【scikit-learn基礎】--『資料載入』之樣本生成器
除了內建的資料集,scikit-learn還提供了隨機樣本的生成器。
通過這些生成器函數,可以生成具有特定特性和分佈的亂資料集,以幫助進行機器學習演演算法的研究、測試和比較。
目前,scikit-learn庫(v1.3.0版)中有20個不同的生成樣本的函數。
本篇重點介紹其中幾個具有代表性的函數。
1. 分類聚類資料樣本
分類和聚類是機器學習中使用頻率最高的演演算法,建立各種相關的樣本資料,能夠幫助我們更好的試驗演演算法。
1.1. make_blobs
這個函數通常用於視覺化分類器的學習過程,它生成由聚類組成的非線性資料集。
import matplotlib.pyplot as plt
from sklearn.datasets import make_blobs
X, Y = make_blobs(n_samples=1000, centers=5)
plt.scatter(X[:, 0], X[:, 1], marker="o", c=Y, s=25)
plt.show()
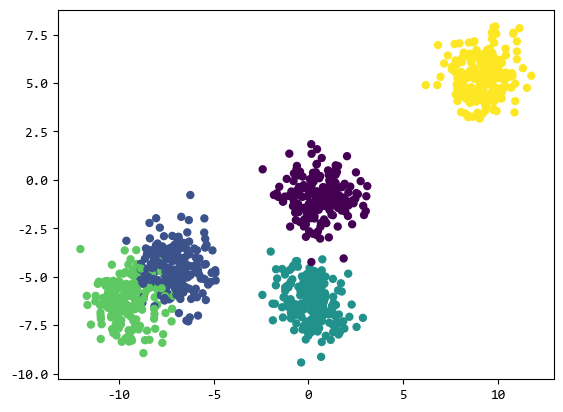
上面的範例生成了1000個點的資料,分為5個類別。
make_blobs的主要引數包括:
- n_samples:生成的樣本數。
- n_features:每個樣本的特徵數。通常為2,表示我們生成的是二維資料。
- centers:聚類的數量。即生成的樣本會被分為多少類。
- cluster_std:每個聚類的標準差。這決定了聚類的形狀和大小。
- shuffle:是否在生成資料後打亂樣本。
- random_state:亂數生成器的種子。這確保了每次執行程式碼時生成的資料集都是一樣的。
1.2. make_classification
這是一個用於生成複雜二維資料的函數,通常用於視覺化分類器的學習過程或者測試機器學習演演算法的效能。
import matplotlib.pyplot as plt
from sklearn.datasets import make_classification
X, Y = make_classification(n_samples=100, n_classes=4, n_clusters_per_class=1)
plt.scatter(X[:, 0], X[:, 1], marker="o", c=Y, s=25)
plt.show()
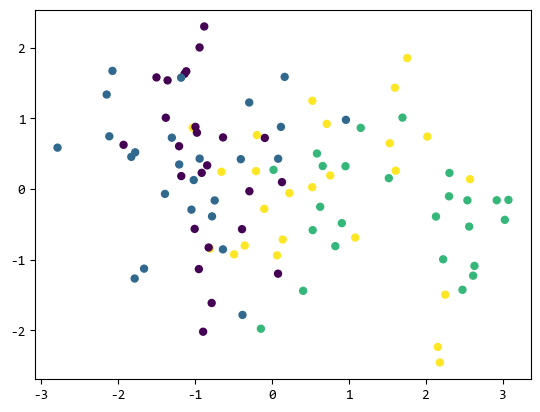
可以看出它生成的各類資料交織在一起,很難做線性的分類。
make_classification的主要引數包括:
- n_samples:生成的樣本數。
- n_features:每個樣本的特徵數。這個引數決定了生成的資料集的維度。
- n_informative:具有資訊量的特徵的數量。這個引數決定了特徵集中的特徵有多少是有助於分類的。
- n_redundant:冗餘特徵的數量。這個引數決定了特徵集中的特徵有多少是重複或者沒有資訊的。
- random_state:亂數生成器的種子。這確保了每次執行程式碼時生成的資料集都是一樣的。
1.3. make_moons
和函數名稱所表達的一樣,它是一個用於生成形狀類似於月牙的資料集的函數,通常用於視覺化分類器的學習過程或者測試機器學習演演算法的效能。
from sklearn.datasets import make_moons
fig, ax = plt.subplots(1, 3)
fig.set_size_inches(9, 3)
X, Y = make_moons(noise=0.01, n_samples=1000)
ax[0].scatter(X[:, 0], X[:, 1], marker="o", c=Y, s=25)
ax[0].set_title("noise=0.01")
X, Y = make_moons(noise=0.05, n_samples=1000)
ax[1].scatter(X[:, 0], X[:, 1], marker="o", c=Y, s=25)
ax[1].set_title("noise=0.05")
X, Y = make_moons(noise=0.5, n_samples=1000)
ax[2].scatter(X[:, 0], X[:, 1], marker="o", c=Y, s=25)
ax[2].set_title("noise=0.5")
plt.show()
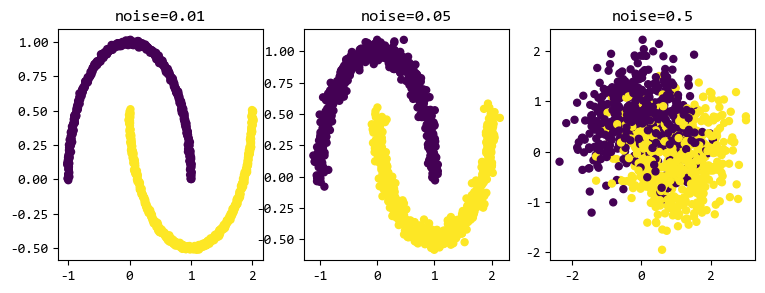
noise越小,資料的分類越明顯。
make_moons的主要引數包括:
- n_samples:生成的樣本數。
- noise:在資料集中新增的噪聲的標準差。這個引數決定了月牙的噪聲程度。
- random_state:亂數生成器的種子。這確保了每次執行程式碼時生成的資料集都是一樣的。
2. 迴歸資料樣本
除了分類和聚類,迴歸是機器學習的另一個重要方向。scikit-learn同樣也提供了建立迴歸資料樣本的函數。
from sklearn.datasets import make_regression
fig, ax = plt.subplots(1, 3)
fig.set_size_inches(9, 3)
X, y = make_regression(n_samples=100, n_features=1, noise=20)
ax[0].scatter(X[:, 0], y, marker="o")
ax[0].set_title("noise=20")
X, y = make_regression(n_samples=100, n_features=1, noise=10)
ax[1].scatter(X[:, 0], y, marker="o")
ax[1].set_title("noise=10")
X, y = make_regression(n_samples=100, n_features=1, noise=1)
ax[2].scatter(X[:, 0], y, marker="o")
ax[2].set_title("noise=1")
plt.show()
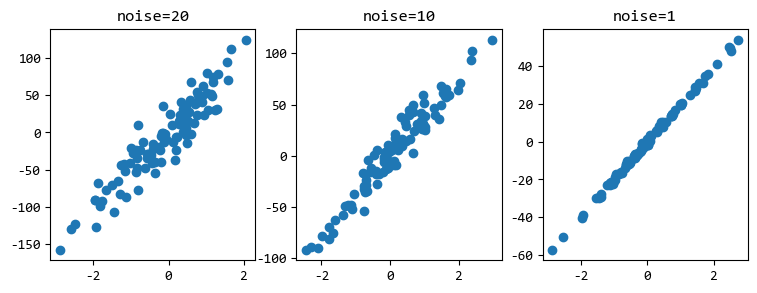
通過調節noise引數,可以建立不同精確度的迴歸資料。
make_regression的主要引數包括:
- n_samples:生成的樣本數。
- n_features:每個樣本的特徵數。通常為一個較小的值,表示我們生成的是一維資料。
- noise:噪音的大小。它為資料新增一些隨機噪聲,以使結果更接近現實情況。
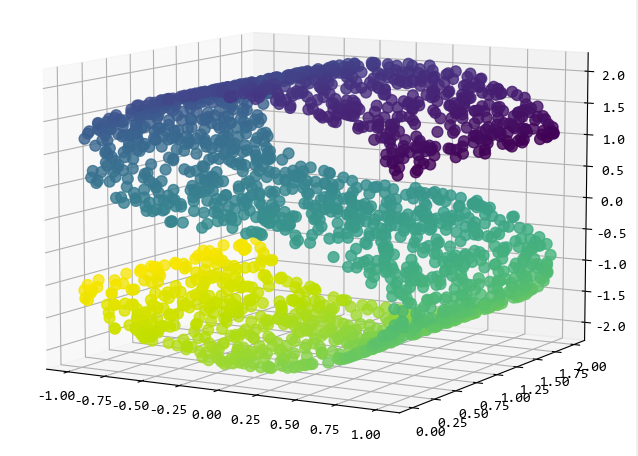
3. 流形資料樣本
所謂流形資料,就是S形或者瑞士捲那樣旋轉的資料,可以用來測試更復雜的分類模型的效果。
比如下面的make_s_curve函數,就可以建立S形的資料:
from sklearn.datasets import make_s_curve
X, Y = make_s_curve(n_samples=2000)
fig, ax = plt.subplots(subplot_kw={"projection": "3d"})
fig.set_size_inches((8, 8))
ax.scatter(X[:, 0], X[:, 1], X[:, 2], c=Y, s=60, alpha=0.8)
ax.view_init(azim=-60, elev=9)
plt.show()
4. 總結
本文介紹的生成樣本資料的函數只是scikit-learn庫中各種生成器的一部分,
還有很多種其他的生成器函數可以生成更加複雜的樣本資料。
所有的生成器函數請參考檔案:
https://scikit-learn.org/stable/modules/classes.html