部落格園又崩了,這個鍋要不要阿里雲背?
昨天下午部落格園又崩了,不過與其它大廠的崩潰不同,部落格園出現崩潰的頻率好像有點高。
這是怎麼回事呢?和阿里雲又有什麼關係,這篇文章就來分析分析。
到底是誰的問題?
昨天下午(2023年12月8日)部落格園官方釋出了一個故障公告,官網截圖如下:

部落格園的故障是資料庫CPU 100%,今年已經出現了7次,根據我這個不經常上部落格園的人的觀察,往年也有出現,好像頻率沒這麼高。
出現了7次都不能解決,這是個什麼問題呢?
根據我的技術經驗,資料庫CPU百分之百,一般是某些SQL寫的質量不佳,在某些情況下可能出現了巨量資料量全表掃描的情況,遲遲不能執行完畢,長期霸佔CPU資源導致的。
按說這種問題只要定位到對應的SQL,改掉相關語句就可以了,但是就是這個問題把部落格園難住了。
引數嗅探問題?
看看官方針對此次問題的說明:



這裡有兩個重要的資訊:部落格園的資料庫使用的是 SQL Server;部落格園的主要查詢使用的是儲存過程。部落格園是.NET技術體系的,使用SQL Server比較順其自然;使用儲存過程可以提高SQL執行的效率,部落格園是08年創立的,這在十幾年前也比較流行;看它使用的分頁方法也是比較新的,這說明它也一直在優化。
官方懷疑是引數嗅探問題造成 SQL Server 快取了效能極差的執行計劃,這句話中有兩個名詞:引數嗅探問題和執行計劃,沒接觸過的同學可能會比較蒙,我先給大家普及一下。
執行計劃:每條SQL在資料庫內部執行時都會有一個執行計劃,主要就是先查詢哪張表、表之間怎麼關聯、執行的時候使用哪些索引,等等。
引數嗅探問題:儲存過程在首次執行時會先進行編譯,後續執行的時候都使用這個編譯的結果,而不是每次都解釋執行,因為編譯相對比較耗時。編譯時,資料庫還會根據當前使用的儲存過程引數確定一個最優的執行計劃,並把這個執行計劃也一併快取起來,後續再執行的時候就會直接使用這個執行計劃。
問題主要就出現在這個快取的執行計劃,因為對於不同的引數來說,執行計劃的效率可能差別很大,這主要是查詢資料分佈不均勻的問題造成的。
我在公司的業務中也經常遇到這個問題,有的使用者資料多,有的使用者資料少,即使我們為使用者Id欄位設定了索引,資料庫有時仍舊會認為不使用這個索引的效率更高,它會自己選擇一個自認為更優的查詢路徑,比如全表掃描,實際執行時就出現了慢SQL的情況。
到部落格園這裡,官方認為就是自己的某個儲存過程因為引數嗅探問題導致某些慢SQL,慢SQL導致CPU使用過高,最後導致資料庫崩潰。
而官方一直沒有定位到出現問題的SQL或者出現問題的儲存過程,可能部落格園的SQL太多了吧,出現問題的不止一個SQL。又或者是 SQL Server 的問題,或者阿里雲的鍋?
SQL Server的問題?
SQL Server 作為一款商業資料庫,能活到現在,而且價格還不低,其產品能力是經過了殘酷的市場考驗的。雖然任何產品都不可避免的存在一些BUG,但是導致這種問題的BUG應該不會持續這麼久。所以 SQL Server 本身的問題應該不大,或者說 SQL Server 的資料查詢方式沒有問題。
還有很多同學提到 SQL Server 效能不行,單純根據我的使用經驗來說,類似的場景 SQL Server的查詢效能往往比 MySQL 要好不少,其它很多使用者也有類似的反饋:

我也專門找了一些 SQL Server 和其它資料庫的效能對比,截圖如下:
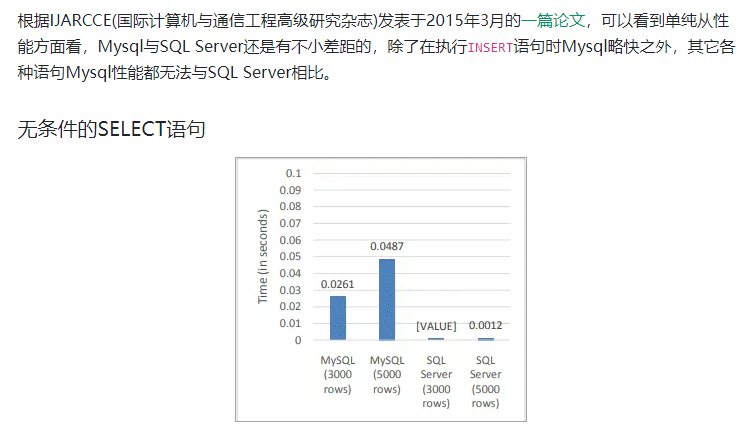
文章和資料來源:
https://segmentfault.com/q/1010000022848400
https://www.ijarcce.com/upload/2015/march-15/IJARCCE%2039.pdf
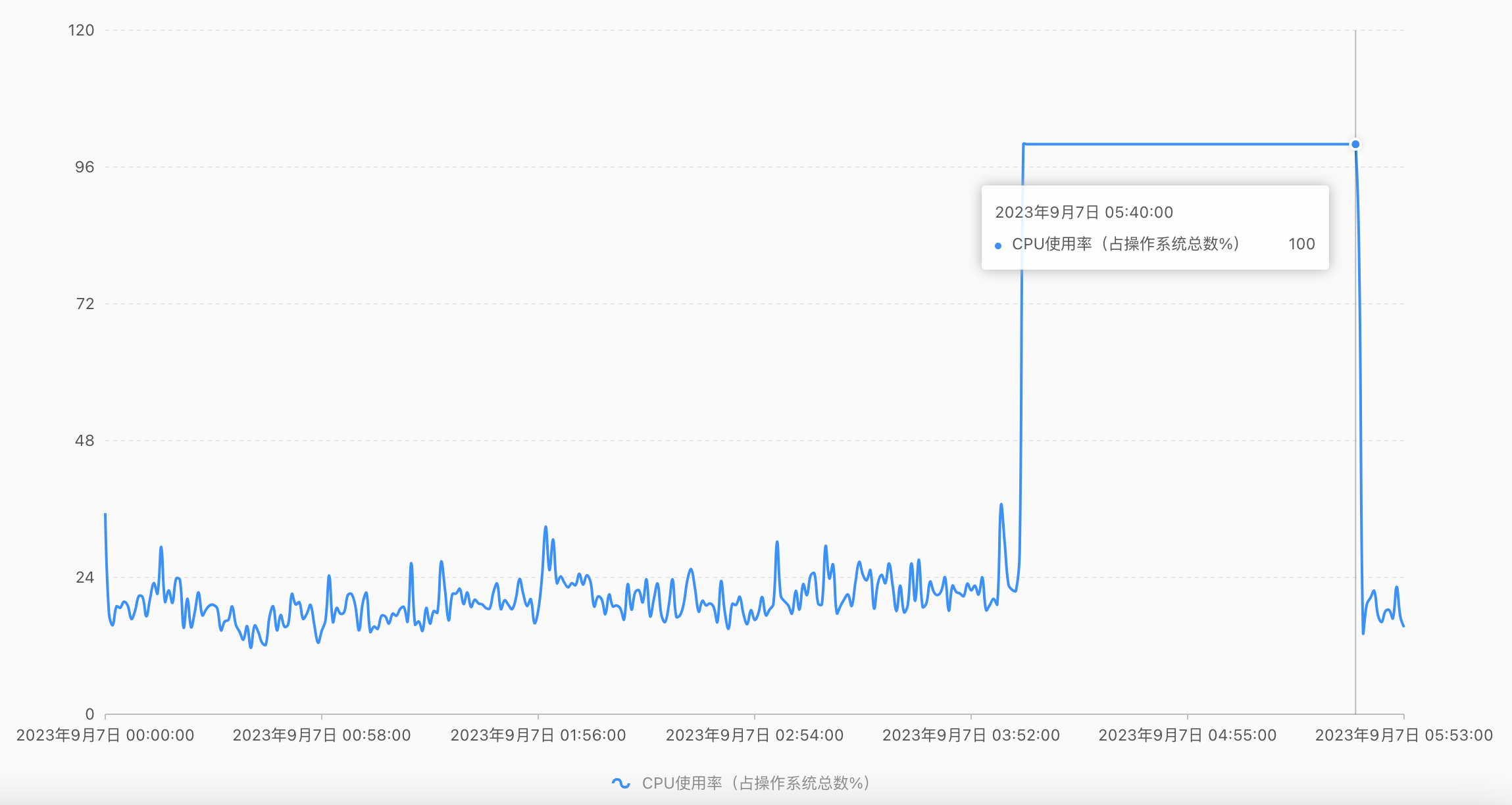
另外我們也可以從部落格園分享的資料庫的監控紀錄檔中略窺一二:

從圖上可以看出,出現問題的時間比較隨機,也不是什麼高峰期。部落格園也提到過凌晨4-5點鐘出現類似問題。看這個CPU使用率只有20%多一點,所以並非是遇到了效能瓶頸。
阿里雲的問題?
阿里云為什麼可能背鍋?因為部落格園部署在阿里雲上,伺服器和資料庫都用的阿里雲產品。
記得之前出現這個問題時,部落格園官方對阿里雲頗多微詞,後來雙方可能進行了深入交流,部落格園接受了引數嗅探問題,此後就一直在這塊查詢。
那麼阿里雲能不能徹底撇清關係呢?
正常情況下,阿里雲上部署的 SQL Server 應該是從微軟購買的,微軟應該也要提供一些技術支援,包括安裝和日常的執行維護支援。這個 SQL Server 可能和 Azure 上部署的有些差別,但微軟也不會砸自己的招牌,資料庫版本不應該有大問題。
阿里雲只是部署和運維 SQL Server,說白了阿里雲只是搞了底層的儲存、網路、作業系統等服務,上層的資料庫應用完全是微軟的,他插不上手,這種資料庫程式的CPU百分百的故障很難和阿里雲乾的事掛上鉤。
再者阿里雲自己也開發資料庫,雖然 SQL Server 不開源,但是高手們對於一些底層的設計,或者可能存在問題的地方,應該也是門清的。阿里雲上 SQL Server 服務使用者眾多,如果很多企業都遇到這個問題,應該也早就爆出來並解決了。
所以這個問題甩鍋到阿里雲身上的難度比較大。當然也沒辦法完全排除,畢竟總有些極端情況,阿里雲最近也崩了很多次,會不會在某些方面有些么蛾子?大家也不知道。
怎麼解決問題?
換資料庫?

正如上文所說,問題出現在資料庫自身上的可能性不大,而且換資料庫要重寫所有的SQL,還可能要修改表結構,這個工作量不是一星半點。
如果真的是引數嗅探問題,換了資料庫一樣存在執行計劃效率不一致的問題。
換雲?
這基本是認為阿里雲能力不行。
如果真的懷疑是這方面的問題,倒是可以試試,不過不是直接遷移過去,而是把資料匯出來一份,放到別的公有云上,或者本地部署一套SQL Server。
然後採集SQL執行紀錄檔,在測試的資料庫中進行重放執行,如果問題還會發生,那就不是雲廠商的問題,如果跑了很久,問題都沒有出現過,那才有根據說雲服務的問題概率比較大一些。
當然這個測試的成本比較高,也許可以通過精簡樣本或者提高SQL執行頻率加速一下測試。
作為技術人,甩鍋時一定要有理有據。
再或者就不講理,部落格園死磕阿里雲,要麼就是你的問題,要麼就是你幫我找出問題來。有時候雲廠商的技術團隊也是可以上門或者以其他方式進行親密溝通的。再不行花點錢找個高手呢?可能還是部落格園太老實了?或者阿里雲太傲慢了?又或者部落格園太窮了?
解決引數嗅探問題
阿里雲的問題只能是猜測,引數嗅探的問題確是能夠實實在在抓住的,阿里雲的資料庫產品是提供了慢SQL紀錄檔查詢的。
只需要找出出現問題時的慢SQL,看部落格園以往的故障公告也是曾經抓到過一些問題SQL的。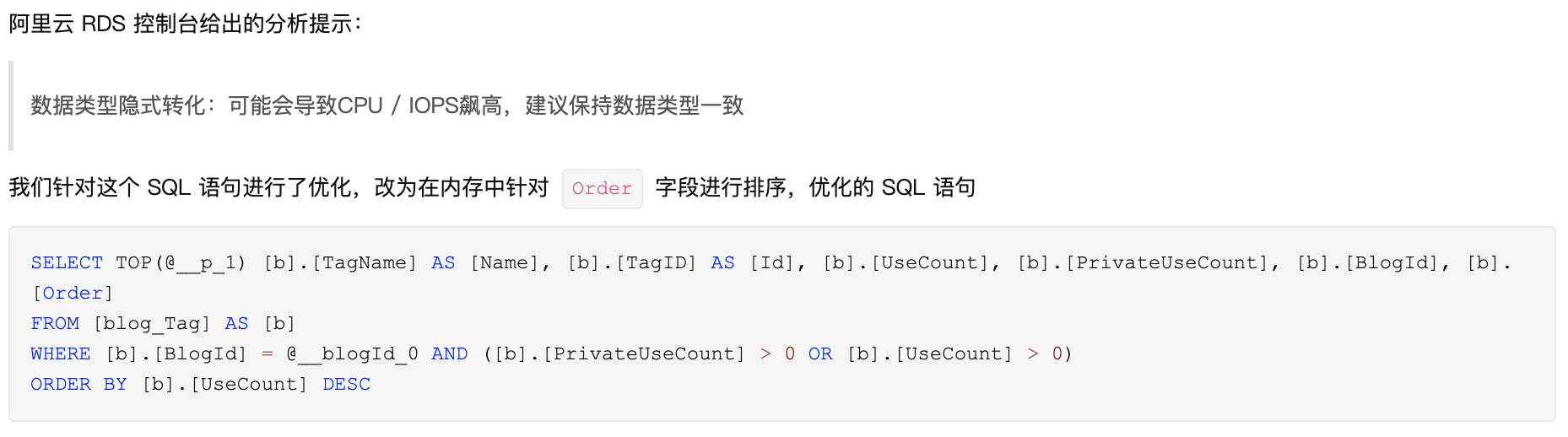
但是問題為什麼還會一直出現呢?
有可能是問題SQL太多了。經過十幾年的迭代,部落格園的程式碼量可能十分龐大,再加上部落格園這兩年經營比較困難,沒有人力和精力投入到這方面,只能問題出現了再去反查,然後改正。能活著就不錯了,估計團隊內部也沒有技術牛人,精力都放到了活下來的事情上。
具體為什麼一直解決不了,咱們就說到這裡。
下面給大家聊聊怎麼解決引數嗅探的問題,我想這個對於搞技術的同學來說才是最重要的.
上面我們已經說過引數嗅探問題就是資料庫使用了效率不高的執行計劃,那麼解決這個問題的核心思路就是讓資料庫不去使用這些低效計劃。這裡分享一些我瞭解的方法。
暴力清理
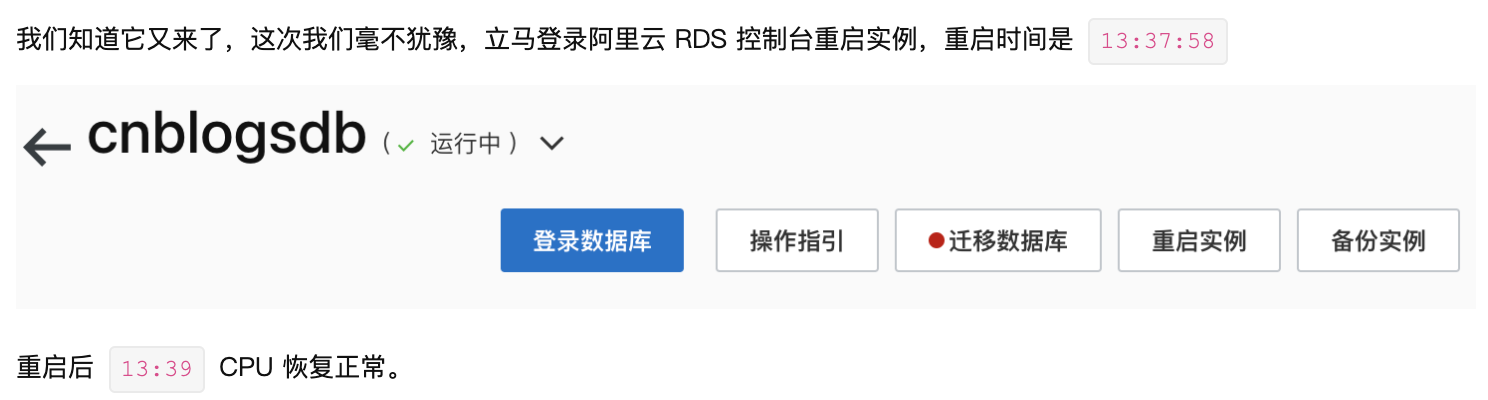
重啟伺服器、重啟資料庫,部落格園採用的處理方法差不多都是這個。
還有一個稍微優雅點的方案,清除所有的執行計劃快取:DBCC FREEPROCCACHE,不管這些執行計劃是不是有問題。但是不確定這個指令能不能在阿里雲的資料庫服務上執行。
這些都是強制重新建立執行計劃的方法,壞處就是影響都比較大,很可能會影響使用者使用服務,比較暴力。
而且這些方法不能治本,只能短時間的緩解一下,說不定在某個時刻,執行計劃又被重建了,或者SQL執行又超時了。
優雅機制
SQL Server本身也有一些優雅的方案來緩解這個問題。比如:
- 不快取執行計劃,雖然快取能帶來一些效率上的提升,但相比引數嗅探問題帶來的效能損失就是小巫見大巫了。可以在儲存過程中使用WITH RECOMPILE,讓查詢每次都重新編譯。
- 強制使用某個查詢計劃,比如強制使用某個索引,這個索引對於所有的查詢都不會太差;SQL Server中還可以強制使用某個條件的查詢計劃。不過找到這個索引或者條件的難度可能比較大,因為資料一直在變化,現在是好的並不代表一直好。
- 只清除特定語句或儲存過程的查詢快取,使用 DBCC FREEPROCCACHE(@plan_id) 指定執行計劃,這樣影響更小。
- 另外表統計資訊陳舊、索引碎片、缺少索引都可能導致引數嗅探問題,遇到問題時可以從這幾個方面調查一下。
詳情可參考阿里的這篇文章: http://mysql.taobao.org/monthly/2016/10/10/
謹慎評估
在我們設計表、編寫SQL的時候,需要考慮資料會如何分佈,查詢有哪些條件,特別是資料可能分佈不均勻的情況。
比如有的使用者的資料量可能是大部分使用者的10倍、甚至百倍,排序的欄位可能導致不使用包含條件欄位的索引,查詢可能在多個索引之間飄移。
如果可能存在問題,就要考慮表如何設計、資料如何查詢,普通關聯式資料庫難以解決時,我們還可以考慮採用NoSQL、分散式資料庫等方案,以穩定查詢效率。
以上就是本文的主要內容了,因本人才疏學淺,不免存在錯漏,如有問題還望指正。
關注螢火架構,技術提升不迷路。
