機器學習-學習率:從理論到實戰,探索學習率的調整策略
本文全面深入地探討了機器學習和深度學習中的學習率概念,以及其在模型訓練和優化中的關鍵作用。文章從學習率的基礎理論出發,詳細介紹了多種高階調整策略,並通過Python和PyTorch程式碼範例提供了實戰經驗。
關注TechLead,分享AI全維度知識。作者擁有10+年網際網路服務架構、AI產品研發經驗、團隊管理經驗,同濟本復旦碩,復旦機器人智慧實驗室成員,阿里雲認證的資深架構師,專案管理專業人士,上億營收AI產品研發負責人。

一、引言
學習率(Learning Rate)是機器學習和深度學習中一個至關重要的概念,它直接影響模型訓練的效率和最終效能。簡而言之,學習率控制著模型引數在訓練過程中的更新幅度。一個合適的學習率能夠在確保模型收斂的同時,提高訓練效率。然而,學習率的選擇並非易事;過高或過低的學習率都可能導致模型效能下降或者訓練不穩定。
在傳統的機器學習演演算法中,例如支援向量機(SVM)和隨機森林(Random Forest),引數優化通常是通過解析方法或者貪婪演演算法來完成的,因此學習率的概念相對較少涉及。但在涉及優化問題和梯度下降(Gradient Descent)的方法中,例如神經網路,學習率成了一個核心的調節因子。

學習率的選擇對於模型效能有著顯著影響。在實踐中,不同型別的問題和資料集可能需要不同的學習率或者學習率調整策略。因此,瞭解如何合適地設定和調整學習率,是每一個機器學習從業者和研究者都需要掌握的基礎知識。
這個領域的研究已經從簡單的固定學習率擴充套件到了更為複雜和高階的自適應學習率演演算法,如 AdaGrad、RMSprop 和 Adam 等。這些演演算法試圖在訓練過程中動態地調整學習率,以適應模型和資料的特性,從而達到更好的優化效果。
綜上所述,學習率不僅是一個基礎概念,更是一個充滿挑戰和機會的研究方向,具有廣泛的應用前景和深遠的影響。在接下來的內容中,我們將深入探討這一主題,從基礎理論到高階演演算法,再到實際應用和最新研究進展。
二、學習率基礎
學習率(Learning Rate)在優化演演算法,尤其是梯度下降和其變體中,扮演著至關重要的角色。它影響著模型訓練的速度和穩定性,並且是實現模型優化的關鍵引數之一。本章將從定義與解釋、學習率與梯度下降、以及學習率對模型效能的影響等幾個方面,詳細地介紹學習率的基礎知識。
定義與解釋
學習率通常用符號 (\alpha) 表示,並且是一個正實數。它用於控制優化演演算法在更新模型引數時的步長。具體地,給定一個損失函數 ( J(\theta) ),其中 ( \theta ) 是模型的引數集合,梯度下降演演算法通過以下公式來更新這些引數:

學習率與梯度下降
學習率在不同型別的梯度下降演演算法中有不同的應用和解釋。最常見的三種梯度下降演演算法是:
- 批次梯度下降(Batch Gradient Descent)
- 隨機梯度下降(Stochastic Gradient Descent, SGD)
- 小批次梯度下降(Mini-batch Gradient Descent)
在批次梯度下降中,學習率應用於整個資料集,用於計算損失函數的平均梯度。而在隨機梯度下降和小批次梯度下降中,學習率應用於單個或一小批樣本,用於更新模型引數。
隨機梯度下降和小批次梯度下降由於其高度隨機的性質,常常需要一個逐漸衰減的學習率,以幫助模型收斂。
學習率對模型效能的影響
選擇合適的學習率是非常重要的,因為它會直接影響模型的訓練速度和最終效能。具體來說:
- 過大的學習率:可能導致模型在最優解附近震盪,或者在極端情況下導致模型發散。
- 過小的學習率:雖然能夠保證模型最終收斂,但是會大大降低模型訓練的速度。有時,它甚至可能導致模型陷入區域性最優解。
實驗表明,不同的模型結構和不同的資料集通常需要不同的學習率設定。因此,實踐中常常需要多次嘗試和調整,或者使用自適應學習率演演算法。
綜上,學習率是機器學習中一個基礎但複雜的概念。它不僅影響模型訓練的速度,還會影響模型的最終效能。因此,理解學習率的基礎知識和它在不同情境下的應用,對於機器學習的實踐和研究都是非常重要的。
三、學習率調整策略
學習率的調整策略是優化演演算法中一個重要的研究領域。合適的調整策略不僅能夠加速模型的收斂速度,還能提高模型的泛化效能。在深度學習中,由於模型通常包含大量的引數和複雜的結構,選擇和調整學習率變得尤為關鍵。本章將詳細介紹幾種常用的學習率調整策略,從傳統方法到現代自適應方法。
常數學習率
最簡單的學習率調整策略就是使用一個固定的學習率。這是最早期梯度下降演演算法中常用的方法。雖然實現簡單,但常數學習率往往不能適應訓練動態,可能導致模型過早地陷入區域性最優或者在全域性最優點附近震盪。
時間衰減
時間衰減策略是一種非常直觀的調整方法。在這種策略中,學習率隨著訓練迭代次數的增加而逐漸減小。公式表示為:

自適應學習率
自適應學習率演演算法試圖根據模型的訓練狀態動態調整學習率。以下是一些廣泛應用的自適應學習率演演算法:
AdaGrad

RMSprop

Adam

綜上,學習率調整策略不僅影響模型訓練的速度,還決定了模型的收斂性和泛化能力。選擇合適的學習率調整策略是優化演演算法成功應用的關鍵之一。
四、學習率的程式碼實戰
在實際應用中,理論知識是不夠的,還需要具體的程式碼實現來實驗和驗證各種學習率調整策略的效果。本節將使用Python和PyTorch來展示如何實現前文提到的幾種學習率調整策略,並在一個簡單的模型上進行測試。
環境設定
首先,確保你已經安裝了PyTorch。如果沒有,可以使用以下命令進行安裝:
pip install torch
資料和模型
為了方便演示,我們使用一個簡單的線性迴歸模型和生成的模擬資料。
import torch
import torch.nn as nn
import torch.optim as optim
# 生成模擬資料
x = torch.rand(100, 1) * 10 # shape=(100, 1)
y = 2 * x + 3 + torch.randn(100, 1) # y = 2x + 3 + noise
# 線性迴歸模型
class LinearRegression(nn.Module):
def __init__(self):
super(LinearRegression, self).__init__()
self.linear = nn.Linear(1, 1)
def forward(self, x):
return self.linear(x)
model = LinearRegression()
常數學習率
使用固定的學習率進行優化。
# 使用SGD優化器和常數學習率
optimizer = optim.SGD(model.parameters(), lr=0.01)
# 訓練模型
for epoch in range(100):
outputs = model(x)
loss = nn.MSELoss()(outputs, y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
print(f'Epoch {epoch+1}, Loss: {loss.item()}')
在這裡,我們使用了常數學習率0.01,並沒有進行任何調整。
時間衰減
應用時間衰減調整學習率。
# 初始化引數
lr = 0.1
gamma = 0.1
decay_rate = 0.95
# 使用SGD優化器
optimizer = optim.SGD(model.parameters(), lr=lr)
# 訓練模型
for epoch in range(100):
outputs = model(x)
loss = nn.MSELoss()(outputs, y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
# 更新學習率
lr = lr * decay_rate
for param_group in optimizer.param_groups:
param_group['lr'] = lr
print(f'Epoch {epoch+1}, Learning Rate: {lr}, Loss: {loss.item()}')
這裡我們使用了一個簡單的時間衰減策略,每個epoch後將學習率乘以0.95。
Adam優化器
使用自適應學習率的Adam優化器。
# 使用Adam優化器
optimizer = optim.Adam(model.parameters(), lr=0.01)
# 訓練模型
for epoch in range(100):
outputs = model(x)
loss = nn.MSELoss()(outputs, y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
print(f'Epoch {epoch+1}, Loss: {loss.item()}')
Adam優化器會自動調整學習率,因此我們不需要手動進行調整。
在這幾個例子中,你可以明顯看到學習率調整策略如何影響模型的訓練過程。選擇適當的學習率和調整策略是實現高效訓練的關鍵。這些程式碼範例提供了一個出發點,但在實際應用中,通常需要根據具體問題進行更多的調整和優化。
五、學習率的最佳實踐
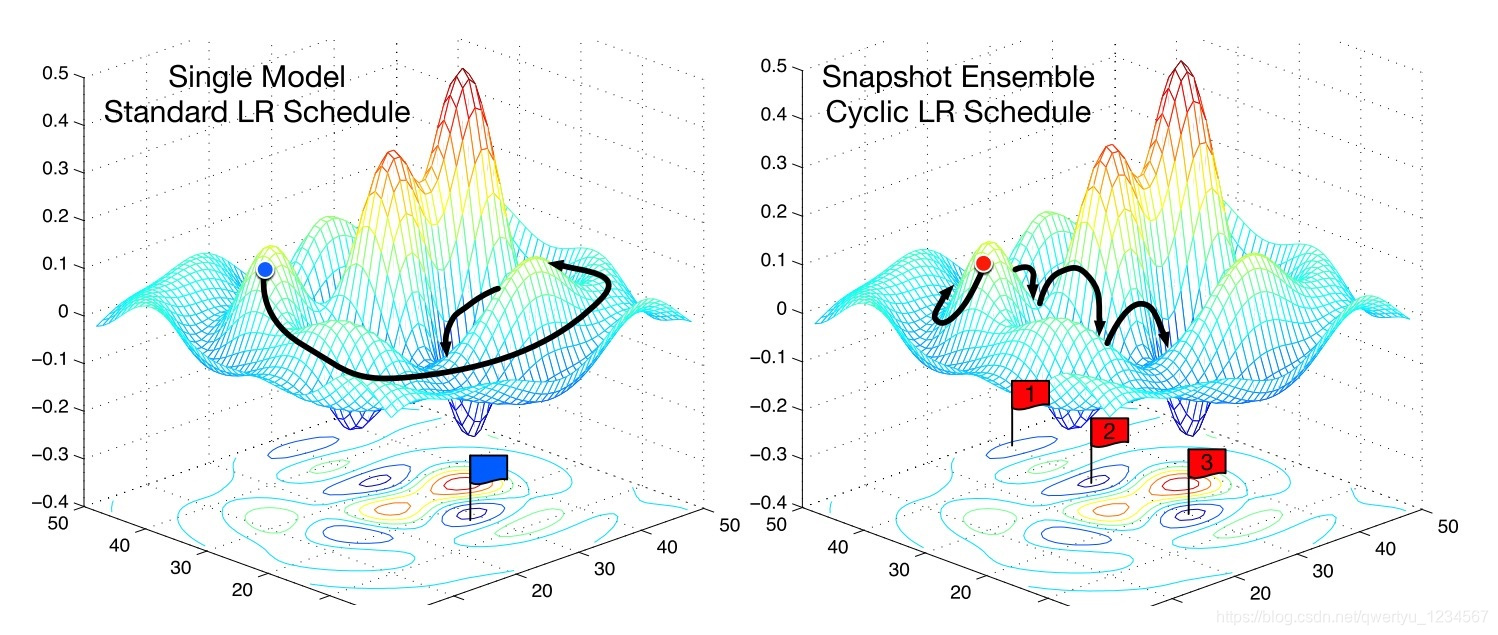
在深度學習中,選擇合適的學習率和調整策略對模型效能有著巨大的影響。本節將探討一些學習率的最佳實踐,每個主題後都會提供具體的例子來增加理解。
學習率範圍測試
定義: 學習率範圍測試是一種經驗性方法,用於找出模型訓練中較優的學習率範圍。
例子: 你可以從一個非常小的學習率(如0.0001)開始,每個mini-batch或epoch後逐漸增加,觀察模型的損失函數如何變化。當損失函數開始不再下降或開始上升時,就可以找出一個合適的學習率範圍。
迴圈學習率(Cyclical Learning Rates)
定義: 迴圈學習率是一種策略,其中學習率會在一個預定義的範圍內週期性地變化。
例子: 你可以設定學習率在0.001和0.1之間迴圈,週期為10個epochs。這種方法有時能更快地收斂,尤其是當你不確定具體哪個學習率值是最佳選擇時。
學習率熱重啟(Learning Rate Warm Restart)
定義: 在每次達到預設的訓練週期後,將學習率重置為較高的值,以重新「啟用」模型的訓練。
例子: 假設你設定了一個週期為20個epochs的學習率衰減策略,每次衰減到較低的值後,你可以在第21個epoch將學習率重置為一個較高的值(如初始值的0.8倍)。
梯度裁剪與學習率
定義: 梯度裁剪是在優化過程中限制梯度的大小,以防止因學習率過大而導致的梯度爆炸。
例子: 在某些NLP模型或RNN模型中,由於梯度可能會變得非常大,因此採用梯度裁剪和較小的學習率通常更為穩妥。
使用預訓練模型和微調學習率
定義: 當使用預訓練模型(如VGG、ResNet等)時,微調學習率是非常關鍵的。通常,預訓練模型的頂層(或自定義層)會使用更高的學習率,而底層會使用較低的學習率。
例子: 如果你在一個影象分類任務中使用預訓練的ResNet模型,可以為新新增的全連線層設定較高的學習率(如0.001),而對於預訓練模型的其他層則可以設定較低的學習率(如0.0001)。
總體而言,學習率的選擇和調整需要根據具體的應用場景和模型需求來進行。這些最佳實踐提供了一些通用的指導方針,但最重要的還是通過不斷的實驗和調整來找到最適合你模型和資料的策略。
六、總結
學習率不僅是機器學習和深度學習中的一個基礎概念,而且是模型優化過程中至關重要的因素。儘管其背後的數學原理相對直觀,但如何在實踐中有效地應用和調整學習率卻是一個充滿挑戰的問題。本文從學習率的基礎知識出發,深入探討了各種調整策略,並通過程式碼實戰和最佳實踐為讀者提供了全面的指導。
-
自適應優化與全域性最優:雖然像Adam這樣的自適應學習率方法在很多情況下表現出色,但它們不一定總是能找到全域性最優解。在某些需要精確優化的應用中(如生成模型),更加保守的手動調整學習率或者更復雜的排程策略可能會更有效。
-
複雜性與魯棒性的權衡:更復雜的學習率調整策略(如迴圈學習率、學習率熱重啟)雖然能帶來更快的收斂,但同時也增加了模型過擬合的風險。因此,在使用這些高階策略時,配合其他正則化技術(如Dropout、權重衰減)是非常重要的。
-
資料依賴性:學習率的最佳設定和調整策略高度依賴於具體的資料分佈。例如,在處理不平衡資料集時,較低的學習率可能更有助於模型學習到少數類的特徵。
-
模型複雜性與學習率:對於更復雜的模型(如深層網路或者Transformer結構),通常需要更精細的學習率調控。這不僅因為複雜模型有更多的引數,還因為它們的優化面通常更為複雜和崎嶇。
通過深入地理解學習率和其在不同場景下的應用,我們不僅可以更高效地訓練模型,還能在模型優化的過程中獲得更多關於資料和模型結構的洞見。總之,掌握學習率的各個方面是任何希望在機器學習領域取得成功的研究者或工程師必須面對的挑戰之一。
關注TechLead,分享AI全維度知識。作者擁有10+年網際網路服務架構、AI產品研發經驗、團隊管理經驗,同濟本復旦碩,復旦機器人智慧實驗室成員,阿里雲認證的資深架構師,專案管理專業人士,上億營收AI產品研發負責人。
如有幫助,請多關注
TeahLead KrisChang,10+年的網際網路和人工智慧從業經驗,10年+技術和業務團隊管理經驗,同濟軟體工程本科,復旦工程管理碩士,阿里雲認證雲服務資深架構師,上億營收AI產品業務負責人。