聊聊GLM基座模型的理論知識
概述
大模型有兩個流程:預訓練和推理。
- 預訓練是在某種神經網路模型架構上,匯入大規模語料資料,通過一系列的神經網路隱藏層的矩陣計算、微分計算等,輸出權重,學習率,模型引數等超引數資訊。
- 推理是在預訓練的成果上,應用超引數檔案,基於預訓練結果,根據使用者的輸入資訊,推理預測其行為。
GLM模型原理的理解,就是預訓練流程的梳理,如下流程所示:
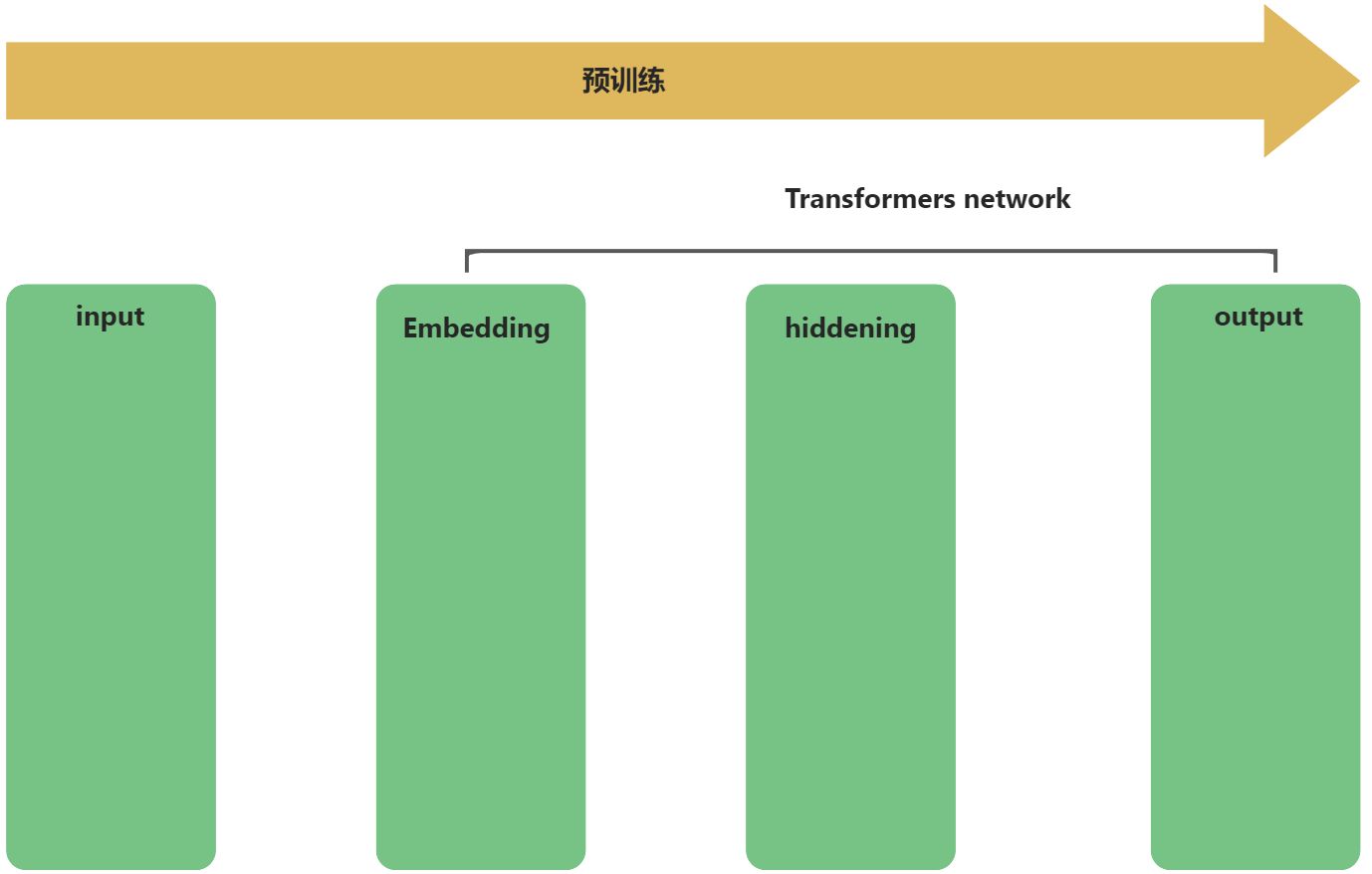
input輸入層會預處理輸入資料,在預訓練過程中,該輸入資料,其實就是預先準備好的預料資料集,也就是常說的6B,130B大小的資料集。
掩碼處理
GLM統一了自編碼模型與自迴歸模型,主要是在該處理過程實現的。該過程也被成為自迴歸空格填充。該過程體現了自編碼與自迴歸思想:
1、自編碼思想:在輸入文字中,隨機刪除連續的tokens,做成掩碼[MASK]。
2、自迴歸思想:順序重建連續tokens。在使用自迴歸方式預測缺失tokens時,模型既可以存取帶掩碼的文字,又可以存取之前已經被取樣的spans。
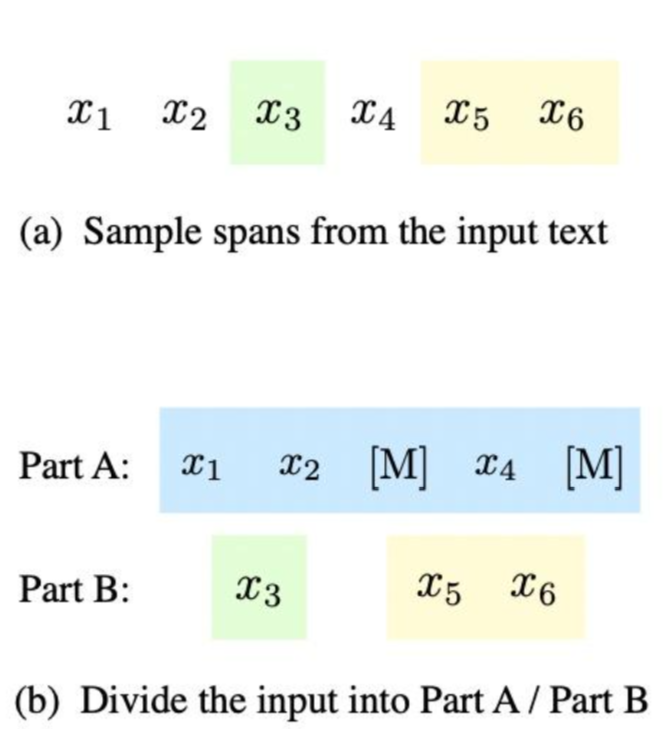
輸入 可以被分成兩部分:Part A是被損壞的文字
可以被分成兩部分:Part A是被損壞的文字 ,Part B由masked spans組成。
,Part B由masked spans組成。
假設原始輸入文字是 ,取樣的兩個文字片段是
,取樣的兩個文字片段是 以及
以及 。那麼mask後的文字序列是:
。那麼mask後的文字序列是: ,即Part A;、即PartB。
,即Part A;、即PartB。
再對Part B的片段進行shuffle。每個片段使用 填充在開頭作為輸入,使用
填充在開頭作為輸入,使用 填充在末尾作為輸出。如論文中的圖所示:
填充在末尾作為輸出。如論文中的圖所示:
掩碼處理時,會隨機選擇輸入序列中的某些詞語進行掩碼(mask)處理。掩碼的目的是讓模型學習預測那些被掩碼的詞語。讓模型能夠在預訓練過程中更好地學習語言規律和上下文資訊。
掩碼處理的流程如下:
- 輸入資料取樣:首先,從輸入文字中隨機取樣多個片段,這些片段包含了多個需要被預測的詞(即[mask]標記)。
- 掩碼替換:在這些取樣片段中,用[mask]標記替換掉部分詞語,形成一個被掩碼的文字。這樣,模型需要根據已給出的上下文資訊來預測被掩碼的詞語。
- 自迴歸預測:GLM模型採用自迴歸的方式,從已給出的片段中預測被掩碼的詞語。這意味著在預測[mask]中原來的詞的同時,模型可以參考之前片段的資訊。
- 上下文資訊利用:為了讓模型能夠更好地理解上下文資訊,GLM模型將被掩碼的片段的順序打亂。這樣,模型在預測時需要參考更廣泛的上下文資訊,從而提高其語言理解能力。
- 預訓練任務:通過這種方式,GLM模型實現了自監督訓練,讓模型能夠在不同的任務(如NLU、NLG和條件NLG)中表現更好。
從結構化來思考,剖析下這個過程所涉及到的一些開發知識點。
- 隨機抽樣:在掩碼處理中,需要從輸入資料中隨機選擇一部分資料進行掩碼。遵循泊松分佈,重複取樣,直到原始tokens中有15%被mask。
- 掩碼策略:在GLM模型中,採用了自迴歸空白填充(Autoregressive Blank Infilling)的自監督訓練方式。這需要根據掩碼策略來生成掩碼,如根據預先設定的規則來選擇掩碼的長度和位置。這個過程涉及到組合數學和離散數學的知識。
- 掩碼填充:在生成掩碼後,需要對掩碼進行填充。在GLM模型中,採用了特殊的填充方式,如span shuffling和2D positional encoding。這個過程涉及到線性代數和矩陣運算的知識。
- 損失函數:在掩碼處理過程中,需要根據損失函數來計算掩碼處理的效果。在GLM模型中,採用了交叉熵損失函數來衡量模型在掩碼處理任務上的表現。這個過程涉及到優化理論和數值分析的知識。
位置編碼
在基於Transformer網路架構的模型中,位置編碼是必不可少的一個處理,其作用簡單來說就是在沒有顯式順序資訊的情況下,為模型提供關於詞的相對位置的資訊,以便讓模型理解輸入序列中的序列資訊以及上下文資訊。
位置編碼在GLM中,通過採用一種稱為"旋轉位置編碼"(RoPE)的方法來處理的。RoPE是一種相對位置編碼技術,它能夠有效地捕捉輸入序列中不同token之間的相對位置資訊。相較於傳統的絕對位置編碼,RoPE具有更好的外推性和遠端衰減特性,能夠更好地處理長文字。
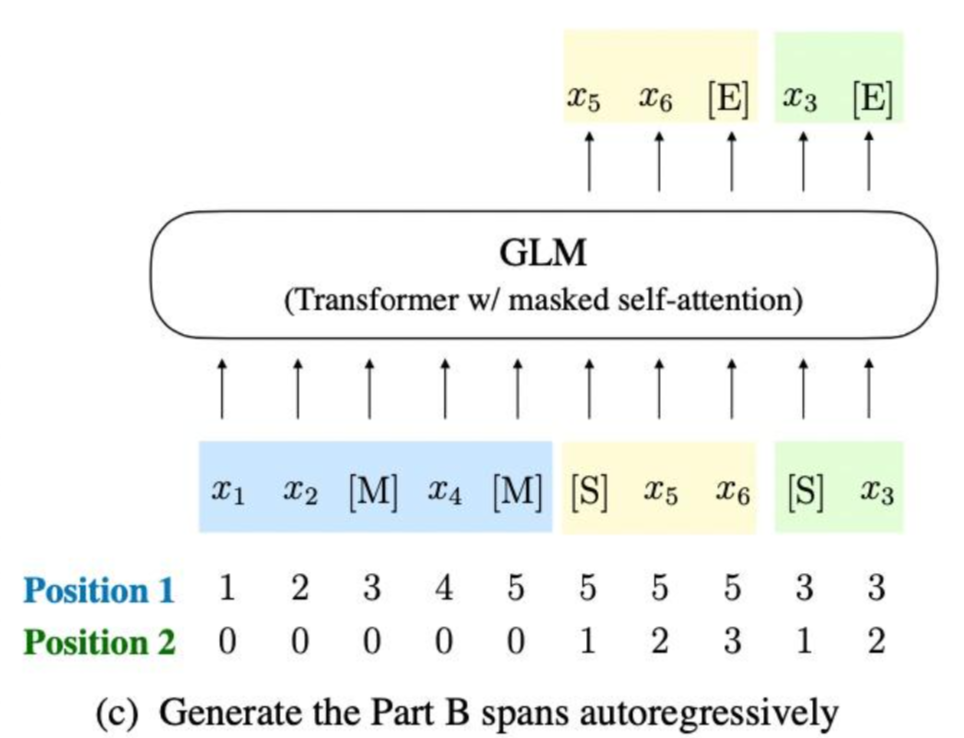
在GLM中,使用二維位置編碼,第一個位置id用來標記Part A中的位置,第二個位置id用來表示跨度內部的相對位置。這兩個位置id會通過embedding表被投影為兩個向量,最終都會被加入到輸入token的embedding表達中。如論文中的圖所示:
自注意力計算
自注意力機制中的 矩陣計算如圖所示:
矩陣計算如圖所示:
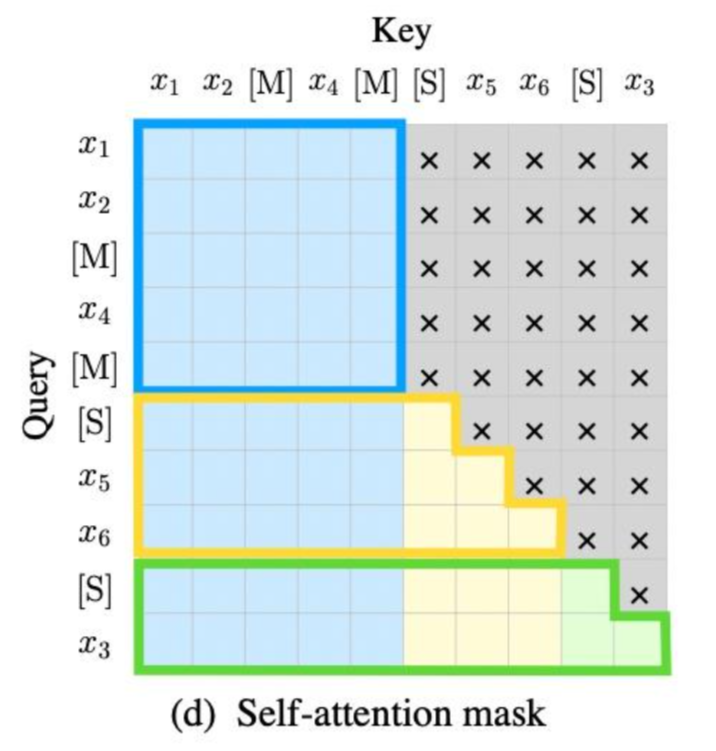
這裡面的道道暫時還沒有摸清,不過計算的邏輯還是基於Tranformer網路中的自注意力計算,只是這框出來的藍黃綠,其表徵有點道道。
其它
GLM在原始single Transformer的基礎上進行了一些修改:
1)重組了LN和殘差連線的順序;
2)使用單個線性層對輸出token進行預測;
3)啟用函數從ReLU換成了GeLUS。
這些修改是比較常見的,簡單瞭解下即可。
參考
清華ChatGLM底層原理詳解
GLM(General Language Model)論文閱讀筆記