LLM面面觀之LLM復讀機問題及解決方案
1. 背景
關於LLM復讀機問題,本qiang~在網上搜颳了好幾天,結果是大多數客觀整理的都有些支離破碎,不夠系統。
因此,本qiang~打算做一個相對系統的整理,包括LLM復讀機產生的原因以及對應的解決方案。
2. LLM復讀機範例
範例1:短語級別的重複
|
User: 你喜歡北京麼? AI: 北京是中國的首都,有很多名勝古蹟,如長城,故宮,天壇等,我十分喜歡喜歡喜歡喜歡….. |
範例2:句子級別的重複
|
User: 你喜歡北京麼? AI: 北京是中國的首都,有很多名勝古蹟,如長城,故宮,天壇等,我十分熱愛北京,我十分熱愛北京,我十分熱愛北京,….. |
3. LLM復讀機原因
本文主要參考了清華大學的論文《Learning to Break the Loop: Analyzing and Mitigating Repetitions for Neural Text Generation》,文中詳細介紹了LLM產生復讀的原因。論文的前提假設是LLM的解碼均為貪心解碼(greedy decoding),即每次生成的token選擇詞表中概率最大的token。
結論如下:
(1) LLM趨向於提高重複先前句子的概率
特別地,即使僅出現一條句子級的上下文重複,重複的概率在大多數情況下也會增加。產生這種現象的原因可能是LLM對上下文非常有信心,當先前的token共用同一個句子級的上下文時,模型會學到一條捷徑,直接複製該token。
另一種解釋就是Inudction Head機制,即模型會傾向於從前面已經預測word裡面挑選最匹配的詞。
舉個例子來說明下,範例1中的第二個’喜歡’共用了同句子中的’我十分喜歡’,因此模型直接會將’喜歡’拷貝至’我十分喜歡’,進而生成’我十分喜歡喜歡’
(2) 自我強化效應(self-reinforcement effect)
重複的概率幾乎隨著歷史重複次數的增加而單調增加,最終,重複概率穩定在某個上限值附近。
一旦生成的句子重複幾次,模型將會受困於因自我強化效應引起的句子迴圈。
下圖是論文中的圖,意思是隨著重複次數的增加,’general’一詞的概率幾乎單調增加,最終趨於穩定。其中紅柱表示生成相同token的概率,藍色表示最大概率。
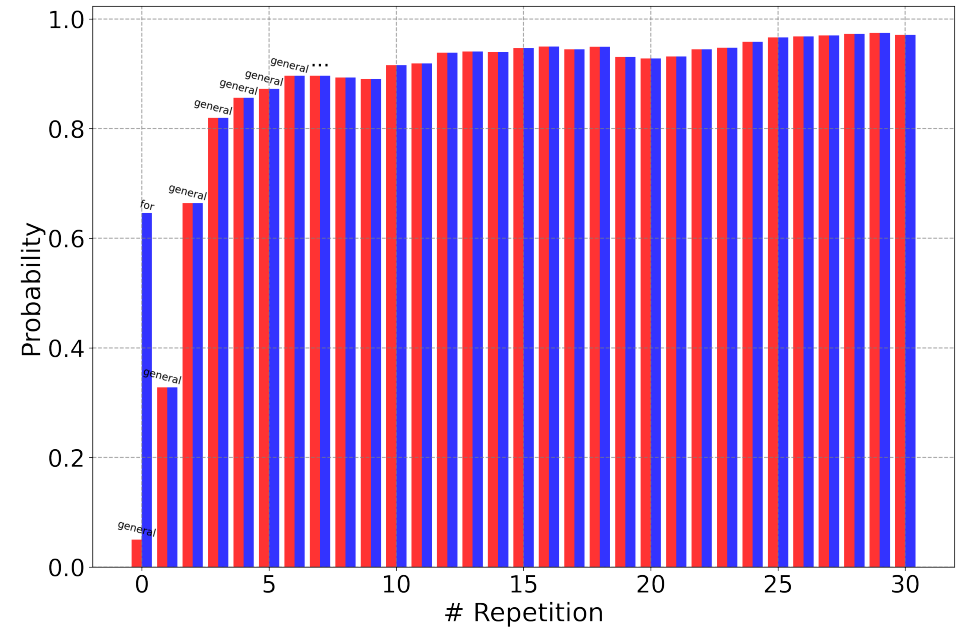
(3) 初始概率較高的句子通常具有較強的自我強化效應。
4. 如何解決
目前針對LLM重複生成的問題,主要有兩種策略,一種是基於訓練思想,一種是基於解碼策略。
4.1 基於訓練策略
整體思想就是通過構造偽資料,即短語重複、句子重複等偽資料,如短語或句子重複N遍,然後設計重複懲罰項來抑制大模型生成重複句子。
論文中提出了DITTO方法即採用了此策略,DITTO全稱為PseuDo RepetITion PenalizaTiOn(不得不佩服演演算法名稱的設計精美~)。
重複懲罰項通過設計損失函數來達成,其中是懲罰因子λ,論文中提到,對於開放式生成,推薦取值為0.5,對於總結摘要類任務,取值為0.9效能更好。
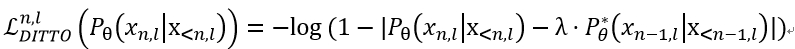
程式碼分析:
DITTO損失函數計算的程式碼塊位於https://github.com/Jxu-Thu/DITTO中」DITTO/fairseq/custom/repetetion_penalty_accum_loss.py」方法中,大體流程簡要分析如下:
|
# 構造隨機重複的特徵 sample, P, L, N, K = self.re_orgnize_sentence(sample) # 基於構造的重複特徵進行預測 net_output = model(**sample['net_input'])
……….
## 計算損失函數 # 獲取重複的基線概率資訊 gt_probs, mask, valid_tokens = self.obtain_rep_baseline_prob(model.get_targets(sample, net_output), target_probs.detach(), P, L, N, K) # 損失函數公式套用 one_minus_probs = torch.clamp((1.0 - torch.abs((target_probs - gt_probs*self.rep_reduce_gamma))), min=1e-20) loss = -torch.log(one_minus_probs) * mask loss = loss.sum() |
此外,基於訓練的策略還有其他方式,如UL(unlikelihood training)和SG(straight to gradient),論文連結可以參考第6小節。
4.2 基於解碼策略
基於解碼策略包含諸多方法,如beam search, random search(topK, topP), 溫度, ngram等。
(1) 集束搜尋(beam search)
針對貪心策略的改進,思想就是稍微放寬一些考察範圍。即,在每一個時間步,不再只保留當前分數最高的1個輸出(貪心策略),而是保留num_beams個,當num_beams=1時,集束搜尋就退化成了貪心搜尋。
(2) random search(topK, topP)
topK即從概率最高的K個token中進行篩選,即允許其他高分tokens有機會被選中
topP將可能性之和不超過特定值的top tokens列入候選名單,topP通常設定較高的值,目的是限制可能被取樣的低概率token的長尾
(3) 溫度T
較低的溫度意味著較少的隨機性,溫度為0將始終產生相同的輸出,較高的溫度意味著更多的隨機性,可以幫助模型給出更有創意的輸出。
基於解碼的策略牆裂建議直接查閱transformers框架中的實現方法,本qiang~切身體會,閱讀原始碼確實能愉悅身心~
5. 總結
一句話足矣~
本文主要展開解讀了LLM的復讀機問題,並參考相關論文,給出基於訓練策略和基於解碼策略的解決手段,相信客官們清楚該問題了。
靜待下一次的LLM知識點分享~
6. 參考
(1) DITTO: https://arxiv.org/pdf/2206.02369.pdf
(2) UL: https://arxiv.org/pdf/1908.04319v2.pdf
(3) SG: https://arxiv.org/pdf/2106.07207v1.pdf
(4) beam search: https://zhuanlan.zhihu.com/p/114669778
(5) random search(topK, topP), 溫度: https://zhuanlan.zhihu.com/p/613428710
