新來個架構師,把Xxl-Job原理講的爐火純青
大家好,我是三友~~
今天來繼續探祕系列,扒一扒輕量級的分散式任務排程平臺Xxl-Job背後的架構原理
公眾號:三友的java日記
核心概念
這裡還是老樣子,為了保證文章的完整性和連貫性,方便那些沒有使用過的小夥伴更加容易接受文章的內容,快速講一講Xxl-Job中的概念和使用
如果你已經使用過了,可直接跳過本節和下一節,快進到後面原理部分講解
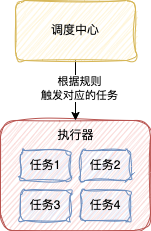
1、排程中心
排程中心是一個單獨的Web服務,主要是用來觸發定時任務的執行
它提供了一些頁面操作,我們可以很方便地去管理這些定時任務的觸發邏輯
排程中心依賴資料庫,所以資料都是存在資料庫中的
排程中心也支援叢集模式,但是它們所依賴的資料庫必須是同一個
所以同一個叢集中的排程中心範例之間是沒有任何通訊的,資料都是通過資料庫共用的

2、執行器
執行器是用來執行具體的任務邏輯的
執行器你可以理解為就是平時開發的服務,一個服務範例對應一個執行器範例
每個執行器有自己的名字,為了方便,你可以將執行器的名字設定成服務名
3、任務
任務什麼意思就不用多說了
一個執行器中也是可以有多個任務的
總的來說,呼叫中心是用來控制定時任務的觸發邏輯,而執行器是具體執行任務的,這是一種任務和觸發邏輯分離的設計思想,這種方式的好處就是使任務更加靈活,可以隨時被呼叫,還可以被不同的排程規則觸發。
來個Demo
1、搭建排程中心
排程中心搭建很簡單,先下載原始碼
https://github.com/xuxueli/xxl-job.git
然後改一下資料庫連線資訊,執行一下在專案原始碼中的/doc/db下的sql檔案
啟動可以打成一個jar包,或者本地啟動就是可以的
啟動完成之後,存取下面這個地址就可以存取到控制檯頁面了
http://localhost:8080/xxl-job-admin/toLogin
使用者名稱密碼預設是 admin/123456
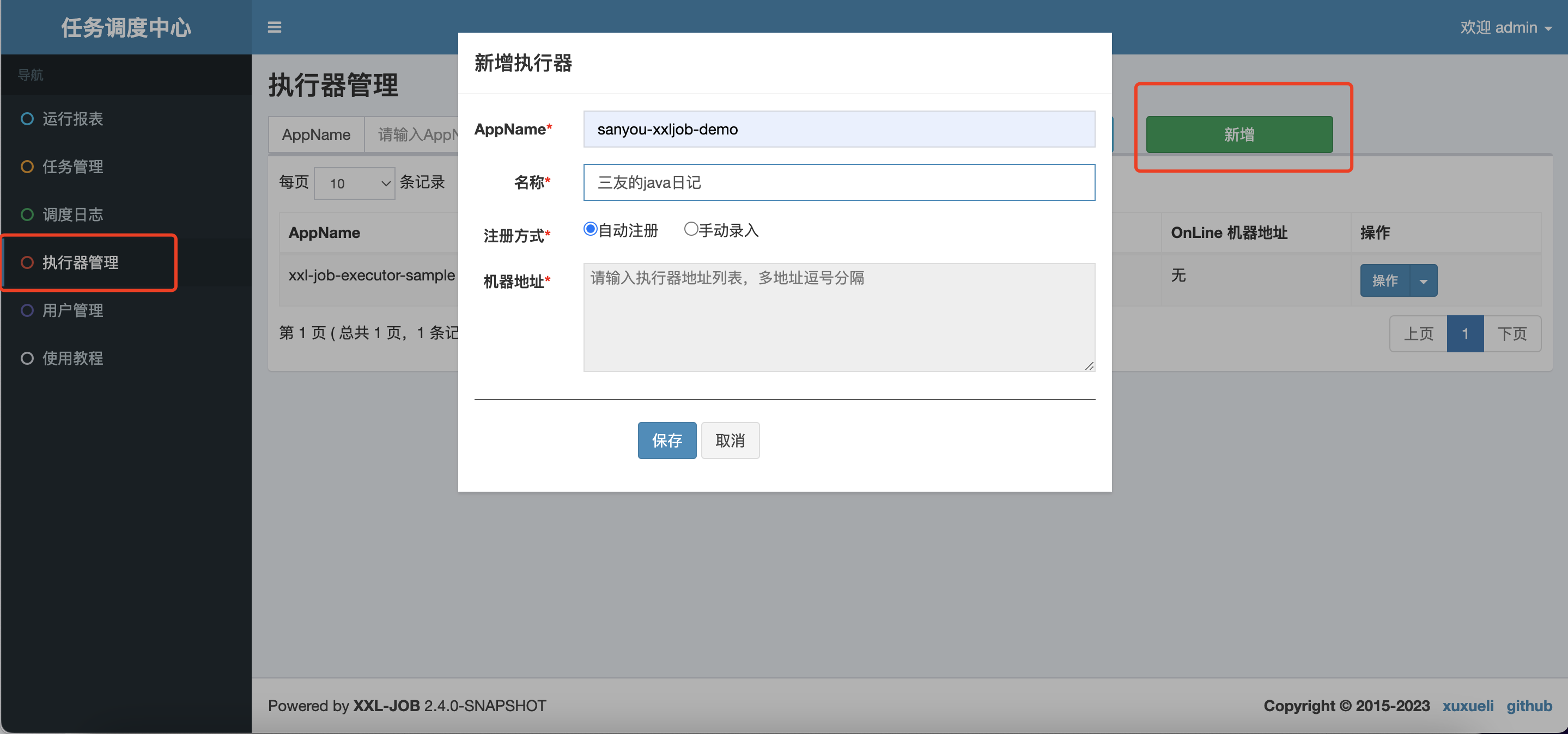
2、執行器和任務新增
新增一個名為sanyou-xxljob-demo執行器
任務新增
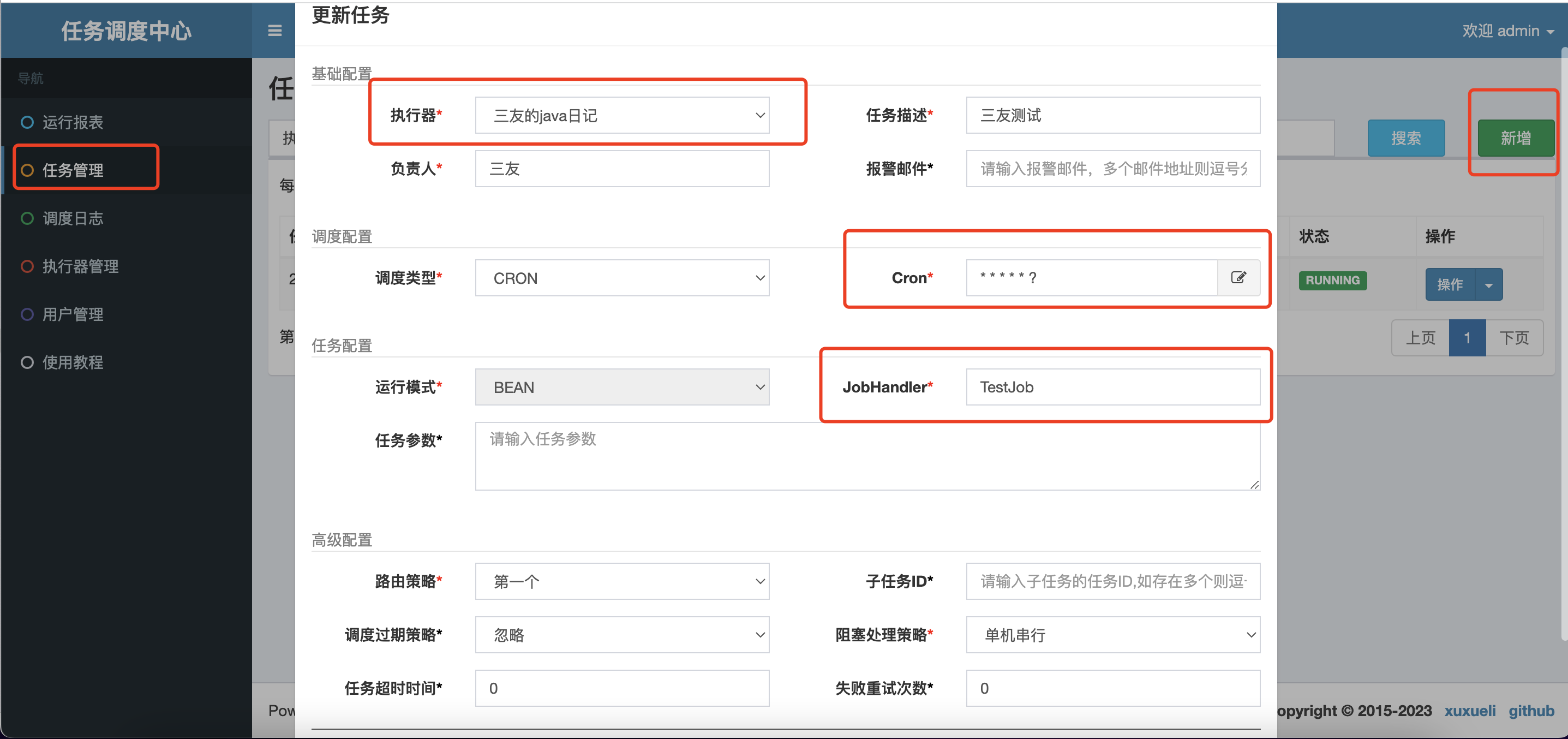
執行器選擇我們剛剛新增的,指定任務名稱為TestJob,corn表示式的意思是每秒執行一次
建立完之後需要啟動一下任務,預設是關閉狀態,也就不會執行
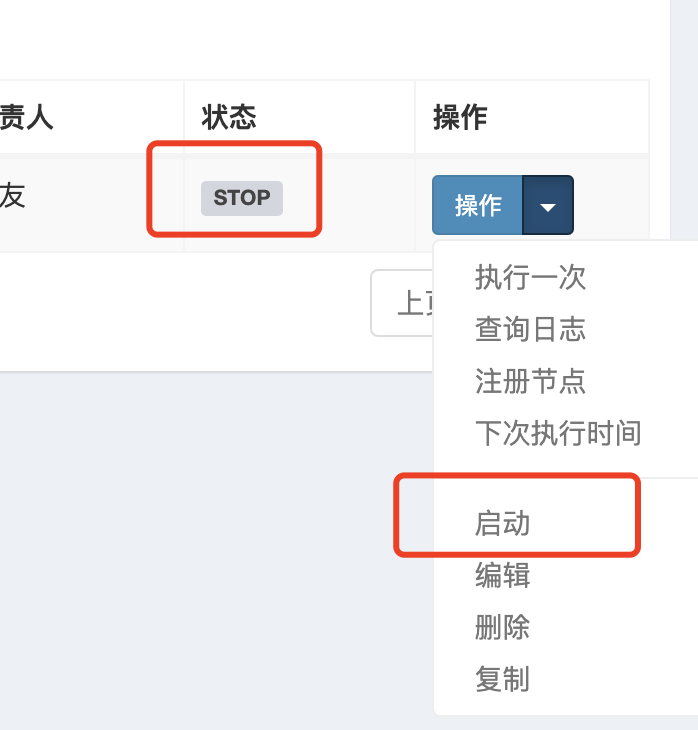
建立執行器和任務其實就是CRUD,並沒有複雜的業務邏輯
按照如上設定的整個Demo的意思就是
每隔1s,執行一次sanyou-xxljob-demo這個執行器中的TestJob任務
3、建立執行器和任務
引入依賴
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
<version>2.2.5.RELEASE</version>
</dependency>
<dependency>
<groupId>com.xuxueli</groupId>
<artifactId>xxl-job-core</artifactId>
<version>2.4.0</version>
</dependency>
</dependencies>
設定XxlJobSpringExecutor這個Bean
@Configuration
public class XxlJobConfiguration {
@Bean
public XxlJobSpringExecutor xxlJobExecutor() {
XxlJobSpringExecutor xxlJobSpringExecutor = new XxlJobSpringExecutor();
//設定呼叫中心的連線地址
xxlJobSpringExecutor.setAdminAddresses("http://localhost:8080/xxl-job-admin");
//設定執行器的名稱
xxlJobSpringExecutor.setAppname("sanyou-xxljob-demo");
//設定一個埠,後面會講作用
xxlJobSpringExecutor.setPort(9999);
//這個token是保證存取安全的,預設是這個,當然可以自定義,
// 但需要保證排程中心設定的xxl.job.accessToken屬性跟這個token是一樣的
xxlJobSpringExecutor.setAccessToken("default_token");
//任務執行紀錄檔存放的目錄
xxlJobSpringExecutor.setLogPath("./");
return xxlJobSpringExecutor;
}
}
XxlJobSpringExecutor這個類的作用,後面會著重講
通過@XxlJob指定一個名為TestJob的任務,這個任務名需要跟前面頁面設定的對應上
@Component
public class TestJob {
private static final Logger logger = LoggerFactory.getLogger(TestJob.class);
@XxlJob("TestJob")
public void testJob() {
logger.info("TestJob任務執行了。。。");
}
}
所以如果順利的話,每隔1s鍾就會列印一句TestJob任務執行了。。。
啟動專案,注意修改一下埠,因為呼叫中心預設也是8080,本地起會埠衝突
最終執行結果如下,符合預期

講完概念和使用部分,接下來就來好好講一講Xxl-Job核心的實現原理
從執行器啟動說起
前面Demo中使用到了一個很重要的一個類
XxlJobSpringExecutor
這個類就是整個執行器啟動的入口
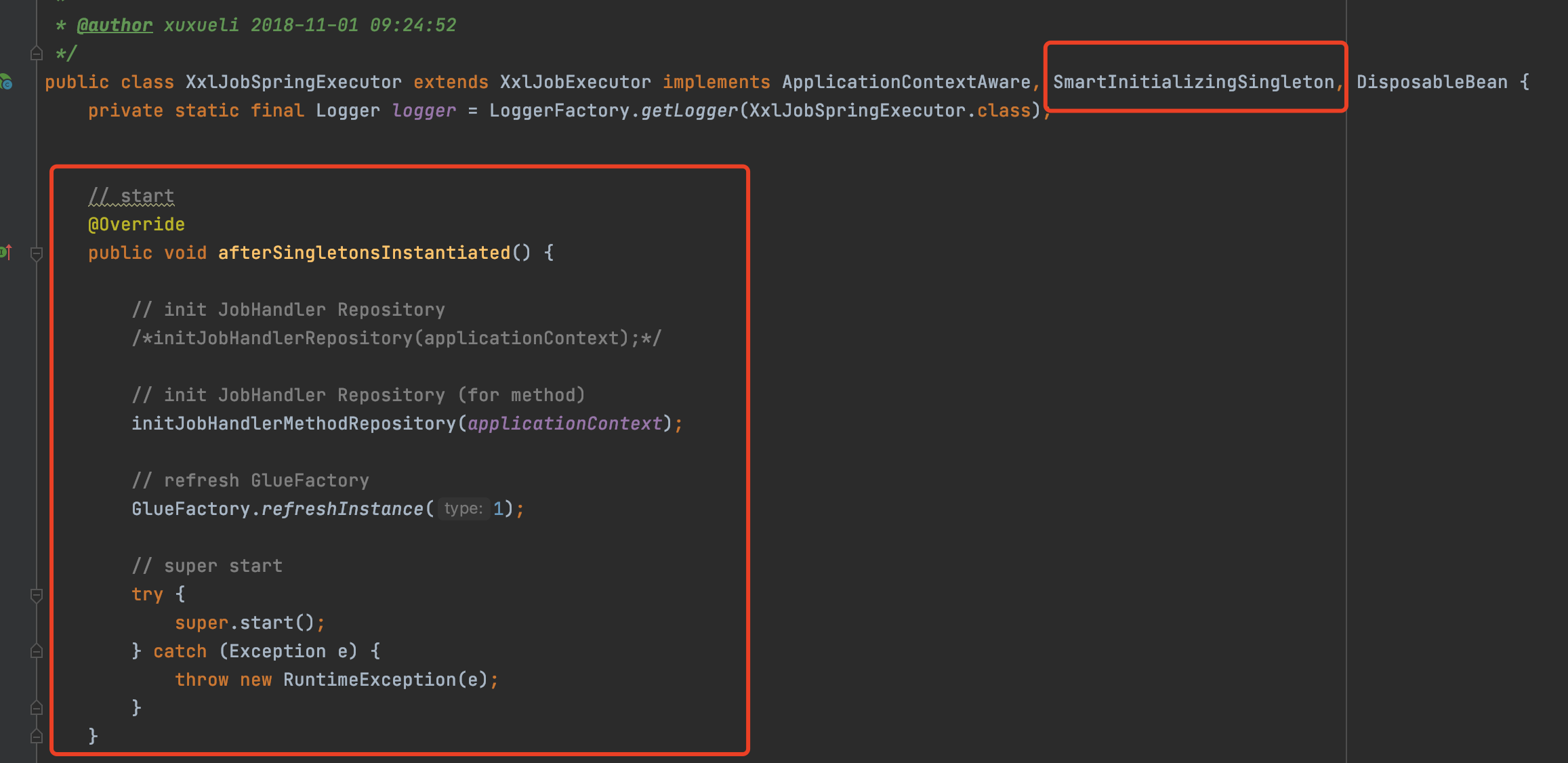
這個類實現了SmartInitializingSingleton介面
所以經過Bean的生命週期,一定會呼叫afterSingletonsInstantiated這個方法的實現
這個方法幹了很多初始化的事,這裡我挑三個重要的講,其餘的等到具體的功能的時候再提
1、初始化JobHandler
JobHandler是個什麼?
所謂的JobHandler其實就是一個定時任務的封裝
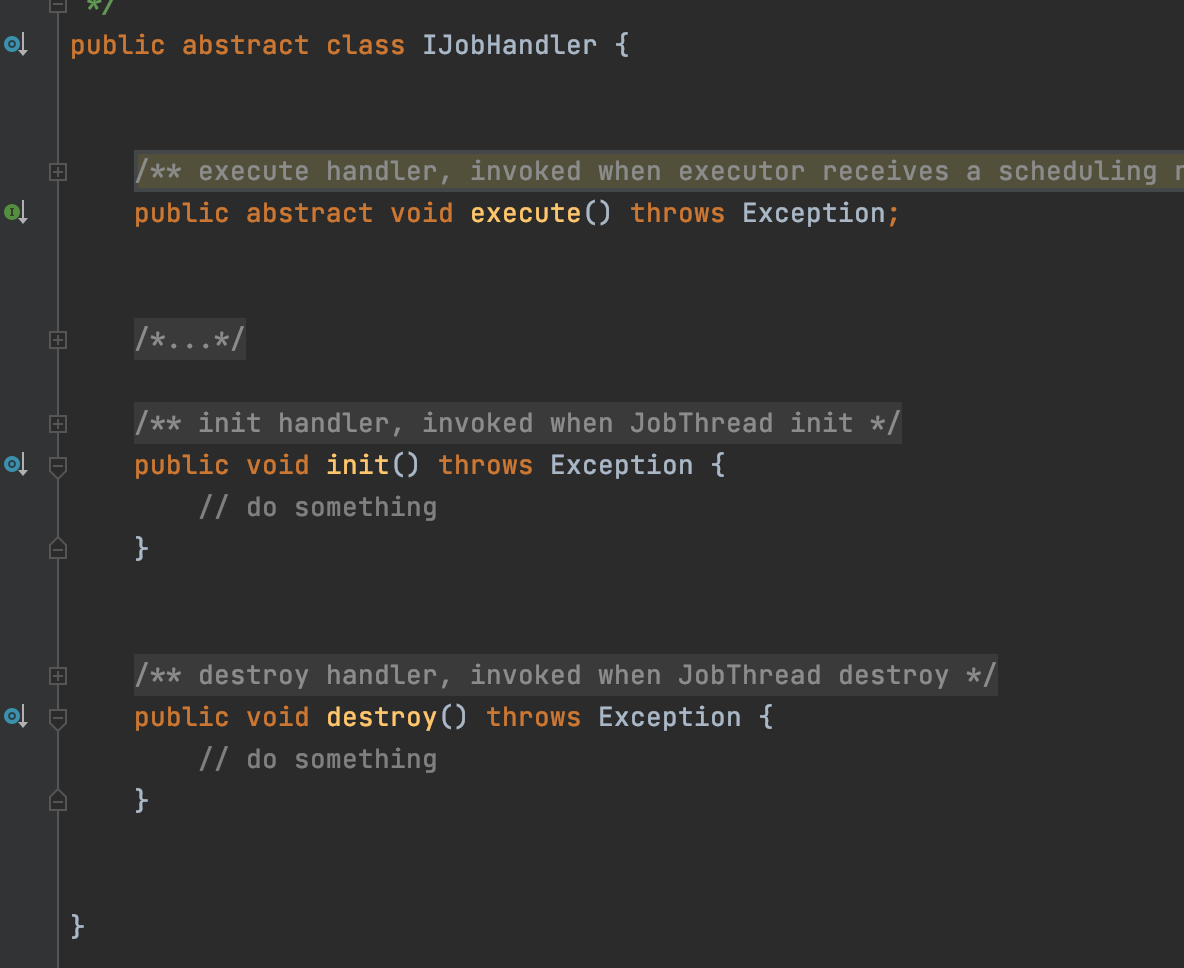
一個定時任務會對應一個JobHandler物件
當執行器執行任務的時候,就會呼叫JobHandler的execute方法
JobHandler有三種實現:
MethodJobHandler GlueJobHandler ScriptJobHandler
MethodJobHandler是通過反射來呼叫方法執行任務
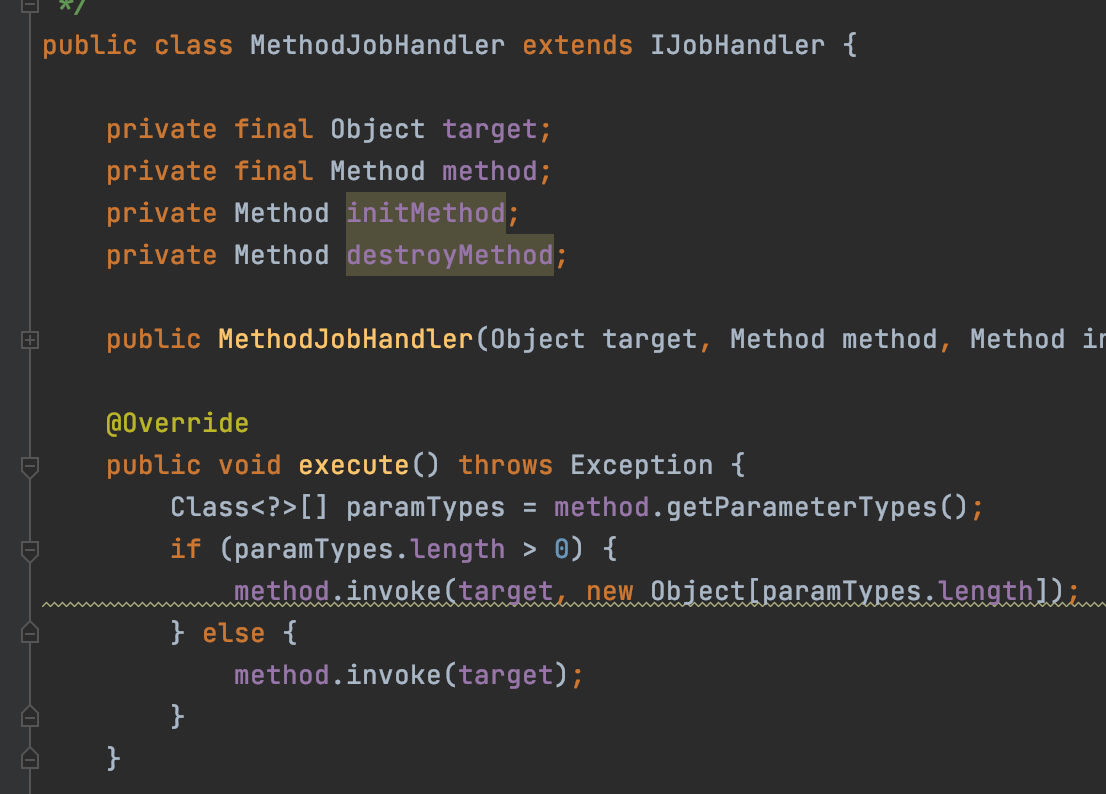
所以MethodJobHandler的任務的實現就是一個方法,剛好我們demo中的例子任務其實就是一個方法
所以Demo中的任務最終被封裝成一個MethodJobHandler
GlueJobHandler比較有意思,它支援動態修改任務執行的程式碼
當你在建立任務的時候,需要指定執行模式為GLUE(Java)
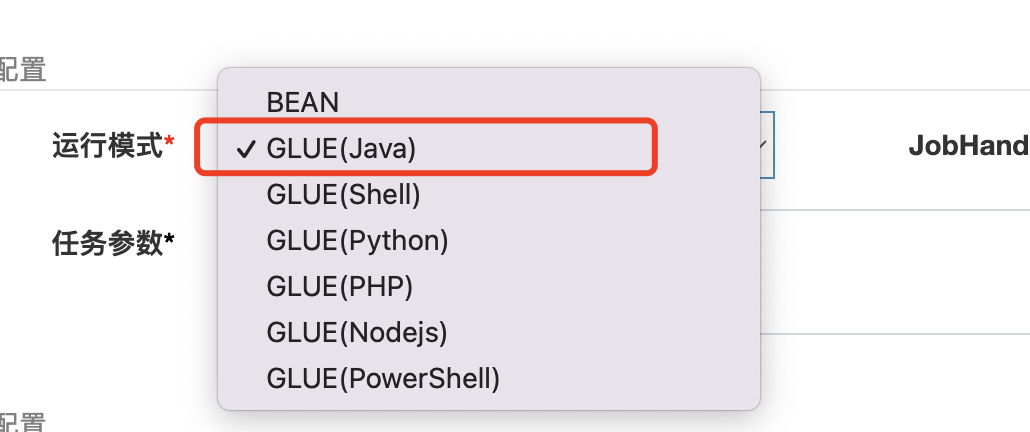
之後需要在操作按鈕點選GLUE IDE編寫Java程式碼
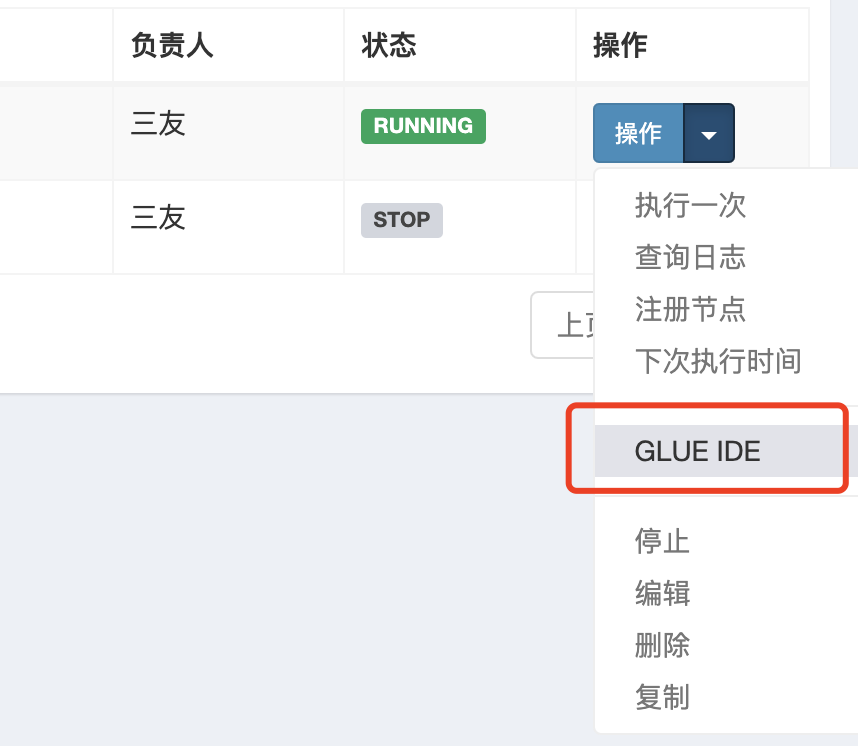
程式碼必須得實現IJobHandler介面,之後任務執行的時候就會執行execute方法的實現
如果你需要修改任務的邏輯,只需要重新編輯即可,不需要重啟服務
ScriptJobHandler,通過名字也可以看出,是專門處理一些指令碼的
執行模式除了BEAN和GLUE(Java)之外,其餘都是指令碼模式
而本節的主旨,所謂的初始化JobHandler就是指,執行器啟動的時候會去Spring容器中找到加了@XxlJob註解的Bean
解析註解,然後封裝成一個MethodJobHandler物件,最終存到XxlJobSpringExecutor成員變數的一個原生的Map快取中
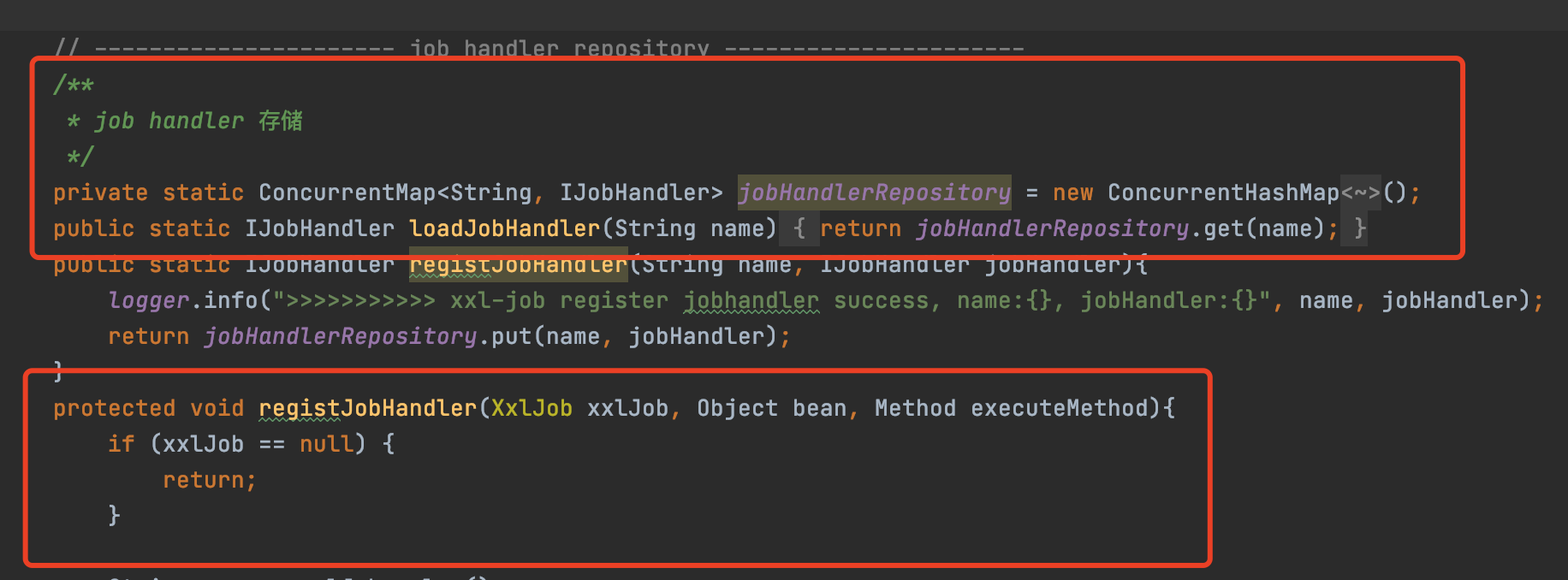
快取key就是任務的名字
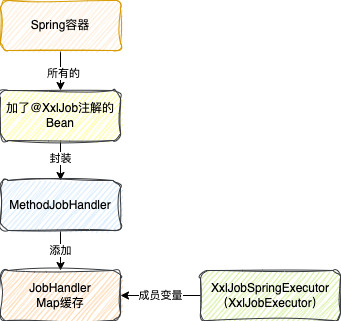
至於GlueJobHandler和ScriptJobHandler都是任務觸發時才會建立
除了上面這幾種,你也自己實現JobHandler,手動註冊到JobHandler的快取中,也是可以通過排程中心觸發的
2、建立一個Http伺服器
除了初始化JobHandler之外,執行器還會建立一個Http伺服器
這個伺服器埠號就是通過XxlJobSpringExecutor設定的埠,demo中就是設定的是9999,底層是基於Netty實現的
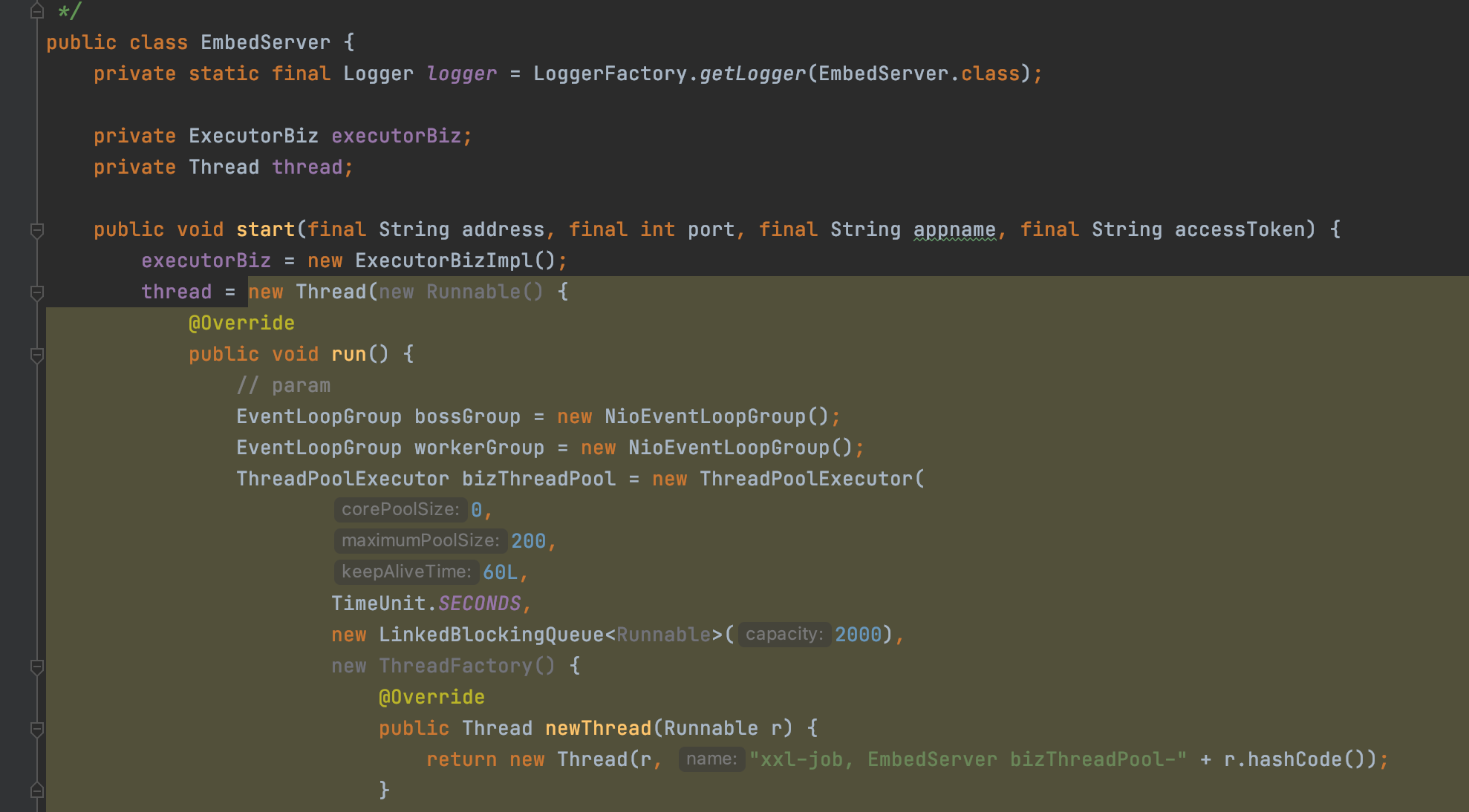
這個Http伺服器端會接收來自排程中心的請求
當執行器接收到排程中心的請求時,會把請求交給ExecutorBizImpl來處理
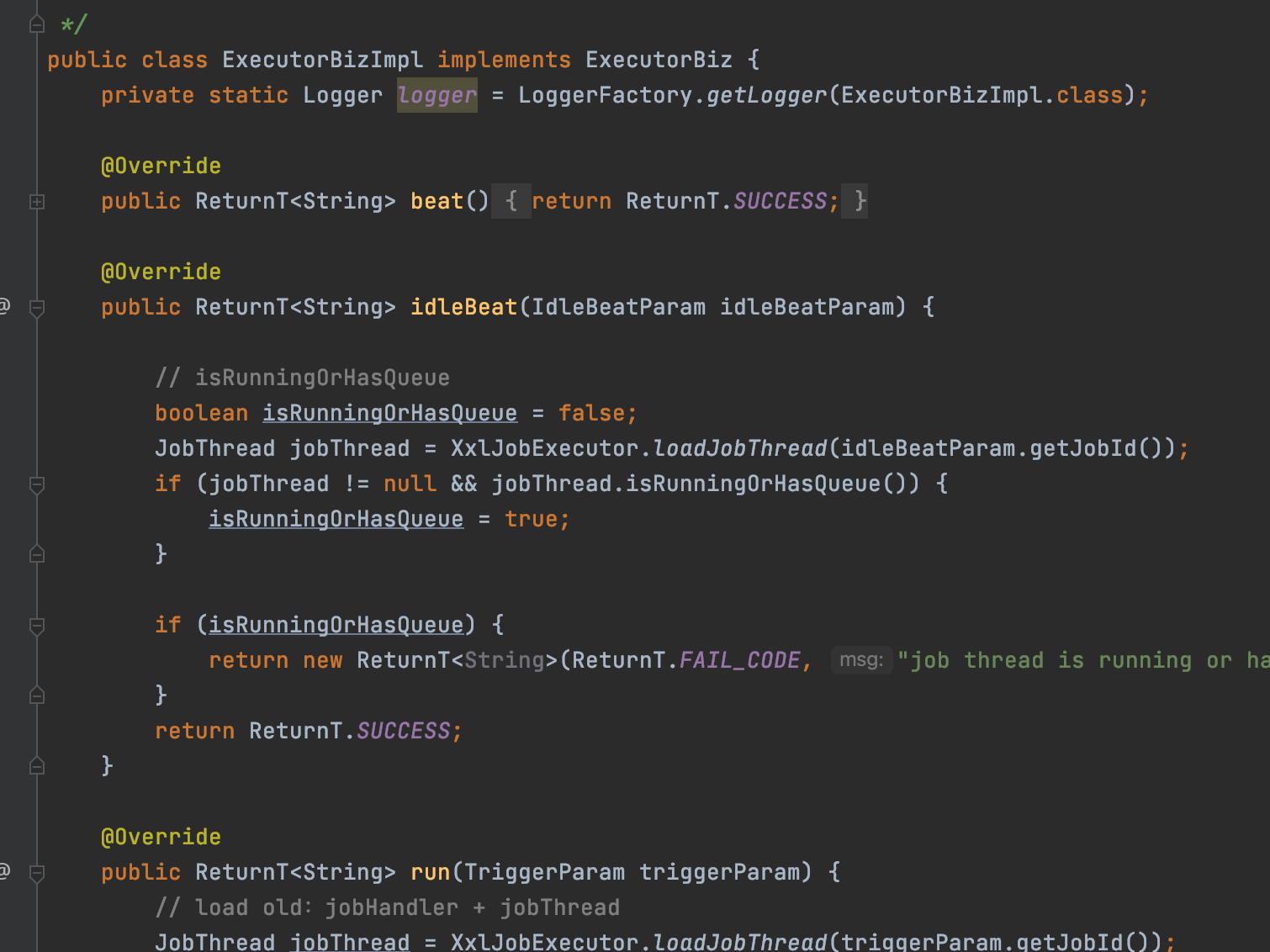
這個類非常重要,所有排程中心的請求都是這裡處理的
ExecutorBizImpl實現了ExecutorBiz介面
當你翻原始碼的時候會發現,ExecutorBiz還有一個ExecutorBizClient實現
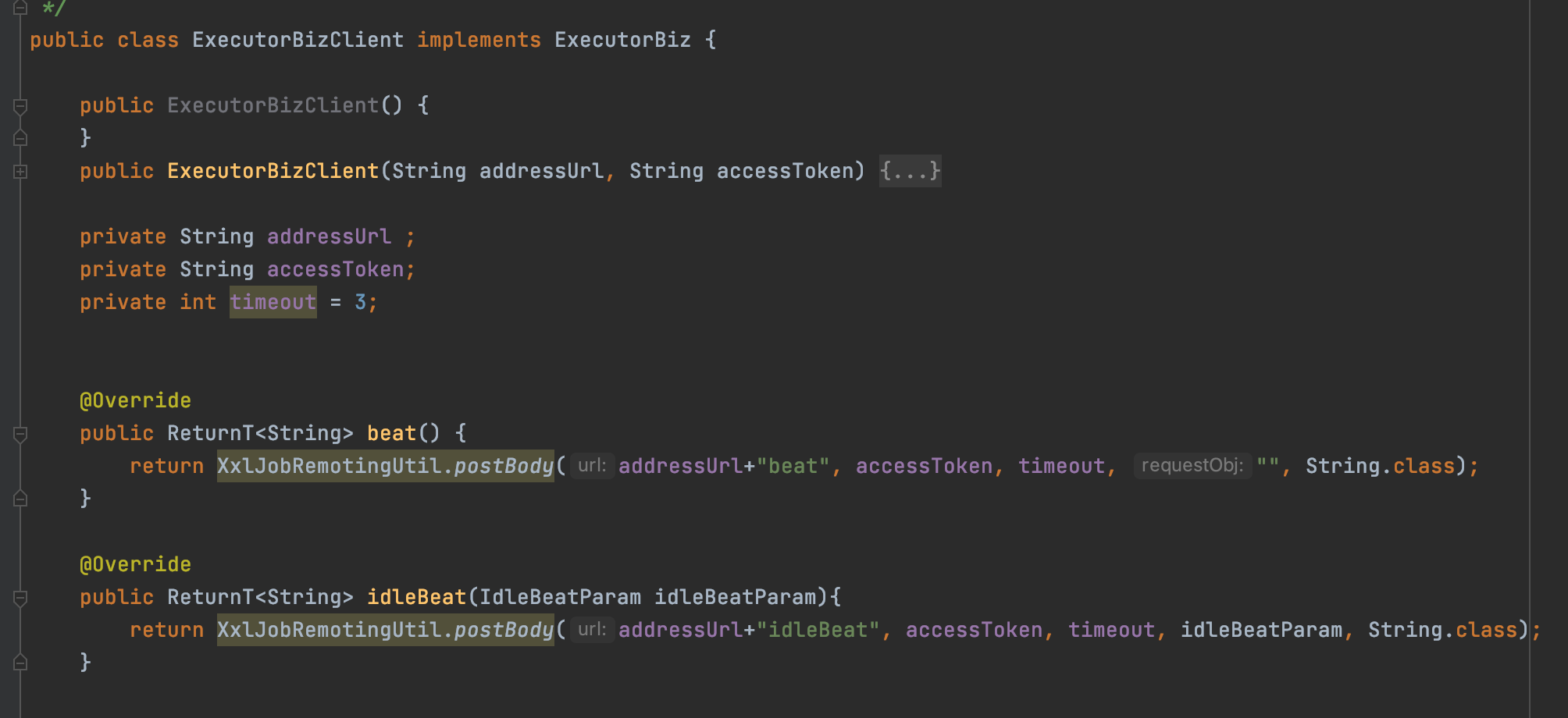
ExecutorBizClient的實現就是傳送http請求,所以這個實現類是在排程中心使用的,用來存取執行器提供的http介面

3、註冊到排程中心
當執行器啟動的時候,會啟動一個註冊執行緒,這個執行緒會往排程中心註冊當前執行器的資訊,包括兩部分資料
執行器的名字,也就是設定的appname 執行器所在機器的ip和埠,這樣排程中心就可以存取到這個執行器提供的Http介面
前面提到每個服務範例都會對應一個執行器範例,所以呼叫中心會儲存每個執行器範例的地址
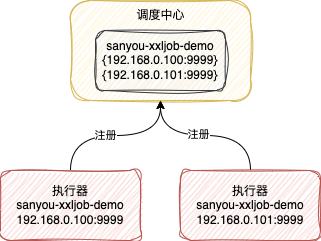
這裡你可以把排程中心的功能類比成註冊中心
任務觸發原理
弄明白執行器啟動時幹了哪些事,接下來講一講Xxl-Job最最核心的功能,那就是任務觸發的原理
任務觸發原理我會分下面5個小點來講解
任務如何觸發? 快慢執行緒池的非同步觸發任務優化 如何選擇執行器範例? 執行器如何去執行任務? 任務執行結果的回撥
1、任務如何觸發?
排程中心在啟動的時候,會開啟一個執行緒,這個執行緒的作用就是來計算任務觸發時機,這裡我把這個執行緒稱為排程執行緒
這個排程執行緒會去查詢xxl_job_info這張表
這張表存了任務的一些基本資訊和任務下一次執行的時間
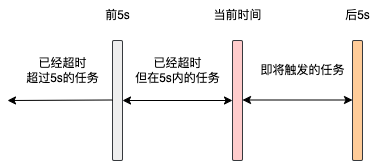
排程執行緒會去查詢下一次執行的時間 <= 當前時間 + 5s的任務
這個5s是XxlJob寫死的,被稱為預讀時間,提前讀出來,保證任務能準時觸發
舉個例子,假設當前時間是2023-11-29 08:00:10,這裡的查詢就會查出下一次任務執行時間在2023-11-29 08:00:15之前執行的任務

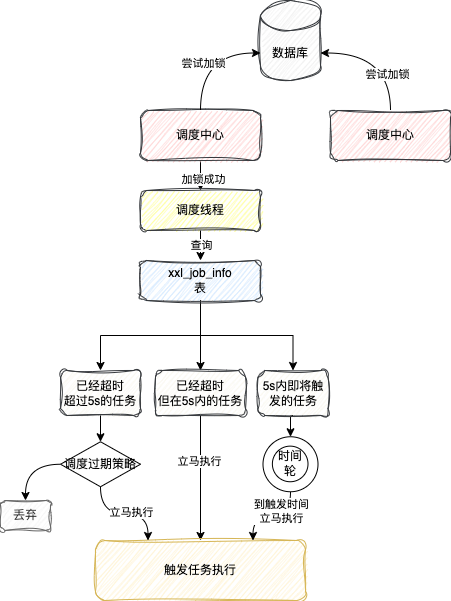
查詢到任務之後,排程執行緒會去將這些任務根據執行時間劃分為三個部分:
當前時間已經超過任務下一次執行時間5s以上,也就是需要在 2023-11-29 08:00:05(不包括05s)之前的執行的任務當前時間已經超過任務下一次執行時間,但是但不足5s,也就是在 2023-11-29 08:00:05和2023-11-29 08:00:10(不包括10s)之間執行的任務還未到觸發時間,但是一定是5s內就會觸發執行的
對於第一部分的已經超過5s以上時間的任務,會根據任務設定的排程過期策略來選擇要不要執行
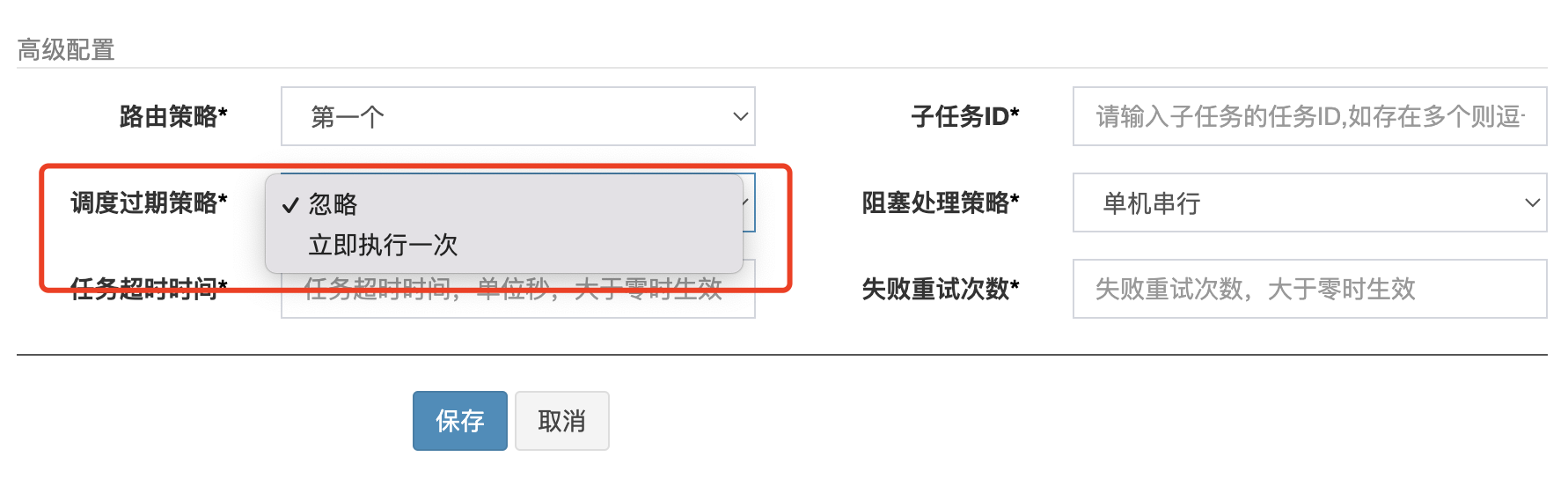
排程過期策略就兩種,就是字面意思
直接忽略這個已經過期的任務 立馬執行一次這個過期的任務
對於第二部分的超時時間在5s以內的任務,就直接立馬執行一次,之後如果判斷任務下一次執行時間就在5s內,會直接放到一個時間輪裡面,等待下一次觸發執行
對於第三部分任務,由於還沒到執行時間,所以不會立馬執行,也是直接放到時間輪裡面,等待觸發執行
當這批任務處理完成之後,不論是前面是什麼情況,排程執行緒都會去重新計算每個任務的下一次觸發時間,然後更新xxl_job_info這張表的下一次執行時間
到此,一次排程的計算就算完成了
之後排程執行緒還會繼續重複上面的步驟,查任務,排程任務,更新任務下次執行時間,一直死迴圈下去,這就實現了任務到了執行時間就會觸發的功能
這裡在任務觸發的時候還有一個很有意思的細節
由於排程中心可以是叢集的形式,每個排程中心範例都有排程執行緒,那麼如何保證任務在同一時間只會被其中的一個排程中心觸發一次?
我猜你第一時間肯定想到分散式鎖,但是怎麼加呢?
XxlJob實現就比較有意思了,它是基於八股文中常說的通過資料庫來實現的分散式鎖的
在排程之前,排程執行緒會嘗試執行下面這句sql
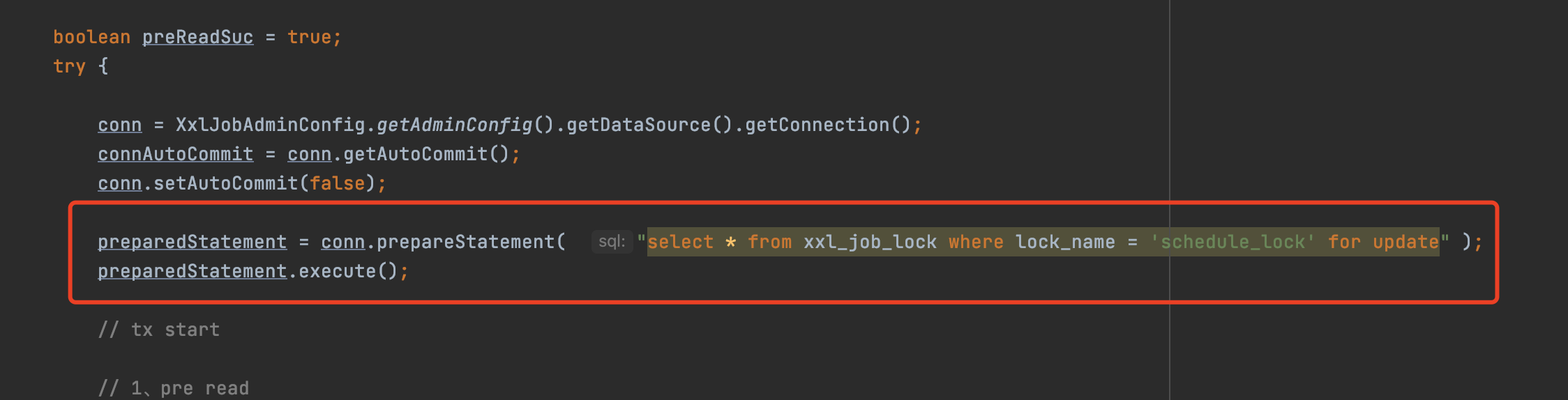
就是這個sql
select * from xxl_job_lock where lock_name = 'schedule_lock' for update
一旦執行成功,說明當前排程中心成功搶到了鎖,接下來就可以執行排程任務了
當排程任務執行完之後再去關閉連線,從而釋放鎖
由於每次執行之前都需要去獲取鎖,這樣就保證在排程中心叢集中,同時只有一個排程中心執行排程任務
最後畫一張圖來總結一下這一小節
2、快慢執行緒池的非同步觸發任務優化
當任務達到了觸發條件,並不是由排程執行緒直接去觸發執行器的任務執行
排程執行緒會將這個觸發的任務交給執行緒池去執行
所以上圖中的最後一部分觸發任務執行其實是執行緒池非同步去執行的
那麼,為什麼要使用執行緒池非同步呢?
主要是因為觸發任務,需要通過Http介面呼叫具體的執行器範例去觸發任務

這一過程必然會耗費時間,如果排程執行緒去做,就會耽誤排程的效率
所以就通過非同步執行緒去做,排程執行緒只負責判斷任務是否需要執行
並且,Xxl-Job為了進一步優化任務的觸發,將這個觸發任務執行的執行緒池劃分成快執行緒池和慢執行緒池兩個執行緒池

在呼叫執行器的Http介面觸發任務執行的時候,Xxl-Job會去記錄每個任務的觸發所耗費的時間
注意並不是任務執行時間,只是整個Http請求耗時時間,這是因為執行器執行任務是非同步執行的,所以整個時間不包括任務執行時間,這個後面會詳細說
當任務一次觸發的時間超過500ms,那麼這個任務的慢次數就會加1
如果這個任務一分鐘內觸發的慢次數超過10次,接下來就會將觸發任務交給慢執行緒池去執行
所以快慢執行緒池就是避免那種頻繁觸發並且每次觸發時間還很長的任務阻塞其它任務的觸發的情況發生
3、如何選擇執行器範例?
上一節說到,當任務需要觸發的時候,排程中心會向執行器傳送Http請求,執行器去執行具體的任務
那麼問題來了
由於一個執行器會有很多範例,那麼應該向哪個範例請求?
這其實就跟任務設定時設定的路由策略有關了
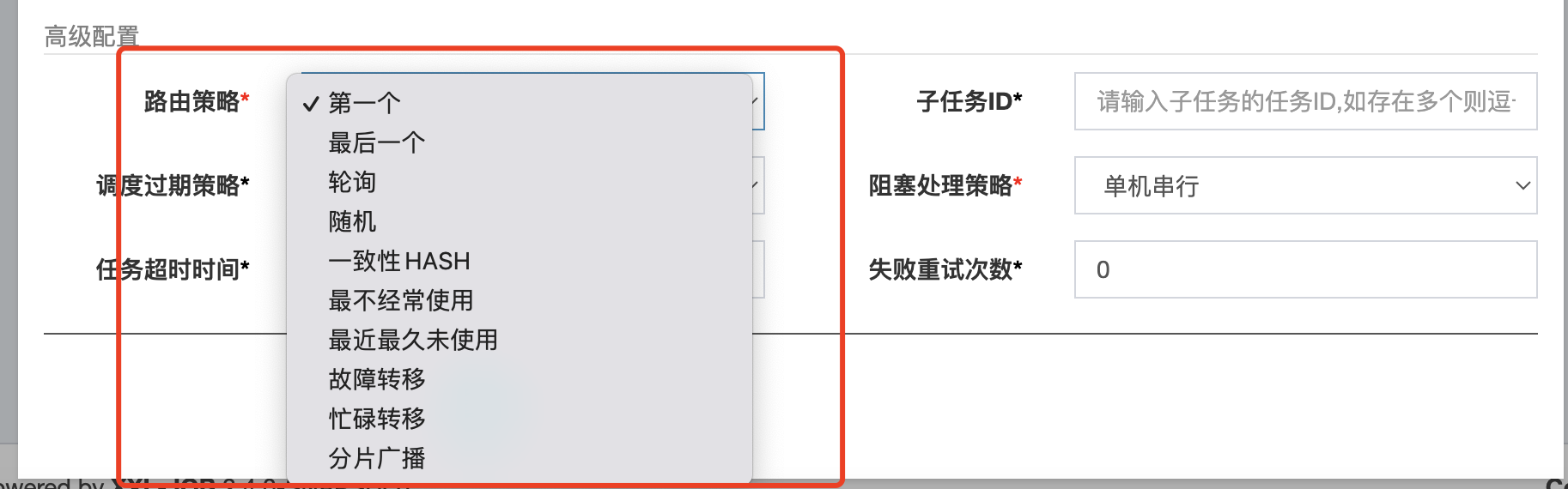
從圖上可以看出xxljob支援多種路由策略
除了分片廣播,其餘的具體的演演算法實現都是通過ExecutorRouter的實現類來實現的
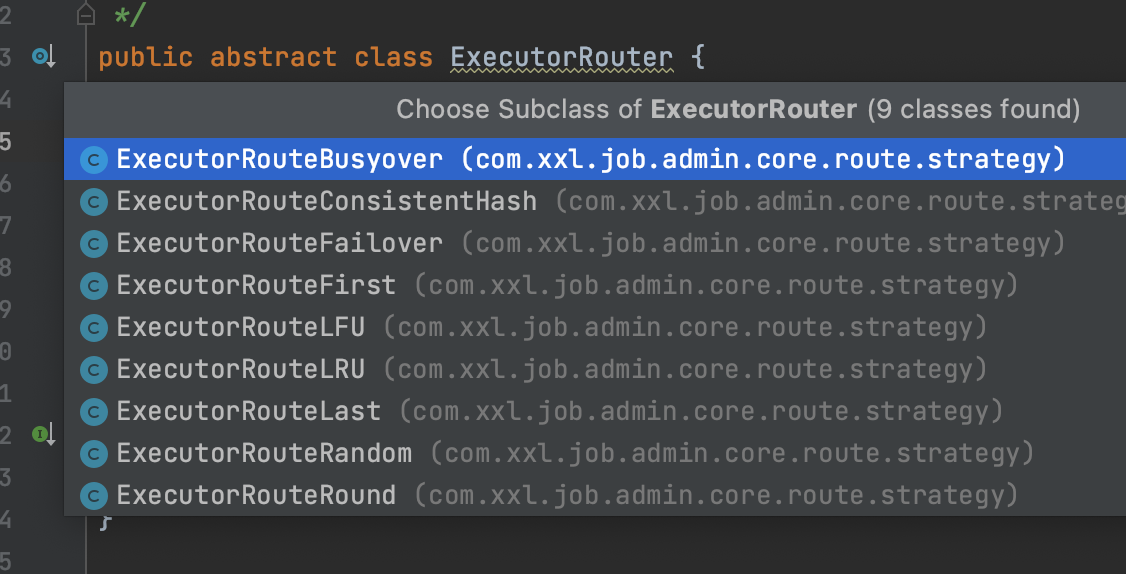
這裡簡單講一講各種演演算法的原理,有興趣的小夥伴可以去看看內部的實現細節
第一個、最後一個、輪詢、隨機都很簡單,沒什麼好說的
一致性Hash講起來比較複雜,你可以先看看這篇文章,再去檢視Xxl-Job的程式碼實現
https://zhuanlan.zhihu.com/p/470368641
最不經常使用(LFU:Least Frequently Used):Xxl-Job內部會有一個快取,統計每個任務每個地址的使用次數,每次都選擇使用次數最少的地址,這個快取每隔24小時重置一次
最近最久未使用(LRU:Least Recently Used):將地址存到LinkedHashMap中,它利用LinkedHashMap可以根據元素存取(get/put)順序來給元素排序的特性,快速找到最近最久未使用(未存取)的節點
故障轉移:排程中心都會去請求每個執行器,只要能接收到響應,說明執行器正常,那麼任務就會交給這個執行器去執行
忙碌轉移:排程中心也會去請求每個執行器,判斷執行器是不是正在執行當前需要執行的任務(任務執行時間過長,導致上一次任務還沒執行完,下一次又觸發了),如果在執行,說明忙碌,不能用,否則就可以用
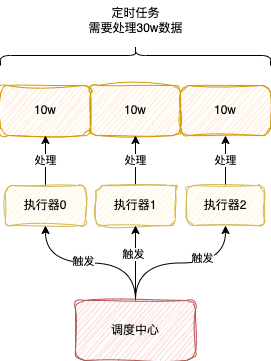
分片廣播:XxlJob給每個執行器分配一個編號,從0開始遞增,然後向所有執行器觸發任務,告訴每個執行器自己的編號和總共執行器的資料
我們可以通過XxlJobHelper#getShardIndex獲取到編號,XxlJobHelper#getShardTotal獲取到執行器的總資料量
分片廣播就是將任務量分散到各個執行器,每個執行器只執行一部分任務,加快任務的處理
舉個例子,比如你現在需要處理30w條資料,有3個執行器,此時使用分片廣播,那麼此時可將任務分成3分,每份10w條資料,執行器根據自己的編號選擇對應的那份10w資料處理
當選擇好了具體的執行器範例之後,呼叫中心就會攜帶一些觸發的引數,傳送Http請求,觸發任務
4、執行器如何去執行任務?
相信你一定記得我前面在說執行器啟動是會建立一個Http伺服器的時候提到這麼一句
當執行器接收到排程中心的請求時,會把請求交給ExecutorBizImpl來處理
所以前面提到的故障轉移和忙碌轉移請求執行器進行判斷,最終執行器也是交給ExecutorBizImpl處理的
執行器處理觸發請求是這個ExecutorBizImpl的run方法實現的
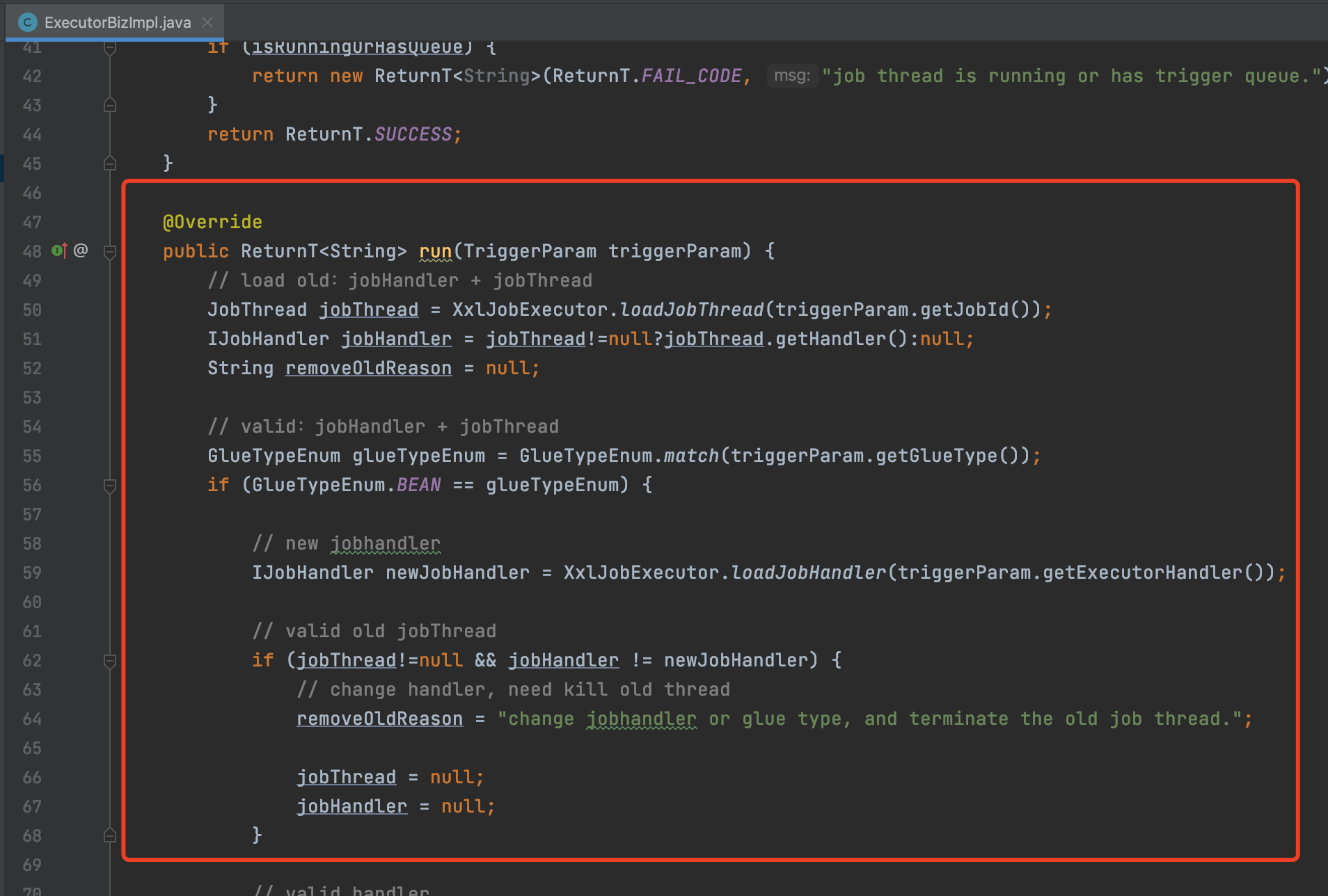
當執行器接收到請求,在正常情況下,執行器會去為這個任務建立一個單獨的執行緒,這個執行緒被稱為JobThread
每個任務在觸發的時候都有單獨的執行緒去執行,保證不同的任務執行互不影響
之後任務並不是直接交給執行緒處理的,而是直接放到一個記憶體佇列中,執行緒直接從佇列中獲取任務
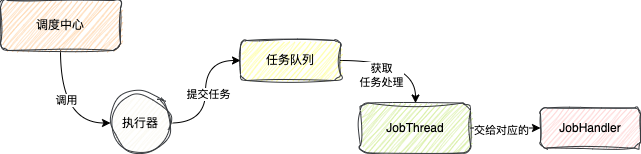
這裡我相信你一定有個疑惑
為什麼不直接處理,而是交給佇列,從佇列中獲取任務呢?
那就得講講不正常的情況了
如果排程中心選擇的執行器範例正在處理定時任務,那麼此時該怎麼處理呢?**
這時就跟阻塞處理策略有關了
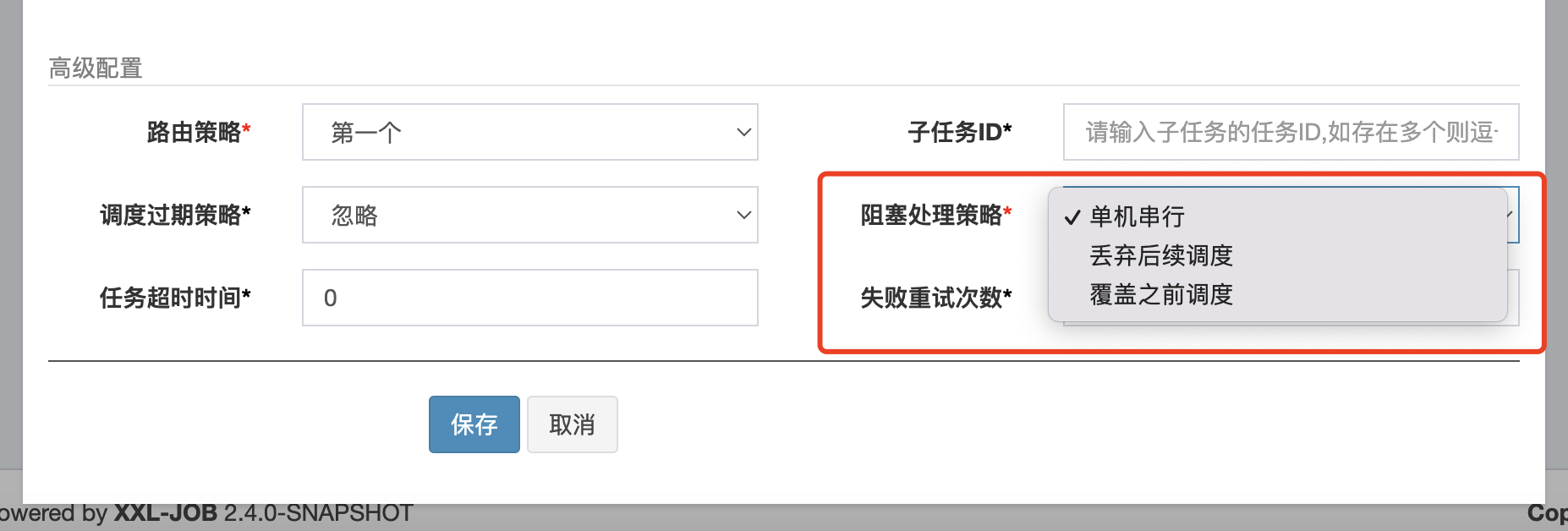
阻塞處理策略總共有三種:
單機序列 丟棄後續排程 覆蓋之前排程
單機序列的實現就是將任務放到佇列中,由於佇列是先進先出的,所以就實現序列,這也是為什麼放在佇列的原因
丟棄排程的實現就是執行器什麼事都不用幹就可以了,自然而然任務就丟了
覆蓋之前排程的實現就很暴力了,他是直接重新建立一個JobThread來執行任務,並且嘗試打斷之前的正在處理任務的JobThread,丟棄之前佇列中的任務
打斷是通過Thread#interrupt方法實現的,所以正在處理的任務還是有可能繼續執行,並不是說一打斷正在執行的任務就終止了
這裡需要注意的一點就是,阻塞處理策略是對於單個執行器上的任務來生效的,不同執行器範例上的同一個任務是互不影響的
比如說,有一個任務有兩個執行器A和B,路由策略是輪詢
任務第一次觸發的時候選擇了執行器範例A,由於任務執行時間長,任務第二次觸發的時候,執行器的路由到了B,此時A的任務還在執行,但是B感知不到A的任務在執行,所以此時B就直接執行了任務
所以此時你設定的什麼阻塞處理策略就沒什麼用了
如果業務中需要保證定時任務同一時間只有一個能執行,需要把任務路由到同一個執行器上,比如路由策略就選擇第一個
5、任務執行結果的回撥
當任務處理完成之後,執行器會將任務執行的結果傳送給排程中心

如上圖所示,這整個過程也是非同步化的
JobThread會將任務執行的結果傳送到一個記憶體佇列中 執行器啟動的時候會開啟一個處傳送任務執行結果的執行緒:TriggerCallbackThread 這個執行緒會不停地從佇列中獲取所有的執行結果,將執行結果批次傳送給排程中心 呼叫中心接收到請求時,會根據執行的結果修改這次任務的執行狀態和進行一些後續的事,比如失敗了是否需要重試,是否有子任務需要觸發等等
到此,一次任務的就算真正處理完成了
最後
最後我從官網撈了一張Xxl-Job架構圖
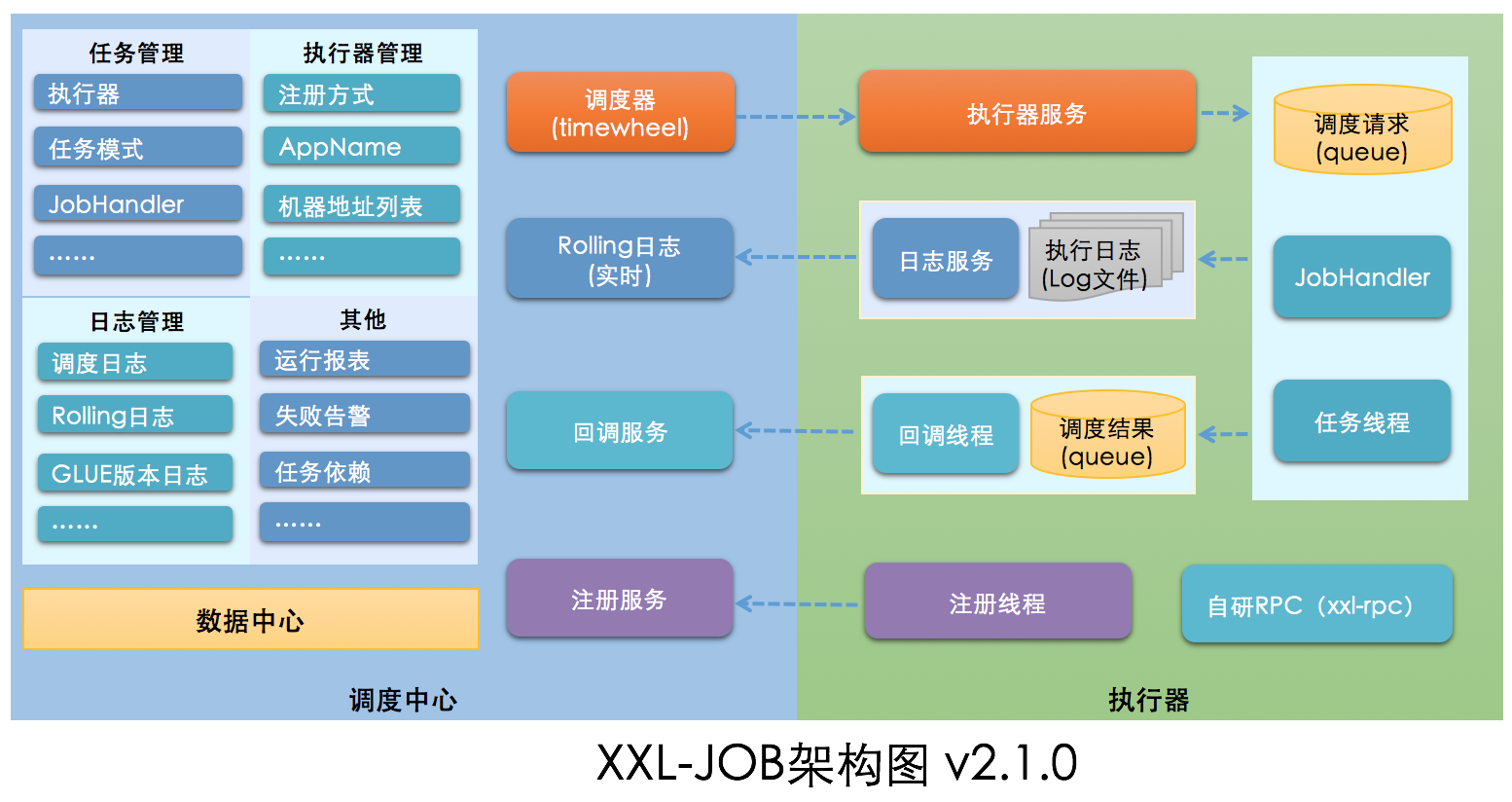
奈何作者不更新吶,導致這個圖稍微有點老了,有點跟現有的架構對不上
比如說圖中的自研RPC(xxl-rpc)部分已經替換成了Http協定,這主要是擁抱生態,方便跨語言接入
但是不要緊,大體還是符合現在的整個的架構
從架構圖中也可以看出來,本文除了紀錄檔部分的內容沒有提到,其它的整個核心邏輯基本上都講到了
而紀錄檔部分其實是個輔助的作用,讓你更方便檢視任務的執行情況,對任務的觸發邏輯是沒有影響的,所以就沒講了
所以從本文的講解再到官方架構圖,你會發現整個Xxl-Job不論是使用還是實現都是比較簡單的,非常的輕量級
說點什麼
好了,到這又又成功講完了一款框架或者說是中介軟體的核心架構原理,不知道你有沒有什麼一點收穫
如果你覺得有點收穫,歡迎點贊、在看、收藏、轉發分享給其他需要的人
你的支援就是我更新文章最大的動力,非常地感謝!
其實這篇文章我在十一月上旬的時候我就打算寫了
但是由於十一月上旬之後我遇到一系列煩心事,導致我實在是沒有精力去寫
現在到月底了,雖然煩心事只增不少,但是我還是想了想,覺得不能再拖了,最後也是連續肝了幾個晚上,才算真正完成
所以如果你發現文章有什麼不足和問題,也歡迎批評指正
當這篇文章快寫完的時候,我收到了來自阿里雲社群的頒發的專家博主的證書,也算為即將過去的十一月畫下了一個不太完美的句號

好了,本文就講到這裡了,讓我們十二月再見,拜拜!
往期熱門文章推薦
掃碼或者搜尋關注公眾號 三友的java日記 ,及時乾貨不錯過,公眾號致力於通過畫圖加上通俗易懂的語言講解技術,讓技術更加容易學習,回覆 面試 即可獲得一套面試真題。
