MongoDB中的分散式叢集架構
MongoDB 中的分散式叢集架構
前言
前面我們瞭解了 MongoDB 中的索引,事務,鎖等知識點。線上使用的 MongoDB 大部分的場景我們都會考慮使用分散式結構,這裡我們來了解一下 MongoDB 中的分散式架構。
MongoDB 中常用的分散式架構有下面幾種:
1、Replica Set 副本集模式:一個 Primary 節點用於寫入資料,其它的 Secondary 節點用於查詢資料,適合讀寫少的場景,是目前較為主流的架構方式,Primary 節點掛了,會自動從 Secondary 節點選出新的 Primary 節點,提供資料寫入操作;
2、Master-Slaver 主從副本的模式:也是主節點寫入,資料同步到 Slave 節點,Slave 節點提供資料查詢,最大的問題就是可用性差,MongoDB 3.6 起已不推薦使用主從模式,自 MongoDB 3.2 起,分片群集元件已棄用主從複製。因為 Master-Slave 其中 Master 宕機後不能自動恢復,只能靠人為操作,可靠性也差,操作不當就存在丟資料的風險,這種模式被 Replica Set 所替代 ;
3、Sharding 分片模式:將不同的資料分配在不同的機器中,也就是資料的橫向擴充套件,單個機器只儲存整個資料中的一部分,這樣通過橫向增加機器的數量來提高叢集的儲存和計算能力。
因為 Master-Slaver 模式已經在新版本中棄用了,下面主要來介紹下 Replica Set 模式和 Sharding 模式。
Replica Set 副本集模式
MongoDB 中的 Replica Set 副本集模式,可以簡單理解為一主多從的叢集,包括一個主節點(primary)和多個副本節點(Secondaries)。
主節點只有一個,所有的寫操作都在主節點中進行,副本節點可以有多個,通過同步主節點的操作紀錄檔(oplog)來備份主節點資料。
在主節點掛掉之後,有選舉節點功能會自動從從節點中選出一個新的主節點,如果一個從節點,從節點也會自動從叢集中剔除,保證叢集的資料讀操作不受影響。
搭建一個副本集叢集最少需要三個節點:一個主節點,兩個備份節點,如果三個節點分佈合理,基本可以保證線上資料 99.9% 安全。
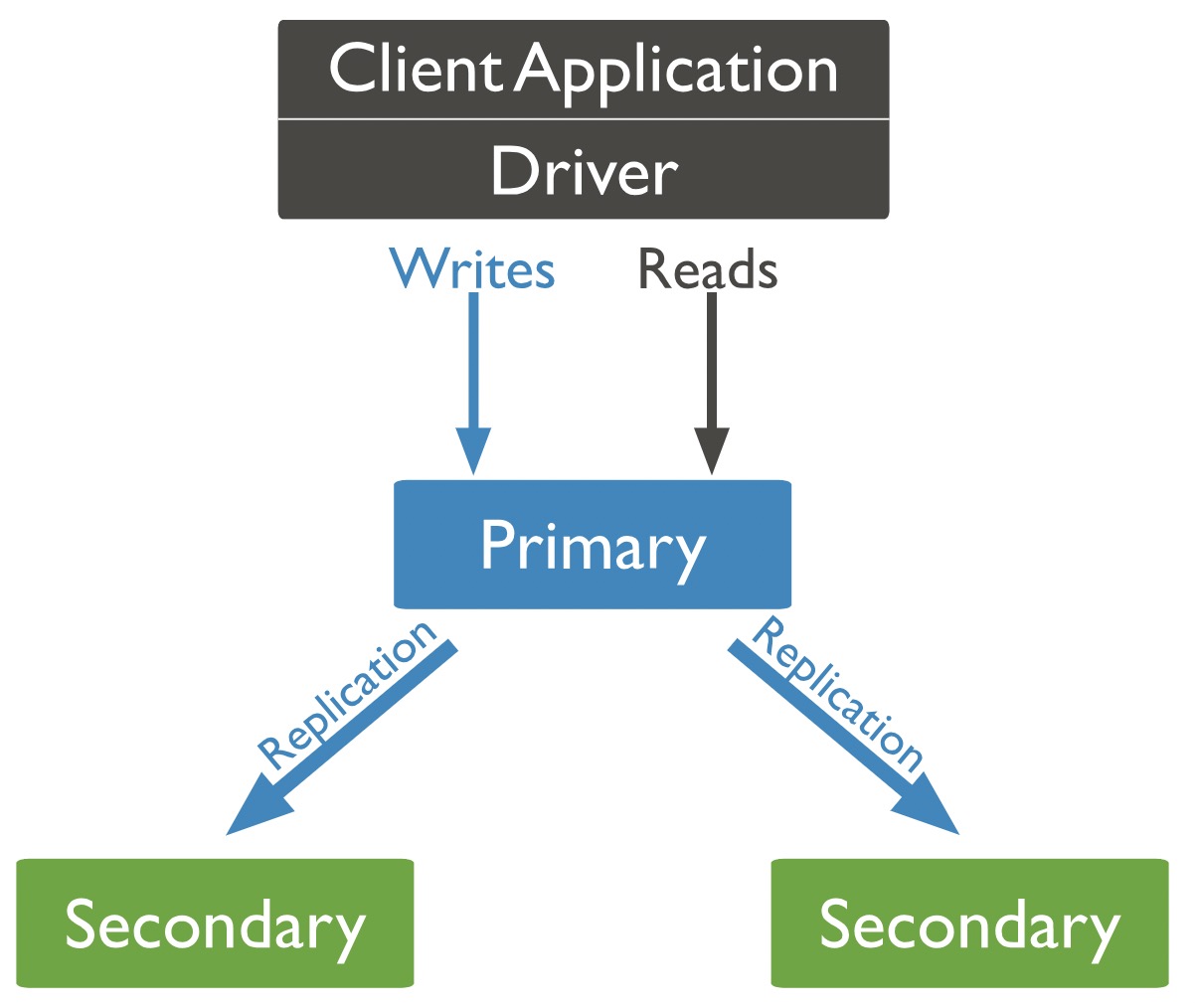
在叢集只有是三個節點的情況下,當主節點超過設定的 electionTimeoutMillis 時間段(預設情況下為10 秒)內未與集合中的其他成員進行通訊時,主節點就會被認為是異常了,兩個副本節點也會進行選舉,重新選出一個新的主節點。
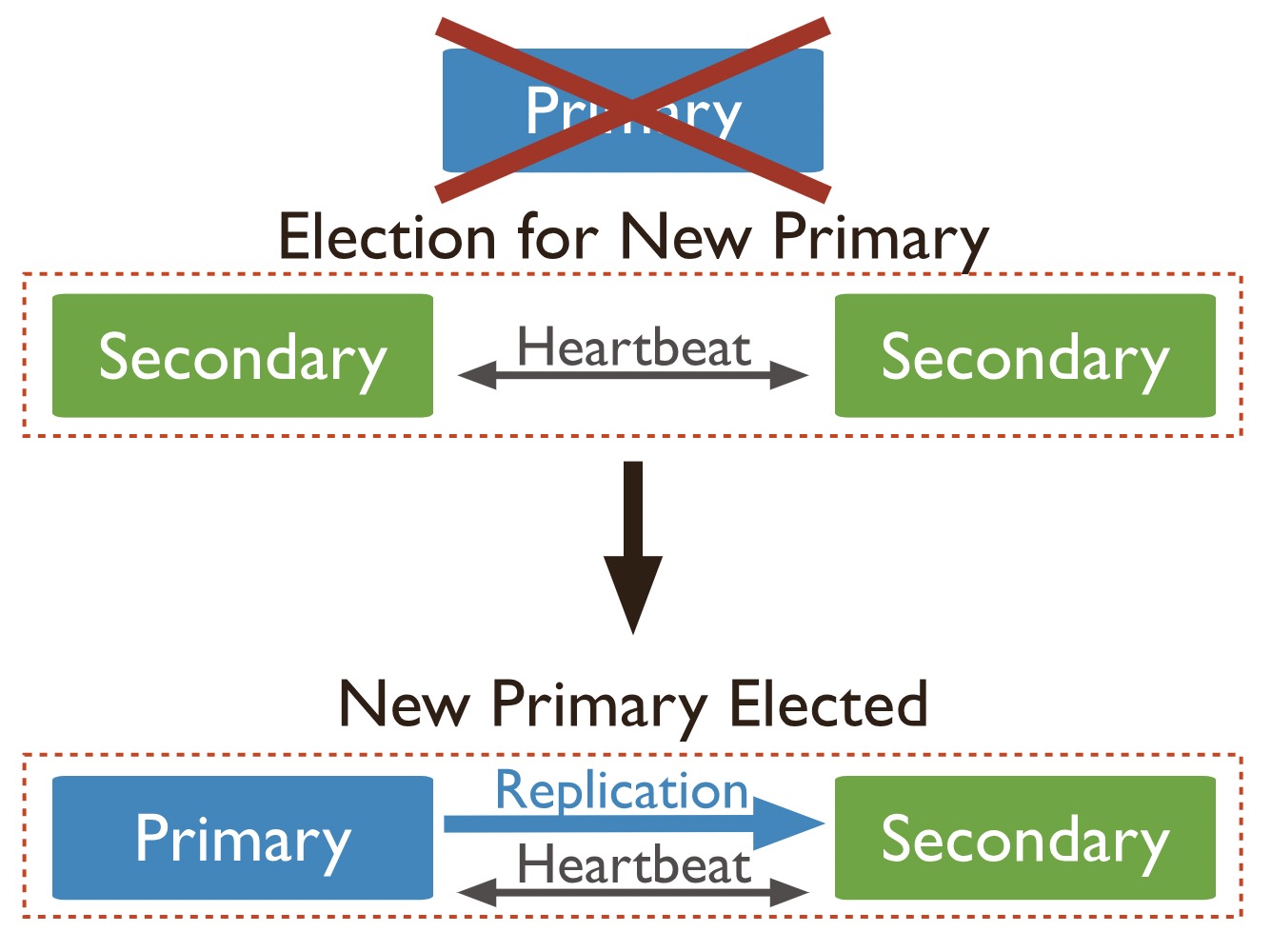
在預設複製設定的情況下,從一個叢集開始選舉新主節點到選舉完成的中間時間通常不超過 12 秒。中間包括將主節點標記不可用,發起並完成選舉所需要的時間。在選舉的過程中,就意味著叢集暫時不能提供寫入操作,時間越久叢集不可寫入的時間也就是越久。
關於副本節點的屬性,這裡來主要的介紹下:priority、hidden、slaveDelay、tags、votes。
- priority
對於副本節點,可以通過該屬性增大或者減小該節點被選舉為主節點的可能性,取值範圍是 0-1000(如果是arbiters,則取值只有0或者1),資料越大,成為主節點的可能性越大,如果被設定為0,那麼他就不能被選舉成為主節點,而且也不能主動發起選舉。
比如說叢集中的某幾臺機器設定較高,希望主節點主要在這幾臺機器中產生,那麼我們就可以通過設定 priority 的大小來實現。
- hidden
隱藏節點可以從主節點同步資料,但對使用者端不可見,在mongo shell 執行 db.isMaster() 方法也不會展示該節點,隱藏節點必須Priority為0,即不可以被選舉成為主節點。但是如果有設定選舉許可權的話,可以參與選舉。
因為隱藏節點對使用者端不可見,所以對於備份資料或者一些定時指令碼可以直接連到隱藏節點,有大的慢查詢也不會影響到叢集本身對外提供的服務。

- slaveDelay
延遲從主節點同步資料,比如延遲節點時間設定為 1 小時,現在的時間是 10 點鐘,那麼從節點同步到的資料就是 9 點之前的資料。
隱藏節點有什麼作用呢?其中有一個和重要的作用就是防止資料庫誤操作,比如當我們對資料的進行大批次的刪除或者更新操作,為了防止出現意外,我們可能會考慮事先備份一下資料,當操作出現異常的時候,我們還能根據備份進行復原回滾操作。有了延遲節點,因為延遲節點還沒及時同步到最新的資料,我們就可以基於延遲節點進行資料庫的復原操作。
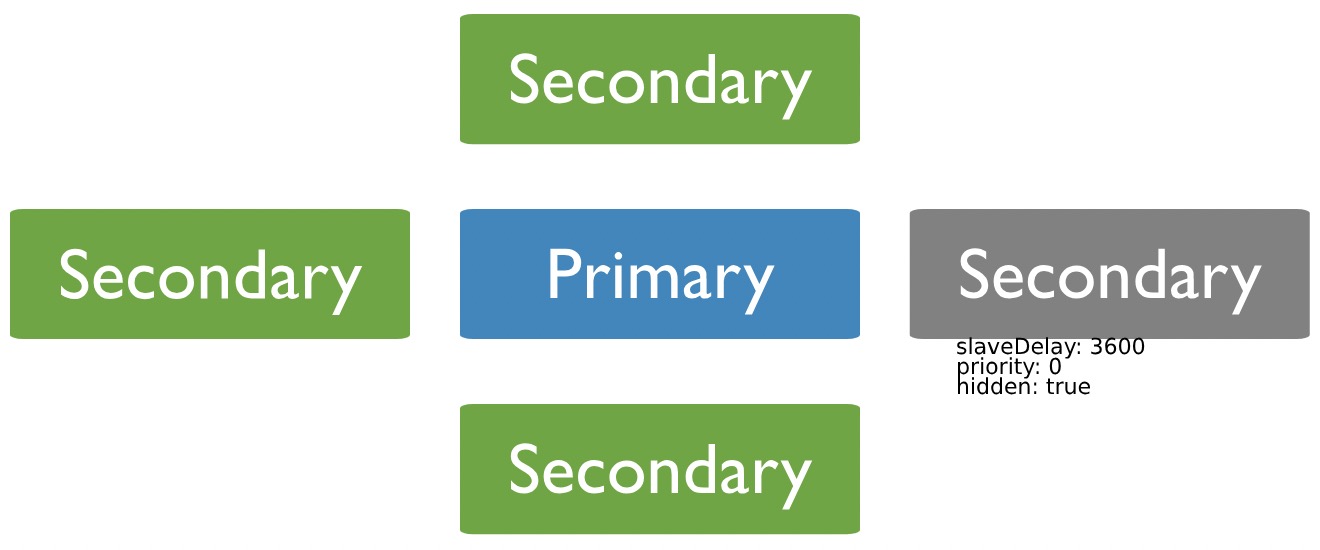
- tags
支援對副本集打成員標籤,在查詢資料時會用到,比如找到對應標籤的副本節點,然後從該節點讀取資料,可以根據標籤對節點分類,查詢資料時不同服務的使用者端指定其對應的標籤的節點,對某個標籤的節點數量進行增加或減少,也不怕會影響到使用其他標籤的服務。
- votes
表示節點是否有許可權參與選舉。
如何構建 MongoDB 的 Replica Set 叢集,可參見 構建mongo的replica-set
副本集寫和讀的特性
寫關注 (Write concern)
副本集寫關注是指寫入一條資料,主節點處理完成之後,需要其它承載副本的節點也確認寫成功之後,才能給使用者端返回寫入資料成功。
這個功能主要是解決主節點掛掉之後,資料還沒來得及同步到從節點,進而導致資料丟失的問題。
可以設定節點個數,預設設定 {「w」:1},這樣表示主節點寫入資料成功即可給使用者端返回成功,「w」 設定為2,則表示除了主節點,還需要收到其中一個副本節點返回寫入成功,「w」 還可以設定為 "majority",表示需要叢集中大多數承載資料且有選舉許可權的節點返回寫入成功。
比如下面的栗子,寫請求裡面帶了 w : 「majority" ,那麼主節點寫入完成後,資料同步到第一個副本節點,且第一個副本節點回復資料寫入成功後,才給使用者端返回成功。
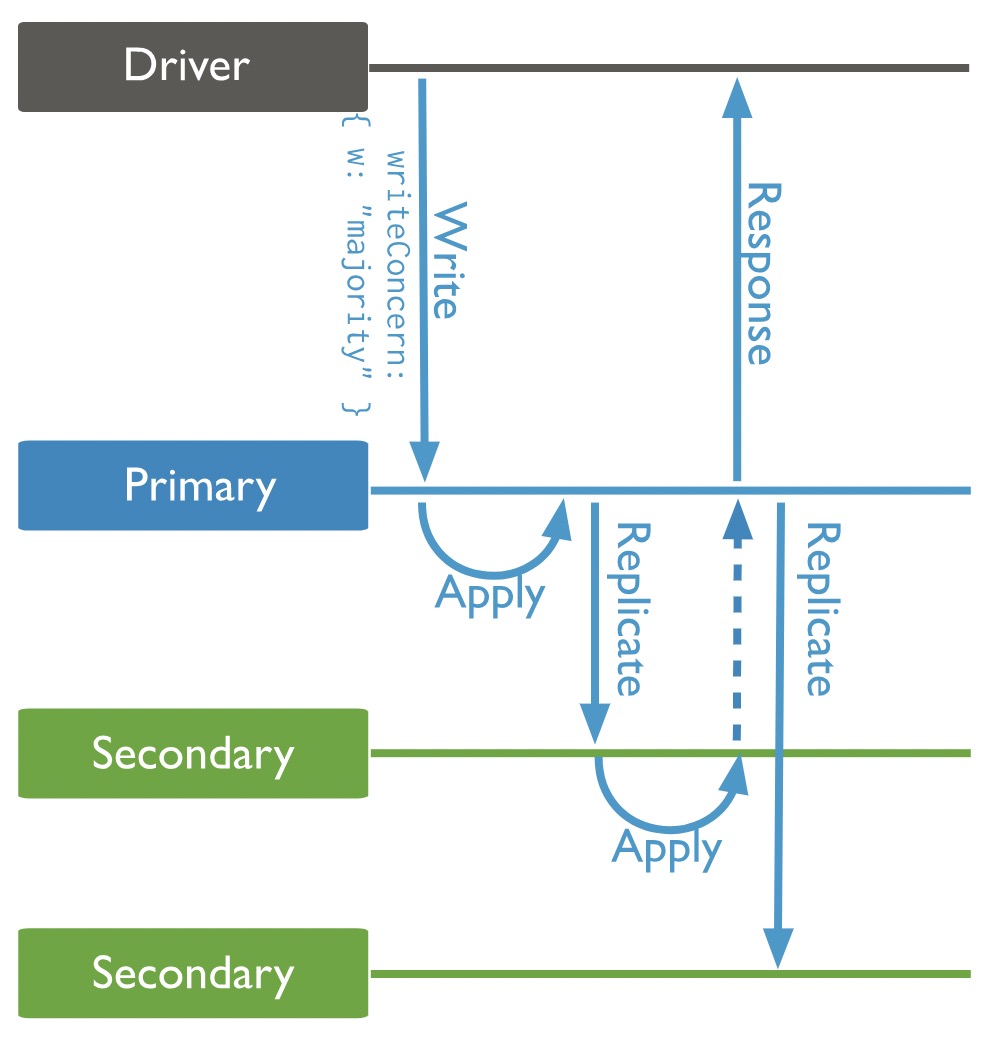
一般有兩種使用策略
1、修改副本集的設定
cfg = rs.conf()
cfg.settings.getLastErrorDefaults = { w: "majority", wtimeout: 5000 }
rs.reconfig(cfg)
2、單個資料插入或者修改的時候攜帶該引數
db.products.insert(
{ item: "envelopes", qty : 100, type: "Clasp" },
{ writeConcern: { w: "majority" , wtimeout: 5000 } }
)
讀偏好 (Read preference)
讀和寫不一樣, 為了保持一致,寫只能通過主節點,但是讀可以選擇主節點,也可以選擇副本節點。區別是主節點資料最新,副本節點因為同步問題可能會有延遲,但從副本節點讀取資料可以分散對主節點的壓力。
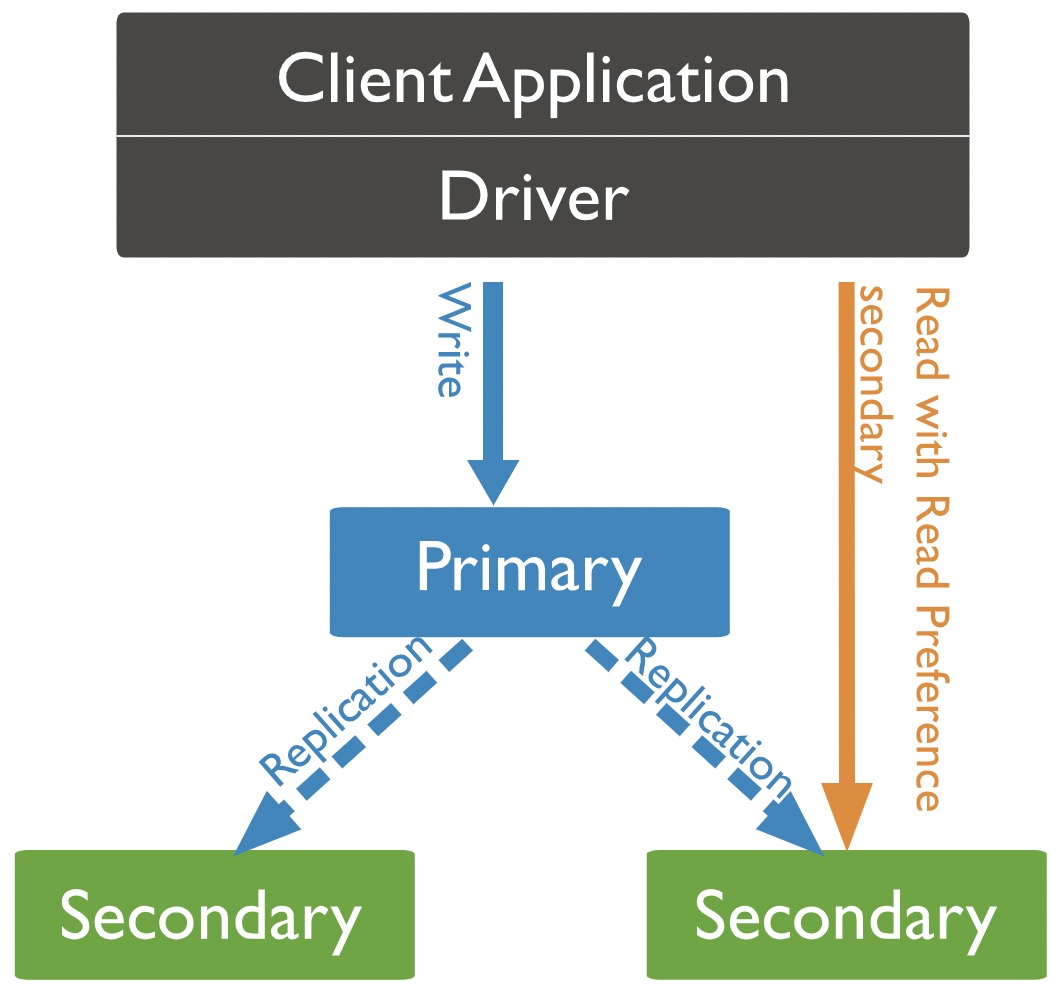
來看下 5 種讀偏好模式的具體特點
| 模式 | 特點 |
|---|---|
| primary | 所有讀請求都從主節點讀取 |
| primaryPreferred | 主節點正常,則所有讀請求都從主節點讀取,如果主節點掛掉,則從符合條件的副本節點讀取 |
| secondary | 所有讀請求都從副本節點讀取 |
| secondaryPreferred | 所有讀請求都從副本節點讀取,但如果副本節點都掛掉了,那就從主節點讀取 |
| nearest | 主要看網路延遲,選取延遲最小的節點,主節點跟副本節點均可 |
Sharding 分片模式
分片將資料分散式在不同的機器中。MongoDB 使用分片來支援具有非常巨量資料集和高吞吐量操作的部署。
當資料量的資料逐漸變大或者資料的請求變大之後,機器我們就會考慮到升級,通常會有兩種方式:垂直擴充套件和水平擴充套件。
垂直擴充套件:垂直擴充套件就是提高單個機器的效能,使用更高的 CPU,增加更多的 RAM 或者儲存空間。但是單個的機器的效能總歸是有上限的,因此垂直擴充套件理論上是有上限的。
水平擴充套件:水平擴充套件將系統資料集和負載均勻的分配到多個伺服器中,根據實際的需求,增加伺服器,就能提高整體的容量和效能。雖然單個機器的總速度或容量可能不高,但每臺機器處理整體工作負載的一個子集,相比單一的高速大容量伺服器,可能提供更好的效率。擴充套件部署的容量只需根據需要新增額外的伺服器,與單機的高階硬體相比,這可能是更低的總體成本。代價則是增加了部署的基礎設施和維護的複雜性。
分片的優勢
讀寫
MongoDB 在分片叢集上的分片上分散讀寫,允許每個分片處理叢集操作的一部分。通過新增更多的分片,可以在叢集中水平擴充套件讀寫工作負載。
對於包含分片鍵或符合分片鍵的字首查詢的操作,mongos 可以將查詢定向到特定的分片或分片集,這樣的查詢是很高效的,如果不攜帶分片鍵,就需要將操作廣播到叢集中的每個分片中。
從 MongoDB 4.4 開始,mongos 可以支援對衝讀取以最小化延遲,什麼是對衝讀,分片叢集中,mongos 節點會把一個使用者端的讀請求同時傳送給某個 Shard 分片的多個副本集節點,最後選擇響應最快節點的返回結果回覆給使用者端,來減少業務側感知到的延遲。
儲存容量
分片在叢集中的分片上分配資料,允許每個分片包含總叢集資料的一個子集。隨著資料集的增長,新增額外的分片可以增加叢集的儲存容量。
高可用性
設定伺服器和分片作為副本集的部署提供了增強的可用性。
即使一個或多個分片副本集完全不可用,分片叢集仍可以繼續執行部分讀寫操作。也就是說,雖然無法存取不可用分片上的資料,但針對可用分片的讀寫操作仍然可以成功。
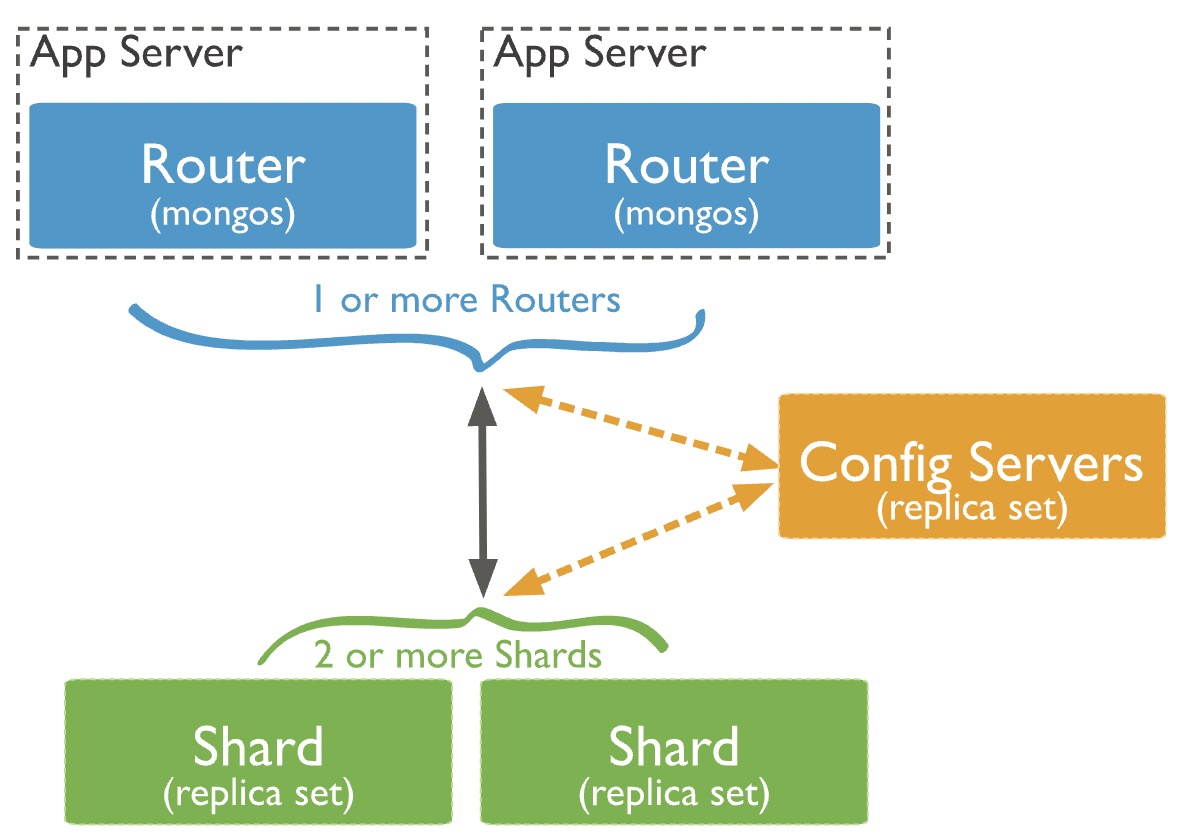
MongoDB 分片的元件
MongoDB 中的 Sharding 分片模式由下面幾個元件組成:
-
分片(shard):每個分片包含一部分分片資料。每個分片可以部署為一個副本集;
-
mongos:mongos作為查詢路由器,提供使用者端應用程式與分片叢集之間的介面。從MongoDB 4.4開始,mongos 可以支援對衝讀取(hedged reads)以最小化延遲;
-
設定伺服器(config servers):設定伺服器儲存叢集的後設資料和設定設定。
分片鍵
MongoDB 在集合級別分片資料,將收集資料分佈在叢集中的各個分片上。
MongoDB 使用分片鍵在各個分片之間分發集合中的檔案。分片鍵由檔案中的一個或多個欄位組成。
在 4.2 及之前的版本中,分片集合中的每個檔案都必須存在分片鍵欄位。
從 4.4 版本開始,在分片集合中的檔案可以缺少分片鍵欄位。
可以選擇叢集中的分片鍵
在 MongoDB 4.2 及以前的版本里,一旦完成分片,分片鍵的選擇就不能更改了。
從 MongoDB 4.4 開始,可以通過新增一個字尾欄位或多個欄位到現有的分片鍵來優化分片鍵。
從 MongoDB 5.0 開始,可以通過更改集合的分片鍵來重新分片集合。
要對集合進行分片處理,集合必須有一個以分片鍵開頭的索引,如果集合本身沒有對應的索引,在指定分片的時候會建立對應的索引。
chunk 是什麼
我們知道 MongoDB 的分片叢集,資料會被均勻的分佈在不同的 shard 中,對於每一個 shard 中的資料,是儲存在一個個的 chunk 中的,每個 chunk 代表 shard 中的一部分資料。
chunk 有什麼作用:
1、Splitting:當一個 chunk 的大小超過設定的 chunk size ,MongoDB 的程序會把這個 chunk 切分成更小的 chunk ,避免 chunk 過大的情況出現;
2、Balancing:在 MongoDB 中,balancer 是一個後臺的程序,負責 chunk 的轉移,從而均衡各個 shard server 的負載。
簡單就是使用 chunk 儲存資料,方便叢集進行資料在分片叢集中進行資料的均衡遷移操作。
chunk 的大小選擇很重要,叢集預設的大小是 64 兆,可以根據業務大小進行調節。
- 較小的 chunksize
優點:資料均衡和遷移速度快,資料分佈更均勻;
缺點:資料分裂頻繁,路由節點消耗更多資源。
- 較大的 chunksize
優點:資料分裂少;
缺點:資料塊移動集中消耗IO資源。
分片的演演算法
MongoDB 中支援兩種分片策略來跨分片叢集分佈資料。雜湊分片和範圍分片。
雜湊分片
雜湊分片會計算分片鍵欄位值的雜湊,然後根據雜湊分片鍵值,每個塊分配一個範圍。
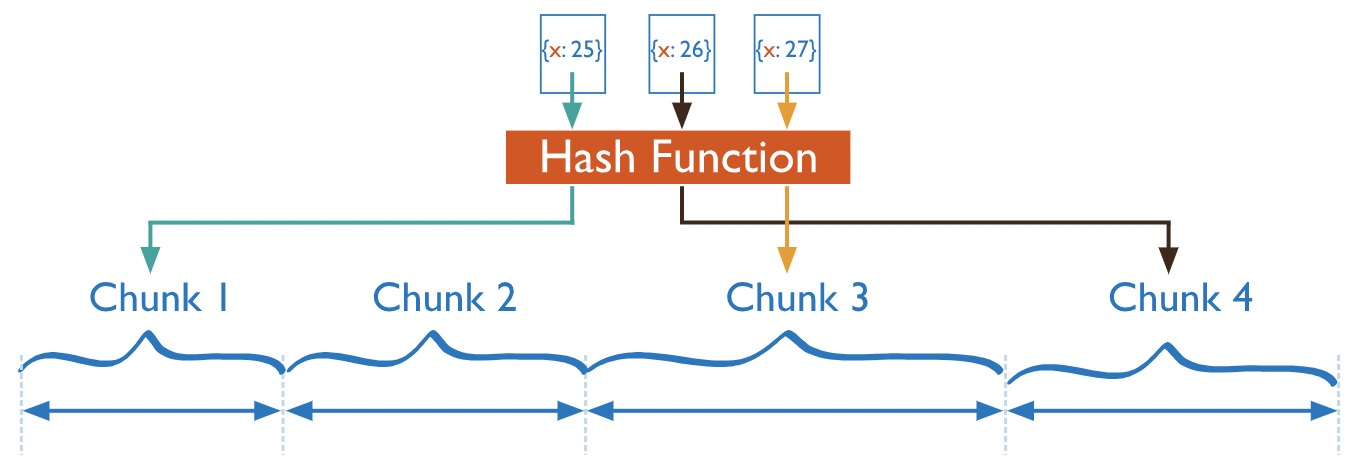
雖然一系列分片鍵可能是「接近」的,但它們的雜湊值不太可能在同一個塊上。基於雜湊值的資料分佈有助於更加均勻地分佈資料,特別是在分片鍵單調變化的資料集中。
對於 MongoDB 中的查詢,如果查詢中包含分片鍵,那麼能定位到具體的分片直接查詢,否則就要廣播查詢到叢集中所有的分片了。
mongos 在接收到所有分片的響應後,將合併資料並返回結果檔案。廣播操作的效能取決於叢集的整體負載,以及網路延遲、各個分片的負載和每個分片返回的檔案數量等因素。所有在使用雜湊分片方式部署的叢集,我們應該減少可能導致廣播的查詢。
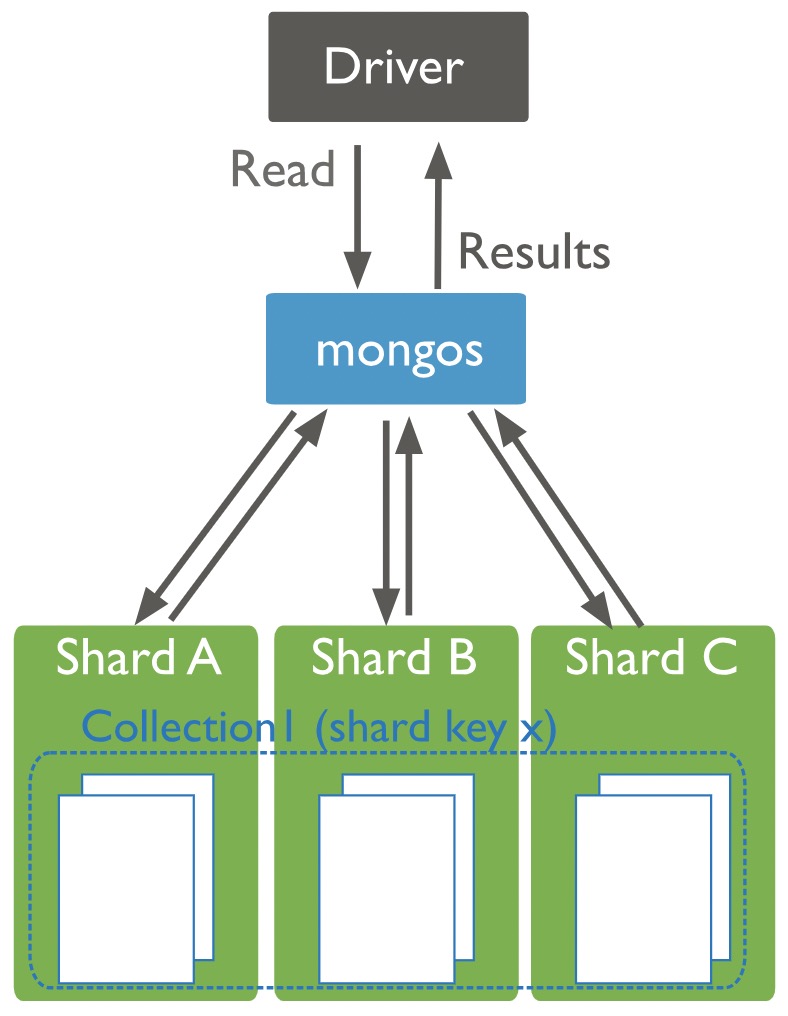
一般雜湊對於範圍查詢都支援的很差。
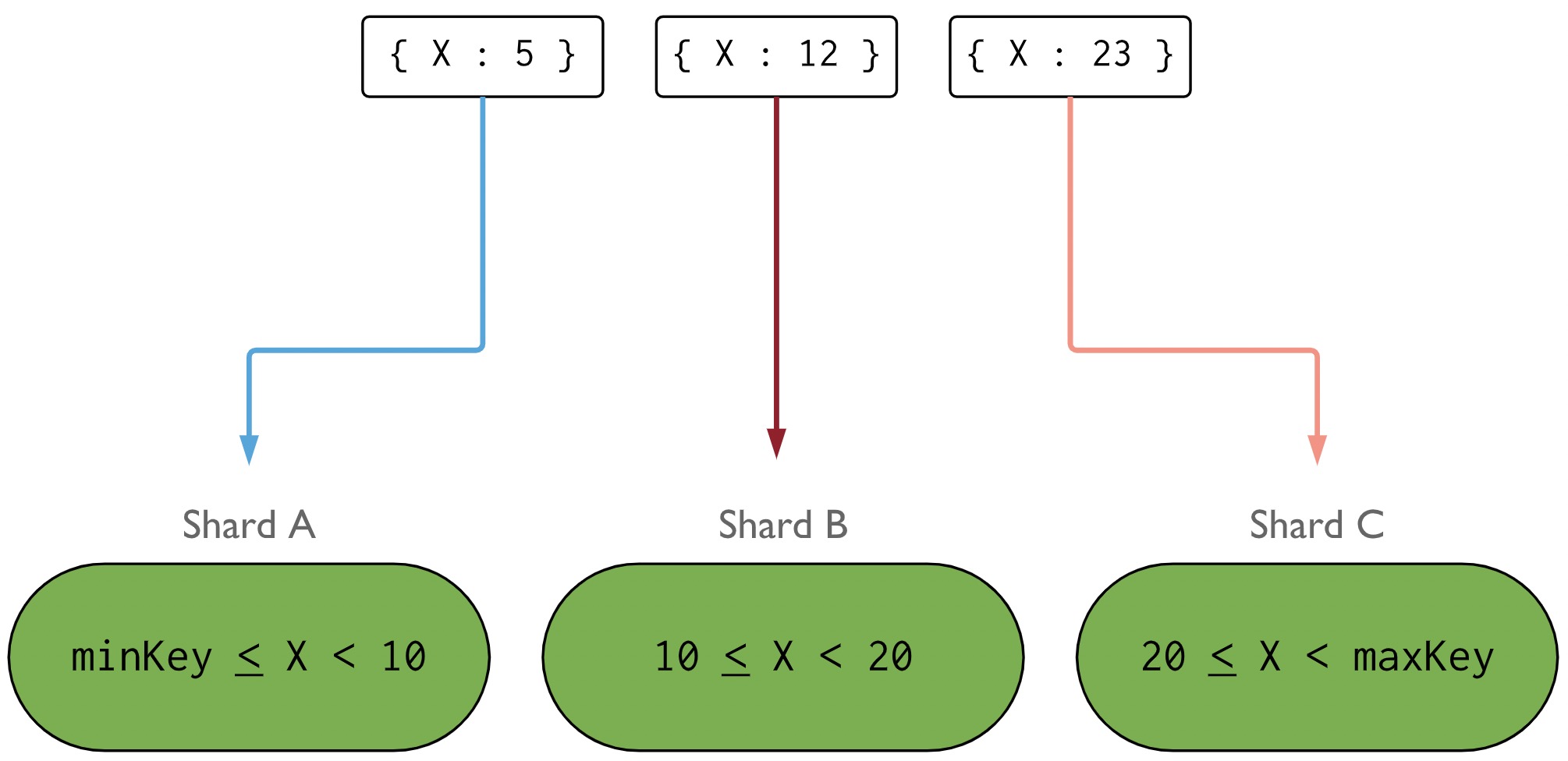
範圍分片
MongoDB 中分片鍵劃分數會根據資料範圍,將不同範圍內的資料劃分到不同的分片中,同一個範圍內的資料就能夠分佈在同一個分片中了。
這樣針對連續範圍的查詢就能夠高效的執行了。
總結
1、Replica Set 副本集模式:一個 Primary 節點用於寫入資料,其它的 Secondary 節點用於查詢資料,適合讀寫少的場景,是目前較為主流的架構方式,Primary 節點掛了,會自動從 Secondary 節點選出新的 Primary 節點,提供資料寫入操作;
2、Sharding 分片模式:將不同的資料分配在不同的機器中,也就是資料的橫向擴充套件,單個機器只儲存整個資料中的一部分,這樣通過橫向增加機器的數量來提高叢集的儲存和計算能力;
參考
【replication】https://www.mongodb.com/docs/manual/replication/
【MongoDB 副本集之入門篇】https://jelly.jd.com/article/5f990ebbbfbee00150eb620a
【sharding】https://www.mongodb.com/docs/manual/sharding/
【MongoDB中的分散式叢集】https://boilingfrog.github.io/2023/12/16/mongo中的分散式叢集/