【論文閱讀】HTTP 流量和惡意 URL 的異常檢測
Part 1關於論文
基本資訊
題目:HTTP 流量和惡意 URL 的異常檢測 原始碼:sec2vec原始碼
摘要
在本文中,我們將展示如何利用自然語言處理(NLP)中已知 的方法來檢測 HTTP 請求中的異常情況和惡意 URL。目前大 多數針對類似問題的解決方案要麼基於規則,要麼使用人工 選擇的特徵進行訓練。然而,現代 NLP 方法在深入理解樣本 並因此改進分類結果方面具有巨大潛力。其他依賴於類似想法 的方法往往忽略了結果的可解釋性,而這一點在機器學習中 非常重要。我們正試圖填補這一空白。此外,我們還展示了 所提出的解決方案在多大程度上能夠抵禦概念漂移。在我們 的工作中,我們比較了三種不同的向量化方法:簡單 BoW、 fastText 和當前最先進的語言模型 RoBERTa。獲得的向量隨 後將用於分類任務。為了解釋我們的結果,我們使用了 SHAP 方法。我們在四個不同的資料集上評估了我們方法的可行性 :CSIC2010, UNSW-NB15, MALICIOUSURL 和 ISCXURL2016.前兩個與 HTTP 流量有關,另外兩個包含惡意 URL 。我們展示的結果與其他結果不相上下,甚至更好,最重要 的是,這些結果是可解釋的。
關鍵點
NLP機器學習的可解釋性 抵禦概念漂移 比較了三種向量化方法:簡單 BoW、 fastText 和當前最先進的語言模型 RoBERTa
1. 什麼是機器學習的的解釋性?
關於機器學習可解釋性(Interpretability),又或者是XAI(Explainable Artificial Intelligence )其實就是搞機器學習的研究者們始終存在的一個擔憂:很多現在的深度神經網路沒有辦法以一種從人類角度完全理解模型的決策。我們知道現在的模型既可以完勝世界圍棋冠軍電競冠軍,圖形識別語音識別接近滿分,然而我們對這些預測始終抱有一絲戒備之心,就是我們因為不完全瞭解他們的預測依據是什麼,不知道它什麼時候會出現錯誤。這也是現在幾乎所有的模型都沒法部署到一些對於效能要求較高的關鍵領域,例如運輸,醫療,法律,財經等。(參照自https://zhuanlan.zhihu.com/p/141013178)
2. 什麼是概念漂移?
如果要對概念漂移下定義的話,它的定義是:概念漂移是一種現象,即目標領域的統計屬性隨著時間的推移以一種任意的方式變化。 下面這張圖很直觀:當模型學到的模式不再成立時,就會發生概念漂移。 這種變化可快可慢,比如慢一點的情況: 宏觀經濟條件不斷變化。隨著一些借款人拖欠貸款,信用風險被重新定義。計分模型需要學習它。 而突然變化的案例就是,covid-19,幾乎在一夜之間,流動性和購物模式發生了轉變。它影響了各種模式,甚至是原本 "穩定 "的模式。 家居服,隨著政府的隔離政策頒佈,開始銷量猛增,口罩也是一樣。 簡而言之一句話,資料沒有變化,但是世界變了。 (參照自:https://zhuanlan.zhihu.com/p/406281023)
解決的問題
目前NLP檢測方法基於規則和人工特徵工程進行訓練
Part 2背景
當前研究進度
自然語言處理(NLP)的快速發展,已經開發 出了許多文字向量化方法,其中既有簡單的方法,如 bag-of-words、 tf-idf 或 bag-of-n-grams ;也有更先進的方法,如 Doc2Vec、 fastText、ELMo 或 BERT。其中一些已成功用於解決 HTTP 流量或惡意 URL 中的異常檢測問題。
當前相關方法的優缺點
缺少可解釋性 沒有討論概念漂移的問題--分類器執行的環境是不斷變化的, 很難說這會如何影響其有效性。
Part 3本文主要方法
(1)我們提出了一種 HTTP 流量和惡意URL 的向量化方法,稱為 "Sec2vec"("Security to vector"), 它建立在 RoBERTa 模型的基礎上。我們將其與簡單的 BoW 和 fasText 方法進行了比較。我們使用隨機森林( Random Forest)在下游分類任務中對這些模型進行了評估。
(2) 為了驗證我們的向量化模型(概念漂移)的通用性,我們在不同的資料集上對其進行了驗證(這就是為什麼我們需要 至少兩個同類資料集)。
(3) 我們還展示瞭如何利用向量表示 法來分析資料,並識別與所發現的異常情況相關的可解釋標記模式。
對比三種方法
在我們的工作中,我們比較了下面描述的三種流行的向量化方法。
BoW。BoW(Bag-of-words)是一個簡單的模型,它使用單詞的頻率(獲得的向量中的每個位置對應一個單詞)來表示檔案,或者在我們的範例中,使用從標記化階段獲得的標記來表示檔案。向量大小僅使用最常見的標記進行限制。此外,在我們的實現中,我們決定在向量的最後一個位置表示詞彙外 (OOV) 標記。
什麼是OOV?
未登入詞就是訓練時未出現,測試時出現了的單詞。在自然語言處理或者文書處理的時候,我們通常會有一個字詞庫(vocabulary)。這個vocabulary要麼是提前載入的,或者是自己定義的,或者是從當前資料集提取的。假設之後你有了另一個的資料集,這個資料集中有一些詞並不在你現有的vocabulary裡,我們就說這些詞彙是Out-of-vocabulary,簡稱OOV。
fastText。fastText [1] 是一個類似於 word2vec 的詞向量化模型。fastText 的主要功能是利用每個標記的內部表示,使用有關其 n-gram 的資訊。每個 n-gram 的表示由所有令牌共用,部分解決了 OOV。在我們的工作中,標記被向量化,然後它們的平均值產生線向量,這些線向量用於生成最終的表示向量。
RoBERTa。RoBERTa[14]是一種基於transformer神經網路架構的語言模型。它是對 BERT [4] 的修改——作者刪除了下一句話預測 (NSP) 目標,並決定使用更大的小批次和學習率進行訓練。刪除 NSP 目標可以在缺乏明確句子邊界的檔案中更好地表示標記——從我們的任務角度來看,這很重要。在我們的工作中,最終表示向量是樣本中每條線的平均值,每條線都是標記表示的平均值。令牌表示是通過連線模型的最後四層來獲得的(如原始 BERT 論文中所建議的那樣)。模型的選擇大小為「基本」,最大序列長度為 512,層數設定為 6,以及 12 個注意頭和 15% 的掩蔽標記。
Part 4實驗
1 資料集
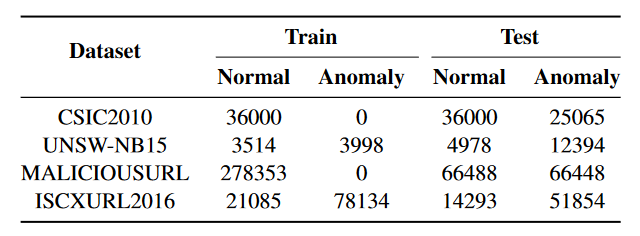
工作重點是不利用特徵工程的半監督方法的可解釋性。這方面在文獻中經常被忽略,但可解釋性技術的使用在任何IDS的實施、維護和使用中都具有相當大的潛力。儘管如此,我們的目標是我們的結果不會比表中顯示的結果更差。這個目標已經實現。
2 過程
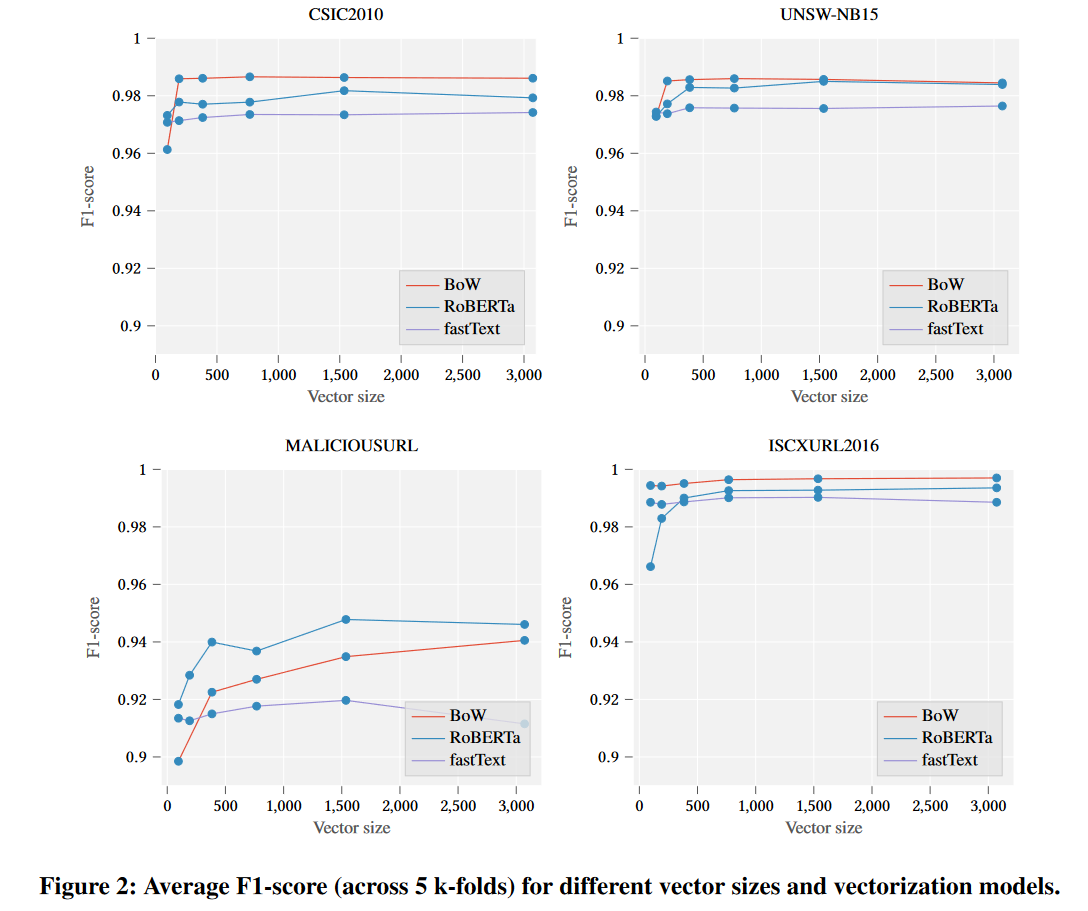
首先,我們使用不同的向量長度(即:96、192、384、768、1536、3072)多次訓練向量化模型(BoW、fastText、RoBERTa)。這個想法背後的主要動機是展示分類分數如何隨著特徵空間的維度而變化。
圖 2 顯示了被視為正類(跨越 5 個 k 倍)的異常類的平均 F1 分數與測試向量大小之間的關係。可以看出,最簡單的向量化方法(BoW)幾乎總是能給我們帶來最好的結果(儘管所有分類器都表現良好,但差異幾乎不明顯)。這證明資料集實際上很容易處理,並且分詞器會產生有意義的(至少對於分類器而言)標記。請記住,此向量化器不是上下文相關的(如 fastText 或 RoBERTa),因此只有「單詞」的頻率很重要。此外,向量大小的增加會導致模型未知值的減小(OOV – BoW 實現中的最後一個位置)。還值得注意的是,僅在正常樣本上訓練的向量化器似乎也顯示出高效率。
最容易解釋的模型是 BoW,因為生成的向量中的每個位置都有意義——它以表格形式描述樣本中給定標記的頻率(因此,無需從語言模型中重新推斷修改後的樣本)。圖 3 顯示了分類器的前五個特徵(基於使用 SHAP 庫獲得的重要性)。在縱軸上顯示所選的標記(例如,在CSIC2010資料集中,重要的標記是:「OOV」、「%」、「/」、"<s>"、「modo」)。
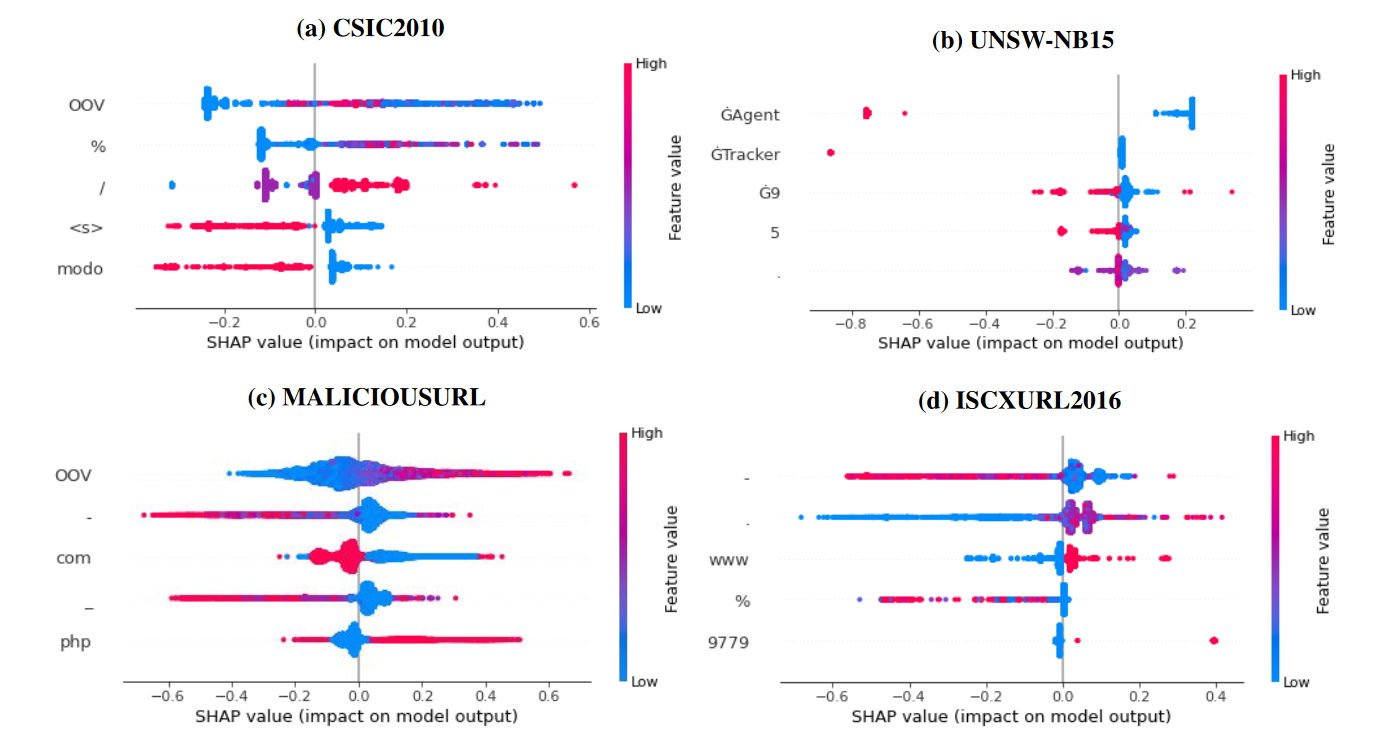
顏色編碼給定標記的數量,與異常類的相關性由正 SHAP 值給出。可以很容易地看出,這些特徵(標記)與模型輸出密切相關。例如,如果「/」符號的數量很高(紅色),則很可能是異常。為了進一步研究這些標記的重要性,我們決定構建一個僅基於它們的簡單決策樹。表 4 顯示了我們的發現——儘管新構建的分類器無法正確地為 MALICIOUSURL 資料集分配標籤,但這些資料集非常容易分類。請注意,事實上,這是 RoBERTa 向量化器表現最好的唯一資料集。為了解釋fastText或RoBERTa,我們使用了SHAP方法。該庫能夠通過遮蔽樣本中的每個標記並重新計算分類概率來生成文字的特徵重要性。由於這個過程很耗時,我們決定只分析每個資料集的一個子集。我們只展示了CSIC2010資料集的發現,但我們得出的結論也適用於所有其他資料集。首先,我們從CSIC2010資料集中選擇一個隨機異常樣本,然後使用RoBERTa模型和歐幾里得距離生成其鄰域。如表5所示(請注意,樣本相似,與注入攻擊有關)。然後,我們計算了上述的 SHAP 值。表 6 顯示了與攻擊相關的標記的標準化總和。 RoBERTa 模型的結果比 BoW 的結果直觀得多,因為該表包含明顯與注入攻擊相關的標記(例如「DROP」)。此外,得分最高的特徵可以與百分比編碼字元相關聯,這些字元通常用於繞過輸入過濾(input sanitation)。另一方面,BoW 方法的重要性分數向我們展示了我們已經建立的東西——如果「/」的數量很高(或者「Accept-Language」檔頭設定為「en」),那麼樣本很可能是異常。雖然它不是一個毫無意義的陳述,但此功能在很大程度上依賴於給定的資料集。這種方法還允許對任何樣品中的重要區域進行著色——如圖 4 所示。
樣本「0」,其中包含使用 SHAP 獲得的彩色相關標記。第一張圖片(從上到下)與BoW模型相關,第二張圖片與fastText相關,第三張圖片與RoBERTa相關。紅色表示應與異常相對應的標記,藍色表示樣本的「正常」部分
可以看出,在RoBERTa模型中,樣本的整個異常部分以紅色突出顯示(查詢的正常部分以藍色標記,大部分是正確的)。fastText 和 BoW 模型都不是這種情況。在這一點上,我們表明,儘管 RoBERTa 沒有得到最佳結果,但是分類所基於的特徵是可解釋的(分類並非純粹基於資料中的強偽影)。與BoW一樣,fastText模型獲得的特徵也是不可解釋的(可能是由於多次平均操作)。
這裡強調RoBERTa模型獲得的效果雖然不是很好,但是結果都是可解釋的。
討論
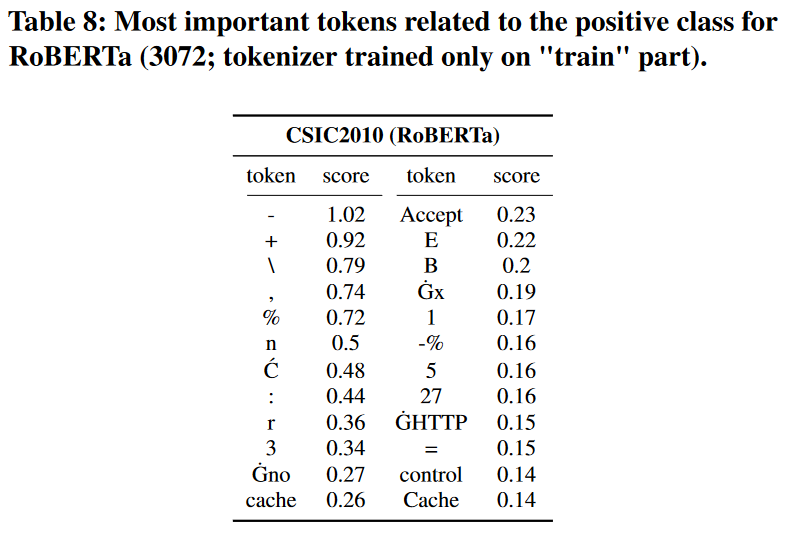
更詳細討論的一個主題是分詞器訓練過程。一般來說,如果標記是未知的,它們要麼被分成更小的塊,要麼被替換為「〈unk〉」標記(這種情況很少見),因此,表 6 將更難解釋(例如,單詞「DROP」可以分解為單個字母)。為了證明這一點,我們只使用「訓練」部分資料來訓練我們的分詞器,並重新執行我們的實驗。表8給出了新獲得的全域性(與表6中相同的子集)重要性。儘管所呈現的令牌不再與攻擊明確相關,但它們仍然比使用更好的字典(例如,百分比編碼字元)的 BoW 方法更令人信服。針對先前引入樣本(圖 6)的新生成的區域性重要性仍然有用(異常部分標記得很好),儘管分類器也考慮了它的其他部分。大多數分類分數保持穩定(表7),儘管RoBERTa模型的CSIC2010資料集的結果有所下降。
圖6中原始選擇的特徵
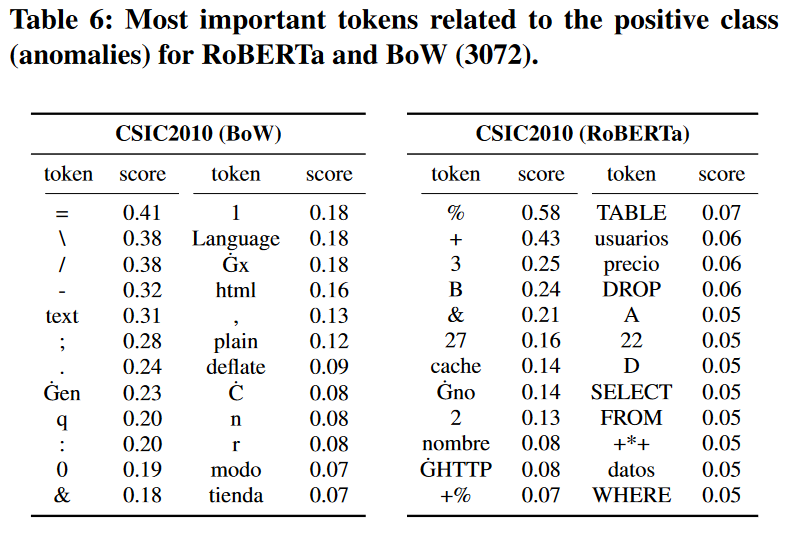
圖8中的新特徵
Part 5結果
我們得到的結果非常接近所有樣本都被歸類為異常時得到的結果。這表明,領域的快速變化可能會對分類產生可怕的後果。另一方面,我們還在真實世界的未標記資料(伺服器紀錄檔)上測試了其中一個 RoBERTa 模型(和相關分類器),我們成功發現了 50 次新 Log4j 漏洞利用嘗試中的 47 次(圖 5)和許多更常見的攻擊嘗試(使用預測概率作為異常分數)。
對於四個資料集中的三個資料集,分類結果保持在同一水平,但是,CSIC2010問題為概念漂移帶來了另一個方面。儘管 RoBERTa 解決了詞彙量不足的問題,但從我們任務的角度來看,所有標記的知識仍然很重要。為了克服這個問題,需要一個更好的分詞器。一種解決方案是使用其他資料來源(例如 SQL 查詢)對其進行訓練。理想情況下,應該有公開可用的資料集,其中包含來自各個網路安全領域的文字樣本。另一種選擇是手動擴充套件詞彙表或構建也可以利用 BBPE 的自定義分詞器。由於HTTP請求結構良好,使用語法樹似乎是一個很有前途的研究方向。然而,在現實中,字典中缺少特定的令牌不應該是一個常見的問題 - 新的攻擊很少引入許多以前看不見的攻擊(在我們的實驗中,模型不知道單個惡意令牌,但成功標記了異常)。在現實世界中,嵌入的二進位制資料(例如,對談 ID、cookie 的內容、base64)可能是一個更大的問題。為了保持解決方案的質量,可能應該將其替換為自定義令牌,特別是為此目的建立的令牌。僅就較差的分類結果而言,微調應該會增加它們,但全域性解釋仍然不清楚。請注意,微調意味著將分類器與語言模型一起訓練。在我們的實驗中,我們決定使用凍結表示,因為一個沒有被引入異常概念的功能良好的語言模型,能在一個完全無監督的系統中帶來了更大的潛力。這是我們未來的工作之一。
Part 6總結
我們認為,獲得良好的向量表示是構建正確 IDS 系統的關鍵。我們在研究中使用的分類器幾乎無關緊要,因為獲得的特徵提供了精細的類別分離。請記住,我們以完全無監督的方式訓練向量化器。獲得的模型可以很容易地應用於其他情況。因此,未來最重要的任務是準備一個基於各種來源的資料進行訓練的RoBERTa模型。
我們相信,它可以像自然語言模型一樣使用——作為任何其他主題相關任務的堅實基礎。其次,我們想僅使用無監督的下游方法來檢查這種模型的有效性,因為當前的方法需要標籤來訓練分類器。這也是我們沒有將RoBERTa模型與分類器一起訓練的原因之一(另一個是與其他模型進行公平的比較),儘管效能可能會提高。然而,展示儘可能高的結果並不是我們的目標(但我們給出的分數是令人滿意的)。接下來,正如我們在上一節中所描述的,開發一個更好的分詞器也很重要。最後,值得如何以增量方式訓練模型(和分類器)。換句話說,如何提高準確性以及如何處理真實場景中的概念漂移。
END
一個只記錄最真實學習網路安全歷程的小木屋,最新文章會在公眾號更新,歡迎各位師傅關注!
公眾號名稱:奇怪小木屋

部落格園主頁:
部落格園-我記得https://www.cnblogs.com/Zyecho/