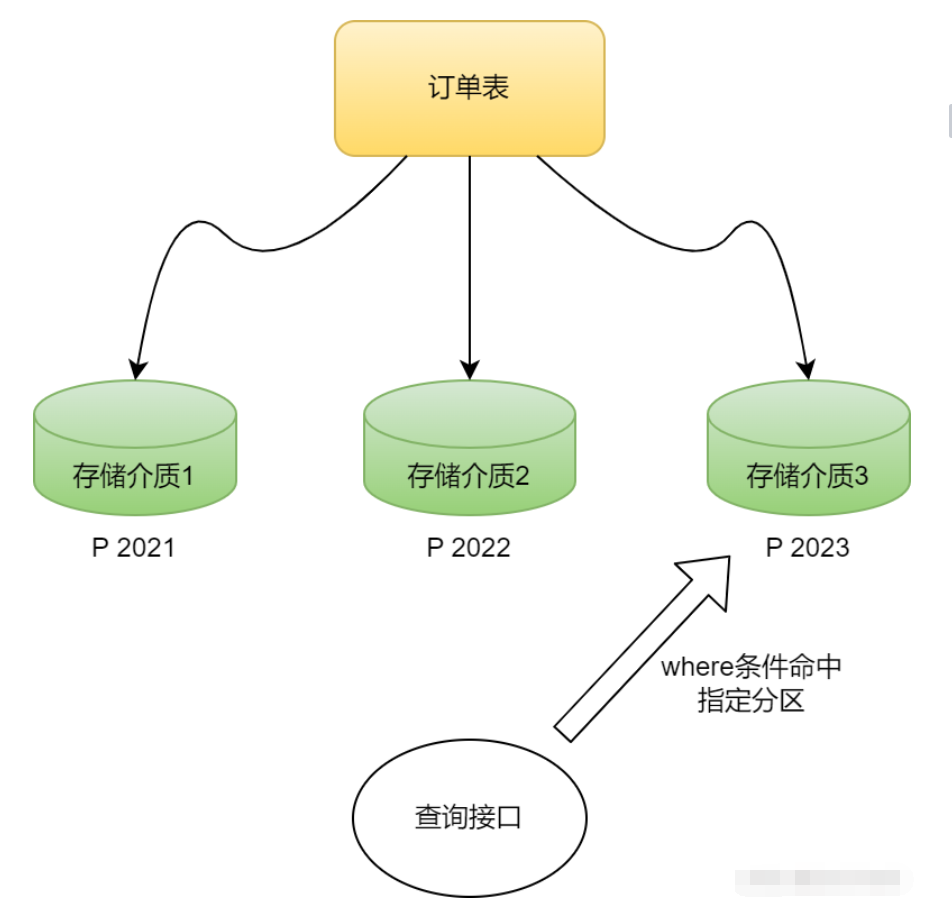
接著舉個範例,我們假設有一張訂單表,那麼對這張訂單表按照年份進行分割區的命令如下:
-- 建立訂單表
CREATE TABLE orders (
id INT PRIMARY KEY AUTO_INCREMENT,
order_number VARCHAR(20),
order_date DATE,
customer_id INT,
total_amount DECIMAL(10, 2)
);
-- 按照年份對訂單表進行分割區
ALTER TABLE orders
PARTITION BY RANGE(YEAR(order_date)) (
PARTITION p2018 VALUES LESS THAN (2019),
PARTITION p2019 VALUES LESS THAN (2020),
PARTITION p2020 VALUES LESS THAN (2021),
PARTITION p2021 VALUES LESS THAN (2022),
PARTITION p2022 VALUES LESS THAN (2023),
PARTITION p2023 VALUES LESS THAN (2024)
);
這樣一來,資料庫就會將這張表的資料按照YEAR(order_date)的值分別存在 p2018 ~ p2023 這6個分割區中。
如果結合本篇的問題,3000多萬條記錄,那麼按照年份分割區,大概一個分割區是1000萬記錄左右,然後可以優化查詢語句只去掃描特定的分割區,是不是一下就輕鬆了很多。
再深入點,按照年份一個分割區1000萬還是有點多了,我們是不是可以找到一個更合理的分割區欄位,讓每個分割區的資料更少呢?
這裡就要結合實際業務了,沒有真正的通用方案。
你要先明確一點,做分割區的目的,最終是為了讓某個業務環節的查詢更快,就比如本篇這裡,主要是為了讓客戶查詢訂單相關業務更快,那麼你就要先把這塊的查詢語句摘取出來,分析一下里面的where條件有哪些。
-
比如,客戶要查詢某個或某些狀態的訂單,可能會這樣寫:where order_status in (?);
-
比如,客戶要查詢某個特定群體的訂單,可能會這樣寫:where user_flag_id = ?;
-
比如,客戶要查詢某個或多個業務型別的訂單,可能會這樣寫:where order_type in (?);
甚至,還可能有其他的組合條件摻雜進來,你千萬別以為你去的每個公司都把表設計的很漂亮很合理,我這麼多年工作下來,真見過不少奇葩設計,訂單表裡面能給你塞上openId或者某些單純為了方便而加的冗餘欄位,完全把訂單表自身的功能性打碎。
這個時候,如果分割區欄位本身存在,且剛好能把分割區資料分的很合理,有利於查詢,比如前面按照年份劃分,每個分割區如果只有兩三百萬記錄,再結合本身的索引,查詢就會很快,那麼一切安好,搞完收工。
但如果分割區欄位很難定位,就像上面講的,一些主要SQL語句的where條件並不包含相同的欄位,那就頭大了。
而且MySQL還有一個需要注意的點,就是它的分割區本身是有限制的。
MySQL分割區欄位必須是唯一索引的一部分。
也就是說,如果沒有其他能用的唯一索引,我們只能結合主鍵ID,和分割區欄位組成複合主鍵才行。
這就更難了,純粹看這表長什麼樣了。
話到這裡,其實大家也看出來了,資料庫分割區的優缺點很明顯。
優點:遇到合適的場景,優化起來就是一個命令的事情。
缺點:限制太多,稍微複雜一點的場景你就很難定位分割區欄位。
那麼,真的就沒法分了嗎?其實還有一個迂迴的方案。
2、迂迴方案
我們可以在表中新增一個專門為了分割區而量身定做的欄位,比如archive_flag,表示一種資料歸檔狀態,當值為1時表示已歸檔,值為0時表示未歸檔。
這個欄位可以沒有業務意義,但一定要有分割區意義。
我們可以把半年內的資料刷成 archive_flag=0,半年以外的資料刷成 archive_flag=1。
接下來,我們按照歸檔狀態進行分割區即可,半年內的活躍資料是一個分割區,其他非活躍資料是一個分割區。
最後,只需要把核心的查詢語句where條件中都新增一個 archive_flag=0 就可以了,這樣就會掃描這個非歸檔狀態的分割區,也就是活躍資料的分割區。
試想一下,這個分割區只有半年的記錄,按照本篇的場景,最多也就是500萬了,結合自身表索引,已經完全可以解決當前存在的問題。
好了,這個迂迴方案其實挺不錯的,但一定有人會有疑問。
1)、加欄位真的好嗎?
2)、為什麼一定要半年內的資料?
首先解答第一個問題,答案是不好,在我這裡的話甚至可以說非常不好,幾千萬資料量的表,為了解決一個查詢問題刻意新增一個沒有實際意義的欄位,是捨本逐末的行為,如果除了這張表,還有其他表也有類似問題,難道每個都要加欄位嗎?顯然是不可行,也是不安全的。
第二個問題,半年內的資料完全可以結合實際業務做修改。
舉個簡單的例子,你如果經常逛京東商城購物,一定會開啟我的訂單看看,實際上給你展示的就是近3個月的訂單,你可以理解成這就是非歸檔的活躍資料。
當你想查詢以前的記錄時,就會給你一個連結叫歷史記錄,點選後跳轉到歷史記錄列表,或者通過其他方式如下拉框,讓你選擇其他更早時間的訂單資料,這種其實就是已經歸檔的資料。
這些資料一般不會直接從業務表裡查出來,而是從其他歸檔表,或者非關係型資料庫如mongodb、EasticSearch等查詢出來。
這種方式就類似做了分割區,把你經常存取的資料和存取頻率較低的資料分佈儲存,達到一個資料分離的目的。
這樣你就懂了,資料分割區大體就是這樣的思考方式。
現在回過頭來想想前面說的優缺點,資料庫分割區真的合適嗎?
實際情況下,很少有情況合適,主要原因還是前面講過的,限制真的太多了,而業務往往又是複雜的。
另外,資料庫分割區對於很多程式設計師來說,其實是陌生的,在中小企業更是如此,有這樣的現實擺在面前,加上短期內就要解決問題,隨便使用的話對於團隊來講也是一種風險。
所以,另一種更合理的方案也就呼之欲出了,資料的冷熱分離。
3、冷熱分離
前面講了那麼多,其實就是為了過渡到這裡來,上面的迂迴方案或多或少已經摸到了冷熱分離的邊緣,主要是為了讓大家知其然並知其所以然。
1)、基本概念
冷熱分離聽起來很高階,其實本質很簡單,就是把活躍資料和非活躍資料區分開,一熱一冷,頻率高的查詢只操作熱資料,頻率低的只操作冷資料。
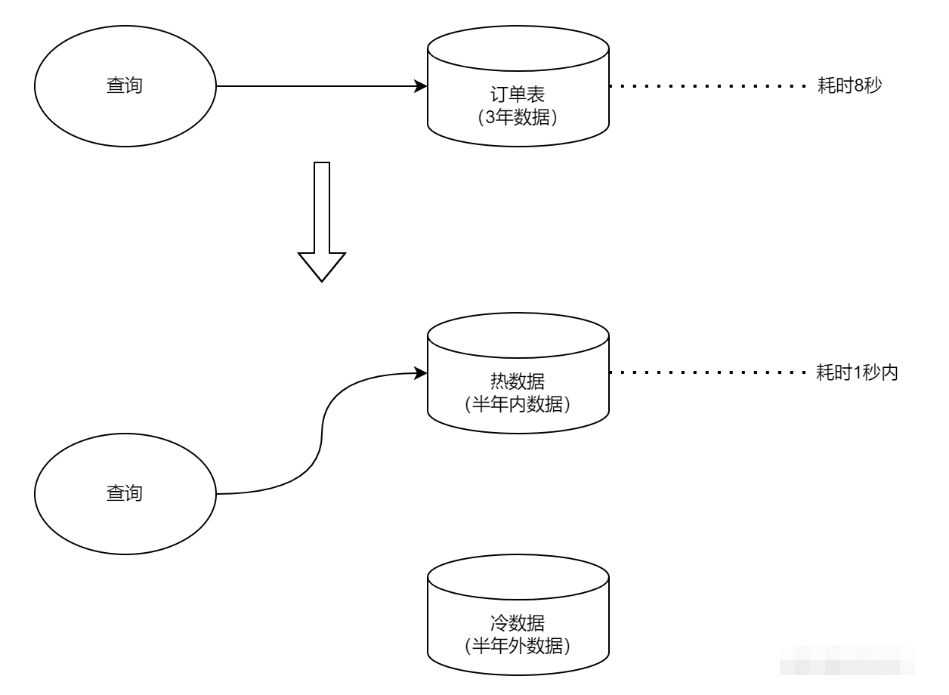
2)、儲存方案
既然要分離,就要考慮清楚熱資料和冷資料分別放在哪裡。
這裡我提供兩種選擇:
中小企業,我推薦依然用MySQL。
一來是不需要額外成本(降本增效?哈哈),二來是中小企業相對大廠,業務複雜度低一點且資料量小很多,那麼此時完全可以用MySQL新增一張表來儲存某個業務的冷資料,比如訂單。
如果需要冷熱分離的業務較多,也可以建一個單獨的冷庫,來專門存放冷資料,不過這種我也不太推薦,因為涉及到跨庫查詢,增加了維護難度,咱們程式設計師儘量對自己好一點哈。
一個專案裡面,其實兩三張冷表的出現已經可以處理核心業務資料冷熱分離的問題了,如果真有那麼多巨量資料的表,我覺得要從其他方面找問題了(一些老專案,設計上本身有問題,那是真的沒好辦法)。
大廠,推薦HBase。
大廠的資源較多,平臺較大,冷熱分離不單是解決這種問題的唯一方案,但大廠比較推薦更合適的資料庫來儲存這樣的冷資料。
其中HBase是我從各種資料中見過的最多的一種,當然也有其他的,但HBase應該是裡面最受歡迎的一類。
當然,我個人是沒有大廠經驗的,我只能把我掌握到的訊息告訴你們。
如果有興趣的話,可以去學習下HBase,它是一種在 Hadoop 上構建的分散式、可延伸的列式資料庫。
它最大的優勢就是快速讀寫海量資料,且具有強一致性。
一般大廠對於冷資料的處理,往往都是因為冷資料在業務中也有相當的查詢體量,如果太慢也不符合大廠維護專案的標準,所以有必要專門優化。
好了,這裡之所以提到HBase,主要是為了擴充大家的知識面,其實中小企業的工程師也沒啥必要特地去學,依靠自身興趣驅動即可。
3)、區分冷熱資料
既然要冷熱分離,那麼一張表中,如何區分哪些是熱資料,哪些是冷資料?
要分析這張表的
欄位特徵,拿訂單表舉例,馬上能想到的就是:訂單狀態、建立時間。
訂單狀態的話,其實也類似於前面資料庫分割區提過的歸檔狀態,你可以將狀態是已完成的資料歸類為冷資料,而待處理、處理中的都歸類為熱資料,這個要視你們自己的業務決定。
建立時間的話,就比較常見了,也是我推薦中小企業使用的方法,因為幾乎所有的核心業務表,都一定會有建立時間這個欄位,我們可以把查詢頻繁的時間區間的資料歸類為熱資料,其他時間都歸類為冷資料。
比如本篇我講的案例,當時我們公司就是半年內的資料是查詢非常頻繁的,因此直接按照最近半年作為區分冷熱資料的規則。
4)、如何冷熱分離
這裡有四種方案:
- 程式碼中處理
這個很好理解,比如訂單表中,當狀態從處理中改為已完成時,你就可以將這條記錄歸類為冷資料,放到冷表或冷庫中。
優點是很靈活,而且實時性高。
缺點是相關的程式碼位置你都要做修改,另外如果是按照時間做冷熱分離,這個方案基本就不可取。
你想想,你怎麼判斷呢?我們按照半年內的資料作為熱資料,那麼你在哪個方法哪個事件觸發時將這筆訂單歸類為冷資料?可以說做不到。
- 任務排程處理
這種就是定時任務去掃描資料庫,比如xxl-job,新建一個排程任務,定時去掃描資料庫,判斷哪些是冷資料,然後歸檔到冷表或冷庫中去。
這種的優點,一來是不用大量修改程式碼,二來就是非常適合按照時間劃分冷熱資料的場景。因為它是一種延遲處理方式,你可以設定為半夜去執行。
比如我之前的那家公司,就是設定為凌晨以後執行,因為那個時候很少有使用者在使用了,沒有什麼新的訂單產生,哪怕有新的訂單,也屬於誤差範圍內,可以接受。
- 監聽binlog
這種方案我是從書本上獲取到的,給我漲了點知識。
監聽binlog的目的說白了,就是判斷訂單狀態是否變化,和程式碼中處理很類似,唯一的區別在於,
如果你維護的這個專案又老又複雜,程式碼很難改也改不全,監聽binlog就是很好的方案了,你可以不改程式碼,監聽資料庫變更紀錄檔然後做相應處理即可。當然,缺點和前面一樣,當按照時間來劃分冷熱資料時,這種方案也不可取,因為你不知道如何監聽。
- 人工遷移
冷熱分離操作的最終還是資料,分離實質上也就是一種資料遷移,因此,人工干預其實是很靠譜的選擇。
上面每種方案都有自己的優勢,但也有各自的侷限性。
程式碼處理,你只能處理髮布上線以後的新資料。
任務排程,當資料量龐大的情況下,你一次可能根本無法完成分離,對於緊急的要快速優化的場景顯然不適合。
監聽binlog,除了前面提到的缺點,還需要工程師對其比較熟悉,否則短時間內上手容易帶來不確定性。
此時,DBA或整合工程師(俗稱打雜工程師)的優勢就體現出來了,備份後,抽某天晚上,直接把半年以外的資料遷移到冷庫即可。
這樣不僅簡單,也避免了其他技術方案可能存在的問題及風險。專業的人,做專業的事,才是最靠譜的。
4、最終方案
通過上面簡述的幾種方案,我們已經有了較為清晰的認知。
現在我可以告訴大家,當初的公司所採用的方案是其中兩種方案的結合:
人工遷移 + 任務排程。
人工遷移用於一次遷移完成冷資料到冷庫,任務排程用於對後續新產生的資料進行解耦且延遲的冷熱分離。
思維導圖大概是這樣:
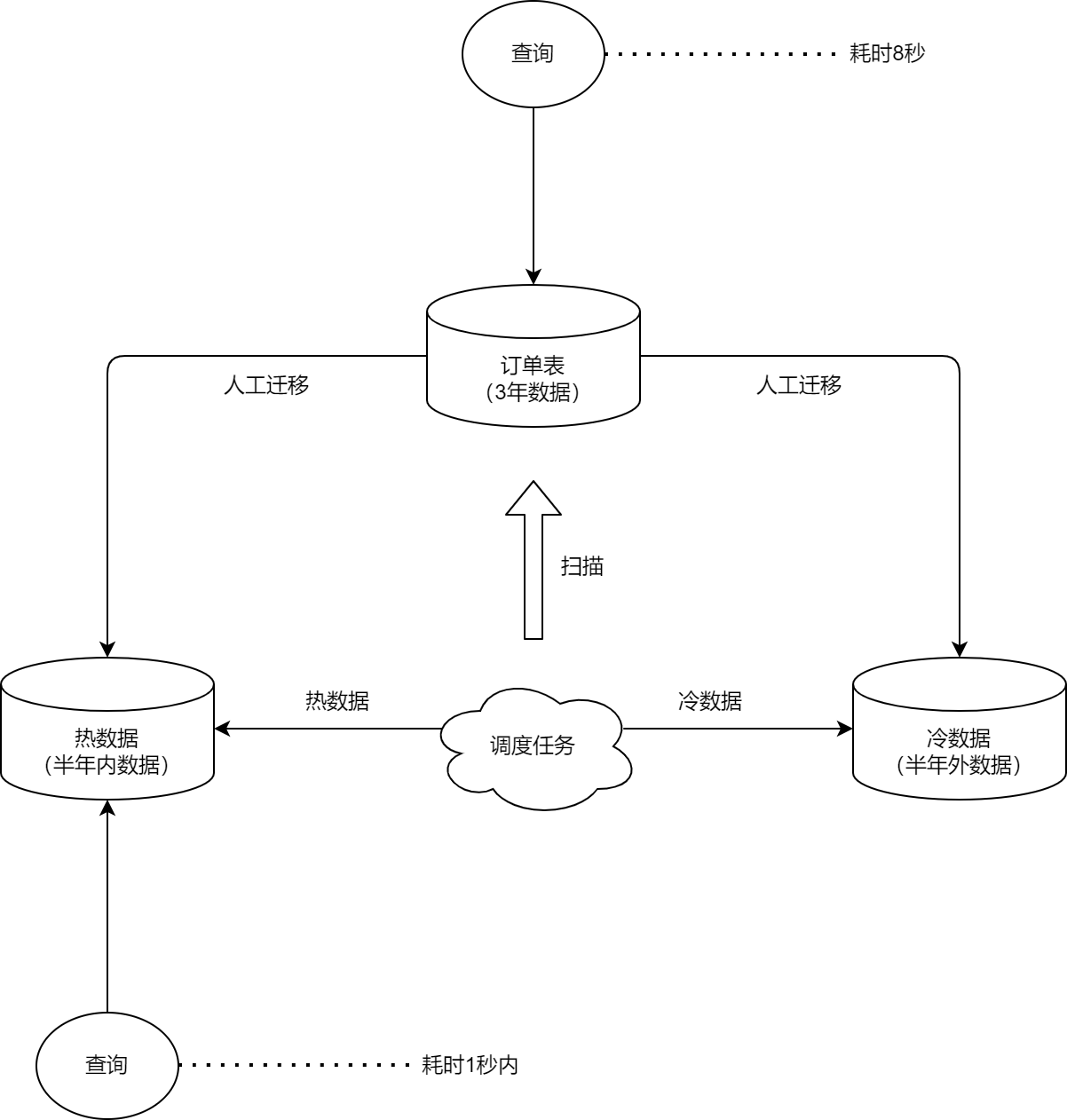
基本步驟如下:
-
1)、定位冷熱分離的規則,比如本篇,就是按照訂單交易完成時間,以半年內和半年外作為分離的基準;
-
2)、冷資料遷移,由公司的DBA或整合工程師對資料進行備份,然後在釋出當晚將冷資料遷移到冷庫中去;
-
3)、開發人員新建一個排程任務,並實現任務呼叫的介面,專門掃描資料庫,將超過半年的訂單資料通過程式邏輯遷移到冷庫,保證熱資料一直維持在半年內,任務可以每天凌晨執行一次,或根據自身業務決定排程頻率。
這樣一來,既解決了冷熱分離規則的問題,不管是什麼規則,你最終都可以通過人工遷移資料來做到分離。
也解決了時間上的緊迫性,你只需要開發一個用於排程的介面,不再需要考慮其他任何技術層面的影響,時間成倍縮短。
這在中小企業算是比較適合的方案了,當初我們在一週內就優化完成了,研發工程師用了1天完成排程介面的實現,剩下的時間都是整合工程師進行資料遷移的演練。
最終客戶還是很滿意的,核心業務的查詢速度一下就提升了近10倍。
優缺點
好了,臨近尾聲,我們來說一下冷熱分離方案整體的優缺點吧。
1、優點
優點我歸納了3點:
1)、提高效能
很明顯,冷熱分離後,將更多計算資源集中在了熱資料上,將查詢效能最大化。
2)、降低成本
對於千萬級的資料表,冷熱分離方案不需要額外的第三方中介軟體,極大地節約了成本。尤其是在中小公司,老闆對成本還是很在意的。
3)、簡化維護
冷熱分離之後,對於資料的維護更直觀,可以把更多精力放在熱資料的處理上。
比如備份策略,冷熱資料可以分別採用不同的策略維護,更關注熱資料備份,簡化冷資料備份。
2、缺點
缺點我歸納了2點:
1)、場景限制多
冷熱分離並不是萬能的,一定要根據業務來分析,查詢的複雜度較高,很可能你冷熱分離後,熱資料的查詢依然沒有得到明顯優化。
比如你有一張表,查詢的語句關聯很多,表資料量也挺大,那麼這個時候冷熱分離一點作用都沒有,因為你分離完了,查詢語句還是關聯那麼多,速度依然很慢。
這個時候,類似的場景就無法使用冷熱分離方案了,而是要考慮其他方案,比如讀寫分離,比如查詢分離,這樣才能從根源上解決查詢慢的問題。
2)、統計效率低
這種也是冷熱分離方案比較明顯的一個缺點,當你們的業務中,需要對資料做一些複雜的統計分析,甚至要求一定的實時性。
那麼這個時候,因為已經冷熱分離,冷資料的統計分析效率會非常低,對於客戶提出的一些五花八門的統計分析就難以操作了。
因此,又需要引入其他方案來配合,比如ElasticSearch,這樣又增加了額外的成本,不僅要考慮ES的資源成本,還要考慮諸如部署方案、維護方案、安全性問題等等。
今年我們內部就公佈了一個小道訊息,某家業內還挺不錯的網際網路公司因為ElasticSearch的未授權漏洞導致千萬使用者敏感資訊被洩露,直接被行業除名了。
所以,在實際工作中,中介軟體的引入是個需要審慎考慮的問題,而不是你想當然了就可以使用。
總結
通篇寫的還是挺長的,主要是一開始列出了大綱,但在寫的過程中又想起了新的知識點,就一起加進來了。
前面講的資料庫分割區等方案,主要是為了過渡,因為這是一個線性的思維,展現出來讓大家知道一個方案最終落地的脈絡是怎樣的。
今後還會繼續寫一些架構相關的知識,放在單獨的專欄裡面,希望大家支援和喜歡。
如果喜歡,請點贊+關注↓↓↓,持續分享工作經驗及各種乾貨哦!