深度學習專案實戰:垃圾分類系統
簡介:
今天開啟深度學習另一板塊。就是計算機視覺方向,這裡主要討論影象分類任務--垃圾分類系統。其實這個專案早在19年的時候,我就寫好了一個版本了。之前使用的是python搭建深度學習網路,然後前後端互動的採用的是java spring MVC來寫的。之前感覺還挺好的,但是使用起來還比較困難的。不光光需要有python的基礎,同時還需要有一定的java的基礎。尤其是搭建java的環境,還是很煩的。最近剛好有空,就給這個專案拿了過來優化了一下,本次優化主要涉及前後端介面互動的優化,另外一條就是在模型的識別效能上的優化,提高模型的識別速度。
展示:
下面是專案的初始化介面:
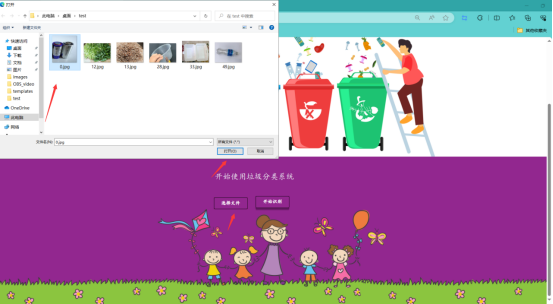
使用本系統的話也是比較簡單的,點選選擇檔案按鈕選擇需要識別的圖片資料。然後再點選開始識別就可以識別了
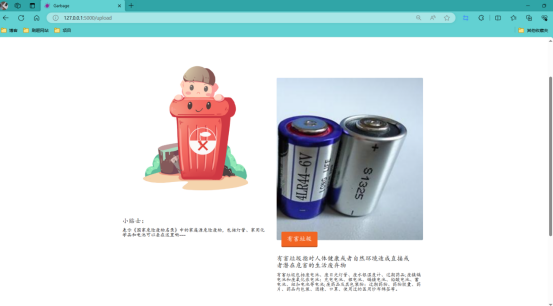
識別結果如下:
實際的使用請看下面的視訊:
B站--深度學習專案實戰:垃圾分類系統
專案實現思路:
專案主要分為兩塊,第一塊是深度學習模組,另一塊呢就是系統的使用介面了。
1、深度學習模組
先說第一個模組,也就是深度學習模組,這塊的主體呢其實就是深度學習的網路的搭建以及模型的訓練,還有就是模型的使用了。
深度學習網路的我主要使用的是ResNet的網路結構,使用這個網路結構來實現四分類的垃圾分類的任務肯定是可以的。同時呢在訓練模型的時候,我這裡又使用了一些調參的手法--遷移學習。為什麼要使用遷移學習呢?由於ResNet在影象任務上表現的是比較出色的,同時我們的任務也是影象分類,所以呢是可以使用ResNet來進行遷移學習的。
下面是相關程式碼:
`import torch
from torch import nn
from torch.nn import functional as F
class ResBlk(nn.Module):
def init(self, ch_in, ch_out, stride=1):
super(ResBlk, self).init()
self.conv1 = nn.Conv2d(ch_in, ch_out, kernel_size=3, stride=stride, padding=1)
self.bn1 = nn.BatchNorm2d(ch_out)
self.conv2 = nn.Conv2d(ch_out, ch_out, kernel_size=3, stride=1, padding=1)
self.bn2 = nn.BatchNorm2d(ch_out)
self.extra = nn.Sequential()
if ch_out != ch_in:
self.extra = nn.Sequential(
nn.Conv2d(ch_in, ch_out, kernel_size=1, stride=stride),
nn.BatchNorm2d(ch_out)
)
def forward(self, x):
out = F.relu(self.bn1(self.conv1(x)))
out = self.bn2(self.conv2(out))
out = self.extra(x) + out
out = F.relu(out)
return out
class ResNet18(nn.Module):
def init(self, num_class):
super(ResNet18, self).init()
self.conv1 = nn.Sequential(
nn.Conv2d(3, 16, kernel_size=3, stride=3, padding=0),
nn.BatchNorm2d(16)
)
self.blk1 = ResBlk(16, 32, stride=3)
self.blk2 = ResBlk(32, 64, stride=3)
self.blk3 = ResBlk(64, 128, stride=2)
self.blk4 = ResBlk(128, 256, stride=2)
self.outlayer = nn.Linear(25633, num_class)
def forward(self, x):
x = F.relu(self.conv1(x))
x = self.blk1(x)
x = self.blk2(x)
x = self.blk3(x)
x = self.blk4(x)
# print(x.shape)
x = x.view(x.size(0), -1)
x = self.outlayer(x)
return x
def main():
blk = ResBlk(64, 128)
tmp = torch.randn(2, 64, 224, 224)
out = blk(tmp)
print('block:', out.shape)
model = ResNet18(5)
tmp = torch.randn(2, 3, 224, 224)
out = model(tmp)
print('resnet:', out.shape)
p = sum(map(lambda p:p.numel(), model.parameters()))
print('parameters size:', p)
if name == 'main':
main()`
下面是遷移學習的主要程式碼:
trained_model=resnet18(pretrained=True) model = nn.Sequential(*list(trained_model.children())[:-1], Flatten(), nn.Linear(512,4) ).to(device)
這部分程式碼將預訓練模型的所有層(除了最後一層)複製到新模型中。Flatten()是將最後一層的輸出展平,以便可以輸入到全連線層(nn.Linear(512,4))。nn.Linear(512,4)是一個全連線層,有512個輸入節點和4個輸出節點,對應於任務中的類別數。
最後,.to(device)將模型移動到指定的裝置上(例如GPU或CPU)。如果你沒有指定裝置,那麼預設會使用CPU。
之後呢設定batchsize、learning rate、優化器就可以進行模型的訓練了
引數設定如下:
batchsz = 64 lr = 1e-4 epochs = 5
2、使用介面
接下來呢,就是關於使用介面的實現思路介紹了。使用介面就是為了方便對模型使用不是很瞭解的小夥伴使用的。如下所示,可以看到我們只需要點選兩個按鈕就可以使用了。
這裡的實現呢,主要採用的是Flask進行開發的,以前的版本是採用java的方式開的,使用起來不但笨重,同時模型識別的速度還比較的慢。最要命的是,搭建環境也是讓人頭疼的一件事。所以這次我給整個專案做了優化。主要就是提高模型的識別速度,同時讓使用者擁有良好的使用體驗。
系統主要架構如下圖所示:
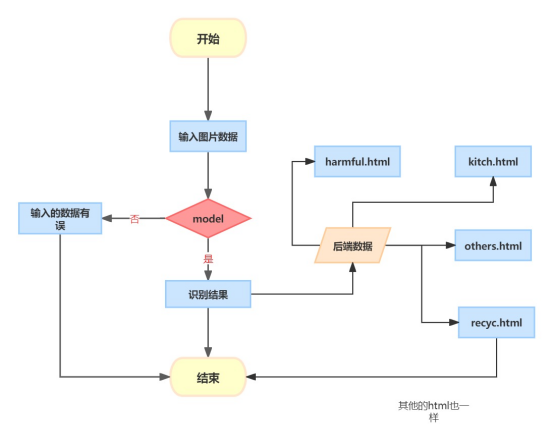
其實比較簡單,其實也就4步:
第一步:就是給通過使用端選擇需要識別的圖片資料
第二步:給資料傳到指定目錄下,然後給模型識別使用
第三步:模型進行識別
第四步:給識別結果以網頁的方式進行展示,這裡做的是四分類的任務,所以主要設計了四個網頁。還有一個就是出現意外狀況的test.html
我舉一個例子:比如我們輸入的圖片是廚房的垃圾圖片,那麼模型識別以後給識別結果交給Flask程式碼,Flask程式碼會根據對應的識別結果給跳轉到kitch.html介面中,最後的結果如下所示,可以看到的有識別結果還有識別的圖片,以及對於相應的垃圾的分類的定義還有一些小貼士。
Flask的主要程式碼如下:
`uploaded_file = request.files['file']
file_name = uploaded_file.filename
if not os.path.exists(UPLOAD_FOLDER):
os.makedirs(UPLOAD_FOLDER)
# get file path
file_path = os.path.join(UPLOAD_FOLDER, file_name)
# write image to UPLOAD_FOLDER
with open(file_path, 'wb') as f:
f.write(uploaded_file.read())`
下面的程式碼主要就是獲取到form傳遞過來的圖片資料,然後整個程式碼就會給資料上傳到指定的資料夾下面。
最後說明:
由於筆者能力有限,所以在描述的過程中難免會有不準確的地方,還請多多包含!
更多NLP和CV文章以及完整程式碼請到"陶陶name"獲取。
專案實戰持續更新,大家加油!!!!