【scikit-learn基礎】--『預處理』之 標準化
2023-12-13 15:00:27
資料的預處理是資料分析,或者機器學習訓練前的重要步驟。
通過資料預處理,可以
- 提高資料質量,處理資料的缺失值、異常值和重複值等問題,增加資料的準確性和可靠性
- 整合不同資料,資料的來源和結構可能多種多樣,分析和訓練前要整合成一個資料集
- 提高資料效能,對資料的值進行變換,規約等(比如無量綱化),讓演演算法更加高效
本篇介紹的標準化處理,可以消除資料之間的差異,使不同特徵的資料具有相同的尺度,
以便於後續的資料分析和建模。
1. 原理
資料標準化的過程如下:
- 計算資料列的算術平均值(
mean) - 計算資料列的標準差(
sd) - 標準化處理:\(new\_data = (data - mean) / sd\)
data 是原始資料,new_data 是標準化之後的資料。
根據原理,實現的對一維資料標準化的範例如下:
import numpy as np
# 標準化的實現原理
data = np.array([1, 2, 3, 4, 5])
mean = np.mean(data) # 平均值
sd = np.std(data) # 標準差
# 標準化
data_new = (data-mean)/sd
print("處理前: {}".format(data))
print("處理後: {}".format(data_new))
# 執行結果
處理前: [1 2 3 4 5]
處理後: [-1.41421356 -0.70710678 0. 0.70710678 1.41421356]
使用scikit-learn庫中的標準化函數scale,得到的結果也和上面一樣。
from sklearn import preprocessing as pp
data = np.array([1, 2, 3, 4, 5])
pp.scale(data)
# 執行結果
array([-1.41421356, -0.70710678, 0. , 0.70710678, 1.41421356])
scikit-learn庫中的標準化函數scale不僅可以處理一維的資料,也可以處理多維的資料。
2. 作用
標準化處理的作用主要有:
2.1. 消除資料量級的影響
資料分析時,不一樣量級的資料放在一起分析會增加很多不必要的麻煩,比如下面三組資料:
data_min = np.array([0.001, 0.002, 0.003, 0.004, 0.005])
data = np.array([1, 2, 3, 4, 5])
data_max = np.array([10000, 20000, 30000, 40000, 50000])
三組資料看似差距很大,但是標準化處理之後:
from sklearn import preprocessing as pp
print("data_min 標準化:{}".format(pp.scale(data_min)))
print("data 標準化:{}".format(pp.scale(data)))
print("data_max 標準化:{}".format(pp.scale(data_max)))
# 執行結果
data_min 標準化:[-1.41421356 -0.70710678 0. 0.70710678 1.41421356]
data 標準化:[-1.41421356 -0.70710678 0. 0.70710678 1.41421356]
data_max 標準化:[-1.41421356 -0.70710678 0. 0.70710678 1.41421356]
標準化處理之後,發現三組資料其實是一樣的。
將資料轉化為相同的尺度,使得不同變數之間的比較更加方便和有意義,避免對分析結果產生誤導。
2.2. 增強視覺化效果
此外,標準化之後的資料視覺化效果也會更好。
比如下面一個對比學生們數學和英語成績的折線圖:
math_scores = np.random.randint(0, 150, 10)
english_scores = np.random.randint(0, 100, 10)
fig, ax = plt.subplots(2, 1)
fig.subplots_adjust(hspace=0.4)
ax[0].plot(range(1, 11), math_scores, label="math")
ax[0].plot(range(1, 11), english_scores, label="english")
ax[0].set_ylim(0, 150)
ax[0].set_title("標準化之前")
ax[0].legend()
ax[1].plot(range(1, 11), pp.scale(math_scores), label="math")
ax[1].plot(range(1, 11), pp.scale(english_scores), label="english")
ax[1].set_title("標準化之後")
ax[1].legend()
plt.show()
隨機生成10個數學和英語的成績,數學成績的範圍是0~150,英語成績的範圍是0~100。
標準化前後的折線圖對比如下: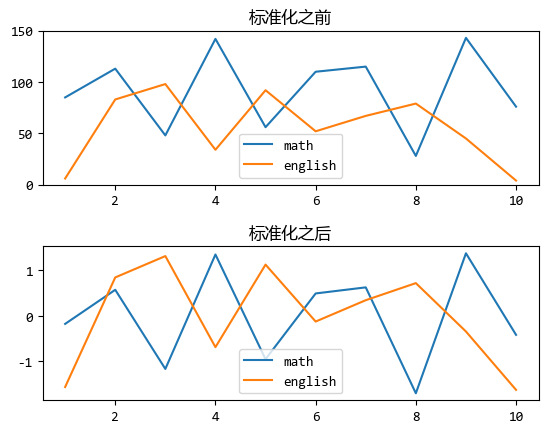
標準化之前的對比,似乎數學成績要比英語成績好。
而從標準化之後的曲線圖來看,其實兩門成績是差不多的。
這就是標準化的作用,使得視覺化結果更加準確和有意義。
2.3. 機器學習的需要
許多機器學習演演算法對輸入資料的規模和量綱非常敏感。
如果輸入資料的特徵之間存在數量級差異,可能會影響演演算法的準確性和效能。
標準化處理可以將所有特徵的資料轉化為相同的尺度,從而避免這種情況的發生,提高演演算法的準確性和效能。
3. 總結
總的來說,資料標準化處理是資料處理中不可或缺的一步,它可以幫助我們消除資料之間的差異,提高分析結果的效能和穩定性,增加資料的可解釋性,從而提高我們的決策能力。