衡蘭芷若成絕響,人間不見周海媚(4k修復基於PaddleGan)

一代人有一代人的經典回憶,1994年由周海媚、馬景濤、葉童主演的《神鵰俠侶》曾經風靡一時,周海媚所詮釋的周芷若凝聚了漢水之鐘靈,峨嵋之毓秀,遇雪尤清,經霜更豔,俘獲萬千觀眾,成為了一代人的共同記憶。
如今美人仙去,回望經典,雪膚依然,花貌如昨,白璧微瑕之處是九十年代電視劇的解析度有些低,本次我們利用百度自研框架PaddleGan的視訊超分SOTA演演算法來對九十年代電視劇進行4K修復。
設定PaddlePaddle框架
PaddlePaddle框架需要本地環境支援CUDA和cudnn,具體請參照:聲音好聽,顏值能打,基於PaddleGAN給人工智慧AI語音模型配上動態畫面(Python3.10),囿於篇幅,這裡不再贅述。
接著去PaddlePaddle官網檢視本地cudnn對應的paddlepaddle版本:
https://www.paddlepaddle.org.cn/
輸入命令檢視本地cudnn版本:
nvcc --version
nvcc: NVIDIA (R) Cuda compiler driver
Copyright (c) 2005-2022 NVIDIA Corporation
Built on Tue_Mar__8_18:36:24_Pacific_Standard_Time_2022
Cuda compilation tools, release 11.6, V11.6.124
Build cuda_11.6.r11.6/compiler.31057947_0
可以看到版本是11.6
隨後安裝對應11.6的最新paddle-gpu版本:
python -m pip install paddlepaddle-gpu==2.5.2.post116 -f https://www.paddlepaddle.org.cn/whl/windows/mkl/avx/stable.html
注意這裡的最新版是paddlepaddle-gpu2.5.2.post116,而非之前的paddlepaddle-gpu2.4.2.post116
安裝成功後,進行檢測:
PS C:\Users\zcxey> python
Python 3.10.11 (tags/v3.10.11:7d4cc5a, Apr 5 2023, 00:38:17) [MSC v.1929 64 bit (AMD64)] on win32
Type "help", "copyright", "credits" or "license" for more information.
>>> import paddle
>>> paddle.utils.run_check()
Running verify PaddlePaddle program ...
I1214 14:38:08.825912 4800 interpretercore.cc:237] New Executor is Running.
W1214 14:38:08.827040 4800 gpu_resources.cc:119] Please NOTE: device: 0, GPU Compute Capability: 8.9, Driver API Version: 12.3, Runtime API Version: 11.6
W1214 14:38:08.829569 4800 gpu_resources.cc:149] device: 0, cuDNN Version: 8.4.
I1214 14:38:12.468061 4800 interpreter_util.cc:518] Standalone Executor is Used.
PaddlePaddle works well on 1 GPU.
PaddlePaddle is installed successfully! Let's start deep learning with PaddlePaddle now.
說明PaddlePaddle的設定沒有問題。
隨後克隆專案並且進行編譯:
git clone https://gitee.com/PaddlePaddle/PaddleGAN
cd PaddleGAN
pip3 install -v -e .
視訊修復超分模型
關於視訊修復超分模型的選擇,這裡我們使用百度自研SOTA超分系列模型PP-MSVSR、業界領先的視訊超分模型還包括EDVR、BasicVSR,IconVSR和BasicVSR++等等。
百度自研的PP-MSVSR是一種多階段視訊超分深度架構,具有區域性融合模組、輔助損失和細化對齊模組,以逐步細化增強結果。具體來說,在第一階段設計了區域性融合模組,在特徵傳播之前進行區域性特徵融合, 以加強特徵傳播中跨幀特徵的融合。在第二階段中引入了一個輔助損失,使傳播模組獲得的特徵保留了更多與HR空間相關的資訊。在第三階段中引入了一個細化的對齊模組,以充分利用前一階段傳播模組的特徵資訊。大量實驗證實,PP-MSVSR在Vid4資料集效能優異,僅使用 1.45M 引數PSNR指標即可達到28.13dB。
PP-MSVSR提供兩種體積模型,開發者可根據實際場景靈活選擇:PP-MSVSR(引數量1.45M)與PP-MSVSR-L(引數量7.42)。
關於EDVR:
EDVR模型在NTIRE19視訊恢復和增強挑戰賽的四個賽道中都贏得了冠軍,並以巨大的優勢超過了第二名。視訊超分的主要難點在於(1)如何在給定大運動的情況下對齊多個幀;(2)如何有效地融合具有不同運動和模糊的不同幀。首先,為了處理大的運動,EDVR模型設計了一個金字塔級聯的可變形(PCD)對齊模組,在該模組中,從粗到精的可變形折積被使用來進行特徵級的幀對齊。其次,EDVR使用了時空注意力(TSA)融合模組,該模組在時間和空間上同時應用注意力機制,以強調後續恢復的重要特徵。
關於BasicVSR:
BasicVSR在VSR的指導下重新考慮了四個基本模組(即傳播、對齊、聚合和上取樣)的一些最重要的元件。 通過新增一些小設計,重用一些現有元件,得到了簡潔的 BasicVSR。與許多最先進的演演算法相比,BasicVSR在速度和恢復質量方面實現了有吸引力的改進。 同時,通過新增資訊重新填充機制和耦合傳播方案以促進資訊聚合,BasicVSR 可以擴充套件為 IconVSR,IconVSR可以作為未來 VSR 方法的強大基線 .
關於BasicVSR++:
BasicVSR++通過提出二階網格傳播和導流可變形對齊來重新設計BasicVSR。通過增強傳播和對齊來增強迴圈框架,BasicVSR++可以更有效地利用未對齊視訊幀的時空資訊。 在類似的計算約束下,新元件可提高效能。特別是,BasicVSR++ 以相似的引數數量在 PSNR 方面比 BasicVSR 高0.82dB。BasicVSR++ 在NTIRE2021的視訊超解析度和壓縮視訊增強挑戰賽中獲得三名冠軍和一名亞軍。
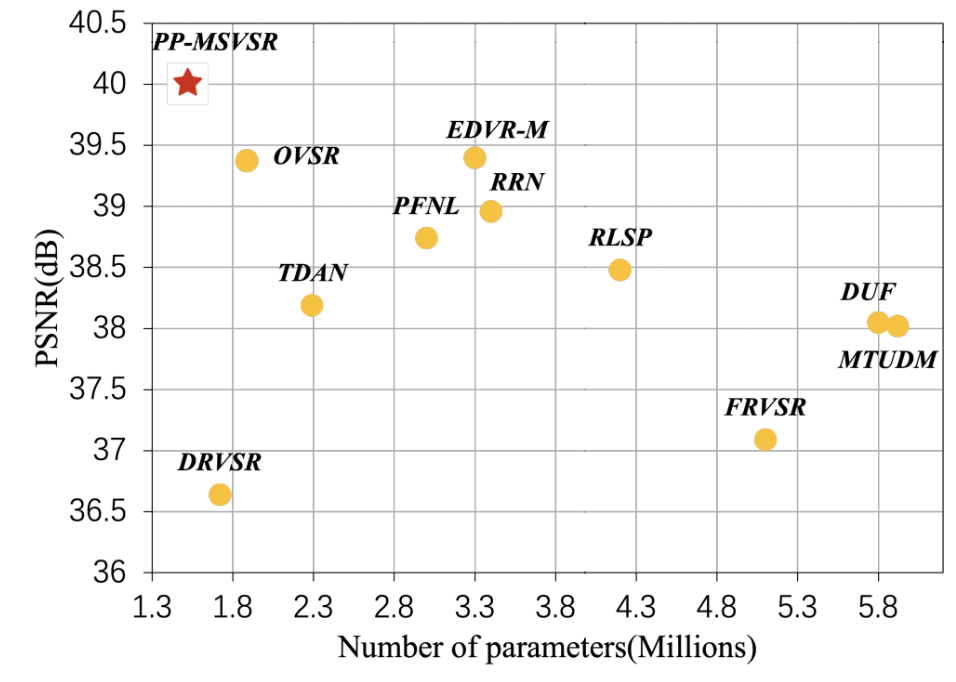
在當前引數量小於6M的輕量化視訊超分模型在 UDM10 資料集上的PSNR指標對比上,PP-MSVSR可謂是「遙遙領先」:
視訊修復實踐
PP-MSVSR提供兩種體積模型,開發者可根據實際場景靈活選擇:PP-MSVSR(引數量1.45M)與PP-MSVSR-L(引數量7.42)。這裡推薦使用後者,因為該大模型的引數量更大,修復效果更好:
ppgan.apps.PPMSVSRLargePredictor(output='output', weight_path=None, num_frames)
引數說明:
output_path (str,可選的): 輸出的資料夾路徑,預設值:output.
weight_path (None,可選的): 載入的權重路徑,如果沒有設定,則從雲端下載預設的權重到本地。預設值:None.
num_frames (int,可選的): 模型輸入幀數,預設值:10.輸入幀數越大,模型超分效果越好。
隨後進入專案的根目錄:
cd PaddleGAN
編寫test.py來檢視視訊引數:
import cv2
import imageio
import numpy as np
import matplotlib.pyplot as plt
import matplotlib.animation as animation
from IPython.display import HTML
import warnings
warnings.filterwarnings("ignore")
def display(driving, fps, size=(8, 6)):
fig = plt.figure(figsize=size)
ims = []
for i in range(len(driving)):
cols = []
cols.append(driving[i])
im = plt.imshow(np.concatenate(cols, axis=1), animated=True)
plt.axis('off')
ims.append([im])
video = animation.ArtistAnimation(fig, ims, interval=1000.0/fps, repeat_delay=1000)
plt.close()
return video
video_path = 'd:/倚天屠龍記.mp4'
video_frames = imageio.mimread(video_path, memtest=False)
# 獲得視訊的原解析度
cap = cv2.VideoCapture(video_path)
fps = cap.get(cv2.CAP_PROP_FPS)
HTML(display(video_frames, fps).to_html5_video())
如此,就可以獲得視訊的原解析度。
隨後,進入專案的根目錄,執行修復命令:
python3 tools/video-enhance.py --input d:/倚天屠龍記.mp4 \
--process_order PPMSVSR \
--output d:/output_dir \
--num_frames 100
這裡使用PPMSVSR模型對該視訊進行修復,input參數列示輸入的視訊路徑;output表示處理後的視訊的存放資料夾;proccess_order 表示使用的模型和順序;num_frames 表示模型輸入幀數。
隨後展示修復後的視訊:
output_video_path = 'd:/倚天屠龍記_PPMSVSR_out.mp4'
video_frames = imageio.mimread(output_video_path, memtest=False)
# 獲得視訊的原解析度
cap = cv2.VideoCapture(output_video_path)
fps = cap.get(cv2.CAP_PROP_FPS)
HTML(display(video_frames, fps, size=(16, 12)).to_html5_video())
修復效果:

除了視訊超分外,PaddleGAN中還提供了視訊上色與補幀的功能,配合上述的PP-MSVSR一起使用,即可實現視訊清晰度提高、色彩豐富、播放更加行雲流水。
補幀模型DAIN
DAIN 模型通過探索深度的資訊來顯式檢測遮擋。並且開發了一個深度感知的流投影層來合成中間流。在視訊補幀方面有較好的效果:
ppgan.apps.DAINPredictor(
output_path='output',
weight_path=None,
time_step=None,
use_gpu=True,
remove_duplicates=False)
引數:
output_path (str,可選的): 輸出的資料夾路徑,預設值:output.
weight_path (None,可選的): 載入的權重路徑,如果沒有設定,則從雲端下載預設的權重到本地。預設值:None。
time_step (int): 補幀的時間係數,如果設定為0.5,則原先為每秒30幀的視訊,補幀後變為每秒60幀。
remove_duplicates (bool,可選的): 是否刪除重複幀,預設值:False.
上色模型DeOldifyPredictor
DeOldify 採用自注意力機制的生成對抗網路,生成器是一個U-NET結構的網路。在影象的上色方面有著較好的效果:
ppgan.apps.DeOldifyPredictor(output='output', weight_path=None, render_factor=32)
引數:
output_path (str,可選的): 輸出的資料夾路徑,預設值:output.
weight_path (None,可選的): 載入的權重路徑,如果沒有設定,則從雲端下載預設的權重到本地。預設值:None。
render_factor (int): 會將該引數乘以16後作為輸入幀的resize的值,如果該值設定為32, 則輸入幀會resize到(32 * 16, 32 * 16)的尺寸再輸入到網路中。
結語
AI技術通過分析視訊中的影象資訊並應用影象處理和修復演演算法,自動修復視訊中的缺陷、噪聲、模糊等問題,以提高視訊的觀看質量和可用性,配合語音克隆等技術,從而讓演員在某種程度上實現「數位永生」。