MySQL運維6-Mycat垂直分庫
一、垂直分庫場景
場景:在業務系統中,涉及一下表結構,但是由於使用者與訂單每天都會產生大量的資料,單臺伺服器的資料儲存以及處理能力是有限的,可以對資料庫表進行拆分,原有資料庫如下
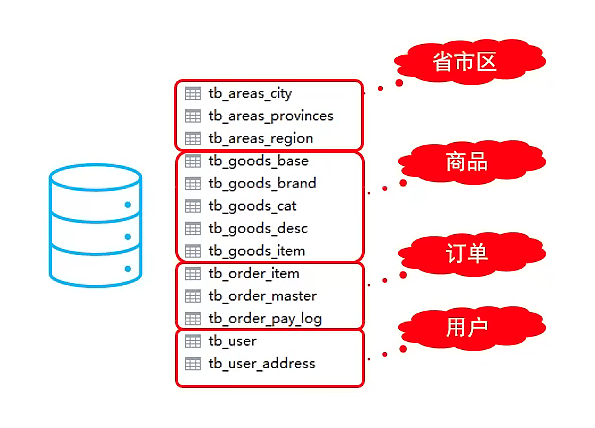
說明1:整個業務系統中的表,大致分為四個,商品資訊類的表,訂單相關的表,使用者相關表及省市區相關的表,這裡暫時將省市區的表和使用者相關的表放在一個資料節點上。
說明2:因為商品,訂單和使用者相關的資料,每天都會產生海量的資料,所以我們採取的分庫策略是將不同業務型別資料,放在不同資料庫中,即垂直分庫。
二、準備工作
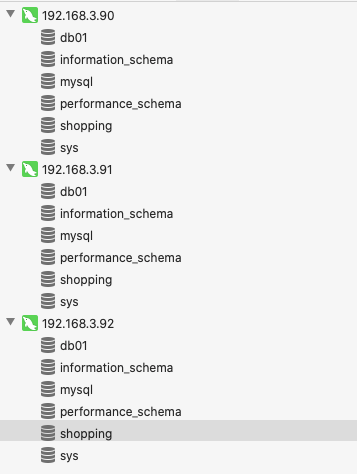
在192.168.3.90,192.168.3.91,192.168.3.92三臺伺服器上建立shopping資料庫
三、設定schema.xml
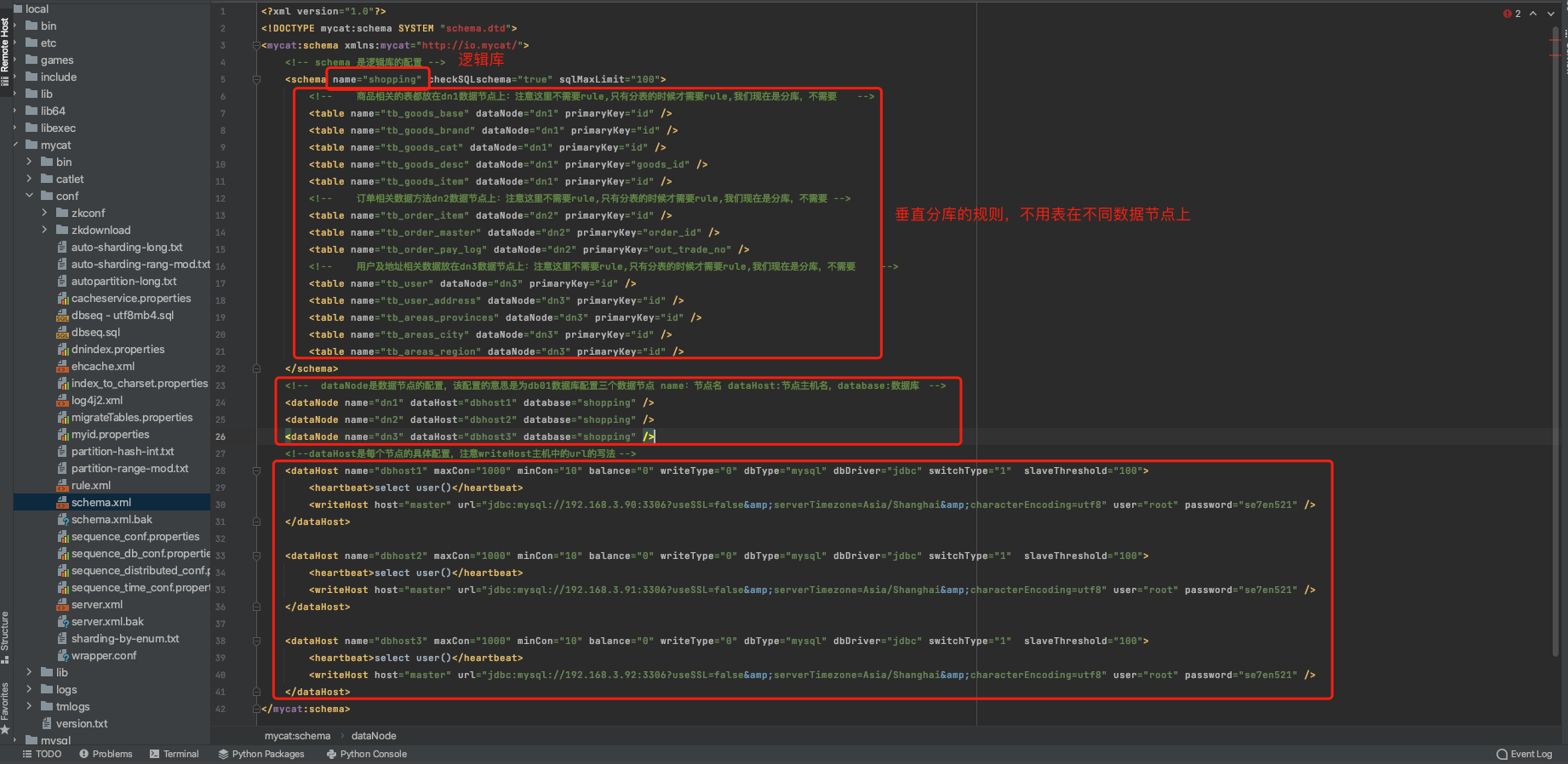
說明1:在schema標籤裡面的table標籤不需要rule屬性的,只有在分表時才需要rule,我們現在是分庫操作,不需要rule屬性
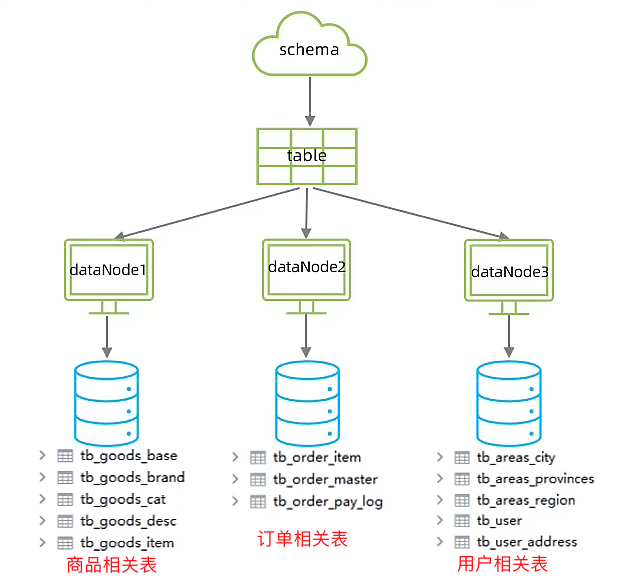
說明2:在table標籤中,商品相關的表都放在dn1資料節點上,和訂單相關的表都放在dn2資料節點上,和使用者和地址相關的都放在dn3資料節點上
四、設定server.xml
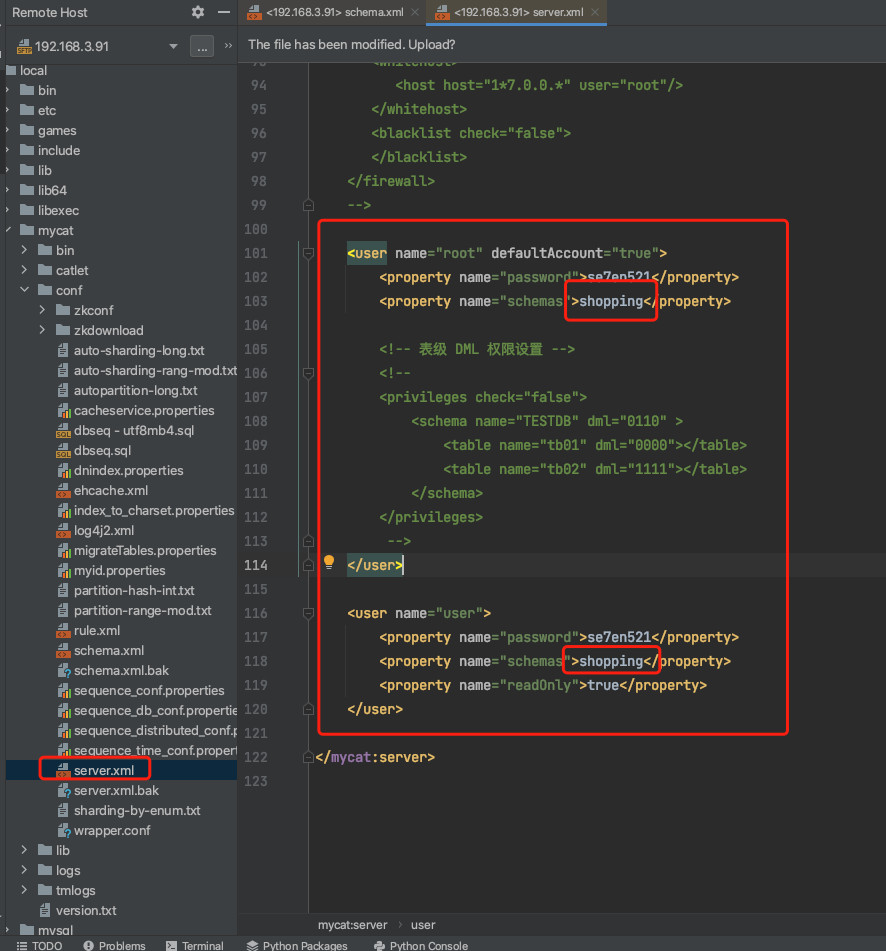
說明1:修改schemas標籤中的資料庫名稱為shopping
五、Mycat分庫測試
首先因為修改Mycat的組態檔,所以需要重啟一下Mycat,保證新的設定起作用。
重啟之後,在192.168.3.91伺服器上連線Mycat
檢視邏輯庫和邏輯表
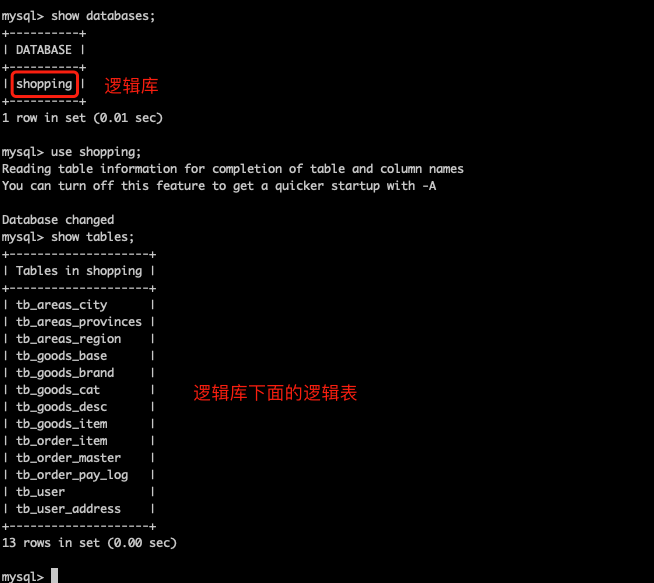
說明1:目前這些表都還只是邏輯表,在mycat中存在,但是在MySQL的資料庫中都沒不存在,所以還需要把這些表建立出來。
說明2:這裡我們建立三個表作為代表,其他暫時用不到的表就先不建立了,每個資料節點上建立一個表,然後這些表就會自動的出現在設定好的資料節點上。
create table tb_goods_base(id int auto_increment primary key, goods_name varchar(20), category varchar(20), price int); create table tb_order_master(order_id int auto_increment primary key, money int, goods_id int, receiver_province varchar(6), receiver_city varchar(6), receiver varchar(20)); create table tb_user(id int auto_increment primary key, name varchar(20), age int, gender varchar(1));
在往每個表中插入一些測試資料
insert into tb_user (name, age, gender) values ("張三", 21, "男"); insert into tb_user (name, age, gender) values ("李四", 22, "女"); insert into tb_user (name, age, gender) values ("王五", 23, "男");
insert into tb_goods_base (goods_name, category, price) values ("華為手機","家電", 5888); insert into tb_goods_base (goods_name, category, price) values ("中國李寧","服裝", 499); insert into tb_goods_base (goods_name, category, price) values ("雙匯火腿","食品", 15); insert into tb_order_master (money, goods_id, receiver_province, receiver_city, receiver) values (5888, 1, "130000", "130200", "張三"); insert into tb_order_master (money, goods_id, receiver_province, receiver_city, receiver) values (499, 2, "130000", "130800", "李四"); insert into tb_order_master (money, goods_id, receiver_province, receiver_city, receiver) values (15, 3, "110000", 110100, "王五");
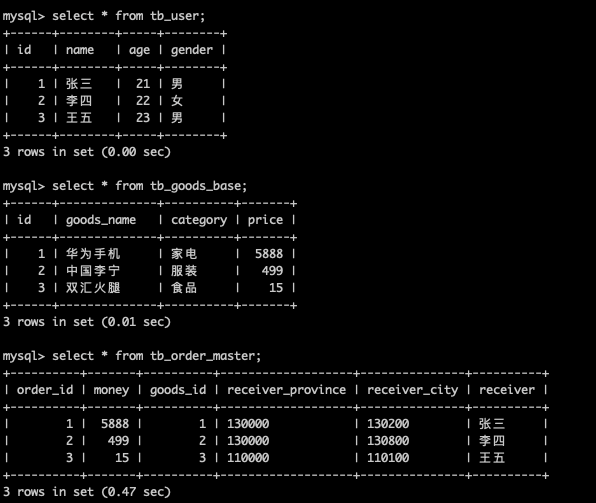
以上是對Mycat資料垂直分庫的建立表,插入資料和查詢資料的測試。
六、Mycat多表查詢測試
情況一:同一資料節點上的多表查詢
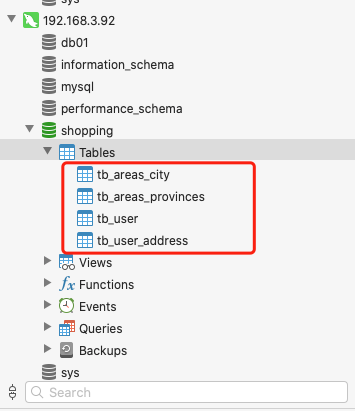
首先建立一個三個的表用於測試,同一資料節點內的多表查詢,tb_areas_provinces, tb_areas_city, tb_user_address 三個表都是在dn3資料節點上的。
create table tb_areas_provinces (id int auto_increment primary key, provinceid varchar(6), province varchar(20)); create table tb_areas_city (id int auto_increment primary key, cityid varchar(6), city varchar(20), provinceid varchar(6)); create table tb_user_address (id int auto_increment primary key, user_id int, province_id varchar(6), city_id varchar(6), address varchar(20));
說明1:根據分庫策略,建立的這三個測試表,都是屬於使用者和地址相關的資料,都在dn3資料節點上。
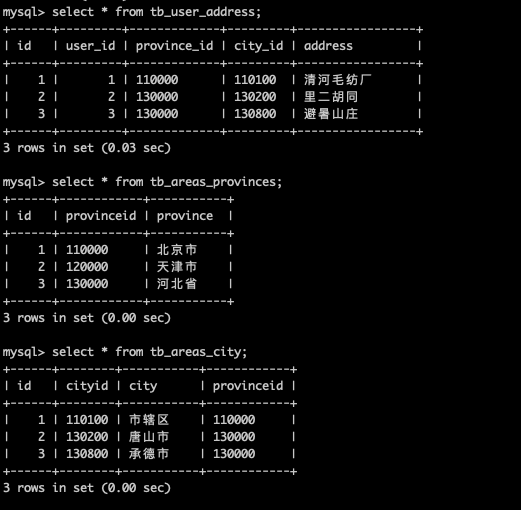
新增一些測試資料
insert into tb_areas_provinces (provinceid, province) values ("110000", "北京市"); insert into tb_areas_provinces (provinceid, province) values ("120000", "天津市"); insert into tb_areas_provinces (provinceid, province) values ("130000", "河北省"); insert into tb_areas_city (cityid, city, provinceid) values ("110100", "市轄區", "110000"); insert into tb_areas_city (cityid, city, provinceid) values ("130200", "唐山市", "130000"); insert into tb_areas_city (cityid, city, provinceid) values ("130800", "承德市", "130000"); insert into tb_user_address (user_id, province_id, city_id, address) values (1, "110000", "110100", "清河毛紡廠"); insert into tb_user_address (user_id, province_id, city_id, address) values (2, "130000", "130200", "裡二胡同"); insert into tb_user_address (user_id, province_id, city_id, address) values (3, "130000", "130800", "避暑山莊");
現多表查詢需求是:根據tb_user, tb_user_address表,tb_areas_provinces表和tb_areas_city表查出使用者的名字已經所在的省,市,已經詳細的地址:使用Mycat查詢
select u.name, p.province, c.city, ua.address from tb_user as u, tb_user_address as ua, tb_areas_provinces as p, tb_areas_city as c where u.id = ua.user_id and ua.province_id = p.provinceid and ua.city_id = c.cityid;

說明:同一資料節點內的多表聯合查詢在mycat中可以正確查出結果。
select o.order_id, o.receiver,p.province, c.city from tb_order_master as o, tb_areas_provinces as p, tb_areas_city as c where o.receive_province=p.provinceid and o.receiver_city=c.cityid;

這個時候就報錯了, 報錯的原因是:誇資料節點的多表查詢,在執行sql的時候,Mycat並不知道,將這條sql給哪一個資料節點處理。
解決方式:將一些資料量少,並且一旦確定了就很少改變的表,設定為全域性表,全域性表可以在每個資料節點上都能存取。而本案例中的省/市表就符合這個特性,中國每個城市的編碼一旦確定,幾乎就不會變化,這樣的資料表,我們就可以設定為全域性表。全域性表會存在每一個資料節點上。
如果要設定全域性表,只需要在schema.xml設定邏輯表的時候加上 type="global"引數即可
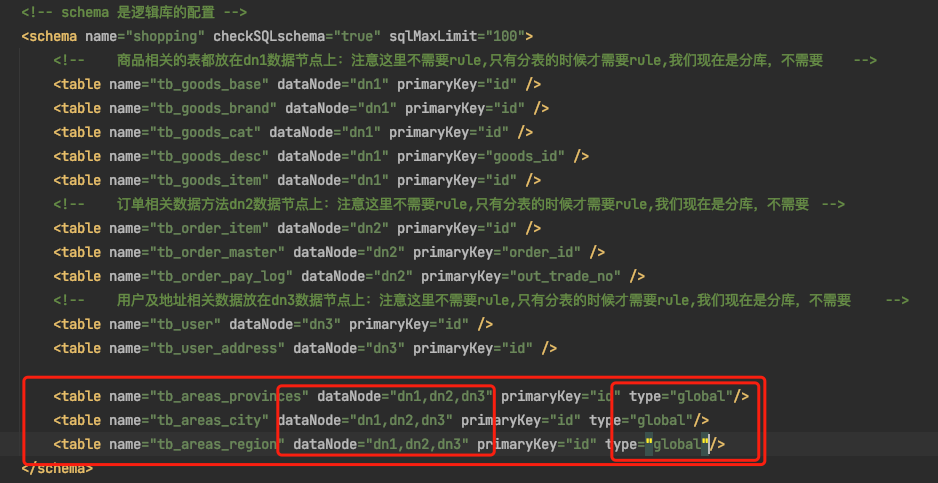
說明1: 因為省市相關的資料表需要在dn1,dn2,dn3 三個資料節點上,所以dataNode這裡要設定dn1,dn2,dn3三個節點
說明2:在table標籤內新增type="global"屬性
說明3:因為之前的areas的表,都要變成全域性表,所以需要資料清空在重新新增測試資料
說明4:因為修改了Mycat設定,所以需要重新啟動Mycat
重新建立tb_areas_provinces和tb_areas_city兩個表
create table tb_areas_provinces (id int auto_increment primary key, provinceid varchar(6), province varchar(20)); create table tb_areas_city (id int auto_increment primary key, cityid varchar(6), city varchar(20), provinceid varchar(6));

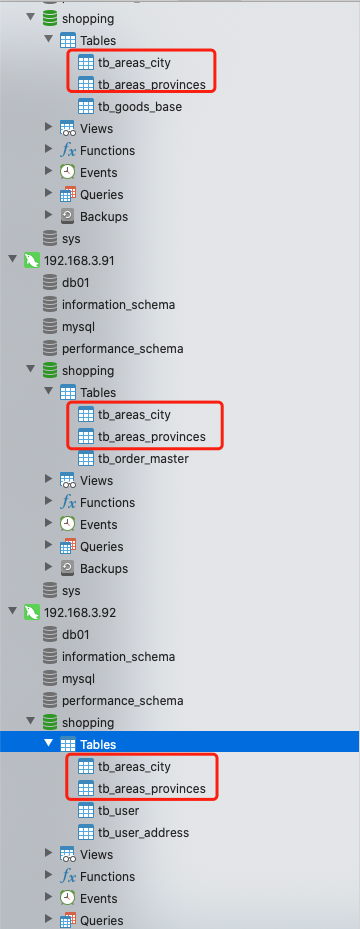
說明5:這時候就會發現tb_areas_procinces和tb_areas_city出現在了三個資料節點上
再次插入資料進行多表查詢測試:
insert into tb_areas_provinces (provinceid, province) values ("110000", "北京市"); insert into tb_areas_provinces (provinceid, province) values ("120000", "天津市"); insert into tb_areas_provinces (provinceid, province) values ("130000", "河北省"); insert into tb_areas_city (cityid, city, provinceid) values ("110100", "市轄區", "110000"); insert into tb_areas_city (cityid, city, provinceid) values ("130200", "唐山市", "130000"); insert into tb_areas_city (cityid, city, provinceid) values ("130800", "承德市", "130000");
會發現插入的這些測試資料,會在dn1,dn2,dn3的每個資料節點的表中都新增成功。
現在就可以順利的進行多表查詢了。

說明6:當全域性表中的資料發生改變的時候,每個資料節點下的表,也都會發生資料改變。
侯哥語錄:我曾經是一個職業教育者,現在是一個自由開發者。我希望我的分享可以和更多人一起進步。分享一段我喜歡的話給大家:"我所理解的自由不是想幹什麼就幹什麼,而是想不幹什麼就不幹什麼。當你還沒有能力說不得時候,就努力讓自己變得強大,擁有說不得權利。"