拆解全景,解鎖未來——深度分析大模型六大領域及五大應用解決方案
在本篇文章中,我們將帶您首先通過解讀 LLM 的全景圖,深入探討了 LLM 的六個關鍵領域,隨後提出五種主要方案以解決企業在這一技術領域面臨的挑戰。從商業模型到開源模型、微調、自定義構建,再到與 AI 提供商的合作,本文將引領您深入瞭解 LLM 的技術脈絡,為探索和應用這一技術提供一些思考與指導。
大型語言模型圖
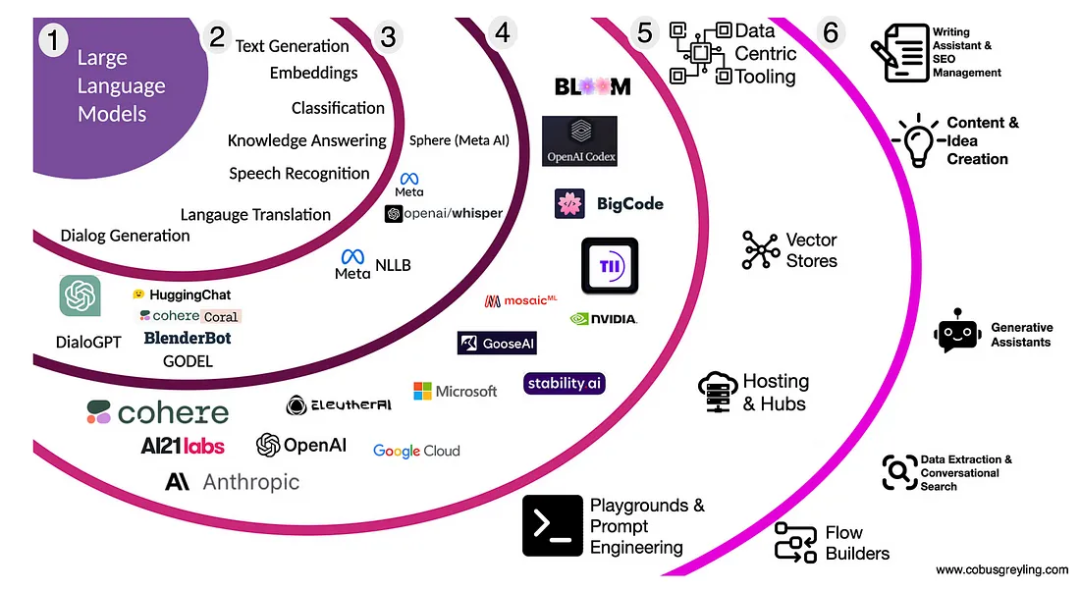
上圖顯示了由 LLMs 延伸出來的內容,分為六個區域。隨著這些區域的擴充套件,產品和服務有不同的需求和機會。其中一些機會已經被發現,但還有一些尚未被發現。在區域5為差異化、實質性的內建智慧財產權和卓越的使用者體驗提供了更大的機會,使企業能夠利用 LLMs 的力量。
區域1 - 可用的大型語言模型
就 LLM 而言,從本質上講 LLM 是與語言繫結的,不過多模態模型已經在影象、音訊等方面引入。這種轉變產生了一個更通用的術語,即基礎模型。除了增加的模態性外,還提供了多個更專注於特定任務的模型,以及大量開源模型可供使用。
新的提示工程(Prompt Engineering)技術[1]說明了如何增強模型效能,以及市場如何朝著利用資料發現、資料設計、資料開發和資料交付來實現這種程度的模型自治的方向發展。
除了增加模式外,大型商業供應商還提供了多種模式,這些模式更加針對具體任務。此外,還出現了大量開源模型,新的提示技術說明了如何提高模型效能,以及市場如何朝著利用資料發現、資料設計、資料開發和資料交付來實現模型自治的方向發展。
區域2 - 通用用例
隨著大型語言模型的出現,功能更加細分,模型被訓練用於特定任務。例如 Meta 下的 Sphere 專注於知識問答,稱之為知識密集型自然語言處理(KI-NLP)。像 DialoGPT、GODEL 和其他模型則專注於對話管理等方面。
最近 LLM 的發展採用了一種方法,即模型結合了這些特點,並且可以通過不同的提示技術提取出令人驚歎的效能。
LLM 的主要實現和應用如下:
-
文字分析變得越來越重要,嵌入對於這類實現至關重要。
-
語音識別,也稱為 ASR,是將音訊語音轉換為文字的過程。通過一種稱為詞錯誤率(WER)的方法可以輕鬆地衡量任何ASR過程的準確性。ASR 為 LLM 的訓練和使用提供了大量的錄音語言資料。
這個領域有兩個值得注意的變化:
- 知識問答和知識密集型 NLP(KI-NLP)方法被 RAG 提示工程在推理中取代。
- 對話生成由 GODEL 和 DialoGPT 等發展推動。這些已被 ChatGPT、HuggingChat 和 Cohere Coral 等特定實現所取代。還有通過提示工程,在提示中呈現對話上下文的小樣本訓練(Few-shot training)。
區域3-具體實現
該區域列出了一些特定用途的模型。目前已逐漸分為兩部分,一個是通用的 LLM,另一個則是基於 LLM 的數位/個人助手。
區域4-模型
這裡列出了業內最為突出的大型語言模型提供商。大多數 LLM 都具有內建的知識和功能,包括自然語言翻譯、解釋和編寫程式碼的能力,通過提示工程進行對話和上下文管理。
區域5-基礎工具
該領域顯示的是利用 LLM 的工具,包括向量儲存、Playground 和提示工程工具。例如 HuggingFace 這樣的託管平臺通過模型卡和簡單的推理 API 實現無程式碼互動。
在這個區域中我還列出了資料中心工具(Data Centric Tooling),它專注於重複使用 LLM 的高價值用途。
在這個領域的市場機會是創造基礎工具,以解決未來對資料發現、資料設計、資料開發和資料交付的需求。
企業可參考的 LLM 五大應用方案
企業希望利用 LLM 來創造更多商業價值和競爭優勢,隨著 LLM 領域的迅速演進和分化,做出正確的選擇不僅需要了解可用的模型,還需要了解每個模型如何與企業獨特的業務目標保持一致。企業不得不在日益複雜的選擇面前謹慎抉擇。這裡我們列出關於企業採用 LLM 的五大方案,企業可單獨或混合應用以實現其業務目標。
商業模型
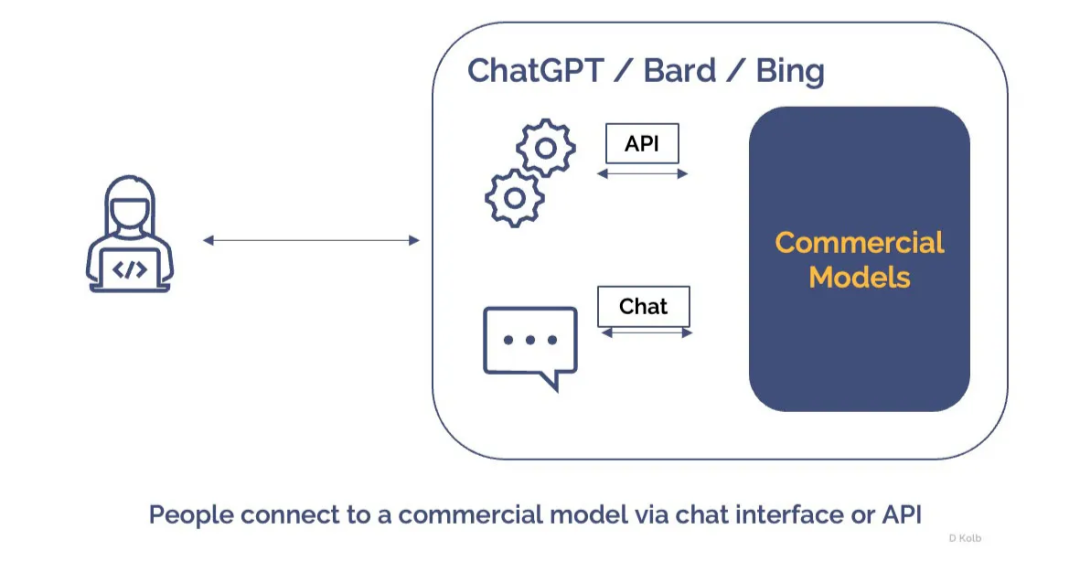
商業模型,如 ChatGPT、Google Bard 和 Microsoft Bing,為追求實現大型語言模型的有遠見的領袖和企業家提供了一種簡單高效的解決方案。這些模型已經在不同的資料集上進行了廣泛的訓練,提供了文字生成、語言翻譯和問答能力。它們的主要優勢在於它們的即時可用性。通過正確的策略、程式和流程,企業可以快速部署這些模型,迅速利用它們的能力。
然而,需要記住的是,雖然這些模型設計用於多功能性,服務於廣泛的應用,但它們可能在您企業特定的任務中表現不佳。因此,應考慮它們在您獨特的業務需求中的適用性。
開源模型
對於考慮 LLM 解決方案的企業來說,開源模型是一種經濟實惠的選擇。這些免費提供的模型提供先進的語言功能,同時將成本最小化。然而,值得注意的是,對於需要廣泛客製化的組織,開源模型可能無法提供與專有選項相同的控制水平。
在某些情況下,它們是基於比商業模型更小的資料集進行訓練的。開源 LLM 仍然提供文字生成、翻譯和問答任務的多功能性。開源模型的主要優勢在於其成本效益。幾家開源提供商提供微調以與特定的業務需求相一致,提供更加個性化的方法。
一個考慮因素是開源模型的維護和支援。公共雲提供商經常更新和改進他們的商業模型,而開源模型可能缺乏一致的關注。評估所選擇的開源模型的可靠性和持續發展是確保長期適用性的重要因素。
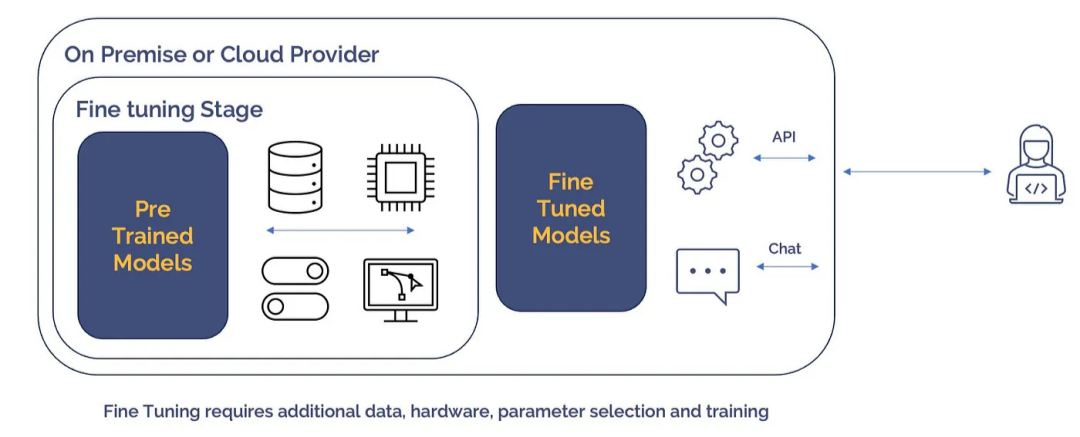
微調模型
微調模型允許企業在特定的業務任務上實現最佳效能。這些模型通過使用組織的資料進行額外的訓練,結合商業模型的優勢。
一家希望改進其客戶支援聊天機器人的公司可能會從一個能夠理解和生成自然語言的商業模型開始。他們可以使用其歷史客戶支援聊天記錄來對其進行微調,以訓練其特定的客戶查詢、響應和上下文。
微調模型的優點在於能夠根據具體需求客製化模型,同時受益於商業模型提供的易用性。這對於行業特定的術語、獨特的要求或專業用例尤其有價值。然而,微調可能需要大量的資源,需要一個準確代表目標領域或任務的合適資料集。獲取和準備這個資料集可能涉及額外的成本和時間。
微調可以使企業將大型語言模型適應其獨特的要求,提高效能和任務特定的相關性。儘管涉及規劃和投資,但這些好處使得微調模型對於旨在增強其語言處理能力的組織非常有吸引力。
構建自定義語言模型
從頭開始構建自定義語言模型 LLM 可以為企業提供無與倫比的控制和客製化性,但成本較高。這個選項很複雜,需要機器學習和自然語言處理的專業知識。自定義 LLM 的優勢在於其量身客製化的性質。它可以根據您企業的獨特需求進行設計,確保最佳效能和目標的一致性。
通過自定義 LLM,您可以控制模型的架構、訓練資料和微調引數。然而,構建自定義 LLM 非常耗時和昂貴。它需要一個熟練的團隊、硬體、廣泛的研究、資料收集和註釋以及嚴格的測試。還需要進行持續的維護和更新,以保持模型的有效性。
構建自定義 LLM 是尋求絕對控制和高效能的組織的最佳選擇。儘管需要投資,但它為您的語言處理需求提供了高度客製化的解決方案。
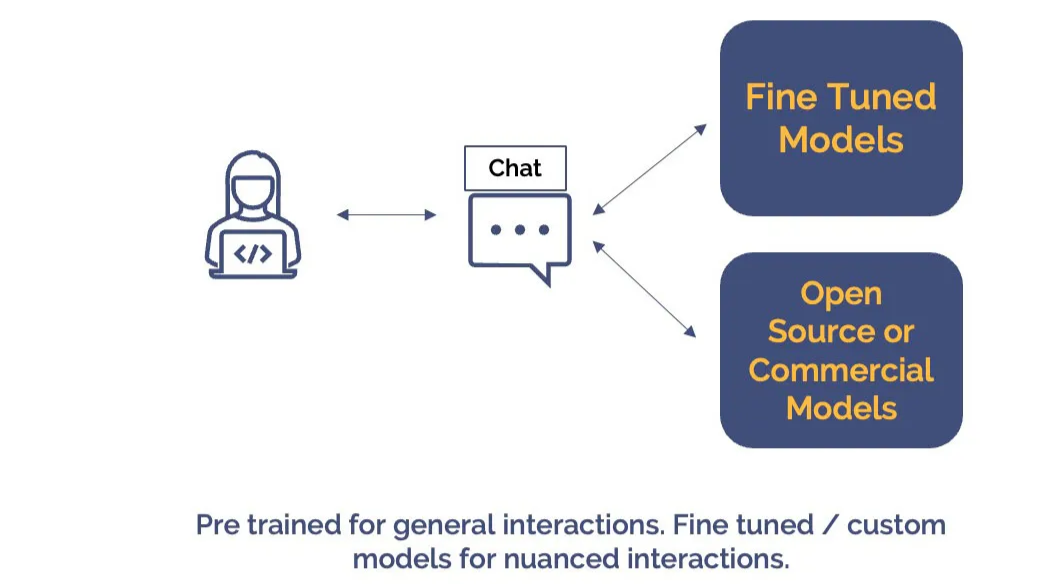
混合方法
混合方法結合了不同策略的優勢,提供了一個平衡的解決方案。通過將商業模型與微調或自定義模型結合使用,企業可以實現客製化化和高效的語言模型策略。
該方法經過優化,以滿足特定任務要求和行業細微差別。例如,當出現新的客戶請求時,商業模型可以處理文字並提取相關資訊。這種初始互動受益於商業模型對語言理解和知識的普遍掌握。經過明確訓練於企業客戶參與和對話資料上的微調或自定義模型接管。它分析處理後的資訊,提供客製化化和上下文相關的迴應,利用其在客戶評價和類似互動方面的訓練。
通過採用混合方法,企業可以實現一個靈活高效的策略,提供客製化化解決方案的同時利用商業模型中的知識。這個策略為在已有語言模型的背景下解決企業特定需求提供了實用和有效的方法。
與 AI 提供商合作
與 AI 提供商合作是實施 LLM 的一個可行選擇。這些提供商提供專業知識和資源,用於構建和部署客製化語言模型。與 AI 提供商合作的優勢在於獲得他們的專業知識和支援。他們擁有深入的機器學習和自然語言處理知識,有效地指導企業。他們提供見解,推薦模型,並在開發和部署過程中提供支援。不過選擇與 AI 提供商合作,請考慮可能涉及額外成本,評估財務影響。
通過與 AI 提供商合作,企業可以從專業知識中受益,確保 LLM 的順利整合。儘管應考慮成本,但與AI提供商合作的優勢,尤其是在專業指導和支援方面,可能超過了費用。
結論
在快速發展的生成式 AI 世界中,選擇正確的道路不僅僅需要掌握可用模型,還需要理解每個模型如何與您獨特的業務目標相契合。成功實施這些模型並非偶然之舉,需要取決於全面的思考,平衡即時需求與未來趨勢和機遇。並非所有情況都有通用的解決方案,因此最佳的策略應當是量身打造的。在生成式 AI 的複雜環境中,最大的挑戰通常不在於技術本身,而在於確定正確的策略以釋放其潛力。