聊一聊 .NET高階偵錯 中必知的符號表
一:背景
1. 講故事
在高階偵錯的旅行中,發現有不少人對符號表不是很清楚,其實簡而言之符號表中記錄著一些程式的生物特徵,比如哪個地址是函數(簽名資訊),哪個地址是全域性變數,靜態變數,行號是多少,資料型別是什麼 等等,目的就是輔助我們視覺化的偵錯,如果沒有這些輔助我們看到的都是一些無意義的組合程式碼,逆向起來會非常困難,這一篇我們就來系統的聊一聊。
二:程式編譯的四個階段
1. 案例程式碼
要想理解符號表,首先需要理解 程式碼檔案 是如何變成 可執行檔案 的,即如下的四個階段。
- 預處理階段
- 編譯階段
- 組合階段
- 連結階段
為了能夠看到每一個階段,用 gcc 的相關命令手工推進,並用 chatgpt 寫一段測試程式碼,包含全域性變數,靜態變數,函數等資訊。
#include <stdio.h>
#define PI 3.1415926
int global_var = 10;
void func() {
static int static_var = 5;
printf("global_var = %d, static_var = %d PI=%f\n", global_var, static_var,PI);
global_var++;
static_var++;
}
int main() {
func();
func();
return 0;
}
接下來用 gcc --help 命令檢視下需要使用的命令列表。
[root@localhost data]# gcc --help
Usage: gcc [options] file...
Options:
-E Preprocess only; do not compile, assemble or link
-S Compile only; do not assemble or link
-c Compile and assemble, but do not link
-o <file> Place the output into <file>
...
2. 預編譯階段
預處理主要做的就是程式碼整合,比如將 #include 檔案匯入,將 #define 宏替換等等,接下來使用 gcc -E 進行預處理。
[root@localhost data]# gcc main.c -E -o main.i
[root@localhost data]# ls
main.c main.i
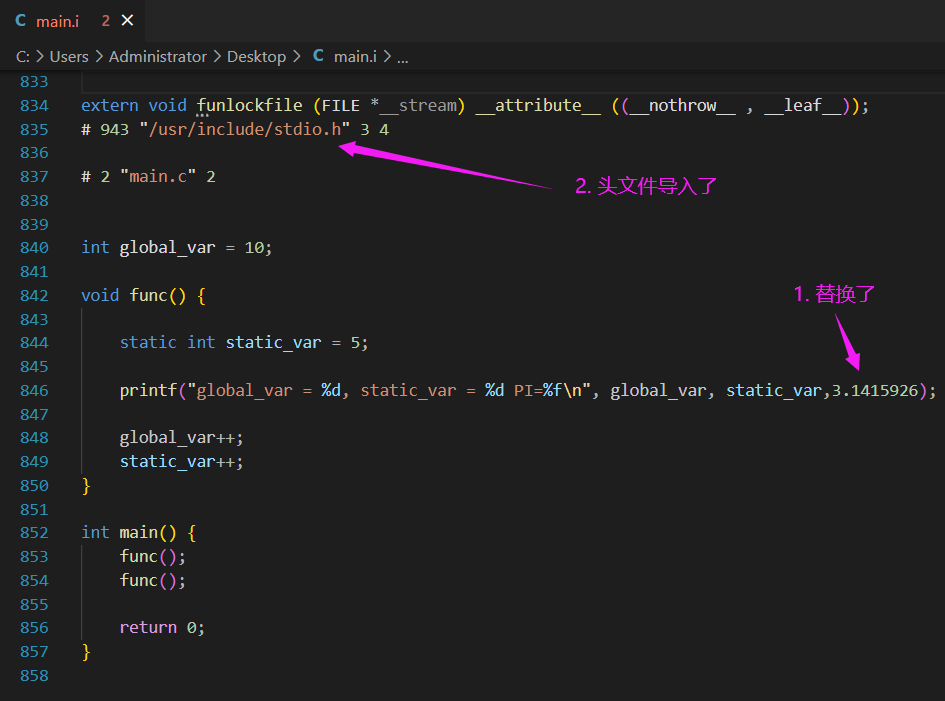
可以看到這個 main.c 檔案已經膨脹到了 858 行了。
3. 編譯階段
前面階段是把程式碼預處理好,接下來就是將C程式碼編譯成組合程式碼了,使用 gcc -S 即可。
[root@localhost data]# gcc main.c -S -o main.s -masm=intel
[root@localhost data]# ls
main.c main.i main.s
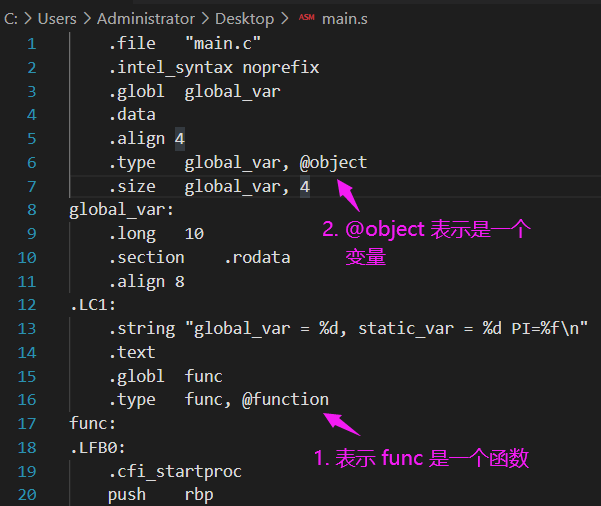
從圖中可以看到組合程式碼中也有很多輔助資訊,比如 global_var 是一個 @object 變數,型別為 int,在 .rodata 唯讀資料段中,目的就是給組合階段打輔助。
4. 組合階段
有了組合程式碼之後,接下來就是將 組合程式碼 轉成 機器程式碼,這個階段會產生二進位制檔案,並且會構建 section 資訊以及符號表資訊,可以使用 gcc -c 即可。
[root@localhost data]# gcc main.c -c -o main.o -masm=intel
[root@localhost data]# ls
main.c main.i main.o main.s
二進位制檔案模式預設是不能視覺化開啟的,可以藉助於 objdump 工具。
[root@localhost data]# objdump
-h, --[section-]headers Display the contents of the section headers
-t, --syms Display the contents of the symbol table(s)
[root@localhost data]# objdump -t main.o
main.o: file format elf64-x86-64
SYMBOL TABLE:
0000000000000000 l df *ABS* 0000000000000000 main.c
0000000000000000 l d .text 0000000000000000 .text
0000000000000000 l d .data 0000000000000000 .data
0000000000000000 l d .bss 0000000000000000 .bss
0000000000000000 l d .rodata 0000000000000000 .rodata
0000000000000004 l O .data 0000000000000004 static_var.2179
0000000000000000 l d .note.GNU-stack 0000000000000000 .note.GNU-stack
0000000000000000 l d .eh_frame 0000000000000000 .eh_frame
0000000000000000 l d .comment 0000000000000000 .comment
0000000000000000 g O .data 0000000000000004 global_var
0000000000000000 g F .text 0000000000000058 func
0000000000000000 *UND* 0000000000000000 printf
0000000000000058 g F .text 000000000000001f main
在上面的符號表中看到了 func函數以及 static_var 和 global_var 以及所屬的 section。
5. 連結階段
這個階段主要是將多個二進位制程式碼檔案進一步整合變成可在作業系統上執行的可執行檔案,可以使用 gcc -o 。
[root@localhost data]# gcc main.c -o main
[root@localhost data]# ls
main main.c main.i main.o main.s
[root@localhost data]# ./main
global_var = 10, static_var = 5 PI=3.141593
global_var = 11, static_var = 6 PI=3.141593
[root@localhost data]# objdump -t main
main: file format elf64-x86-64
SYMBOL TABLE:
...
0000000000601034 g O .data 0000000000000004 global_var
0000000000601034 g O .data 0000000000000004 global_var
...
000000000040052d g F .text 0000000000000058 func
...
相比組合階段,這個階段的 符號表 中的第一列都是有地址值的,是相對模組的偏移值,比如說: module+0x000000000040052d 標記的是 func 函數。
上面是 linux 上的可執行檔案的符號表資訊,有些朋友說我是 windows 平臺上的,怎麼看符號表資訊呢?
三:Windows 上的 pdb 解析
1. 觀察 pdb 檔案
上一節我們看到的是 linux 上 elf格式 的可執行檔案,這一節看下 windows 平臺上的PE檔案 的符號表資訊是什麼樣的呢?有了前面四階段編譯的理論基礎,再聊就比較簡單了。
在 windows 平臺上 符號表資訊 是藏在 pdb 檔案中的,這種拆開的方式是有很大好處的,如果需要偵錯程式碼,windbg 會自動載入 pdb 檔案,無偵錯的情況下就不需要載入 pdb 了,減少了可執行檔案的大小,也提升了效能。
接下來用 SymView.exe 這種工具去開啟 pdb 檔案,截圖如下:

從圖中可以看到,符號表資訊高達 10968 個,並且 func 函數的入口地址是在 module +0x11870 處,相當於做了一個標記,接下來我們拿這個func做一個測試。
2. 有 pdb 的 func 函數
首先說一下為什麼通過 exe 可以找到 pdb,這是因為 PE 頭的 DIRECTORY_ENTRY_DEBUG 節中記錄了 pdb 的地址。

只要這個路徑有 pdb 就可以在 windbg 執行中按需載入了,然後通過 u MySample.exe+0x11870 觀察,截圖如下:
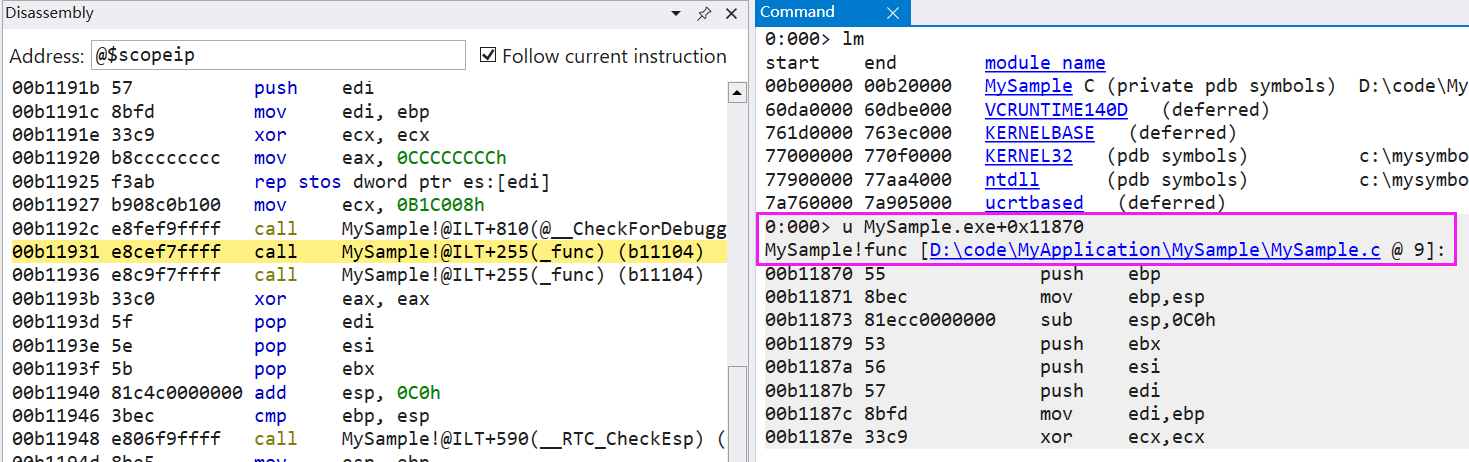
圖中顯示的非常清楚,地址 00fd1870 就是 func 的入口地址,讓一個無意義的地址馬上有意義起來了,哈哈~~~
3. 無 pdb 的 func 函數
這一小節是提供給好奇的朋友的,如果沒有 pdb,那組合上又是一個什麼模樣,為了找到 func 的入口地址,我們內嵌一個 int 3 ,然後把 pdb 給刪掉,程式碼如下:
int main() {
__asm {
int 3;
}
func();
func();
return 0;
}
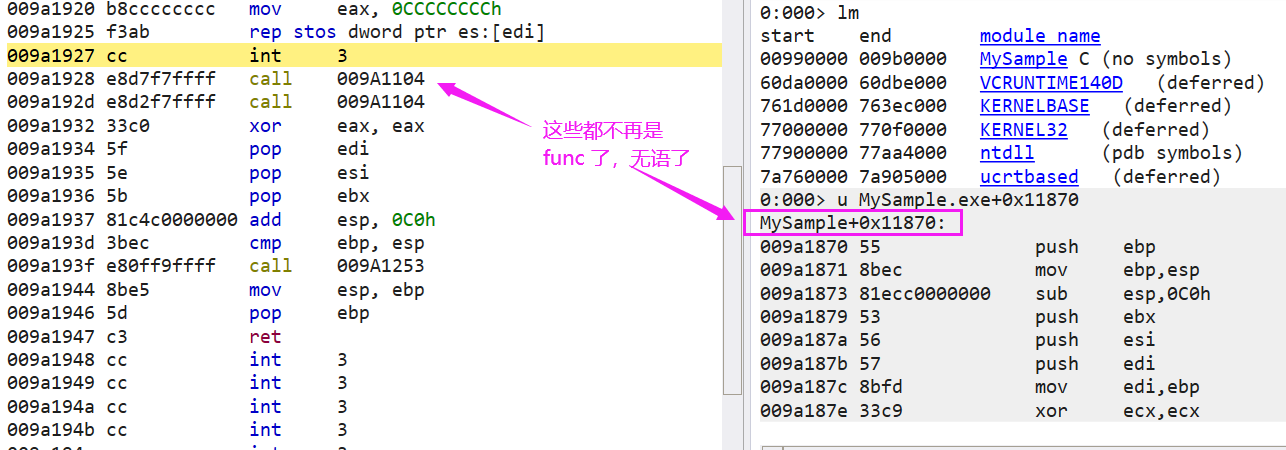
從圖中可以看到,func 標記已經沒有了,取而代之的都是 module+0xxx,這就會給我們逆向偵錯帶來巨大的障礙。
三: 總結
總而言之,符號表就是對茫茫記憶體進行標記,就像百度地圖一樣,讓我們知道某個經緯度上有什麼建築,讓無情的地理座標更加有溫度,讓世界更美好。
