【解決方案】MySQL5.7 百萬資料遷移到 ElasticSearch7.x 的思考
前言
在日常專案開發中,可能會遇到使用 ES 做關鍵詞搜尋的場景,但是一般來說業務資料是不會直接通過 CRUD 寫進 ES 的。
因為這可能違背了 ES 是用來查詢的初衷,資料持久化的事情可以交給資料庫來做。那麼,這裡就有一個顯而易見的問題:ES 裡的資料從哪裡來?
本文介紹的就是如何將 MySQL 的表資料遷移到 ES 的全過程。
一、一次性全量
該方案的思路很簡單直接:將資料庫中的表資料一次性查出,放入記憶體,在轉換 DB 與 ES 的實體結構,遍歷迴圈將 DB 的資料 放入 ES 中。
但是對機器的效能考驗非常大:本地 MySQL 10w 條資料,電腦記憶體16GB,僅30秒鐘記憶體佔用90%,CPU佔用100%。太過於粗暴了,不推薦使用。
@Component05
@Slf4j
public class FullSyncArticleToES implements CommandLineRunner {
@Resource
private ArticleMapper articleMapper;
@Resource
private ArticleRepository articleRepository;
/**
* 執行一次即可全量遷移
*/
//todo: 弊端太明顯了,資料量一大的話,對記憶體和 cpu 都是考驗,不推薦這麼簡單粗暴的方式
public void fullSyncArticleToES() {
LambdaQueryWrapper<Article> wrapper = new LambdaQueryWrapper<>();
List<Article> articleList = articleMapper.selectList(wrapper);
if (CollectionUtils.isNotEmpty(articleList)) {
List<ESArticle> esArticleList = articleList.stream().map(ESArticle::dbToEs).collect(Collectors.toList());
final int pageSize = 500;
final int total = esArticleList.size();
log.info("------------FullSyncArticleToES start!-----------, total {}", total);
for (int i = 0; i < total; i += pageSize) {
int end = Math.min(i + pageSize, total);
log.info("------sync from {} to {}------", i, end);
articleRepository.saveAll(esArticleList.subList(i, end));
}
log.info("------------FullSyncPostToEs end!------------, total {}", total);
}
else {
log.info("------------DB no Data!------------");
}
}
@Override
public void run(String... args) {}
}
二、定時任務增量
這種方案的思想是按時間範圍以增量的方式讀取,比全量的一次性資料量要小很多。
也存在弊端:頻繁的資料庫連線 + 讀寫,對伺服器資源消耗較大。且在極端短時間內大量資料寫入的場景,可能會導致效能、資料不一致的問題(即來不及把所有資料都查到,同時還要寫到 ES)。
但還是有一定的可操作性,畢竟可能沒有那麼極端的情況,高並行寫入的場景不會時刻都有。
@Component
@Slf4j
public class IncSyncArticleToES {
@Resource
private ArticleMapper articleMapper;
@Resource
private ArticleRepository articleRepository;
/**
* 每分鐘執行一次
*/
@Scheduled(fixedRate = 60 * 1000)
public void run() {
// 查詢近 5 分鐘內的資料,有 id 重複的資料 ES 會自動覆蓋
Date fiveMinutesAgoDate = new Date(new Date().getTime() - 5 * 60 * 1000L);
List<Article> articleList = articleMapper.listArticleWithData(fiveMinutesAgoDate);
if (CollectionUtils.isNotEmpty(articleList)) {
List<ESArticle> esArticleList = articleList.stream().map(ESArticle::dbToEs).collect(Collectors.toList());
final int pageSize = 500;
int total = esArticleList.size();
log.info("------------IncSyncArticleToES start!-----------, total {}", total);
for (int i = 0; i < total; i += pageSize) {
int end = Math.min(i + pageSize, total);
log.info("sync from {} to {}", i, end);
articleRepository.saveAll(esArticleList.subList(i, end));
}
log.info("------------IncSyncArticleToES end!------------, total {}", total);
}
else {
log.info("------------DB no Data!------------");
}
}
}
三、強一致性問題
如果大家看完以上兩個方案,可能會有一個問題:
無論是增量還是全量, MySQL 和 ES 進行連線/讀寫是需要耗費時間的,如果這個過程中如果有大量的資料插到 MySQL 裡,那麼有沒有可能寫入 ES 裡的資料並不能和 MySQL 裡的完全一致?
答案是:在資料量大和高並行的場景下,是很有可能會發生這種情況的。
如果需要我們自己寫程式碼來保證一致性,可以怎麼做才能較好地解決呢?
思路:由於 ES 查詢做了分頁,每次查只有10 條,那麼每次呼叫查詢的時候,就拿這10條資料的唯一標識 id 再去 MySQL 中查一下,MySQL 裡有的就會被查出來,那麼返回這些結果就好,就不直接返回 ES 的查詢結果了;同時刪除掉 ES 裡那些在資料庫中被刪除的資料,做個」反向同步「。這個思路有幾個明顯的優點:
1、單次資料量很小,在記憶體中操作幾乎就是毫秒級的;
2、返回的是 MySQL 的源資料,不再 」信任「 ES 了,保證強一致性;
3、反向刪除 ES 中的那些已經被 MySQL 刪除了的資料。
以下是程式碼,註釋很詳細,應該很好理解:
@Override
public PageInfo<Article> testSearchFromES(ArticleSearchDTO articleSearchDTO){
// 獲取查詢物件的結果, searchQuery 這裡忽略,就當查詢條件已經寫好了,可以查到資料
SearchHits<ESArticle> searchHits = elasticTemplate.search(searchQuery, ESArticle.class);
//todo: 以下考慮使用 MySQL 的源資料,不再以 ES 的資料為準
List<Article> resultList = new ArrayList<>();
// 從 ES 查出結果後,再與 db 獲的資料進行對比,確認後再組裝返回
if (searchHits.hasSearchHits()) {
// 收集 ES 裡業務物件的 Id 成 List
List<String> articleIdList = searchHits.getSearchHits().stream()
.map(val -> val.getContent().getId())
.collect(Collectors.toList());
// 獲取資料庫的符合體條件的資料,由於是分頁的,一次性的資料量小(10條而已),剩下的都是記憶體操作,效能可以保證
List<Article> articleList = baseMapper.selectBatchIds(articleIdList);
if (CollectionUtils.isNotEmpty(articleList)) {
//根據 db 裡業務物件的 Id 進行分組
Map<String , List<Article>> idArticleMap = articleList.stream().collect(Collectors.groupingBy(Article::getId));
//對 ES 中的 Id 的集合進行 for 迴圈,經過對比後新增資料
articleIdList.forEach(articleId -> {
// 如果 ES 裡的 Id 在資料庫裡有,說明資料已經同步到 ES 了,兩邊的資料是一致的
if (idArticleMap.containsKey(articleId)) {
// 則把符合的資料放入 page 物件中
resultList.add(idArticleMap.get(articleId).get(NumberUtils.INTEGER_ZERO));
} else {
// 刪除 ES 中那些在資料庫中被刪除的資料;因為資料庫都沒有這條資料庫了,那麼 ES 裡也不能有,算是一種反向同步吧
String delete = elasticTemplate.delete(String.valueOf(articleId), PostEsDTO.class);
log.info("delete post {}", delete);
}
});
}
}
// 初始化 page 物件
PageInfo<Article> pageInfo = new PageInfo<>();
pageInfo.setList(resultList);
pageInfo.setTotal(searchHits.getTotalHits());
System.out.println(pageInfo);
return pageInfo;
}
然而,以上的所有內容並不是今天文章的重點。只是為引入 canal 做的鋪墊,引入、安裝、設定好 canal 後可以解決以上的全部問題。對,就是全部。
四、canal 框架
4.1基本原理
canal 是 Alibaba 開源的一個用於 MySQL 資料庫增量資料同步工具。它通過解析 MySQL 的 binlog 來獲取增量資料,並將資料傳送到指定位置。
canal 會模擬 MySQL slave 的互動協定,偽裝自己為 MySQL 的 slave ,向 MySQL master 傳送 dump 協定。MySQL master 收到 dump 請求,開始推播 bin-log 給 slave (即 canal )。

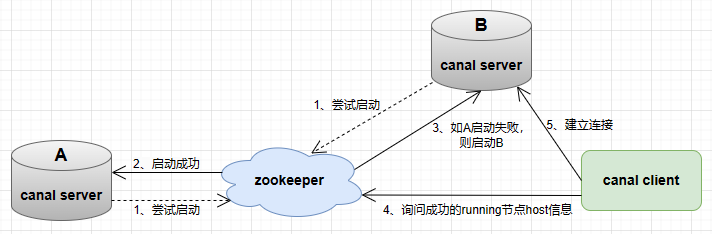
canal 的高可用分為兩部分:canal server 和 canal client。
canal server 為了減少對 MySQL dump 的請求,不同 server 上的範例要求同一時間只能有一個處於 running 狀態;
canal client 為了保證有序性,一份範例同一時間只能由一個 canal client 進行 get/ack/rollback 操作來保證順序。
4.2安裝使用(重點)
-
版本說明
- Centos 7(這個關係不大)
- JDK 11(這個很關鍵)
- MySQL 5.7.36(只要5.7.x都可)
- Elasticsearch 7.16.x(不要太高,比較關鍵)
- cannal.server: 1.1.5(有官方映象,放心拉取)
- canal.adapter: 1.1.5(無官方映象,但問題不大)
注:我這裡由於自己的個人伺服器的一些中介軟體版本問題,始終無法成功安裝上 canal-adapter,所以沒有最終將資料遷移到 ES 裡去。

主要原因在於兩點:
- JDK 版本需要 JDK11及以上,我自己個人伺服器現用的是 JDK 8,但 canal 並不相容 JDK 8;
- 我的 ES 的版本太高用的是7.6.1,這可能導致 canal 版本與它不相容,可能實際需要降低到7.16.x 左右。
但是本人在工作中是有過專案實踐的,推薦使用 docker 安裝 canal,步驟參考:https://zhuanlan.zhihu.com/p/465614745
4.3引入依賴(測試)
<!-- https://mvnrepository.com/artifact/com.alibaba.otter/canal.client -->
<dependency>
<groupId>com.alibaba.otter</groupId>
<artifactId>canal.client</artifactId>
<version>1.1.4</version>
</dependency>
4.4程式碼範例(測試)
以下程式碼 demo 來自官網,僅用於測試。
首先需要連線上4.2小節中的 canal-server 設定,然後啟動該類中的 main 方法後會不斷去監聽對應的 MySQL 庫-表資料是否有變化,有的話就列印出來。
public class CanalClientUtils {
public static void main(String[] args) {
// 建立連線
CanalConnector connector = CanalConnectors.newSingleConnector(new InetSocketAddress
("你的公網ip地址", 11111), "example", "", "");
int batchSize = 1000;
int emptyCount = 0;
try {
connector.connect();
connector.subscribe(".*\\..*");
connector.rollback();
int totalEmptyCount = 1000;
while (emptyCount < totalEmptyCount) {
// 獲取指定數量的資料
Message message = connector.getWithoutAck(batchSize);
long batchId = message.getId();
int size = message.getEntries().size();
if (batchId == -1 || size == 0) {
emptyCount++;
System.out.println("empty count : " + emptyCount);
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
}
} else {
emptyCount = 0;
System.out.printf("message[batchId=%s,size=%s] \n", batchId, size);
printEntry(message.getEntries());
}
// 提交確認
connector.ack(batchId);
// 處理失敗, 回滾資料
//connector.rollback(batchId);
}
System.out.println("empty too many times, exit");
} finally {
// 關閉連線
connector.disconnect();
}
}
private static void printEntry(List<CanalEntry.Entry> entries) {
for (CanalEntry.Entry entry : entries) {
if (entry.getEntryType() == CanalEntry.EntryType.TRANSACTIONBEGIN || entry.getEntryType() == CanalEntry.EntryType.TRANSACTIONEND) {
continue;
}
CanalEntry.RowChange rowChage;
try {
rowChage = CanalEntry.RowChange.parseFrom(entry.getStoreValue());
} catch (Exception e) {
throw new RuntimeException("ERROR ## parser of error-event has an error , data:" + entry, e);
}
CanalEntry.EventType eventType = rowChage.getEventType();
System.out.printf(
"-----------binlog[%s:%s] , name[%s,%s] , eventType:%s%n ------------",
entry.getHeader().getLogfileName(), entry.getHeader().getLogfileOffset(),
entry.getHeader().getSchemaName(), entry.getHeader().getTableName(),
eventType);
for (CanalEntry.RowData rowData : rowChage.getRowDatasList()) {
if (eventType == CanalEntry.EventType.DELETE) {
printColumn(rowData.getBeforeColumnsList());
} else if (eventType == CanalEntry.EventType.INSERT) {
printColumn(rowData.getAfterColumnsList());
} else {
System.out.println("---------before data----------");
printColumn(rowData.getBeforeColumnsList());
System.out.println("---------after data-----------");
printColumn(rowData.getAfterColumnsList());
}
}
}
}
private static void printColumn(List<CanalEntry.Column> columns) {
for (CanalEntry.Column column : columns) {
System.out.println(column.getName() + " : " + column.getValue() + ",update status:" + column.getUpdated());
}
}
}
預期的結果會表明涉及的庫、表名稱,以及操作的型別,同時還可以知道欄位的狀態:true 為有變化,false 為無變化。如下圖所示:
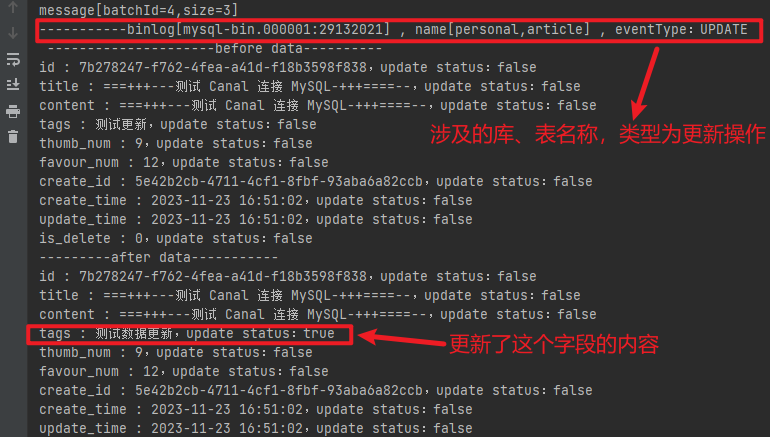
以上的4.3和4.4小節都是用來測試效果的,在伺服器上安裝設定好 canal 以後,實際無需在專案中寫關於 canal 的操作程式碼。
每一步的 MySQL 操作 binlog 都會被 canal 獲取到,然後將資料同步到 ES 中,這些操作都是在伺服器上進行的,基本上對於開發人員來說是無感的。
阿里雲上有專門的產品來支援資料從 MySQL 遷移到 ES 的場景,真正的商業專案開發,還是可以選擇雲廠商現有的方案(我不是打廣告):
五、文章小結
到這裡我就和大家分享完了關於資料從 MySQL 遷移到 ES 全過程的思考,如有錯誤和不足,期待大家的指正和交流。
參考檔案:
- 阿里巴巴 canal 的 GitHub 開源專案地址:https://github.com/alibaba/canal
- 安裝以及設定步驟:https://zhuanlan.zhihu.com/p/465614745