解密Prompt系列21. LLM Agent之再談RAG的召回資訊密度和質量
話接上文的召回多樣性優化,多路索引的召回方案可以提供更多的潛在候選內容。但候選越多,如何對這些內容進行篩選和排序就變得更加重要。這一章我們嘮嘮召回的資訊密度和質量。同樣參考經典搜尋和推薦框架,這一章對應排序+重排環節,考慮排序中粗排和精排的區分主要是針對低延時的工程優化,這裡不再進一步區分,統一算作排序模組。讓我們先對比下重排和排序模組在經典框架和RAG中的異同
- 排序模組
- 經典框架:pointwise建模,區域性單一item價值最大化,這裡的價值可以是搜尋推薦中的內容點選率,或者廣告中的ecpm,價值由後面使用的使用者來決定
- RAG:基本和經典框架相同,不過價值是大模型使用上文多大程度可以回答問題,價值的定義先由背後的大模型給出,再進一步才能觸達使用者。更具體的定義是,排序模組承擔著最大化資訊密度的功能,也就是在更少的TopK內篩選出儘可能多的高質量內容,並過濾噪聲資訊。
- 重排模組
- 經典框架:Listwise建模,通過對item進行排列組合,使得全域性價值最大化,進而使得使用者多次行為帶來的整體體驗感更好。這裡的整體可以是一個搜尋列表頁,一屏推薦資訊流,也可以是更長的一整個session內使用者體驗的整體指標,以及背後的商業價值。常見的做法是打散,提高連續內容的多樣性,以及前後內容的邏輯連貫性,不過打散只是手段,全域性價值才是終極目標
- RAG:概念相似,通過重排優化模型對整體上文的使用效率。優化模型對上文的使用,提升資訊連貫性和多樣性,最小化資訊不一致性和衝突。不過當前大模型對話式的互動方式更難拿到使用者體驗的反饋訊號,想要優化使用者體驗難度更高。
下面我們分別說兩這兩個模組有哪些實現方案
1. 排序模組
上一章提到使用query改寫,多路索引,包括bm25離散索引,多種embedding連續索引進行多路內容召回。這種方案會提供更豐富的內容候選,但也顯著增加了上文長度。而很多論文都評估過,過長的上文,以及過長上文中更大比例的噪聲資訊,都會影響模型推理的效果,如下圖
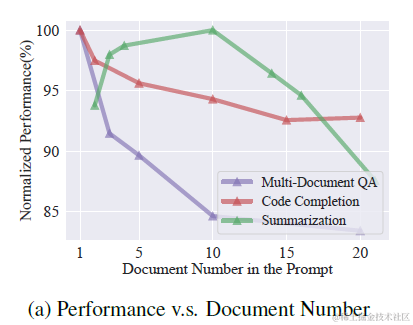
因此如何從這些召回內容中排序篩選出更出質量更高的內容,過濾噪聲資訊就是排序模組需要做的。考慮不同索引之間對於相似度的計算打分相互不可比,更不可加,因此需要統一的打分維度來對候選內容進行排序,這裡提供兩個無監督的混合排序打分方案
1.1 RRF混排
多路召回混合排序較常見的就是Reciprocal Rank Fusion(RRF),把所有打分維度都轉化成排名,每個檔案的最終得分是多路打分的排名之和的倒數。通過排名來解決不同打分之間scale的差異性。公式如下,其中r(d)是單一打分維度中的檔案排名,K是常數起到平滑的作用,微軟實驗後給的取值是60。
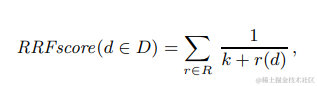
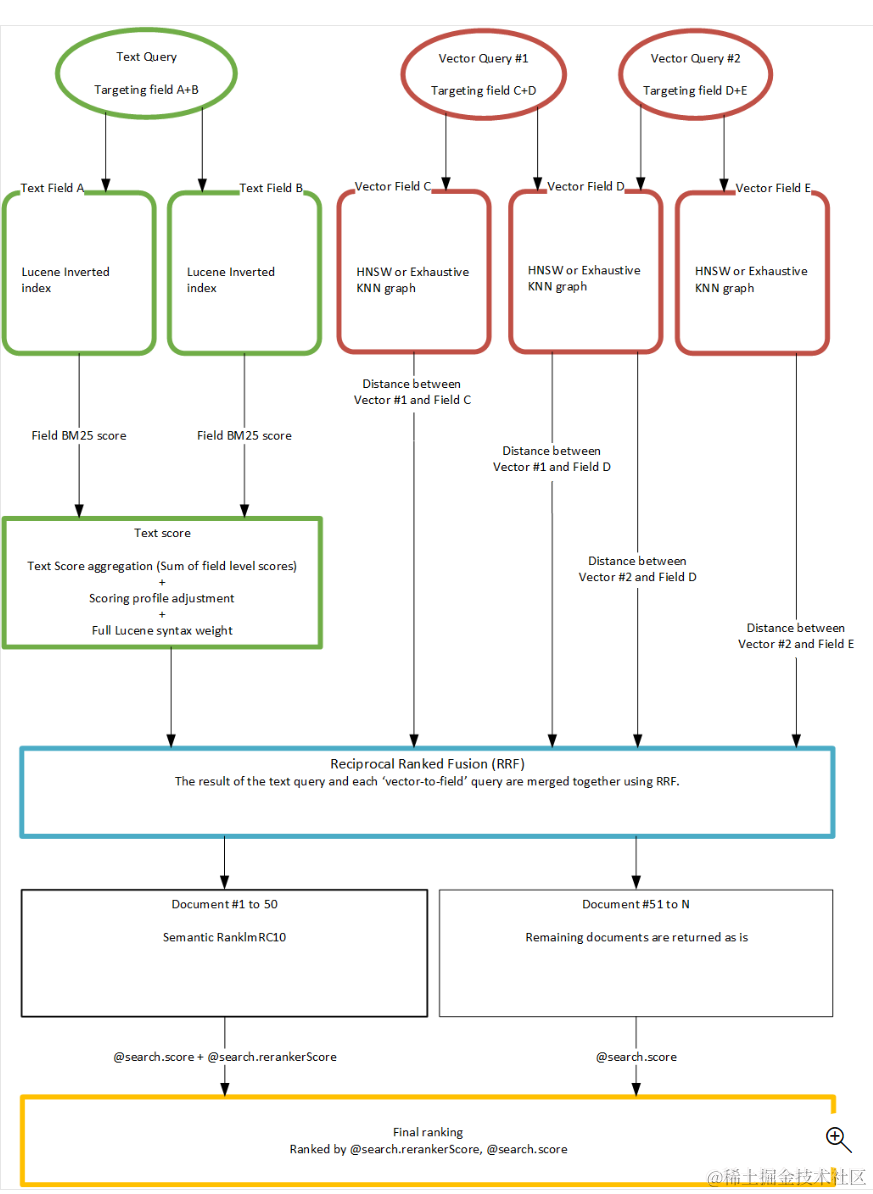
以下是微軟搜尋中使用RRF類合併文字檢索和向量檢索的一個示意圖,使用RRF分別對文字檢索和向量檢索的多路召回內容進行混合排序
1.2 資訊熵打分
除了使用排名來對各路召回的內容質量進行歸一化,當然也可以使用統一的模型打分來對內容質量進行衡量,比如可以使用Bert Cross-Encoder BGE-Reranker來對所有候選檔案來進行打分排序,利用cross模型比embedding模型更精準的特點來進一步對召回內容進行過濾。
這裡我想聊聊除了相關性之外的另一個內容質量評估維度 - Information-Entropy。Information-Entropy是從文字資訊熵的角度對內容有效性和質量進行打分篩選,有以下幾種不同的資訊熵度量方式
1.2.1 Selective-Context
Unlocking Context Constraints of LLMs: Enhancing Context Efficiency of LLMs with Self-Information-Based Content Filtering
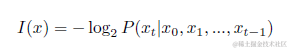
Selective-Context使用自資訊對內容質量進行評估。上一次碰到自資訊,還是在做新詞挖掘的演演算法。放在內容質量篩選也是同樣的道理,熵值越低(不確定性越低),自資訊越低的token帶給語言模型的資訊量就越低,例如停用詞,同義詞等等。因此自資訊更低的內容本身的價值更低。不過自資訊的計算是token粒度的,想要對短語,句子,段落進行計算可以近似採用token求和的方式,也就是假設token之間是相互獨立。但是越大粒度的資訊合併,簡單求和的自資訊誤差越大,因為token並非真正獨立。因此單純使用內容自資訊的計算方式更適合短語粒度的上文內容壓縮,似乎不完全適合對RAG召回的段落內容進行打分,不過不要著急接著往後看喲~
以下是Selective-Context通過自資訊對Context進行壓縮的效果,至於壓縮幅度和壓縮後對模型推理的影響我們放到最後一起對比

1.2.2 LLMLingua
LLMLingua: Compressing Prompts for Accelerated Inference of Large Language Models
LLMLingua同樣是使用token熵值來對內容質量進行打分,不過進一步放鬆了token獨立性的假設。 計算公式如下,先把整個上文context分段,論文使用100個token為一段。以下\(S_{j,i}\)為第j個段落中第i個字,\(\tilde{S}_j\)是第j個段落前所有段落經過壓縮後的內容。也就是在計算當前段落每個字的熵值時,會把之前已經壓縮過的內容拼接在前面,使得對更大粒度的段落熵值估計更加準確。
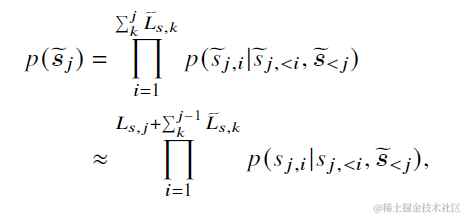
1.2.3 LongLLMLingua
LongLLMLingua: Accelerating and Enhancing LLMs in Long Context Scenarios via Prompt Compression
LongLLMLingua進一步把完全基於內容的資訊熵,優化成了基於內容回答問題的條件熵,更完美的適配RAG框架中排序模組對召回內容整體打分的要求。
以上LLMLinugua和Selective-Context單純對上文內容的熵值進行計算,但很有可能熵值高的內容雖然包含大量資訊但都和問題無關,只是單純的資訊噪聲。因此LongLLMLingua在熵值計算中引入了問題,那無非就是兩種計算方案,要麼給定問題計算內容的熵值,要麼給定內容計算問題的熵值。論文考慮內容中可能是有效資訊和噪聲資訊的混合,因此選用了後者。也就是給定每段召回內容,計算問題的熵值。
這裡論文還在問題前加了一段指令,"\(X^{restrict}=\)we can get the answer to this question in the given documents",通過增加內容到問題的關聯程度,來優化條件熵的計算。
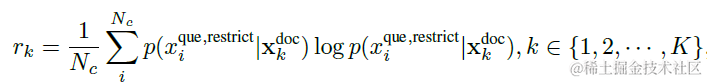
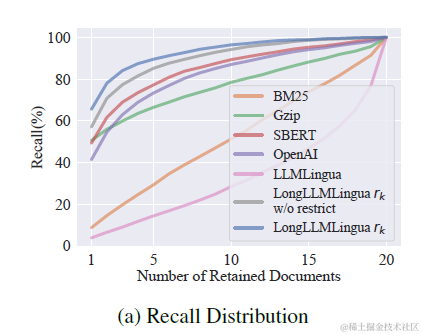
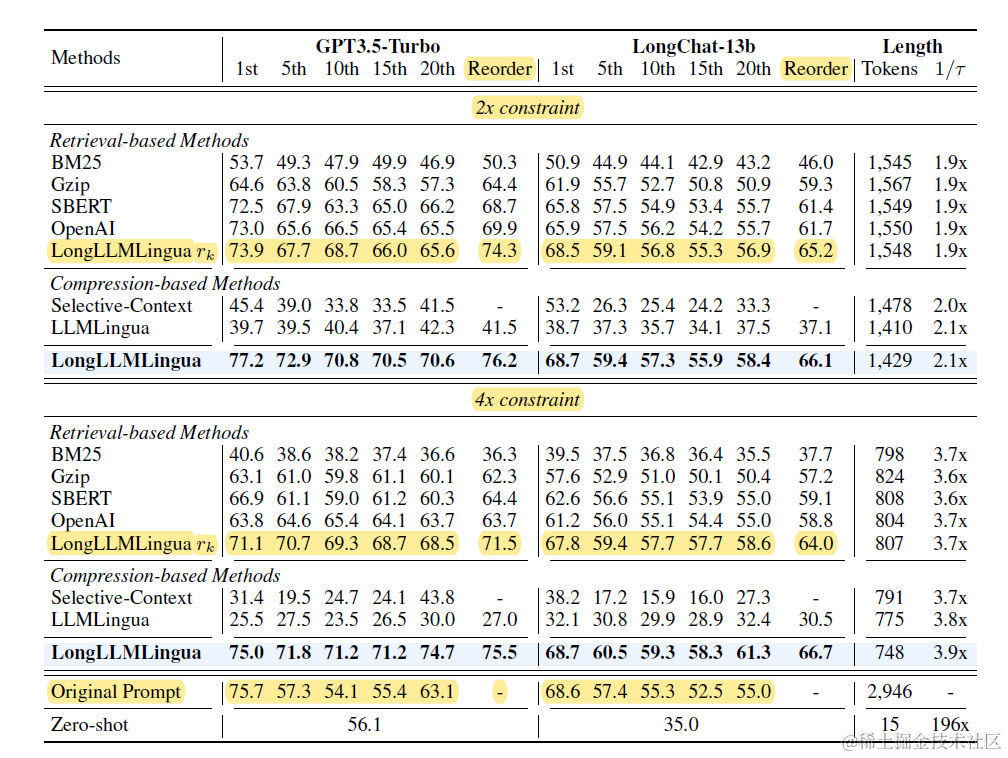
論文對比了不同打分排序方案,包括BM25,各種向量embedding,以及LLMLingua,其中LongLLMLinuga在TopK檔案的召回率上顯著更優,如下圖。具體的壓縮率和推理效果對比,我們放到後面的重排模組一起來說。
LongLLMLingua在以上的段落打分之外,還加入了對段落內部token級別的內容壓縮。也就是先篩選TopN段落,再在段落內篩選有效Token。不過看論文效果感覺段落排序的重要性>>內容壓縮,這部分就不再贅述,感興趣的朋友去看論文吧~
重排模組
針對排序模組篩選出的TopK上文候選,重排模組需要通過對內容進一步排列組合,最大化模型整體推理效果。和排序模組最大的差異在於它的整體性,不再針對每個Doc進行獨立打分,而是優化整個Context上文的效果。主要有以下兩個優化方向:一個是檔案位置的優化,一個是檔案之間關聯性的優化
檔案位置
- LongLLMLingua: Accelerating and Enhancing LLMs in Long Context Scenarios via Prompt Compression
- Lost in the Middle: How Language Models Use Long Contexts
- https://api.python.langchain.com/en/latest/document_transformers/langchain.document_transformers.long_context_reorder.LongContextReorder.html
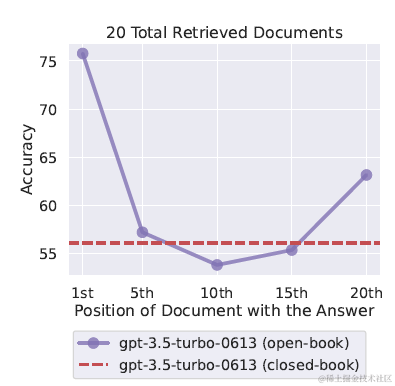
針對檔案位置的最佳化就是Lost in the Middle(上圖),相信大家可能都比較熟悉。簡單說就是大模型在使用上文推理時,傾向於使用最前面和最後面的內容,而對中間的內容愛搭不理。因此可以基於內容的質量,把重要的內容放在Context的前面和後面。
LongLLMLingua也做了類似的嘗試,並且認為前面的位置比後面更加重要,因此直接使用上面排序模組對段落的打分,對排序後保留的候選內容,進行重新排列,按照分數由高到低依次從前往後排列。
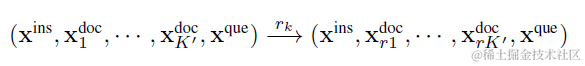
最後來一起看下效果,在LongLLMLingua中,論文對比了各種相似度排序方案保留TopN檔案,並使用該排序方案進一步重排內容的效果。在2倍和4倍的壓縮率下LongLLMLingua的效果都是顯著最好的,不過可以發現只使用LongLLMLingua進行排序(Retrieval-base Methods)並做重排(Reorder列)的效果其實就已經不差了,而段落內部的token壓縮更多是錦上添花。
檔案關聯性
- https://python.langchain.com/docs/integrations/retrievers/merger_retriever
- MetaInsight: Automatic Discovery of Structured Knowledge for
Exploratory Data Analysis
以上排序和重排的邏輯,都是考慮問題和召回內容之間的關聯性,但都沒有引入Context內部不同召回內容之間的關聯性。
langchain的LOTR (Merger Retriever)實現了部分類似的功能,包括使用embedding對多路召回的內容進行消重,以及對內容進行聚類,每個聚類中篩選最靠近中心的一條內容。這一步可以放在排序中去做,也可以放在排序後的重排模組。
之前解密Prompt系列19. LLM Agent之資料分析領域的應用章節提到的微軟的MetaInsight也引入了類似的打散邏輯。其中
- 內容的整體價值=每條內容的價值之和-內容之間重合的價值
- 兩兩內容重合價值=兩條內容打分的最小值*內容重合率
那放到RAG框架可能就可以使用以上的資訊熵來作為打分,相似度來作為重合率
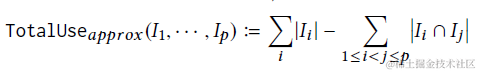
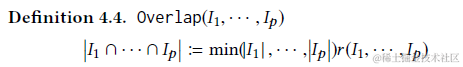
這塊我們也在嘗試中,所以沒有結論性的內容,這裡只丟擲幾個問題,有試驗過效果的有緣人可以在評論區回覆
- 資訊連貫性:把內容相似的多個召回連續排列,會比散落在Context各處效果更好麼
- 資訊多樣性:對召回內容進行聚類,把內容相似觀的多個召回進行消重,或者只使用每個cluster內距離類中心最新的一條或TopN條內容,會提升推理效果麼
- 資訊一致性:觀點或內容衝突的多個召回內容,對推理的影響有多大
想看更全的大模型相關論文梳理·微調及預訓練資料和框架·AIGC應用,移步Github >> DecryPrompt
Reference
- 推薦系統[四]:精排-詳解排序演演算法LTR (Learning to Rank)_ poitwise, pairwise, listwise相關評價指標,超詳細知識指南。
- 多業務建模在美團搜尋排序中的實踐
- 搜尋重排序和推薦列表重排序,在建模思路上有什麼異同?
- Transformer 在美團搜尋排序中的實踐
- 工業界(搜尋 推薦)粗排模型一般怎麼做?
- 知乎搜尋排序模型的演進