火星探測器背後的人工智慧:從原理到實戰的強化學習
本文詳細探討了強化學習在火星探測器任務中的應用。從基礎概念到模型設計,再到實戰程式碼演示,我們深入分析了任務需求、環境模型構建及演演算法實現,提供了一個全面的強化學習案例解析,旨在推動人工智慧技術在太空探索中的應用。
關注TechLead,分享AI全維度知識。作者擁有10+年網際網路服務架構、AI產品研發經驗、團隊管理經驗,同濟本復旦碩,復旦機器人智慧實驗室成員,阿里雲認證的資深架構師,專案管理專業人士,上億營收AI產品研發負責人。

一、引言
火星,作為人類探索太空的下一個重要目標,一直吸引著科學家們的眼球。火星探測器作為探索這一未知世界的先鋒,承擔著巨大的任務和挑戰。在這一任務中,強化學習(Reinforcement Learning, RL)作為一種智慧學習方法,為火星探測器的自主決策提供了新的可能性。
強化學習,簡而言之,是讓計算機通過與環境的互動,自主學習如何做出最優的決策。在火星探測任務中,由於火星環境的複雜性和不確定性,傳統的程式設計方法難以覆蓋所有潛在的情況。因此,強化學習在這裡扮演著至關重要的角色。它允許探測器在模擬環境中進行大量的試驗和錯誤,從而學習如何在各種複雜環境下作出最佳決策。
這種學習過程類似於人類學習一個新技能。想象一下,當你第一次學習騎自行車時,你可能會摔倒很多次,但每次摔倒後,你都會學會一些新的技巧,比如如何保持平衡,如何調整方向。最終,這些累積的經驗使你能夠熟練地騎自行車。同樣,在強化學習中,探測器通過與環境的不斷互動,逐漸學習如何更好地執行任務。
在本文章中,我們將深入探討強化學習在火星探測器任務中的應用。我們將從基本的強化學習概念開始,逐步深入到具體的模型設計、程式碼實現,以及最終的任務執行。通過這一系列的解析,我們不僅能夠了解強化學習技術的細節,還能夠領略到其在現實世界中的巨大潛力和應用價值。
二、強化學習基礎
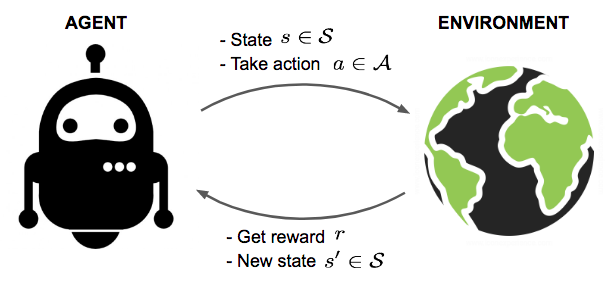
在深入探討火星探測器的案例之前,我們需要建立強化學習的基礎。強化學習是一種讓機器通過試錯來學習如何完成複雜任務的方法。這種方法的美妙之處在於,它不是簡單地告訴機器每一步該做什麼,而是讓機器自己發現如何達成目標。
強化學習的基本概念
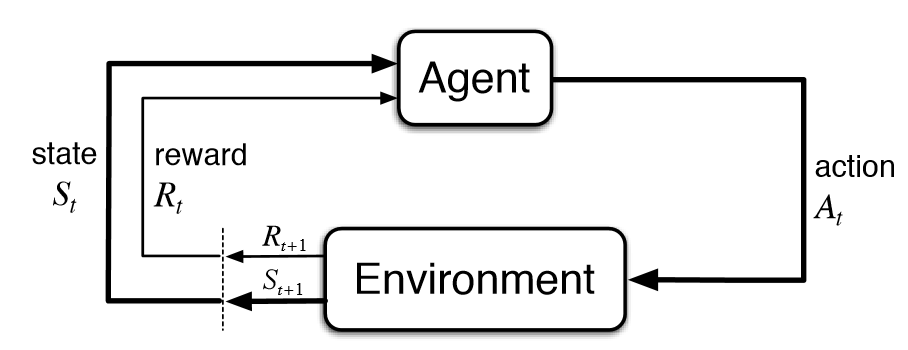
在強化學習中,有幾個關鍵概念:
- 代理(Agent):在火星探測器的例子中,代理就是探測器本身。
- 環境(Environment):環境是代理所處的世界,即火星的表面和大氣。
- 狀態(State):代理在某一時間點的情況,例如探測器的位置和周圍環境。
- 動作(Action):代理可以執行的操作,比如移動或者採集樣本。
- 獎勵(Reward):代理根據其動作獲得的反饋,用於評價動作的好壞。
主要演演算法概述
在強化學習中,有多種演演算法,如Q-Learning、Deep Q-Network(DQN)、Policy Gradients等。每種演演算法都有其獨特之處,但它們共同的目標是優化代理的行為以最大化累積獎勵。
以Q-Learning為例,它是一種基於價值的方法,旨在學習一個動作價值函數(Action-Value Function),指示在特定狀態下采取特定動作的預期效用。
Q-Learning 範例程式碼
import numpy as np
# 初始化Q表
Q = np.zeros([環境狀態數, 環境動作數])
# 學習引數
學習率 = 0.8
折扣因子 = 0.95
for episode in range(總迭代次數):
狀態 = 初始化環境()
while not done:
動作 = 選擇動作(狀態, Q) # 根據Q表或隨機選擇
新狀態, 獎勵, done, _ = 執行動作(動作)
# Q表更新
Q[狀態, 動作] = Q[狀態, 動作] + 學習率 * (獎勵 + 折扣因子 * np.max(Q[新狀態]) - Q[狀態, 動作])
狀態 = 新狀態
環境建模與獎勵設計
在火星探測器的案例中,環境建模尤為關鍵。我們需要準確地模擬火星的地形、大氣條件等,以確保訓練的有效性。獎勵設計也至關重要,它直接影響著探測器學習的方向。例如,我們可能會給探測器設定獎勵,以鼓勵它避開危險地形或有效採集科學資料。
通過這一節的學習,我們為深入理解火星探測器案例奠定了堅實的基礎。接下來,我們將探討如何將這些基礎應用於實際的火星探測任務。
三、火星探測器任務分析

火星探測器任務,作為一項前所未有的挑戰,需要在極端和未知的環境中作出精確決策。本章節將深入分析這一任務的細節,並探討如何通過強化學習建立有效的模型和機制來解決這些挑戰。
任務需求與挑戰
火星探測器的主要任務包括表面探測、樣本收集、資料傳輸等。每項任務都面臨著獨特的挑戰,如極端溫度變化、地形複雜、通訊延遲等。這些挑戰要求探測器具備高度的自主性和適應性。
探測器環境建模
為了讓強化學習演演算法能有效地學習和適應火星環境,我們首先需要構建一個準確的環境模型。這個模型需要包括:
- 地形特徵:模擬火星的地形,包括平原、山脈、沙丘等。
- 環境條件:考慮溫度、塵暴、太陽輻射等因素。
- 機器人狀態:包括位置、能源水平、載荷等。
這個環境模型是探測器學習的「沙盒」,在這裡,它可以安全地嘗試和學習,而不會面臨真實世界的風險。
目標設定與獎勵機制
在強化學習中,明確的目標和獎勵機制是至關重要的。對於火星探測器,我們可以設定如下目標和獎勵:
- 目標:安全導航、有效採集樣本、保持通訊等。
- 獎勵:成功採集樣本獲得正獎勵,能源消耗過大或受損獲得負獎勵。
這些目標和獎勵構成了探測器學習的驅動力。通過不斷地嘗試和調整,探測器學習如何在複雜環境中實現這些目標。
層層遞進的關係
在這個分析中,我們建立了一個層層遞進的框架:
- 環境建模:首先,我們建立了一個模擬火星環境的詳細模型。
- 目標與獎勵:接著,我們定義了探測器需要實現的具體目標和相應的獎勵機制。
- 學習與適應:基於這個環境和獎勵系統,探測器通過強化學習演演算法學習如何完成任務。
這種逐步深入的方法不僅確保了強化學習演演算法可以有效地應用於火星探測器任務,而且還提供了一個框架,用於評估和優化探測器的行為和策略。
通過這個詳盡的分析,我們為火星探測器的強化學習應用打下了堅實的基礎。接下來,我們將深入探討如何設計和實施強化學習模型,以實現這些複雜且關鍵的任務。
四、強化學習模型設計
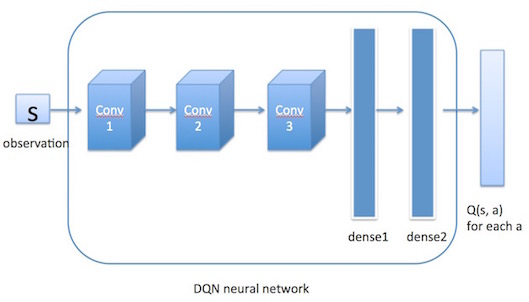
設計強化學習模型是實現火星探測器自主決策的核心。這一部分將詳細介紹模型的設計過程,包括架構、狀態和動作的定義,以及深度學習與強化學習的結合。
模型架構概述
在火星探測器的案例中,我們選擇深度Q網路(Deep Q-Network, DQN)作為核心演演算法。DQN結合了傳統的Q-Learning演演算法和深度神經網路,使得代理能夠處理更復雜的狀態空間。
DQN架構核心元件:
- 輸入層:代表探測器的當前狀態。
- 隱藏層:多個層次,用於提取狀態的特徵。
- 輸出層:代表每個動作的預期回報。
狀態、動作與獎勵的定義
在強化學習中,狀態、動作和獎勵的定義至關重要。在我們的案例中:
- 狀態(State):包括探測器的位置、方向、速度、能源水平等。
- 動作(Action):如移動方向、速度改變、資料採集等。
- 獎勵(Reward):基於任務目標,如成功採集樣本給予正獎勵,能耗過大或損壞給予負獎勵。
深度學習與強化學習的結合
將深度學習與強化學習結合起來,能夠處理複雜的狀態空間和高維動作空間。在DQN中,深度神經網路用於近似Q函數(動作價值函數),以預測在給定狀態下每個動作的預期回報。
DQN模型程式碼範例
import torch
import torch.nn as nn
import torch.optim as optim
# 神經網路結構定義
class DQN(nn.Module):
def __init__(self, 輸入狀態數, 動作數):
super(DQN, self).__init__()
self.fc1 = nn.Linear(輸入狀態數, 50)
self.fc2 = nn.Linear(50, 50)
self.fc3 = nn.Linear(50, 動作數)
def forward(self, x):
x = torch.relu(self.fc1(x))
x = torch.relu(self.fc2(x))
return self.fc3(x)
# 範例化網路
網路 = DQN(輸入狀態數, 動作數)
損失函數 = nn.MSELoss()
優化器 = optim.Adam(網路.parameters(), lr=0.001)
在這個範例中,我們構建了一個簡單的神經網路,具有三個全連線層。這個網路將接受探測器的狀態作為輸入,並輸出每個動作的預期價值。
通過這一節的設計和程式碼實現,我們為火星探測器的自主決策打下了堅實的基礎。在接下來的章節中,我們將展示如何使用這個模型進行實際的訓練和評估。
五、完整實戰程式碼演示
在這一部分,我們將演示一套完整的實戰程式碼,用於火星探測器任務的強化學習訓練。這套程式碼將包括環境設定、模型定義、訓練迴圈,以及模型評估的步驟。
1. 環境設定
首先,我們需要設定模擬火星環境。這裡假設我們已經有一個模擬環境,它能夠提供狀態資訊和接受動作輸入。
import gym # 使用gym庫來建立模擬環境
# 假設'火星探測器環境'是已經定義好的環境
環境 = gym.make('火星探測器環境')
2. DQN模型定義
接下來,我們定義深度Q網路(DQN)模型。這個模型將用於學習在給定狀態下執行哪個動作可以獲得最大的回報。
class DQN(nn.Module):
def __init__(self, 輸入狀態數, 動作數):
super(DQN, self).__init__()
# 定義網路層
self.fc1 = nn.Linear(輸入狀態數, 64)
self.fc2 = nn.Linear(64, 64)
self.fc3 = nn.Linear(64, 動作數)
def forward(self, x):
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
return self.fc3(x)
輸入狀態數 = 環境.observation_space.shape[0]
動作數 = 環境.action_space.n
網路 = DQN(輸入狀態數, 動作數)
3. 訓練過程
在訓練過程中,我們將讓探測器在模擬環境中執行動作,並根據反饋更新網路。
def 選擇動作(狀態, epsilon):
if np.random.rand() < epsilon:
return 環境.action_space.sample() # 探索
else:
with torch.no_grad():
return 網路(torch.from_numpy(狀態).float()).max(0)[1].item() # 利用
# 訓練引數
epochs = 1000
epsilon = 1.0
epsilon_decay = 0.995
min_epsilon = 0.01
學習率 = 0.001
優化器 = optim.Adam(網路.parameters(), lr=學習率)
for epoch in range(epochs):
狀態 = 環境.reset()
總獎勵 = 0
while True:
動作 = 選擇動作(狀態, epsilon)
新狀態, 獎勵, done, _ = 環境.step(動作)
總獎勵 += 獎勵
# Q-Learning更新
目標 = 獎勵 + (0.99 * 網路(torch.from_numpy(新狀態).float()).max(0)[0] if not done else 0)
當前Q值 = 網路(torch.from_numpy(狀態).float())[動作]
loss = F.mse_loss(當前Q值, torch.tensor([目標]))
優化器.zero_grad()
loss.backward()
優化器.step()
if done:
break
狀態 = 新狀態
epsilon = max(epsilon * epsilon_decay, min_epsilon)
print(f"Epoch: {epoch}, Total Reward: {總獎勵}")
4. 模型評估
最後,我們對訓練好的模型進行評估,以驗證其效能。
def 評估模型(環境, 網路, 評估次數=10):
總獎勵 = 0
for _ in range(評估次數):
狀態 = 環境.reset()
while True:
動作 = 網路(torch.from_numpy(狀態).float()).max(0
)[1].item()
狀態, 獎勵, done, _ = 環境.step(動作)
總獎勵 += 獎勵
if done:
break
平均獎勵 = 總獎勵 / 評估次數
return 平均獎勵
評估結果 = 評估模型(環境, 網路)
print(f"平均獎勵: {評估結果}")
以上是火星探測器任務的強化學習實戰程式碼演示。通過這個例子,我們展示瞭如何從環境設定、模型定義到訓練和評估的整個流程,為實現火星探測器的自主決策提供了一個詳細的指南。
六、總結
經過前面幾個章節的深入探討和實戰演示,我們現在對於如何應用強化學習於火星探測器的任務有了全面的瞭解。此篇章節的總結旨在回顧我們所學的內容,並提出一些對未來研究和應用的展望。
回顧核心要點
-
強化學習的基礎:我們介紹了強化學習的基本概念,包括代理、環境、狀態、動作和獎勵,並概述了主要的強化學習演演算法,為後續內容打下基礎。
-
火星探測器任務分析:在這一部分,我們分析了火星探測器任務的需求和挑戰,包括環境建模、目標設定與獎勵機制的設計,這是強化學習模型成功的關鍵。
-
模型設計與實戰程式碼:詳細介紹了強化學習模型的設計,特別是深度Q網路(DQN)的應用。我們還提供了一套完整的實戰程式碼,包括環境設定、模型訓練和評估,使理論得以應用於實踐。
展望未來
儘管我們在模擬環境中取得了進展,但在實際應用中,火星探測器面臨的挑戰要複雜得多。未來的研究可以聚焦於以下幾個方面:
- 環境模型的改進:更加精確地模擬火星的環境,包括更多變化和未知因素。
- 演演算法的進一步發展:探索更先進的強化學習演演算法,提高學習效率和適應性。
- 硬體與軟體的協同:優化探測器的硬體設計以更好地適應強化學習演演算法,提高整體效能。
- 實際任務應用:在模擬環境中驗證的演演算法需要在實際火星探測任務中得到測試和應用。
結語
強化學習在火星探測器任務中的應用展示了人工智慧技術在解決複雜、現實世界問題中的巨大潛力。通過不斷的研究和實踐,我們不僅能推動科技的發展,還能為人類的太空探索事業做出貢獻。希望這篇文章能激發更多熱情和興趣,促進人工智慧和太空探索領域的進一步研究和發展。
關注TechLead,分享AI全維度知識。作者擁有10+年網際網路服務架構、AI產品研發經驗、團隊管理經驗,同濟本復旦碩,復旦機器人智慧實驗室成員,阿里雲認證的資深架構師,專案管理專業人士,上億營收AI產品研發負責人。
如有幫助,請多關注
TeahLead KrisChang,10+年的網際網路和人工智慧從業經驗,10年+技術和業務團隊管理經驗,同濟軟體工程本科,復旦工程管理碩士,阿里雲認證雲服務資深架構師,上億營收AI產品業務負責人。