阿里雲AnalyticDB基於Flink CDC+Hudi實現多表全增量入湖實踐
湖倉一體(LakeHouse)是巨量資料領域的重要發展方向,提供了流批一體和湖倉結合的新場景。阿里雲AnalyticDB for MySQL基於 Apache Hudi 構建了新一代的湖倉平臺,提供紀錄檔、CDC等多種資料來源一鍵入湖,在離線計算引擎融合分析等能力。本文將主要介紹AnalyticDB for MySQL基於Apache Hudi實現多表CDC全增量入湖的經驗與實踐。
1. 背景簡介
1.1. 多表CDC入湖背景介紹
客戶在使用資料湖、傳統資料倉儲的過程中,常常會遇到以下業務痛點:
-
全量建倉或直連分析對源庫壓力較大,需要解除安裝線上壓力規避故障
-
建倉延遲較長(T+1天),需要T+10m的低延遲入湖
-
海量資料在事務庫或傳統數倉中儲存成本高,需要低成本歸檔
-
傳統資料湖存在不支援更新/小檔案較多等缺點
-
自建巨量資料資料平臺運維成本高,需要產品化、雲原生、一體化的方案
-
常見數倉的儲存不開放,需要自建能力、開源可控
-
其他痛點和需求……
針對這些業務痛點,AnalyticDB MySQL 資料管道元件(AnalyticDB Pipeline Service) 基於Apache Hudi 實現了多表CDC全增量入湖,提供入湖和分析過程中高效的全量資料匯入,增量資料實時寫入、ACID事務和多版本、小檔案自動合併優化、元資訊校驗和自動進化、高效的列式分析格式、高效的索引優化、超大分割區表儲存等等能力,很好地解決了上述提到的客戶痛點。
1.2. Apache Hudi簡介
AnalyticDB MySQL選擇了Apache Hudi作為CDC入湖以及紀錄檔入湖的儲存底座。回顧 Hudi 的出現主要針對性解決Uber巨量資料系統中存在的以下痛點:
-
HDFS的可延伸性限制。大量的小檔案會使得HDFS的Name Node壓力很大,NameNode節點成為HDFS的瓶頸。
-
HDFS上更快的資料處理。Uber不再滿足於T+1的資料延遲。
-
支援Hadoop + Parquet的更新與刪除。Uber的資料大多按天分割區,舊資料不再修改,T+1 Snapshot讀源端的方式不夠高效,需要支援更新於刪除提高匯入效率。
-
更快的ETL和資料建模。原本模式下,下游的資料處理任務也必須全量地讀取資料湖的資料,Uber希望提供能力使得下游可以唯讀取感興趣的增量資料。
基於以上的設計目標,Uber公司構建了Hudi(Hadoop Upserts Deletes and Incrementals)並將其捐贈給Apache基金會。從名字可以看出,Hudi最初的核心能力是高效的更新刪除,以及增量讀取Api。Hudi和「資料湖三劍客」中的其他兩位(Iceberg,DeltaLake)整體功能和架構類似,都大體由以下三個部分組成:
-
需要儲存的原始資料(Data Objects)
-
用於提供upsert功能的索引資料 (Auxiliary Data)
-
以及用於管理資料集的後設資料(Metadata)
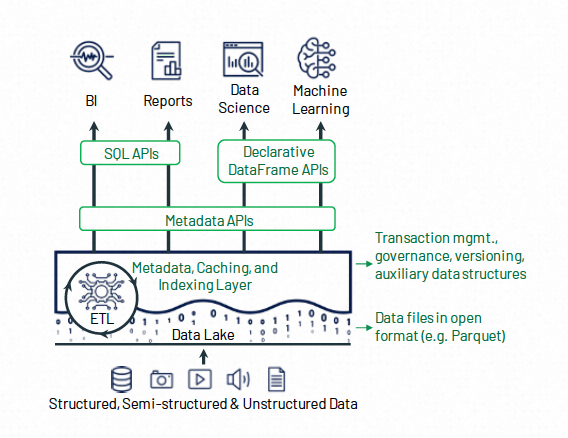
在儲存的原始資料層面,Lakehouse一般採用開源的列存格式(Parquet,ORC等),這方面沒有太大的差異。 在輔助資料層面,Hudi提供了比較高效的寫入索引(Bloomfilter, Bucket Index) ,使得其更加適合CDC大量更新的場景。
1.3. 業界方案簡介
阿里雲AnalyticDB團隊在基於Hudi構建多表CDC入湖之前,也調研了業界的一些實現作為參考,這裡簡單介紹一下一些業界的解決方案。
1.3.1. Spark/Flink + Hudi 單表入湖
使用Hudi實現單表端到端CDC資料入湖的整體架構如圖所示:
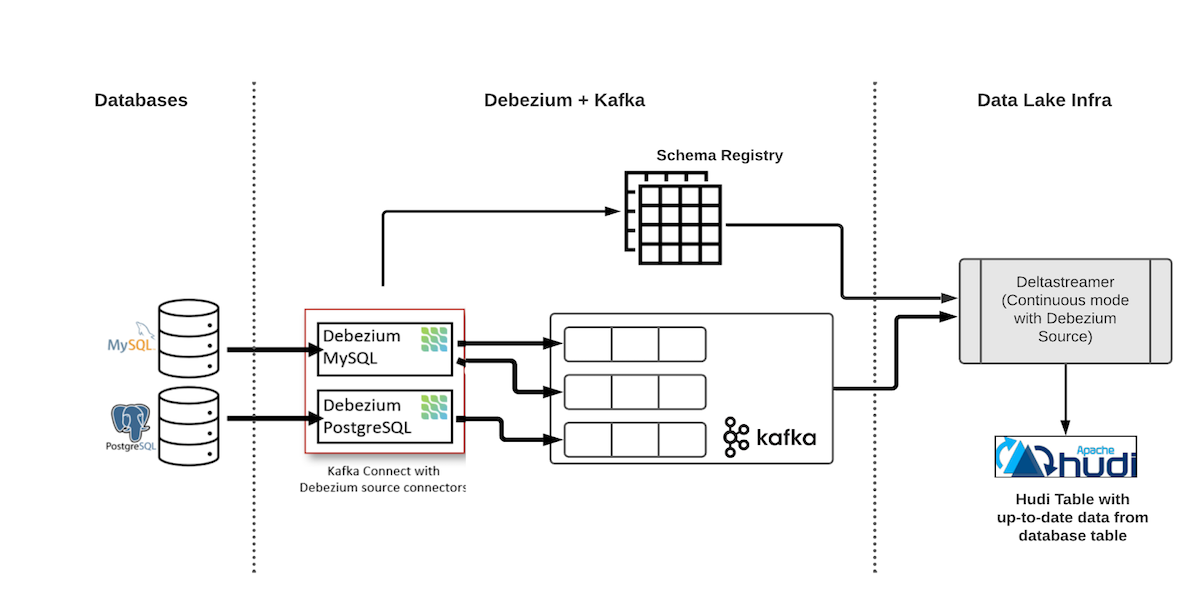
圖中的第一個元件是Debezium deployment,它由 Kafka 叢集、Schema Registry(Confluence 或 Apicurio)和 Debezium 聯結器組成。會源源不斷讀取資料庫的binlog資料並將其寫入到Kafka中。
圖中的下游則是Hudi的消費端,這裡我們選用Hudi提供的DeltaStreamer元件,他可以消費Kafka中的資料並寫入到Hudi資料湖中。業界實現類似單表CDC入湖,可以將上述方案中的binlog源從Debezium + Kafka替換成Flink CDC + Kafka等等,入湖使用的計算引擎也可以根據實際情況使用Spark/Flink。
這種方式可以很好地同步CDC的資料,但是存在一個問題就是每一張表都需要建立一個單獨的入湖鏈路,如果想要同步資料庫中的多張表,則需要建立多個同步鏈路。這樣的實現存在幾個問題:
-
同時存在多條入湖鏈路提高了運維難度
-
動態增加刪除庫表比較麻煩
-
對於資料量小/更新不頻繁的表,也需要單獨建立一條同步鏈路,造成了資源浪費。
目前,Hudi也支援一條鏈路多表入湖,但還不夠成熟,不足以應用於生產,具體的使用可以參考這篇檔案。
1.3.2. Flink VVP 多表入湖
阿里雲實時計算Flink版(即Flink VVP) 是一種全託管Serverless的Flink雲服務,開箱即用,計費靈活。具備一站式開發運維管理平臺,支援作業開發、資料偵錯、執行與監控、自動調優、智慧診斷等全生命週期能力。
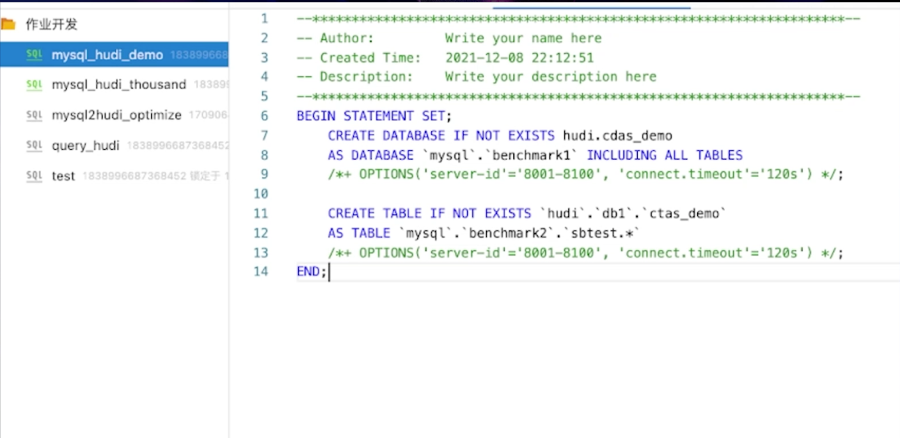
阿里雲Flink產品提供了多表入湖的能力(binlog -> flink cdc -> 下游消費端),支援在一個Flink任務中同時消費多張表的binlog並寫入下游消費端:
-
Flink SQL執行create table as table,可以把MySQL庫下所有匹配正規表示式的表同步到Hudi單表,是多對一的對映關係,會做分庫分表的合併。
-
Flink SQL執行create database as database,可以把 MySQL庫下所有的表結構和表資料一鍵同步到下游資料庫,暫時不支援hudi表,計劃支援中。
啟動任務後的拓撲如下,一個源端binlog source運算元將資料分發到下游所有Hudi Sink運算元上。
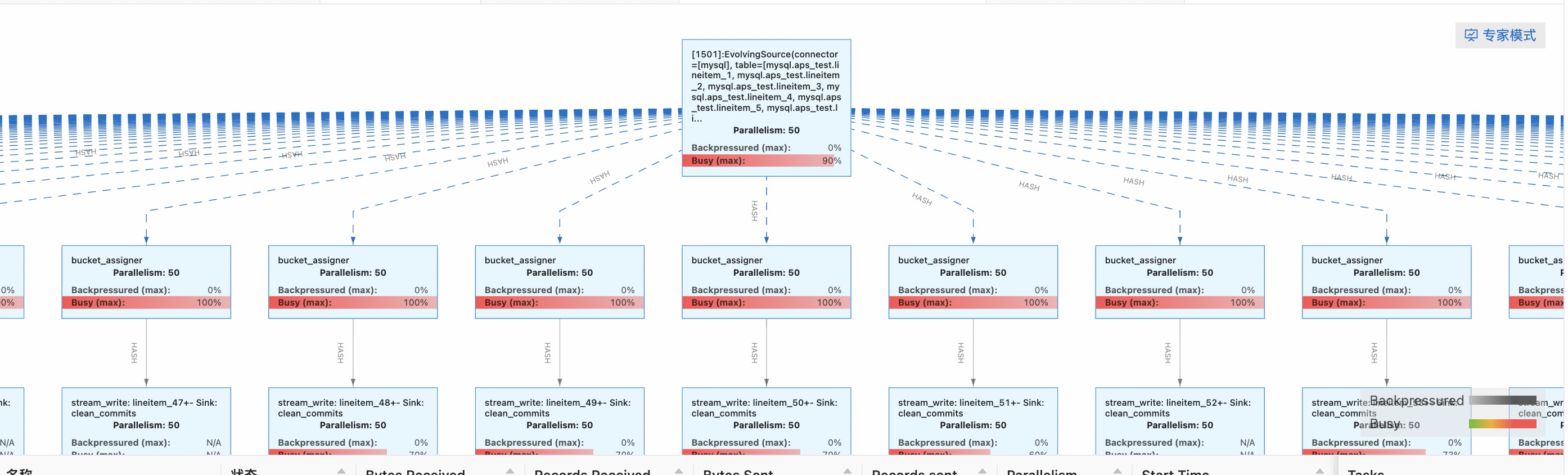
通過Flink VVP可以比較簡單地實現多表CDC入湖,然而,這個方案仍然存在以下的一些問題:
-
沒有成熟的產品化的入湖管理介面,如增刪庫表,修改設定等需要直接操作Flink作業,新增統一的庫表名字首需要寫sql hint。(VVP更多的還是一個全託管Flink平臺而不是一個資料湖產品)
-
只提供了Flink的部署形態,在不進行額外比較複雜的設定的情況下,Compaction/Clean等TableService必須執行在鏈路內,影響寫入的效能和穩定性。
綜合考慮後,我們決定採用類似Flink VVP多表CDC入湖的方案,在AnalyticDB MySQL上提供產品化的多表CDC全增量入湖的功能。
2. 基於Flink CDC + Hudi 實現多表CDC入湖
2.1. 整體架構
AnalyticDB MySQL多表CDC入湖的主要設計目標如下:
-
支援一鍵啟動入湖任務消費多表資料寫入Hudi,降低客戶管理成本。
-
提供產品化管理介面,使用者可以通過介面啟停編輯入湖任務,提供庫表名統一字首,主鍵對映等產品化功能。
-
儘可能降低入湖成本,減少入湖過程中需要部署的元件。
基於這樣的設計目標,我們初步選擇了以Flink CDC作為binlog和全量資料來源,並且不經過任何中間快取,直接寫入Hudi的技術方案。

Flink CDC 是 Apache Flink 的一個Source Connector,可以從 MySQL等資料庫讀取快照資料和增量資料。在Flink CDC 2.0 中,實現了全程無鎖讀取,全量階段並行讀取以及斷點續傳的優化,更好地達到了「流批一體」。
使用了Flink CDC的情況下,我們不需要擔心全量增量的切換,可以使用統一的Hudi Upsert介面進行資料消費,Flink CDC會負責多表全增量切換和位點管理,降低了任務管理的負擔。而Hudi並不支援原生消費多表資料,所以需要開發一套程式碼,將Flink CDC的資料寫入到下游多個Hudi表。
這樣實現的好處是:
-
鏈路短,需要維護的元件少,成本低(不需要依賴獨立部署的binlog源元件如kafka,阿里雲DTS等)
-
業界有方案可參考,Flink CDC + Hudi 單表入湖是一個比較成熟的解決方案,阿里雲VVP也已經支援了Flink多表寫入Hudi。
下面詳細介紹一下 AnalyticDB MySQL 基於這樣架構選型的一些實踐經驗。
2.2. Flink CDC+ Hudi 支援動態Schema變更
目前通過Flink將CDC資料寫入Hudi的流程為
-
資料消費:源端使用CDC Client消費binlog資料,並進行反序列化,過濾等操作。
-
資料轉換:將CDC格式根據特定Schema資料轉換為Hudi支援的格式,比如Avro格式、Parquet格式、Json格式。
-
資料寫入:將資料寫入Hudi,部署在TM的多個Hudi Write Client,使用相同的Schema將資料寫入目標表。
-
資料提交:由部署在Flink Job Manager的Hudi Coordinator進行單點提交,Commit後設資料包括本次提交的檔案、寫入Schema等資訊。
其中,步驟2-4都要用到使用寫入Schema,在目前的實現中都是在任務部署前確定好的。同時在任務執行時沒有提供動態變更Schema的能力。
針對這個問題,我們設計實現了一套可以動態無干預更新Flink Hudi入湖鏈路Schema的方案。整體思路為在Flink CDC中識別DDL binlog事件,遇到DDL事件時,停止消費增量資料,等待savepoint完成後以新的schema重新啟動任務。
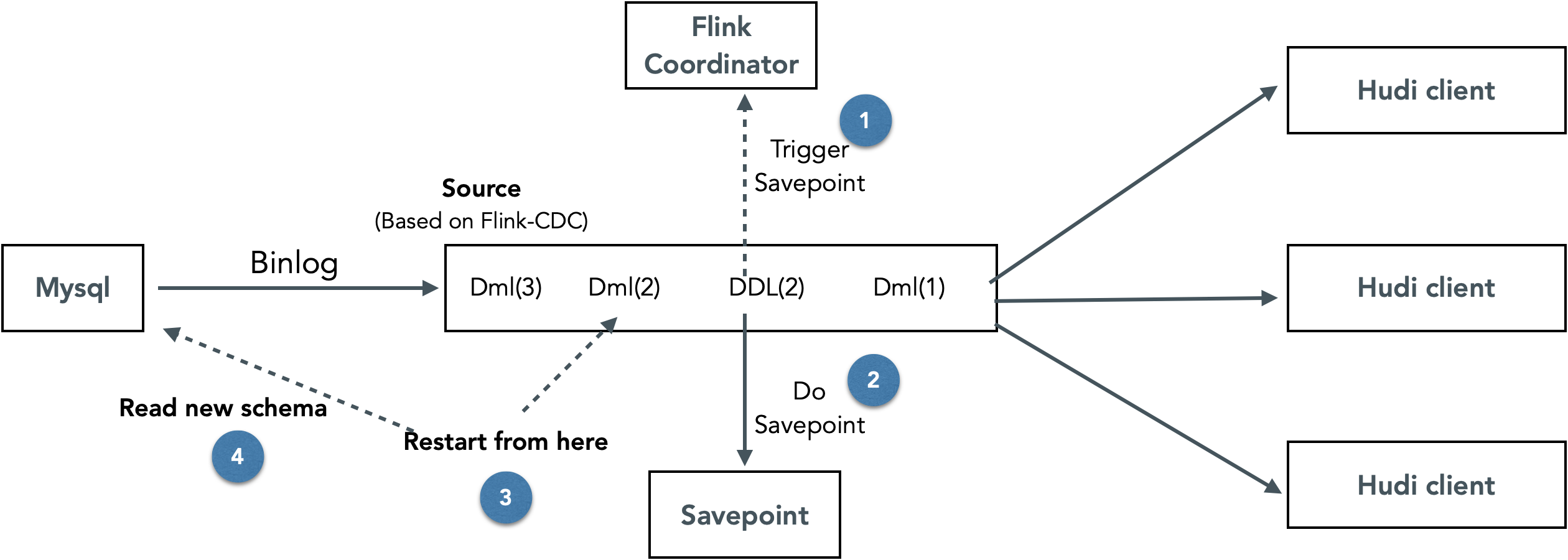
這樣實現的好處是可以動態更新鏈路中的Schema,不需要人工干預。缺點是需要停止所有庫表的消費再重啟,DDL頻繁的情況下對鏈路效能的影響很大。
2.3. Flink多表讀寫效能調優
2.3.1. Flink CDC + Hudi Bucket Index 全量匯入調優
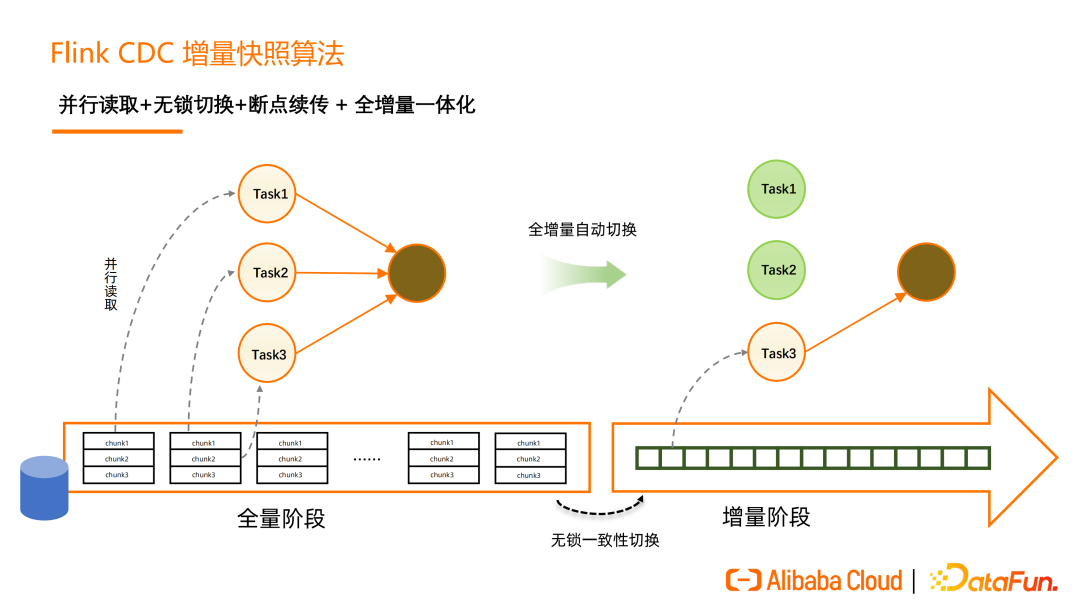
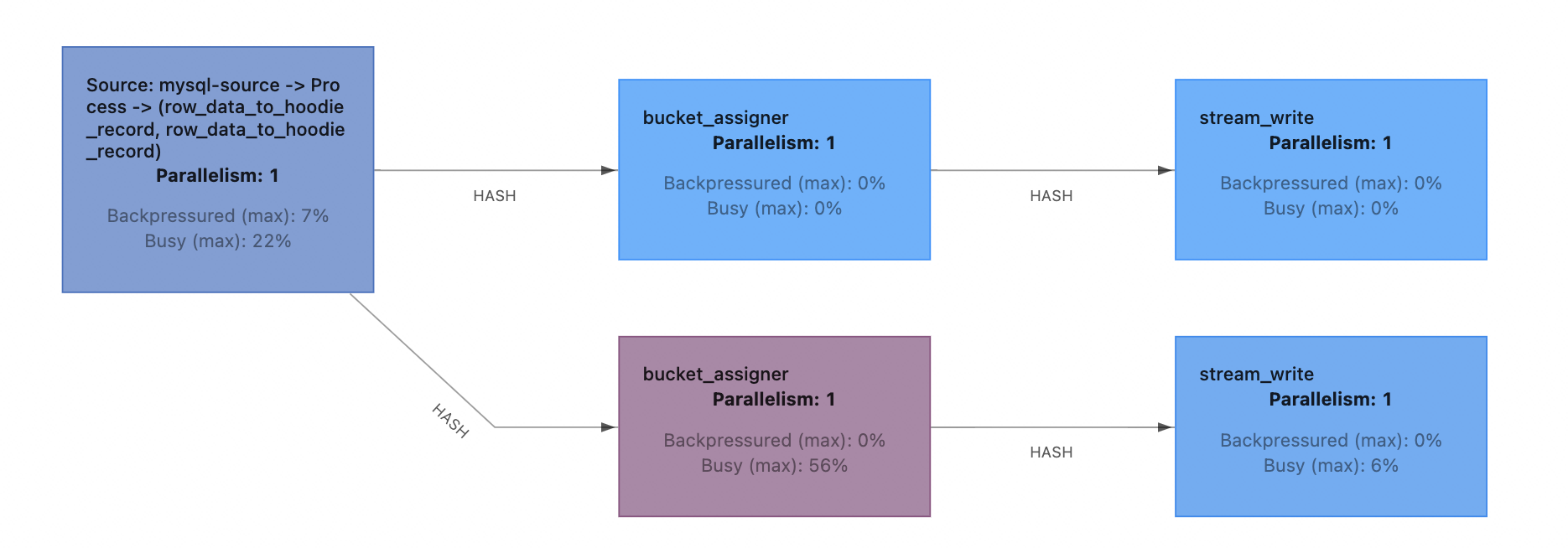
這裡首先簡單介紹一下Flink CDC 2.0 全量讀取 + 全增量切換的流程。在全量階段,Flink CDC會將單表根據並行度劃分為多個chunk並分發到TaskManager並行讀取,全量讀取完成後可以在保證一致性的情況下,實現無鎖切換到增量,真正做到「流批一體」。
在匯入的過程中,我們發現了兩個問題:
1)全量階段寫入的資料為log檔案,但為加速查詢,需要compact成Parquet,帶來寫放大
由於全量和增量的切換Hudi是沒有感知的,所以為了實現去重,在全量階段我們也必須使用Hudi的Upsert介面,而Hudi Bucket Index的Uspert會產生log檔案,需要進行一次Compaction才能得到parquet檔案,造成一定的寫放大。並且如果全量匯入的過程中compaction多次,寫放大會更加嚴重。
那麼能不能犧牲讀取效能,只寫入log檔案呢? 答案也是否定的,log檔案增多不僅會降低讀取效能,也會降低oss file listing的效能,使得寫入也變慢(寫入的時候會list當前file slice中的log和base檔案)
解決方法:調大Ckp間隔或者全量增量使用不同的compaction策略解決(全量階段不做compaction)
2)Flink 全量匯入表之間為序列,而寫Hudi的最大並行為Bucket數,有時無法充分利用叢集並行資源
Flink CDC全量匯入的是表內並行,表之間序列。匯入單表的時候,如果讀+寫的並行小於叢集的並行數,會造成資源浪費,在叢集可用資源較多的時候,可能需要適當調高Hudi的Bucket數以提高寫入並行 。而小表並不需要很大的並行即可匯入完成,在序列匯入多個小表的時候一般會有資源浪費情況。如果可以支援小表並行匯入,全量匯入的效能會有比較好的提升。
解決辦法:適當的調大Hudi bucket數來提高匯入效能。
2.3.2. Flink CDC + Hudi Bucket Index 增量調優
1) Checkpoint 反壓調優
在全增量匯入的過程中,我們發現鏈路Hudi Ckp經常反壓引起寫入抖動:
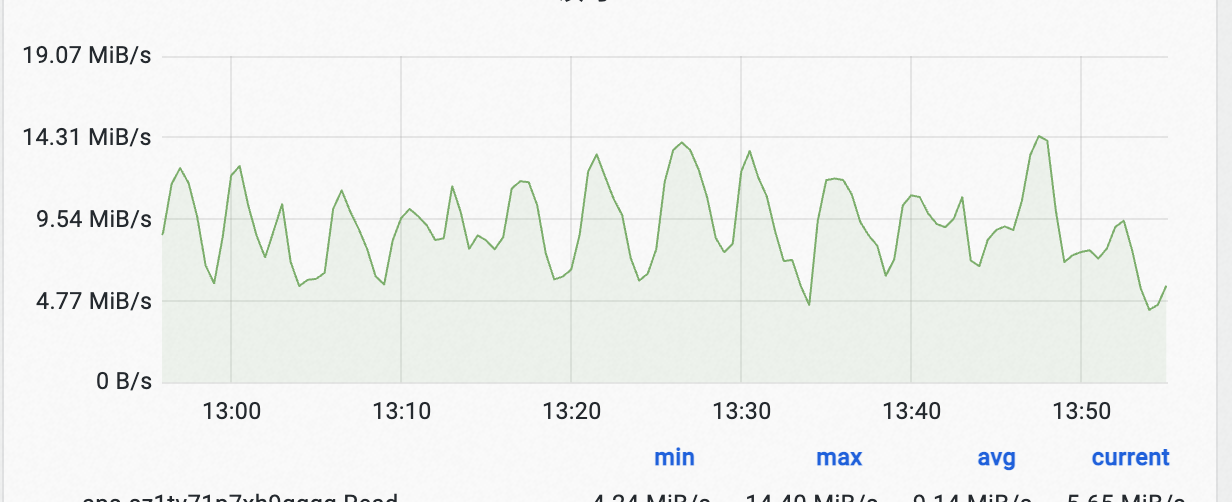
可以發現寫入流量的波動非常大。
我們詳細排查了寫入鏈路,發現反壓主要是因為Hudi Ckp時會flush資料,在流量比較大時候,可能需要在一個ckp間隔內flush 3G資料,造成寫入停頓。
解決這個問題的思路就是調小Hudi Stream Write的buffer大小(即write.task.max.size)將Checkpoint視窗期間flush資料的壓力平攤到平時。
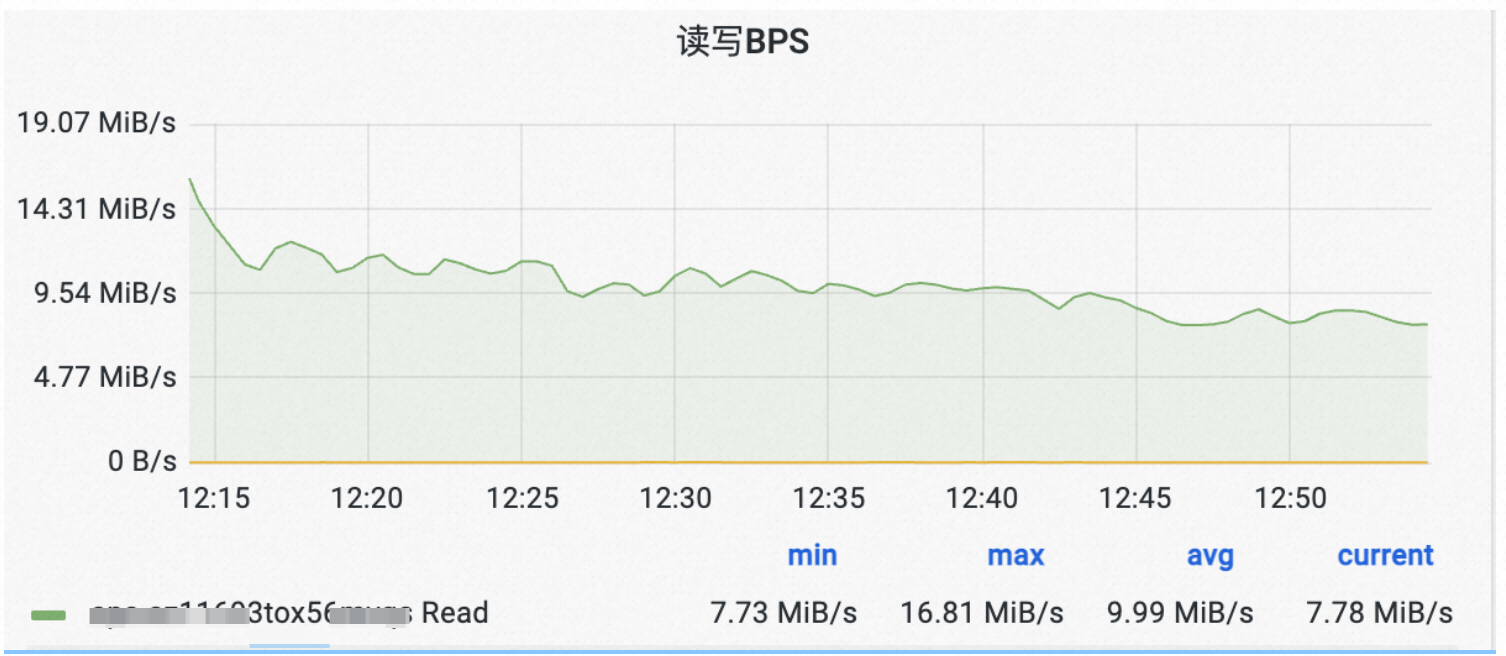
從上圖可以看到,調整了buffer size後,因checkpoint造成了反壓引起的寫入流量變化得到了很好的緩解。
為了緩解Ckp的反壓,我們還做了其他的一些優化:
-
調小Hudi bucket number,減少Ckp期間需要flush的檔案個數(這個和全量階段調大bucket數是衝突的,需要權衡選擇)
-
使用鏈路外Spark作業及時執行Compaction,避免積累log檔案過多導致寫log時list files的開銷過大
2) 提供合適的寫入Metrics幫助排查效能問題
在調優flink鏈路的過程中,我們發現了flink hudi寫入相關的metrics缺失的比較嚴重,排查時需要通過比較麻煩的手段分析效能(如觀察現場紀錄檔,dump記憶體、做cpu profiling等)。於是,我們在內部開發了一套Flink Stream Write的 Metrics 指標幫助我們可以快速的定位效能問題。
指標主要包括:
-
當前Stream Write運算元佔據的buffer大小
-
Flush Buffer耗時
-
請求OSS建立檔案耗時
-
當前活躍的寫入檔案數
-
....
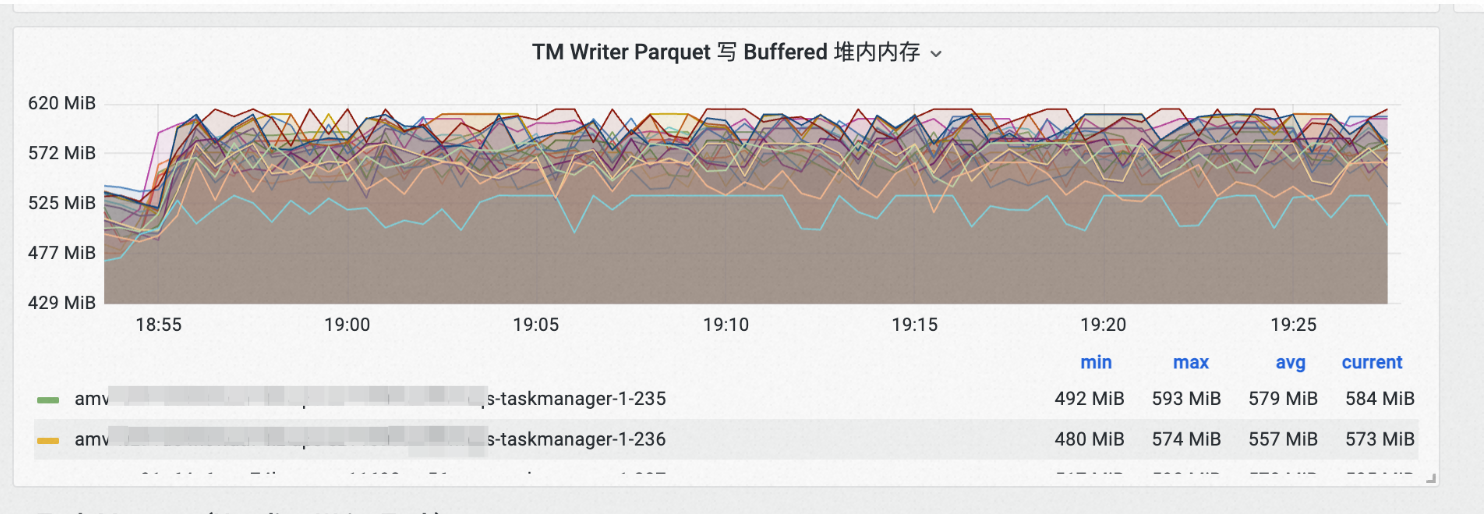
Stream Write/Append Write 佔據的堆內記憶體Buffer大小統計:
Parquet/Avro log Flush到磁碟耗時:
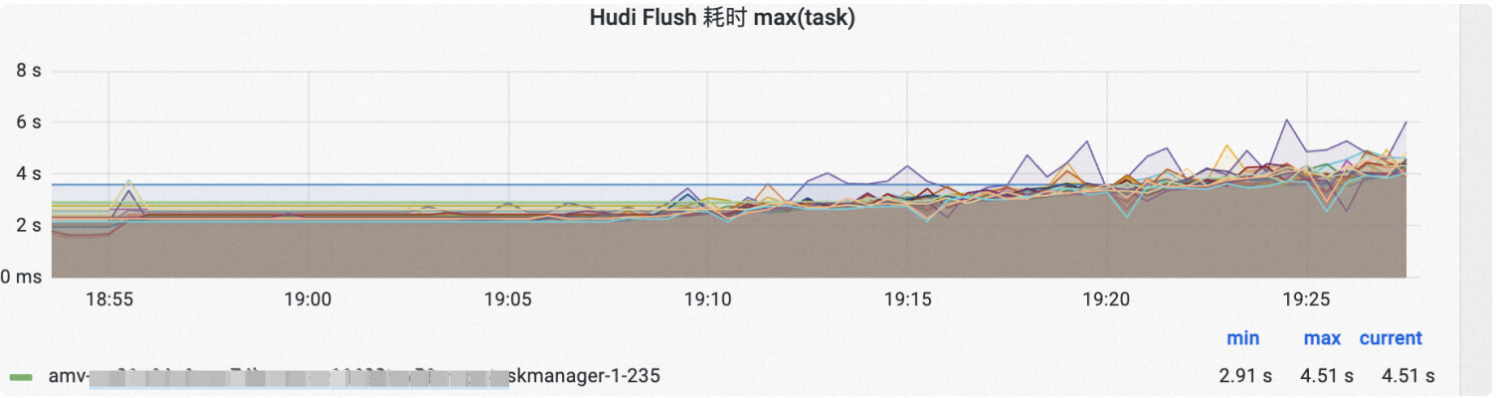
通過指標值的變化可以幫助快速定位問題,比如上圖Hudi flush的耗時有一個上揚的趨勢,我們很快定位發現了因為Compaction做得不及時,導致log檔案積壓,使得file listing速度減慢。在調大Compaction資源後,Flush耗時可以保持平穩。
Flink-Hudi Metrics相關的程式碼我們也在持續貢獻到社群,具體可以參考HUDI-2141。
3) Compaction調優
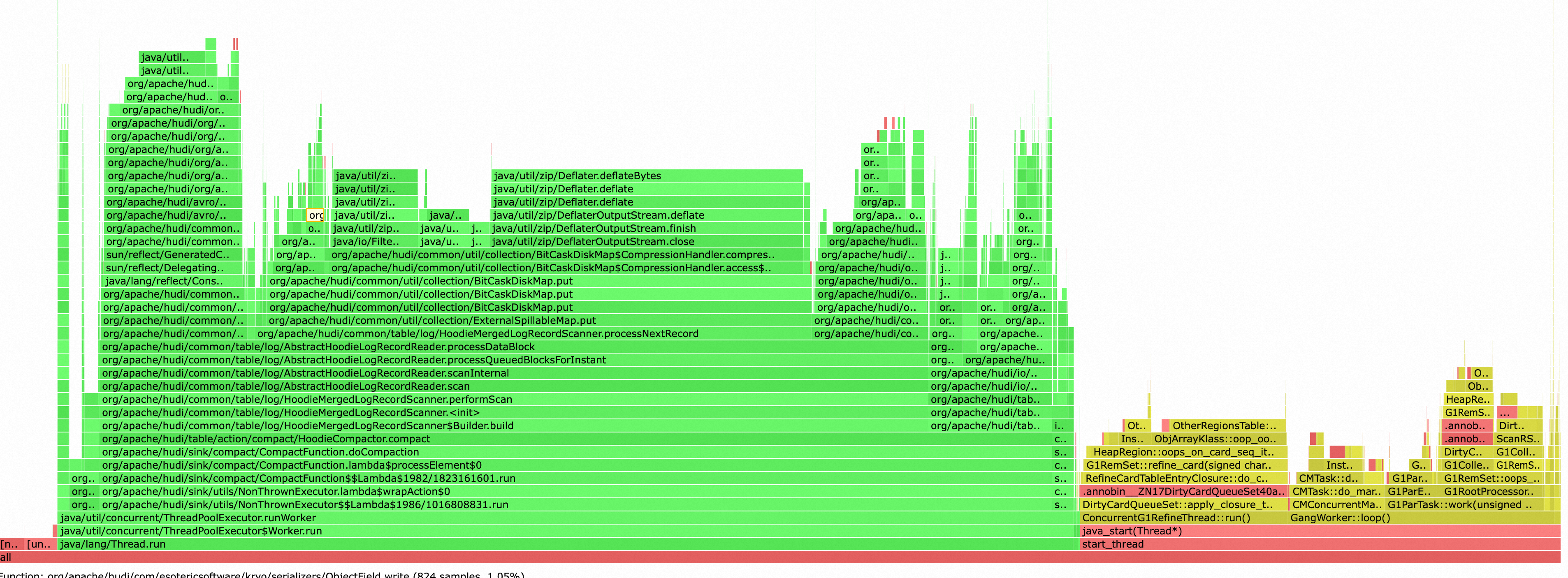
為了簡化設定,我們一開始採用了在鏈路內Compaction的方案,但是我們很快就發現了Compaction對寫入資源的搶佔非常嚴重,並且負載不穩定,很大影響了寫入鏈路的效能和穩定性。如下圖,Compaction和GC幾乎吃滿了Task Manager的Cpu資源。
於是,我們採用了TableService和寫入鏈路分離部署的策略,使用Spark離線任務執行TableService,使得TableService和寫入鏈路相互不影響。並且,Table Service的消耗的是Serverless資源,按需收費。寫入鏈路因為不用做Compaction,可以保持一個比較小的資源,整體來看資源利用率和效能穩定性都得到了很好的提升。
為了方便管理資料庫內多表的TableService,我們開發了一個可以在單個Spark任務內執行多表的多個TableService的實用工具,目前已經貢獻到社群,可以參見PR。
3. Flink CDC Hudi 多表入湖總結
經過我們多輪的開發和調優,Flink CDC 多表寫入 Hudi 達到了一個基本可用的狀態。其中,我們認為比較關鍵的穩定性/效能優化是
-
將Compaction從寫入鏈路獨立出去,提高寫入和Compaction的資源利用率
-
開發了一套Flink Hudi Metrics系統,結合原始碼和紀錄檔精細化調優Hoodie Stream Write。
但是,這套架構方案仍然存在以下的一些無法簡單解決的問題:
-
Flink Hudi不支援schema evolution。Hudi轉換Flink Row到HoodieRecord所用的schema在拓撲被建立時固定,這意味著每次DDL都需要重啟Flink鏈路,影響增量消費。而支援不停止任務動態變更Schema在Flink Hudi場景經POC,改造難度比較大。
-
多表同步需要較大的資源開銷,對於沒有資料的表,仍然需要維護他們的運算元,造成不必要的開銷。
-
新增同步表和摘除同步表需要重啟鏈路。Flink任務拓撲在任務啟動時固定,新增表/刪除表都需要更改拓撲重啟鏈路,影響增量消費。
-
直接讀取源庫/binlog對源庫壓力大,多並行讀取binlog容易打掛源庫,也使得binlog client不穩定。並且由於沒有中間快取,一旦binlog位點過期,資料需要重新匯入。
-
全量同步同一時刻只能並行同步一張表,對於小表的匯入不夠高效,大表也有可能因為並行設定較小而利用不滿資源。
-
Hudi的Bucket數對全量匯入和增量Upsert寫入的效能影響很大,但是使用Flink CDC + Hudi的框架目前沒辦法為資料庫裡不同的表決定不同的Bucket數,使得這個值難以權衡。
如果繼續基於這套方案實現多表CDC入湖,我們也可以嘗試從下面的一些方向著手:
-
優化Flink CDC全量匯入,支援多表並行匯入,支援匯入時對源表資料量進行sample以動態決定Hudi的Bucket Index Number。解決上述問題5,問題6。
-
引入Hudi的Consistent Hashing Bucket Index,從Hudi端解決bucket index數無法動態變更的問題,參考HUDI-6329。解決上述問題5,問題6。
-
引入一個新的binlog快取元件(自己搭建或者使用雲上成熟產品),下游多個鏈路從快取佇列中讀取binlog,而不是直接存取源庫。解決上述問題4。
-
Flink支援動態拓撲,或者Hudi支援動態變更Schema。解決上述問題1,2,3。
不過,基於經過內部討論和驗證,我們認為繼續基於Flink + Hudi框架實現多表CDC全增量入湖難度較大,針對這個場景,應該更換為Spark引擎。主要的一些考慮如下。
-
上述討論的Flink-Hudi優化方向,工程量和難度都比較大,有些涉及到了核心機制的變動。
-
團隊內部對Spark全增量多表入湖有一定的積累,線上已經有了長期穩定執行的客戶案例。
-
基於Spark引擎的功能豐富度更好,如Spark微批語意可以支援隱式的動態Schema變更,Table Service也更適合使用Spark批作業執行。
在我們後續的實踐中,也證實了我們的判斷是正確的。引擎更換為Spark後,多表CDC全增量入湖的功能豐富程度,擴充套件性,效能和穩定性都得到了很好的提升。我們將在之後的文章中介紹我們基於Spark+Hudi實現多表CDC全增量的實踐,也歡迎讀者們關注。
4. 參考資料
PS:如果您覺得閱讀本文對您有幫助,請點一下「推薦」按鈕,您的「推薦」,將會是我不竭的動力!
作者:leesf 掌控之中,才會成功;掌控之外,註定失敗。
出處:http://www.cnblogs.com/leesf456/
本文版權歸作者和部落格園共有,歡迎轉載,但未經作者同意必須保留此段宣告,且在文章頁面明顯位置給出原文連線,否則保留追究法律責任的權利。
如果覺得本文對您有幫助,您可以請我喝杯咖啡!

