拓展了個新業務列舉型別,資損了
分享是最有效的學習方式。
案例背景
翻車了,為了cover線上一個業務場景,小貓新增了一個新的列舉型別,盲目自信就沒有測試發生產了,由於是底層服務,上層呼叫導致計算邏輯有誤,造成資損。老闆很生氣,後果很嚴重。
產品提出了一個新的業務場景,新增一種套餐費用的計算方式,由於業務比較著急,小貓覺得功能點比較小,開發完就決定迅速上線。不廢話貼程式碼。
public enum BizCodeEnums {
BIZ_CODE0(50),
BIZ_CODE1(100),
BIZ_CODE2(150); //新拓展
private Integer code;
BizCodeEnums(Integer code) {
this.code = code;
}
public Integer getCode() {
return code;
}
}
套餐計費方式是一種列舉型別,每一種列舉代表一種套餐方式,因為涉及的到資金相關業務,小貓想要穩妥,於是拓展了一個新的業務型別BIZ_CODE2,接下來只要當上層傳入指定的Code的時候,就可以進行計費了。下面為大概的演示程式碼,
public class NumCompare {
public static void main(String[] args) {
Integer inputBizCode = 150; //上層業務
if(BizCodeEnums.BIZ_CODE0.getCode() == inputBizCode) {
method0();
}else if(BizCodeEnums.BIZ_CODE1.getCode() == inputBizCode) {
method1();
//新拓展業務
}else if (BizCodeEnums.BIZ_CODE2.getCode() == inputBizCode) {
method2();
}
}
private static void method0(){
System.out.println("method0 execute");
}
private static void method1(){
System.out.println("method1 execute");
}
private static void method2(){
System.out.println("method2 execute");
}
}
上述可見,程式碼也沒有經過什麼比較好的設計,純屬堆業務程式碼,為了穩妥起見,小貓就照著以前的老程式碼拓展出來了新的業務程式碼,見上述備註。也沒有經過仔細的測試,然後欣然上線了。事後發現壓根他新的業務程式碼就沒有生效,走的套餐計算邏輯還是預設的套餐計算邏輯。
容咱們盤一下這個技術細節,這可能也是很多初中級開發遇到的坑。
覆盤分析
接下來,我們就來好好盤盤裡面涉及的技術細節。其實造成這個事故的原因底層涉及兩種原因,
- 開發人員並沒有對Integer底層的原理吃透
- 開發人員對值比較以及地址比較沒有掌握好
Intger底層分析
從上述程式碼中,我們先看一下發生了什麼。
當Integer變數inputBizCode被賦值的時候,其實java預設會呼叫Integer.valueOf()方法進行裝箱操作。
Integer inputBizCode = 100
裝箱變成
Integer inputBizCode = Integer.valueOf(100)
接下來我們來扒一下Integer的原始碼看一下實現。原始碼如下
@IntrinsicCandidate
public static Integer valueOf(int i) {
if (i >= IntegerCache.low && i <= IntegerCache.high)
return IntegerCache.cache[i + (-IntegerCache.low)];
return new Integer(i);
}
我們點開 IntegerCache.low 以及IntegerCache.high的時候就會發現其中對應著兩個值,分別是最小值為-128 最大的值為127,那麼如此看來,如果目標值在-128~127之間的時候,那麼直接會從cache陣列中取值,否則就會新建物件。
我們再看一下IntegerCache中的cache是怎麼被快取進去的。
public final class Integer extends Number
implements Comparable<Integer>, Constable, ConstantDesc {
...此處省略無關程式碼
private static class IntegerCache {
static final int low = -128;
static final int high;
static final Integer[] cache;
static Integer[] archivedCache;
static {
// high value may be configured by property
int h = 127;
String integerCacheHighPropValue =
VM.getSavedProperty("java.lang.Integer.IntegerCache.high");
if (integerCacheHighPropValue != null) {
try {
h = Math.max(parseInt(integerCacheHighPropValue), 127);
// Maximum array size is Integer.MAX_VALUE
h = Math.min(h, Integer.MAX_VALUE - (-low) -1);
} catch( NumberFormatException nfe) {
// If the property cannot be parsed into an int, ignore it.
}
}
high = h;
// Load IntegerCache.archivedCache from archive, if possible
CDS.initializeFromArchive(IntegerCache.class);
int size = (high - low) + 1;
// Use the archived cache if it exists and is large enough
if (archivedCache == null || size > archivedCache.length) {
Integer[] c = new Integer[size];
int j = low;
for(int i = 0; i < c.length; i++) {
c[i] = new Integer(j++);
}
archivedCache = c;
}
cache = archivedCache;
// range [-128, 127] must be interned (JLS7 5.1.7)
assert IntegerCache.high >= 127;
}
private IntegerCache() {}
}
}
上述其實我們不難發現,原來IntegerCache是Integer這個類的靜態內部類,裡面的陣列進行初始化的時候其實就是在Integer進行初始化進行類載入的時候就被快取進去了,被static修飾的屬性會儲存到我們的棧記憶體中。在上面列舉BizCodeEnums.BIZ_CODE1.getCode()也是Integer型別,說白了當值在-127~128之間的時候,jvm拿到的其實是同一個地址的值。所以兩個值當前相等。
當然我們從上面的原始碼中其實不難發現其實最大值128並不是一成不變的,也可以通過自定義設定變成其他範圍,具體的應該是上述的這個設定:
java.lang.Integer.IntegerCache.high
本人自己親測設定了一下,如下圖,是生效了的。
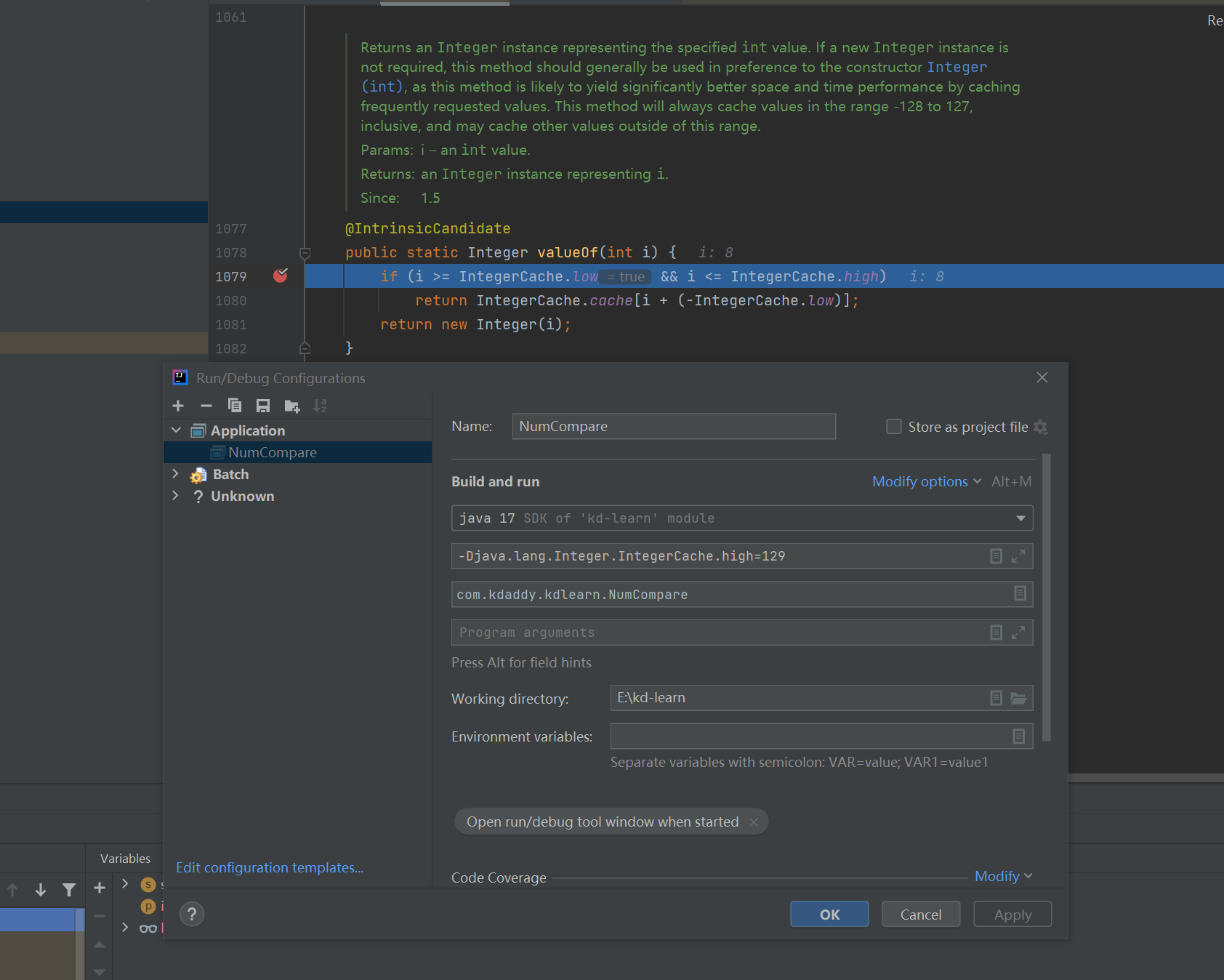
那麼Integer為什麼是-127~128進行快取了呢?翻了一下Java API中,大概是這麼解釋的:
Returns an Integer instance representing the specified int value. If a new Integer instance is not required, this method should generally be used in preference to the constructor Integer(int), as this method is likely to yield significantly better space and time performance by caching frequently requested values. This method will always cache values in the range -128 to 127, inclusive, and may cache other values outside of this range.
上述大概意思就是-128~127資料在int範圍內使用最頻繁,為了減少頻繁建立物件帶來的記憶體消耗,這裡其實採用了以空間換時間的涉及理念,也就是設計模式中的享元模式。
其實在JDK中享元模式的應用不僅僅只是侷限於Integer,其實很多其他基礎型別的包裝類也有使用,咱們來看一下比較:
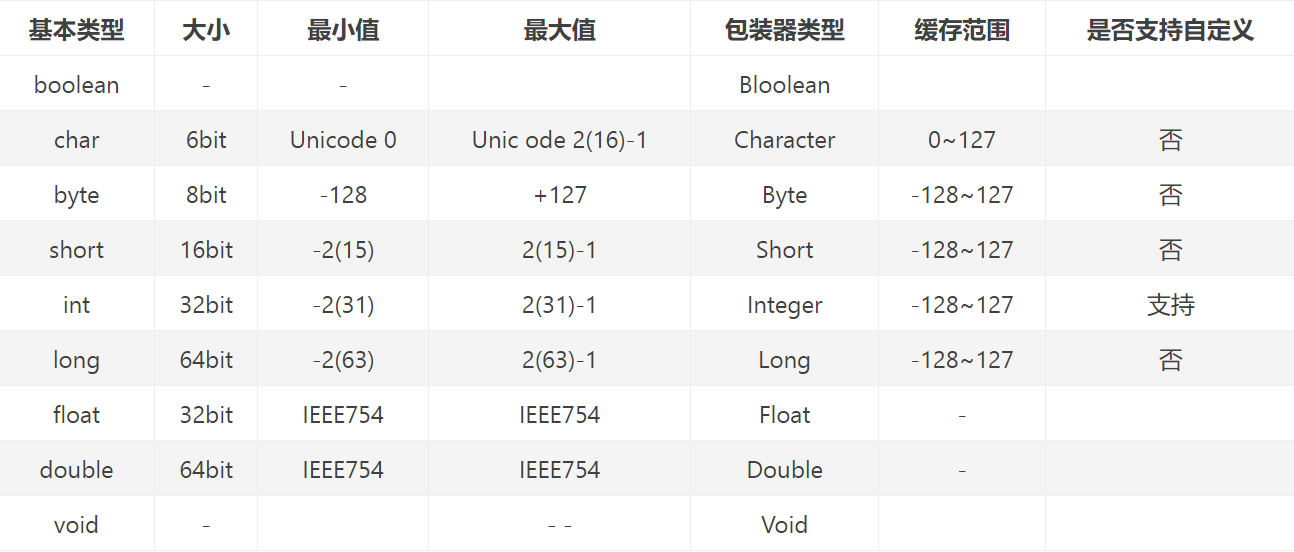
此處其實也是面試中的一個高頻考點,需要大家注意,另外的話關於享元模式此處不展開討論,後續老貓會穿插到設計模式中和大家一起學習使用。
值比較以及物件比較
我們再來看一下兩種比較方式。
「==」比較
- 基本資料型別:byte,short,char,int,long,double,float,blooean,它們之間的比較,比較是它們的值;
- 參照資料型別:使用==比較的時候,比較的則是它們在記憶體中的地址(heap上的地址)。
業務程式碼中賦值為150的時候,底層程式碼重新new出來一個新的Integer物件,那麼此時new出來的那個物件的值在棧記憶體中其實是新分配的一塊地址,和之前的快取中的地址完全不同。兩分值進行等號比較的時候當然不會相等,所以也就不會走到method2方法塊中。
「equals」比較
equals方法本質其實是屬於Object方法:
public boolean equals(Object obj) {
return (this == obj);
}
但是從上面這段程式碼中我們可以明顯地看到 預設的Object物件的equals方法其實和「==」是一樣的,比較的都是參照地址是否一致。
我們測試一下將上述的==變成equals的時候,其實程式碼就沒有什麼問題了
if (BizCodeEnums.BIZ_CODE2.getCode() == inputBizCode)
改成
if (BizCodeEnums.BIZ_CODE2.getCode().equals(inputBizCode))
那麼這個又是為什麼呢?其實在一般情況下物件在整合Object物件的時候都會去重寫equals方法,Integer型別中的equals也不例外。我們來看一下重寫後的程式碼:
public boolean equals(Object obj) {
if (obj instanceof Integer) {
return value == ((Integer)obj).intValue();
}
return false;
}
上述我們看到如果使用Integer中的equals進行比較的時候,最終比較的是基本型別值,就上述程式碼比較的其實就是150==150?那麼這種情況下,返回的就自然是true了,那麼所以對應的mthod也會執行到了。
「hashCode」
既然已經聊到equals重寫了,那麼我們不得不再聊一下hashCode重寫。可能經常會有面試官這麼問「為什麼重寫 equals方法時一定要重寫hashCode方法?」。
其實重寫equals方法時一定要重寫hashCode方法的原因是為了保證物件在使用雜湊集合(如HashMap、HashSet等)時能夠正確地進行儲存和查詢。
在Java中,hashCode方法用於計算物件的雜湊碼,而equals方法用於判斷兩個物件是否相等。在雜湊集合中,物件的雜湊碼被用作索引,通過雜湊碼可以快速定位到儲存的位置,然後再通過equals方法判斷是否是相同的物件。
我們知道HashMap中的key是不能重複的,如果重複新增,後新增的會覆蓋前面的內容。那麼我們看看HashMap是如何來確定key的唯一性的(估計會有小夥伴對底層HashMap的完整實現感興趣,另外也是面試的高頻題,不過在此我們不展開,老貓後續儘量在其他文章中展開分析)。老貓的JDK版本是java17,我們一起看下原始碼
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
檢視程式碼發現,它是通過計算Map key的hashCode值來確定在連結串列中的儲存位置的。那麼這樣就可以推測出,如果我們重寫了equals但是沒重寫hashCode,那麼可能存在元素重複的矛盾情況。
咱們舉個例子簡單實驗一下:
public class Person {
private Integer age;
private String name;
public Person(Integer age, String name) {
this.age = age;
this.name = name;
}
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
Person person = (Person) o;
return Objects.equals(age, person.age) && Objects.equals(name, person.name);
}
// @Override
// public int hashCode() {
// return Objects.hash(age, name);
// }
}
public class TestPerson {
public static void main(String[] args) {
Person p1 = new Person(18,"ktdaddy");
Person p2 = new Person(18,"ktdaddy");
HashMap<Person,Object> map = new HashMap<>();
map.put(p1, "1");
System.out.println("equals:" + p1.equals(p2));
System.out.println(map.get(p2));
}
}
上述的結果輸出為
equals:true
null
由於沒有重寫hashCode方法,p1和p2的hashCode方法返回的雜湊碼不同,導致它們在HashMap中被當作不同的鍵,因此無法正確地獲取到值。如果重寫了hashCode方法,使得相等的物件返回相同的雜湊碼,就可以正確地進行儲存和查詢操作。
案例總結
其實當我們在日常維護的程式碼的時候要勇於去質疑現有程式碼體系,如果發現不合理的地方,隱藏的坑點,咱們還是需要立刻將其填好,以免發生類似小貓遇到的這種情況。
另外的話,寫程式碼還是不能停留於會寫,必要的時候還是得翻看底層的原始碼實現。只有這樣才能知其所以然,未來也才能夠更好地用好大神封裝的一些程式碼。或者可以自主封裝一些好用的工具給他人使用。
派生面試題
上面的案例中涉及到的知識點可能會牽扯到這樣的面試題。
問題1: 如何自定義一個類的equals方法?
答案: 要自定義一個類的equals方法,可以按照以下步驟進行:
- 在類中建立一個equals方法的覆蓋(override)。
- 確保方法簽名為public boolean equals(Object obj),並且引數型別是Object。
- 在equals方法中,首先使用==運運算元比較物件的參照,如果參照相同,返回true。
- 如果參照不同,檢查傳遞給方法的物件是否屬於相同的類。
- 如果屬於相同的類,將傳遞的物件強制轉換為相同型別,然後比較物件的欄位,以確定它們是否相等。
- 最後,返回比較結果,通常是true或false。
問題2:equals 和 hashCode 之間有什麼關係?
答案:
equals 和 hashCode 在Java中通常一起使用,以維護物件在雜湊集合(如HashMap和HashSet)中的正確行為。
如果兩個物件相等(根據equals方法的定義),那麼它們的hashCode值應該相同。
也就是說,如果重寫了一個類的equals方法,通常也需要重寫hashCode方法,以便它們保持一致。
這是因為雜湊集合使用物件的hashCode值來確定它們在內部儲存結構中的位置。
問題3:== 在哪些情況下比較的是物件內容而不是參照?
答案:
在Java中,== 運運算元通常比較的是物件的參照。但在以下情況下,== 可以比較物件的內容而不是參照:
對於基本資料型別(如int、char等),== 比較的是它們的值,而不是參照。
字串常數池:對於字串字面值,Java使用常數池來儲存它們,因此相同的字串字面值使用==比較通常會返回true。
我是老貓,10Year+資深研發老鳥,讓我們一起聊聊技術,聊聊人生。
個人公眾號,「程式設計師老貓」