理解Mysql索引原理及特性
作為開發人員,碰到了執行時間較長的sql時,基本上大家都會說」加個索引吧」。但是索引是什麼東西,索引有哪些特性,下面和大家簡單討論一下。
1 索引如何工作,是如何加快查詢速度
索引就好比書本的目錄,提高資料庫表資料存取速度的資料庫物件。當我們的請求打過來之後,如果有目錄,就會快速的定位到章節,再從章節裡找到資料。如果沒有目錄,如大海撈針一般,難度可見一斑。這就是我們經常碰到的罪魁禍首,全表掃描。
一條索引記錄中包含的基本資訊包括:鍵值(即你定義索引時指定的所有欄位的值)+邏輯指標(指向資料頁或者另一索引頁)。通常狀況下,由於索引記錄僅包含索引欄位值(以及4-9位元組的指標),索引實體比真實的資料行要小許多,索引頁相較資料頁來說要密集許多。一個索引頁可以儲存數量更多的索引記錄,這意味著在索引中查詢時在I/O上佔很大的優勢,理解這一點有助於從本質上了解使用索引的優勢,也是大部分效能優化所需要切入的點。
1)沒有索引的情況下存取資料:
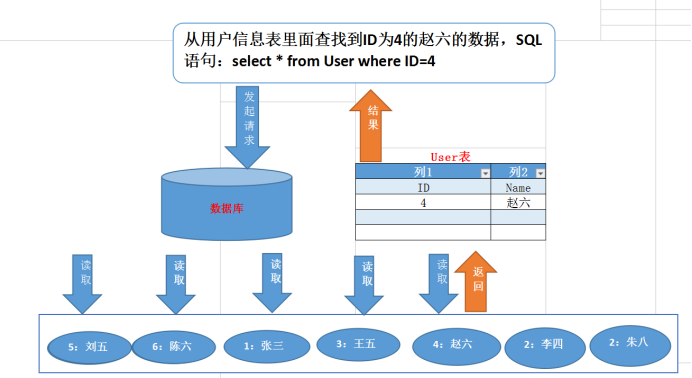
2)使用平衡二元樹結構索引的情況下存取資料:

第一張圖沒有使用索引我們會進行順序查詢,依照資料順序逐個進行匹配,進行了5次定址才查詢出所需資料,第二張圖用了一個簡單的平衡二元樹索引之後我們只用了3次,這還是資料量小的情況下,資料量大了效果更明顯,所以總結來說建立索引就是為了加快資料查詢速度;
2 索引的組成部分和種類
常見的索引的實現方式有很多種,比如hash、陣列、樹,下面為大家介紹下這幾種模型使用上有什麼區別
2.1 hash
hash思路簡單,就是把我們插入的key通過hash函數演演算法(以前一般是取餘數,就好比hashmap的計算方式移位互斥或之類的),計算出對應的value,把這個value放到一個位置,這個位置叫做雜湊槽。對應磁碟位置指標放入hash槽裡面。一句話總結hash索引,就是儲存了索引欄位的hash值和資料所在磁碟檔案指標。
但是不可避免的是,無論什麼演演算法,資料量大了之後難免會出現不同的資料被放在一個hash槽裡面。比如字典上的 「吳」和」武」就是同音,你查字典的時候到這裡只能順序往下去找了。索引的處理也是這樣,會拉出一個連結串列,需要的時候順序遍歷即可。
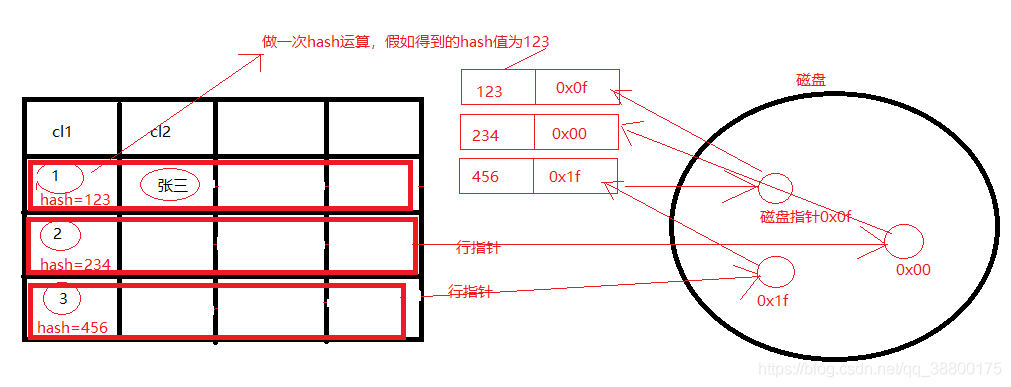
- 缺點:無序索引,區間查詢效能低,因為區間查詢會造成多次存取磁碟,多次io耗時是很難接受的。
- 優點:insert迅速,只需往後補就行
- 場景:等值查詢, 比如memcached 。不適用大量重複資料的列,避免hash衝突
- 總結:想成java的hashmap即可
2.2 有序陣列
如果我們需要區間查詢的時候,hash索引的效能就不盡如人意了。這個時候有序陣列的優勢就能體現出來了。
當我們需要從一個有序陣列裡取A和B之間的值時,只需要通過二分法定位到A的位置,時間複雜度O(log(N)),接著從A遍歷到B即可,論速度的話,基本上可以說是最快的了。但是當我們需要更新的時候,需要進行的操作就很多了。如果需要插入一條資料,你需要挪動資料之後的所有資料,浪費效能。所以總結來說,只有不怎麼變化的資料適合有序陣列結構的索引。
- 缺點:insert新資料的時候,需要改變後續所有資料,成本略高。
- 優點:查詢速度很快,理論最大值。
- 場景:歸檔查詢,紀錄檔查詢等極少變化的
- 總結:就是順序排的陣列
2.3 二元搜尋樹
基本原則是樹的左節點都小於父節點,右節點都大於父節點
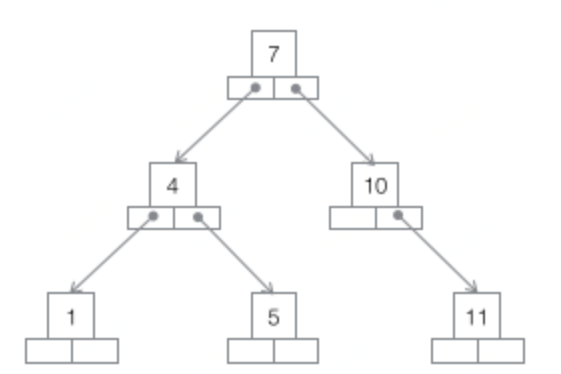
這裡我們就能看出來,二元搜尋樹的查詢效率原則上是O(log(N)),為了保證是平衡二元樹,更新效率也是O(log(N))。但是資料很多的情況樹的高度會達到很高,過多次存取磁碟,是不可取的。並且極端情況下,樹退化成連結串列,查詢的複雜度會被拉成O(n)。
進化成多叉樹,也就是多個子節點的時候,會大大的減少樹的高度,降低存取磁碟。
- 缺點:資料量大的時候,樹會過高,導致多次存取磁碟
- 優點:進化成多叉樹,會降低樹高,存取磁碟次數。
- 場景:適用很多場景
- 總結:左小右大的樹
2.4 B樹
在每個節點儲存多個元素,在每個節點儘可能多的儲存資料。每個節點可以儲存1000個索引(16k/16=1000),這樣就將二元樹改造成了多叉樹,通過增加樹的叉樹,將樹從高瘦變為矮胖。構建1百萬條資料,樹的高度只需要2層就可以(1000*1000=1百萬),也就是說只需要2次磁碟IO就可以查詢到資料。磁碟IO次數變少了,查詢資料的效率也就提高了。
這種資料結構我們稱為B樹,B樹是一種多叉平衡查詢樹
2.5 B+樹
B+樹和B樹最主要的區別在於非葉子節點是否儲存資料的問題。
- B樹:非葉子節點和葉子節點都會儲存資料。
- B+樹:只有葉子節點才會儲存資料,非葉子節點至儲存鍵值。葉子節點之間使用雙向指標連線,最底層的葉子節點形成了一個雙向有序連結串列。

正是因為B+樹的葉子節點是通過連結串列連線的,所以找到下限後能很快進行區間查詢,比正常的中序遍歷快
3 索引的維護
當你insert一條資料的時候,索引需要做出必要的操作來保證資料的有序型。一般自增資料直接在後面加就行了,特殊情況下如果資料加到了中間,就需要挪動後面所有的資料,這樣效率比較受影響。
最糟糕的情況,如果當前的資料頁(頁是mysql儲存的最小單位)存滿了,需要申請一個新的資料頁,這個過程被稱為頁分裂。如果造成了頁分裂的話,勢必會造成效能的影響。但是mysql並不是無腦的資料分裂,如果你是從中間進行資料分裂的話,對於自增主鍵,會導致一半的效能浪費。mysql會根據你的索引的型別,和追蹤插入資料的情況決定分裂的方式,一般都存在mysql資料頁的head裡面,如果是零散的插入,會從中間分裂。如果是順序插入,一般是會選擇插入點開始分裂,或者插入點往後幾行導致的。決定是否從中間分裂,還是從最後分裂。
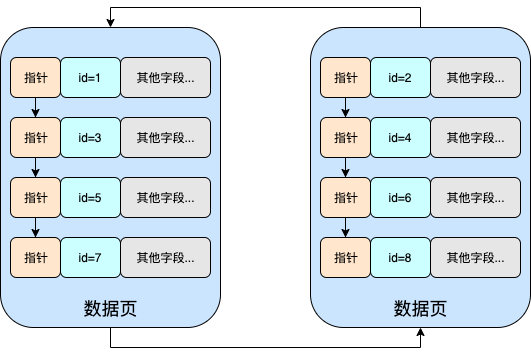
如果插入的是不規則的資料,沒法保證後一個值比前一個大,就會觸發上面說的分裂邏輯,最後達到下面的效果

所以絕大多數情況下,我們都需要使用自增索引,除非需要業務自定義主鍵,最好能保證只有一個索引,且索引是唯一索引。這樣可以避免回表,導致查詢搜尋兩棵樹。保證資料頁的有序性,可以更好的使用索引。
4 回表
通俗的講就是,如果索引的列在 select 所需獲得的列中(因為在 mysql 中索引是根據索引列的值進行排序的,所以索引節點中存在該列中的部分值)或者根據一次索引查詢就能獲得記錄就不需要回表,如果 select 所需獲得列中有大量的非索引列,索引就需要先找到主鍵,再到表中找到相應的列的資訊,這就叫回表。
要介紹回表自然就得介紹聚集索引和非聚集索引
InnoDB聚集索引的葉子節點儲存行記錄,因此, InnoDB必須要有,且只有一個聚集索引:
- 如果表定義了主鍵,則PK就是聚集索引;
- 如果表沒有定義主鍵,則第一個非空唯一索引(not NULL unique)列是聚集索引;
- 否則,InnoDB會建立一個隱藏的row-id作為聚集索引;

當我們使用普通索引查詢方式,則需要先搜尋普通索引樹,然後得到主鍵 ID後,再到 ID 索引樹搜尋一次。因為非主鍵索引的葉子節點裡面,實際存的是主鍵的ID。這個過程雖然用了索引,但實際上底層進行了兩次索引查詢,這個過程就稱為回表。也就是說,基於非主鍵索引的查詢需要多掃描一棵索引樹。因此,我們在應用中應該儘量使用主鍵查詢。或者有高頻請求時,合理建立聯合索引,防止回表。
5 索引覆蓋
一句話表達的話,是隻需要在一棵索引樹上就能獲取SQL所需的所有列資料,無需回表,速度更快。落實到sql上的話,只要執行計劃裡面的輸出結果Extra欄位為Using index時,能夠觸發索引覆蓋。
常見的優化手段,就是上面提到的,將查詢的欄位都建到索引裡面,至於dba願不願意讓你建,那就需要你們自己battle了。
一般索引覆蓋適用的場景包括 全表count查詢優化、列查詢回表、分頁回表。高版本的mysql已經做了優化,當命中聯合索引的其中一個欄位,另外一個是id的時候,會自動優化,無需回表。因為二級索引的葉子上存了primary key,也算索引覆蓋,無需額外成本。

6 最左匹配原則
簡單來說,就是你使用 ‘xx%’的時候,符合條件的話也會使用索引。
如果是聯合索引的話,我舉個例子,建立一個(a,b)的聯合索引

可以看到a的值是有順序的,1,1,2,2,3,3,而b的值是沒有順序的1,2,1,4,1,2。但是我們又可發現a在等值的情況下,b值又是按順序排列的,但是這種順序是相對的。這是因為MySQL建立聯合索引的規則是首先會對聯合索引的最左邊第一個欄位排序,在第一個欄位的排序基礎上,然後在對第二個欄位進行排序。所以b=2這種查詢條件沒有辦法利用索引。舉個例子,我弄一個索引,
KEYidx_time_zone(time_zone,time_string) USING BTREE
執行第一條sql,全表掃描

執行第二條sql,可以看到使用了索引。

再看兩條sql,建立的索引是 KEYidx_time_zone(time_zone,time_string) USING BTREE


按照正常邏輯來說,第二條sql是不符合索引欄位的順序的,應該不能使用索引才對,但是實際情況卻和我們期望的不太一樣,這是為啥呢?
從mysql被oracle收購以後,mysql加入了很多oracle以前的技術,高版本mysql自動優化了where條件的先後順序。簡單來說就是查詢優化器做了這一步操作,sql會做預處理,那一條能更好的查詢就會使用那種規則。
順便提一下mysql的查詢優化器能幫忙乾的一些事
6.1 條件轉化
例如where a=b and b=2,可以得到a=2,條件傳遞。最後的sql是 a=2 and b=2 > < = like 都可以傳遞
6.2 無效程式碼的排除
例如 where 1=1 and a=2, 1=1永遠是正確的,所以最後會優化成 a=2
在比如 where 1=0 永遠是false的,這樣的也會被排除掉,整sql無效
或者非空欄位 where a is null ,這樣的也會被排除
6.3 提前計算
包含數學運算的部分,例如 where a= 1+2 會幫你算好,where a=3
6.4 存取型別
當我們評估一個條件表示式,MySQL判斷該表示式的存取型別。下面是一些存取型別,按照從最優到最差的順序進行排列:
- system系統表,並且是常數表
- const 常數表
- eq_ref unique/primary索引,並且使用的是’=’進行存取
- ref 索引使用’=’進行存取
- ref_or_null 索引使用’=’進行存取,並且有可能為NULL
- range 索引使用BETWEEN、IN、>=、LIKE等進行存取
- index 索引全掃描
- ALL 表全掃描
經常看執行計劃的,一眼就能看出來這是啥意思,舉個例子
where index_col=2 and normal_col =3 這裡就會選用index_col=2 會作為驅動項。驅動項的意思是指一個sql選定他的執行計劃的時候,可能有多條執行路徑,一個是全表掃描,再過濾是否符合索引欄位及非索引欄位的值。另一種是通過索引欄位,鍵值=2找到對應的索引樹,過濾後的結果,再比較是否符合非索引欄位的值。一般情況下,走索引都比全表掃描需要讀取磁碟的次數少,所以稱它為更好的執行路徑,也就是通過索引欄位,作為其驅動表示式
6.5 範圍存取
簡單來說,a in(1,2,3) 和 a=1 or a=2 or a=3 是一樣的,between 1 and 2 和 a>1 and a<2也是一樣的, 無需可以優化。
6.6 索引存取型別
避免使用相同字首的索引,也就是一個欄位不要在多個索引上有相同的字首。比如一個欄位已經建立了唯一索引,這個時候如果再給他建立一個聯合索引,會導致優化器並不知道你要使用哪個索引。或者你建了字首相同的一個單索引,一個聯合索引,就算你寫上了條件,也不一定能用上聯合索引。當然,可以force,這就另說了。
6.7 轉換
簡單的表示式可以進行轉換,比如 where -2 = a 會自動變成 where a= -2 ,但是如果牽扯到數學運算,就不能轉換了 比如 where 2= -a 這時候不會自動轉成 where a =-2.

第二條sql就可以使用索引

所以 我們在開發的過程中,需要注意sql的寫法,自覺寫成 where a=-2
6.8 and、union、order by、group by等
1)and
and條件後,如果都沒索引,掃描全表。有一個存取型別更好,見5.4 ,會使用儲存型別更好的索引,如果都一樣,哪個索引先建立,用哪個。
2)union
union 每條語句單獨優化

這裡就會分別執行兩條sql,用到索引,再合併結果集
3)order by
order by 會過濾無效排序,比如一個欄位本來就有索引

第二條sql和第一條的查詢效果是一樣的

所以,寫sql的時候,不要寫無用排序,比如order by ‘xxx’ 這樣沒有意義。
4)group by
簡單來說 group by 的欄位,有索引會走索引,group by a order by a 這裡的order by等於沒寫,結果集已經是排序完畢的了,參考 6.8-3 order by
select distinct col_a from table a 等價於 select col_a from a group by col_a
7 索引下推
主要的核心點就在於把資料篩選的過程放在了儲存引擎層去處理,而不是像之前一樣放到Server層去做過濾。
如果在一張表上,name和age都建立索引,查詢條件為 where name like ‘xx%’ and age=11,在低版本的mysql(5.6 以下)的根據索引的最左匹配原則,可以得到放棄了age,只根據name過濾資料。根據name拿到所有的id之後,再根據id回表。
高版本mysql裡,沒有忽略age這個屬性,帶著age屬性過濾,直接過濾掉了age為11的資料,假設不根據age過濾的資料為10條,過濾後只剩3條,就少了7次回表。減少了io會大量減少效能消耗
8 小表驅動大表
小表驅動大表,也是我們聽慣了的話了,其含義主要是指小表的資料集驅動大表的資料集,減少連線次數。打個比方:
表A有1w資料,表B有100w資料,如果A表作為驅動表,處於迴圈的外層,那麼只需要1w次的連線即可。如果B表在外層,那麼則需要回圈100w次。
下面我們實際測試看看,準備環境mysql 5.7+
準備兩張表,一張表 ib_asn_d 資料 9175, 一張表 bs_itembase_ext_attr 資料 1584115,都在商品編碼欄位上有索引。
首先小表驅動大表
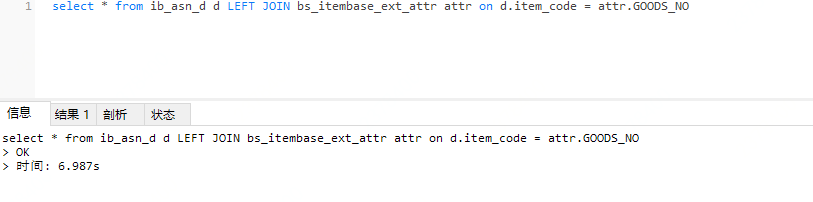
多次反覆測試,執行時間大概7秒。
接下來看看大表驅動小表。
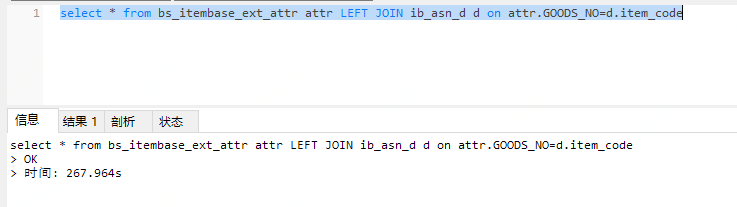
將近300秒,不是一個量級的。
接下來分別分析執行計劃,執行計劃裡第一條就是驅動表。

小表驅動大表,大表用了索引,小表全表掃描,只掃描8000多行

大表驅動小表,大表全表掃描,需要掃描147w行。
經過多次測試得出了結論:
- 當使用left join時,左表是驅動表,右表是被驅動表 ;
- 當使用right join時,右表是驅動表,左表是被驅動表 ;
- 當使用inner join時,mysql會選擇資料量比較小的表作為驅動表,大表作為被驅動表 ;
- 驅動表索引不生效,非驅動表索引生效
保證小表是驅動表很重要。
9 總結
- 覆蓋索引:如果查詢條件使用的是普通索引(或是聯合索引的最左原則欄位),查詢結果是聯合索引的欄位或是主鍵,不用回表操作,直接返回結果,減少IO磁碟讀寫讀取整行資料,所以高頻欄位建立聯合索引是很有必要的
- 最左字首:聯合索引的最左 N 個欄位,也可以是字串索引的最左 M 個字元。建立索引的時候,注意左字首不要重複,避免查詢優化器無法判定如何使用索引
- 索引下推:name like ‘hello%’and age >10 檢索,MySQL 5.6版本之前,會對匹配的資料進行回表查詢。5.6版本後,會先過濾掉age<10的資料,再進行回表查詢,減少回表率,提升檢索速度
作者:京東物流 吳思維
來源:京東雲開發者社群 轉載請註明來源