RocksDB 在 vivo 訊息推播系統中的實踐
作者:vivo 網際網路伺服器團隊 - Zeng Luobin
本文主要介紹了 RocksDB 的基礎原理,並闡述了 RocksDB 在vivo訊息推播系統中的一些實踐,通過分享一些對 RocksDB 原生能力的探索,希望可以給使用RocksDB的讀者帶來啟發。
一、背景
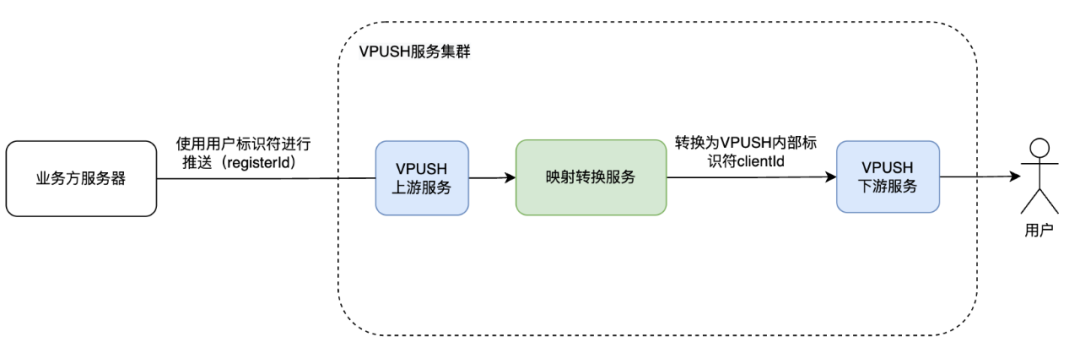
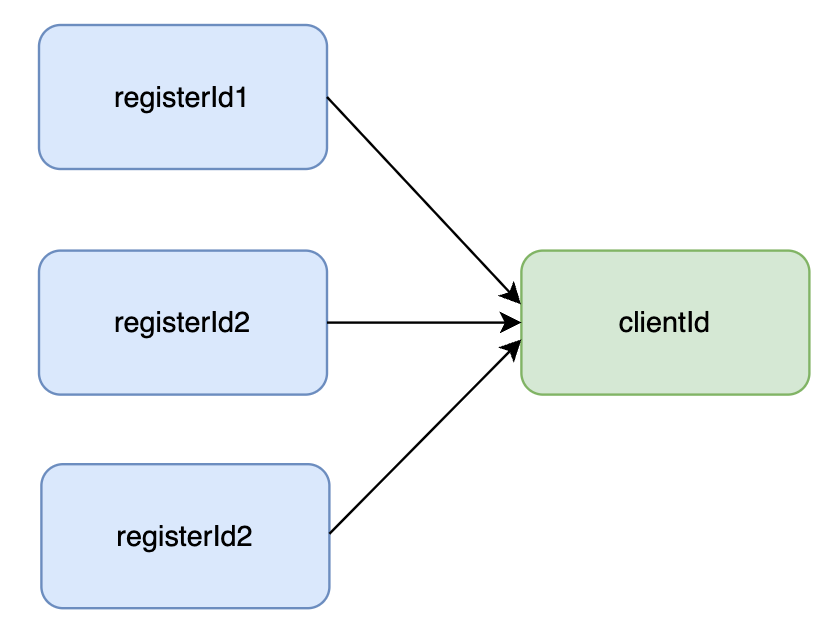
在訊息推播系統中,業務方伺服器通過呼叫推播介面向 VPUSH 服務傳送訊息,請求中會包含一個 registerId,用於標識接收該訊息的使用者裝置。當 VPUSH 服務接收到推播請求時,會使用 registerId 找到對應的使用者,並將訊息推播給其手機。然而,在 VPUSH 內部處理訊息推播時,需要使用一個內部識別符號 ClientId 來標識每個使用者的裝置,可以通過 ClientId 查詢到對應的裝置資訊。
因此,系統中引入了一個對映儲存服務 MappingTranformServer(後文簡稱MT),用於處理 registerId 和 ClientId 之間的轉換。MT 服務快取了所有使用者的裝置識別符號,使用 RocksDB 作為底層儲存引擎,RocksDB 可以提供高並行讀寫能力,以磁碟作為儲存媒介,節省儲存成本。當 VPUSH 服務需要將 registerId 轉換為 ClientId 時,會向 MT 服務發起查詢請求,MT 服務根據請求中的 registerId 查詢對應的 ClientId 並返回,這樣系統下游節點就能夠通過 ClientId 找到對應的裝置,並將訊息推播到使用者手機上了。
系統中除了 registerId 以外,還有許多其他的識別符號,所以引入了 ClientId 來降低後期維護和開發的成本。由於regId 比較有代表性,下文中主要會以 regId 進行舉例講解。
二、RocksDB 原理介紹
在介紹業務場景之前,先簡單介紹一下RocksDB的基本原理。RocksDB的前身是LevelDB,由於LevelDB不支援高並行寫入,Facebook(Meta)針對於LevelDB的一些痛點進行了改造,便有了RocksDB。RocksDB相比於LevelDB,其支援高並行讀寫,優化了SST檔案佈局,提供了多種壓縮策略,總的來說,RocksDB 在繼承了 LevelDB 的全部功能的基礎之上,還針對記憶體和磁碟資料儲存進行了優化,使得 RocksDB 具有更高的吞吐量和更低的延遲,更適合分散式、高可靠性的儲存場景。行業內也有許多資料庫將RocksDB作為底層的儲存引擎,比如 TiDB。
2.1 LSM設計思想
在介紹RocksDB的架構和原理之前,先來了解一下其設計思想:LSM。
LSM全稱為log-structured merge-tree。LSM並非一種資料結構,而是一種設計思想,最根本的目的就是要規避對磁碟的隨機寫入問題,提升寫的效率。其思路如下:
寫入順序:從記憶體到磁碟
-
將資料先寫入到記憶體中。
-
隨著記憶體儲存資料越來越多,達到記憶體閾值,則會將記憶體中的資料轉移到磁碟中。
-
磁碟中資料也分為多層,其中L0層的資料最熱,而最冷的資料分佈在Ln層,且會定期進行合併操作。
LSM 在 RocksDB 設計中的體現:
-
在寫入資料的時候,同時記錄操作紀錄檔。因為記憶體具有易失性,當程式崩潰後,記憶體的資料就丟失了,記錄紀錄檔用於在程式崩潰或者重啟時,記憶體的資料不會丟失。
-
磁碟中的資料並非使用了整體索引結構,而是使用了有序的檔案集合結構。每次將記憶體中的資料寫入到磁碟中或者將磁碟中的資料進行合併時,都會生成新的檔案,這一次生成的檔案會作為一個層,磁碟上會劃分多層,層與層之間相互隔離,並且有序,有序保證了查詢資料時可以使用二分查詢。磁碟檔案層級如下圖所示。
-
資料按照key進行字典序排序。由上述可知,資料從記憶體寫入磁碟時,會不斷生成新的檔案,所以需要不斷對磁碟中的檔案進行合併,然而如果資料亂序,便無法做到高效合併且保持有序。
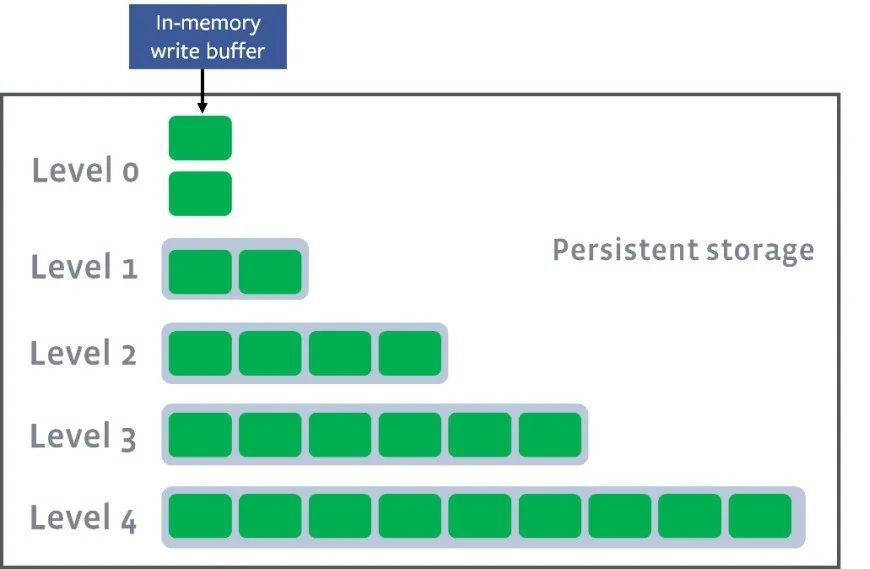
(圖片來源:Leveled-Compaction)
當然,LSM也存在一些讀放大、寫放大、空間放大的問題:
-
【讀放大】:讀取的時候需要從記憶體一直尋找到磁碟中
-
【寫放大】:程式寫入資料一次,系統要寫多次(例如:記憶體一次、磁碟一次)
-
【空間放大】:一份資料在系統中多個地方存在,佔用了更多空間
2.2 內部結構
瞭解完LSM後,可以仔細剖析一下 RocksbDB 的內部結構,下圖是 RocksDB 的內部結構圖。
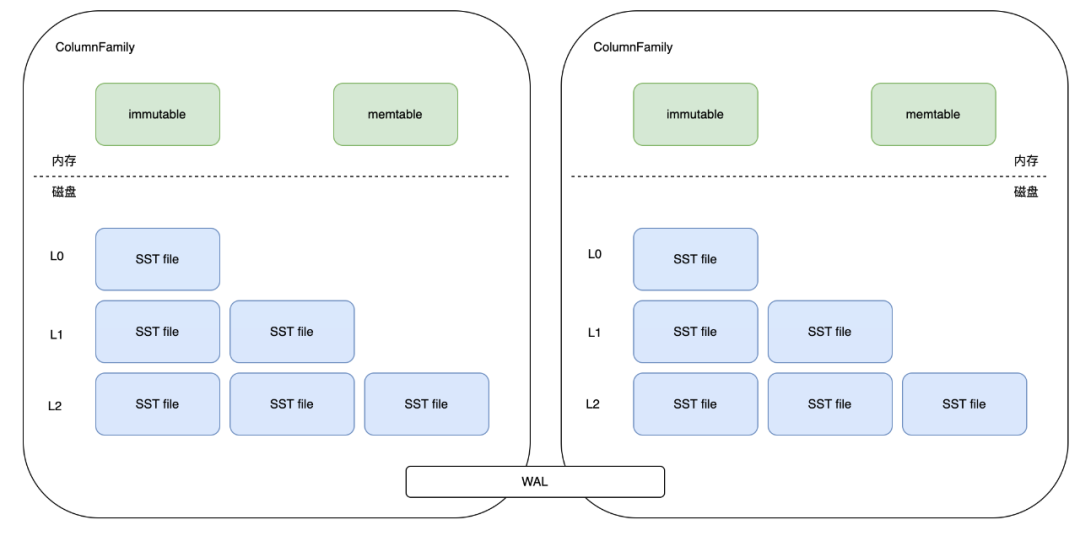
RocksDB 中會分出 ColumnFamily(列族,一系列 kv 組成的資料集,可以理解為就是一個namespace),所有的讀寫操作都需指定 ColumnFamily,每個 ColumnFamily 主要由三部分組成,分別是 memtable/sstfile/wal。
-
memtable 是記憶體檔案資料,新寫入的資料會先進入到 memtable 中,當 memtable 記憶體空間寫滿後,會有一部分老資料被轉移到 sstfile 中。
-
sstfile 便是磁碟中的持久化檔案。
-
所有 ColumnFamily 都會共用 WAL(write-ahead-log) 紀錄檔檔案。
(1)記憶體部分
① memtable
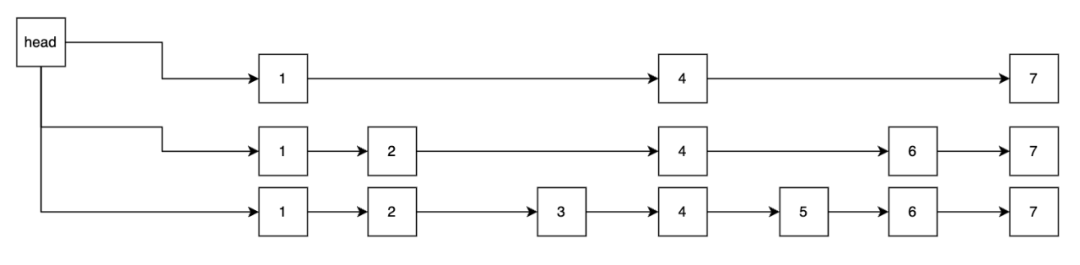
也稱為active memtable。熱點資料均存在這塊記憶體中,用於快速返回使用者的讀寫請求。一旦memtable被寫滿之後,就會被轉為immutable memtable,並生成一個新的active memtable來提供服務。memtable支援多種結構:
skipList/vector/hashLinkList。寫入資料時通過對key進行字典序排序,保持有序。跳躍表的查詢速度可以簡單理解近似二分查詢log(n)。跳錶結構如下圖所示
② immutable memtable
是由於memtable寫滿後,轉換而來,只提供讀,不能做修改。當系統中觸發flush時,就會將同一個ColumnFamily中的immutable memtable進行合併,生成一個sst file放入磁碟中,位於磁碟的L0層。
(2)磁碟部分
① sst,全稱為sorted sequence table
是儲存在磁碟中的持久化資料。sst中也有多種格式,預設設定為BlockBasedTable。其是根據data block來進行歸類儲存的。block中還分為data block資料塊,meta block後設資料塊,footer塊尾。每塊的k-v都是有序的。data block也有快取,名為block cache。顧名思義用於快取SST檔案中的熱點資料到記憶體中,提供高速的讀服務,所有ColumnFamily中都共用一塊block cache。block cache可以設定兩種資料結構:LRU cache和Clock cache。
② WAL,全稱為write ahead log。
WAL會把所有寫操作儲存到磁碟中,當程式發生崩潰時,可以利用WAL重新構建memtable。如果容忍一定數量資料丟失,也可以關閉WAL來提升寫入的效能。
③ Manifest
該檔案主要用於持久化整個LSM的資訊。RocksDB需要將LSM樹的資訊儲存於記憶體中,以便快速進行查詢或者對sst進行compaction壓縮合並。而RocksDB也會將這些資訊持久化到磁碟中,這個就是Manifest檔案。其主要內容便是事務性相關紀錄檔以及RocksDB狀態的變化。當RocksDB崩潰後重啟時,就會先讀取Manifest檔案對LSM進行重建,再根據WAL對記憶體memtable進行恢復。
2.3 寫入資料流程
瞭解完RocksDB的內部結構,我們來分析一下 RocksDB 的寫入流程如下:
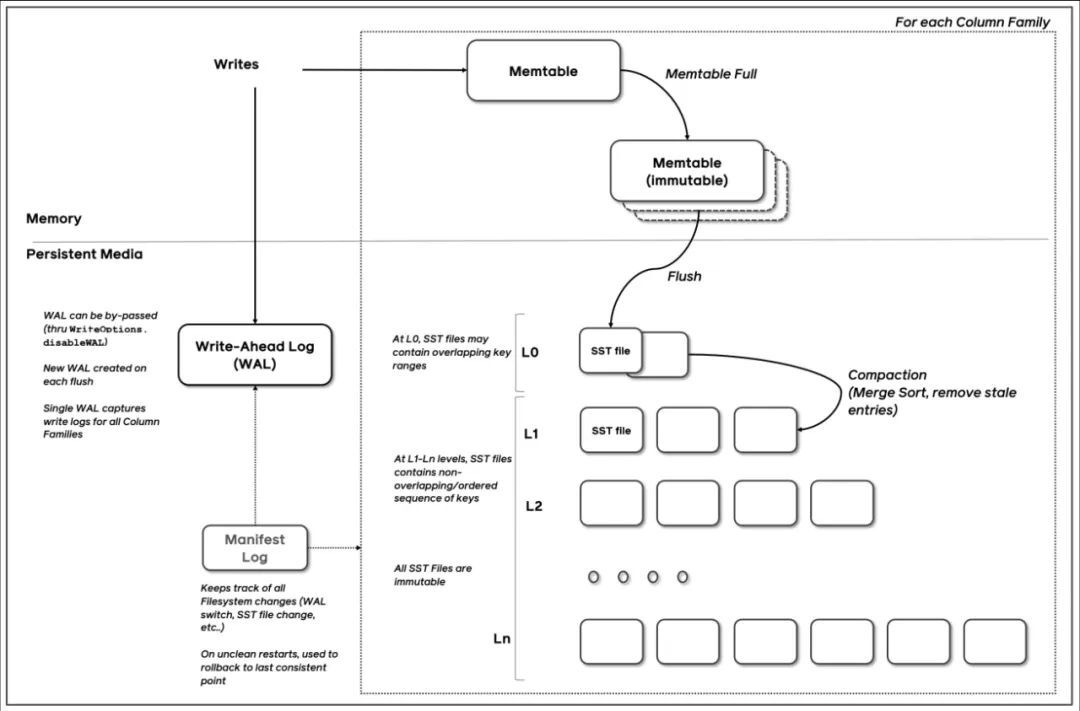
(圖片來源:RocksDB-Overview)
寫入流程:
-
將資料寫入 memtable 的同時也會寫 WAL(write-ahead-log)
-
當 memtable 達到一定閾值後,會將資料遷移到 immutable memtable,其中,immutable 中的資料只能讀不能寫
-
之後 flush 執行緒會負責將 immutable 中的資料持久化到磁碟中,即 SST file(L0層)
-
compaction 執行緒會觸發 compaction 操作將 L0 的 sst file 合併到 L1-Ln 層中。所有的 sst file 都是唯讀不寫
2.4 讀取資料流程
同樣地,還有讀取流程,RocksDB 的讀取流程如下:

簡而言之,讀流程基於記憶體到磁碟的順序,逐層進行查詢。
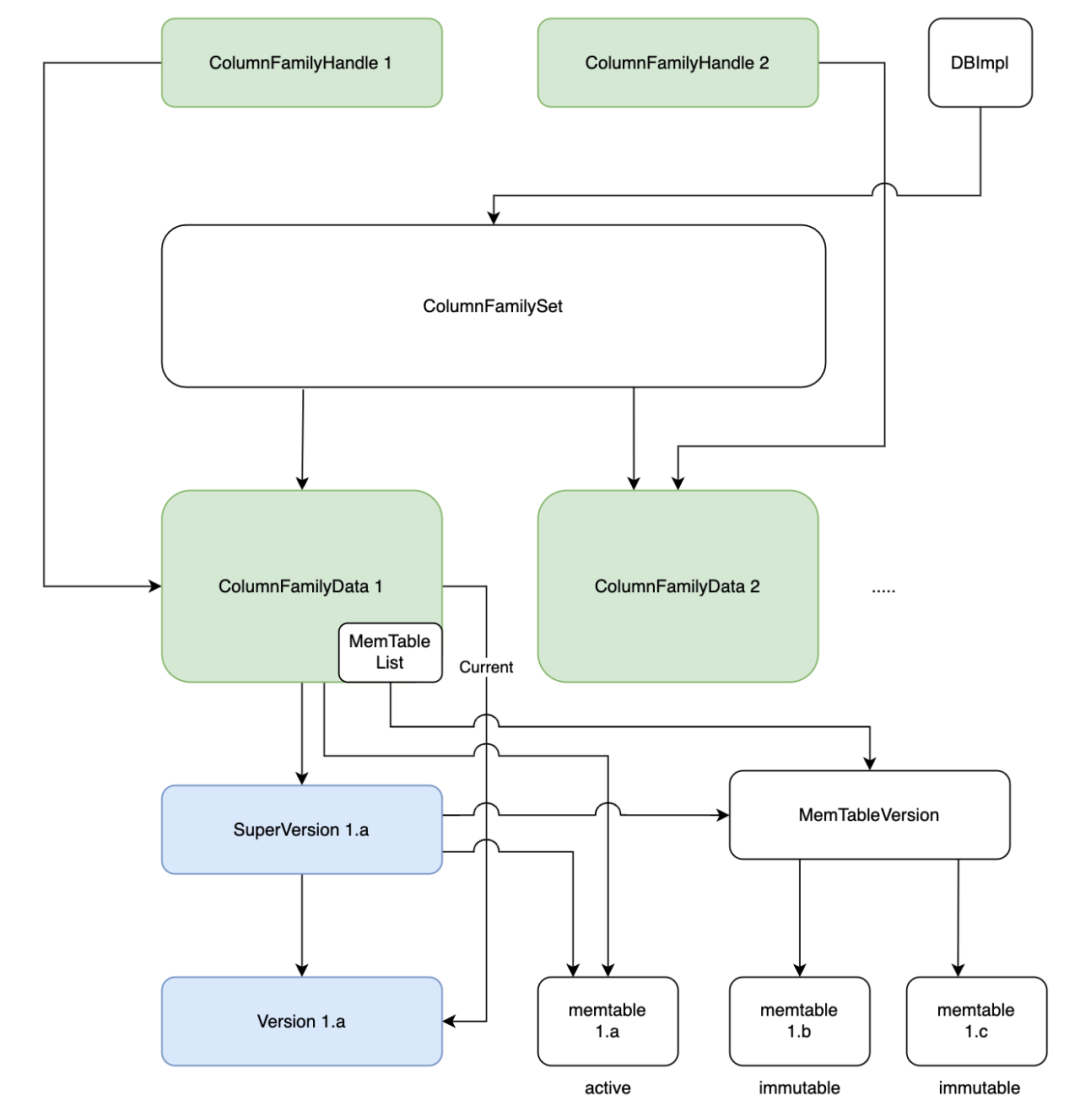
下圖為讀取過程中所經歷的一些資料物件:
-
列族指標ColumnFamilyHandle指向了列族物件ColumnFamily,列族物件中存放有列族相關的資料:ColumnFamilyData。
-
ColumnFamilyData 中關鍵的資料為 SuperVersion,SuperVersion 為當前最新版本的資料集,內部維護了記憶體的memtable和immutable memtable的指標以及磁碟資料的指標。
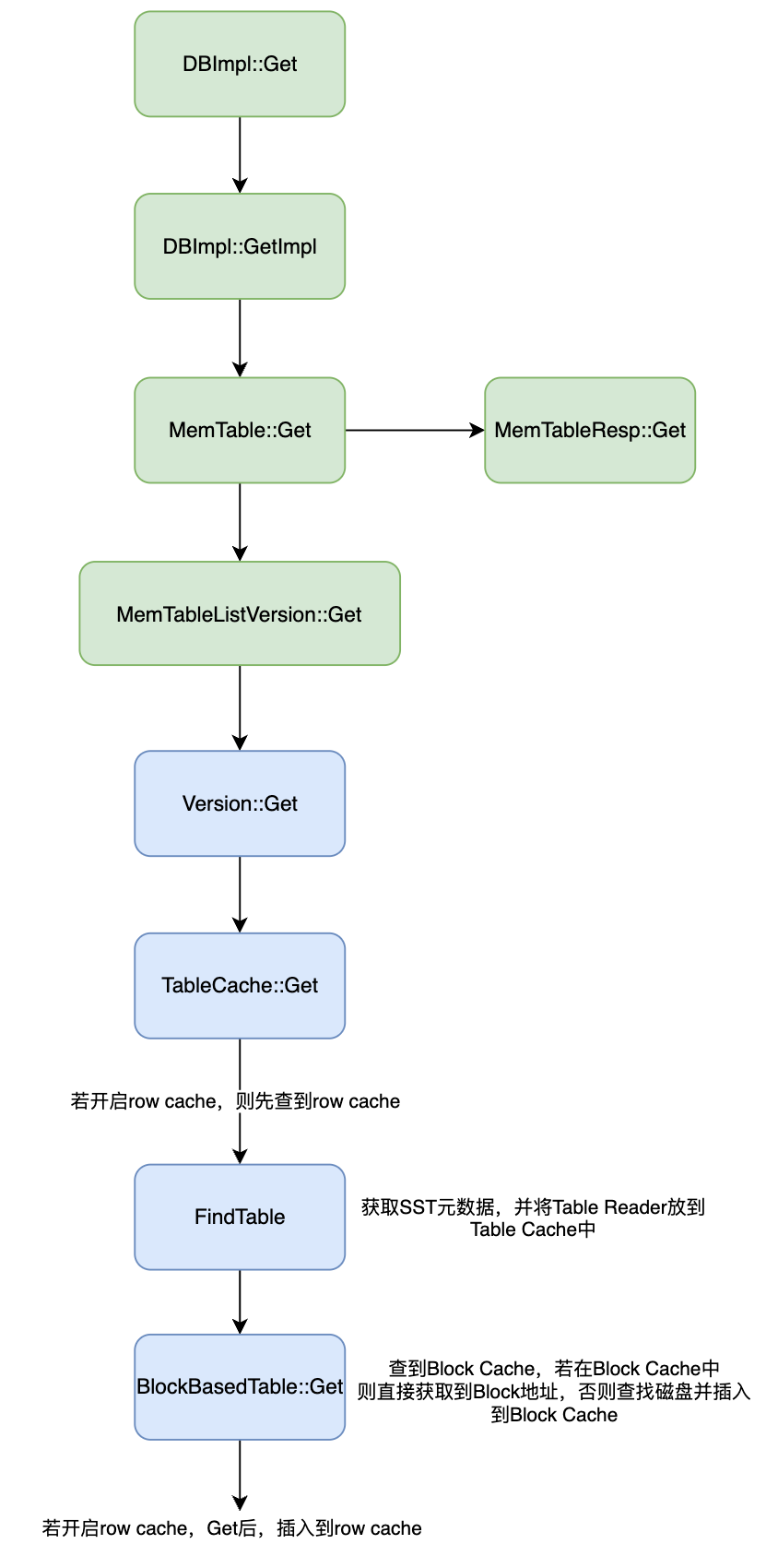
讀取細節如下圖所示:
-
資料讀取的入口為DBImpl的Get方法,通過該入口,先在記憶體中的MemTable進行遍歷。圖中的MemTableResp為MemTable的具體實現。
-
當在MemTable中沒有讀取到資料時,便會到MemTableListVersion中進行讀取,MemTableListVersion 內部存放著多個 immutable memtable。
-
當記憶體中讀取不到資料時,便會到磁碟中讀取,也就是Version類。Version中FilePicker逐層讀取檔案,每次讀取到檔案時,先檢視TableCache,TableCache維護了SST讀取器的資訊,方便快速查詢。
-
如果在TableCache中沒找到相關的資訊,便會執行FindTable,並將讀取到讀取器放入到TableCache中,方便下次查詢。
-
最後,通過讀取器對SST進行遍歷查詢。
2.5 小結
RocksDB 通過在寫入資料時先存入記憶體來保證寫入高效能,記憶體寫滿後便會將記憶體的資料轉移到磁碟,寫入磁碟時保持 key 有序來提升磁碟查詢的效率(類似於二分查詢),並且對磁碟中的資料進行分層,熱點資料所在的層級越低,冷資料儲存的層級越高。
三、業務場景介紹
簡單瞭解了 RocksDB 後,來看下具體的一些業務實踐場景。
目前,registerId 與 clientId 的對映數量約為數百億,每個應用為每個使用者分配一個 registerId,但每個使用者只有一個 clientId,因此,registerId 到 clientId 的對映是多對一的關係。這些資料都儲存在RocksDB中。
為了做到服務的高並行、高可用,每個應用的快取以多副本的形式分散在多臺 MT 伺服器中,形成多對多的關係。例如,MT1、MT2 和 MT3 中均快取了app1的全量資料,app2 的全量資料則存放於 MT2 和 MT4 中,如下圖所示:
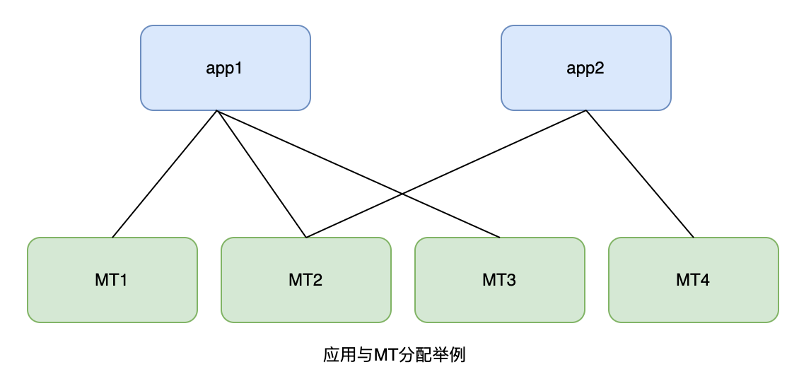
訊息推播時,MT的上游服務會根據推播請求內的appId定址到MT伺服器完成對映的轉換。
此時,讀者可能會想到,不少系統使用 Redis 作為快取服務,它似乎也可以完成這樣的任務,為什麼還需要開發一個專門的對映服務?
實際上,主要有以下幾個原因:
-
成本問題:作為一種磁碟鍵值(KV)儲存引擎,RocksDB 相比 Redis 更具有成本優勢,可以有效降低儲存成本。
-
容災問題:Redis 更傾向於集中儲存,如果 Redis 出現故障,就會導致訊息推播失敗,嚴重影響系統可用性。相反,使用分散式對映服務則可以在多臺機器上部署資料,即使某些 MT 服務崩潰,也不會影響整個系統的訊息推播。每個應用至少分配三個快取分片,即使其中一個分片出現問題,仍有另外兩個分片在支撐,容錯率更高。
-
MT自定義能力更強,面對多變的業務需求,可以快速滿足。
3.1 業務場景一:RocksDB列族的使用
瞭解了業務場景之後,可以來看一些 MT 中 RocksDB 實踐案例。
RocksDB 中列族的設計貫穿了始終,列族可以簡單理解為將資料進行分組,MT業務上將一個應用的資料歸類到一個列族中,方便管理,也方便對某個應用的快取進行一些特殊的操作,比如拷貝應用快取等。
在使用者沒有指定列族時,RocksDB 預設使用的是 default 列族。而指定了列族之後,只會在對應列族的資料物件中進行讀寫操作。
(1) 初始化以及列族建立
首先,在使用列族之前,需要在 RocksDB 初始化時進行一些列族的設定,以下是 RocksDB 初始化時的範例程式碼:
#include "rocksdb/db.h"
#include "rocksdb/slice.h"
#include "rocksdb/options.h"
#include "rocksdb/utilities/checkpoint.h"
#include "rocksdb/metadata.h"
#include "rocksdb/cache.h"
#include "rocksdb/table.h"
#include "rocksdb/slice_transform.h"
#include "rocksdb/filter_policy.h"
#include <fstream>
using namespace rocksdb;
int32_t RocksDBCache::init(){
DB *db; // RocskDB 指標
std::string m_dbPath = "/rocksdb"; // RocksDB 資料夾位置
Options options; // 初始化設定
// 設定一些設定項,RocksDB設定細分較多,此處不一一列舉
options.IncreaseParallelism();
options.OptimizeLevelStyleCompaction();
// ...
// 列族的相關設定
options.create_missing_column_families = true;
// 獲取當前目錄下已有的列族
std::vector <std::string> column_families_list;
DB::ListColumnFamilies(options, m_dbPath, &column_families_list);
// 「default」列族是必須要提供的
if (column_families_list.empty()) {
column_families_list.push_back("default");
}
// open DB with column_families
std::vector <ColumnFamilyDescriptor> column_families;
for (auto cfName : column_families_list) {
column_families.push_back(
ColumnFamilyDescriptor(cfName, ColumnFamilyOptions()));
}
// 列族指標列表,建立 RocksDB 範例時會將現有的列族指標傳入
std::vector < ColumnFamilyHandle * > handles;
s = DB::Open(options, m_dbPath, column_families, &handles, &db);
// 如果列族指標列表
if (column_families_list.size() != handles.size()) {
return FAILURE;
}
// 提供一個私有屬性Map,記錄獲取到列族指標,方便後續使用
for (unsigned int i = 0; i < column_families_list.size(); i++) {
handleMap[column_families_list[i]] = handles[i];
}
return SUCCESS;
}初始化完成後,也可以建立列族,範例程式碼如下,主要使用了CreateColumnFamily 介面:
int32_t RocksDBCache::createCF(const std::string &cfName) {
// 初始化需要賦值為nullptr,否則出現野指標在rocksdb內會因為assert不通過直接殺掉程式
ColumnFamilyHandle *cf = nullptr;
Status s;
if(handleMap.find(cfName) != handleMap.end()) {
// 列族已經存在
return FAILURE;
}
// 建立列族
s = db->CreateColumnFamily(ColumnFamilyOptions(), cfName, &cf);
if (!s.ok()) {
return FAILURE;
}
// 寫入Map,方便使用
handleMap[cfName] = cf;
return SUCCESS;
}(2) 讀、寫以及批次寫入
初始化完 RocksDB 範例後,可以進行讀寫等操作。
讀操作範例程式碼:
int32_t RocksDBCache::get(const std::string &cf, const std::string &key,
std::string &value){
// cf為列族名稱,通過名稱來獲取到列族指標
auto it = handleMap.find(cf);
if (it == handleMap.end()) {
return FAILURE;
}
std::string value = "";
// 根據列族、key來獲取到相應的資料,並將資料賦值給value,以引數的形式返回
Status s = db->Get(ReadOptions(), it->second, key, &value);
if (s.ok()) {
return SUCCESS;
} else if (!s.IsNotFound()) {
// 除了「未找到key」之外的錯誤
return FAILURE;
}
return FAILURE;
}寫操作範例程式碼:
int32_t RocksDBCache::get(const std::string &cf, const std::string &key,
const std::string &value){
Status s;
// 通過cf列族名稱獲取到對應的列族指標
auto it = handleMap.find(cf);
if (it == handleMap.end()) {
return FAILURE;
}
// 通過列族指標、key、value,將資料寫入DB
rocksdb::WriteOptions options = rocksdb::WriteOptions();
s = db->Put(options, handleMap[cf], key, value);
if (s.ok()) {
return SUCCESS;
} else {
return FAILURE;
}
return FAILURE;
}此外,還可以使用批次寫入的能力來加快寫入的速度:
int32_t RocksDBCache::writeBatch(const std::string &cfName, const std::string& file) {
if(handleMap.find(cfName) == handleMap.end()) {
// 列族不存在,寫入失敗
return FAILURE;
}
rocksdb::WriteBatch batch;
int32_t count = 0;
ColumnFamilyHandle * handle = handleMap[cfName];
while (std::getline(file, line)) { // 逐行讀取資料流
vector <string> infoVec = tars::TC_Common::sepstr<string>(line, ",");
// 根據內容構造key與value
std::string key = buildCacheKey(infoVec);
std::string value = buildCacheValue(infoVec);
batch.Put(handle, key, value);
count++;
// 每批次寫入1000個kv
if (count >= 1000) {
db->Write(rocksdb::WriteOptions(), &batch);
batch.Clear();
count = 0;
}
}
db->Write(rocksdb::WriteOptions(), &batch);
return SUCCESS;
}3.2 業務場景二:RocksDB快照的使用
上述場景中,講到了一些RocksDB的基礎用法,也是一些比較常規的用法。而該場景妙用了快照能力來實現了伺服器間資料的備份。
最初,使用者資料載入到MT RocksDB 的方式為:通過 SQL 批次進行拉取。每批拉取數十萬條資料,但隨著資料量的不斷增加,快取載入速度變得越來越慢。例如,載入數億級使用者的資料資訊需要 3-4 天。
每逢大型促銷活動,如雙十一、雙十二、618 等,許多應用需要提高訊息推播速度。此時 MT 服務便需要擴充套件副本,而每次擴充套件都需要耗費大量時間和人力成本。
為此,考慮使用複製的方式直接拷貝已有 MT 伺服器中的 RocksDB 檔案,並將其作為快取的副本。以下是一個例子:
假如有一臺新的MT伺服器需要加入到叢集中,這臺新的MT伺服器需要載入app1與app2的使用者資料。如下圖所示:
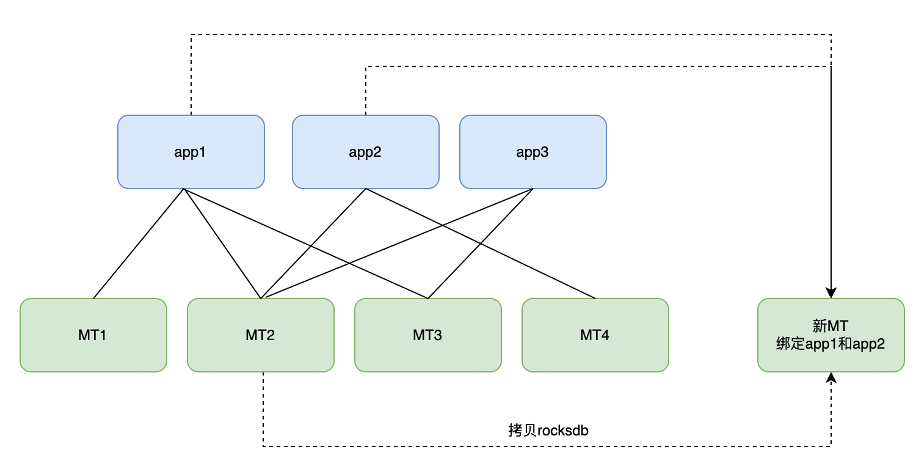
其中MT2機器中快取有app1和app2,所以直接使用 rsync/scp 命令將 MT2 的 RocksDB 資料夾拷貝到新的MT機器中。
rsync 和 scp 都是 Linux/Unix 作業系統中常用的檔案傳輸工具,但是它們在原理、功能和使用場景等方面有很大的不同。
(1)原理
scp 採用的是 SSH 協定進行加密並傳輸資料,資料傳輸過程中都經過了加密,保證了資料安全性。而 rsync 採用了類似於增量備份的方式,在本地和遠端對比檔案的變化,只傳輸發生變化的部分,從而實現檔案資料的同步更新。
(2)功能
rsync 的功能比 scp 更加強大,rsync 不僅可以做到多臺伺服器檔案之間的同步和遷移,還能保持整個檔案系統的一致性,支援檔案許可權、硬連線等資訊的同步。而 scp 只能將本地檔案傳輸到遠端伺服器,或者將遠端伺服器的檔案傳輸到本地,保持檔案本身的特性不變,不能保證系統的一致性。
(3)使用場景
scp 適合小檔案傳輸(少量資料或檔案),例如組態檔、程式碼等檔案傳輸,速度快,方便易用,支援跨平臺操作。rsync 適合大量資料或檔案的同步和傳輸,例如在資料中心的大量資料備份、同步和遷移等應用場景。
總的來說,scp 是傳統的檔案複製命令,使用簡單,適合小檔案傳輸,而 rsync 是專門針對同步和遷移等大量資料和大量檔案的非同步傳輸工具,優點是高效、安全、節省頻寬和磁碟空間等特殊用途。因此,在實際應用中,應選擇合適數量、合適的檔案傳輸工具來滿足不同的需求。
拷貝完成後,新的MT服務啟動後便能直接提供服務。這個方案遠比原有 SQL 方案要快不少,一般在1-2小時內便可以完成。
但是也存在一些問題,MT2伺服器中還快取有app3的資料,而app3並不是新MT伺服器想要快取的應用,這便導致了新MT伺服器中RocksDB中存在一些無用資料,浪費了磁碟空間,也加深了sst檔案的層級深度,拖慢了資料讀取的速度。
因此,便考慮是否可以只拷貝 RocksDB 中的部分sst檔案,而列族可以滿足這個需求。
列族可以簡單理解為將資料進行分組,業務上將一個應用的資料歸類到一個列族中。這樣做的好處在於,在匯出RocksDB檔案時,可以針對單個列族生成快照檔案,然後將該快照檔案匯出到新機器上,便可以解決上述提到的問題。
原先 RocksDB 中設計該快照功能主要是用於同一臺機器中的資料備份,但稍加改造便可以實現跨伺服器備份。
這個快照檔案是一個硬連結,連結到了真實的sst檔案中。如下圖所示,該資料夾內便是生成的快照檔案,其與真實的sst別無二致:
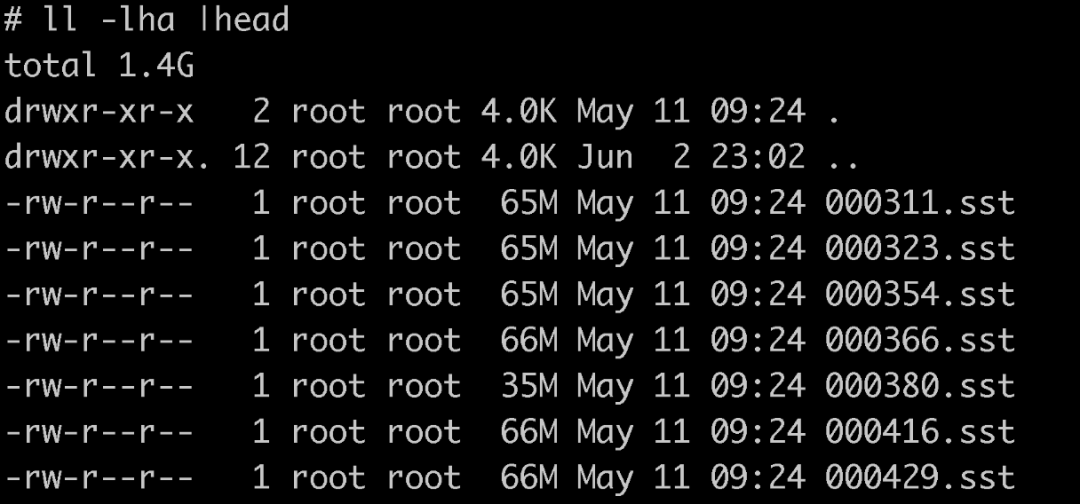
這個快照檔案中,只包含了某個應用的資料。下文中,會闡述如何生成快照,並將這類快照檔案匯入到新機器的 RocksDB 資料夾中使用。
程式碼實現
(1)首先,是生成快照的介面,關鍵方法是 ExportColumnFamily ,此介面將會根據現有的app資料生成該列族的快照檔案,範例程式碼如下:
void RocksDBCache::createCfSnapshot(const std::string &cfName){
if(handleMap.find(cfName) == handleMap.end()) {
// 列族不存在,寫入失敗
return FAILURE;
}
// 上游初始化好的ColumnFamilyHandle指標
ColumnFamilyHandle* app_cf_handle = handleMap[cfName]; // 應用列族對應的指標
// 生成快照檔案的目錄地址
std::string export_files_dir_ = "/rocksdb_app_snapshot";
// 生成快照後會有一個meta後設資料指標,該指標指向的物件中儲存了快照檔案的內容和資訊
ExportImportFilesMetaData* metadata_ptr_ = nullptr;
// 初始化CheckPoint範例,所有的快照都需要經過CheckPoint來生成
Checkpoint* checkpoint;
Checkpoint::Create(db, &checkpoint);
// 生成app的資料快照
checkpoint->ExportColumnFamily(app_cf_handle, export_files_dir_, &metadata_ptr_);
// 由於在新機器匯入快照檔案時需要meta後設資料,但RocksDB中沒有提供meta後設資料的序列化方法
// 所以自行補充了序列化方法。將meta後設資料序列化後寫入到json文字中,方便在不同的機器中傳輸
std::string jsonMetaInfo;
metaToJson(metaData, jsonMetaInfo); // 將meta轉換成json
ofstream ofs;
ofs.open(export_files_dir_ + "/meta.json", ios::out);
if (ofs.is_open()) {
// 將json 後設資料寫入到文字檔案中
ofs << jsonMetaInfo << endl;
ofs.close();
}}序列化方法的具體實現:
// 傳入後設資料指標,json字串通過jsonRes引數返回
void RocksDBCache::metaToJson(ExportImportFilesMetaData *meta, std::string &jsonRes) {
Json::Value record;
record[std::string("db_comparator_name")] = meta->db_comparator_name;
Json::Value arrayFileInfos;
for (size_t j = 0; j < meta->files.size(); j++) {
Json::Value fileInfo;
auto &file = meta->files[j];
fileInfo[string("column_family_name")] = file.column_family_name;
// ...將欄位寫入到file中
arrayFileInfos.append(fileInfo);
}
record[string("files")] = arrayFileInfos;
Json::StyledWriter sw;
jsonRes = sw.write(record);
return;
}
// 傳入json檔案,解析出後設資料並寫入到meta物件中
void RocksDBCache::jsonToMeta(ifstream &payload, ExportImportFilesMetaData& meta) {
Json::Value metaData;
Json::Reader reader;
try{
bool parseResult = reader.parse(payload, metaData);
if(!parseResult) {
cout << "jsonToMeta parse error" << endl;
return;
}
std::vector<LiveFileMetaData> files;
meta.db_comparator_name = metaData[string("db_comparator_name")].asString();
for(unsigned int i = 0; i < metaData[string("files")].size(); i ++) {
const Json::Value& fileInfo = metaData[string("files")][i];
LiveFileMetaData fileMetaData;
fileMetaData.column_family_name = fileInfo["column_family_name"].asString();
// ...欄位賦值
files.push_back(fileMetaData);
}
meta.files = files;
} catch (const std::exception& e) {
cout << "jsonToMeta parse error: " << e.what() << endl;
}
}(2)生成好某個應用的快照檔案後,便可通過 rsync/scp 傳輸檔案。
(3)傳輸完成後,在新的MT伺服器中,可以通過CreateColumnFamilyWithImport 方法來將快照檔案引入到現有的RocksDB中,範例demo如下:
// path為拷貝過來的快照目錄,cfName為準
int32_t RocksDBCache::importSnapshot(const std::string &cfName, const std::string &path){
if(handleMap.find(cfName) != handleMap.end()) {
// 列族存在,匯入失敗
return FAILURE;
}
ColumnFamilyHandle* app_cf_handle; // 應用列族對應的指標
// 後設資料物件
ExportImportFilesMetaData meta;
// 通過拷貝過來的後設資料json,生成後設資料物件meta
std::string metaJsonPath = path + "/meta.json";
ifstream fin(metaJsonPath, ios::binary);
if(!fin.is_open()) {
return FAILURE;
}
ExportImportFilesMetaData meta;
jsonToMeta(fin, meta);
fin.close();
// 將快照檔案匯入rocksdb中
db->CreateColumnFamilyWithImport(ColumnFamilyOptions(), cfName,
ImportColumnFamilyOptions(),
meta, &app_cf_handle);
}RocksDB官方檔案中的範例demo>> 點選檢視
通過上述的方法,擴容一臺新的MT伺服器流程變為如下,以新MT載入app1和app2的快取為例:
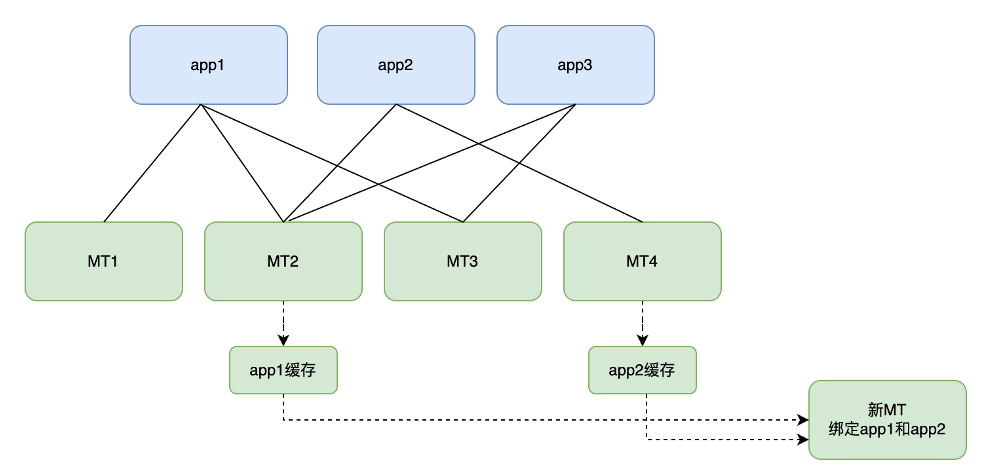
- 從MT2中匯出app1的快取快照、從MT4中匯出app2的快取快照。
-
分別從MT2和MT4中拷貝生成的快照檔案到新的MT伺服器中。
-
通過介面的方式,觸發新的MT伺服器載入app1和app2的快照到RocksDB中。
-
新的MT伺服器擴容完成,對外提供服務。
四、總結
本文從介紹 RocksDB 的設計和特性入手,結合訊息推播系統的業務場景,對 RocksDB 在分散式高可用儲存方面的優勢和應用進行了闡述,並探討了如何使用 RocksDB 來優化訊息推播系統的效能和效率。
作為一種高效能的嵌入式 KeyValue 儲存引擎,RocksDB 具有多樣的特性和優點,如支援記憶體表和檔案儲存引擎、支援多維度資料分割區和多層次儲存模型、支援高並行和快速寫入等。在訊息推播系統中,RocksDB 可以有效地儲存分散式實時資料,並支援高吞吐量。同時,文章還介紹了一些訊息推播場景下的 RocksDB 應用案例,如如何利用快照功能實現跨伺服器備份、如何充分利用 RocksDB 的快速寫入和高並行特性等。
本文的價值在於,通過對 RocksDB 的介紹和實際應用案例的分析,對讀者產生一些啟示性和實用性價值。讀者可以從中瞭解 RocksDB 的基本特性和使用方法,如何應對高並行、高可用常見的分散式系統問題,同時,也可以瞭解到基於RocksDB的有狀態服務中,快速擴容的可行方案。
同時,需要注意的是,RocksDB 作為一種嵌入式的儲存引擎,在侷限性和短板方面可能存在一些挑戰,例如資料模型和資料結構的適用性等。針對這些問題,需要讀者自行進行一些額外的適配,並調整 RocksDB 的設定引數等,來改善 RocksDB 的效能和適用性。
參考文獻: