深入解析LLaMA如何改進Transformer的底層結構
本文分享自華為雲社群《大語言模型底層架構你瞭解多少?LLM大底層架構之LLM模型結構介紹》,作者: 碼上開花_Lancer 。
大語言模型結構當前絕大多數大語言模型結構都採用了類似GPT 架構,使用基於Transformer 架構構造的僅由解碼器組成的網路結構,採用自迴歸的方式構建語言模型。但是在位置編碼、層歸一化位置以及啟用函數等細節上各有不同。上篇文章 介紹了GPT-3 模型的訓練過程,包括模型架構、訓練資料組成、訓練過程以及評估方法。
由於GPT-3 並沒有開放原始碼,根據論文直接重現整個訓練過程並不容易,因此根據GPT-3 的描述復現的過程,並構造開源了系統OPT(OpenPre-trained Transformer Language Models)。Meta AI 也仿照GPT-3 架構開源了LLaMA 模型,公開評測結果以及利用該模型進行有監督微調後的模型都有非常好的表現。由於自GPT-3 模型之後,OpenAI 就不再開源也沒有開源模型,因此並不清楚ChatGPT 和GPT-4 所採用的模型架構。
本篇文章將以LLaMA 模型為例,介紹大語言模型架構在Transformer 原始結構上的改進,並介紹Transformer 模型結構中空間和時間佔比最大的注意力機制優化方法。
一、 LLaMA 的模型結構
上篇文章有介紹了LLaMA 所採用的Transformer 結構和細節,與在本篇文章所介紹的Transformer架構不同的地方包括採用了前置層歸一化(Pre-normalization)並使用RMSNorm 歸一化函數(Normalizing Function)、啟用函數更換為SwiGLU,並使用了旋轉位置嵌入(RoP),整體Transformer架構與GPT-2 類似,如圖1.1所示。
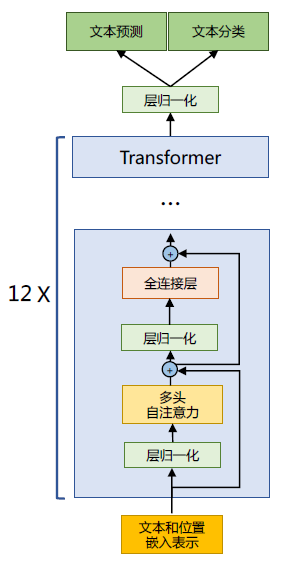
圖1.1 GPT-2 模型結構
接下來,將分別介紹RMSNorm 歸一化函數、SwiGLU 啟用函數和旋轉位置嵌入(RoPE)的具體內容和實現。
1.1. RMSNorm 歸一化函數
為了使得模型訓練過程更加穩定,GPT-2 相較於GPT 就引入了前置層歸一化方法,將第一個層歸一化移動到多頭自注意力層之前,第二個層歸一化也移動到了全連線層之前,同時殘差連線的位置也調整到了多頭自注意力層與全連線層之後。層歸一化中也採用了RMSNorm 歸一化函數。針對輸入向量aRMSNorm 函數計算公式如下:
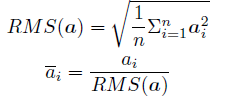
此外,RMSNorm 還可以引入可學習的縮放因子gi 和偏移引數bi,從而得到
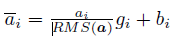
RMSNorm 在HuggingFace Transformer 庫中程式碼實現如下所示:
class LlamaRMSNorm(nn.Module): def __init__(self, hidden_size, eps=1e-6): """ LlamaRMSNorm is equivalent to T5LayerNorm """ super().__init__() self.weight = nn.Parameter(torch.ones(hidden_size)) self.variance_epsilon = eps # eps 防止取倒數之後分母為0 def forward(self, hidden_states): input_dtype = hidden_states.dtype variance = hidden_states.to(torch.float32).pow(2).mean(-1, keepdim=True) hidden_states = hidden_states * torch.rsqrt(variance + self.variance_epsilon) # weight 是末尾乘的可訓練引數, 即g_i return (self.weight * hidden_states).to(input_dtype)
1.2. SwiGLU 啟用函數
SwiGLU[50] 啟用函數是Shazeer 在文獻中提出,並在PaLM等模中進行了廣泛應用,並且取得了不錯的效果,相較於ReLU 函數在大部分評測中都有不少提升。在LLaMA 中全連線層使用帶有SwiGLU 啟用函數的FFN(Position-wise Feed-Forward Network)的計算公式如下:
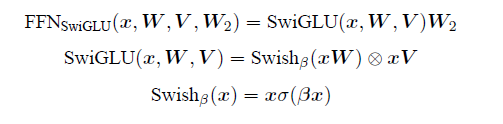
其中,σ(x) 是Sigmoid 函數。圖1.2給出了Swish 啟用函數在引數β 不同取值下的形狀。可以看到當β 趨近於0 時,Swish 函數趨近於線性函數y = x,當β 趨近於無窮大時,Swish 函數趨近於ReLU 函數,β 取值為1 時,Swish 函數是光滑且非單調。在HuggingFace 的Transformer 庫中Swish1 函數使用silu 函數 代替。
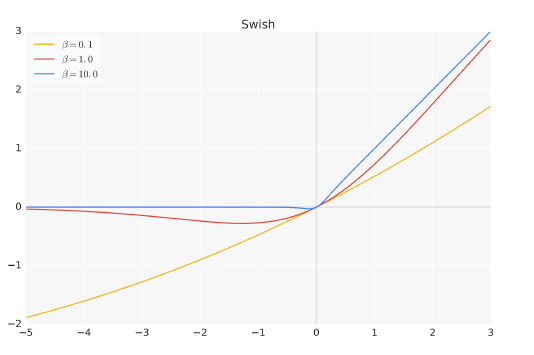
圖1.2 Swish 啟用函數在引數β 不同取值下的形狀
1.3. 旋轉位置嵌入(RoPE)
在位置編碼上,使用旋轉位置嵌入(Rotary Positional Embeddings,RoPE)[52] 代替原有的絕對位置編碼。RoPE 藉助了複數的思想,出發點是通過絕對位置編碼的方式實現相對位置編碼。其目標是通過下述運算來給q,k 新增絕對位置資訊:

經過上述操作後, ˜qm 和˜kn 就帶有位置m 和n 的絕對位置資訊。
最終可以得到二維情況下用複數表示的RoPE:

根據複數乘法的幾何意義,上述變換實際上是對應向量旋轉,所以位置向量稱為「旋轉式位置編碼」。還可以使用矩陣形式表示:

根據內積滿足線性疊加的性質,任意偶數維的RoPE,都可以表示為二維情形的拼接,即:
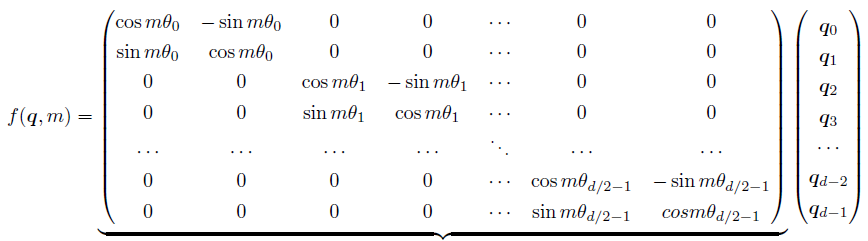
由於上述矩陣Rn 具有稀疏性,因此可以使用逐位相乘⊗ 操作進一步加快計算速度。RoPE 在HuggingFace Transformer 庫中程式碼實現如下所示:
class LlamaRotaryEmbedding(torch.nn.Module): def __init__(self, dim, max_position_embeddings=2048, base=10000, device=None): super().__init__() inv_freq = 1.0 / (base ** (torch.arange(0, dim, 2).float().to(device) / dim)) self.register_buffer("inv_freq", inv_freq) # Build here to make `torch.jit.trace` work. self.max_seq_len_cached = max_position_embeddings t = torch.arange(self.max_seq_len_cached, device=self.inv_freq.device, dtype=self.inv_freq.dtype) freqs = torch.einsum("i,j->ij", t, self.inv_freq) # Different from paper, but it uses a different permutation # in order to obtain the same calculation emb = torch.cat((freqs, freqs), dim=-1) dtype = torch.get_default_dtype() self.register_buffer("cos_cached", emb.cos()[None, None, :, :].to(dtype), persistent=False) self.register_buffer("sin_cached", emb.sin()[None, None, :, :].to(dtype), persistent=False) def forward(self, x, seq_len=None): # x: [bs, num_attention_heads, seq_len, head_size] # This `if` block is unlikely to be run after we build sin/cos in `__init__`. # Keep the logic here just in case. if seq_len > self.max_seq_len_cached: self.max_seq_len_cached = seq_len t = torch.arange(self.max_seq_len_cached, device=x.device, dtype=self.inv_freq.dtype) freqs = torch.einsum("i,j->ij", t, self.inv_freq) # Different from paper, but it uses a different permutation # in order to obtain the same calculation emb = torch.cat((freqs, freqs), dim=-1).to(x.device) self.register_buffer("cos_cached", emb.cos()[None, None, :, :].to(x.dtype), persistent=False) self.register_buffer("sin_cached", emb.sin()[None, None, :, :].to(x.dtype), persistent=False) return ( self.cos_cached[:, :, :seq_len, ...].to(dtype=x.dtype), self.sin_cached[:, :, :seq_len, ...].to(dtype=x.dtype), ) def rotate_half(x): """Rotates half the hidden dims of the input.""" x1 = x[..., : x.shape[-1] // 2] x2 = x[..., x.shape[-1] // 2 :] return torch.cat((-x2, x1), dim=-1) def apply_rotary_pos_emb(q, k, cos, sin, position_ids): # The first two dimensions of cos and sin are always 1, so we can `squeeze` them. cos = cos.squeeze(1).squeeze(0) # [seq_len, dim] sin = sin.squeeze(1).squeeze(0) # [seq_len, dim] cos = cos[position_ids].unsqueeze(1) # [bs, 1, seq_len, dim] sin = sin[position_ids].unsqueeze(1) # [bs, 1, seq_len, dim] q_embed = (q * cos) + (rotate_half(q) * sin) k_embed = (k * cos) + (rotate_half(k) * sin) return q_embed, k_embed
1.4. 模型整體框架
基於上述模型和網路結構可以實現解碼器層,根據自迴歸方式利用訓練語料進行模型的過程與本文介紹的過程基本一致。不同規模LLaMA 模型所使用的具體超引數如表1.3所示。但是由於大語言模型的引數量非常大,並且需要大量的資料進行訓練,因此僅利用單個GPU 很難完成訓練,需要依賴分散式模型訓練框架(後面文章將詳細介紹相關內容)。
表1.3 LLaMA 不同模型規模下的具體超引數細節

HuggingFace Transformer 庫中LLaMA 解碼器整體實現程式碼實現如下所示:
class LlamaDecoderLayer(nn.Module): def __init__(self, config: LlamaConfig): super().__init__() self.hidden_size = config.hidden_size self.self_attn = LlamaAttention(config=config) self.mlp = LlamaMLP( hidden_size=self.hidden_size, intermediate_size=config.intermediate_size, hidden_act=config.hidden_act, ) self.input_layernorm = LlamaRMSNorm(config.hidden_size, eps=config.rms_norm_eps) self.post_attention_layernorm = LlamaRMSNorm(config.hidden_size, eps=config.rms_norm_eps) def forward( self, hidden_states: torch.Tensor, attention_mask: Optional[torch.Tensor] = None, position_ids: Optional[torch.LongTensor] = None, past_key_value: Optional[Tuple[torch.Tensor]] = None, output_attentions: Optional[bool] = False, use_cache: Optional[bool] = False, ) -> Tuple[torch.FloatTensor, Optional[Tuple[torch.FloatTensor, torch.FloatTensor]]]: residual = hidden_states hidden_states = self.input_layernorm(hidden_states) # Self Attention hidden_states, self_attn_weights, present_key_value = self.self_attn( hidden_states=hidden_states, attention_mask=attention_mask, position_ids=position_ids, past_key_value=past_key_value, output_attentions=output_attentions, use_cache=use_cache, ) hidden_states = residual + hidden_states # Fully Connected residual = hidden_states hidden_states = self.post_attention_layernorm(hidden_states) hidden_states = self.mlp(hidden_states) hidden_states = residual + hidden_states outputs = (hidden_states,) if output_attentions: outputs += (self_attn_weights,) if use_cache: outputs += (present_key_value,) return outputs
二、注意力機制優化
在Transformer 結構中,自注意力機制的時間和儲存複雜度與序列的長度呈平方的關係,因此佔用了大量的計算裝置記憶體和並消耗大量計算資源。因此,如何優化自注意力機制的時空複雜度、增強計算效率是大語言模型需要面臨的重要問題。一些研究從近似注意力出發,旨在減少注意力計算和記憶體需求,提出了包括稀疏近似、低秩近似等方法。此外,也有一些研究從計算加速裝置本身的特性出發,研究如何更好利用硬體特性對Transformer 中注意力層進行高效計算。本文將分別介紹上述兩類方法。
2.1. 稀疏注意力機制
通過對一些訓練好的Transformer 模型中的注意力矩陣進行分析發現,其中很多通常是稀疏的,因此可以通過限制Query-Key 對的數量來減少計算複雜度。這類方法就稱為稀疏注意力(SparseAttention)機制。可以將稀疏化方法進一步分成兩類:基於位置資訊和基於內容。基於位置的稀疏注意力機制的基本型別如圖2.6所示,主要包含如下五種型別:
(1)全域性注意力(Global Attention):為了增強模型建模長距離依賴關係,可以加入一些全域性節點;
(2)帶狀注意力(Band Attention):大部分資料都帶有區域性性,限制Query 只與相鄰的幾個節點進行互動;
(3)膨脹注意力(Dilated Attention);與CNN 中的Dilated Conv 類似,通過增加空隙以獲取更大的感受野;
(4)隨機注意力(Random Attention):通過隨機取樣,提升非區域性的互動;
(5)區域性塊注意力(Block Local Attention):使用多個不重疊的塊(Block)來限制資訊互動。
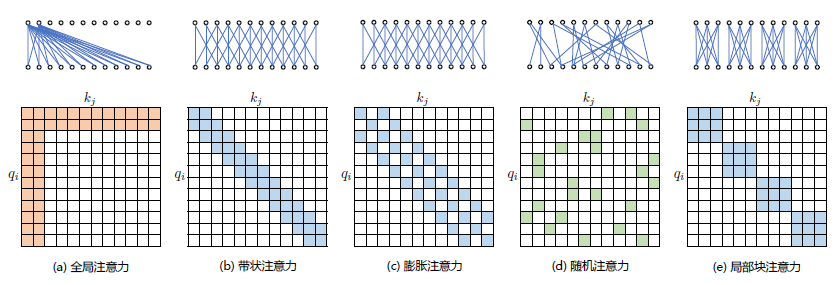
圖2.1 五種基於位置的稀疏注意力基本型別
現有的稀疏注意力機制,通常是基於上述五種基本基於位置的稀疏注意力機制的複合模式,圖2.2給出了一些典型的稀疏注意力模型。
Star-Transformer[54] 使用帶狀注意力和全域性注意力的組合。具體來說,Star-Transformer 只包括一個全域性注意力節點和寬度為3 的帶狀注意力,其中任意兩個非相鄰節點通過一個共用的全域性注意力連線,而相鄰節點則直接相連。
Longformer使用帶狀注意力和內部全域性節點注意力(Internal Global-node Attention)的組合。此外,Longformer 還將上層中的一些帶狀注意力頭部替換為具有擴張視窗的注意力,在增加感受野同時並不增加計算量。Extended Transformer Construction(ETC)利用帶狀注意力和外部全域性節點注意力(External Global-node Attention)的組合。ETC 稀疏注意力還包括一種掩碼機制來處理結構化輸入,並採用對比預測編碼(Contrastive Predictive Coding,CPC)進行預訓練。
BigBird使用帶狀和全域性注意力,還使用額外的隨機注意力來近似全連線注意力,此外還揭示了稀疏編碼器和稀疏解碼器的使用可以模擬任何圖靈機,這也在一定程度上解釋了,為什麼稀疏注意力模型可以取得較好的結果原因。
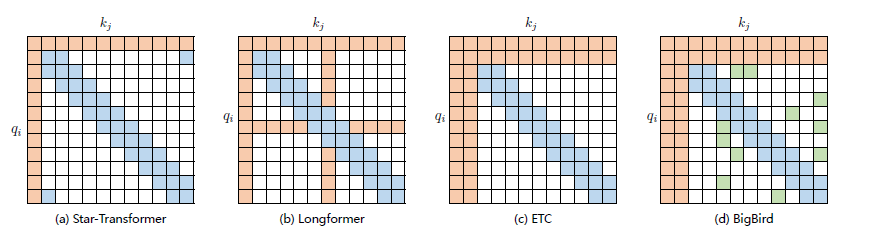
圖2.2 基於位置複合稀疏注意力型別
基於內容的稀疏注意力是是根據輸入資料來建立稀疏注意力,其中一種很簡單的方法是選擇和給定查詢(Query)有很高相似度的鍵(Key)。Routing Transformer 採用K-means 聚類方法,針對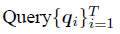 和
和 一起進行聚類,類中心向量集合為
一起進行聚類,類中心向量集合為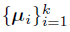 ,其中k 是類中心個數。每個Query 只與其處在相同簇(Cluster)下的Key 進行互動。中心向量採用滑動平均的方法進行更新:
,其中k 是類中心個數。每個Query 只與其處在相同簇(Cluster)下的Key 進行互動。中心向量採用滑動平均的方法進行更新:
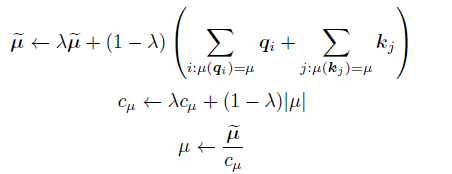
其中|μ| 表示在簇μ 中向量的數量。Reformer[60] 則採用區域性敏感雜湊(Local-Sensitive Hashing,LSH)方法來為每個Query 選擇Key-Value 對。其主要思想使用LSH 函數將Query 和Key 進行雜湊計算,將它們劃分到多個桶內。提升在同一個桶內的Query 和Key 參與互動的概率。假設b 是桶的個數,給定一個大小為[Dk, b/2]隨機矩陣R,LSH 函數定義為:
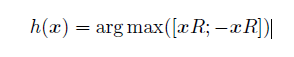
如果hqi = hkj 時,qi 才可以與相應的Key-Value 對進行互動。
2.2. FlashAttention
NVIDIA GPU 中的記憶體(視訊記憶體)按照它們物理上是在GPU 晶片內部還是板卡RAM 儲存晶片上,決定了它們的速度、大小以及存取限制。GPU 視訊記憶體分為全域性記憶體(Global memory)、本地記憶體(Local memory)、共用記憶體(Shared memory,SRAM)、暫存器記憶體(Register memory)、常數記憶體(Constant memory)、紋理記憶體(Texture memory)等六大類。圖2.8給出了NVIDIA GPU 記憶體的整體結構。其中全域性記憶體、本地記憶體、共用記憶體和暫存器記憶體具有讀寫能力。
全域性記憶體和本地記憶體使用的高頻寬視訊記憶體(High Bandwidth Memory,HBM)位於板卡RAM 儲存晶片上,該部分記憶體容量很大。全域性記憶體是所有執行緒都可以存取,而本地記憶體則只能當前執行緒存取。NVIDIA H100 中全域性記憶體有80GB 空間,其存取速度雖然可以達到3.35TB/s,但是如果全部執行緒同時存取全域性記憶體時,其平均頻寬仍然很低。共用記憶體和暫存器位於GPU 晶片上,因此容量很小,並且共用記憶體只有在同一個GPU 執行緒塊(Thread Block)內的執行緒才可以共用存取,而暫存器僅限於同一個執行緒內部才能存取。
NVIDIA H100 中每個GPU 執行緒塊在流式多處理器(Stream Multi-processor,SM)可以使用的共用儲存容量僅有228KB,但是其速度非常快,遠高於全域性記憶體的存取速度。
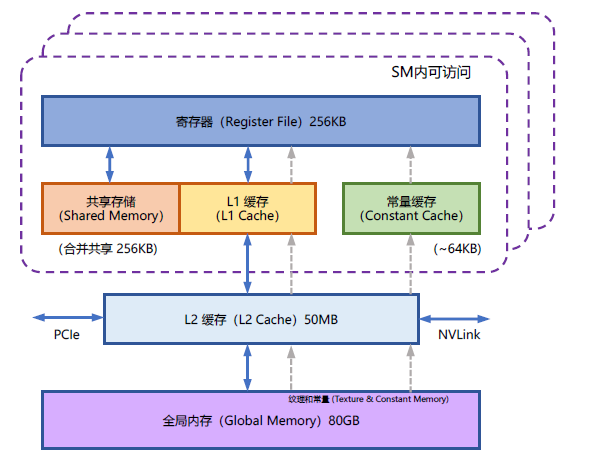
圖2.2 NVIDIA GPU 的整體記憶體結構圖
在本章第2.2 節中介紹自注意力機制的原理,在GPU 中進行計算時,傳統的方法還需要引入:兩個中間矩陣S 和P 並儲存到全域性記憶體中。具體計算過程如下:

按照上述計算過程,需要首先從全域性記憶體中讀取矩陣Q 和K,並將計算好的矩陣S 再寫入全域性記憶體,之後再從全域性記憶體中獲取矩陣S,計算Softmax 得到矩陣P,再寫入全域性內容,之後讀取矩
陣P 和矩陣V ,計算得到矩陣矩陣O。這樣的過程會極大佔用視訊記憶體的頻寬。在自注意力機制中,計算速度比記憶體速度快得多,因此計算效率越來越多地受到全域性記憶體存取的瓶頸。
FlashAttention就是通過利用GPU 硬體中的特殊設計,針對全域性記憶體和共用儲存的I/O 速度的不同,儘可能的避免HBM 中讀取或寫入注意力矩陣。
FlashAttention 目標是儘可能高效地使用SRAM 來加快計算速度,避免從全域性記憶體中讀取和寫入注意力矩陣。達成該目標需要能做到在不存取整個輸入的情況下計算Softmax 函數,並且後向傳播中不能儲存中間注意力矩陣。
標準Attention 演演算法中,Softmax 計算按行進行,即在與V 做矩陣乘法之前,需要將Q、K 的各個分塊完成一整行的計算。在得到Softmax 的結果後,再與矩陣V 分塊做矩陣乘。而在FlashAttention 中,將輸入分割成塊,並在輸入塊上進行多次傳遞,從而以增量方式執行Softmax 計算。
自注意力演演算法的標準實現將計算過程中的矩陣S、P 寫入全域性記憶體中,而這些中間矩陣的大小與輸入的序列長度有關且為二次型。因此,FlashAttention 就提出了不使用中間注意力矩陣,通過儲存歸一化因子來減少全域性記憶體的消耗。
FlashAttention 演演算法並沒有將S、P 整體寫入全域性記憶體,而是通過分塊寫入,儲存前向傳遞的Softmax 歸一化因子,在後向傳播中快速重新計算片上注意力,這比從全域性內容中讀取中間注意力矩陣的標準方法更快。由於大幅度減少了全域性記憶體的存取量,即使重新計算導致FLOPs 增加,但其執行速度更快並且使用更少的記憶體。具體演演算法如程式碼2.2所示,其中內迴圈和外迴圈所對應的計算可以參考下圖。

2.3 FlashAttention 計算流程圖
2.3. 多查詢注意力
多查詢注意力(Multi Query Attention)[62] 是多頭注意力的一種變體。其主要區別在於,在多查詢注意力中不同的注意力頭共用一個鍵和值的集合,每個頭只單獨保留了一份查詢引數。
因此鍵和值的矩陣僅有一份,這大幅度減少了視訊記憶體佔用,使其更高效。由於多查詢注意力改變了注意力機制的結構,因此模型通常需要從訓練開始就支援多查詢注意力。文獻[63] 的研究結果表明,可以通過對已經訓練好的模型進行微調來新增多查詢注意力支援,僅需要約5% 的原始訓練資料量就可以達到不錯的效果。包括Falcon、SantaCoder、StarCoder等在內很多模型都採用了多查詢注意力機制。
以LLM Foundry 為例,多查詢注意力實現程式碼如下:
程式碼2.2: FlashAttention 演演算法,簡單來說我梳理下邏輯:

class MultiQueryAttention(nn.Module): """Multi-Query self attention. Using torch or triton attention implemetation enables user to also use additive bias. """ def __init__( self, d_model: int, n_heads: int, device: Optional[str] = None, ): super().__init__() self.d_model = d_model self.n_heads = n_heads self.head_dim = d_model // n_heads self.Wqkv = nn.Linear( # Multi-Query Attention 建立 d_model, d_model + 2 * self.head_dim, # 只建立查詢的頭向量,所以只有1 個d_model device=device, # 而鍵和值則共用各自的一個head_dim 的向量 ) self.attn_fn = scaled_multihead_dot_product_attention self.out_proj = nn.Linear( self.d_model, self.d_model, device=device ) self.out_proj._is_residual = True # type: ignore def forward( self, x, ): qkv = self.Wqkv(x) # (1, 512, 960) query, key, value = qkv.split( # query -> (1, 512, 768) [self.d_model, self.head_dim, self.head_dim], # key -> (1, 512, 96) dim=2 # value -> (1, 512, 96) ) context, attn_weights, past_key_value = self.attn_fn( query, key, value, self.n_heads, multiquery=True, ) return self.out_proj(context), attn_weights, past_key_value
與LLM Foundry 中實現的多頭自注意力程式碼相對比,其區別僅在於建立Wqkv 層上:
# Multi Head Attention self.Wqkv = nn.Linear( # Multi-Head Attention 的建立方法 self.d_model, 3 * self.d_model, # 查詢、鍵和值3 個矩陣, 所以是3 * d_model device=device ) query, key, value = qkv.chunk( # 每個tensor 都是(1, 512, 768) 3, dim=2 ) # Multi Query Attention self.Wqkv = nn.Linear( # Multi-Query Attention 的建立方法 d_model, d_model + 2 * self.head_dim, # 只建立查詢的頭向量,所以是1* d_model device=device, # 而鍵和值不再具備單獨的頭向量 ) query, key, value = qkv.split( # query -> (1, 512, 768) [self.d_model, self.head_dim, self.head_dim], # key -> (1, 512, 96) dim=2 # value -> (1, 512, 96) )
本篇文章將以LLaMA 模型為例,從底層詳細的介紹了大語言模型架構在Transformer 原始結構上的改進,並介紹Transformer 模型結構中空間和時間佔比最大的注意力機制優化方法。看起來確實比較「幹」貨一點,但是隻有從底層更加了解大模型原理,才能更加知道怎麼使用。