訓練一個目標檢測模型
(一)識別背景/目的
第十八屆全國大學生智慧汽車競賽室外 ROS 無人車賽(高教組)
無人車在室外執行中, 需要探索未知環境, 識別障礙物, 停車標誌牌、紅綠燈等標誌物。
比賽場地為不規則環形場地, 由紅藍兩色錐桶搭建而成, 整體賽道由直線區域、 "S"彎、 直角區域、 圓形區域等部分元素或全部元素構成

(二)識別/執行場地
① 一食堂二樓

② 室外網球場地

(三)實現效果



(四)技術棧
- 識別模型:yolov5
- 標註工具:labelmaster
- 執行環境:Ubuntu20.04
- 加速方式:使用onnx及tensorrt將模型進行推理加速
(五)識別類別
- 0: red 紅色錐桶
- 1: blue 藍色錐桶
- 2: stop 紅綠燈(紅燈)
- 3: wait 停車牌

(六)yolov5目標檢測模型及其環境設定過程
第一步:下載yolov5原始碼

第二步:解壓原始碼壓縮包
第三步:在程式碼編輯器 pycharm/vscode 中開啟原始碼資料夾(設定完成)

(七)訓練資料、測試資料採集

第一步:開啟 ROS 智慧車攝像頭
終端輸入 cheese

第二步:點選拍攝按鍵,採集資料集圖片
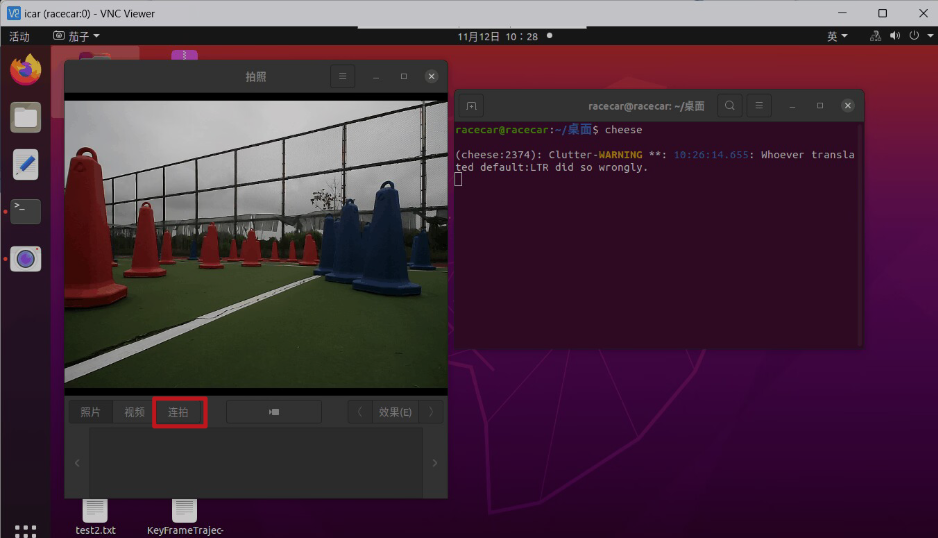
第三步:將無人車上的照片拷貝到電腦上,為資料標註做準備

(八)訓練資料、測試資料標註、整理
第一步:安裝 labelmaster 庫
pip install labelImg

第二步:啟動 labelmaster
labelImg

第三步:開啟採集圖片的儲存路徑


第四步:滑鼠右鍵圖片,建立區塊標註
左側選擇建立區塊

滑鼠移至目標的左上角

點選滑鼠並拉直右下角

在出現的框裡面選擇自己標註目標的分類

鍵入新的分類,則會自動生成一個新的分類
這邊選擇wait的紅綠燈分類

左鍵單擊 ok 鍵
完成單個目標的標註

其他類別同樣操作,只是分類時選擇不同分類
依次按照識別類別對其餘區塊進行標註
例如下圖選擇red的紅色錐桶分類

全部完成後左上角點選「改變儲存目錄」
選擇儲存的目標資料夾
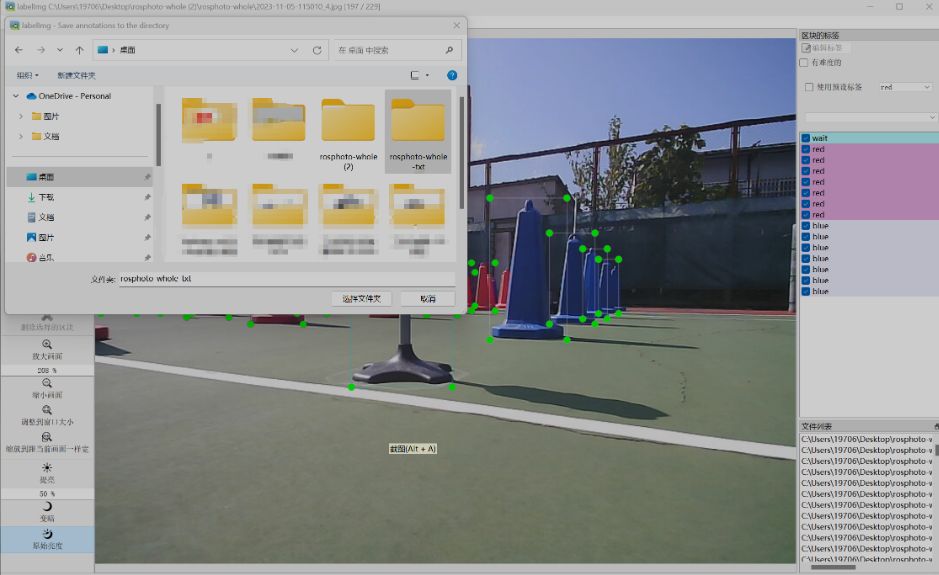
第五步:儲存標註引數,儲存為 .txt 檔案字尾
點選儲存下方的按鍵,改變儲存的檔案格式,儲存為 .txt 檔案字尾
「yolo」對應的是「txt」檔案
「PascalVOC」對應的是「xml」檔案
「CreatelML」對應的是「json」檔案
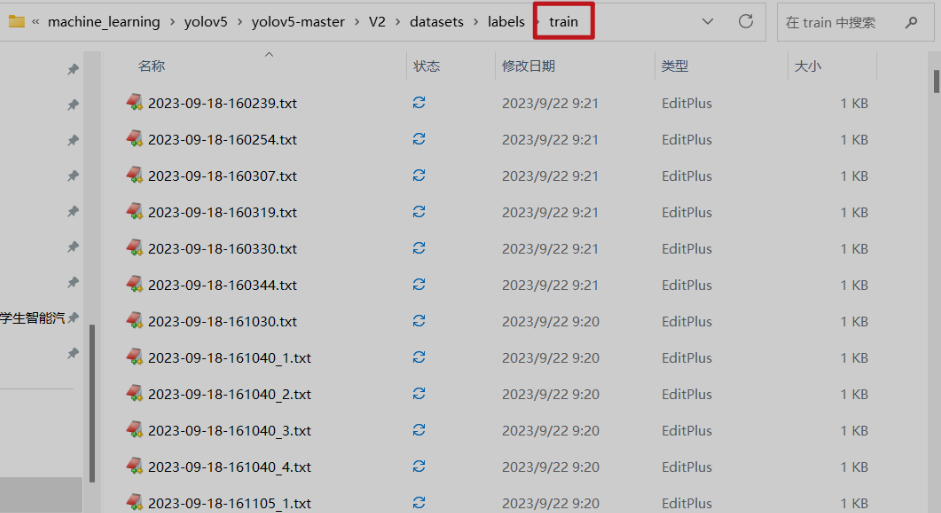
最後單擊儲存完成標註
此時,儲存的資料夾中會自動生成一個 class.txt 檔案

(九)模型訓練過程
為了減小最終模型儲存的大小,保證無人車整體執行的流程性,我們選用 yolov5n.yaml 的引數作為樣本
原始碼:yolov5n.yaml
# Parameters
nc: 80 # number of classes
depth_multiple: 0.33 # model depth multiple
width_multiple: 0.25 # layer channel multiple
anchors:
- [10,13, 16,30, 33,23] # P3/8
- [30,61, 62,45, 59,119] # P4/16
- [116,90, 156,198, 373,326] # P5/32
# YOLOv5 v6.0 backbone
backbone:
# [from, number, module, args]
[[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
[-1, 1, Conv, [128, 3, 2]], # 1-P2/4
[-1, 3, C3, [128]],
[-1, 1, Conv, [256, 3, 2]], # 3-P3/8
[-1, 6, C3, [256]],
[-1, 1, Conv, [512, 3, 2]], # 5-P4/16
[-1, 9, C3, [512]],
[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
[-1, 3, C3, [1024]],
[-1, 1, SPPF, [1024, 5]], # 9
]
# YOLOv5 v6.0 head
head:
[[-1, 1, Conv, [512, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 6], 1, Concat, [1]], # cat backbone P4
[-1, 3, C3, [512, False]], # 13
[-1, 1, Conv, [256, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 4], 1, Concat, [1]], # cat backbone P3
[-1, 3, C3, [256, False]], # 17 (P3/8-small)
[-1, 1, Conv, [256, 3, 2]],
[[-1, 14], 1, Concat, [1]], # cat head P4
[-1, 3, C3, [512, False]], # 20 (P4/16-medium)
[-1, 1, Conv, [512, 3, 2]],
[[-1, 10], 1, Concat, [1]], # cat head P5
[-1, 3, C3, [1024, False]], # 23 (P5/32-large)
[[17, 20, 23], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
]
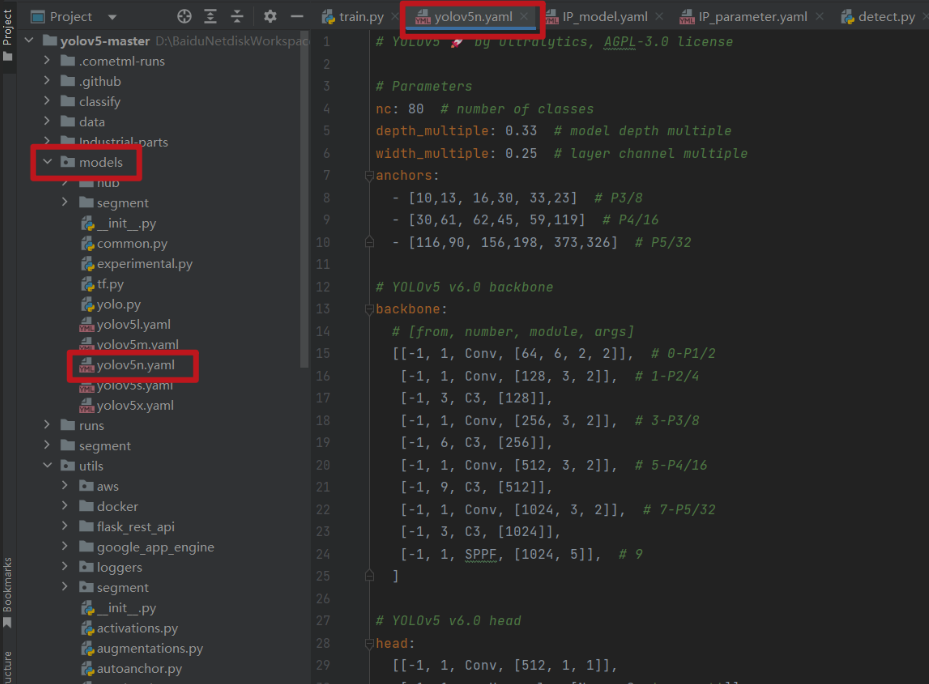
第一步:設定識別模型引數
① IP_model.yaml(在 yolov5n.yaml 基礎上進行修改)
# Parameters
nc: 4 # number of classes
depth_multiple: 0.33 # model depth multiple
width_multiple: 0.25 # layer channel multiple
anchors:
- [10,13, 16,30, 33,23] # P3/8
- [30,61, 62,45, 59,119] # P4/16
- [116,90, 156,198, 373,326] # P5/32
# YOLOv5 v6.0 backbone
backbone:
# [from, number, module, args]
[[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
[-1, 1, Conv, [128, 3, 2]], # 1-P2/4
[-1, 3, C3, [128]],
[-1, 1, Conv, [256, 3, 2]], # 3-P3/8
[-1, 6, C3, [256]],
[-1, 1, Conv, [512, 3, 2]], # 5-P4/16
[-1, 9, C3, [512]],
[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
[-1, 3, C3, [1024]],
[-1, 1, SPPF, [1024, 5]], # 9
]
# YOLOv5 v6.0 head
head:
[[-1, 1, Conv, [512, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 6], 1, Concat, [1]], # cat backbone P4
[-1, 3, C3, [512, False]], # 13
[-1, 1, Conv, [256, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 4], 1, Concat, [1]], # cat backbone P3
[-1, 3, C3, [256, False]], # 17 (P3/8-small)
[-1, 1, Conv, [256, 3, 2]],
[[-1, 14], 1, Concat, [1]], # cat head P4
[-1, 3, C3, [512, False]], # 20 (P4/16-medium)
[-1, 1, Conv, [512, 3, 2]],
[[-1, 10], 1, Concat, [1]], # cat head P5
[-1, 3, C3, [1024, False]], # 23 (P5/32-large)
[[17, 20, 23], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
]
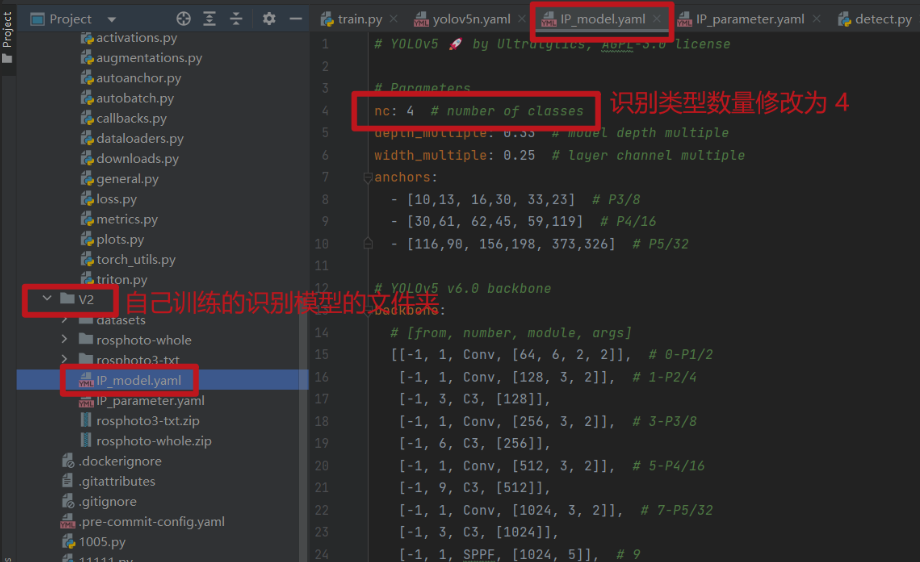
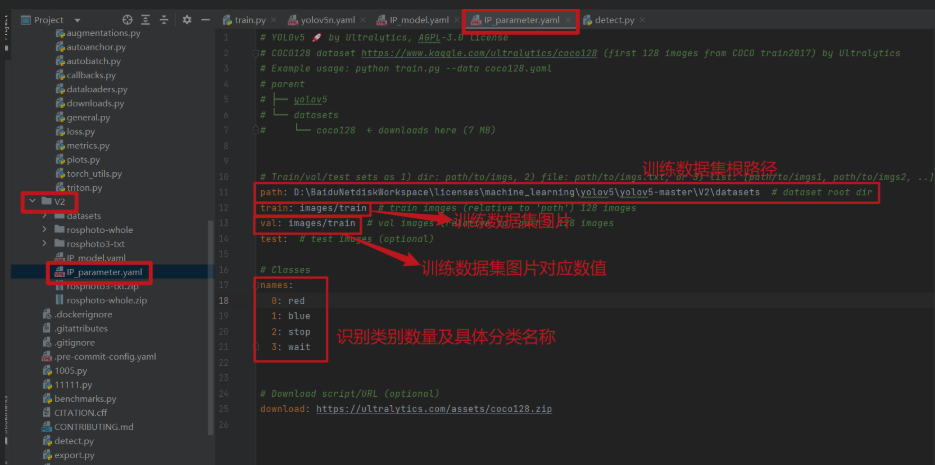
② IP_parameter.yaml(模型訓練以及模型儲存路徑等引數設定)
path: D:\BaiduNetdiskWorkspace\licenses\machine_learning\yolov5\yolov5-master\V2\datasets # dataset root dir
train: images/train # train images (relative to 'path') 128 images
val: images/train # val images (relative to 'path') 128 images
test: # test images (optional)
# Classes
names:
0: red
1: blue
2: stop
3: wait
# Download script/URL (optional)
download: https://ultralytics.com/assets/coco128.zip
第二步:編寫模型訓練程式碼
train.py
import argparse
import math
import os
os.environ["GIT_PYTHON_REFRESH"] = "quiet"
import random
import subprocess
import sys
import time
from copy import deepcopy
from datetime import datetime
from pathlib import Path
import numpy as np
import torch
import torch.distributed as dist
import torch.nn as nn
import yaml
from torch.optim import lr_scheduler
from tqdm import tqdm
FILE = Path(__file__).resolve()
ROOT = FILE.parents[0] # YOLOv5 root directory
if str(ROOT) not in sys.path:
sys.path.append(str(ROOT)) # add ROOT to PATH
ROOT = Path(os.path.relpath(ROOT, Path.cwd())) # relative
import val as validate # for end-of-epoch mAP
from models.experimental import attempt_load
from models.yolo import Model
from utils.autoanchor import check_anchors
from utils.autobatch import check_train_batch_size
from utils.callbacks import Callbacks
from utils.dataloaders import create_dataloader
from utils.downloads import attempt_download, is_url
from utils.general import (LOGGER, TQDM_BAR_FORMAT, check_amp, check_dataset, check_file, check_git_info,
check_git_status, check_img_size, check_requirements, check_suffix, check_yaml, colorstr,
get_latest_run, increment_path, init_seeds, intersect_dicts, labels_to_class_weights,
labels_to_image_weights, methods, one_cycle, print_args, print_mutation, strip_optimizer,
yaml_save)
from utils.loggers import Loggers
from utils.loggers.comet.comet_utils import check_comet_resume
from utils.loss import ComputeLoss
from utils.metrics import fitness
from utils.plots import plot_evolve
from utils.torch_utils import (EarlyStopping, ModelEMA, de_parallel, select_device, smart_DDP, smart_optimizer,
smart_resume, torch_distributed_zero_first)
LOCAL_RANK = int(os.getenv('LOCAL_RANK', -1)) # https://pytorch.org/docs/stable/elastic/run.html
RANK = int(os.getenv('RANK', -1))
WORLD_SIZE = int(os.getenv('WORLD_SIZE', 1))
GIT_INFO = check_git_info()
def train(hyp, opt, device, callbacks): # hyp is path/to/hyp.yaml or hyp dictionary
save_dir, epochs, batch_size, weights, single_cls, evolve, data, cfg, resume, noval, nosave, workers, freeze = \
Path(opt.save_dir), opt.epochs, opt.batch_size, opt.weights, opt.single_cls, opt.evolve, opt.data, opt.cfg, \
opt.resume, opt.noval, opt.nosave, opt.workers, opt.freeze
callbacks.run('on_pretrain_routine_start')
# Directories
w = save_dir / 'weights' # weights dir
(w.parent if evolve else w).mkdir(parents=True, exist_ok=True) # make dir
last, best = w / 'last.pt', w / 'best.pt'
# Hyperparameters
if isinstance(hyp, str):
with open(hyp, errors='ignore') as f:
hyp = yaml.safe_load(f) # load hyps dict
LOGGER.info(colorstr('hyperparameters: ') + ', '.join(f'{k}={v}' for k, v in hyp.items()))
opt.hyp = hyp.copy() # for saving hyps to checkpoints
# Save run settings
if not evolve:
yaml_save(save_dir / 'hyp.yaml', hyp)
yaml_save(save_dir / 'opt.yaml', vars(opt))
# Loggers
data_dict = None
if RANK in {-1, 0}:
loggers = Loggers(save_dir, weights, opt, hyp, LOGGER) # loggers instance
# Register actions
for k in methods(loggers):
callbacks.register_action(k, callback=getattr(loggers, k))
# Process custom dataset artifact link
data_dict = loggers.remote_dataset
if resume: # If resuming runs from remote artifact
weights, epochs, hyp, batch_size = opt.weights, opt.epochs, opt.hyp, opt.batch_size
# Config
plots = not evolve and not opt.noplots # create plots
cuda = device.type != 'cpu'
init_seeds(opt.seed + 1 + RANK, deterministic=True)
with torch_distributed_zero_first(LOCAL_RANK):
data_dict = data_dict or check_dataset(data) # check if None
train_path, val_path = data_dict['train'], data_dict['val']
nc = 1 if single_cls else int(data_dict['nc']) # number of classes
names = {0: 'item'} if single_cls and len(data_dict['names']) != 1 else data_dict['names'] # class names
is_coco = isinstance(val_path, str) and val_path.endswith('coco/val2017.txt') # COCO dataset
# Model
check_suffix(weights, '.pt') # check weights
pretrained = weights.endswith('.pt')
if pretrained:
with torch_distributed_zero_first(LOCAL_RANK):
weights = attempt_download(weights) # download if not found locally
ckpt = torch.load(weights, map_location='cpu') # load checkpoint to CPU to avoid CUDA memory leak
model = Model(cfg or ckpt['model'].yaml, ch=3, nc=nc, anchors=hyp.get('anchors')).to(device) # create
exclude = ['anchor'] if (cfg or hyp.get('anchors')) and not resume else [] # exclude keys
csd = ckpt['model'].float().state_dict() # checkpoint state_dict as FP32
csd = intersect_dicts(csd, model.state_dict(), exclude=exclude) # intersect
model.load_state_dict(csd, strict=False) # load
LOGGER.info(f'Transferred {len(csd)}/{len(model.state_dict())} items from {weights}') # report
else:
model = Model(cfg, ch=3, nc=nc, anchors=hyp.get('anchors')).to(device) # create
amp = check_amp(model) # check AMP
# Freeze
freeze = [f'model.{x}.' for x in (freeze if len(freeze) > 1 else range(freeze[0]))] # layers to freeze
for k, v in model.named_parameters():
v.requires_grad = True # train all layers
# v.register_hook(lambda x: torch.nan_to_num(x)) # NaN to 0 (commented for erratic training results)
if any(x in k for x in freeze):
LOGGER.info(f'freezing {k}')
v.requires_grad = False
# Image size
gs = max(int(model.stride.max()), 32) # grid size (max stride)
imgsz = check_img_size(opt.imgsz, gs, floor=gs * 2) # verify imgsz is gs-multiple
# Batch size
if RANK == -1 and batch_size == -1: # single-GPU only, estimate best batch size
batch_size = check_train_batch_size(model, imgsz, amp)
loggers.on_params_update({'batch_size': batch_size})
# Optimizer
nbs = 64 # nominal batch size
accumulate = max(round(nbs / batch_size), 1) # accumulate loss before optimizing
hyp['weight_decay'] *= batch_size * accumulate / nbs # scale weight_decay
optimizer = smart_optimizer(model, opt.optimizer, hyp['lr0'], hyp['momentum'], hyp['weight_decay'])
# Scheduler
if opt.cos_lr:
lf = one_cycle(1, hyp['lrf'], epochs) # cosine 1->hyp['lrf']
else:
lf = lambda x: (1 - x / epochs) * (1.0 - hyp['lrf']) + hyp['lrf'] # linear
scheduler = lr_scheduler.LambdaLR(optimizer, lr_lambda=lf) # plot_lr_scheduler(optimizer, scheduler, epochs)
# EMA
ema = ModelEMA(model) if RANK in {-1, 0} else None
# Resume
best_fitness, start_epoch = 0.0, 0
if pretrained:
if resume:
best_fitness, start_epoch, epochs = smart_resume(ckpt, optimizer, ema, weights, epochs, resume)
del ckpt, csd
# DP mode
if cuda and RANK == -1 and torch.cuda.device_count() > 1:
LOGGER.warning(
'WARNING ⚠️ DP not recommended, use torch.distributed.run for best DDP Multi-GPU results.\n'
'See Multi-GPU Tutorial at https://docs.ultralytics.com/yolov5/tutorials/multi_gpu_training to get started.'
)
model = torch.nn.DataParallel(model)
# SyncBatchNorm
if opt.sync_bn and cuda and RANK != -1:
model = torch.nn.SyncBatchNorm.convert_sync_batchnorm(model).to(device)
LOGGER.info('Using SyncBatchNorm()')
# Trainloader
train_loader, dataset = create_dataloader(train_path,
imgsz,
batch_size // WORLD_SIZE,
gs,
single_cls,
hyp=hyp,
augment=True,
cache=None if opt.cache == 'val' else opt.cache,
rect=opt.rect,
rank=LOCAL_RANK,
workers=workers,
image_weights=opt.image_weights,
quad=opt.quad,
prefix=colorstr('train: '),
shuffle=True,
seed=opt.seed)
labels = np.concatenate(dataset.labels, 0)
mlc = int(labels[:, 0].max()) # max label class
assert mlc < nc, f'Label class {mlc} exceeds nc={nc} in {data}. Possible class labels are 0-{nc - 1}'
# Process 0
if RANK in {-1, 0}:
val_loader = create_dataloader(val_path,
imgsz,
batch_size // WORLD_SIZE * 2,
gs,
single_cls,
hyp=hyp,
cache=None if noval else opt.cache,
rect=True,
rank=-1,
workers=workers * 2,
pad=0.5,
prefix=colorstr('val: '))[0]
if not resume:
if not opt.noautoanchor:
check_anchors(dataset, model=model, thr=hyp['anchor_t'], imgsz=imgsz) # run AutoAnchor
model.half().float() # pre-reduce anchor precision
callbacks.run('on_pretrain_routine_end', labels, names)
# DDP mode
if cuda and RANK != -1:
model = smart_DDP(model)
# Model attributes
nl = de_parallel(model).model[-1].nl # number of detection layers (to scale hyps)
hyp['box'] *= 3 / nl # scale to layers
hyp['cls'] *= nc / 80 * 3 / nl # scale to classes and layers
hyp['obj'] *= (imgsz / 640) ** 2 * 3 / nl # scale to image size and layers
hyp['label_smoothing'] = opt.label_smoothing
model.nc = nc # attach number of classes to model
model.hyp = hyp # attach hyperparameters to model
model.class_weights = labels_to_class_weights(dataset.labels, nc).to(device) * nc # attach class weights
model.names = names
# Start training
t0 = time.time()
nb = len(train_loader) # number of batches
nw = max(round(hyp['warmup_epochs'] * nb), 100) # number of warmup iterations, max(3 epochs, 100 iterations)
# nw = min(nw, (epochs - start_epoch) / 2 * nb) # limit warmup to < 1/2 of training
last_opt_step = -1
maps = np.zeros(nc) # mAP per class
results = (0, 0, 0, 0, 0, 0, 0) # P, R, [email protected], [email protected], val_loss(box, obj, cls)
scheduler.last_epoch = start_epoch - 1 # do not move
scaler = torch.cuda.amp.GradScaler(enabled=amp)
stopper, stop = EarlyStopping(patience=opt.patience), False
compute_loss = ComputeLoss(model) # init loss class
callbacks.run('on_train_start')
LOGGER.info(f'Image sizes {imgsz} train, {imgsz} val\n'
f'Using {train_loader.num_workers * WORLD_SIZE} dataloader workers\n'
f"Logging results to {colorstr('bold', save_dir)}\n"
f'Starting training for {epochs} epochs...')
for epoch in range(start_epoch, epochs): # epoch ------------------------------------------------------------------
callbacks.run('on_train_epoch_start')
model.train()
# Update image weights (optional, single-GPU only)
if opt.image_weights:
cw = model.class_weights.cpu().numpy() * (1 - maps) ** 2 / nc # class weights
iw = labels_to_image_weights(dataset.labels, nc=nc, class_weights=cw) # image weights
dataset.indices = random.choices(range(dataset.n), weights=iw, k=dataset.n) # rand weighted idx
# Update mosaic border (optional)
# b = int(random.uniform(0.25 * imgsz, 0.75 * imgsz + gs) // gs * gs)
# dataset.mosaic_border = [b - imgsz, -b] # height, width borders
mloss = torch.zeros(3, device=device) # mean losses
if RANK != -1:
train_loader.sampler.set_epoch(epoch)
pbar = enumerate(train_loader)
LOGGER.info(('\n' + '%11s' * 7) % ('Epoch', 'GPU_mem', 'box_loss', 'obj_loss', 'cls_loss', 'Instances', 'Size'))
if RANK in {-1, 0}:
pbar = tqdm(pbar, total=nb, bar_format=TQDM_BAR_FORMAT) # progress bar
optimizer.zero_grad()
for i, (imgs, targets, paths, _) in pbar: # batch -------------------------------------------------------------
callbacks.run('on_train_batch_start')
ni = i + nb * epoch # number integrated batches (since train start)
imgs = imgs.to(device, non_blocking=True).float() / 255 # uint8 to float32, 0-255 to 0.0-1.0
# Warmup
if ni <= nw:
xi = [0, nw] # x interp
# compute_loss.gr = np.interp(ni, xi, [0.0, 1.0]) # iou loss ratio (obj_loss = 1.0 or iou)
accumulate = max(1, np.interp(ni, xi, [1, nbs / batch_size]).round())
for j, x in enumerate(optimizer.param_groups):
# bias lr falls from 0.1 to lr0, all other lrs rise from 0.0 to lr0
x['lr'] = np.interp(ni, xi, [hyp['warmup_bias_lr'] if j == 0 else 0.0, x['initial_lr'] * lf(epoch)])
if 'momentum' in x:
x['momentum'] = np.interp(ni, xi, [hyp['warmup_momentum'], hyp['momentum']])
# Multi-scale
if opt.multi_scale:
sz = random.randrange(int(imgsz * 0.5), int(imgsz * 1.5) + gs) // gs * gs # size
sf = sz / max(imgs.shape[2:]) # scale factor
if sf != 1:
ns = [math.ceil(x * sf / gs) * gs for x in imgs.shape[2:]] # new shape (stretched to gs-multiple)
imgs = nn.functional.interpolate(imgs, size=ns, mode='bilinear', align_corners=False)
# Forward
with torch.cuda.amp.autocast(amp):
pred = model(imgs) # forward
loss, loss_items = compute_loss(pred, targets.to(device)) # loss scaled by batch_size
if RANK != -1:
loss *= WORLD_SIZE # gradient averaged between devices in DDP mode
if opt.quad:
loss *= 4.
# Backward
scaler.scale(loss).backward()
# Optimize - https://pytorch.org/docs/master/notes/amp_examples.html
if ni - last_opt_step >= accumulate:
scaler.unscale_(optimizer) # unscale gradients
torch.nn.utils.clip_grad_norm_(model.parameters(), max_norm=10.0) # clip gradients
scaler.step(optimizer) # optimizer.step
scaler.update()
optimizer.zero_grad()
if ema:
ema.update(model)
last_opt_step = ni
# Log
if RANK in {-1, 0}:
mloss = (mloss * i + loss_items) / (i + 1) # update mean losses
mem = f'{torch.cuda.memory_reserved() / 1E9 if torch.cuda.is_available() else 0:.3g}G' # (GB)
pbar.set_description(('%11s' * 2 + '%11.4g' * 5) %
(f'{epoch}/{epochs - 1}', mem, *mloss, targets.shape[0], imgs.shape[-1]))
callbacks.run('on_train_batch_end', model, ni, imgs, targets, paths, list(mloss))
if callbacks.stop_training:
return
# end batch ------------------------------------------------------------------------------------------------
# Scheduler
lr = [x['lr'] for x in optimizer.param_groups] # for loggers
scheduler.step()
if RANK in {-1, 0}:
# mAP
callbacks.run('on_train_epoch_end', epoch=epoch)
ema.update_attr(model, include=['yaml', 'nc', 'hyp', 'names', 'stride', 'class_weights'])
final_epoch = (epoch + 1 == epochs) or stopper.possible_stop
if not noval or final_epoch: # Calculate mAP
results, maps, _ = validate.run(data_dict,
batch_size=batch_size // WORLD_SIZE * 2,
imgsz=imgsz,
half=amp,
model=ema.ema,
single_cls=single_cls,
dataloader=val_loader,
save_dir=save_dir,
plots=False,
callbacks=callbacks,
compute_loss=compute_loss)
# Update best mAP
fi = fitness(np.array(results).reshape(1, -1)) # weighted combination of [P, R, [email protected], [email protected]]
stop = stopper(epoch=epoch, fitness=fi) # early stop check
if fi > best_fitness:
best_fitness = fi
log_vals = list(mloss) + list(results) + lr
callbacks.run('on_fit_epoch_end', log_vals, epoch, best_fitness, fi)
# Save model
if (not nosave) or (final_epoch and not evolve): # if save
ckpt = {
'epoch': epoch,
'best_fitness': best_fitness,
'model': deepcopy(de_parallel(model)).half(),
'ema': deepcopy(ema.ema).half(),
'updates': ema.updates,
'optimizer': optimizer.state_dict(),
'opt': vars(opt),
'git': GIT_INFO, # {remote, branch, commit} if a git repo
'date': datetime.now().isoformat()}
# Save last, best and delete
torch.save(ckpt, last)
if best_fitness == fi:
torch.save(ckpt, best)
if opt.save_period > 0 and epoch % opt.save_period == 0:
torch.save(ckpt, w / f'epoch{epoch}.pt')
del ckpt
callbacks.run('on_model_save', last, epoch, final_epoch, best_fitness, fi)
# EarlyStopping
if RANK != -1: # if DDP training
broadcast_list = [stop if RANK == 0 else None]
dist.broadcast_object_list(broadcast_list, 0) # broadcast 'stop' to all ranks
if RANK != 0:
stop = broadcast_list[0]
if stop:
break # must break all DDP ranks
# end epoch ----------------------------------------------------------------------------------------------------
# end training -----------------------------------------------------------------------------------------------------
if RANK in {-1, 0}:
LOGGER.info(f'\n{epoch - start_epoch + 1} epochs completed in {(time.time() - t0) / 3600:.3f} hours.')
for f in last, best:
if f.exists():
strip_optimizer(f) # strip optimizers
if f is best:
LOGGER.info(f'\nValidating {f}...')
results, _, _ = validate.run(
data_dict,
batch_size=batch_size // WORLD_SIZE * 2,
imgsz=imgsz,
model=attempt_load(f, device).half(),
iou_thres=0.65 if is_coco else 0.60, # best pycocotools at iou 0.65
single_cls=single_cls,
dataloader=val_loader,
save_dir=save_dir,
save_json=is_coco,
verbose=True,
plots=plots,
callbacks=callbacks,
compute_loss=compute_loss) # val best model with plots
if is_coco:
callbacks.run('on_fit_epoch_end', list(mloss) + list(results) + lr, epoch, best_fitness, fi)
callbacks.run('on_train_end', last, best, epoch, results)
torch.cuda.empty_cache()
return results
def parse_opt(known=False):
parser = argparse.ArgumentParser()
parser.add_argument('--weights', type=str, default=ROOT / r'yolov5n.pt', help='initial weights path')
parser.add_argument('--cfg', type=str, default=ROOT / 'D:/BaiduNetdiskWorkspace/licenses/machine_learning/yolov5/yolov5-master/V2/IP_model.yaml', help='model.yaml path')
parser.add_argument('--data', type=str, default=ROOT / 'D:/BaiduNetdiskWorkspace/licenses/machine_learning/yolov5/yolov5-master/V2/IP_parameter.yaml', help='dataset.yaml path')
parser.add_argument('--hyp', type=str, default=ROOT / 'data/hyps/hyp.scratch-low.yaml', help='hyperparameters path')
parser.add_argument('--epochs', type=int, default=300, help='total training epochs')
parser.add_argument('--batch-size', type=int, default=-1, help='total batch size for all GPUs, -1 for autobatch')
parser.add_argument('--imgsz', '--img', '--img-size', type=int, default=256, help='train, val image size (pixels)')
parser.add_argument('--rect', action='store_true', help='rectangular training')
parser.add_argument('--resume', nargs='?', const=True, default=False, help='resume most recent training')
parser.add_argument('--nosave', action='store_true', help='only save final checkpoint')
parser.add_argument('--noval', action='store_true', help='only validate final epoch')
parser.add_argument('--noautoanchor', action='store_true', help='disable AutoAnchor')
parser.add_argument('--noplots', action='store_true', help='save no plot files')
parser.add_argument('--evolve', type=int, nargs='?', const=300, help='evolve hyperparameters for x generations')
parser.add_argument('--bucket', type=str, default='', help='gsutil bucket')
parser.add_argument('--cache', type=str, nargs='?', const='ram', help='image --cache ram/disk')
parser.add_argument('--image-weights', action='store_true', help='use weighted image selection for training')
parser.add_argument('--device', default='0', help='cuda device, i.e. 0 or 0,1,2,3 or cpu')
parser.add_argument('--multi-scale', action='store_true', help='vary img-size +/- 50%%')
parser.add_argument('--single-cls', action='store_true', help='train multi-class data as single-class')
parser.add_argument('--optimizer', type=str, choices=['SGD', 'Adam', 'AdamW'], default='SGD', help='optimizer')
parser.add_argument('--sync-bn', action='store_true', help='use SyncBatchNorm, only available in DDP mode')
parser.add_argument('--workers', type=int, default=6, help='max dataloader workers (per RANK in DDP mode)')
parser.add_argument('--project', default=ROOT / 'runs/train', help='save to project/name')
parser.add_argument('--name', default='exp', help='save to project/name')
parser.add_argument('--exist-ok', action='store_true', help='existing project/name ok, do not increment')
parser.add_argument('--quad', action='store_true', help='quad dataloader')
parser.add_argument('--cos-lr', action='store_true', help='cosine LR scheduler')
parser.add_argument('--label-smoothing', type=float, default=0.0, help='Label smoothing epsilon')
parser.add_argument('--patience', type=int, default=100, help='EarlyStopping patience (epochs without improvement)')
parser.add_argument('--freeze', nargs='+', type=int, default=[0], help='Freeze layers: backbone=10, first3=0 1 2')
parser.add_argument('--save-period', type=int, default=-1, help='Save checkpoint every x epochs (disabled if < 1)')
parser.add_argument('--seed', type=int, default=0, help='Global training seed')
parser.add_argument('--local_rank', type=int, default=-1, help='Automatic DDP Multi-GPU argument, do not modify')
# Logger arguments
parser.add_argument('--entity', default=None, help='Entity')
parser.add_argument('--upload_dataset', nargs='?', const=True, default=False, help='Upload data, "val" option')
parser.add_argument('--bbox_interval', type=int, default=-1, help='Set bounding-box image logging interval')
parser.add_argument('--artifact_alias', type=str, default='latest', help='Version of dataset artifact to use')
return parser.parse_known_args()[0] if known else parser.parse_args()
def main(opt, callbacks=Callbacks()):
# Checks
if RANK in {-1, 0}:
print_args(vars(opt))
check_git_status()
check_requirements()
# Resume (from specified or most recent last.pt)
if opt.resume and not check_comet_resume(opt) and not opt.evolve:
last = Path(check_file(opt.resume) if isinstance(opt.resume, str) else get_latest_run())
opt_yaml = last.parent.parent / 'opt.yaml' # train options yaml
opt_data = opt.data # original dataset
if opt_yaml.is_file():
with open(opt_yaml, errors='ignore') as f:
d = yaml.safe_load(f)
else:
d = torch.load(last, map_location='cpu')['opt']
opt = argparse.Namespace(**d) # replace
opt.cfg, opt.weights, opt.resume = '', str(last), True # reinstate
if is_url(opt_data):
opt.data = check_file(opt_data) # avoid HUB resume auth timeout
else:
opt.data, opt.cfg, opt.hyp, opt.weights, opt.project = \
check_file(opt.data), check_yaml(opt.cfg), check_yaml(opt.hyp), str(opt.weights), str(opt.project) # checks
assert len(opt.cfg) or len(opt.weights), 'either --cfg or --weights must be specified'
if opt.evolve:
if opt.project == str(ROOT / 'runs/train'): # if default project name, rename to runs/evolve
opt.project = str(ROOT / 'runs/evolve')
opt.exist_ok, opt.resume = opt.resume, False # pass resume to exist_ok and disable resume
if opt.name == 'cfg':
opt.name = Path(opt.cfg).stem # use model.yaml as name
opt.save_dir = str(increment_path(Path(opt.project) / opt.name, exist_ok=opt.exist_ok))
# DDP mode
device = select_device(opt.device, batch_size=opt.batch_size)
if LOCAL_RANK != -1:
msg = 'is not compatible with YOLOv5 Multi-GPU DDP training'
assert not opt.image_weights, f'--image-weights {msg}'
assert not opt.evolve, f'--evolve {msg}'
assert opt.batch_size != -1, f'AutoBatch with --batch-size -1 {msg}, please pass a valid --batch-size'
assert opt.batch_size % WORLD_SIZE == 0, f'--batch-size {opt.batch_size} must be multiple of WORLD_SIZE'
assert torch.cuda.device_count() > LOCAL_RANK, 'insufficient CUDA devices for DDP command'
torch.cuda.set_device(LOCAL_RANK)
device = torch.device('cuda', LOCAL_RANK)
dist.init_process_group(backend='nccl' if dist.is_nccl_available() else 'gloo')
# Train
if not opt.evolve:
train(opt.hyp, opt, device, callbacks)
# Evolve hyperparameters (optional)
else:
# Hyperparameter evolution metadata (mutation scale 0-1, lower_limit, upper_limit)
meta = {
'lr0': (1, 1e-5, 1e-1), # initial learning rate (SGD=1E-2, Adam=1E-3)
'lrf': (1, 0.01, 1.0), # final OneCycleLR learning rate (lr0 * lrf)
'momentum': (0.3, 0.6, 0.98), # SGD momentum/Adam beta1
'weight_decay': (1, 0.0, 0.001), # optimizer weight decay
'warmup_epochs': (1, 0.0, 5.0), # warmup epochs (fractions ok)
'warmup_momentum': (1, 0.0, 0.95), # warmup initial momentum
'warmup_bias_lr': (1, 0.0, 0.2), # warmup initial bias lr
'box': (1, 0.02, 0.2), # box loss gain
'cls': (1, 0.2, 4.0), # cls loss gain
'cls_pw': (1, 0.5, 2.0), # cls BCELoss positive_weight
'obj': (1, 0.2, 4.0), # obj loss gain (scale with pixels)
'obj_pw': (1, 0.5, 2.0), # obj BCELoss positive_weight
'iou_t': (0, 0.1, 0.7), # IoU training threshold
'anchor_t': (1, 2.0, 8.0), # anchor-multiple threshold
'anchors': (2, 2.0, 10.0), # anchors per output grid (0 to ignore)
'fl_gamma': (0, 0.0, 2.0), # focal loss gamma (efficientDet default gamma=1.5)
'hsv_h': (1, 0.0, 0.1), # image HSV-Hue augmentation (fraction)
'hsv_s': (1, 0.0, 0.9), # image HSV-Saturation augmentation (fraction)
'hsv_v': (1, 0.0, 0.9), # image HSV-Value augmentation (fraction)
'degrees': (1, 0.0, 45.0), # image rotation (+/- deg)
'translate': (1, 0.0, 0.9), # image translation (+/- fraction)
'scale': (1, 0.0, 0.9), # image scale (+/- gain)
'shear': (1, 0.0, 10.0), # image shear (+/- deg)
'perspective': (0, 0.0, 0.001), # image perspective (+/- fraction), range 0-0.001
'flipud': (1, 0.0, 1.0), # image flip up-down (probability)
'fliplr': (0, 0.0, 1.0), # image flip left-right (probability)
'mosaic': (1, 0.0, 1.0), # image mixup (probability)
'mixup': (1, 0.0, 1.0), # image mixup (probability)
'copy_paste': (1, 0.0, 1.0)} # segment copy-paste (probability)
with open(opt.hyp, errors='ignore') as f:
hyp = yaml.safe_load(f) # load hyps dict
if 'anchors' not in hyp: # anchors commented in hyp.yaml
hyp['anchors'] = 3
if opt.noautoanchor:
del hyp['anchors'], meta['anchors']
opt.noval, opt.nosave, save_dir = True, True, Path(opt.save_dir) # only val/save final epoch
# ei = [isinstance(x, (int, float)) for x in hyp.values()] # evolvable indices
evolve_yaml, evolve_csv = save_dir / 'hyp_evolve.yaml', save_dir / 'evolve.csv'
if opt.bucket:
# download evolve.csv if exists
subprocess.run([
'gsutil',
'cp',
f'gs://{opt.bucket}/evolve.csv',
str(evolve_csv),])
for _ in range(opt.evolve): # generations to evolve
if evolve_csv.exists(): # if evolve.csv exists: select best hyps and mutate
# Select parent(s)
parent = 'single' # parent selection method: 'single' or 'weighted'
x = np.loadtxt(evolve_csv, ndmin=2, delimiter=',', skiprows=1)
n = min(5, len(x)) # number of previous results to consider
x = x[np.argsort(-fitness(x))][:n] # top n mutations
w = fitness(x) - fitness(x).min() + 1E-6 # weights (sum > 0)
if parent == 'single' or len(x) == 1:
# x = x[random.randint(0, n - 1)] # random selection
x = x[random.choices(range(n), weights=w)[0]] # weighted selection
elif parent == 'weighted':
x = (x * w.reshape(n, 1)).sum(0) / w.sum() # weighted combination
# Mutate
mp, s = 0.8, 0.2 # mutation probability, sigma
npr = np.random
npr.seed(int(time.time()))
g = np.array([meta[k][0] for k in hyp.keys()]) # gains 0-1
ng = len(meta)
v = np.ones(ng)
while all(v == 1): # mutate until a change occurs (prevent duplicates)
v = (g * (npr.random(ng) < mp) * npr.randn(ng) * npr.random() * s + 1).clip(0.3, 3.0)
for i, k in enumerate(hyp.keys()): # plt.hist(v.ravel(), 300)
hyp[k] = float(x[i + 7] * v[i]) # mutate
# Constrain to limits
for k, v in meta.items():
hyp[k] = max(hyp[k], v[1]) # lower limit
hyp[k] = min(hyp[k], v[2]) # upper limit
hyp[k] = round(hyp[k], 5) # significant digits
# Train mutation
results = train(hyp.copy(), opt, device, callbacks)
callbacks = Callbacks()
# Write mutation results
keys = ('metrics/precision', 'metrics/recall', 'metrics/mAP_0.5', 'metrics/mAP_0.5:0.95', 'val/box_loss',
'val/obj_loss', 'val/cls_loss')
print_mutation(keys, results, hyp.copy(), save_dir, opt.bucket)
# Plot results
plot_evolve(evolve_csv)
LOGGER.info(f'Hyperparameter evolution finished {opt.evolve} generations\n'
f"Results saved to {colorstr('bold', save_dir)}\n"
f'Usage example: $ python train.py --hyp {evolve_yaml}')
def run(**kwargs):
# Usage: import train; train.run(data='coco128.yaml', imgsz=320, weights='yolov5m.pt')
opt = parse_opt(True)
for k, v in kwargs.items():
setattr(opt, k, v)
main(opt)
return opt
if __name__ == '__main__':
opt = parse_opt()
main(opt)

(十)模型推斷過程的程式編寫
第一部分:編寫 detect.py
import argparse
import os
import platform
import sys
from pathlib import Path
import torch
FILE = Path(__file__).resolve()
ROOT = FILE.parents[0] # YOLOv5 root directory
if str(ROOT) not in sys.path:
sys.path.append(str(ROOT)) # add ROOT to PATH
ROOT = Path(os.path.relpath(ROOT, Path.cwd())) # relative
from models.common import DetectMultiBackend
from utils.dataloaders import IMG_FORMATS, VID_FORMATS, LoadImages, LoadScreenshots, LoadStreams
from utils.general import (LOGGER, Profile, check_file, check_img_size, check_imshow, check_requirements, colorstr, cv2,
increment_path, non_max_suppression, print_args, scale_boxes, strip_optimizer, xyxy2xywh)
from utils.plots import Annotator, colors, save_one_box
from utils.torch_utils import select_device, smart_inference_mode
@smart_inference_mode()
def run(
weights=ROOT / r'D:\BaiduNetdiskWorkspace\licenses\machine_learning\yolov5\yolov5-master\runs\train\exp15\weights\best.pt',
# model path or triton URL
# source=ROOT / 'data/images', # file/dir/URL/glob/screen/0(webcam)
source=ROOT / '0', # file/dir/URL/glob/screen/0(webcam)
data=ROOT / 'car-parts/IP_parameter.yaml', # dataset.yaml path
imgsz=(640, 640), # inference size (height, width)
conf_thres=0.25, # confidence threshold
iou_thres=0.45, # NMS IOU threshold
max_det=1000, # maximum detections per image
device='', # cuda device, i.e. 0 or 0,1,2,3 or cpu
view_img=False, # show results
save_txt=False, # save results to *.txt
save_conf=False, # save confidences in --save-txt labels
save_crop=False, # save cropped prediction boxes
nosave=False, # do not save images/videos
classes=None, # filter by class: --class 0, or --class 0 2 3
agnostic_nms=False, # class-agnostic NMS
augment=False, # augmented inference
visualize=False, # visualize features
update=False, # update all models
project=ROOT / 'runs/detect', # save results to project/name
name='exp', # save results to project/name
exist_ok=False, # existing project/name ok, do not increment
line_thickness=3, # bounding box thickness (pixels)
hide_labels=False, # hide labels
hide_conf=False, # hide confidences
half=False, # use FP16 half-precision inference
dnn=False, # use OpenCV DNN for ONNX inference
vid_stride=1, # video frame-rate stride
):
source = str(source)
save_img = not nosave and not source.endswith('.txt') # save inference images
is_file = Path(source).suffix[1:] in (IMG_FORMATS + VID_FORMATS)
is_url = source.lower().startswith(('rtsp://', 'rtmp://', 'http://', 'https://'))
webcam = source.isnumeric() or source.endswith('.streams') or (is_url and not is_file)
screenshot = source.lower().startswith('screen')
if is_url and is_file:
source = check_file(source) # download
# Directories
save_dir = increment_path(Path(project) / name, exist_ok=exist_ok) # increment run
(save_dir / 'labels' if save_txt else save_dir).mkdir(parents=True, exist_ok=True) # make dir
# Load model
device = select_device(device)
model = DetectMultiBackend(weights, device=device, dnn=dnn, data=data, fp16=half)
stride, names, pt = model.stride, model.names, model.pt
imgsz = check_img_size(imgsz, s=stride) # check image size
# Dataloader
bs = 1 # batch_size
if webcam:
view_img = check_imshow(warn=True)
dataset = LoadStreams(source, img_size=imgsz, stride=stride, auto=pt, vid_stride=vid_stride)
bs = len(dataset)
elif screenshot:
dataset = LoadScreenshots(source, img_size=imgsz, stride=stride, auto=pt)
else:
dataset = LoadImages(source, img_size=imgsz, stride=stride, auto=pt, vid_stride=vid_stride)
vid_path, vid_writer = [None] * bs, [None] * bs
# Run inference
model.warmup(imgsz=(1 if pt or model.triton else bs, 3, *imgsz)) # warmup
seen, windows, dt = 0, [], (Profile(), Profile(), Profile())
for path, im, im0s, vid_cap, s in dataset:
with dt[0]:
im = torch.from_numpy(im).to(model.device)
im = im.half() if model.fp16 else im.float() # uint8 to fp16/32
im /= 255 # 0 - 255 to 0.0 - 1.0
if len(im.shape) == 3:
im = im[None] # expand for batch dim
# Inference
with dt[1]:
visualize = increment_path(save_dir / Path(path).stem, mkdir=True) if visualize else False
pred = model(im, augment=augment, visualize=visualize)
# NMS
with dt[2]:
pred = non_max_suppression(pred, conf_thres, iou_thres, classes, agnostic_nms, max_det=max_det)
# Second-stage classifier (optional)
# pred = utils.general.apply_classifier(pred, classifier_model, im, im0s)
# Process predictions
for i, det in enumerate(pred): # per image
seen += 1
if webcam: # batch_size >= 1
p, im0, frame = path[i], im0s[i].copy(), dataset.count
s += f'{i}: '
else:
p, im0, frame = path, im0s.copy(), getattr(dataset, 'frame', 0)
p = Path(p) # to Path
save_path = str(save_dir / p.name) # im.jpg
txt_path = str(save_dir / 'labels' / p.stem) + ('' if dataset.mode == 'image' else f'_{frame}') # im.txt
s += '%gx%g ' % im.shape[2:] # print string
#####################################################################################################
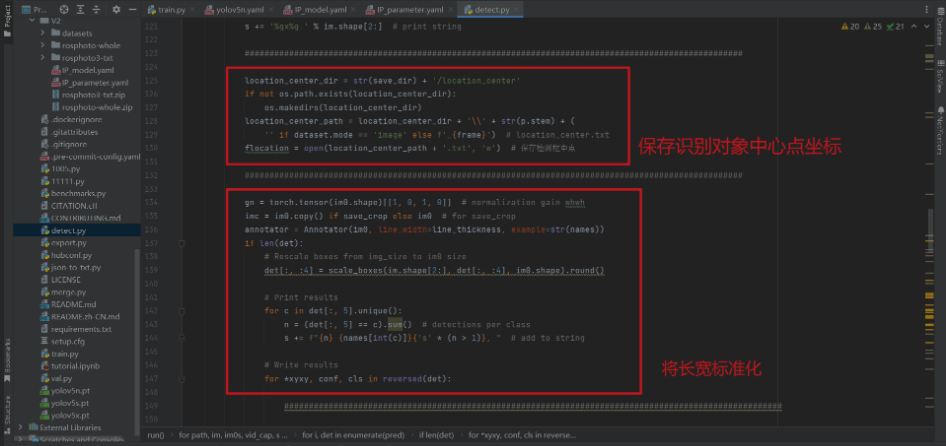
location_center_dir = str(save_dir) + '/location_center'
if not os.path.exists(location_center_dir):
os.makedirs(location_center_dir)
location_center_path = location_center_dir + '\\' + str(p.stem) + (
'' if dataset.mode == 'image' else f'_{frame}') # location_center.txt
flocation = open(location_center_path + '.txt', 'w') # 儲存檢測框中點
#####################################################################################################
gn = torch.tensor(im0.shape)[[1, 0, 1, 0]] # normalization gain whwh
imc = im0.copy() if save_crop else im0 # for save_crop
annotator = Annotator(im0, line_width=line_thickness, example=str(names))
if len(det):
# Rescale boxes from img_size to im0 size
det[:, :4] = scale_boxes(im.shape[2:], det[:, :4], im0.shape).round()
# Print results
for c in det[:, 5].unique():
n = (det[:, 5] == c).sum() # detections per class
s += f"{n} {names[int(c)]}{'s' * (n > 1)}, " # add to string
# Write results
for *xyxy, conf, cls in reversed(det):
#####################################################################################################
x0 = (int(xyxy[0].item()) + int(xyxy[2].item())) / 2
y0 = (int(xyxy[1].item()) + int(xyxy[3].item())) / 2 # 中心點座標(x0, y0)
class_index = cls # 獲取屬性
object_name = names[int(cls)] # 獲取標籤名
flocation.write(object_name + ': ' + str(x0) + ', ' + str(y0) + '\n')
#####################################################################################################
if save_txt: # Write to file
xywh = (xyxy2xywh(torch.tensor(xyxy).view(1, 4)) / gn).view(-1).tolist() # normalized xywh
line = (cls, *xywh, conf) if save_conf else (cls, *xywh) # label format
with open(f'{txt_path}.txt', 'a') as f:
f.write(('%g ' * len(line)).rstrip() % line + '\n')
if save_img or save_crop or view_img: # Add bbox to image
c = int(cls) # integer class
label = None if hide_labels else (names[c] if hide_conf else f'{names[c]} {conf:.2f}')
annotator.box_label(xyxy, label, color=colors(c, True))
if save_crop:
save_one_box(xyxy, imc, file=save_dir / 'crops' / names[c] / f'{p.stem}.jpg', BGR=True)
#####################################################################################################
flocation.close()
#####################################################################################################
# Stream results
im0 = annotator.result()
if view_img:
if platform.system() == 'Linux' and p not in windows:
windows.append(p)
cv2.namedWindow(str(p), cv2.WINDOW_NORMAL | cv2.WINDOW_KEEPRATIO) # allow window resize (Linux)
cv2.resizeWindow(str(p), im0.shape[1], im0.shape[0])
cv2.imshow(str(p), im0)
cv2.waitKey(1) # 1 millisecond
# Save results (image with detections)
if save_img:
if dataset.mode == 'image':
cv2.imwrite(save_path, im0)
else: # 'video' or 'stream'
if vid_path[i] != save_path: # new video
vid_path[i] = save_path
if isinstance(vid_writer[i], cv2.VideoWriter):
vid_writer[i].release() # release previous video writer
if vid_cap: # video
fps = vid_cap.get(cv2.CAP_PROP_FPS)
w = int(vid_cap.get(cv2.CAP_PROP_FRAME_WIDTH))
h = int(vid_cap.get(cv2.CAP_PROP_FRAME_HEIGHT))
else: # stream
fps, w, h = 30, im0.shape[1], im0.shape[0]
save_path = str(Path(save_path).with_suffix('.mp4')) # force *.mp4 suffix on results videos
vid_writer[i] = cv2.VideoWriter(save_path, cv2.VideoWriter_fourcc(*'mp4v'), fps, (w, h))
vid_writer[i].write(im0)
# Print time (inference-only)
LOGGER.info(f"{s}{'' if len(det) else '(no detections), '}{dt[1].dt * 1E3:.1f}ms")
# Print results
t = tuple(x.t / seen * 1E3 for x in dt) # speeds per image
LOGGER.info(f'Speed: %.1fms pre-process, %.1fms inference, %.1fms NMS per image at shape {(1, 3, *imgsz)}' % t)
if save_txt or save_img:
s = f"\n{len(list(save_dir.glob('labels/*.txt')))} labels saved to {save_dir / 'labels'}" if save_txt else ''
LOGGER.info(f"Results saved to {colorstr('bold', save_dir)}{s}")
if update:
strip_optimizer(weights[0]) # update model (to fix SourceChangeWarning)
def parse_opt():
parser = argparse.ArgumentParser()
# parser.add_argument('--weights', nargs='+', type=str, default=ROOT / 'yolov5s.pt', help='model path or triton URL')
parser.add_argument('--weights', nargs='+', type=str,
default=ROOT / r'D:\BaiduNetdiskWorkspace\licenses\machine_learning\yolov5\yolov5-master\runs\train\exp3\weights\best.pt',
help='model path or triton URL')
# parser.add_argument('--source', type=str, default=ROOT / 'data/images', help='file/dir/URL/glob/screen/0(webcam)')
parser.add_argument('--source', type=str,
default=ROOT / r'D:\BaiduNetdiskWorkspace\licenses\machine_learning\yolov5\yolov5-master\V2\datasets\images\train',
help='file/dir/URL/glob/screen/0(webcam)')
parser.add_argument('--data', type=str, default=ROOT / 'data/coco128.yaml', help='(optional) dataset.yaml path')
parser.add_argument('--imgsz', '--img', '--img-size', nargs='+', type=int, default=[640], help='inference size h,w')
parser.add_argument('--conf-thres', type=float, default=0.25, help='confidence threshold')
parser.add_argument('--iou-thres', type=float, default=0, help='NMS IoU threshold')
parser.add_argument('--max-det', type=int, default=10, help='maximum detections per image')
parser.add_argument('--device', default='', help='cuda device, i.e. 0 or 0,1,2,3 or cpu')
parser.add_argument('--view-img', action='store_true', help='show results')
parser.add_argument('--save-txt', action='store_true', help='save results to *.txt')
parser.add_argument('--save-conf', action='store_true', help='save confidences in --save-txt labels')
parser.add_argument('--save-crop', action='store_true', help='save cropped prediction boxes')
parser.add_argument('--nosave', action='store_true', help='do not save images/videos')
parser.add_argument('--classes', nargs='+', type=int, help='filter by class: --classes 0, or --classes 0 2 3')
parser.add_argument('--agnostic-nms', action='store_true', help='class-agnostic NMS')
parser.add_argument('--augment', action='store_true', help='augmented inference')
parser.add_argument('--visualize', action='store_true', help='visualize features')
parser.add_argument('--update', action='store_true', help='update all models')
parser.add_argument('--project', default=ROOT / 'runs/detect', help='save results to project/name')
parser.add_argument('--name', default='exp', help='save results to project/name')
parser.add_argument('--exist-ok', action='store_true', help='existing project/name ok, do not increment')
parser.add_argument('--line-thickness', default=3, type=int, help='bounding box thickness (pixels)')
parser.add_argument('--hide-labels', default=False, action='store_true', help='hide labels')
parser.add_argument('--hide-conf', default=False, action='store_true', help='hide confidences')
parser.add_argument('--half', action='store_true', help='use FP16 half-precision inference')
parser.add_argument('--dnn', action='store_true', help='use OpenCV DNN for ONNX inference')
parser.add_argument('--vid-stride', type=int, default=1, help='video frame-rate stride')
opt = parser.parse_args()
opt.imgsz *= 2 if len(opt.imgsz) == 1 else 1 # expand
print_args(vars(opt))
return opt
def main(opt):
check_requirements(exclude=('tensorboard', 'thop'))
run(**vars(opt))
if __name__ == '__main__':
opt = parse_opt()
main(opt)



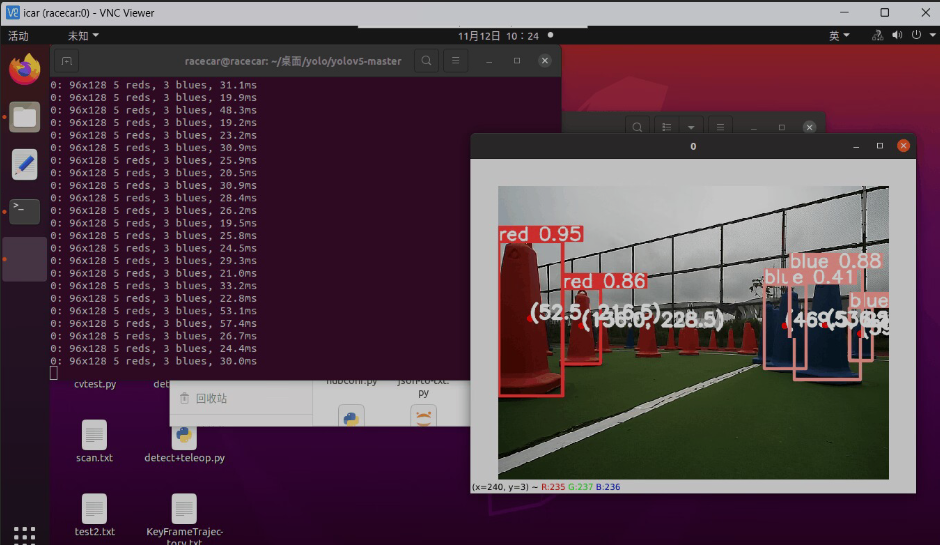
第二部分:在無人車終端執行程式碼,呼叫物理攝像頭,檢視具體效果


(十一)使用onnx及TensorRT將模型進行推理加速
第一步:將pt模型轉化為onnx模型
① 安裝onnx
pip install onnx

pip install onnxruntime

② 使用 export.py 匯出模型為ONNX
python export.py --weights D:\BaiduNetdiskWorkspace\licenses\machine_learning\yolov5\yolov5-master\runs\train\exp3\weights\best.pt --img-size 640 --batch-size 1 --include onnx


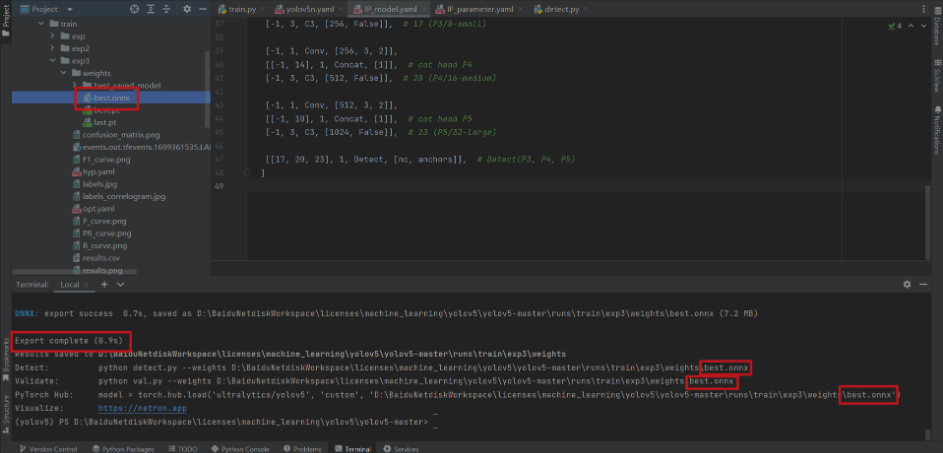
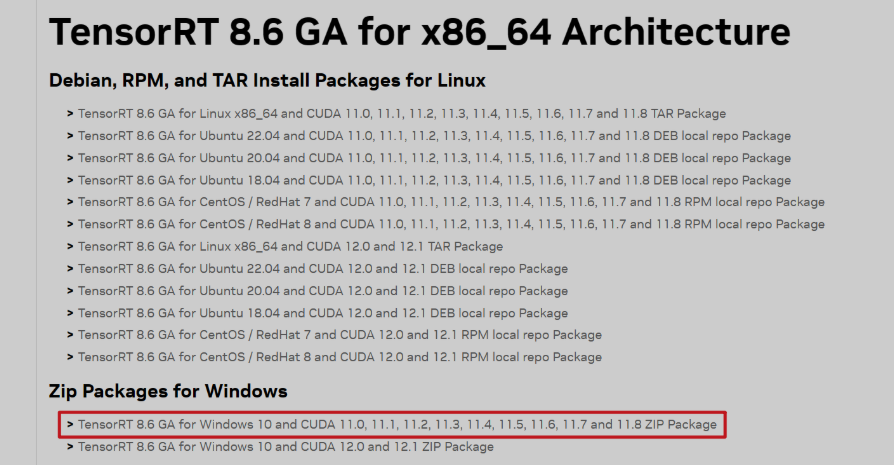
第二步:TensorRT環境安裝及設定
① 下載對應TensorRT版本
https://developer.nvidia.com/nvidia-tensorrt-8x-download
② 解壓 TensorRT
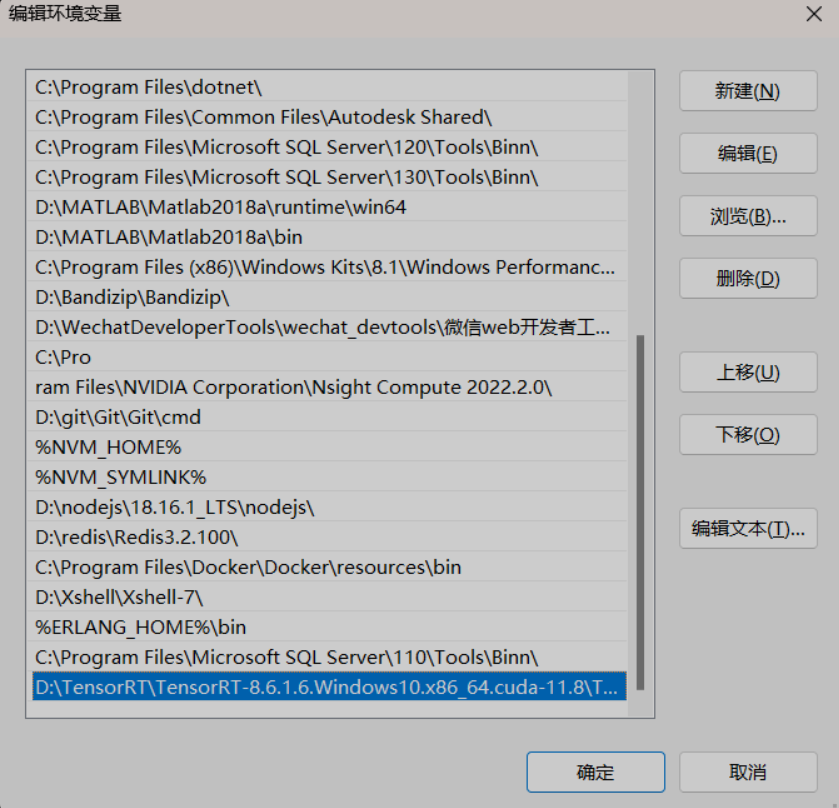
③ 設定環境變數
將TensorRT解壓位置\lib 加入系統環境變數
將TensorRT解壓位置\lib下的dll檔案複製到C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.7\bin目錄下

④ 測試範例程式碼
用VS2019開啟sampleOnnxMNIST範例(D:\TensorRT\TensorRT-8.6.1.6.Windows10.x86_64.cuda-11.8\TensorRT-8.6.1.6\samples\sampleOnnxMNIST)
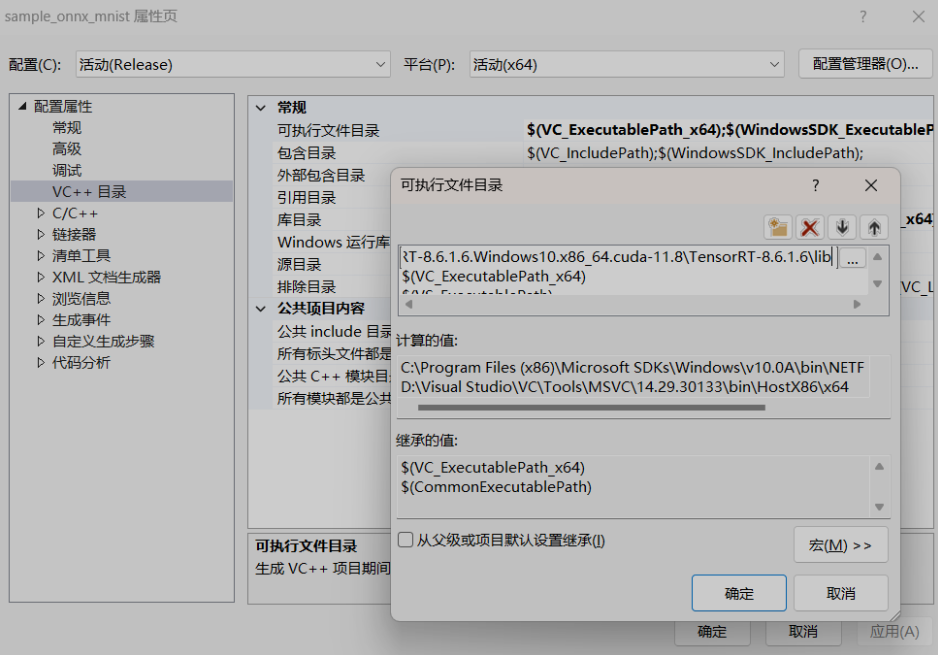
將D:\TensorRT\TensorRT-8.6.1.6.Windows10.x86_64.cuda-11.8\TensorRT-8.6.1.6\lib加入 VC++目錄–>可執行檔案目錄
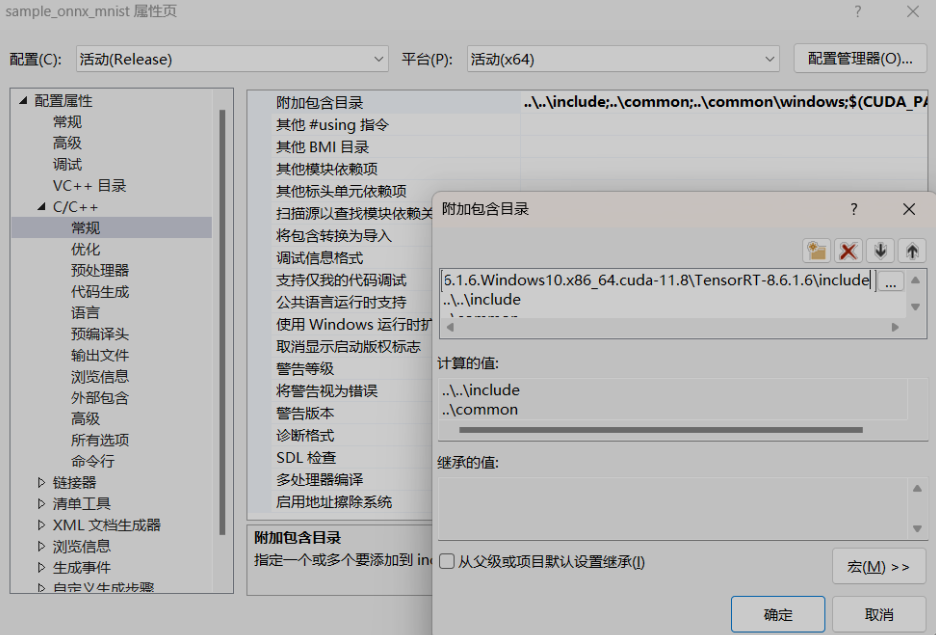
將D:\TensorRT\TensorRT-8.6.1.6.Windows10.x86_64.cuda-11.8\TensorRT-8.6.1.6\include加入C/C++ --> 常規 --> 附加包含目錄
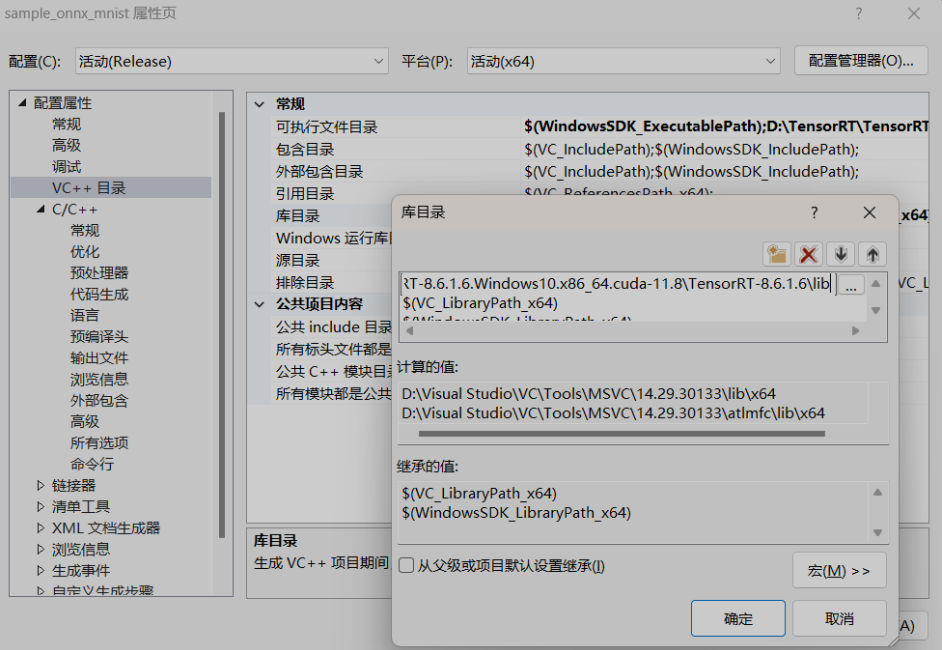
將D:\TensorRT\TensorRT-8.6.1.6.Windows10.x86_64.cuda-11.8\TensorRT-8.6.1.6\lib加入 VC++目錄–>庫目錄
將nvinfer.lib、nvinfer_plugin.lib、nvonnxparser.lib和nvparsers.lib加入連結器–>輸入–>附加依賴項


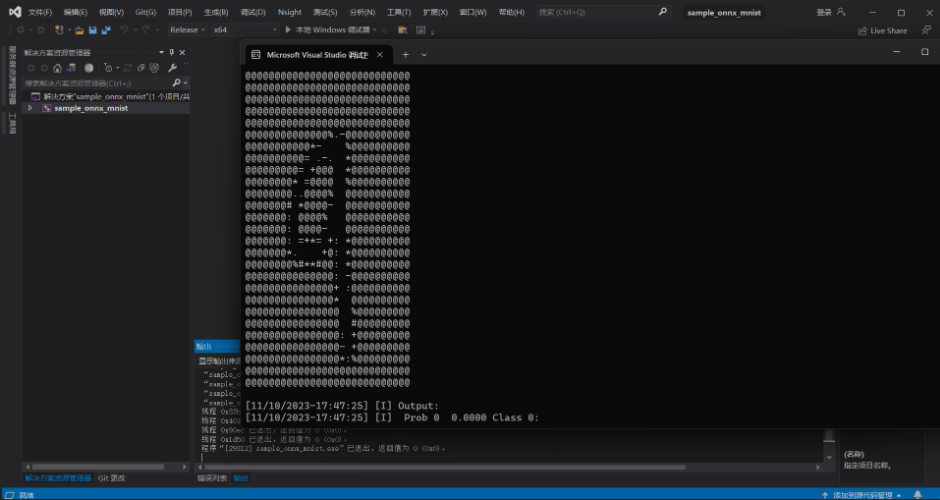
⑤ 安裝 pycuda
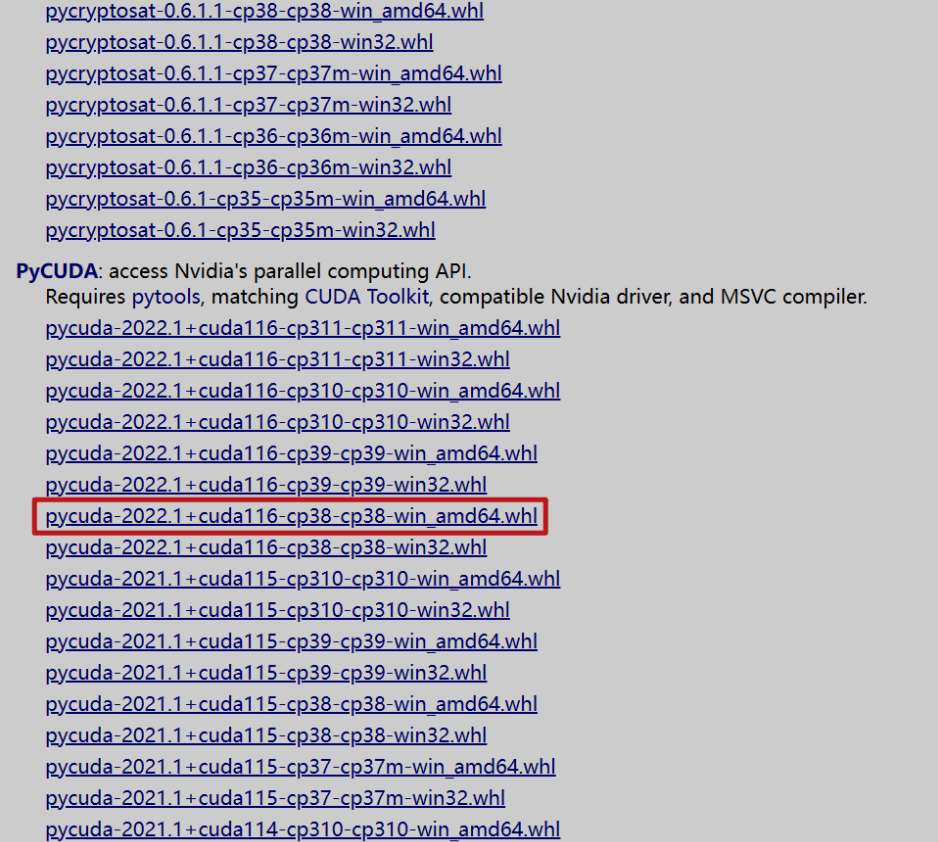
pip install "D:\pycuda\pycuda-2022.1+cuda116-cp38-cp38-win_amd64.whl"


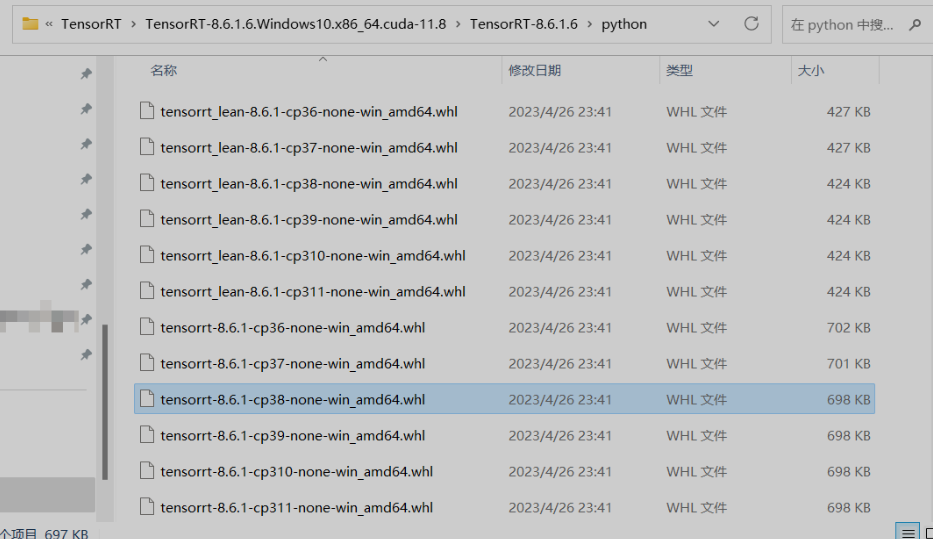
⑥ python 環境設定 TensorRT
pip install "D:\TensorRT\TensorRT-8.6.1.6.Windows10.x86_64.cuda-11.8\TensorRT-8.6.1.6\python\tensorrt-8.6.1-cp38-none-win_amd64.whl"

⑦ python 環境測試
python "D:\TensorRT\TensorRT-8.6.1.6.Windows10.x86_64.cuda-11.8\TensorRT-8.6.1.6\samples\python\network_api_pytorch_mnist\sample.py"

第三步:使用 TensorRT 編譯 onnx 檔案,轉換成 .trt 字尾檔案
D:\TensorRT\TensorRT-8.6.1.6.Windows10.x86_64.cuda-11.8\TensorRT-8.6.1.6\bin\trtexec.exe --onnx=D:\BaiduNetdiskWorkspace\licenses\machine_learning\yolov5\yolov5-master\runs\train\exp3\weights\best.onnx --saveEngine=D:\BaiduNetdiskWorkspace\licenses\machine_learning\yolov5\yolov5-master\runs\train\exp3\weights\best.trt --buildOnly

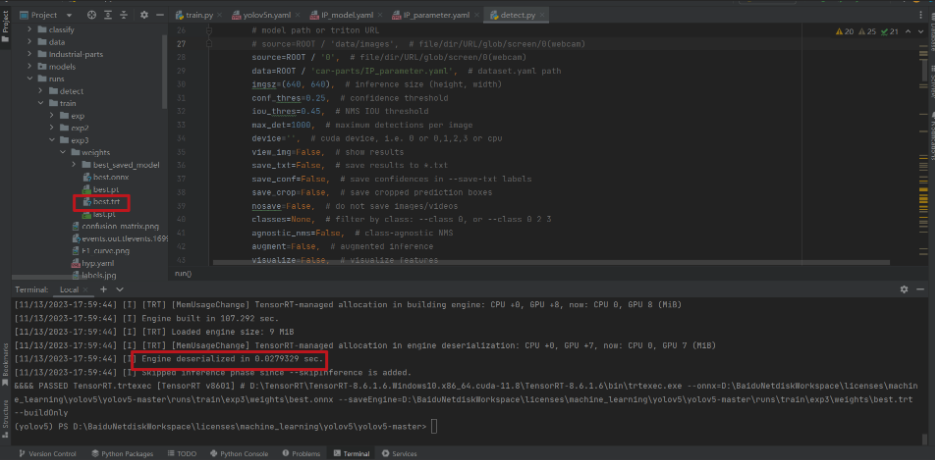
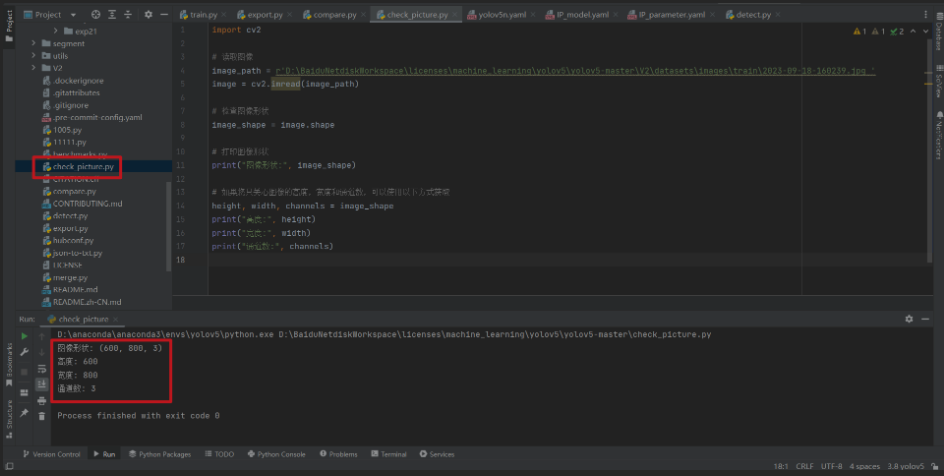
第四步:檢視訓練圖片的維度
check_picture.py
import cv2
# 讀取影象
image_path = r'D:\BaiduNetdiskWorkspace\licenses\machine_learning\yolov5\yolov5-master\V2\datasets\images\train\2023-09-18-160239.jpg '
image = cv2.imread(image_path)
# 檢查影象形狀
image_shape = image.shape
# 列印影象形狀
print("影象形狀:", image_shape)
# 如果您只關心影象的高度,寬度和通道數,可以使用以下方式獲取
height, width, channels = image_shape
print("高度:", height)
print("寬度:", width)
print("通道數:", channels)
第五步:編寫加速推理指令碼
compare.py
import numpy as np
import pycuda.driver as cuda
import pycuda.autoinit
import tensorrt as trt
import cv2
import time
# 載入.trt檔案
trt_file_path = r'D:\BaiduNetdiskWorkspace\licenses\machine_learning\yolov5\yolov5-master\runs\train\exp3\weights\best.trt'
with open(trt_file_path, 'rb') as f, trt.Runtime(trt.Logger(trt.Logger.WARNING)) as runtime:
engine = runtime.deserialize_cuda_engine(f.read())
# 建立執行上下文
context = engine.create_execution_context()
# 分配輸入和輸出記憶體
input_size = trt.volume(context.get_binding_shape(0))
output_size = trt.volume(context.get_binding_shape(1))
# 在GPU上分配記憶體
input_host = cuda.pagelocked_empty(input_size, dtype=np.float32)
output_host = cuda.pagelocked_empty(output_size, dtype=np.float32)
input_device = cuda.mem_alloc(input_host.nbytes)
output_device = cuda.mem_alloc(output_host.nbytes)
# 準備輸入資料
# 讀取彩色影象
image_path = r'D:\BaiduNetdiskWorkspace\licenses\machine_learning\yolov5\yolov5-master\V2\datasets\images\train\2023-09-18-160239.jpg '
image = cv2.imread(image_path)
# 調整資料形狀以匹配模型期望的輸入形狀
input_data = image.astype(np.float32) / 255.0 # 歸一化(假設模型期望的輸入範圍是 [0, 1])
# 使用cv2.resize調整影象大小
resized_image = cv2.resize(input_data, (640, 640))
input_data = np.transpose(resized_image, (2, 0, 1)) # 將通道移到正確的位置
input_data = np.expand_dims(input_data, axis=0) # 新增批次處理維度
# 確保輸入資料的長度與模型期望的輸入大小一致
if input_data.size != input_size:
raise ValueError(f"Input data size ({input_data.size}) does not match the expected input size ({input_size})")
np.copyto(input_host, input_data.ravel())
cuda.memcpy_htod(input_device, input_host)
# 計時開始
start_time = time.time()
# 執行推理
context.execute_v2(bindings=[int(input_device), int(output_device)])
# 計時結束
end_time = time.time()
# 獲取輸出
cuda.memcpy_dtoh(output_host, output_device)
# 處理輸出資料
result = output_host.reshape(context.get_binding_shape(1))
# 列印結果
print(result)
# 列印推理時間
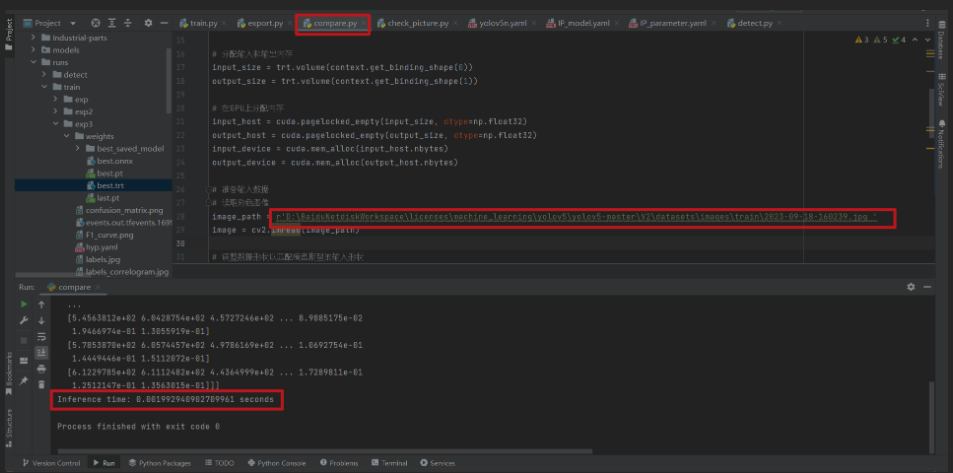
inference_time = end_time - start_time
print(f"Inference time: {inference_time} seconds")
第六步:對比測試
加速前
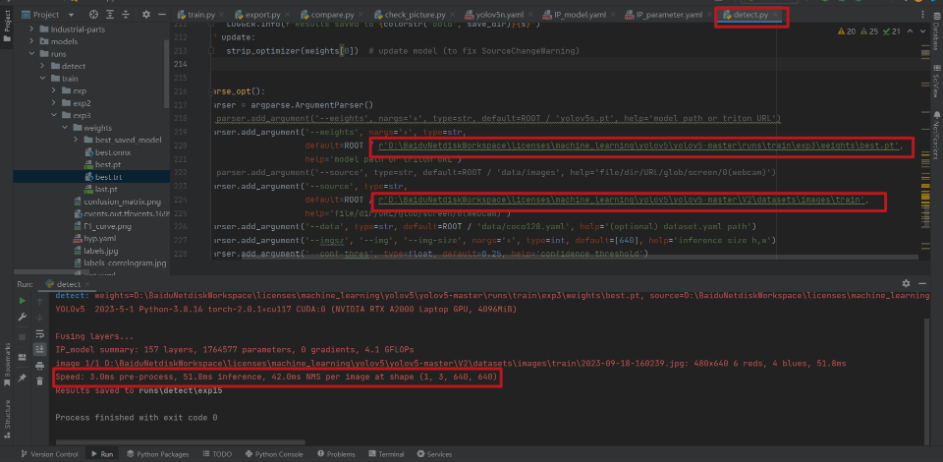
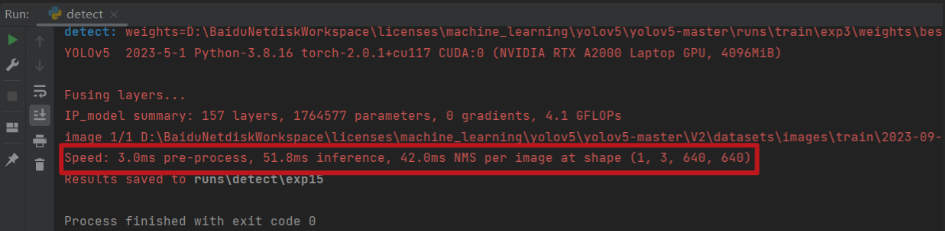
加速後

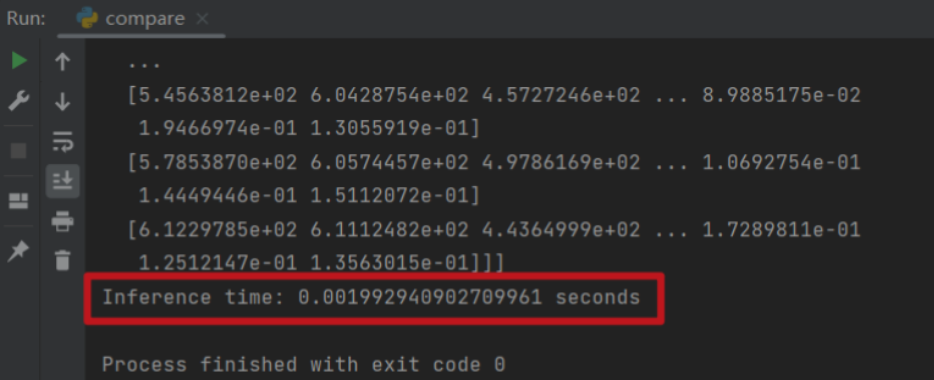
(十二)問題彙總
(1)error MSB8036:找不到 Windows SDK 版本......
參考連結
error MSB8036:找不到 Windows SDK 版本···_microsoft.cpp.windowssdk.targe ts(46,5): error msb-CSDN部落格
(2)too many values to unpack
參考連結
too many values to unpack (expected 4)_UC_Gundam的部落格-CSDN部落格
(3)執行範例時,提示找不到 MNIST資料
參考連結
TensorRT之安裝與測試(Windows和Linux環境下安裝TensorRT)_判斷tensorrt是否可以正常使用-CSDN部落格
(4)載入 libnvinfer.so.7報錯
參考連結
TensorRT之安裝與測試(Windows和Linux環境下安裝TensorRT)_判斷tensorrt是否可以正常使用-CSDN部落格