Java開發者的Python快速進修指南:實戰之跳錶pro版本
之前我們講解了簡易版的跳錶,我希望你能親自動手實現一個更完善的跳錶,同時也可以嘗試實現其他資料結構,例如動態陣列或雜湊表等。通過實踐,我們能夠發現自己在哪些方面還有所欠缺。這些方法只有在熟練掌握之後才會真正理解,就像我在編寫程式碼的過程中,難免會忘記一些方法或如何宣告屬性等等。
我不太願意寫一些業務邏輯,例如典型的購物車邏輯,因為這對個人的成長沒有太大幫助,反而可能使我們陷入業務誤區。但是,資料結構與演演算法則不同。好了,言歸正傳,現在我們來看看如何對之前的簡易版跳錶進行優化。
關於跳錶的解釋我就不再贅述了。在上一篇中,我們只定義了一個固定步長為2的跳錶,使節點可以進行跳躍查詢,而不是遍歷節點查詢。然而,真正的跳錶有許多跳躍步長的選擇,並不僅限於單一的步長。因此,今天我們將實現多個跳躍步長的功能,先從簡單的開始練習,例如增加一個固定的跳躍步長4。
如果一個節點具有多個跳躍步長,我們就不能直接用單獨的索引節點來表示了,而是需要使用列表來儲存。否則,我們將不得不為每個步長定義一個索引節點。因此,我修改了節點的資料結構如下:
class SkipNode:
def __init__(self,value,before_node=None,next_node=None,index_node=None):
self.value = value
self.before_node = before_node
self.next_node = next_node
# 這是一個三元表示式
self.index_node = index_node if index_node is not None else []
在這個優化過程中,我們使用了一個三元表示式。在Python中,沒有像Java語言中的三元運運算元(?:)那樣的寫法。不過,我們可以換一種寫法:[值1] if [條件] else [值2],這與 [條件] ? [值1] : [值2] 是等價的。
我們不需要對插入資料的邏輯實現進行修改。唯一的區別在於我們將重新建立索引的方法名更改為re_index_pro。為了節省大家查閱歷史文章的時間,我也直接將方法貼在下面。
def insert_node(node):
if head.next_node is None:
head.next_node = node
node.next_node = tail
node.before_node = head
tail.before_node = node
return
temp = head.next_node
# 當遍歷到尾節點時,需要直接插入
while temp.next_node is not None or temp == tail:
if temp.value > node.value or temp == tail:
before = temp.before_node
before.next_node = node
temp.before_node = node
node.before_node = before
node.next_node = temp
break
temp = temp.next_node
re_index_pro()
為了提高效能,我們需要對索引進行升級和重新規劃。具體操作包括刪除之前已規劃的索引,並新增索引步長為2和4。
def re_index_pro():
step = 2
second_step = 4
# 用來建立步長為2的索引的節點
index_temp_for_one = head.next_node
# 用來建立步長為4的索引的節點
index_temp_for_second = head.next_node
# 用來遍歷的節點
temp = head.next_node
while temp.next_node is not None:
temp.index_node = []
if step == 0:
step = 2
index_temp_for_one.index_node.append(temp)
index_temp_for_one = temp
if second_step == 0:
second_step = 4
index_temp_for_second.index_node.append(temp)
index_temp_for_second = temp
temp = temp.next_node
step -= 1
second_step -= 1
我們需要對查詢方法進行優化,雖然不需要做大的改動,但由於我們的索引節點已更改為列表儲存,因此需要從列表中獲取值,而不僅僅是從節點獲取。在從列表中獲取值的過程中,你會發現列表可能有多個節點,但我們肯定先要獲取最大步長的節點。如果確定步長太大,我們可以縮小步長,如果仍然無法滿足要求,則需要遍歷節點。
def search_node(value):
temp = head.next_node
# 由於我們有了多個索引節點,所以我們需要知道跨步是否長了,如果長了需要縮短步長,也就是尋找低索引的節點。index_node[1] --> index_node[0]
step = 0
while temp.next_node is not None:
step += 1
if value == temp.value:
print(f"該值已找到,經歷了{step}次查詢")
return
elif value < temp.value:
print(f"該值在列表不存在,經歷了{step}次查詢")
return
if temp.index_node:
for index in range(len(temp.index_node) - 1, -1, -1):
if value > temp.index_node[index].value:
temp = temp.index_node[index]
break
else:
temp = temp.next_node
else:
temp = temp.next_node
print(f"該值在列表不存在,經歷了{step}次查詢")
為了使大家更容易檢視資料和索引的情況,我對節點遍歷的方法進行了修改,具體如下所示:
def print_node():
my_list = []
temp = head.next_node
while temp.next_node is not None:
if temp.index_node:
my_dict = {"current_value": temp.value, "index_value": [node.value for node in temp.index_node]}
else:
my_dict = {"current_value": temp.value, "index_value": temp.index_node} # 設定一個預設值為None
my_list.append(my_dict)
temp = temp.next_node
for item in my_list:
print(item)
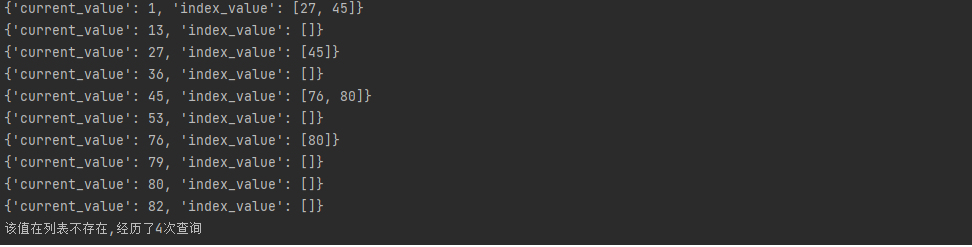
為了進一步優化查詢結果,我們可以簡單地執行一下,通過圖片來觀察優化的效果。從結果可以看出,我們確實減少了兩次查詢的結果,這是一個很好的進展。然而,實際的跳錶結構肯定比我簡化的要複雜得多。例如,步長可能不是固定的,因此我們需要進一步優化。
由於我們已經將索引節點改為列表儲存,所以我們能夠進行一些較大的修改的地方就是重建索引的方法。
為了實現動態設定步長,我需要獲取當前列表的長度。為此,我在檔案中定義了一個名為total_size的變數,並將其初始值設定為0。在插入操作時,我會相應地對total_size進行修改。由於多餘的程式碼較多,我不會在此貼上。
def insert_node(node):
global total_size
total_size += 1
if head.next_node is None:
# 此處省略重複程式碼。
在這個方法中,我們使用了一個global total_size,這樣定義的原因是因為如果我們想要在函數內部修改全域性變數,就必須這樣寫。希望你能記住這個規則,不需要太多的解釋。Python沒有像Java那樣的限定符。
def re_index_fin():
# 使用字典模式儲存住step與前一個索引的關係。
temp_size = total_size
dict = {}
dict_list = []
# 這裡最主要的是要將字典的key值與節點做繫結,要不然當設定索引值時,每個源節點都不一樣。
while int((temp_size / 2)) > 1:
temp_size = int((temp_size / 2))
key_str = f"step_{temp_size}"
# 我是通過key_str繫結了temp_size步長,這樣當這個步長被減到0時,步長恢復到舊值時,我能找到之前的元素即可。
dict[key_str] = head.next_node
dict_list.append(temp_size)
# 備份一下,因為在步長減到0時需要恢復到舊值
backup = list(dict_list)
# 用來遍歷的節點
temp = head.next_node
while temp.next_node is not None:
temp.index_node = []
# 直接遍歷有幾個步長
for i in range(len(dict_list)):
dict_list[i] -= 1 # 每個元素減一
if dict_list[i] == 0:
dict_list[i] = backup[i] # 恢復舊值
# 找到之前的源節點,我要進行設定索引節點了
temp_index = f"step_{backup[i]}"
temp_index_node = dict[temp_index]
temp_index_node.index_node.append(temp)
dict[temp_index] = temp # 更換要設定的源節點
temp = temp.next_node
這裡有很多回圈,其實我想將步長和節點繫結到一起,以優化效能。如果你願意,可以嘗試優化一下,畢竟這只是跳錶的最初版本。讓我們來演示一下,看看優化的效果如何。最終結果如下,其實還是可以的。我大概試了一下,如果資料分佈不太好的話,很可能需要進行多達6次的查詢才能找到結果。

總結
我們實現的跳錶有許多優化的方面需要考慮。例如,我們可以避免每次都重新規劃索引,因為這是不必要的。另外,我們也可以探索不同的步長繫結方法,不一定要按照我目前的方式進行。今天先說到這裡,因為我認為跳錶的實現邏輯相當複雜。我們可以在跳錶這個領域暫時告一段落。